Architecture and Mechanics of Transformer Models 2026
The introduction of the self-attention mechanism by Vaswani et al. in 2017 marked a permanent paradigm shift in artificial intelligence, fundamentally reorganizing the computational approach to sequence modeling 123. By discarding the temporal recurrence of Long Short-Term Memory (LSTM) networks and the rigidly localized receptive fields of Convolutional Neural Networks (CNNs), the Transformer established a framework where sequence processing relies entirely on massively parallel associative matching. The ramifications of this shift are profound; by 2026, the architecture has transcended its origins in natural language processing (NLP) to dominate computer vision, genomics, and multi-stream real-time continuous audio generation 323.
The defining architectural advantage of the Transformer is its decoupling of sequence length from temporal computation steps. In traditional recurrent architectures, input sequences are processed linearly, a design that imposes strict computational bottlenecks and inherently degrades the preservation of long-term memory states as the sequence extends 47. The Transformer bypasses this constraint by enabling every token in a sequence to interact directly and simultaneously with every other token through attention matrices. Recent theoretical analyses of the Transformer's loss landscape, specifically through derivations of its Hessian matrix, reveal that its optimization properties differ radically from classical multi-layer perceptrons (MLPs) and CNNs. The Transformer's highly non-linear dependencies on data and weight matrices necessitate specific optimization choices, such as adaptive optimizers, layer normalization, and learning rate warmup, to navigate its uniquely non-convex yet smooth optimization landscape 8. As the parameter counts of Large Language Models (LLMs) have scaled from the millions into the trillions, this core architecture has undergone profound structural optimization 95. This report provides an exhaustive analysis of the mathematical mechanics, architectural archetypes, mechanistic interpretability, and global structural innovations defining state-of-the-art Transformer models.
The Mathematical Engine: Query-Key-Value (QKV) Operations
At the epicenter of the Transformer's computational capability is the Query-Key-Value (QKV) self-attention mechanism. Unlike earlier neural mechanisms that apply static weight matrices to inputs, self-attention computes dynamic, data-dependent weights that continuously fluctuate based on the specific context of the input sequence 67.
To grasp the QKV operation conceptually without immediately resorting to linear algebra, one can employ an information retrieval analogy, or envision a gravitational system where entities exert pull based on semantic similarity. The Query acts as the current token's active search intent. When the model processes a highly ambiguous word such as the pronoun "it" in a complex sentence, the query vector functions as a broadcasting signal seeking contextual resolution, effectively asking which surrounding entities possess attributes that define its current state 467. Concurrently, every token in the sequence acts as a Key, representing the metadata or intrinsic identity of that token. A noun like "animal" broadcasts a key identifying it as an animate object capable of specific actions. The attention mechanism measures the similarity between the active Query and all available Keys. When a Query strongly matches a Key - indicating semantic relevance - the system retrieves the Value vector associated with that Key. The Value represents the actual underlying meaning or payload of the token 4613. Through this dynamic matching, the isolated, static embedding of a word "bakes in" the nuances of its surrounding context, resolving ambiguities by absorbing the representations of relevant nearby tokens 6.
In practice, this conceptual framework is executed via a highly parallelized series of matrix multiplications. For a given input sequence matrix, which we denote as $X$ where each row constitutes a token embedding of dimension $d_{model}$, the network linearly projects this input into three distinct representation subspaces. This is achieved by multiplying the input matrix by three learned weight matrices, $W_Q, W_K,$ and $W_V$, generating the corresponding Query, Key, and Value matrices. These matrices map the high-dimensional input embeddings into lower-dimensional spaces, typically denoted by $d_k$ and $d_v$, that are mathematically optimized specifically for the attention calculation 6.
Once the projections are computed, the model determines how much focus each token should allocate to every other token by calculating the dot product between the Query matrix and the transposed Key matrix, yielding $Q K^T$. A higher dot product result mathematically signifies greater semantic similarity or structural relevance between a specific query and a key 614. However, as the dimensionality of the key vectors ($d_k$) scales up, these dot products can reach massive magnitudes. Large magnitude outputs would push the subsequent softmax function into regions where gradients are infinitesimally small, severely destabilizing the learning process. To counteract this phenomenon, the dot product scores are scaled down by dividing them by the square root of the key dimension, $\sqrt{d_k}$ 6.
