Self-Supervised and Representation Learning for Financial Time Series
The application of machine learning to financial time series analysis has historically been constrained by the unique, adversarial nature of market data. Unlike the relatively stable, high-signal-to-noise environments of natural language processing or computer vision, financial markets are characterized by pervasive non-stationarity, extreme volatility, low signal-to-noise ratios, and heavy-tailed distributions 1. Classical econometric approaches, such as Autoregressive Integrated Moving Average (ARIMA) and Generalized Autoregressive Conditional Heteroskedasticity (GARCH) models, rely on strict statistical assumptions that often fail to capture the complex, non-linear dynamics of modern trading environments 23. Conversely, traditional supervised deep learning methods are highly sensitive to label noise and frequently overfit to transient market regimes, severely limiting their out-of-sample generalization 44.
To overcome the limitations of strictly supervised approaches and the manual feature engineering required by classical models, the field has increasingly pivoted toward self-supervised learning (SSL) and representation learning. By pre-training neural architectures on vast quantities of unlabeled market data, SSL algorithms construct robust latent representations that capture intrinsic market structures, temporal dependencies, and cross-asset correlations 45. These generalized representations can then be fine-tuned for a variety of downstream tasks, including continuous price forecasting, discrete trend classification, and portfolio optimization 16.
Foundational Architectures in Self-Supervised Learning
The development of self-supervised representations for financial time series broadly falls into two primary architectural paradigms: temporal contrastive learning and masked time series modeling. While both methodologies aim to extract meaningful features without human-annotated labels, they operate on fundamentally different objective functions and yield distinct advantages and computational trade-offs when processing highly volatile market data.
Temporal Contrastive Learning
Contrastive learning frameworks attempt to learn robust representations by maximizing the similarity between differently augmented views of the same temporal sequence (positive pairs) while minimizing the similarity between distinct sequences (negative pairs) 7. Frameworks such as TS2Vec and TS-TCC establish hierarchical contrastive tasks that operate at both the instance and patch levels, enabling the extraction of universal representations across different temporal resolutions 8109.
In financial applications, temporal contrastive learning has proven highly effective at capturing global dependencies and cross-asset correlations. For example, the SimStock framework applies temporal domain generalization alongside contrastive learning to map the evolving similarities between thousands of individual equities 5. By treating different time periods as distinct domains and modeling parameter drift, SimStock effectively contextualizes firm fundamentals alongside time-series features, addressing the non-stationary nature of financial relationships 10. Another architecture, CI-STHPAN, utilizes dynamic hypergraph learning combined with channel-independent processing to construct adaptive hypergraphs based on time series similarities using Dynamic Time Warping 6.
However, contrastive learning faces significant methodological and computational hurdles in the financial domain. Computationally, the contrastive loss function requires calculating similarity scores across all sample pairs within a batch, resulting in a quadratic time complexity of $O(B^2)$, where $B$ represents the batch size 7. This high computational cost makes it difficult to scale to massive datasets without specialized memory-efficient techniques like momentum contrast or feature queueing 7. Methodologically, contrastive learning heavily relies on data augmentation techniques - such as jittering, scaling, or cropping 13 - to generate positive pairs. In financial time series, arbitrary augmentations risk destroying vital temporal correlations or artificially altering the magnitude of volatility signals, thereby generating representations that are divorced from underlying economic realities and leading to negative transfer in downstream forecasting tasks 1411.
Masked Time Series Modeling
To bypass the sampling biases and augmentation risks associated with contrastive methods, masked time series modeling (MTM) - often implemented via Masked Autoencoders (MAEs) - has emerged as a powerful alternative 1112. Inspired by the success of masked language modeling, MTM involves intentionally obscuring a portion of the input time series and training the model to reconstruct the missing segments based on the visible context 1317.
A primary challenge in applying MAEs to financial data is the high degree of local autocorrelation; if masking is performed randomly at the point level, the model can trivially impute missing values by interpolating adjacent data points without learning deep semantic representations 8. To address this, specialized architectures like TimeMAE and PatchTST deploy a patch-based approach, dividing the sequence into sub-series units before masking 91713. TimeMAE utilizes a decoupled autoencoder architecture where the contextual representations of masked and unmasked regions are processed by distinct encoders 13. This design prevents the information leakage associated with shared encoding and addresses the pre-training and fine-tuning discrepancy caused by the presence of artificial mask tokens during the pre-training phase 913.
