Why Are Transformers Used for Time-Series Forecasting
A transformer is an advanced deep learning architecture that utilizes a "self-attention" mechanism to weigh the importance of different data points across a sequence, originally serving as the engine behind the modern natural language processing revolution. Today, researchers are aggressively adapting transformers for time-series forecasting because their capacity to capture complex, long-range dependencies across massive datasets has enabled the creation of "zero-shot" foundation models. These universal models can accurately predict future trends in finance, retail, and energy markets without requiring task-specific training, fundamentally altering the economics of predictive analytics.
The Evolution of the Forecasting Stack
Time-series forecasting - the practice of predicting future numerical values based on historical data points recorded at equally spaced intervals - has historically relied on distinct, bespoke models 1. For decades, analysts built customized models for individual datasets.
The initial era of forecasting was dominated by classical statistical approaches like AutoRegressive Integrated Moving Average (ARIMA) and Exponential Smoothing (ETS). These models effectively capture linear dependencies and short-term trends within stationary data 234. However, they struggle to model non-linear patterns, are highly sensitive to noise, and lack the capacity to process multivariate inputs natively 35.
As data volumes exploded, the industry transitioned to machine learning frameworks, specifically gradient boosting models like XGBoost and LightGBM 2. These models treat forecasting as a tabular regression problem, requiring extensive manual feature engineering (e.g., adding lag variables and rolling means) to simulate a sense of time 56. While tree-based models excel at capturing complex, non-linear relationships and offer rapid training times, they do not intuitively understand temporal order 6.
To address the need for true sequential understanding, deep learning introduced Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks 41. LSTMs are explicitly designed to process sequential data, holding short-term memory across time steps 18. Yet, LSTMs process data chronologically. When dealing with exceptionally long sequences, they suffer from a "forgetting" problem, diluting the context of early data points by the time they reach the end of the sequence 9. Furthermore, their sequential nature creates computational bottlenecks that limit scalability.
| Forecasting Paradigm | Representative Models | Core Mechanism | Primary Strengths | Notable Limitations |
|---|---|---|---|---|
| Statistical | ARIMA, SARIMA, ETS | Models linear dependencies between past observations. | Fast, highly interpretable, requires minimal data, excellent for stationary datasets. 35 | Fails on non-linear trends; highly sensitive to outliers; univariate focus. 35 |
| Tree-Based ML | XGBoost, LightGBM, Random Forest | Uses ensembles of decision trees to model complex relationships. | Handles non-linearity and missing data well; fast inference. 261 | Lacks native temporal understanding; requires heavy manual feature engineering (lags). 62 |
| Recurrent DL | DeepAR, LSTM, GRU | Processes sequences chronologically with internal memory gates. | Captures sequential logic and multi-horizon dynamics. 18 | Struggles with extremely long-range dependencies; difficult to parallelize. 49 |
| Transformer DL | PatchTST, iTransformer, TFT | Uses self-attention to track global dependencies simultaneously. | Unmatched long-horizon accuracy; captures intricate multivariate interactions. 1312 | High computational cost; prone to overfitting on small, noisy datasets. 3134 |
The transformer architecture, introduced in 2017, abandoned chronological processing entirely. By utilizing a mechanism known as "self-attention," transformers evaluate an entire sequence simultaneously 35. The model directly calculates the mathematical relationship between any two points in the data, regardless of how far apart they are in time 316. This allows a transformer to instantly recognize that a spike in energy demand today correlates with a specific temperature pattern from weeks prior, capturing both local fluctuations and global dependencies simultaneously 16.
The Mathematical Mismatch: Time Is Not Language
When researchers first attempted to apply vanilla natural language processing (NLP) transformers directly to time-series data, they encountered severe computational and architectural hurdles. The features that make transformers exceptional at parsing human language often turn into liabilities when processing numerical signals.
