What Are Time-Series Foundation Models
Time-series foundation models are massive, pre-trained neural networks designed to generate highly accurate, zero-shot forecasts on sequential numerical data without requiring task-specific training or structural modification. Operating with full enterprise maturity as of 2026, these architectures leverage the same self-attention mechanisms that revolutionized natural language processing, adapting them to continuous quantitative data streams.
Imagine these systems as a "ChatGPT for numbers." Instead of ingesting millions of books to predict the next word in a paragraph, a time-series foundation model ingests billions of historical data points - ranging from server loads and retail inventory to meteorological patterns - to predict the next sequence of values. By learning universal structural priors across thousands of diverse domains, these models allow organizations to bypass the historically arduous process of building bespoke forecasting algorithms for every individual dataset.
What exactly are time-series foundation models?
To fully grasp the paradigm shift initiated by time-series foundation models (TSFMs), one must examine the evolutionary trajectory of predictive analytics. For decades, the forecasting discipline was anchored by classical statistical methods, most notably the AutoRegressive Integrated Moving Average (ARIMA) and Exponential Smoothing (ETS) 123. These models are fundamentally univariate, meaning they forecast a single variable based entirely on its own past values. Operating under strict assumptions of linearity and stationarity, classical models demand significant manual intervention: data must be cleaned, outliers removed, and non-stationary trends differenced into stability before the algorithm can accurately identify moving average effects 124. While mathematically rigorous and entirely interpretable, classical methods fail to scale efficiently across enterprise catalogs containing millions of unique series, and they struggle immensely with non-linear dynamics 25.
The transition into the deep learning era sought to rectify these limitations. Architectures such as Long Short-Term Memory (LSTM) networks, N-BEATS, and the Temporal Fusion Transformer (TFT) introduced the capacity to model highly complex, multi-dimensional variable interactions across varying time horizons 678. These neural networks could ingest multiple covariates - such as holiday schedules, promotional pricing, and meteorological data - to inform a target forecast. However, they remained severely bottlenecked by the "one-model-per-dataset" paradigm. Training a deep learning forecaster required vast amounts of historical target data, prolonged computational cycles, and meticulous hyperparameter tuning 7811. If an enterprise sought to forecast demand for a newly launched product lacking a long historical baseline, these highly specialized models would suffer from the "cold-start" problem, unable to generate reliable outputs 89.
Time-series foundation models represent the third and most significant epoch in sequential data analysis. Borrowing the core conceptual framework from natural language processing (NLP) and computer vision, TSFMs are trained once on colossal, domain-agnostic datasets and subsequently deployed across completely unseen forecasting tasks - a capability defined as "zero-shot inference" 131415. A foundation model pre-trained on high-frequency server traffic, daily cardiovascular monitoring data, and monthly economic indicators develops a generalized, universal understanding of temporal dynamics, seasonality, and trend structures 101112.
When presented with a novel dataset that it has never encountered - such as urban bike-sharing demand in New York City or influenza trajectories in Italy - the model immediately generates highly accurate, probabilistic predictions without undergoing any localized gradient updates or retraining 1419. This unified generative approach democratizes advanced forecasting, shifting the discipline away from isolated algorithmic development toward scalable, deployable application programming interfaces (APIs) and open-weight checkpoints 131415. The commercial realization of these models effectively reduces complex forecasting pipelines to a single inference step, cutting operational costs and accelerating decision-making at an enterprise scale 2316.
How do these models differ from large language models?
A pervasive misconception within the broader technology sector is that time-series foundation models are merely standard Large Language Models (LLMs) - like GPT-4 or Llama 3 - fed with numerical digits. While TSFMs share the underlying Transformer architecture, the structural adaptation required to process numerical sequences involves entirely different tokenization schemes, objective functions, and architectural paradigms. Feeding raw numbers directly into a standard LLM highlights a severe modality gap that degrades predictive accuracy and computational efficiency 1726.
Standard LLMs utilize text-based subword tokenizers, such as Byte-Pair Encoding (BPE), which parse sequences based on linguistic frequency. When confronted with continuous numerical data, text tokenizers fail catastrophically. A standard LLM might parse the number 14562 as the discrete tokens [14], [56], and [2], while parsing 14563 as [145], [63]. This arbitrary linguistic shredding destroys the mathematical magnitude, scale, and chronological relationship of the sequential data 1718. Furthermore, human language is naturally discrete and constrained by a fixed, universally understood vocabulary. Time-series data, conversely, is continuous, highly volatile, mathematically unbounded, and characterized by wildly varying sampling frequencies - ranging from millisecond-level telemetric sensor logs to decadal macroeconomic indicators 112829.
