Educational AI equity and socioeconomic achievement gaps
The rapid integration of artificial intelligence into global educational frameworks has frequently been characterized as a democratizing force. Early pedagogical theories posited that the proliferation of large language models (LLMs) and intelligent tutoring systems would act as a universal equalizer, providing personalized, on-demand instruction to marginalized learners and effectively bridging the historical achievement gap. However, empirical data collected across global educational institutions between 2024 and 2026 suggests a far more complex reality. While generative artificial intelligence demonstrably improves baseline academic performance and offers scalable cognitive scaffolding, it simultaneously introduces new, sophisticated vectors of stratification. The integration of algorithmic personalization operates within deeply entrenched institutional and economic frameworks, inadvertently exacerbating disparities through premium subscription paywalls, divergent algorithmic literacy, digital redlining in educational administration, and unequal institutional oversight 123.
This analysis examines the intersection of generative artificial intelligence, traditional intelligent tutoring systems, and educational equity. By evaluating global adoption metrics, cognitive outcomes, institutional policies, and algorithmic bias, the research delineates how algorithmic personalization functions to both narrow and widen the achievement gap across socioeconomic boundaries.
Socioeconomic Stratification in Algorithmic Usage
The foundational assumption governing early educational technology policy suggested that the universal availability of generative artificial intelligence tools would naturally yield equitable learning outcomes. This framework has been decisively challenged by the emergence of the "access-outcome paradox," a phenomenon where students possessing identical access to artificial intelligence software demonstrate vastly different academic achievements 2. The determining factor in educational advantage has shifted from basic hardware access to the support infrastructure, financial capacity, and algorithmic literacy that guide tool usage.
Commercial Paywalls and the Capabilities Gap
A primary mechanism widening the achievement gap is the commercial operational model of generative artificial intelligence. While basic iterations of large language models are frequently available to students without cost, advanced capabilities - including deeper reasoning algorithms, multimodal processing, specialized domain queries, and faster computational speeds - are securely placed behind subscription paywalls 456. This tiered access creates an uneven academic playing field heavily weighted toward affluent students.