In language, a sentence possesses inherent, semantic flow. Discrete tokens (words) retain specific meanings regardless of their precise position 1317. The word "cat" means "cat" whether it is the first or fifth word in a sequence 17. However, time-series data operates on a temporal flow. An individual data point - such as an hourly server load metric of 84% - carries no inherent semantic meaning in isolation 176. Its meaning is defined entirely by its continuous relationship to the numerical values preceding and following it.
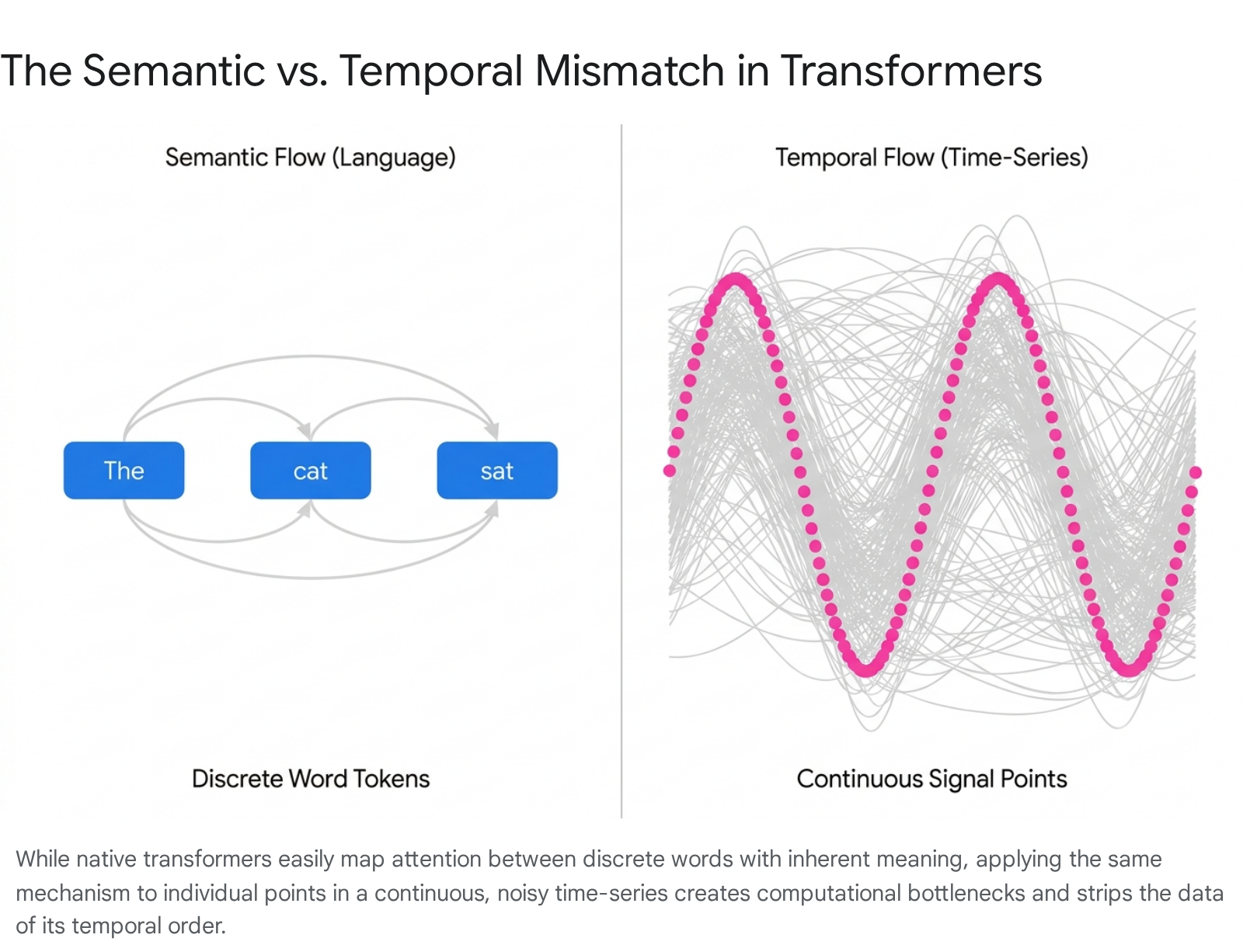
This distinction exposes the "permutation invariance" curse of standard transformers. Because self-attention evaluates all inputs simultaneously, it is naturally order-agnostic 13417. To counter this, NLP models use positional encodings to indicate word order. In time-series analysis, however, time is a continuous dimension featuring irregular intervals, seasonal patterns, and multiple concurrent scales 17. Merely tagging a data point with a position number fails to convey the complex temporal dynamics 417.