To bridge this modality gap and prevent the phenomenon of posterior collapse, TSFM researchers developed distinct mechanisms to translate continuous numerical sequences into representations that Transformer self-attention mechanisms can process effectively.
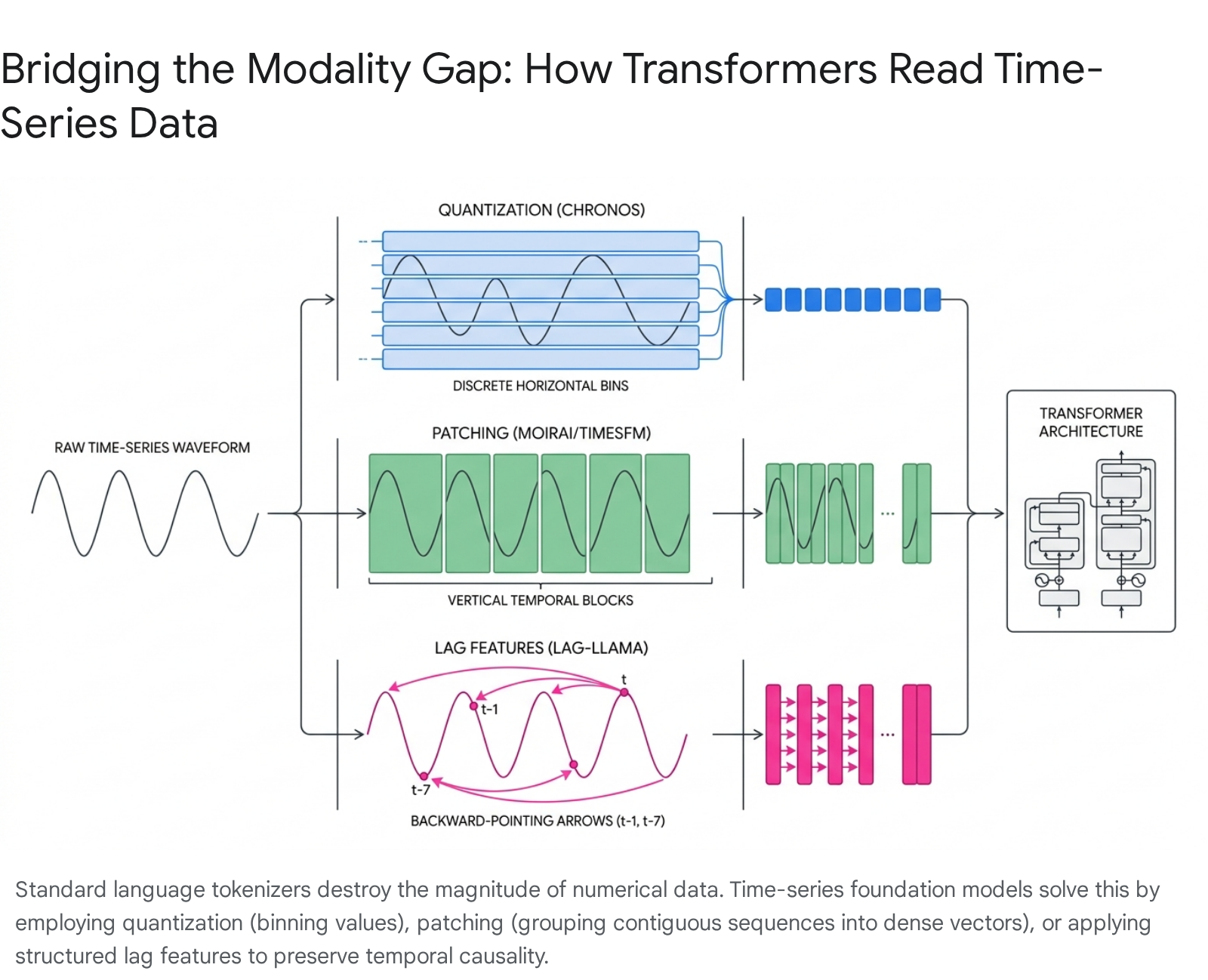
The first approach is Quantization and Scaling, championed by models such as Amazon's Chronos. This methodology forces continuous numerical data into a discrete format, effectively treating time-series data as an actual foreign language. The raw time-series data is first scaled by its absolute mean to normalize the range. These scaled values are then quantized - binned into a fixed vocabulary of uniformly spaced discrete intervals. For example, the Chronos architecture utilizes a restricted vocabulary of 4,096 distinct tokens, supplemented by special tokens for padding (PAD) and end-of-sequence (EOS). By transforming the continuous series into a sequence of bin identifiers, the model casts the regression problem as a classification problem. It trains a standard language model architecture via cross-entropy loss to predict the probability distribution of the next categorical bin, leveraging the exact same mechanical objective used to predict the next word in a paragraph 301920.