The scaled scores are subsequently passed through a softmax function applied along the last dimension. This critical non-linear operation normalizes the raw scores into a valid probability distribution, ensuring that all attention weights for a given query strictly sum to one. The softmax operation aggressively amplifies the highest scores while driving lower scores toward zero, thereby determining exactly what percentage of attention is directed to which tokens and effectively drowning out irrelevant contextual noise 36. Finally, this normalized attention matrix is multiplied by the Value matrix $V$. Tokens that received high attention scores contribute the vast majority of their vector values to the output representation, while those with scores near zero contribute negligibly. This entire sequence is elegantly condensed into the foundational Transformer equation: $\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$ 6.
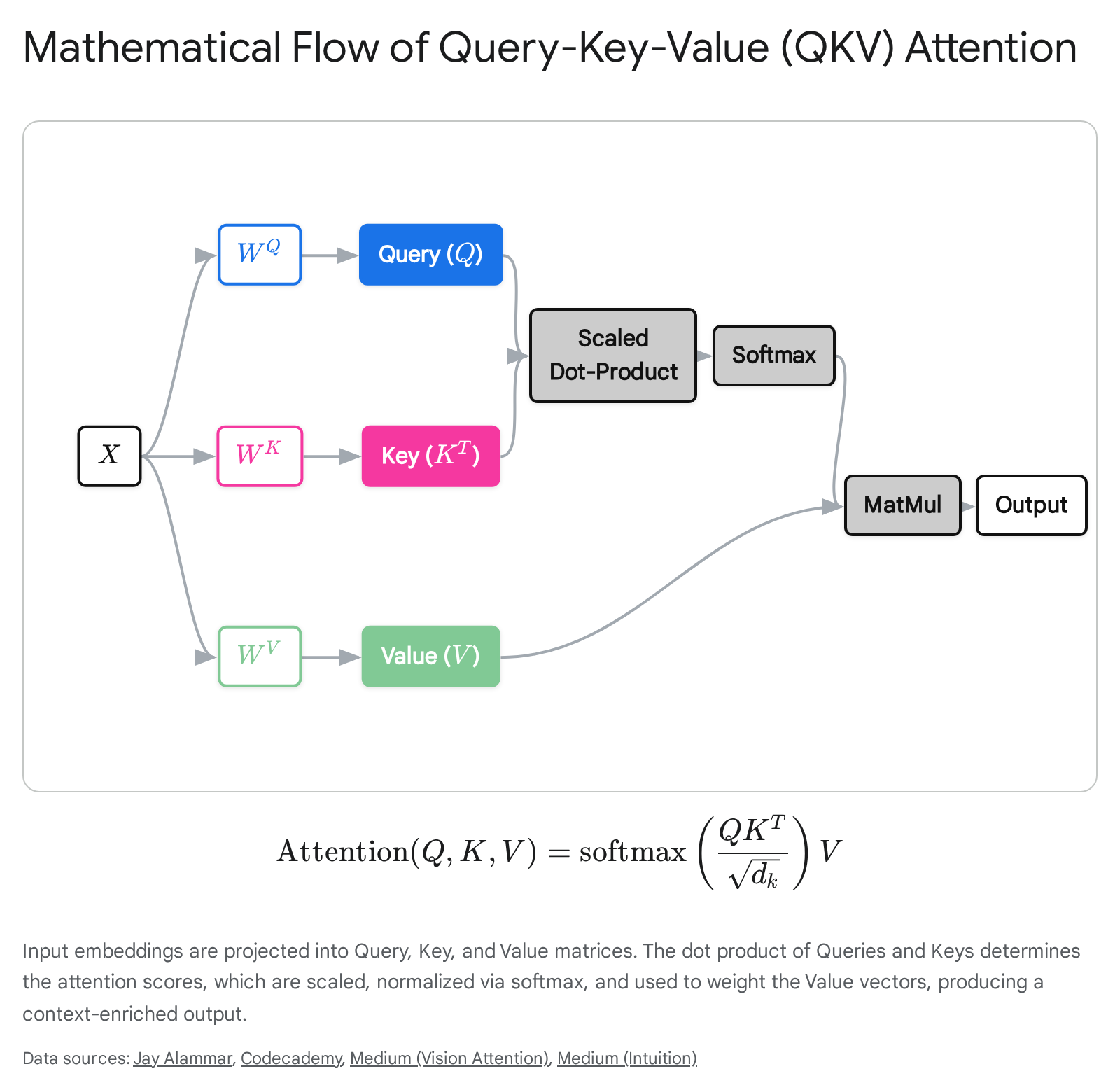
In standard Multi-Head Attention (MHA) configurations, this sequence of operations is replicated in parallel across multiple independent heads. Each head learns entirely distinct weight matrices, allowing the model to simultaneously attend to different representation subspaces. Consequently, one attention head might specialize in tracking syntactic subject-verb agreements, while another independently isolates emotional sentiment or complex coreferences, before their outputs are concatenated and linearly projected back into the main residual stream 37.