Computationally, masked autoencoding scales linearly with respect to the batch size and the percentage of masked patches, denoted as $O(B \cdot P)$ 7. Because models like TimeMAE and related Vision Transformer (ViT)-inspired architectures can mask up to 50% to 75% of the input sequence, the encoder only processes a fraction of the data during pre-training. This yields significant reductions in memory consumption and training time compared to contrastive approaches, allowing for larger batch sizes and more extensive pre-training regimens over equivalent wall-clock times 121914.
| Feature / Requirement | Temporal Contrastive Learning | Masked Time Series Modeling (MAE) |
|---|---|---|
| Primary Objective | Maximize similarity of positive pairs; push apart negative pairs. | Reconstruct masked sub-series patches from visible context. |
| Computational Complexity | $O(B^2)$ (Quadratic relative to batch size). | $O(B \cdot P)$ (Linear relative to batch size and unmasked ratio). |
| Data Augmentation | Heavily reliant (jitter, scale, crop). High risk of distorting financial signals. | Minimal reliance. Uses masking as the primary structural perturbation. |
| Representation Strengths | Captures global, instance-level variations and cross-asset structural similarities. | Excels at local semantic reconstruction, fine-grained temporal dynamics, and missing data imputation. |
| Notable Architectures | TS2Vec, SimStock, TS-TCC. | TimeMAE, PatchTST, SimMTM. |
Table 1: Comparative analysis of contrastive learning and masked autoencoding paradigms in time series representation learning.
Hybrid Spatiotemporal Frameworks
Recognizing that both paradigms offer complementary strengths, recent research has explored hybrid frameworks to capture both temporal depth and cross-sectional breadth. For instance, the Decoupled Spatial-Temporal Representation (DeSTR) model integrates masked autoencoding as the foundational pre-training task to capture intra-series temporal dynamics, while simultaneously using spatial-guided transformers to learn the cross-sectional correlations between different financial variables 11. This approach mitigates the necessity for large negative sample batches inherent to pure contrastive learning while preserving the ability to model the complex interdependencies of multi-asset portfolios across large spatial graphs 11.
Market Non-Stationarity and Tokenization
A central challenge separating financial representation learning from natural language processing is non-stationarity - the phenomenon where the statistical properties of a market (such as its mean and variance) change unpredictably over time due to macroeconomic shifts, regulatory changes, and evolving investor behavior 1. Addressing non-stationarity requires models capable of separating transient noise from structural trends without destroying the underlying signal.
Wavelet-Based Tokenization
Foundation models adapted from natural language processing often struggle with real-valued sequential inputs because continuous numerical data does not easily map to a discrete vocabulary 15. Traditional methods scale and quantize values, but this often leads to information loss, spurious regressions, and a failure to isolate overlapping frequency patterns 16.
The WaveToken architecture directly addresses this by introducing a wavelet-based tokenizer 1517. Rather than treating the time series purely in the time domain, WaveToken subjects the input sequence to wavelet decomposition, breaking the signal into time-localized multiscale frequency components 151819. The model scales, decomposes, thresholds, and quantizes these wavelet coefficients, subsequently pre-training an autoregressive model to forecast future tokens 1718.
Because wavelets isolate both coarse, long-term trends and fine, high-frequency structures, WaveToken generates an exceptionally compact representation - functioning on a vocabulary of merely 1024 tokens 15. Empirical benchmarks across 42 datasets confirm that this dual time-frequency resolution allows the model to accurately capture exponential trends, sparse spikes, and non-stationary signals with evolving frequencies. These are properties that typically degrade the performance of standard transformer-based forecasters, which either artificially eliminate non-stationarity (destroying long-term cointegration) or retain it entirely (causing spurious short-term regressions) 151617.
Distributional Realities and Heavy-Tailed Modeling
The statistical properties of asset returns notoriously violate the assumptions of normality. Empirical financial distributions exhibit significant skewness and excess kurtosis, commonly referred to as "heavy tails," alongside volatility clustering where periods of high variance group together temporally 2021.