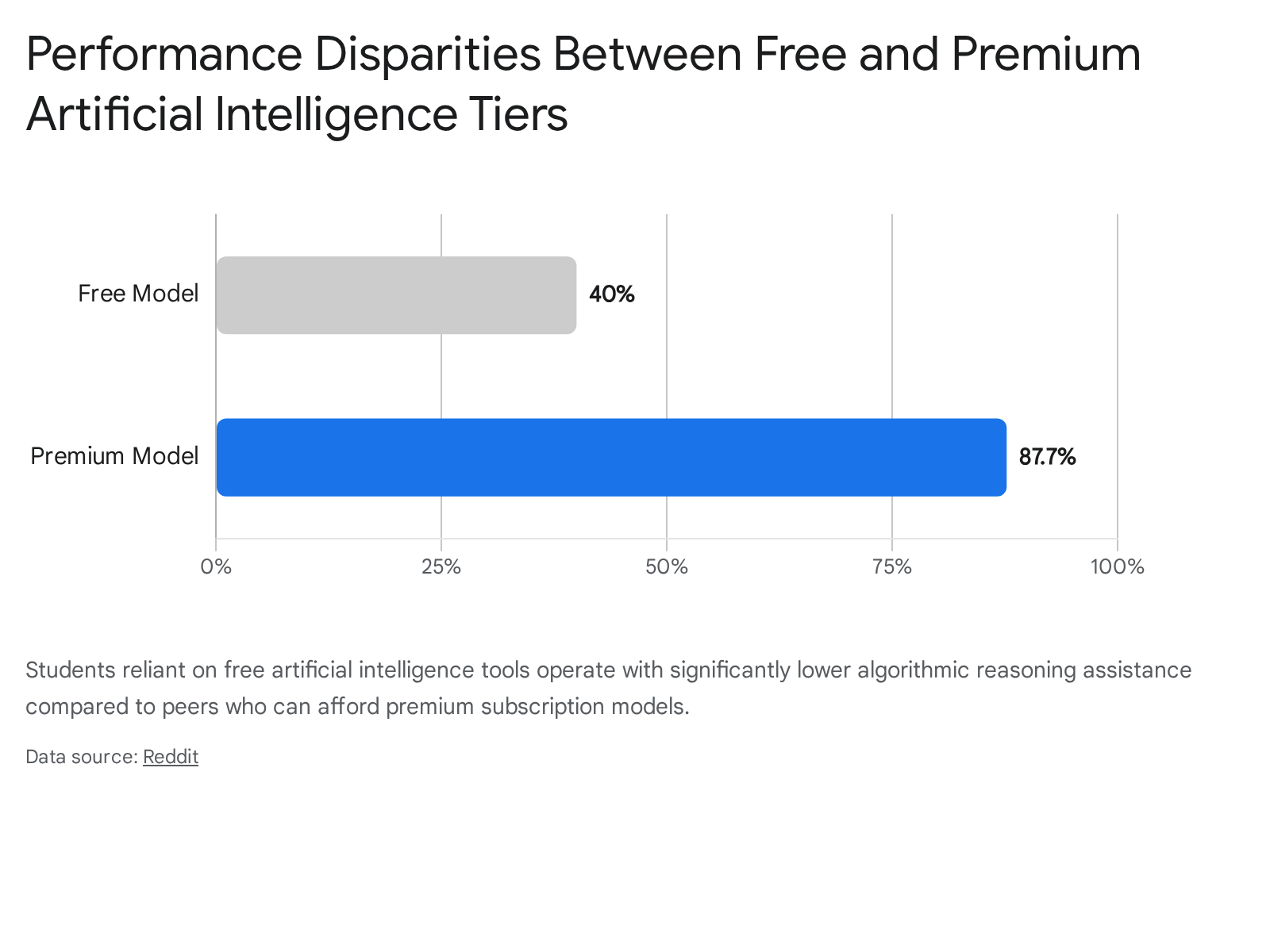
The financial stratification of artificial intelligence capability has immediate implications for student performance and institutional equity. Research indicates a dramatic performance gap between free and premium artificial intelligence tiers, with free models scoring approximately 40% on advanced reasoning tasks compared to 87.7% for premium counterparts 7.
Advanced image generation tools, such as Midjourney, frequently eliminate free tiers entirely, offering basic access starting at $10 per month, while industry-standard models like ChatGPT Plus require $20 monthly subscriptions for reliable, high-speed access 5.
Students with financial constraints are forced to rely on slower, less accurate, and highly hallucination-prone free alternatives. Consequently, institutional surveys highlight a growing anxiety among university students regarding digital inequity. Academic success increasingly correlates with a student's financial capacity to outsource complex analytical tasks to advanced architectures, leading to a two-tiered system where only those who can afford premium subscriptions gain a competitive edge in both academic performance and future employability 678.
Divergence in Prompting Strategies by Socioeconomic Status
Beyond financial access, a student's socioeconomic status (SES) dictates the linguistic frameworks and cognitive strategies used to interact with algorithms. Researchers analyzing human-computer interaction term this phenomenon the "AI Gap," demonstrating that social class fundamentally alters prompting strategies, usage frequency, and the thematic context of algorithmic interactions 9.
Individuals from higher socioeconomic backgrounds utilize artificial intelligence predominately for academic, professional, and technical contexts. Their interactions are heavily centered on coding, data analysis, solving complex mathematical problems, and advanced writing tasks such as summarizing and proofreading 910. Conversely, lower-SES students are more likely to employ large language models for general knowledge queries, entertainment, and generic, unstructured brainstorming 910.
Extensive linguistic analyses of real-world user prompts reveal stark stylistic differences. Higher-SES students employ shorter, highly concise prompts utilizing technical jargon and elevated levels of linguistic abstraction. The average prompt length for upper-class users is 18.4 words, compared to 27.0 words for lower-class users 910. Lower-SES students generally use more concrete language and frequently anthropomorphize the artificial intelligence through politeness markers (e.g., "please," "thank you") and phatic expressions 910.