Architectural Archetypes: Encoder, Decoder, and Encoder-Decoder Models
While the mathematical core of the self-attention mechanism remains universal, the macro-arrangement of these attention blocks rigidly defines a model's downstream functionality and operational constraints. The contemporary Transformer ecosystem is broadly categorized into three dominant architectural archetypes: Encoder-only, Decoder-only, and Encoder-Decoder models. Their primary divergence lies in their approach to attention masking during sequence processing and the specific pre-training objectives they employ 8917.
Encoder-only models, epitomized by Google's BERT (Bidirectional Encoder Representations from Transformers) and its robustly optimized successors like RoBERTa, apply bidirectional self-attention mechanisms. During sequence processing, every individual token is granted mathematically unconstrained visibility into all other tokens in the sequence - both those that precede it and those that follow 810. This complete, unmasked visibility allows the network to develop profoundly deep, contextually integrated representations of language. The standard pre-training objective for such architectures is Masked Language Modeling (MLM). During this phase, a specific percentage of input tokens - traditionally around 15% - are randomly corrupted or replaced with a designated [MASK] token. The model is then penalized based on its ability to accurately predict the original corrupted token by synthesizing bidirectional contextual clues 810. Because they require the entire sequence to be present simultaneously, Encoder models are structurally incapable of generating free-form text in an iterative manner. Instead, they excel at complex natural language understanding (NLU) tasks that require holistic sentence comprehension, such as sentiment analysis, named entity recognition, and extractive question answering 5819.
Conversely, Decoder-only models, prominently featuring OpenAI's Generative Pre-trained Transformer (GPT) series and models like Meta's Llama, operate under strict causal or unidirectional masking constraints 811. In a causal attention configuration, an active token is mathematically restricted; it can only attend to its own representation and the representations of the tokens that strictly precede it in the temporal sequence. Future tokens are algorithmically obscured by applying a negative infinity mask to the upper triangle of the attention matrix prior to the softmax normalization, strictly preventing the model from looking ahead and accessing future data points 910. Their fundamental pre-training objective is Autoregressive Language Modeling, which trains the network to predict the statistically most probable next token given the preceding sequence context 11. This architecture is intrinsically optimized for natural language generation (NLG), sustaining multi-turn conversational agents, and executing open-ended reasoning tasks 58.
The original 2017 formulation of the Transformer was an Encoder-Decoder model, a hybrid structure that has been preserved and refined in modern iterations such as Google's Text-to-Text Transfer Transformer (T5) and Meta's BART 917. These models couple a bidirectional encoder, utilized to ingest and deeply understand a comprehensive prompt or source text, with an autoregressive decoder responsible for generating the final output. The operational bridge between these two distinct components is the Cross-Attention layer located within the decoder blocks. In this specific layer, the decoder's Queries attend directly to the Keys and Values generated by the final layer of the encoder, grounding the generation process in the heavily contextualized input representation 45. These models are predominantly trained using denoising objectives, such as text infilling or span corruption, where the network learns to reconstruct highly degraded input sequences 9. They remain the premier architectural choice for sequence-to-sequence tasks where the output length structurally differs from the input length, such as high-fidelity machine translation, abstractive summarization, and complex generative question answering frameworks 819.
