Transformer Architectures for Financial Time Series Forecasting
Introduction
The application of deep learning to financial time series forecasting resides at the intersection of extreme computational capability and profound epistemological uncertainty. Unlike domains such as natural language processing or computer vision, where the underlying data contains stable, high-signal semantic structures, financial markets are characterized by non-stationarity, heteroskedasticity, volatility clustering, and an exceptionally low signal-to-noise ratio 11. Historically, autoregressive statistical models such as ARIMA and GARCH, alongside classical machine learning ensembles like Random Forests and Gradient Boosting, dominated the field due to their interpretability, parameter efficiency, and inherent resilience against overfitting in volatile regimes 245.
However, the introduction of the Transformer architecture heralded a paradigm shift across sequence modeling disciplines. Originally designed to capture long-range dependencies in natural language via multi-head self-attention mechanisms, Transformers were rapidly adapted for time series forecasting. Early iterations demonstrated theoretical promise by abandoning strict recurrent processing in favor of global attention mechanisms. Yet, by early 2023, the academic community faced a severe reckoning regarding the empirical utility of these complex models. The foundational critique raised by the "DLinear" framework questioned whether the immense computational overhead of Transformers provided any tangible predictive benefit over simple linear projections in continuous time series applications 37.
This comprehensive analysis investigates the evolution of Transformer architectures tailored specifically for financial time series, with a concentrated focus on the pivotal 2023 - 2024 developmental window. By deconstructing the structural mechanisms of the Temporal Fusion Transformer (TFT), PatchTST, and the newer iTransformer, this report evaluates their theoretical underpinnings and empirical efficacy. Furthermore, this analysis dismantles the pervasive misconception that success on standard forecasting benchmarks, such as weather and traffic datasets, equates to viability in quantitative finance. Presenting a rigorous empirical comparison across geographically diverse financial datasets, the report critically assesses the practical limitations of these architectures, balancing computational overhead against the ultimate objective of quantitative finance: robust risk-adjusted accuracy and alpha generation.
The Benchmarking Fallacy: Epistemological Differences in Time Series Data
A structural flaw in the literature surrounding deep learning for time series forecasting has been the over-reliance on standard benchmarking datasets, such as the Electricity Transformer Temperature (ETT), Weather, and Traffic datasets 84. The assumption that architectural supremacy on these benchmarks translates to financial forecasting is a fundamental misconception that has historically polluted model selection in quantitative finance 10.
Standard benchmarking datasets represent fundamentally deterministic physical systems or highly regular human-driven macro-systems. Traffic flows exhibit strict diurnal and weekly periodicities governed by human commuting behaviors; weather and electricity consumption patterns are anchored by thermodynamic cycles, seasonal trends, and predictable calendar events 8115. In these environments, the signal-to-noise ratio is exceedingly high, and the underlying data generating process is relatively stationary over the standard evaluation windows 311. Models that excel on these datasets generally do so by efficiently memorizing and extrapolating these prominent seasonal patterns and strong auto-correlations 13.
Conversely, financial time series data - encompassing equity indices, foreign exchange rates, and options implied volatility - are governed by the Efficient Market Hypothesis. This financial principle suggests that asset prices reflect all available market information, rendering future price movements akin to a random walk driven by unforeseen information arrivals 10. Consequently, financial data is notoriously noisy, exhibiting shifting means and variances over time, and is subject to abrupt, violent regime shifts driven by macroeconomic shocks, geopolitical events, and shifting monetary policies 1415. When applied to these environments, models overly optimized for periodic, stationary data frequently suffer from catastrophic performance degradation 1.