Furthermore, vanilla transformers suffer from quadratic computational complexity. Analyzing a sequence of 100 words requires 10,000 attention computations, which is easily manageable. But high-frequency financial or telemetry data can contain millions of points. Processing a single year of minute-level data (525,600 points) would require roughly 276 billion attention operations, leading to an immediate memory explosion and prohibitive computational costs 317.
The DLinear Reality Check
The tension between complex transformers and the continuous nature of time-series data culminated in a highly influential 2023 paper published at AAAI, titled "Are Transformers Effective for Time Series Forecasting?" 47. The researchers tested heavily engineered time-series transformers against a set of embarrassingly simple linear models, most notably DLinear 420.
DLinear fundamentally bypassed the self-attention mechanism entirely. It simply decomposed the raw time-series data into a trend component and a seasonal remainder using a moving average kernel, applied a single-layer linear network to each, and summed them for the final prediction 4420.
The results were a shock to the deep learning community. DLinear outperformed sophisticated transformer architectures (such as Autoformer and Informer) across nine widely used real-world benchmark datasets, frequently by margins of 20% to 50% 4. The study revealed that vanilla transformers were actually losing temporal information. Their complex self-attention mechanisms were overfitting to noise and failing to preserve the sequential order of the continuous points 420. When the researchers expanded the look-back window (giving the models more historical data to learn from), the performance of the transformers often degraded or remained stagnant, whereas the linear models improved 4.
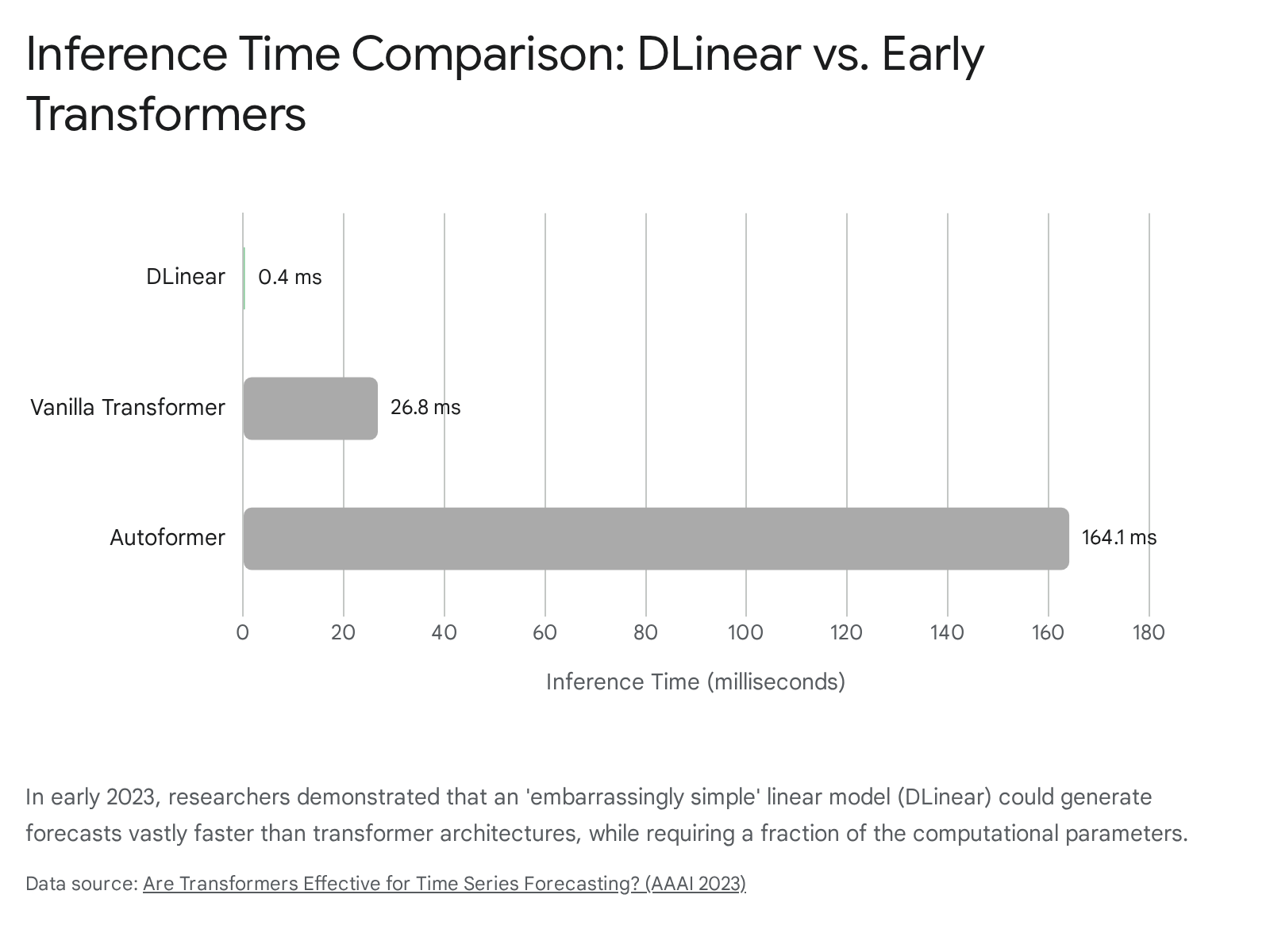