Limitations of Gaussian Assumptions
Standard generative models and time series forecasters that assume Gaussian noise innovations frequently underestimate the probability of extreme market events. This results in suboptimal risk management, inaccurate pricing of derivative instruments, and poor clustering performance when grouping similar temporal dynamics 2022. While heavy-tailed base distributions can theoretically be applied to normalizing flows, they often introduce severe numerical instability and difficulties in optimizing the neural network 22.
Student-T Mixture Models and the TOTO Architecture
To accommodate the extreme outliers inherent in financial and observability time series, advanced Time Series Foundation Models (TSFMs) have abandoned Gaussian assumptions in favor of Student-T Mixture Models (SMM) 2923. The TOTO (Time Series Optimized Transformer for Observability) foundation model, parameterized at 151 million weights, utilizes a specialized SMM prediction head 232432.
By predicting the parameters of $k$ distinct Student-T distributions alongside a learned weighting for each time step, TOTO successfully models highly skewed data without suffering from the cluster collapse or singularity issues that plague maximum likelihood estimations of Gaussian mixtures 2325. To stabilize training dynamics, TOTO employs a composite robust loss function 23.
Furthermore, TOTO introduces a proportional factorized space-time attention mechanism specifically designed for multivariate series. It applies an 11:1 ratio of time-wise transformer blocks to variate-wise transformer blocks, carefully balancing the need to understand historical autocorrelation against cross-sectional relationships 232425. To handle non-stationarity without the pitfalls of static scaling, it utilizes patch-based causal instance normalization, maintaining causal integrity while adapting to dynamic variance 24. The integration of SMM allows the model to output probabilistic interval forecasts rather than deterministic point predictions, providing a calibrated measure of uncertainty essential for calculating downside risk metrics 24.
Graph-Based Contextual and Cross-Sectional Learning
While wavelet tokenization and robust distributional modeling address the longitudinal characteristics of a single asset, financial markets are fundamentally interconnected ecosystems. The volatility of one equity is heavily conditioned by its peers, supply chains, and broader sector dynamics 10.
Dynamic Semantic Graphs
To capture this cross-sectional complexity, researchers deploy graph-based self-supervised learning. The InfoGAT framework combines the Informer architecture - which uses probabilistic sparse attention to efficiently learn long-term periodic fluctuations - with Graph Attention Networks (GAT) 2627. InfoGAT constructs a semantic graph connecting financial concepts to specific equities based on unstructured evidential data, such as financial documents, earnings call transcripts, and news 2.
By dynamically encoding these inter-stock structural relationships, the model captures both strong intra-industry correlations and subtle cross-industry dependencies 27. Furthermore, it employs a multi-task learning architecture with multi-scale graph reconstruction and hierarchical regularization to prevent node feature over-concentration and preserve prediction diversity during inference 26.
Technical Trading Indicator Optimization
Traditional technical indicators (e.g., Moving Averages, Relative Strength Index, Bollinger Bands) provide insights into market momentum but apply rigid mathematical rules indiscriminately across all assets 6. InfoGAT addresses this via a Technical Trading Indicator Optimization (TTIO) module that uses a skip-gram architecture to learn stock-specific embeddings based on collective investment behaviors, allowing the model to dynamically adapt traditional indicators to unique firm properties 2.
Extensive backtesting on the CSI-300 and S&P 500 datasets demonstrates that this combined structural and temporal representation yields significant improvements. The InfoGAT framework consistently outperforms traditional state-of-the-art baselines in key quantitative metrics, including annualized return, Sharpe ratio, and Information Coefficient (IC), underscoring the necessity of fusing qualitative graph relationships with quantitative time-series data 227.
| Metric | Prediction Focus | Benchmark Relevance in Self-Supervised Models |
|---|---|---|
| Information Coefficient (IC) | Correlation between predicted and actual returns. | Evaluates the pure predictive power of the learned representations prior to portfolio construction 636. |
| Sharpe Ratio | Risk-adjusted return (Excess return divided by volatility). | Assesses whether the model successfully captures structural signals without over-indexing on high-variance noise 16. |
| RankIC | Rank correlation of cross-sectional asset predictions. | Crucial for ranking-based stock selection tasks, testing the model's ability to order a universe of assets correctly 36. |
| Maximum Drawdown | Largest peak-to-trough drop in portfolio value. | Tests the model's robustness during market regime shifts and extreme tail-risk events 628. |
Table 2: Key quantitative metrics used to evaluate the efficacy of self-supervised financial representations in downstream predictive tasks.