The second approach is Patching and Projection, utilized by architectures like Salesforce's Moirai and Google's TimesFM. Rather than quantizing individual data points, patching treats contiguous blocks of a time series as single, fundamental units. A patching model segments a sequence into non-overlapping temporal windows (e.g., grouping 32 individual time steps into a single patch). Each patch is passed through a Multi-Layer Perceptron (MLP) residual block to project it into a high-dimensional dense vector space. This allows the Transformer to capture local semantic meaning and temporal micro-structures within the patch before calculating global attention across the broader, macro-level timeline 123321. Advanced models employ multi-patch size input projection layers to handle diverse frequencies dynamically. A high-frequency dataset requires a large patch size to capture meaning, whereas a low-frequency dataset requires a smaller patch size; the model shares these projection layers across disparate series to maintain universal applicability 2135.
The third paradigm relies on Lagged Covariates, notably deployed by Lag-Llama. This approach entirely rejects arbitrary token limits and discretization, instead engineering explicit statistical lag features natively into the input tensor. A model using this methodology constructs input vectors utilizing specific historical offsets (e.g., $t-1$ for daily auto-regression, $t-7$ for weekly seasonality, $t-30$ for monthly cycles). These lagged values are combined with static temporal indicators (hour-of-day, day-of-week) and processed directly. This explicit mathematical engineering ensures the model embeds cyclical and periodic behaviors directly into its representation space without relying solely on the self-attention mechanism to deduce long-range temporal distances from scratch 103637.
A more experimental fourth approach involves Vector Quantization via Wavelets, as seen in architectures like WaveToken. This methodology decomposes the time series into frequency components using wavelet transforms, isolating high-magnitude coefficients and thresholding out noise. The resulting wavelet components are converted into a highly compact set of tokens, allowing the foundation model to forecast future states using a drastically reduced vocabulary, which improves both generalization to non-stationary data and memory efficiency 38.
Beyond input tokenization, time-series foundation models deviate significantly from general LLMs in their overall architectural paradigms. The landscape is segmented into three distinct structural strategies based on the primary objective of the model 1139.
Encoder-only models, such as MOMENT, operate similarly to BERT. They ingest entire sequences simultaneously, generating dense representations that excel at tasks requiring holistic sequence analysis, such as anomaly detection, time-series classification, and representation learning 83940. Decoder-only models, including TimesFM and Lag-Llama, function autoregressively. Mirroring the mechanics of GPT, they predict future states step-by-step conditioned solely on past context, making them the superior architecture for long-horizon probabilistic forecasting 1012. Finally, encoder-decoder architectures, utilized by TimeGPT and earlier iterations of Chronos, encode a rich, variable-length historical context window into a latent state before a separate decoder network projects the forecasted sequence into the future. This hybrid approach strikes a balance between deep historical contextualization and robust future generation 1339.
Who are the major players and how do they compare?
The commercial and open-source landscape for time-series foundation models consolidated rapidly between 2024 and 2026, primarily driven by major technology laboratories and corporate AI research divisions. While their ultimate goals are identical - creating universal, zero-shot forecasters - their methodologies, dataset curation, and deployment models differ drastically.
