How Transformer Attention Works in Plain English
The attention mechanism allows large language models to weigh the relevance of every word in a text against every other word simultaneously, creating a deep contextual understanding that mimics human reading. By breaking text into mathematical queries, keys, and values, transformers bypass older sequential processing methods, enabling massively parallel computation. Modern breakthroughs have further optimized this mechanism, allowing models to process millions of words without succumbing to computer memory limitations.
The Sequential Memory Dilemma
Before the summer of 2017, the artificial intelligence industry relied heavily on Recurrent Neural Networks (RNNs) and their more advanced variants, such as Long Short-Term Memory (LSTM) networks, to process text 113. The underlying logic of an RNN was elegant but fundamentally flawed for large-scale applications: it read text strictly sequentially, word by word, from left to right. It maintained an internal "hidden state" or memory that carried information from previous words into the processing of subsequent ones 13.
However, this architecture suffered from what researchers often refer to as the "telephone game" problem 1. As the model progressed through a long paragraph or document, the memory of the first few sentences became increasingly diluted or distorted. If a pronoun at the bottom of a page referred back to a noun at the very beginning, the RNN would often lose the connection 3.
Furthermore, because RNNs had to process a word before they could process the subsequent word, their training could not be easily parallelized 32. Modern Graphics Processing Units (GPUs) contain thousands of cores designed to do math simultaneously, but the sequential nature of RNNs forced these massive chips to wait in line, creating a severe bottleneck that prevented models from scaling on massive datasets 2.
This bottleneck was shattered by a team of Google Brain researchers in their landmark 2017 paper, Attention Is All You Need 15. The paper introduced the "Transformer" architecture, which completely discarded sequential recurrence in favor of a mechanism called "self-attention" 15.
Instead of reading a sentence sequentially, the Transformer ingests the entire sequence at once. It then allows every token (a word or sub-word) to directly "look at" and draw context from every other token in the sequence simultaneously, regardless of physical distance 35. This not only solved the memory degradation problem - because the distance between any two words was suddenly reduced to a single mathematical operation - but it also allowed the model's training to be massively parallelized, kicking off the era of modern Large Language Models (LLMs) 325.