Domain-Specific Time Series Foundation Models
The success of Large Language Models (LLMs) has spurred the development of specialized Time Series Foundation Models (TSFMs). The central objective is to pre-train a massive, task-agnostic architecture capable of zero-shot inference across diverse financial applications 29.
General versus Financial Pre-Training
General-purpose TSFMs - such as Chronos, Moirai, and Time-MOE - are pre-trained on diverse, multi-domain corpora comprising weather, traffic, and general macroeconomic data 2930. However, because high-frequency financial data typically constitutes less than 1% of these generalized training corpora, these models often fail to grasp the unique characteristics of market microstructure, such as the low signal-to-noise ratio and the highly specific relationship between open, high, low, close prices, and trading volume 330. Consequently, when applied to quantitative finance tasks, general TSFMs frequently underperform relative to specialized, non-pre-trained models 3.
The Kronos Architecture and K-Line Generation
To bridge this domain gap, specialized financial foundation models have been engineered. The Kronos model abstracts financial K-line (candlestick) sequences as a discrete language 3. Kronos was pre-trained using an autoregressive objective on a massive proprietary corpus comprising over 12 billion K-line records aggregated from 45 global exchanges 3031.
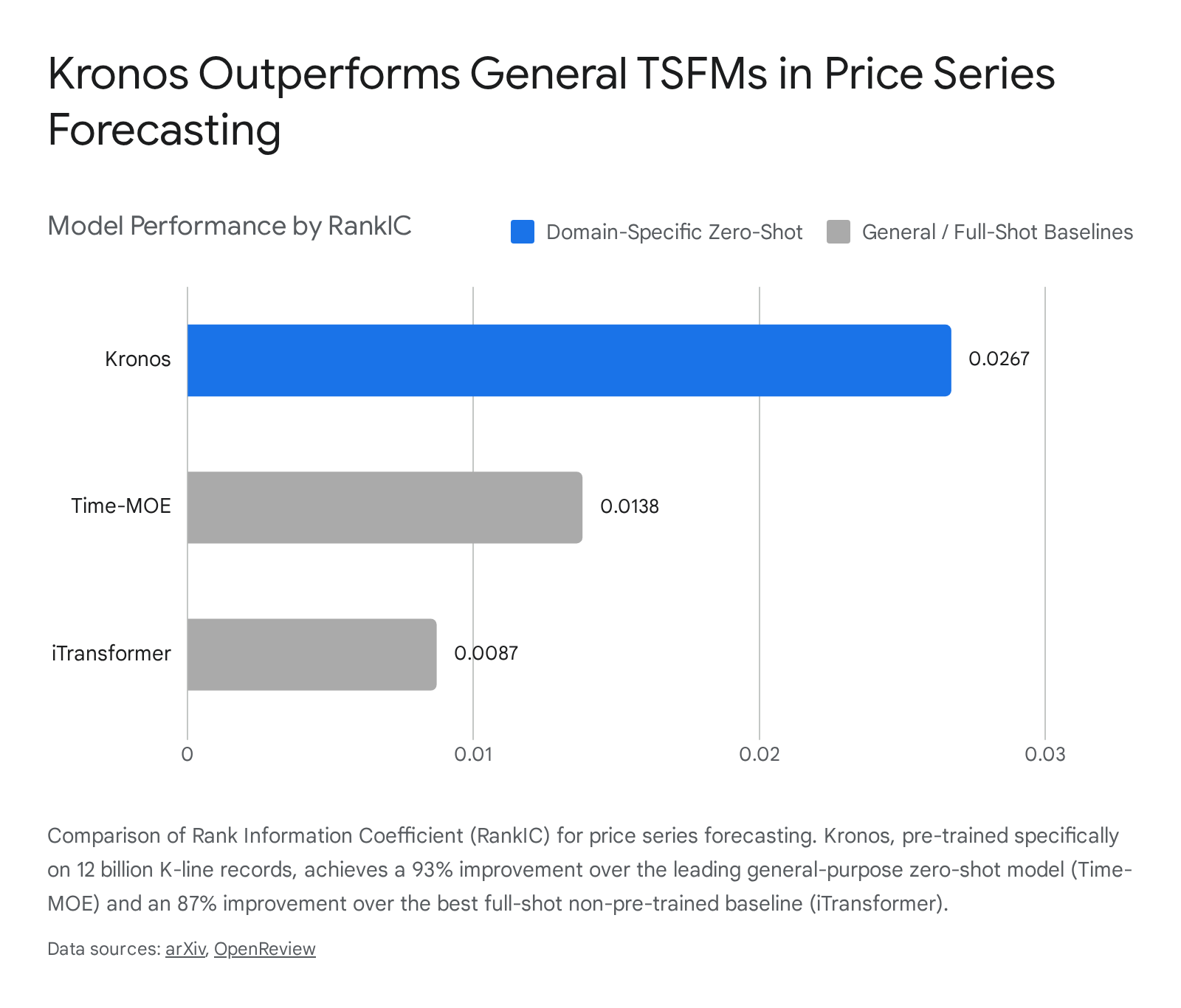
In zero-shot evaluation settings, Kronos establishes state-of-the-art benchmarks across multiple quantitative tasks. On standard price series forecasting tasks, Kronos achieves an average Rank Information Coefficient (RankIC) of 0.0267, representing a 93% improvement over the leading zero-shot general TSFM (Time-MOE, RankIC 0.0138) and an 87% gain over the most robust full-shot, dataset-specific baseline (iTransformer, RankIC 0.0087) 30.
In volatility forecasting, Kronos achieves an average Mean Absolute Error (MAE) of 0.0370 and an $R^2$ of 0.2624, outperforming traditional econometric models like GARCH 30.
Beyond point forecasting, Kronos demonstrates powerful generative fidelity. When tasked with generating synthetic K-line sequences, it outperforms standard generative architectures like TimeGAN, TimeVAE, and DiffusionTS in both discriminative scoring and Train-on-Synthetic, Test-on-Real protocols 30. This validates its capacity to deeply internalize temporal autocorrelation and cross-variable dependencies without deterministic rigidity.
Transferability Across Geographic Markets and Asset Classes
An ongoing area of inquiry is the extent to which self-supervised representations trained on one asset class or geographic region can transfer to others 32. Given the computational expense of pre-training models with billions of parameters, the capacity for inductive transfer learning and parameter transfer is crucial for the deployment of foundation models across diverse domains such as equities, commodities, and foreign exchange (FX) 3233.