| Model | Creator / Lab | Availability | Architecture Paradigm | Tokenization / Input Strategy | Training Data Scale |
|---|---|---|---|---|---|
| TimeGPT | Nixtla | Closed API (Commercial) | Encoder-Decoder Transformer | Continuous / Multi-variate | ~100 Billion data points |
| Chronos (-2) | Amazon Science | Open Weights (Apache 2.0) | T5-based / Encoder-only | Value Scaling & Quantization | Large Public + Synthetic (KernelSynth) |
| Moirai (-MoE) | Salesforce AI Research | Open Weights | Masked Encoder / Sparse MoE | Any-Variate Attention / Patching | 27 Billion observations (LOTSA) |
| Lag-Llama | ServiceNow / Academics | Open Weights | LLaMA-based Decoder-only | Lagged Covariate Features | 7,965 series (352 Million tokens) |
TimeGPT (Nixtla)
Introduced in late 2023, TimeGPT was the industry's first generative pre-trained transformer explicitly engineered for production-ready time-series forecasting. Developed by Nixtla, the model operates exclusively behind a commercial API, positioning it as an enterprise-grade, "infrastructure-free" solution for organizations lacking extensive machine learning operations (MLOps) overhead. TimeGPT is trained on an undisclosed, proprietary collection of approximately 100 billion data points spanning highly diverse domains, including web traffic, cybersecurity network logs, IoT telemetry, finance, and electricity demand 134142.
TimeGPT's underlying architecture maps sequential inputs and optional exogenous covariates through local positional encodings into a full encoder-decoder structure. This network includes residual connections, layer normalization, and a linear output layer that matches the decoder's high-dimensional latent states directly to numerical forecast dimensions 1323. It inherently supports multi-series forecasting and processes data with irregular timestamps seamlessly, requiring no manual gap-filling or interpolation prior to inference.
The subsequent release of the TimeGPT 2 family, culminating in TimeGPT 2.1, dramatically expanded the model's enterprise capabilities. This iteration introduced strict SOC 2 compliance, native multi-GPU scalability for processing millions of concurrent series, and improved zero-shot historical anomaly detection. A key feature of the TimeGPT platform is its utilization of conformal prediction algorithms, allowing the model to generate robust, statistically rigorous prediction intervals based on historically observed error margins, thereby capturing forecast uncertainty 13144122. Furthermore, Nixtla expanded distribution by optimizing variants like TimeGEN-1 specifically for Azure infrastructure, embedding the API deeply within existing corporate cloud ecosystems 2324. Unlike its open-source counterparts, however, TimeGPT operates as a black box; the creators prevent users from inspecting or modifying internal model weights, standardizing all interactions purely through web requests 2547.
Chronos and Chronos-2 (Amazon)
Amazon Web Services (AWS) approached the foundational forecasting problem by rigorously testing the hypothesis that unmodified natural language architectures could effectively model time-series data. The original Chronos framework scaled and quantized continuous numerical values into 4,096 discrete bins, feeding the resulting vocabulary into standard T5 encoder-decoder architectures. These models ranged in size from 20 million to 710 million parameters 73019. Chronos models were trained heavily on a vast aggregate of publicly available datasets, but the true differentiator was Amazon's implementation of "KernelSynth." This proprietary data generation engine utilized Gaussian processes to synthetically produce billions of realistic time-series trajectories, effectively teaching the model complex, generalized mathematical patterns that did not exist in sufficient quantities in public repositories 1920.
By late 2025, Amazon released Chronos-2, shifting the paradigm to an encoder-only architecture (120 million parameters) capable of supporting univariate, multivariate, and covariate-informed tasks simultaneously. Previous foundation models struggled with multivariate forecasting, often treating interdependent variables as isolated streams. Chronos-2 introduced a novel "group attention" mechanism and cuboid processing that allows the model to capture deep interactions across different, co-evolving time series - such as predicting CPU, memory, and storage I/O concurrently based on their interconnected loads 94849.
Delivering over 300 time-series forecasts per second on a single A10G GPU, Chronos-2 boasts a highly efficient memory footprint. Benchmarking on the General Information on Forecasting Tasks Evaluation (GIFT-Eval) and the FEV-bench demonstrated a 90% win rate over its predecessor, establishing Chronos-2 as the dominant open-source option for covariate-heavy, multidimensional forecasting tasks 92548.
Moirai and Moirai-MoE (Salesforce)
Salesforce AI Research tackled the extreme heterogeneity of real-world time-series data - specifically varying magnitudes, non-stationary distributions, and arbitrary dimensionalities - by developing Moirai. Recognizing that data scarcity was the primary bottleneck in training time-series foundation models, Salesforce researchers assembled the Large-scale Open Time Series Archive (LOTSA). Containing 27 billion observations spanning nine distinct domains (including energy, transit, and retail), LOTSA became the largest open-source pre-training corpus in the field 82150.