The Mechanics of Self-Attention
To understand how self-attention works, we must look at how the model processes raw text. When a sentence enters a Transformer, each token is converted into a high-dimensional mathematical vector called an embedding 56. But an embedding alone only represents a word's static dictionary definition; it lacks context. For instance, the word "bank" has the exact same initial embedding whether the sentence is "I sat on the river bank" or "I deposited money in the bank" 7.
Self-attention is the mechanism that updates these static dictionary embeddings into rich, context-aware representations 18. It does this through a framework of three distinct vectors generated for every single token: Queries, Keys, and Values 169.
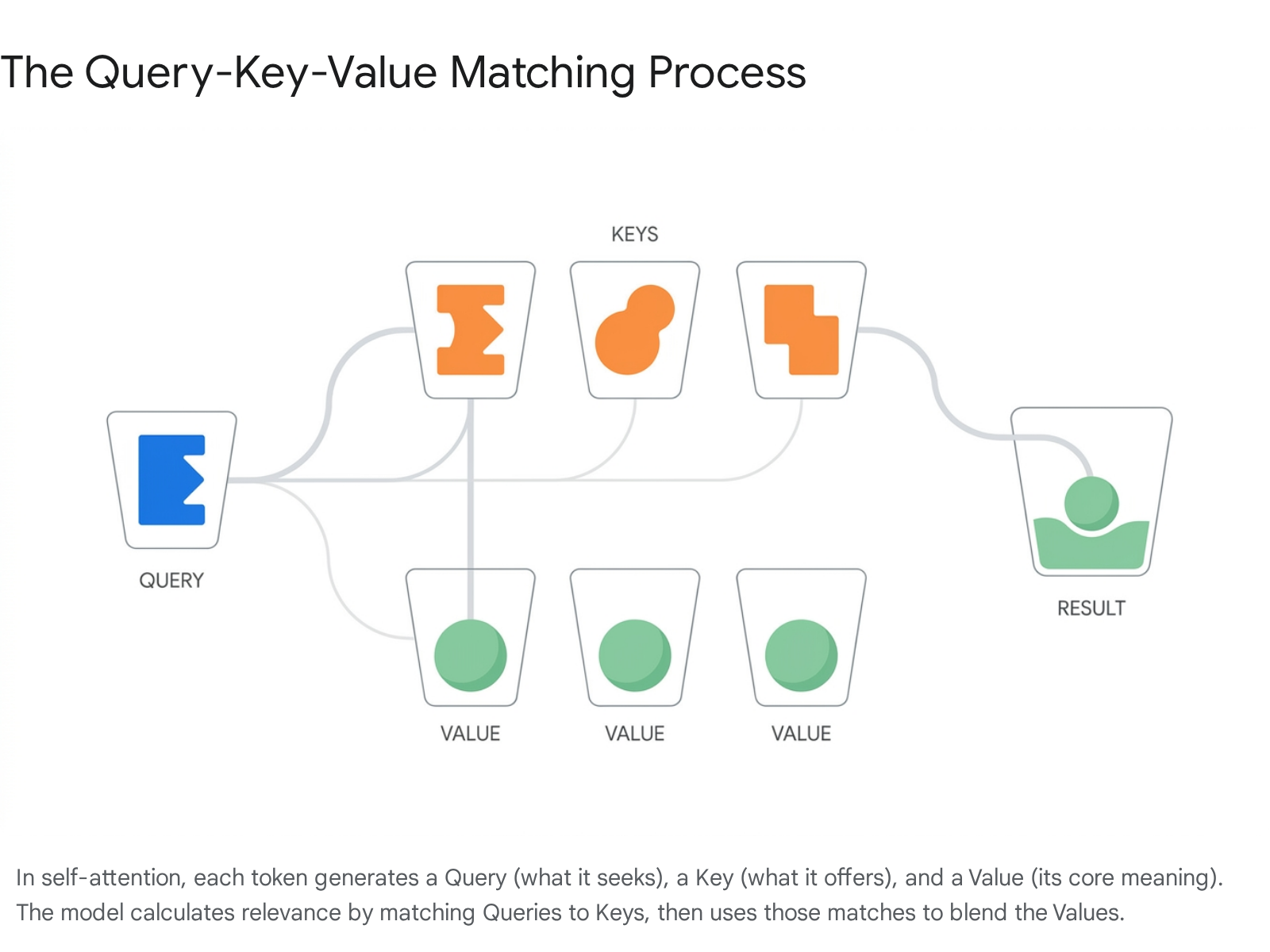
Queries, Keys, and Values (QKV)
The QKV concept is loosely inspired by retrieval systems, much like searching for a video in a database 2.
- The Query (What I am looking for): Think of the Query as a token asking a question. It projects a vector that essentially says, "What other words in this sentence help explain my specific grammatical or semantic meaning?" 29.
- The Key (What I contain): Think of the Key as a token's index tag. It projects a vector broadcasting, "Here is the grammatical and semantic information I possess" 29.
- The Value (My actual substance): Think of the Value as the core meaning of the token that will be passed along if another word decides it is highly relevant 9.
When processing a sentence, the Transformer calculates the "attention score" between one word and every other word. It does this by taking the mathematical dot product of the first word's Query vector and the second word's Key vector 91011. The dot product is a way to measure alignment in linear algebra. If the Query of the word "bank" strongly aligns with the Key of the word "river," the dot product will yield a high numerical score. If it aligns poorly with the word "the," the score will be low 9.
Scaling and the Softmax Function
Once these raw dot-product scores are calculated, they must be stabilized. If the dimensionality of the vectors is very large, dot products can grow into massive numbers, which destabilizes the neural network's gradients 3. To fix this, the mechanism employs "Scaled Dot-Product Attention," dividing the scores by the square root of the key dimension 11313.