Developed versus Emerging Market Dynamics
Machine learning techniques have demonstrated divergent predictive capabilities across different global equity markets. Classical Efficient Market Hypothesis (EMH) frameworks postulate that highly developed, liquid markets possess superior informational efficiency, rendering asset returns largely unpredictable, while emerging markets (EMs) harbor structural inefficiencies that algorithmic models can exploit 4334. Extensive empirical tests support this to an extent: machine learning and non-linear forecasting models frequently generate superior out-of-sample risk-adjusted returns when applied to emerging market equities compared to linear regressions 3445.
Crucially, representations learned solely from developed market data maintain a high degree of predictive power when transferred to emerging markets, predicting EM stock returns nearly as effectively as models trained natively on EM data 45. This transferability implies that the fundamental economic relationships connecting firm characteristics, technical indicators, and future stock returns are deeply conserved globally 45.
However, conflicting empirical evidence introduces a paradox regarding absolute predictability: rigorous cross-validation studies rolling across the 21st century indicate that emerging markets sometimes yield systematically higher absolute forecasting errors than developed markets 43. This suggests that while EMs suffer from persistent mispricing and limits to arbitrage that algorithms can exploit, they are simultaneously subject to higher underlying systemic volatility and noise, making exact point forecasting structurally more difficult than in developed markets 4346.
Reinforcement Learning and Multimodal Meta-Learning
To adapt representations across asset classes that experience extreme regime shifts, such as cryptocurrencies, researchers have integrated self-supervised learning with reinforcement learning (RL) and Large Language Models. The Meta-RL-Crypto framework establishes a triple-loop learning process in which a single LLM acts interchangeably as an Actor, Judge, and Meta-judge 28. The Actor processes on-chain metrics, technical indicators, and unstructured news sentiment to generate return forecasts 28. The Judge evaluates these forecasts using a multi-objective reward vector that optimizes for absolute returns, Sharpe ratio, and drawdown control, effectively mitigating the overfitting associated with optimizing for a single metric 28. This continuous refinement allows the trading policy to maintain robustness despite frequent market regime shifts, showcasing how self-supervised preference signals can adapt learned representations to highly volatile alternative asset classes.