Moirai operates as a universal forecaster via its proprietary "Any-variate Attention" mechanism. Rather than enforcing strict channel independence - a common simplification in deep learning where variables are modeled blindly alongside one another - Moirai flattens multivariate time series into a single, contiguous long sequence. The model utilizes Rotary Position Embeddings (RoPE) and learned binary attention biases to encode both the time and variate axes, empowering a single model architecture to handle forecasts across any arbitrary number of variables concurrently 821. Furthermore, Moirai is uniquely probabilistic at its core, learning the parameters of a mixture of distributions (such as Student's t, Negative Binomial, and Log-Normal) to accommodate data with heavy outliers or strictly positive constraints like retail demand 850.
The architectural evolution to Moirai-MoE addressed the inherent non-stationarity of time-series data. Because market regimes shift and physical systems degrade, fixed projection layers often fail to adapt. Moirai-MoE introduced a Sparse Mixture of Experts (MoE) design. Instead of relying on human-imposed frequency heuristics, Moirai-MoE utilizes a gating network to dynamically route discrete patches of data to specialized "expert" sub-networks at the token level. This data-driven, automatic specialization allowed Moirai-MoE to outperform dense baseline models by up to 17% on benchmarks, while activating up to 65 times fewer parameters during inference, making it highly computationally efficient for complex modeling 354751.
Lag-Llama (ServiceNow)
While Amazon and Salesforce attempt to project or discretize values into latent vectors, Lag-Llama leverages foundational classical statistical logic integrated directly into a generative deep learning framework. Based heavily on the architecture of Meta's LLaMA, this open-source, decoder-only foundation model explicitly engineers the input space using lagged temporal variables rather than simple raw historical points 103336. By maintaining explicit temporal causality without relying entirely on self-attention to deduce chronological distances, Lag-Llama specializes natively in probabilistic forecasting, outputting mathematically rigorous probability distributions rather than mere point forecasts 131037.
Lag-Llama was pre-trained on a meticulously curated, stratified corpus of 7,965 univariate time series, yielding an aggregate of 352 million tokens. While smaller in scale than LOTSA, the model demonstrates flawless adherence to neural scaling laws; its zero-shot performance continuously improves with both model size (scaling from $10^3$ to $3 \times 10^7$ parameters) and data scale 375253. Furthermore, Lag-Llama is particularly recognized for its state-of-the-art capability to adapt via few-shot learning. By fine-tuning the model on just a few hundred data points of an unseen target dataset, it seamlessly aligns to highly specialized downstream tasks, dramatically lowering the barrier to entry for bespoke industrial applications 105326.
TimesFM (Google) and Timer-XL (Tsinghua University)
Google Research's TimesFM is a 200-million parameter decoder-only transformer that leverages variable-length patching to handle arbitrary periodicities and seasonalities. It consistently dominates univariate zero-shot benchmarks, frequently matching or beating heavily tuned machine learning algorithms without undergoing a single gradient update on the target data 21255. Google expanded the capabilities of TimesFM by introducing In-Context Fine-Tuning (TimesFM-ICF). This technique allows the model to adapt dynamically via in-context examples provided at inference time - mirroring the few-shot prompt engineering techniques utilized to steer language models - eliminating the computational overhead of formal supervised fine-tuning while matching supervised accuracy 16.
Similarly, Timer-XL from Tsinghua University addresses the performance degradation standard transformers face when analyzing excessively long historical contexts. By reformulating forecasting strictly as "multivariate next token prediction" and utilizing a novel TimeAttention mechanism that captures fine-grained intra- and inter-series dependencies, Timer-XL excels at zero-shot forecasting over thousands of sequential patches 275728. Related architectures, such as UniTime, incorporate cross-domain prompt instructions, explicitly feeding language-based context alongside the time-series arrays to guide the transformer's attention mechanisms across varying industry verticals 245960.
How do these models handle benchmarking, calibration, and energy efficiency?
Evaluating the genuine utility of foundation models requires rigorous, standardized benchmarking to prevent "test-set contamination" - a phenomenon where a model inadvertently memorizes the test data during its massive pre-training phase, thereby artificially inflating its zero-shot performance metrics 61. To combat this, the academic and industrial community established the General Information on Forecasting Tasks Evaluation (GIFT-Eval). Comprising 28 entirely novel datasets with diverse forecast horizons and frequencies, GIFT-Eval provides an untainted arena to evaluate zero-shot MASE (Mean Absolute Scaled Error) and CRPS (Continuous Ranked Probability Score) 556162.