The misconception of architectural superiority is further exacerbated by the widespread use of misaligned evaluation metrics. In standard forecasting tasks, Mean Squared Error (MSE) and Mean Absolute Error (MAE) are the accepted performance proxies 4. However, in the context of financial markets, MSE is a highly deceptive metric. A naive forecasting model that conservatively predicts the historical mean or assumes zero price change can achieve a statistically low MSE while possessing zero directional accuracy, thereby generating negative economic returns in a live trading environment 416. Empirical evaluations frequently reveal that directional accuracy for complex models on financial datasets hovers around 50.08%, essentially indistinguishable from a random coin toss 6.
In quantitative finance, a model's true utility is measured by its capacity to generate risk-adjusted returns, most commonly quantified by the Sharpe Ratio, Maximum Drawdown, and Information Ratio 17. A model presenting a marginally higher MSE might actually prove superior if its errors are safely concentrated in low-volatility periods, provided it accurately captures the direction, magnitude, and timing of tail-risk events and volatility breakouts. Thus, evaluating Transformers purely on ETT or Traffic benchmarks provides virtually zero evidence of their efficacy in a live financial forecasting or algorithmic trading environment 619.
The DLinear Critique: A Crisis of Architectural Complexity
The underlying tension between complex neural architectures and the noisy reality of continuous time series data culminated in a highly influential 2023 publication at the AAAI conference by Zeng et al., titled "Are Transformers Effective for Time Series Forecasting?" 320. This paper delivered a shock to the forecasting community by exposing severe vulnerabilities in the prevailing Transformer-based methodologies.
Zeng et al. demonstrated that an "embarrassingly simple" architecture named DLinear consistently outperformed highly complex, state-of-the-art Transformers - including the Informer and Autoformer - by significant margins on standard long-term forecasting benchmarks 37. The DLinear architecture operates by decomposing a continuous time series into distinct trend and seasonal remainder components. It then applies a single-layer linear network to independently model each component for the forecasting task, entirely bypassing multi-layer perceptrons, recurrent layers, and attention mechanisms 36.
The theoretical thrust of the DLinear critique focused on two fundamental failures of early Transformer adaptations. First, the self-attention mechanism is inherently permutation-invariant, meaning it processes sequences as unordered sets 320. While positional encoding schemes attempt to artificially inject temporal order into the tokens, attention mechanisms often fail to preserve the strict, continuous sequentiality that defines a time series, resulting in severe temporal information loss 320. Second, the massive parameter counts inherent to deep Transformer networks render them highly prone to overfitting, particularly in environments with low signal-to-noise ratios. By contrast, DLinear's inductive bias - the strict assumption that future temporal states are simply linear projections of decomposed past states - acted as a powerful structural regularizer that effectively prevented the model from memorizing stochastic noise 6.
The findings presented at AAAI 2023 forced the machine learning community to acknowledge that the higher long-term forecasting accuracy previously claimed by Transformer solutions was largely an artifact of their non-autoregressive direct multi-step forecasting strategies, rather than an inherent superiority of the temporal relation extraction capabilities of the self-attention mechanism itself 3.
The 2023 - 2024 Renaissance: Structural Rebuttals to DLinear
The DLinear critique did not spell the end of attention-based forecasting; rather, it initiated a period of intense structural refinement. If mapping individual time steps directly to tokens - a process known as point-wise tokenization - destroyed local temporal semantics and amplified noise, the architecture required fundamental revision. The developments presented at major conferences throughout 2023 and 2024 provided a robust rebuttal to the linear paradigm. Researchers demonstrated that Transformers remain highly effective and can substantially outperform simple linear projections when their tokenization strategies and attention scopes are properly aligned with the mathematical realities of continuous time series data 8229.
This architectural renaissance materialized primarily through the introduction of novel models like PatchTST and iTransformer, which proved that the failure highlighted by the DLinear critique was a failure of data representation rather than a flaw in the self-attention mechanism itself 910.
When Transformers were equipped with sophisticated inductive biases specifically designed for continuous series - such as patch-based segmentation or cross-dimensional inversion - they decisively outperformed linear models in both standard benchmarks and complex, high-noise financial environments 9.