These socioeconomic linguistic variations directly impact the quality of the algorithmic output. Foundational large language models are optimized on training data that heavily skews toward abstract, higher-SES linguistic patterns and Western, English-language perspectives 19. Because the models are structurally aligned with middle- and upper-class phrasing, algorithms process lower-SES, concrete phrasing less effectively. This structural bias ensures that disadvantaged students receive lower-quality, less sophisticated assistance, exacerbating the digital divide despite equal access to the baseline technological interface 9.
Parental Artificial Intelligence Literacy and Support Structures
The academic benefits of generative artificial intelligence are heavily mediated by the technological literacy of the student's household. The achievement gap is increasingly defined not just by device access, but by the guidance a student receives to navigate emerging technologies safely and effectively 11.
Parental education levels strongly correlate with student artificial intelligence integration. High school students whose parents hold graduate degrees are substantially more likely to use generative models frequently for schoolwork; two-thirds of students in this demographic report regular academic usage 11. These highly educated parents demonstrate greater optimism and confidence in guiding their children through algorithmic ethics, limitations, and prompt engineering 1112.
The result is a compounding academic advantage. Students receiving systematic instruction at home regarding artificial intelligence optimization arrive at school with a heightened ability to extract high-level academic value from these tools 2. In contrast, parents without advanced digital literacy often lack the resources to supervise their children's algorithmic interactions. While surveys indicate that roughly 65% of parents want schools to teach responsible artificial intelligence use, the lack of institutional capacity often leaves students from lower-resourced backgrounds to experiment with free, data-extractive tools without necessary guardrails, leading to passive or shallow engagement with the technology 115.
Algorithmic Personalization and Cognitive Development
The core pedagogical promise of artificial intelligence lies in its capacity to dynamically adjust instructional content to match the individual learner's proficiency, effectively scaling the benefits of one-on-one, high-dose tutoring (HDT) 1314. While this personalization drives measurable academic gains, it simultaneously presents severe risks to cognitive endurance, critical thinking, and independent problem-solving.
Baseline Performance Enhancements and Grade Compression
Empirical studies published between 2024 and 2026 consistently demonstrate that artificial intelligence-supported systems enhance academic performance. Across mixed-methods and quasi-experimental designs, performance gains ranging from 15% to 35% have been reported in targeted interventions utilizing adaptive learning platforms and intelligent tutoring systems 141516. These systems are highly effective at raising the academic floor, particularly in STEM subjects where structured, step-by-step problem-solving is required 17.
Longitudinal student-course data from higher education institutions reveals that the introduction of generative artificial intelligence significantly raises grades, particularly for historically lower-performing students. However, this phenomenon has resulted in widespread "grade compression" 18. By artificially elevating the outputs of lower-performing students, the technology compresses the overall grade distribution, eroding the signal value of academic grades for future employers 18.
Furthermore, researchers caution that these improvements frequently reflect the quality of the algorithmic output rather than genuine cognitive gains in the student's internal knowledge base 19. This introduces a critical distinction between the acquisition of "AI-specific human capital" (the ability to operate and prompt software efficiently) and the potential loss of "traditional human capital" (foundational knowledge, independent judgment, and analytical endurance) 18.
Cognitive Offloading Versus Scaffolded Learning
The impact of algorithmic personalization on the achievement gap is highly sensitive to the pedagogical parameters of the software. When employed effectively, generative artificial intelligence acts as a socio-constructivist collaborator, operating within the student's Zone of Proximal Development (ZPD) to scaffold learning 152021.
For example, specialized platforms prompted to utilize "Socratic dialogue" (such as LearnLM, Tutor CoPilot, or Khanmigo) refuse to provide direct solutions. Instead, they force students to identify their own errors, breaking down complex issues to manage cognitive load while sustaining active engagement 132223. In a randomized controlled trial, Tutor CoPilot improved student mastery of topics by 4 percentage points, specifically helping less-effective human tutors achieve outcomes comparable to highly effective peers 23.