A critical concern surrounding foundation models is calibration. In the deep learning domain, neural networks are notoriously overconfident, producing narrow prediction intervals that fail to capture the true variance of real-world outcomes. However, comprehensive evaluations of TSFMs reveal a starkly different reality. Time-series foundation models are consistently well-calibrated out of the box. They provide reliable, distribution-free mathematical guarantees through native probabilistic outputs and conformal prediction techniques, demonstrating neither systematic overconfidence nor underconfidence. When an enterprise requests a 95% prediction interval for inventory demand from Lag-Llama or Moirai, the true value demonstrably falls within that interval 95% of the time, regardless of the underlying data distribution 2293031.
However, this sophisticated generalization comes at an environmental and computational cost. Energy-efficiency benchmarks (such as those conducted using CodeCarbon over Swiss meteorology and school datasets) reveal pronounced architectural disparities. While accuracy is largely dataset-dependent, energy efficiency is strictly architecture-driven. Models utilizing quantization, such as Chronos-Bolt, achieve consistently low latency and exceptional energy efficiency, measured in Watt-hours (Wh) and Energy per Billion Parameters. Conversely, dense models and those utilizing complex Mixture of Experts routing, such as Moirai-MoE, exhibit substantially higher energy expenditure for comparable or marginally superior error reductions. Consequently, enterprise architects must critically evaluate the accuracy-energy trade-off when selecting a foundational backbone for large-scale production deployments 32.
Why is predicting the stock market fundamentally different from retail forecasting?
Given that foundation models are capable of parsing billions of historical data points, a natural hypothesis is that these architectures can effortlessly predict financial asset prices, stock market movements, and foreign exchange rates. However, empirical evidence consistently demonstrates that financial time-series forecasting fundamentally resists the zero-shot capabilities that make TSFMs so powerful in retail, energy, and traffic domains 66768.
The primary difficulty arises from the structural difference between systems governed by behavioral or physical constants and systems governed by adversarial human dynamics. This discrepancy is quantified by the Signal-to-Noise Ratio (SNR) 6769.
In tasks where deep learning traditionally excels, the SNR is extremely high. For example, in computer vision, an image of a cat contains a dense, stable signal (the structural geometry of the feline) against minor noise (background blur or variable lighting). The underlying physical rules of what constitutes a cat do not suddenly change based on the actions of the observer 6769. Financial markets, conversely, operate in an inherently low SNR environment. The "signal" - genuine, predictive alpha regarding an asset's fundamental value or future trajectory - is aggressively obscured by massive volumes of "noise." This noise encompasses high-frequency trading algorithm execution, sudden macroeconomic policy changes, geopolitical shocks, and unpredictable shifts in retail sentiment. Even the most sophisticated investment strategies are subjected to sudden, inexplicable market fluctuations 676970.
More importantly, financial markets are characterized by reflexivity. Unlike forecasting retail demand for winter coats - where predicting a cold weather front does not alter the actual weather - predicting the financial markets alters the behavior of market participants. If a powerful foundation model identifies a reliable arbitrage signal, algorithmic traders instantly deploy capital to exploit it. The act of exploiting the inefficiency neutralizes it, effectively erasing the predictive pattern from all future data 6771.
This adversarial dynamic frequently leads to severe "regime changes." A predictive pattern that works flawlessly during a decade of low-interest-rate quantitative easing will fail catastrophically during an inflationary, high-interest-rate tightening cycle 672. Classical models and deep neural networks assume a degree of stationarity, expecting future probabilistic distributions to roughly resemble past training distributions. Foundation models, pre-trained on diverse historical epochs, frequently struggle when sudden, unprecedented structural breaks invalidate the entire historical context 194029. When a central banking authority suddenly shifts to an aggressive Negative Interest Rate Policy (NIRP), the entropy of the market diverges entirely from standard historical norms, rendering prior generalized patterns useless 72. A foundation model cannot dismiss a sudden structural break as a statistical error; it must rapidly adapt to an entirely new reality without the benefit of prior examples 40.
Furthermore, as outlined in the EPOCH framework (Empathy, Presence, Opinion, Creativity, Hope), AI operates as a universal approximation function that thrives on objective, realized probabilities. Financial markets, however, are driven heavily by subjective probabilities, human judgment, relationships, and speculative ethics 73. Consequently, while TSFMs are exceptional tools for quantitative analysts when simulating portfolio risk, modeling volatility variances, or detecting anomalous execution patterns, they cannot serve as autonomous, zero-shot stock market oracles 66873. Any model claiming long-term, directional financial foresight without continuously adapting to ongoing, macro-level regime shifts is merely extrapolating historical noise, not extracting actionable signal 71.