Efficiency testing on electricity datasets confirmed that DLinear required only 139.7K parameters and 0.4 milliseconds of inference time, while comparable transformers required up to 241 million parameters and 164.1 milliseconds to execute poorer forecasts 4. The DLinear paper forced researchers to acknowledge that simply porting language architectures to time series was mathematically flawed.
The Architectural Rebound: Re-engineering for Time
Rather than abandoning the transformer, engineers recognized that to harness the power of self-attention, they had to alter how the data was ingested. Subsequent research integrated classical signal processing theory with deep learning, leading to highly specialized time-series architectures.
Patching the Input (PatchTST)
The most successful structural fix was tokenization via "patching." Instead of feeding individual time steps (e.g., single minutes or hours) into the transformer as separate tokens, models like PatchTST segment the continuous time series along the time axis into subseries "patches" 689.
By aggregating steps, a patch acquires semantic richness. A single data point holds no structural meaning, but a patch of 24 hourly data points contains an observable daily cycle 6. The attention mechanism can then calculate the relationships between these meaningful patches rather than chaotic individual data points 6. Crucially, this reduces the sequence length the transformer must process, directly solving the quadratic memory complexity issue and allowing the model to look back at much longer historical contexts without crashing 369.
Inverting the Attention Matrix (iTransformer)
While patching solved sequence length issues, multivariate forecasting - predicting dozens of co-evolving variables simultaneously - presented another challenge. Standard transformers embedded all variables for a single timestamp into one token, blurring distinct physical measurements together and resulting in meaningless attention maps across time 1223.