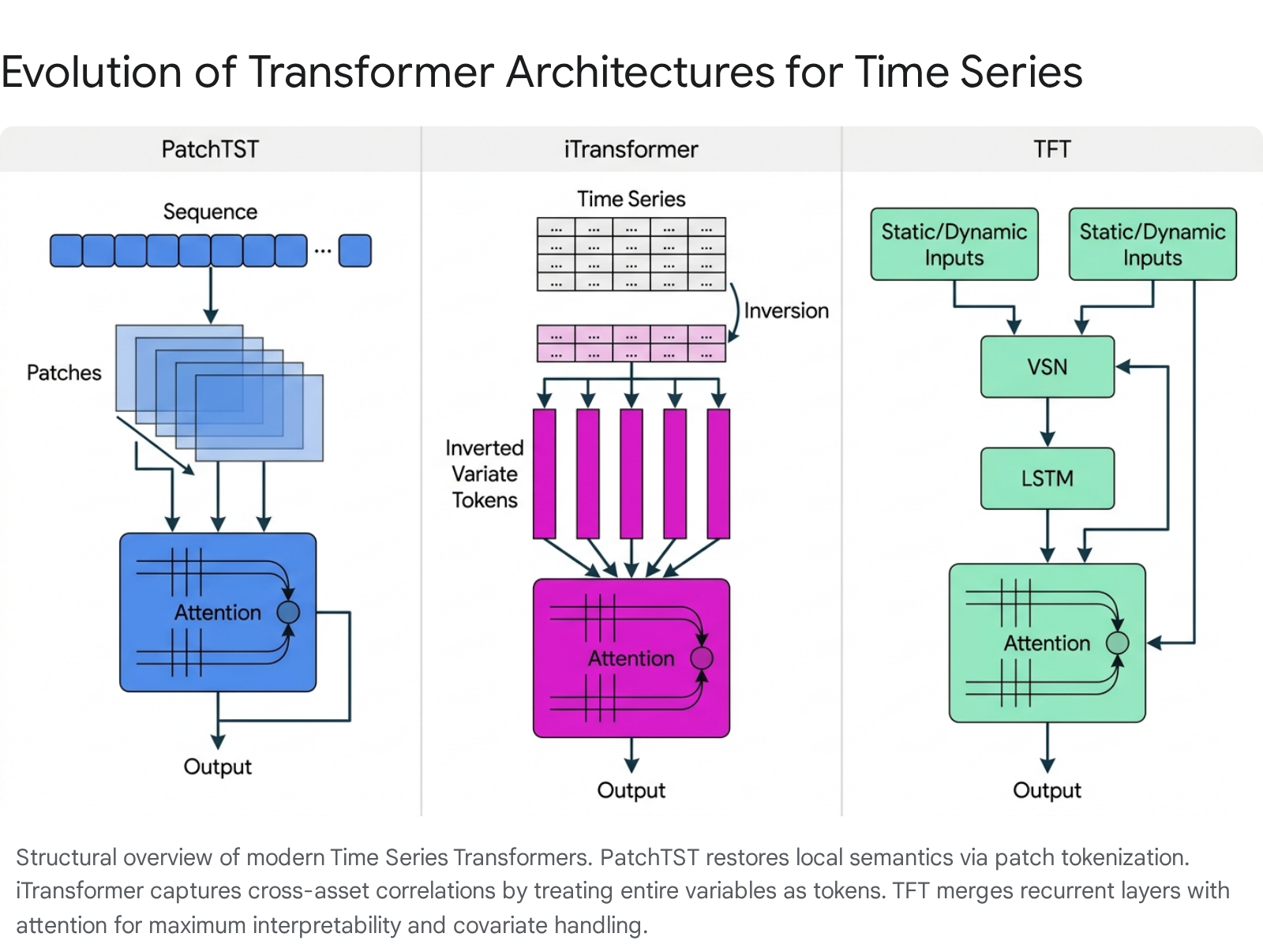
Deconstructing Core Mechanisms of the Financial Transformer
To understand the current state-of-the-art in financial forecasting, it is necessary to deconstruct the specific structural mechanics of the leading Transformer variants: Informer, PatchTST, iTransformer, and the Temporal Fusion Transformer (TFT). Each model represents a distinct philosophical approach to handling temporal sequence data.