| Architectural Dimension | Encoder-Only (e.g., BERT, RoBERTa) | Decoder-Only (e.g., GPT-4, Llama 3) | Encoder-Decoder (e.g., T5, BART) |
|---|---|---|---|
| Attention Masking | Bidirectional (Fully visible global context) | Causal / Unidirectional (Strict left-to-right) | Bidirectional Encoder + Causal Decoder |
| Primary Training Objective | Masked Language Modeling (MLM) | Autoregressive Next-Token Prediction | Span Corruption / Denoising Autoencoding |
| Interaction Mechanism | Self-Attention exclusively | Self-Attention exclusively | Self-Attention + Encoder-Decoder Cross-Attention |
| Standard Applications | Text Classification, Named Entity Recognition, Sentiment Analysis, Extractive QA | Open-ended Text Generation, Chatbots, Code Generation, Conversational AI | Machine Translation, Text Summarization, Abstractive QA |
| Information Flow | Assimilates whole-sequence context simultaneously. | Generates sequentially; relies heavily on continuous KV caching. | Encodes global context first, then generates sequentially. |
Injecting Sequence Order: From Absolute to Relative Positional Encodings
A persistent misconception surrounding the foundational mechanics of Transformers is the assumption that they process text sequentially from left to right, mimicking human cognitive reading patterns or the functionality of legacy Recurrent Neural Networks 4. In reality, the mathematical core of the Transformer - the self-attention mechanism - is completely order-agnostic. The matrix multiplications compute all pairwise token relationships simultaneously in parallel, meaning that without an explicit mechanism to inject sequence order, the model would perceive a highly structured sentence merely as a disorganized bag-of-words. The semantic difference between "The man bit the dog" and "The dog bit the man" would be mathematically invisible to the attention layers 4.
To resolve this critical structural deficit, the original Transformer architecture proposed adding absolute positional encodings directly to the input embeddings prior to their entry into the first attention layer. These initial encodings utilized combinations of sine and cosine functions operating at varying frequencies to generate unique, continuous positional vectors 4. While mathematically elegant, absolute encodings presented severe limitations as sequence lengths expanded. They rigidly tie a token's semantic identity to its exact index in a sequence, meaning a model trained on sequences of a specific length struggles catastrophically to generalize or extrapolate to longer sequences during inference, leading to degraded performance in long-context retrieval tasks 1213.
Consequently, the industry standard has experienced a definitive paradigm shift away from absolute encodings toward relative positional paradigms, specifically Rotary Positional Embeddings (RoPE) 1214. Instead of statically adding a vector to the base embedding, RoPE mathematically rotates the Query and Key vectors within the complex plane by an angle directly proportional to their absolute position in the sequence 1224. The architectural brilliance of RoPE lies in its geometric properties during the dot-product operation. When the model computes the attention score between a rotated Query at position $m$ and a rotated Key at position $n$, the resulting value depends exclusively on their relative distance ($m - n$), rather than their absolute index positions. This aligns the underlying mathematics with linguistic reality, where the relative distance between an adjective and a noun is fundamentally more critical to meaning than their absolute placement within a massive document 12. This geometric rotation has enabled modern foundation models to scale their effective context windows exponentially, facilitating the processing of hundreds of thousands of tokens with exceptional training stability and zero-shot extrapolation capabilities 1314. Models developed across diverse global ecosystems, from Naver's HyperCLOVA X to AI Singapore's SEA-LION, universally implement RoPE to secure robust long-range dependency modeling 131424.
Modern Efficiency and Scaling Optimizations (2023-2026)
As the ambition to model massive contexts grew in parallel with parameter counts, standard Multi-Head Attention (MHA) encountered an inescapable physical limit: the memory bandwidth bottleneck imposed by the Key-Value (KV) Cache 121516. During autoregressive decoding, a model generates tokens sequentially. To prevent the exponentially costly recomputation of all previous token states for every new token generated, the architecture must cache the computed Key and Value vectors of all preceding tokens in memory 27. In models possessing hundreds of billions of parameters, this KV Cache inflates rapidly, consuming hundreds of gigabytes of highly constrained GPU VRAM and drastically limiting the maximum batch size of concurrent users a single hardware node can serve 16.
To mitigate this severe bottleneck, deep learning researchers initiated structural optimizations that altered the fundamental ratio of Queries to Keys and Values. Grouped-Query Attention (GQA) emerged as an initial solution, dividing the Query heads into discrete groups and forcing all Queries within a single group to share a single, unified Key and Value head 112. This structural adjustment achieves a substantial reduction in memory overhead with only a marginal degradation in model expressivity and task accuracy compared to standard MHA 1428.