The iTransformer (Inverted Transformer) revolutionized this by completely flipping the tokenization paradigm. Presented at ICLR 2024, the iTransformer treats the entire historical sequence of a single variable as an independent token 2310. Rather than calculating attention across time steps, the attention mechanism calculates the complex correlations between different variables (e.g., how the trajectory of wind speed influences the trajectory of air pressure) 423. Meanwhile, the model uses a feed-forward network to learn the temporal, non-linear representations within each individual variable 2325. This variate-centric approach has achieved state-of-the-art results on challenging real-world multivariate benchmarks, proving that the transformer architecture is highly effective when its components are correctly aligned with the nature of the data 125.
Signal Decomposition and Sparse Attention
Other specialized architectures leveraged concepts from traditional signal theory. The Autoformer model intrinsically decomposes input signals into underlying trend and periodic (seasonal) components prior to processing, smoothing out noisy signals so the attention mechanism can extrapolate stable future states 197.
To further reduce computational overhead on extremely long sequences, models like the Informer introduced "ProbSparse Self-Attention." This mathematical optimization selectively computes attention only for the most dominant and relevant time steps, bypassing redundant pairwise calculations and reducing time and memory complexity to a manageable logarithmic scale 31611.
The Time-Series Foundation Model (TSFM) Revolution
The stabilization of the transformer architecture paved the way for the current frontier in predictive analytics: Time-Series Foundation Models (TSFMs).
In natural language processing, organizations no longer train proprietary language models from scratch; they leverage pre-trained foundation models capable of "zero-shot" inference on unseen tasks. Throughout 2024 and 2025, tech giants adapted this massive-scale pre-training methodology to numerical data 69. By exposing giant transformer architectures to tens of billions of diverse, open-source time-series observations, researchers created universal forecasters 2728.
| Foundation Model | Developer | Architecture & Approach | Key Characteristics |
|---|---|---|---|
| Chronos-2 | Amazon | T5-inspired encoder-only. Tokenizes numerical values into a discrete text-like vocabulary. 2812 | 120M parameters. Supports zero-shot multivariate forecasting and natively integrates known future covariates. 1230 |
| TimesFM | Decoder-only. Uses 32-point input patches and 128-point output patches to predict next values. 3132 | 200M parameters. Pre-trained on 100 billion real-world time points (Google Trends, Wiki views). Highly effective when fine-tuned on financial data. 3132 | |
| MOIRAI | Salesforce | Encoder-only. Universal transformer with multi-patch layers and Any-variate Attention. 2713 | Up to 311M parameters. Learns a mixture of parametric distributions (e.g., Log-Normal, Student's t) to adapt to diverse real-world data shapes. 627 |
| Tiny Time Mixers (TTM) | IBM | MLP-Mixer architecture (non-transformer). Extremely lightweight alternative. 2834 | Under 1 million parameters. Focuses on speed and low compute footprint while maintaining competitive accuracy via fine-tuning. 28 |
Learning the Language of Numbers
Amazon's Chronos frames forecasting entirely as a language modeling challenge. Rather than processing continuous variables, it tokenizes numerical time-series values into a discrete vocabulary 2835. Utilizing a sequence model inspired by the T5 LLM architecture, Chronos autoregressively predicts future tokens 28. Its successor, Chronos-2, expanded capabilities to support complex multivariate forecasting and covariate-informed tasks via in-context learning 1230.
Conversely, Google's TimesFM retains the continuous nature of the data using input patches. Trained on 100 billion real-world time points, this 200-million-parameter decoder-only model predicts future trajectories efficiently without attempting to translate numbers into a text-like vocabulary 313214.
Universal Distributions with MOIRAI
Salesforce AI Research tackled the heterogeneity of global data with MOIRAI (Masked Encoder-based Universal Time Series Forecasting Transformer) 2713. Recognizing that time-series granularities differ drastically, MOIRAI uses multi-patch layers to learn distinct patch sizes for various frequencies (e.g., large patches for second-level data, small patches for yearly data) 27.