Informer: The Efficiency Precursor
Introduced as an outstanding paper at AAAI 2021, the Informer architecture sought to resolve the fundamental $\mathcal{O}(L^2)$ quadratic memory and time complexity of the vanilla Transformer's self-attention mechanism, a bottleneck that severely limited the length of historical look-back windows 725. The Informer utilizes a proprietary ProbSparse self-attention mechanism, which relies on measuring the Kullback-Leibler divergence between query distributions to identify only the most "active" or dominant queries. By computing attention exclusively for this active subset and ignoring the rest, the model successfully reduces computational complexity to $\mathcal{O}(L \log L)$ 71127. Additionally, it employs a generative-style decoder to output multi-step predictions simultaneously, drastically reducing the error accumulation typically associated with step-by-step autoregressive decoding 7.
Despite its computational elegance, the Informer's application in financial contexts is frequently compromised by its own efficiency mechanism. Financial data is highly irregular and characterized by sparse but extremely impactful events, such as sudden volatility shocks or flash crashes. The ProbSparse mechanism, by intentionally discarding "lazy" or seemingly inactive queries to save compute, can inadvertently filter out these critical, non-periodic market signals. This results in degraded predictive performance and dangerous blind spots when operating in non-stationary market regimes where anomaly detection is paramount 25.
PatchTST: Restoring Local Semantics and Channel Independence
Presented at ICLR 2023, PatchTST (Patch Time Series Transformer) revolutionized the initial tokenization step by borrowing concepts from Vision Transformers 710. Instead of treating every individual time step as an isolated token, PatchTST segments the continuous univariate time series into distinct, overlapping patches, embedding each multi-step patch as a single token 7. This architectural decision yields three profound benefits for time series modeling: it dramatically reduces the effective sequence length fed into the attention mechanism, it preserves essential local temporal semantics and short-term price action dynamics within the boundaries of each patch, and it allows the model to analyze a significantly longer historical context given the same computational constraints 910.
Crucially for quantitative finance, PatchTST adopts a framework of strict channel independence. It treats multivariate time series as completely independent univariate channels, processing each financial asset or feature separately through the identical shared Transformer backbone 928. In the highly stochastic realm of financial markets, attempting to densely model cross-channel relationships frequently leads to catastrophic overfitting, as the network learns to rely on spurious correlations. Channel independence acts as an aggressive implicit regularizer, forcing the model to learn fundamental temporal patterns and preventing it from hallucinating non-existent relationships between unrelated market assets from limited historical data 9.
iTransformer: Inverting the Dimensional Paradigm
While PatchTST relies heavily on channel independence, the iTransformer, introduced at ICLR 2024, takes the diametrically opposite approach. It is explicitly designed to capture complex multivariate correlations, an absolute necessity in advanced quantitative finance where structural lead-lag relationships between asset classes and macroeconomic indicators are the primary source of alpha 92912.
The iTransformer achieves this by entirely inverting the traditional tokenization dimension. Instead of creating a temporal token that fuses multiple variables at a single, isolated time step, an iTransformer token represents the entire historical sequence of a single, distinct variable 1213. Self-attention is then applied strictly across these variate tokens rather than across time steps. For instance, the attention mechanism calculates the relationship between the entire historical vector of the S&P 500 and the entire historical vector of the VIX volatility index. Subsequently, the feed-forward network is applied independently to each variate token to learn nonlinear, series-global temporal representations 912. This dimension inversion empowers the model to explicitly map cross-asset correlations while avoiding the destruction of temporal order, making it an exceptionally potent architecture for broad portfolio-level forecasting and the integration of diverse alternative data streams 131415.