Conversely, when students use generic, un-scaffolded tools to bypass assignments, they engage in "cognitive offloading" 317. The Brookings Institution defines this as a process where students prioritize speed and completion over mastery, outsourcing critical thinking to the algorithm 3. Because the software can improve grades with minimal effort, it atrophies complex cognitive skills and weakens the willingness to engage in "productive struggle" 3.
The equity implication here is profound: privileged students in well-resourced environments are systemically more likely to be taught to use artificial intelligence productively to augment their capabilities. Disadvantaged or unsupported students, lacking institutional guidance, are at a higher risk of using the technology substantively in ways that replace rather than augment their thinking, structurally diminishing their long-term cognitive development 3.
The Role of Background Knowledge and the Matthew Effect
The effectiveness of generative artificial intelligence is inextricably linked to a student's prior knowledge, generating a "Matthew Effect" in education where those who are already academically advantaged gain the most. Students with robust background knowledge possess the requisite vocabulary to craft precise prompts, critically evaluate outputs for "hallucinations," and iterate on complex concepts 192425.
In formal research environments, such as a study analyzing master's students in a formal methods verification course, students tasked with using large language models made significantly more academic progress when they possessed the foundational knowledge to actively modify and experiment with the AI's output. Students lacking this baseline knowledge were relegated to passively copying responses or engaging in repetitive, ineffective prompting loops 25. Furthermore, studies on reading comprehension indicate that over-reliance on algorithms leads to shallow processing, where learners passively receive information without making knowledge-based inferences 19. Consequently, rather than leveling the playing field, algorithmic personalization risks accelerating the academic progress of high-achieving students while offering limited genuine cognitive benefits to those lacking foundational skills.
Architectural Disparities in Educational Algorithms
To fully contextualize the impact of artificial intelligence on the achievement gap, it is necessary to distinguish between traditional Intelligent Tutoring Systems (ITS) and Generative Artificial Intelligence (GenAI) platforms. The architectural differences between these systems dictate their cost, pedagogical effectiveness, and accessibility.
Table 1: Architectural and Pedagogical Comparison of Artificial Intelligence Systems in Education
| Feature | Traditional Intelligent Tutoring Systems (ITS) | Generative Artificial Intelligence (GenAI) |
|---|---|---|
| Core Architecture | Rule-based algorithms, static question banks, predefined domain knowledge modules tracking specific learner misconceptions 26272829. | Large Language Models (LLMs), neural networks, probabilistic text generation based on massive datasets 262829. |
| Development Cost & Scalability | Extremely high; up to 200 hours of development required for 1 hour of instruction (200:1 ratio). Difficult to scale across diverse subjects 28. | Relatively low content preparation cost; leverages pre-trained models. Highly scalable across infinite subjects and domains 28. |
| Pedagogical Interaction | Structured, step-by-step model tracing. Highly deterministic and controlled. Functions as a rigid, task-oriented tutor 272830. | Open-ended, natural language conversational interfaces. Adapts dynamically to student curiosity and produces original content 272830. |
| Accuracy & Safety | Pedagogically rigorous; virtually zero risk of hallucinated facts. High interpretability and transparency in decision-making 2729. | Susceptible to hallucinations, factual inaccuracies, and inheriting training data biases. Operates as an opaque "black box" 22272931. |
| Equity Impact | High financial barrier to institutional implementation restricts access primarily to wealthy districts and universities 28. | Democratized access to the tool itself, but creates a "skills divide" based on prompt engineering literacy and premium paywalls 26. |
Digital Redlining and Algorithmic Bias in Administration
While generative artificial intelligence handles direct student interaction, traditional machine learning and predictive analytics increasingly govern institutional administration. In this domain, artificial intelligence threatens to digitize and automate historical inequalities through a practice researchers term "digital redlining."
Predictive Analytics and Risk Stratification
Universities and secondary school systems rely on predictive analytics to allocate resources, advise students, and manage enrollment. These algorithms process massive datasets - including demographic information, zip codes, and historical grades - to forecast an individual student's likelihood of dropping out or failing a course 323334.