These scaled scores are then passed through a "softmax" function 1213. The softmax function acts as a normalizer, converting the raw scores into percentages (probabilities) that always sum exactly to 1.0 (or 100%) for a given token 124.
For example, when evaluating the word "bank" in the context of a river, the softmax function might dictate that "bank" gives 70% of its attention to "river", 20% to "sat", and 10% to itself 19.
Finally, the model multiplies these percentage weights by the Value vectors of the respective words and adds them all together 129. The result is a brand-new, updated vector for the word "bank" that is heavily tinted by the "river" vector. The word is no longer a static dictionary definition; it is deeply contextualized and aware of its surroundings.
Why One Head Isn't Enough: Multi-Head Attention
A single self-attention mechanism (or "head") computing a single attention distribution can only focus on one type of relationship at a time 1516. If a token's Query is busy searching for grammatical subject-verb agreements, it might miss subtle semantic nuances, causal links, or contextual tone elsewhere in the sentence 1516.
To solve this, the Transformer splits its operations into "Multi-Head Attention" 1115. Instead of executing one massive attention calculation, the model runs multiple self-attention operations in parallel 135. It takes the high-dimensional token embeddings and splits them across several smaller subspaces 1516. For example, if a model has an embedding dimension of 512 and uses 8 attention heads, each head operates in a 64-dimensional subspace 315.
By splitting the workload, each attention head naturally develops a specialization - even though the human programmers never explicitly code them to look for specific things 67. This emergent behavior is one of the most fascinating discoveries in artificial intelligence research, effectively serving as an analogue for how human teams divide labor 157.
The Emergence of Linguistic Specialization (BERTology)
In 2019, researchers from Stanford University and the University of Washington published an exhaustive analysis of the attention heads inside Google's BERT language model 82122. They discovered that specific attention heads autonomously specialize into distinct linguistic parsers 822. Some act as grammar engines, others track narrative flow, and others handle positional logic 157.
The literature broadly categorizes these specialized heads into several distinct functional roles 15789:
| Attention Head Specialization | Function and Behavior | Examples from Research Literature |
|---|---|---|
| Syntactic Heads | Focus on grammatical structure, parsing sentences into verbs, nouns, and modifiers. | Head 8-10 in BERT links direct objects to verbs with 86.8% accuracy; Head 8-11 connects determiners to nouns at 94.3% accuracy 822. |
| Positional Heads | Focus heavily on adjacent words, strictly attending to the token immediately preceding or following. | Crucial for assembling compound words, understanding local phrases, and maintaining sequence order 879. |
| Coreference Heads | Focus on tracking pronouns and connecting them to their original noun subjects across distances. | Allows the model to correctly identify what "it," "he," or "they" refers to across multiple sentences 1568. |
| Semantic Heads | Focus on broad topic relationships and synonyms regardless of grammar or distance. | Connects conceptually related words like "agent," "test suite," and "pull request" to understand software engineering context 15. |
| Delimiter Heads | Focus on special structural tokens (like sentence separators or the start of a prompt). | Helps the model manage transitions between distinct thoughts or document sections 8219. |
Once all these parallel heads have finished computing their specific viewpoints, their outputs are concatenated (stitched together) and passed through a final linear transformation 1113. The result is a singularly unified, profoundly deep representation of the text 16.
Visualizing Attention via Heatmaps
Because attention scores are mathematically deterministic percentages (ranging from 0 to 1), researchers can easily extract them from a running model and visualize them as heatmaps 2410. This provides a rare, transparent window into the "black box" of deep learning.
In an attention heatmap, the words of a sentence are placed along both the X and Y axes 10. The intersection of any two words is shaded based on the attention score 10. Dark, cooler colors (like dark blue) represent a low attention score (near 0%), while bright, warmer colors (like red or yellow) represent a high attention score 2410.
By looking at these heatmaps over successive epochs of training, AI researchers can perform "mechanistic interpretability" 1011. If a model correctly answers a riddle, researchers can look at the heatmap to see exactly which words the model focused on to deduce the answer 10. If a specific attention head consistently produces heatmaps linking verbs to their exact direct objects, researchers know that head has successfully learned English syntax without human intervention 810.