Temporal Fusion Transformer (TFT): The Institutional Standard
Developed by researchers at Google Cloud in 2021, the Temporal Fusion Transformer remains arguably the most robust and practically deployed deep learning model in institutional finance. Its longevity is attributed to its unique capacity for handling highly heterogeneous financial data and its built-in, attention-driven interpretability 928.
The TFT is a sophisticated hybrid architecture that integrates Long Short-Term Memory networks for processing localized sequential temporal dynamics with multi-head attention mechanisms designed to capture complex global dependencies 128. Financial forecasting models rely heavily on the integration of external covariates, and TFT uniquely compartmentalizes these inputs into distinct channels: static metadata such as an asset's sector or geographic region, known future inputs like scheduled central bank announcements or dividend dates, and observed past inputs including historical price and trading volume 916.
To manage this complex data influx, TFT employs Variable Selection Networks to dynamically weigh and filter the importance of different predictive features at each specific time step, effectively muting irrelevant noise. It also utilizes Gated Residual Networks to skip unnecessary non-linear processing for simpler data segments 281617. Furthermore, unlike standard point-forecast models, the TFT outputs a quantile regression, providing sophisticated prediction intervals. This allows quantitative risk managers to actively model uncertainty and quantify tail risks, which is vital for dynamic portfolio sizing and risk-parity strategies 2817.
Empirical Benchmarks: Geographically Diverse Financial Datasets
To evaluate these advanced architectures objectively, the analysis must move beyond the misleading domains of weather forecasting and traffic prediction. Rigorous evaluation requires analyzing model performance strictly on geographically and structurally diverse financial datasets. Recent open-source benchmarking suites tailored for finance, such as QuantBench, the Global Stock Market Indices (GSMI) collection, and various deep financial benchmark repositories, provide the necessary adversarial testing grounds 71436.
Geographic Diversity and Market Characteristics
Financial models must demonstrate robustness across highly varied market microstructures, regulatory regimes, and geopolitical risk exposures. Recent benchmarks systematically evaluate models across distinct global environments: * United States Markets (S&P 500, NASDAQ, Dow Jones): These indices represent the world's deepest liquidity pools, characterized by massive institutional algorithmic trading participation and heavy concentration in the technology and semiconductor sectors 1437. * European Markets (FTSE 100, DAX, CAC 40): European indices frequently exhibit vastly different volatility profiles compared to the US, driven by heavier exposures to traditional industrials, financial institutions, and acute vulnerability to regional geopolitical energy shocks 1437. * Asia-Pacific Markets (CSI 300, Hang Seng, Nikkei 225): These markets present entirely unique modeling challenges. The Chinese CSI 300 operates under distinct regulatory interventions with a high proportion of retail trading volume, altering the standard momentum dynamics. Meanwhile, the Japanese Nikkei often exhibits independent macroeconomic cycles tied to specific domestic monetary policies 161437. * Foreign Exchange and Cryptocurrency: Asset classes like the EUR/USD pairing and Bitcoin Futures provide 24-hour, high-frequency continuous data streams that lack the traditional daily closing auction structures of equity markets 614.
Empirical Performance Summary
When evaluating modern Transformer architectures exclusively on these financial datasets, standard error metrics (RMSE) alongside core financial performance metrics (Sharpe Ratio, Directional Accuracy) reveal distinct operational hierarchies 167.