Because these models are trained on historical data inherently shaped by systemic societal inequities, they routinely inherit and perpetuate past discrimination 3238. The algorithms utilize proxies for socioeconomic status and race, resulting in biased predictions. Investigative analyses of the widely used predictive advising software EAB Navigate revealed severe racial disparities in risk assignment. At the University of Massachusetts Amherst, the algorithm labeled Black women as "high risk" 2.8 times more frequently than White women. Similarly, at the University of Wisconsin-Milwaukee, Black men were labeled high risk at 2.9 times the rate of White men, and at Texas A&M, Black students were labeled high risk at more than double the rate of their White peers 35.
When institutions utilize these automated risk scores to guide academic advising, they risk engaging in opportunity hoarding. Rather than providing support, these algorithmic flags are frequently weaponized to steer marginalized students away from rigorous STEM pathways into "easier" majors, creating a self-fulfilling prophecy of lowered expectations 343536. This automated sorting mechanism acts as an invisible barrier, quietly restricting socioeconomic mobility under the guise of objective, data-driven administration.
Remote Proctoring and Surveillance Disparities
Digital redlining extends into the mechanisms used to assess and surveil students. Remote proctoring software, which utilizes computer vision algorithms to detect alleged cheating, experienced massive growth during the transition to remote learning. However, these systems have been heavily criticized for disproportionately penalizing marginalized groups 41.
Algorithmic surveillance systems frequently struggle to recognize students with darker skin tones or flag innocent, neurodivergent movements as suspicious behavior. This subjects students of color and students with disabilities to heightened surveillance, false accusations, and severe academic anxiety 3441. By integrating biometric surveillance into the foundational grading infrastructure, institutions inadvertently create hostile learning environments for historically underrepresented groups, further expanding the parameters of digital redlining.
Environmental Justice and Infrastructure Placement
The inequities of artificial intelligence are not strictly digital; they manifest in the physical environment, creating a modern spatial adaptation of historical redlining. The massive computational power required to train and operate large language models requires vast data centers that consume immense amounts of water and electricity.
Research indicates a systematic pattern wherein technology companies place these environmentally taxing facilities in historically marginalized, low-income, or predominantly minority communities 37. Case studies of xAI's facility in historically Black South Memphis and Meta's proposed data centers reveal that tech infrastructure targets communities with limited political power 37. Consequently, the communities most marginalized by algorithmic bias in the classroom are the same communities bearing the physical and environmental costs of running the systems. Wealthier institutions and students benefit from the personalized learning outputs, while under-resourced communities suffer the ecological extraction, representing a profound systemic inequity 137.
Institutional Readiness and State-Sponsored Interventions
The burden of mitigating technological risks and ensuring equitable access falls on educational institutions and governments. However, the capacity to develop responsible artificial intelligence policies is heavily stratified by available resources, creating an institutional divide that mirrors the individual achievement gap.
Disparities Between Private and Public Educational Systems
The institutional response to artificial intelligence highlights a severe divergence between private and public educational networks. Recent longitudinal studies demonstrate that private schools are significantly more adept at navigating the technological transition, providing their students with a systemic "artificial advantage" 1138.
Private high schools are more than twice as likely as public schools to permit the use of generative artificial intelligence and to have established formal policies governing its ethical use 11. Furthermore, private school educators report substantially higher rates of technological integration and support. Approximately 45% of private school teachers have received formal artificial intelligence training, compared to only 21% of state school teachers 38.