The Quadratic Bottleneck: The Memory Wall
If attention is so powerful, why can't we simply feed an entire library of books or an hour of video into an AI all at once? The answer lies in the harsh mathematical reality of how standard self-attention scales.
In standard dot-product attention, every single token in a sequence must generate a Query and compare it against the Key of every other token 101213. This creates an $N \times N$ matrix of relationships, where $N$ is the number of tokens in the sequence 1029. * If a sequence is 100 tokens long, the model computes 10,000 interactions. * If a sequence is 1,000 tokens long, the model computes 1,000,000 interactions. * If a sequence is 100,000 tokens long, the model must compute 10,000,000,000 (ten billion) interactions.
This is known as $O(N^2)$ or "quadratic" time and memory complexity 101230. As the sequence length (the "context window") grows, the amount of GPU memory required to compute and store these massive attention matrices explodes 101231. It quickly exceeds the physical limits of standard AI accelerators like Nvidia's H100 GPUs 31.
The industry refers to this fundamental limitation as the "Memory Wall" 1229. Over the past few years, the race to build models capable of reading massive codebases or entire novels has driven researchers to heavily optimize both the attention algorithm and the hardware data pathways 3132.
The Efficiency Era: Rethinking the Architecture (2022 - 2026)
To bypass the quadratic bottleneck, researchers have developed brilliant algorithmic workarounds. These techniques do not change the fundamental linguistic philosophy of the Transformer, but they drastically alter how the mathematics are executed on the silicon.
FlashAttention: Rewriting the IO Pathway
Introduced by Tri Dao and colleagues in 2022, and continually refined into FlashAttention-2 and FlashAttention-3, this algorithm achieved massive speedups without losing any accuracy 1231. It computes exact attention, but does so with profound "IO-awareness" (Input/Output awareness) 1231.
Modern GPUs contain two critical types of memory: 1. HBM (High Bandwidth Memory): Massive capacity but relatively slow to read from and write to 3133. 2. SRAM (Static Random-Access Memory): Tiny capacity (often just megabytes per streaming multiprocessor) but blisteringly fast 3133.
Standard attention implementations move massive $N \times N$ matrices back and forth between the slow HBM and the fast SRAM repeatedly during calculation, creating a massive data traffic jam 1231. FlashAttention bypasses this using a technique called "tiling." It loads smaller blocks of Queries, Keys, and Values from the slow HBM into the fast SRAM, calculates the attention for that block entirely on-chip, and writes only the final output back to the HBM 1231.
By avoiding the materialization of giant intermediate attention matrices in the slow memory, FlashAttention achieves 2x to 4x speedups, radically reduces memory usage, and allows models to push GPU utilization up to 75% of theoretical maximum FLOPs 3133.
Taming the KV Cache: MQA, GQA, and MLA
During inference (when the model is actually generating text), Transformers predict one token at a time autoregressively 634. To predict token 1,001, the model needs the attention context of the previous 1,000 tokens. Recalculating the Keys and Values for those previous 1,000 tokens every single step would be incredibly slow, so models store them in what is known as the "KV Cache" 3234.
However, as context lengths grow to hundreds of thousands of tokens, the KV Cache consumes massive amounts of GPU memory 103234. Researchers developed several attention variants to compress this cache: * Multi-Query Attention (MQA): Instead of every attention head having its own set of Keys and Values, MQA forces all Query heads to share a single Key and Value head 6532. This drastically shrinks the cache but can slightly degrade model performance on complex reasoning 532. * Grouped-Query Attention (GQA): Used by models like Llama and Mistral, GQA strikes a balance 65. It groups several Query heads together and assigns one Key-Value pair to each group (e.g., 32 Query heads sharing 8 Key-Value heads) 6. This preserves high performance while slashing memory costs 65. * Multi-head Latent Attention (MLA): Pioneered by DeepSeek, MLA takes a radical approach by compressing the Key and Value matrices into a single, low-rank latent vector 532. This has been shown to compress the KV cache by up to 93.3% while maintaining top-tier performance, vastly improving inference speed 32.