Critically, MOIRAI acknowledges that financial, environmental, and retail data do not follow a single mathematical distribution. Instead of forcing a specific hypothesis, the model optimizes for a mixture of parametric distributions. It dynamically applies heavy-tailed distributions (Student's t) for general robust forecasting, strictly positive distributions (Negative Binomial) for count data like inventory, and right-skewed distributions (Log-Normal) for economic indicators 627.
Benchmarking the Models: Where Do Transformers Win?
The proliferation of both specialized deep learning models (like PatchTST and iTransformer) and universal foundation models (like Chronos and MOIRAI) necessitates rigorous benchmarking. Comprehensive evaluation frameworks such as GIFT-Eval and TempusBench have clarified the strengths and limitations of the current ecosystem 371539.
The data dictates the model selection. For short-term forecasting on extremely high-frequency, noisy data (such as second-level web traffic or immediate CloudOps telemetry), foundation models frequently struggle. In these high-entropy environments, classical statistical algorithms or specifically fine-tuned deep learning models remain superior 3740.
However, as prediction lengths extend to medium and long-term horizons across lower frequencies (hourly, daily, or weekly data), foundation models dominate. The zero-shot capabilities of models like Chronos and MOIRAI consistently outperform traditional methods by leveraging their extensive pre-training to capture broader macroeconomic patterns and slower dynamics 3715.
Furthermore, while foundation models excel in univariate scenarios, deep learning architectures explicitly designed for multivariate interactions - particularly the iTransformer - currently maintain a performance edge when analyzing highly correlated, co-evolving datasets 837. Recent studies indicate that while inter-variate dependencies (the relationship between different variables) are crucial, the primary driver of prediction performance often remains the intra-variate dependencies (the historical patterns within a single variable over time) 816. Normalization techniques, such as Reversible Instance Normalization (RevIN), are universally critical across all transformer variants to handle non-stationary series and prevent models from flatlining predictions to a simple mean 925.
The Economic Impact of Accurate Forecasting
The transition toward transformer-based forecasting is driven by immense economic stakes. Forecast accuracy directly dictates the alignment of supply with actual demand; errors inevitably result in severe financial penalties 42.
In supply chain and retail operations, inaccurate forecasts result in either overstocks (wasting working capital) or stockouts (sacrificing sales and damaging customer loyalty). A 2023 analysis estimated that global inventory distortion cost retailers $1.77 trillion worldwide 42. Transformers excel at mitigating this by parsing vast arrays of covariates. For example, extreme weather events like tropical cyclones cause cascading disruptions. A transformer model can track weather variables, predict the resulting shortfall in cacao crops, and accurately forecast the subsequent spot-market price spikes for food and pharmaceutical manufacturers, allowing proactive inventory positioning 43.
Similarly, in the energy sector, grid planners must forecast system peak demand years in advance to justify multibillion-dollar investments in power plants 17. Because the operational risks of under-forecasting (rolling blackouts) are catastrophic, planners historically err heavily on the side of over-forecasting 17. Data indicates that utilities have routinely over-forecasted electricity demand by roughly one percentage point per year, resulting in a 10% discrepancy a decade later 17. This overbuild forces consumers to pay billions of dollars annually for generating capacity that is never utilized 1718. Modern time-series transformers, capable of integrating weather covariates and fluctuating renewable energy production rates, provide the tightened accuracy required to safely optimize grid infrastructure 1819.
Bottom line
Transformers are revolutionizing time-series forecasting because their self-attention mechanisms - when properly engineered via data patching and inverted tokenization - excel at identifying complex, long-range numerical patterns that classical statistical models miss. This architectural evolution has enabled the release of powerful "zero-shot" foundation models capable of predicting outcomes in finance, retail, and energy without requiring expensive custom training. While highly volatile, high-frequency datasets may still require bespoke machine learning, the future of enterprise predictive analytics will be dominated by large-scale, pre-trained transformer architectures.