Should businesses replace traditional methods like ARIMA with these models?
The advent of highly accessible, robust time-series foundation models forces modern organizations to fundamentally re-evaluate their predictive analytics architecture. For decades, the Box-Jenkins ARIMA framework and Exponential Smoothing models served as the gold standard for enterprise forecasting. ARIMA operates by mathematically decomposing a series into autoregressive behavior (current values depending on past values), differencing (to enforce stationarity), and moving average effects (current values depending on past forecast errors) 23.
The defining characteristic of ARIMA is its profound interpretability; a data scientist can explicitly isolate and explain to stakeholders exactly how much a Q4 forecast relies on the data point from exactly one year prior (seasonality) versus the prediction error from one step prior 4. The narrative that foundation models instantly render ARIMA obsolete is empirically false. In extensive benchmarking, including the M5 forecasting competition subsets and massive demographic forecasting evaluations spanning decades, classical statistical methods remain fiercely competitive on univariate, well-behaved time series 237.
If an enterprise is forecasting a single, stable metric - such as monthly software-as-a-service (SaaS) churn displaying a clear, linear trend and highly predictable seasonality - ARIMA offers highly accurate forecasting at a fraction of the computational complexity. As noted, energy-efficiency benchmarks highlight that invoking a 311-million parameter MoE foundation model to forecast a simple linear trend requires an exponential increase in energy expenditure with virtually zero gain in predictive accuracy 4403274. A well-tuned classical model remains an essential, dependable baseline.
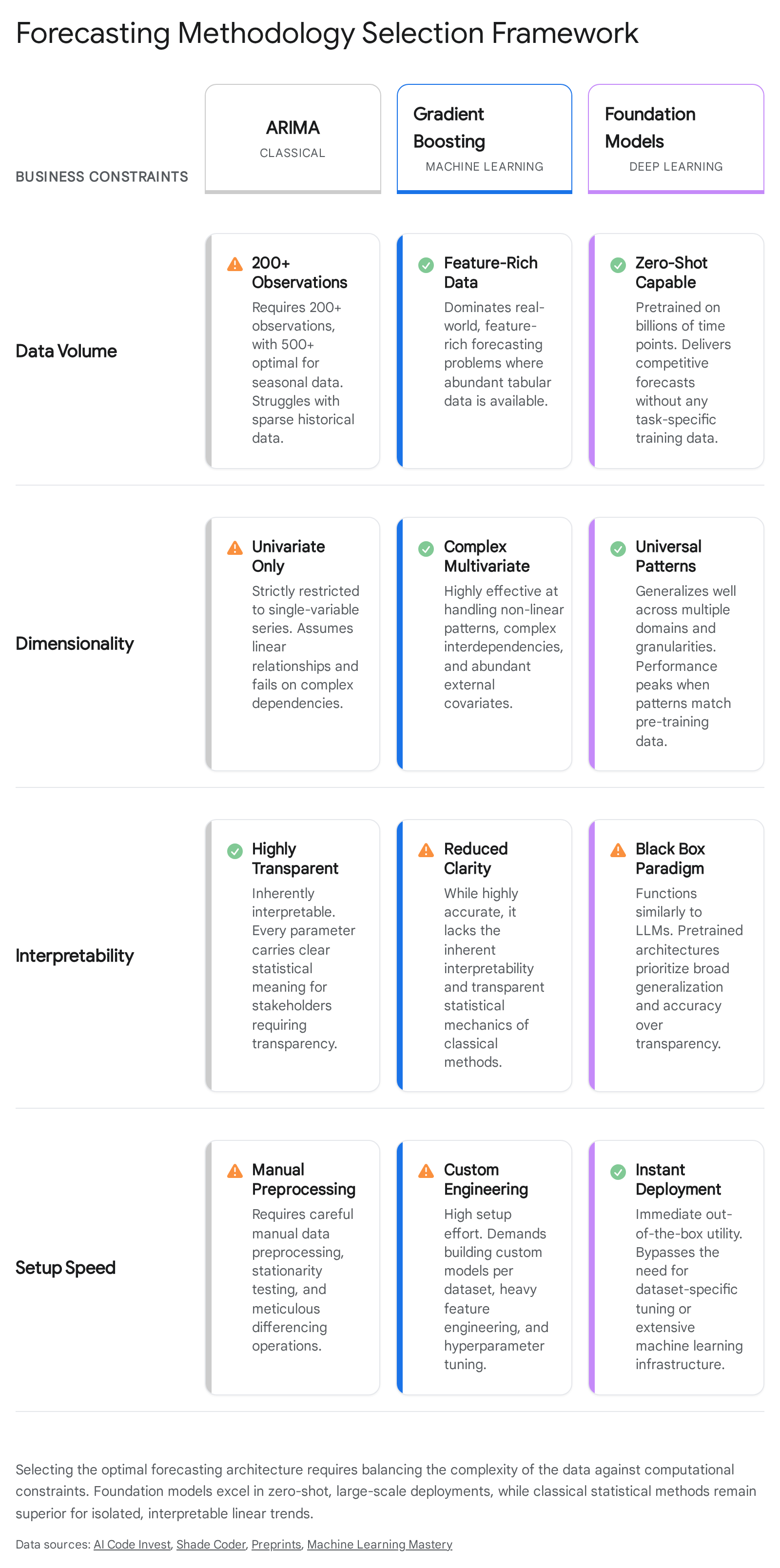
However, traditional statistical models scale exceptionally poorly. If a global logistics firm needs to forecast highly volatile demand for 100,000 distinct stock-keeping units (SKUs) across 500 regional distribution centers, training, validating, and maintaining 50,000,000 individual ARIMA models becomes an operational and infrastructure nightmare 158. Furthermore, pure ARIMA models cannot gracefully handle complex external covariates like sudden promotional events, competitor pricing changes, or compounding weather effects across high-dimensional datasets without evolving into much more complex ARIMAX structures, which remain fundamentally linear 474.
To optimize resource allocation and predictive accuracy, modern organizations should adopt a tiered integration framework when deciding between these disparate methodologies:
1. The Cold-Start and Massive Scale Scenario Enterprises should immediately deploy zero-shot foundation models (such as Chronos-2 or TimesFM) when forecasting entirely new products, entering emerging markets, or dealing with millions of highly volatile series lacking deep historical context. TSFMs leverage their massive pre-training corpora to infer the correct trajectory based on universal patterns, providing an immediate, highly accurate baseline without the need for an extensive, heavily engineered machine learning pipeline 21175.