However, the most aggressive recent innovation in attention efficiency is Multi-Head Latent Attention (MLA), an architecture prominently pioneered by DeepSeek's V2 and V3 models 11227. Rather than storing discrete Key and Value matrices in memory for every token, MLA utilizes a sophisticated low-rank matrix decomposition strategy to compress the input into a single, highly dense latent KV vector. During inference, only this significantly compressed latent vector is cached, effectively reducing memory footprints by over 90% 1229. When attention must be calculated, the latent vector is rapidly up-projected on the fly to reconstruct the necessary Keys and Values. This mechanism allows the model to capture the massive memory savings characteristic of Multi-Query architectures while theoretically preserving the rich, multi-dimensional representational capacity inherent to full Multi-Head Attention, offering unprecedented economical inference scaling 121628.
In addition to attention optimizations, the broader network architecture has pivoted to address compute density. Dense models, where every single parameter is activated for every forward pass, scale highly inefficiently once parameter counts exceed the 100-billion threshold. The Mixture of Experts (MoE) architecture elegantly decouples a model's total parameter count from its active computational cost 1516. In an MoE Transformer, the standard dense Feed-Forward Network (MLP) within a transformer layer is replaced by multiple independent, specialized "expert" neural networks. A trainable routing mechanism mathematically evaluates each token and dynamically forwards it to only the top one or two most relevant experts 15. For context, advanced models like DeepSeek V3 boast a massive 671 billion total parameters distributed across an array of 256 experts. Yet, because a token is only routed to a tiny fraction of these available networks, the model strictly utilizes roughly 32 billion active parameters per token during a standard forward pass 16. This sparse activation paradigm allows MoE models to internalize immense, highly specialized world knowledge across diverse domains without incurring the crippling arithmetic latency and power consumption penalties associated with massive dense matrix multiplications 1630.
The optimization of Transformers has also extended to the fundamental pre-training objective itself, transitioning from strict next-token prediction to Multi-Token Prediction (MTP) 1517. Traditional autoregressive learning dictates that the model predicts exactly one subsequent token per forward pass. Models utilizing MTP deviate from this by employing auxiliary prediction heads that force the network to project multiple tokens into the future simultaneously - for example, attempting to predict tokens $t+1, t+2$, and $t+3$ concurrently based on the same shared contextual base 3017. Information-theoretically, this methodology vastly densifies the training signal. A single forward pass yields significantly more gradient updates across the network, forcing the model to develop robust long-range planning capabilities and pre-compute deeper, more coherent internal representations of syntax and narrative structure 3017. During the inference phase, MTP naturally enables a form of native speculative decoding, where the model can confidently generate multiple tokens in a single architectural step, thereby dramatically accelerating throughput and reducing latency for long-form generation tasks 151632.
At the very foundation of the architecture, Matryoshka Representation Learning (MRL) has redefined how Transformers encode textual data into semantic vectors at the embedding layer. Traditionally, embedding models project text into rigid, fixed-dimensional vectors, forcing downstream applications to utilize full-width embeddings (e.g., 1,536 or 3,072 dimensions) regardless of the specific task's complexity, which wastes memory and compute resources during vector searches 3334. MRL modifies the training objective to force the neural network to front-load the most critical semantic information into the earliest dimensions of the output vector 3335. In a model trained with MRL, a high-dimensional vector is structured such that its first 256 dimensions constitute a fully functional, semantically coherent embedding, as do its first 512, its first 768, and so on 3334. This nested, multi-granular structure empowers system engineers to dynamically truncate embeddings at inference time based on strict latency budgets. Applications can execute rapid, first-pass semantic retrieval across millions of documents using computationally cheap 256-dimensional prefixes, and subsequently utilize the full 1,536 dimensions exclusively for highly precise re-ranking operations on a much smaller candidate set 34.
Mechanistic Interpretability: Peering into the Black Box
For years, the internal computations and representations of deep learning models were treated as inscrutable, dense black boxes, defying classical software analysis. The burgeoning field of Mechanistic Interpretability - pioneered extensively by research teams at Anthropic and DeepMind - seeks to systematically reverse-engineer these complex networks. By treating trained neural networks analogously to compiled computer programs, researchers map specific weight matrices and activation patterns to legible algorithms and causal subgraphs 1837.