| Model Architecture | Forex (Mean RMSE) | Equity Indices (Mean RMSE) | Aggregate Sharpe Ratio (2010 - 2025) | Directional Accuracy | Core Financial Inductive Bias |
|---|---|---|---|---|---|
| DLinear | 0.1279 | 123.80 | Low / Highly Variable | ~50.08% | Captures strong mean-reversion efficiently but fails completely during sudden structural regime shifts. 16 |
| Vanilla LSTM | N/A | N/A | 1.48 | ~51.00% | Processes sequential non-linearities effectively but suffers from severe memory bottlenecks over long horizons. 1 |
| PatchTST | 0.1108 | 111.71 | 0.76 (High Variance) | ~50.08% | Channel independence acts as a powerful implicit regularizer against learning spurious cross-asset correlations. 16 |
| iTransformer | 0.1136 | 113.72 | Moderate | ~50.08% | Variate tokens map macro cross-asset dependencies, ideal when inter-asset relationships are fundamentally sound. 61314 |
| TFT | N/A | N/A | 2.20 - 2.27 | ~53.00% | Variable Selection Networks actively filter market noise; adaptive gating mechanisms adjust to volatility clusters. 119 |
| LPatchTST (LSTM + PatchTST) | N/A | N/A | 2.31 - 2.32 | ~54.00% | The LSTM acts as an initial temporal denoiser prior to patch attention, yielding exceptionally high tail-risk robustness. 1 |
Analysis of Empirical Results
The empirical data synthesized from recent non-peer-reviewed preprints and comprehensive benchmark studies exposes several critical insights regarding model viability. First, while the simple DLinear model appears highly competitive on an absolute RMSE scale for certain mean-reverting Forex pairs, its actual economic utility, as measured by the Sharpe ratio, is surprisingly poor. DLinear fundamentally lacks the dynamic state representation required to survive abrupt volatility regime shifts - such as the sudden market crash triggered by the 2020 pandemic or the prolonged inflationary shocks of 2022 119.
Second, the pure patching approach utilized by PatchTST achieves excellent RMSE scores by aggressively smoothing short-term noise. However, it exhibits a dangerously high sensitivity to specific market years, resulting in a merely moderate long-term aggregate Sharpe ratio of 0.76 1. To resolve this, researchers introduced hybrid structures. When an LSTM layer is positioned as a channel-wise temporal denoiser prior to the PatchTST architecture - creating the hybrid LPatchTST - the model achieves a consistently elite Sharpe ratio of 2.31 to 2.32. This hybrid model demonstrates vastly superior downside-adjusted robustness, offering critical control over maximum portfolio drawdowns 1.