Sparse and Sliding Window Attention
Another strategy is to stop computing attention for tokens that are too far apart to matter. Mistral models utilize "Sliding Window Attention" (SWA) 103214. Instead of every token looking at every previous token, a token is only allowed to look at a fixed local window - for example, the previous 4,096 tokens 1032. This changes the computational complexity from quadratic $O(N^2)$ to linear $O(N \times W)$, where W is the window size 1032.
While it sounds like SWA would cause the model to lose long-term memory, Transformers stack dozens of attention layers on top of each other 6910. If Token A can attend to Token B in Layer 1, and Token B can attend to Token C in Layer 2, then Token A becomes indirectly connected to Token C 6910. The effective "receptive field" grows larger with every layer, similar to how Convolutional Neural Networks process images 6910.
Similarly, models using "Native Sparse Attention" (NSA) or "Mixture of Attention" (MoA) dynamically select only the most important tokens to attend to, routing different sparse patterns to different heads based on their function 303234. Some heads might focus locally, while others act as global sentinels 34.
Scaling the Hardware: Ring Attention
When dealing with massive sequences that simply cannot fit on one machine, researchers at UC Berkeley developed "Ring Attention" 361538. Older distribution methods (like DeepSpeed Ulysses) required gathering the entire sequence on each device, which bottlenecked at scale 36.
Ring Attention splits the input sequence into blocks and distributes them across a cluster of GPUs (or TPUs) arranged in a logical ring topology 3616. Each device holds a portion of the Queries, while the Key-Value blocks are passed sequentially around the ring from device to device 3640. Because no single device is ever forced to store the full sequence, Ring Attention allows context sizes to scale linearly with the number of devices added 3615. In testing, this allowed models to handle contexts exceeding 100 million tokens without making mathematical approximations 1516.
Compressing History: Infini-Attention
To push context windows toward practical infinity - as seen in Google's Gemini 1.5, which boasts a 1-million to 2-million token window - Google researchers introduced Infini-attention 414243.
Infini-attention splits the workload into two simultaneous pathways within a single Transformer block: 1. Local Masked Attention: Standard, highly precise dot-product attention is applied only to the most recent segment of text 74344. 2. Compressive Memory: Instead of discarding older tokens that fall outside the local window, their Key-Value states are mathematically compressed and stored in a fixed-size memory matrix 74143.
When the model needs to recall a specific fact from hundreds of pages ago, its current Query vector interacts with this dense compressive memory matrix using a linear attention mechanism to retrieve the historical data 74142. This approach fuses the high resolution of local attention with the endless capacity of a compressed archive, solving the "lost in the middle" problem where LLMs previously forgot facts buried deep in their context 743.
| Attention Optimization | Primary Bottleneck Solved | Mechanism of Action |
|---|---|---|
| FlashAttention | GPU Memory IO latency | Reorders operations (tiling) to keep data in fast SRAM, minimizing slow HBM reads/writes without altering accuracy 1231. |
| GQA / MLA | KV Cache memory bloat | Groups Query heads to share Key/Value heads, or compresses the entire cache into a latent vector to save memory during inference 6532. |
| Sliding Window / Sparse | Quadratic scaling complexity | Restricts attention to a local window or select subsets of tokens, relying on stacked layers to build global context 103234. |
| Ring Attention | Single-GPU memory limits | Distributes sequence blocks in a circular network across multiple GPUs, allowing context to scale linearly with hardware 361540. |
| Infini-Attention | Context length constraints | Combines exact local attention with a continuously updated compressed memory matrix for historical retrieval 743. |
Case Study: Naver's HyperCLOVA X
The practical impact of combining these optimizations is evident in enterprise-scale models like Naver's HyperCLOVA X, a model optimized specifically for the Korean language alongside English and coding 454647.