A foundational conceptual principle introduced in the seminal work "A Mathematical Framework for Transformer Circuits" by Elhage et al. is the radical reconceptualization of the Residual Stream 18. Instead of viewing residual, or skip, connections merely as a mathematical trick to prevent vanishing gradients during deep backpropagation, mechanistic interpretability defines the residual stream as a high-dimensional linear communication channel - the central bandwidth or foundational memory bus of the model 183839.
At the initiation of the model's forward pass, token embeddings and positional encodings are placed onto this residual stream. Crucially, as the stream flows upward through the sequential layers of the architecture, the stream itself does not undergo non-linear transformations. Instead, the individual Attention and MLP layers act as independent side-stations attached to this highway. Every layer "reads" from the residual stream via an arbitrary linear projection, performs its highly specialized calculation, and subsequently "writes" its output back to the stream via additive linear projection 1838.
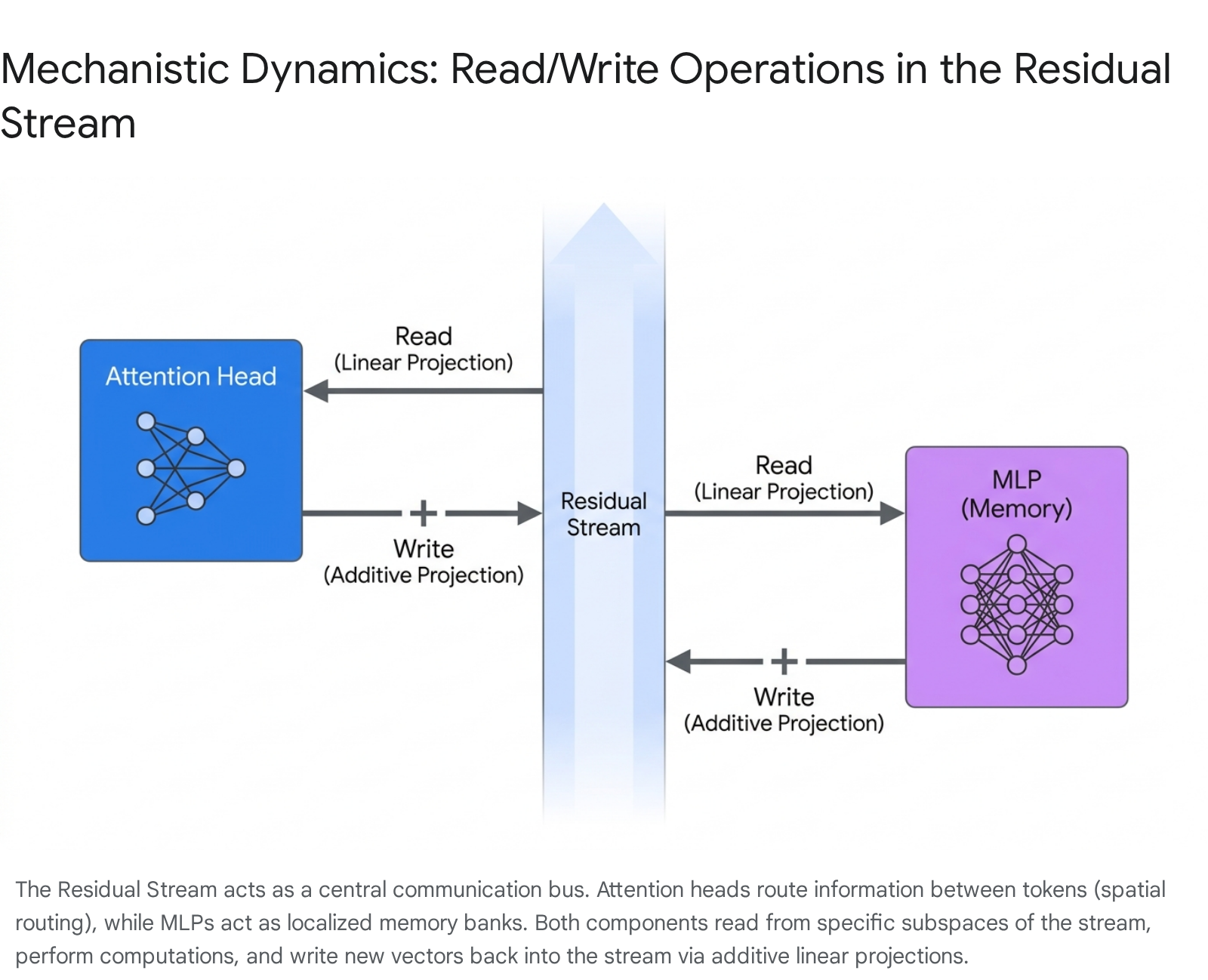
Because the residual stream is vastly high-dimensional, computational components can operate in essentially orthogonal, disjoint subspaces. This means an attention head situated in early layers can write syntactic structural information to specific dimensions, which an MLP located dozens of layers deeper can explicitly read from without experiencing interference from parallel computations 1838.