Third, the iTransformer performs admirably in controlled scenarios where cross-variable relationships are genuine, stable, and economically sound - such as predicting a major index based on the weighted behaviors of its direct constituent stocks. However, in broader datasets where input variables are only loosely correlated or entirely independent, its vast multivariate attention mechanism becomes a liability. The model tends to overfit to statistical noise, yielding sub-optimal Sharpe ratios when directly compared to heavily regularized, channel-independent models 738.
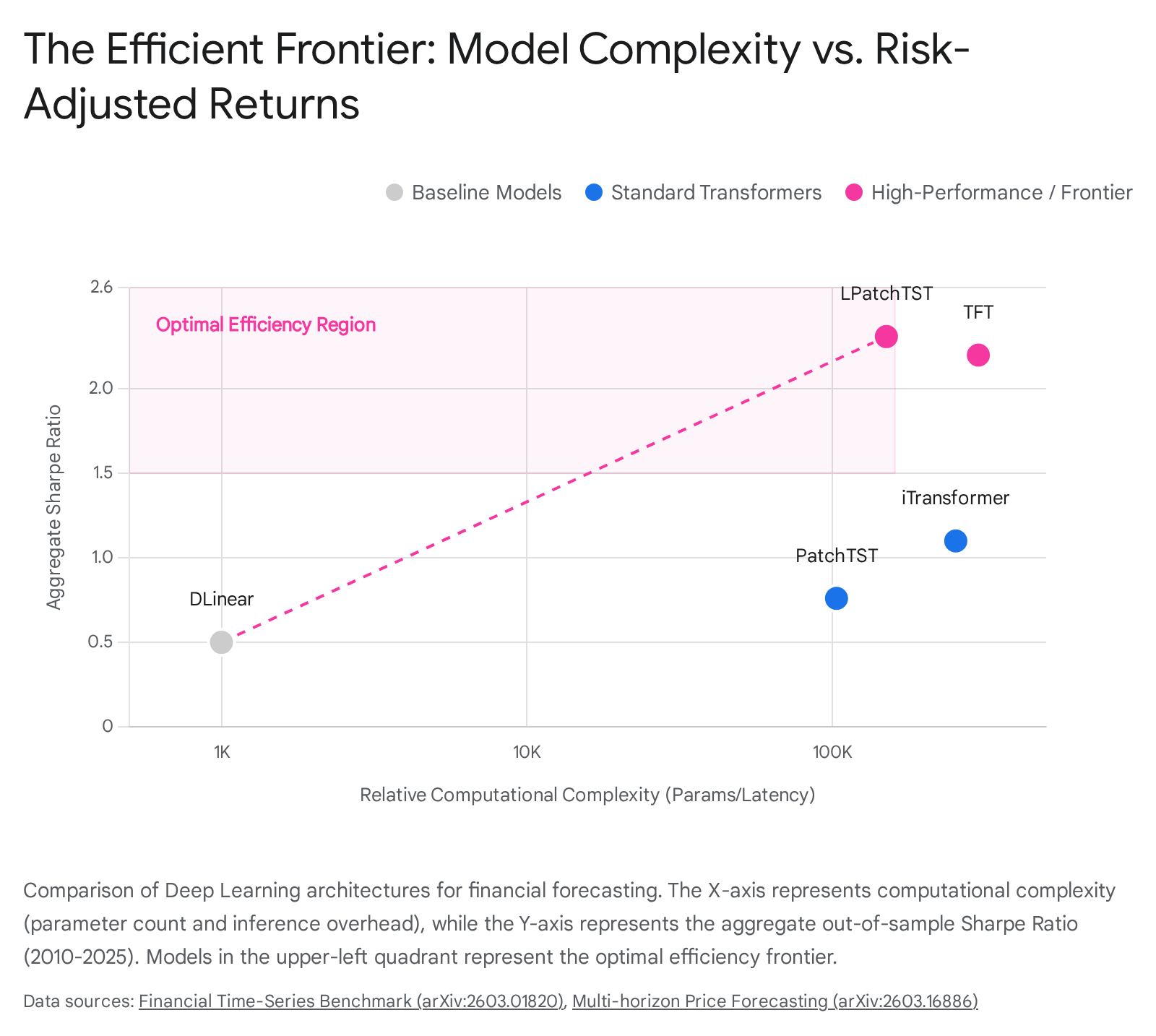
Evaluating Practical Limitations: Computational Overhead vs. Accuracy Gains
The theoretical transition from pristine academic benchmarking to deployment in high-frequency or high-dimensional portfolio trading necessitates a rigorous evaluation of computational overhead. The central operational question for financial practitioners remains whether the hypothetical alpha generated by massive Transformers justifies the inherent execution latency, extensive training costs, and heavy infrastructural requirements 3940.
The architectural simplicity of the DLinear baseline translates to extreme computational efficiency. DLinear operates on the absolute edge of the Pareto frontier regarding execution speed, achieving mid-tier performance utilizing only approximately 1,000 trainable parameters 6. In high-frequency trading environments - where market microstructure dictates that microsecond latency determines the success or failure of execution - such lightweight linear architectures remain highly attractive and often indispensable.
In stark contrast, modern Transformer architectures are computationally massive. PatchTST typically operates with approximately 103,000 parameters, scaling up to handle complex patching mechanics. The iTransformer is significantly heavier, scaling up to 253,000 parameters depending heavily on the dimensionality of the variates being analyzed 6. While the patch-based segmentation in PatchTST successfully reduces the burdensome $\mathcal{O}(L^2)$ complexity of standard self-attention by shrinking the token sequence length, the iTransformer's inference time frequently increases because its unique variate-wise embedding design forces the model to process the entire temporal sequence simultaneously. Consequently, reducing the number of temporal tokens in the iTransformer framework does not proportionally reduce the computational cost, rendering it computationally expensive for multivariate systems with hundreds of distinct assets 2940.