To build an efficient system capable of processing massive multilingual datasets without exorbitant training costs, Naver utilized advanced attention techniques like Grouped-Query Attention (GQA) and rotational position embeddings 4548. Furthermore, they integrated aggressive pruning (removing low-importance parameters) and knowledge distillation, allowing a smaller model like HyperCLOVA X-SEED-0.5B to train with nearly 39 times greater resource efficiency than comparable models 49. This demonstrates how attention optimization is not just academic theory; it dictates the commercial viability and sovereign capability of national AI models 4649.
Manipulating Attention: The Science of Prompt Engineering
Understanding how the attention mechanism works under the hood is critical for interacting with LLMs effectively. The emerging field of "Context Engineering" or "Prompt Engineering" is fundamentally the practice of manipulating a model's attention allocation 1350.
Because the self-attention mechanism forces every token to evaluate every other token, context is a finite and fragile resource 1351. As context lengths increase, the model's "attention budget" gets stretched thin across thousands of tokens, increasing the likelihood of the model hallucinating or losing focus 1351. Modern prompt engineering relies on structural techniques to guide the QKV mechanism toward the right information:
- XML Tagging: Structuring prompts with tags like
<instructions>or<examples>creates highly distinct token embeddings. Because LLMs are often trained on code, the attention mechanism recognizes these structural delimiters, allowing Delimiter Heads to properly segment the input and prevent the model from confusing instructions with reference data 525354. - Chain-of-Thought (CoT): Asking a model to "Think step-by-step" is not a psychological trick; it is an attention allocation strategy 5055. By forcing the model to generate intermediate reasoning tokens, those new tokens enter the context window 50. The model's attention heads can now attend to these explicit, logical stepping stones when generating the final answer, rather than trying to map a complex problem to a solution in a single, massive attention leap 5055.
- Context Layering: Prompt engineers organize information hierarchically - placing the system role, explicit rules, examples, and the immediate user query in strict sequence 515356. This structured flow aligns with how Positional Heads and Syntactic Heads expect information to be presented, reducing the "noise" that the Query vectors must filter out 515356.
Neuroscience and Artificial Cognition
As LLMs scale and their attention mechanisms become more sophisticated, researchers are observing striking functional alignments between artificial attention architectures and biological cognition 1157.
A body of research emerging between 2024 and 2026 suggests that the functional architecture of highly capable LLMs mirrors organizational patterns found in human Functional Brain Networks (FBNs) 5758. In a study analyzing "cognitive heads" using the CogQA dataset, researchers mapped specific attention heads to distinct cognitive tasks like memory retrieval or logical inference 58.
They found an extreme degree of sparsity: for any given cognitive function, fewer than 7% of the attention heads were actually highly active 58. The models rely on highly specialized, localized subnetworks to solve specific problems - paralleling the human brain's tendency to localize functions in specific cortical regions 115758.
Institutions like Google DeepMind and NTT Research are actively exploring how to bridge this gap further 596061. DeepMind's proposals around "Nested Learning" and "Reinforced Attention Learning" represent a fundamental shift 59. Rather than merely rewarding an AI for predicting the correct next word, Nested Learning rewards the model for paying attention to the right internal information at different temporal speeds 59.
By creating a continuum memory system with slow-updating long-term components and fast-updating short-term components, researchers are attempting to mimic how the human brain manages lifelong learning 59. If successful, this could solve the catastrophic forgetting problem, moving AI away from being a static snapshot of training data toward becoming a continuously learning system 5960.
Bottom line
The attention mechanism revolutionized artificial intelligence by allowing models to dynamically weigh the relationships between all parts of a sequence simultaneously, breaking free from the constraints of linear, sequential processing. Through the use of parallel query, key, and value vectors, "attention heads" autonomously specialize to decipher syntax, semantics, and context with remarkable precision. While the quadratic computational cost of attention remains a hurdle, modern engineering innovations - ranging from FlashAttention to Infini-attention - are dismantling the memory wall, paving the way for models with infinite context windows and increasingly brain-like functional architecture.