Structural Validity and Evaluation Integrity
The rapid deployment of representation learning and Large Language Models in quantitative finance has exposed critical flaws in traditional evaluation methodologies. While papers routinely report exceptional backtested performance, these metrics are frequently invalidated by methodological errors inherent to financial data processing 4735.
A comprehensive review of recent literature highlights "look-ahead bias" as the most pervasive and dangerous methodological flaw in training financial models 4736. Look-ahead bias occurs when a model inadvertently incorporates information from the future to predict past events. This is exceptionally difficult to control in foundation models and LLMs pre-trained on massive, temporally indiscriminate web corpora 4737. For instance, an LLM evaluating historical sentiment on a 2018 corporate filing may implicitly leverage its pre-trained knowledge of that company's 2020 bankruptcy, artificially inflating the strategy's predictive accuracy and rendering the backtest economically meaningless 37.
Point-in-Time Temporal Sanitation
To achieve structural validity, researchers must enforce strict temporal sanitation. One direct solution is the development of chronologically constrained architectures, such as the TimeMachineGPT (TiMaGPT) series of models 3738. TiMaGPT models are explicitly designed to be non-prognosticative; they are pre-trained exclusively on text published prior to specified cutoff dates 3738.
By ensuring the underlying language embeddings are entirely devoid of future factual associations and evolving linguistic shifts, these point-in-time models allow researchers to fuse unstructured text with time series data without contaminating the historical simulation 3739. Ensuring chronological integrity guarantees that validation metrics - such as the Sharpe ratio, maximum drawdown, and Information Coefficient - reflect genuine predictive capacity rather than latent data leakage 3640.
Mitigating Survivorship and Objective Bias
Beyond look-ahead bias, robust evaluation frameworks demand the integration of realistic implementation constraints to combat survivorship bias and objective bias 47. Survivorship bias occurs when the training or evaluation universe is restricted only to entities that survived to the end of the sample period, implicitly excluding delisted or bankrupt firms and creating systematic model preferences for large-cap assets 47. Dynamic universe construction is necessary to ensure the model evaluates the exact asset landscape available at the time of the prediction 47.
Furthermore, standard statistical loss functions (e.g., Mean Squared Error) often suffer from objective bias, as they misalign with actual economic utility. To address this, the Finance-Informed Neural Network (FINN) embeds no-arbitrage principles derived from dynamic replication directly into the training objective 54. FINN utilizes a self-supervised learning methodology where option prices and sensitivities are learned by minimizing economically meaningful hedging errors rather than statistical pricing errors 54. By prioritizing replication consistency, the model generalizes effectively from simple diffusion environments to stochastic volatility regimes, bridging the gap between data-driven machine learning and theory-driven quantitative finance 54.
Conclusions
Self-supervised and representation learning architectures have fundamentally altered the landscape of financial time series modeling. By shifting away from rigid statistical assumptions and moving toward data-driven, pre-trained paradigms, researchers are uniquely positioned to address the non-stationarity, high noise levels, and heavy-tailed distributions that characterize financial data.
While temporal contrastive learning effectively captures cross-sectional equity relationships and global dependencies, its high computational overhead and reliance on potentially distorting augmentations have driven a transition toward masked autoencoding and hybrid spatiotemporal transformers. Techniques such as wavelet tokenization offer elegant solutions to non-stationarity, allowing models to operate on time-localized multiscale frequencies without destroying cointegration. Moreover, the emergence of domain-specific foundation models like Kronos demonstrates that pre-training on bespoke financial structures - such as billions of aggregated K-line sequences - yields predictive and generative performance that significantly eclipses both classical econometrics and general-purpose artificial intelligence models.
However, the realization of these theoretical gains in live deployment remains contingent upon rigorous methodological hygiene. As models grow increasingly complex and reliant on external multimodal corpora, practitioners must enforce strict point-in-time training constraints and finance-informed learning objectives. Only by eradicating look-ahead bias, survivorship bias, and objective misalignment can the field ensure that backtested alpha represents a genuine, deployable market edge rather than an artifact of data leakage.