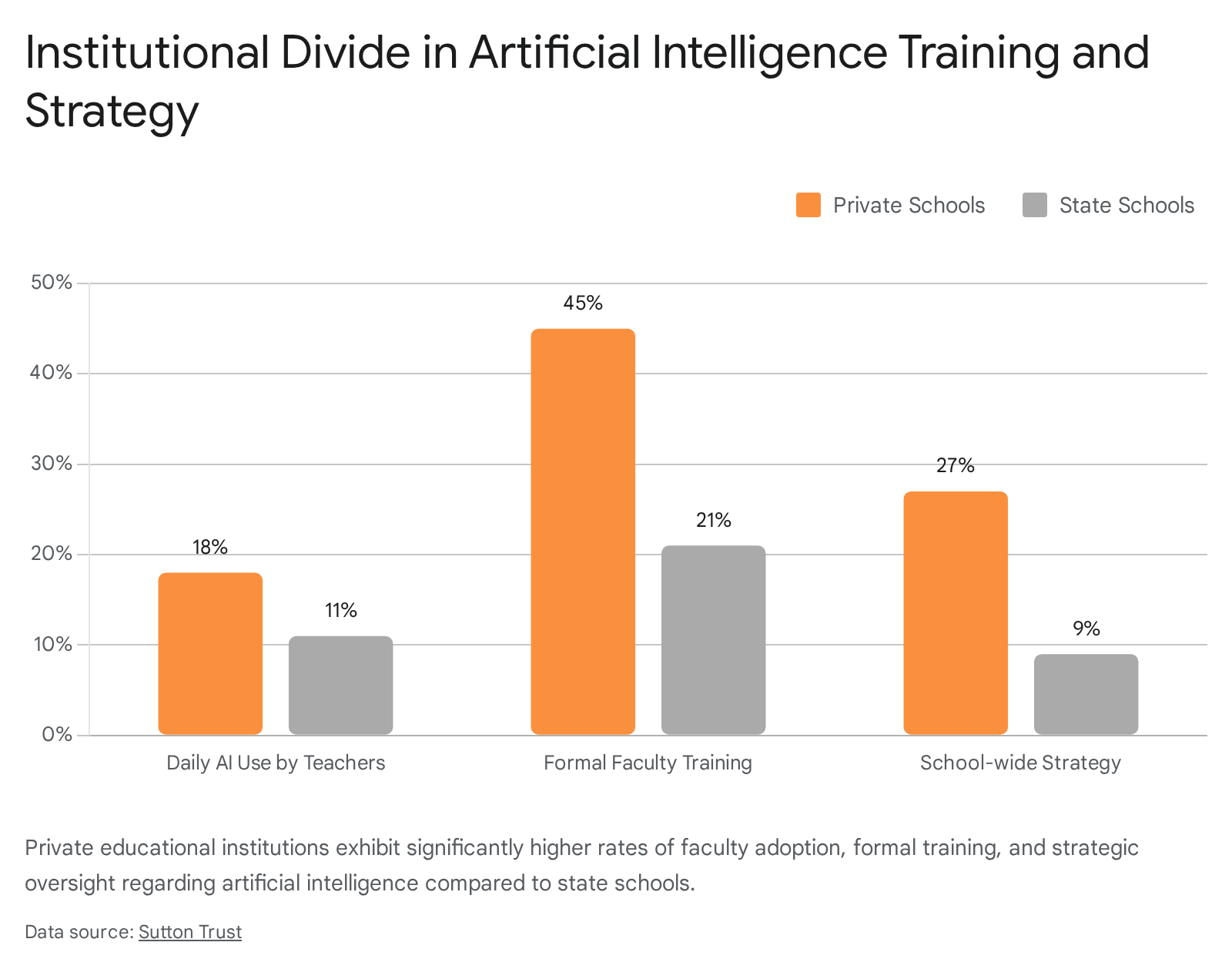
This disparity indicates that students in well-resourced environments are receiving structured guidance on algorithmic literacy. In contrast, students in public systems - particularly those serving higher populations of students eligible for free or reduced-price lunches - are the least likely to have institutional guidelines 11. Wealthier institutions invest in privacy-protective, licensed software integrated securely into their learning management systems, while under-resourced schools are left relying on free, data-hungry tools without proper guardrails 1.
Global Adoption Disparities and the North-South Divide
The inequity of algorithmic access is most pronounced at the macroeconomic level. While artificial intelligence is fundamentally a global technology, its development and deployment remain heavily concentrated in the Global North. By late 2025, data indicated that 24.7% of the working-age population in the Global North utilized generative tools, compared to only 14.1% in the Global South 4.