2. The Feature-Rich, Tabular Operational Scenario For operational environments abundant with domain-specific features - such as incorporating granular minute-by-minute weather data, dynamic grid pricing, localized foot traffic, and specific ad-spend metrics - Gradient Boosting frameworks (such as LightGBM or XGBoost) currently dominate. These machine learning models excel at handling structured tabular data with hundreds of explicitly engineered features, consistently beating purely temporal deep learning models in Kaggle and M5 forecasting competitions 2876. However, the latest foundation models incorporating native any-variate covariate support (like Moirai and Chronos-2) are rapidly closing this gap, especially when efficiently fine-tuned via Low-Rank Adaptation (LoRA) or In-Context Learning directly to local data distributions 93349.
3. The Risk-Aware Probabilistic Scenario In mission-critical sectors such as supply chain logistics, grid energy management, or intensive care unit vitals monitoring, static point forecasts are entirely insufficient; decision-makers require statistically calibrated uncertainty to manage risk dynamically. Predicting that inventory demand will be exactly 1,000 units is infinitely less valuable than knowing there is a rigorously verified 95% probability that demand will fall strictly between 800 and 1,200 units. By utilizing decoder-only generation, mixture distributions, and conformal prediction frameworks, TSFMs natively support probabilistic forecasting, outputting the comprehensive predictive distributions required for automated, risk-aware algorithmic decision-making at scale 2394130.
Bottom line
Time-series foundation models represent a permanent, paradigm-shifting architectural evolution in numerical forecasting. By successfully solving the complex modality gap between linguistic processing and continuous numerical streams through advanced quantization, patching, and lag engineering, models such as Chronos, Moirai, TimesFM, and TimeGPT leverage billions of historical data points to generate accurate, probabilistic forecasts across highly diverse industries. While classical statistical methods like ARIMA maintain a structural, energy-efficient advantage for isolated, linear univariate problems, and financial market prediction remains fundamentally constrained by non-stationary reflexivity and low signal-to-noise ratios, TSFMs have successfully solved the enterprise cold-start problem. For organizations seeking to forecast vast catalogs of multi-dimensional variables at unprecedented scale, these foundation models effectively eliminate the friction of building custom, isolated machine learning pipelines, democratizing access to highly calibrated, robust predictive analytics directly out of the box.