Within this framework, attention heads are revealed to be entirely independent and additive mechanisms. They do not process information jointly; rather, their outputs are independently written back to the residual stream to be synthesized by subsequent layers 18. The functionality of an individual attention head is split into two distinct, mathematically separable operational circuits. The Query-Key ($W_{QK}$) circuit determines where to move information from and to, computing the attention pattern and calculating the dot products that map which source tokens are relevant to the destination token 1840. Simultaneously, the Output-Value ($W_{OV}$) circuit determines exactly what information is actually moved. The left singular vectors of the $W_{OV}$ matrix describe the specific subspace in the destination token's residual stream where the data will be written, while the right singular vectors describe the specific subspace read from the source token's representation 18.
This mathematical separation allows researchers to prove that specific attention heads execute highly legible, specialized algorithms. A primary discovery was the identification of "Induction Heads" - specialized circuits typically composed of two distinct attention heads working in sequential layers. These heads search previous context for identical or similar tokens to the current token, and then attend to the token immediately following that historical instance, effectively implementing a sophisticated copying mechanism that enables the few-shot, in-context learning capabilities characteristic of LLMs 394041.
While attention heads route information laterally across different sequence positions, Multi-Layer Perceptrons (MLPs) act exclusively on individual token representations in isolation 4042. Through the mechanistic lens, MLPs function as high-capacity key-value memory banks that read contextual cues from the residual stream and inject factual world knowledge back into it 1342. Furthermore, MLPs actively perform crucial "memory management" operations. Research indicates that certain MLP neurons consistently exhibit highly negative cosine similarities between their input and output weights. This strongly suggests that these specific neurons act as targeted erasure mechanisms. When they detect outdated, redundant, or fully resolved contextual information in the stream, they calculate its exact negative inverse and add it to the residual stream, effectively deleting that data to free up high-dimensional bandwidth for more complex abstractions in deeper layers 18.
Addressing Common Misconceptions in Transformer Literature
The explosive growth and rapid commercialization of Transformers have inadvertently fostered significant conceptual misunderstandings within both public discourse and technical literature, particularly regarding model interpretability and internal processing dynamics.
A pervasive fallacy in the field is the anthropomorphization of mathematical self-attention, where practitioners erroneously conflate the model's computed attention weights with human cognitive attention or logical reasoning pathways 94344. Early interpretability literature frequently operated on the assumption that if a model placed a high attention weight on a specific token, that token was the definitive causal reason for the model's output, prompting the widespread use of attention heatmaps as definitive explanations of model behavior 431946. However, foundational research by Jain and Wallace (2019) alongside critiques by Wiegreffe and Pinter (2019) definitively proved that "attention is not explanation" 94620.
Attention weights merely represent local, highly contextualized routing operations within a specific layer, not a global chain of causal logic 9. The semantic gap between continuous, high-dimensional vector spaces and discrete human concepts is vast. An attention head might assign massive weight to a seemingly irrelevant comma or an article because, through the complex transformations in the latent space, that specific punctuation mark has been weaponized as an accumulator for broader syntactic information or sentence-level context 9. Furthermore, experimental ablation studies clearly demonstrate that zeroing out "high-attention" tokens often has entirely negligible effects on the final downstream prediction. Conversely, altering tokens with seemingly low attention weights can catastrophically derail the model's output 9. These findings rigorously prove that attention weights are neither necessary nor sufficient for causal explanation. True, reliable interpretability requires observing the holistic computational graph - crucially including the vast parameter space and non-linear transformations embedded in the MLPs - rather than relying solely on simplistic attention heatmaps 9.