This disparity is driven by a lack of digital infrastructure, the prohibitive costs of broadband, and the profound linguistic biases inherent in foundational models. The overwhelming majority of machine learning models are trained predominantly on English-language data and Western cultural paradigms. Consequently, students in developing nations frequently interact with platforms that lack cultural nuance, fail to process native dialects effectively, or perpetuate Western-centric worldviews 11444. Without concerted intervention, current macroeconomic projections suggest that only 3% of the anticipated economic benefits of artificial intelligence will accrue to Latin America, and a mere 8% to Africa and other developing Asian markets 39.
State-Sponsored Interventions in Emerging Markets
Recognizing the threat of a widening international achievement gap, several governments in the Global South have initiated aggressive, state-sponsored educational programs designed to democratize access and circumvent the limitations of commercial paywalls. Interestingly, these targeted interventions have propelled specific emerging markets to the forefront of student adoption. Brazil leads global adoption with 11.6% of students using artificial intelligence for schoolwork, closely followed by India at 11.5%, significantly outpacing advanced economies like the United Kingdom (4.6%) and Japan (5.6%) 40.
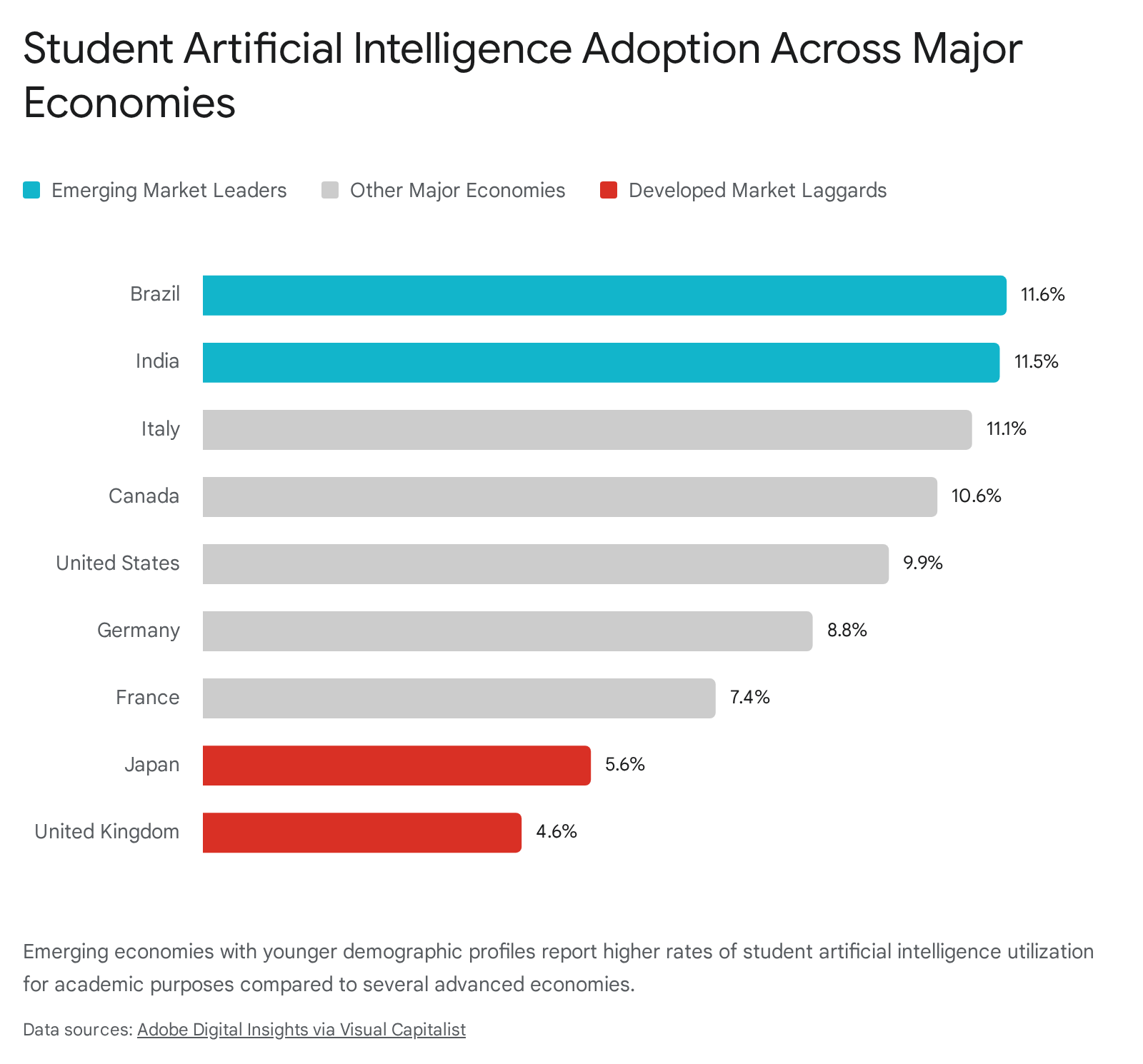
Table 2: State-Sponsored Educational Artificial Intelligence Initiatives
| Nation | Strategic Initiative & Implementation Scope | Equity and Access Outcomes |
|---|---|---|
| India | "AI for All" initiative integrated into the National Education Policy (NEP) 2020. The Central Board of Secondary Education (CBSE) mandated AI coursework for high school students and developed educator handbooks 4142. | Democratizes access for a massive youth demographic. Focuses on regional language support and digital readiness to circumvent commercial barriers 404243. |
| Brazil | National Framework for Responsible AI in Education (2026). Regional programs like Piauí Inteligência Artificial make AI a compulsory subject for 90,000 public school students annually 4445. | Emphasizes national sovereignty in infrastructure. Replaces reliance on foreign commercial models by funding local EdTech and deploying writing platforms to 60,000 students in Espírito Santo 44. |
| Mauritius | The Mauritius Artificial Intelligence Strategy focuses on capacity building, integrating AI into educational administration, and establishing an AI Council to oversee deployment . | Aims to scale the workforce to transition the economy toward high-tech sectors, prioritizing government-subsidized skills training . |