The Temporal Fusion Transformer sits at the higher end of the latency spectrum due to its intricate hybrid design. Recent empirical hardware benchmarks indicate that while modern lightweight architectures like TimeMixer can achieve rapid batch inference latencies of approximately 9.1 milliseconds, the TFT can suffer from execution latencies of up to 112 milliseconds. This delay is an unavoidable byproduct of its complex recurrent LSTM layers, sequential processing constraints, and heavy multi-head attention blocks 41.
For ultra-low latency market-making and algorithmic arbitrage, heavy Transformer networks are currently entirely ill-suited due to this persistent inference overhead 3940. However, for medium-to-low frequency strategies - such as daily or weekly portfolio rebalancing, complex options pricing models, or institutional risk management - this computational overhead is entirely justified by the subsequent accuracy gains and downside tail-risk protection.
Sophisticated research evaluating model robustness against real-world transaction costs - a critical factor universally omitted in standard machine learning evaluation metrics - reveals that advanced sequence models possess substantial economic advantages. The xLSTM and hybrid LPatchTST architectures demonstrate the largest breakeven transaction cost buffers in empirical testing 1. This vital metric indicates that their predictive signals are sufficiently strong, and their portfolio turnover sufficiently low, to generate net-positive absolute returns even when subjected to realistic bid-ask spreads, broker commissions, and market slippage. Conversely, overly complex vanilla Transformers that fail to dynamically adjust to changing market correlations, or those that frequently over-trade based on stochastic noise, witness their theoretical backtested alpha rapidly eradicated by trading frictions 1. Finally, the TFT's unique ability to output probabilistic predictive quantiles offsets its heavy computational cost by allowing portfolio managers to mathematically optimize position sizing using frameworks akin to the Kelly criterion. This risk-aware sizing achieves a superior risk-to-reward ratio that deterministic point-forecast models simply cannot replicate 2817.
Conclusion
The landscape of financial time series forecasting underwent a rigorous and necessary purification between the turbulent years of 2023 and 2024. The DLinear critique successfully shattered the prevailing illusion that blindly transplanting NLP-style Transformer architectures to continuous time series would automatically yield superior results. It exposed the fundamental flaw of point-wise temporal tokenization, proving that treating sequential financial data as unordered tokens merely amplified stochastic noise and destroyed vital local semantics.
However, the subsequent rapid evolution of sophisticated models like PatchTST, the iTransformer, and complex hybrid systems such as the LPatchTST decisively proved that the core Transformer attention mechanism remains profoundly powerful when meticulously coupled with domain-appropriate inductive biases. By intelligently segmenting data into patches to preserve local semantics, completely inverting tensor dimensions to map cross-asset dependencies, and integrating advanced gating networks to aggressively filter the pervasive noise inherent to financial markets, these modern architectures have successfully reclaimed the empirical state-of-the-art.
Crucially, the success of these advanced models cannot be validated on standard deterministic datasets like traffic volume or weather patterns. True financial markets demand resilient models that can survive structural non-stationarity and violent macroeconomic regime shifts. While the massive computational overhead of models like the Temporal Fusion Transformer or the iTransformer currently precludes them from ultra-high-frequency trading applications, their ability to generate highly robust, risk-adjusted returns and dynamic, probabilistic uncertainty estimations makes them indispensable tools for modern quantitative portfolio management. As the field progresses, the optimal frontier will likely be discovered not in infinitely scaling model parameter counts, but in meticulously refining the specific architectural inductive biases that allow neural networks to successfully separate enduring market signals from stochastic financial noise.