These state-driven interventions demonstrate that when governments actively construct digital infrastructure and provide open-access or subsidized algorithmic tools, they can effectively bypass the commercial paywalls and linguistic biases that otherwise stratify student populations.
Synthesis of Equity Implications and Future Trajectories
The integration of artificial intelligence in education presents a profound paradox for equity and access. Algorithmic personalization undeniably holds the capacity to deliver high-dose, scalable tutoring to marginalized students. When deployed with rigorous pedagogical scaffolding, these tools raise baseline academic performance, accommodate self-paced learning, and provide immediate, individualized feedback that traditional classroom environments cannot sustainably replicate 131418.
However, without robust structural interventions, the default trajectory of educational artificial intelligence heavily favors existing privilege. The persistence of commercial paywalls guarantees that affluent students receive superior cognitive assistance, while financially constrained students are relegated to basic, less reliable models 57. Furthermore, institutional discrepancies ensure that privileged students receive the necessary guidance to use these tools as socio-constructivist collaborators for deep learning. Unsupported students, lacking foundational background knowledge and parental digital literacy, are left to use algorithms as a cognitive crutch that diminishes long-term critical thinking and fosters cognitive offloading 31938. Concurrently, hidden administrative algorithms continue to execute digital redlining, utilizing biased historical data to surveil and restrict the academic mobility of minority populations 3436.
To ensure algorithmic personalization narrows rather than widens the achievement gap, stakeholders must shift focus from mere technological access to the cultivation of algorithmic literacy and institutional accountability. This necessitates the deployment of state-subsidized, pedagogically sound models, mandatory and equitable teacher training programs, and rigorous ethical audits of all predictive analytics systems used in educational administration. Only through intentional, human-centered governance can the educational sector harness the capabilities of artificial intelligence without sacrificing systemic equity.