A parallel misconception, as previously addressed, is the persistent assumption that Transformers process language sequentially from left to right, mirroring the architecture of Recurrent Neural Networks 4. While autoregressive generation - the act of emitting output - operates left-to-right, the comprehension phase during the encoding of a user prompt occurs entirely in parallel 4. The self-attention matrix calculates all pairwise relationships across the entire sequence simultaneously. This massive parallelization is precisely what allows Transformers to capture complex long-range dependencies efficiently and train at unprecedented speeds. However, it also clarifies why these models occasionally fail catastrophically in tasks requiring rigid, state-dependent step-by-step logic tracking; unlike LSTMs, they lack an inherent sequential memory state mechanism outside of the residual stream's linear accumulation and positional encodings 413.
Core Limitations and Emerging Alternatives
Despite extensive algorithmic and hardware optimizations, the standard Transformer architecture remains constrained by an inescapable mathematical reality: the self-attention mechanism scales quadratically with respect to sequence length in terms of both temporal processing and memory complexity ($O(N^2)$) 3048. As the sequence length $N$ doubles, the number of pairwise dot products the model must compute across its attention matrices quadruples 30. While mechanisms like FlashAttention heavily optimize GPU memory read/write overhead by fusing operations, they do not alter this fundamental asymptotic complexity.
This quadratic computational bottleneck severely limits the economical scaling of context windows into the millions of tokens. Consequently, the field is aggressively researching sub-quadratic architectural alternatives. State Space Models (SSMs), most notably the Mamba architecture, have emerged as the most formidable theoretical competitors to the Transformer. SSMs mathematically map discrete sequence transformations to continuous-time differential equations, allowing them to process sequences with linear complexity ($O(N)$) and constant memory overhead regardless of context length 84950. By utilizing hardware-aware selective state updates, SSMs emulate the theoretical infinite-context potential of legacy RNNs without sacrificing the massive parallel training efficiency that made Transformers dominant, positioning them as a critical area of ongoing research for ultra-long context and real-time processing applications.
Global Structural Innovations: Beyond Silicon Valley
While the foundational research establishing the Transformer architecture originated in North American laboratories, by 2026, structural innovation has become highly decentralized. International AI labs and research consortiums are driving significant architectural refinements specifically tailored to linguistic diversity, sovereign infrastructure requirements, and localized hardware efficiency constraints 212253.
South Korea and Japan: Multilingual Breadth and Infrastructure Efficiency
South Korea has firmly established itself as a leader in sovereign, culturally aligned LLM development. Naver's HyperCLOVA X serves as a premier example of an architecture fundamentally optimized for a non-English linguistic paradigm 52355. Rather than merely fine-tuning an English-centric foundation model on translated text, HyperCLOVA X was engineered as a massive-scale model built from the ground up, utilizing an intentionally balanced pre-training corpus of Korean, English, and programming code data to ensure native proficiency 2355. Architecturally, it aggressively leverages modern standardizations, including RoPE and Grouped-Query Attention, ensuring superior training stability and inference efficiency. Furthermore, the release of their 32B 'Think' Vision-Language Model demonstrates profound structural integration. It utilizes a custom vision encoder that projects visual patches directly into the shared Transformer embedding dimension alongside text tokens, executing multimodal reasoning without disrupting the established text-based RoPE configuration, ensuring deep alignment with specific cultural contexts 132423. Similarly, major entities like Kakao Brain (with KoGPT) and LG (EXAONE) have driven rigorous advancements in bilingual encoder-decoder models optimized for intricate enterprise applications 25.
Parallel to these architectural efforts, Japanese research initiatives, heavily supported by institutions like the Mitsubishi Research Institute, are actively pioneering hardware-software co-design to address the massive electricity consumption of generative AI. Faced with severe power grid constraints, Japan is heavily investing in structural innovations such as AI-specialized RISC-V chips, photoelectronic fusion integration, and advanced packaging to optimize the physical efficiency of running Transformer inference, projecting capabilities to reduce power demands in data centers significantly by 2040 562425. Transformer efficiency optimizations via static quantization and structured pruning have demonstrated reductions in energy consumption by nearly 30% in edge-computing scenarios, aligning model development with national green transformation (GX) strategies 242559.
Southeast Asia: AI Singapore and the SEA-LION Project
Addressing the historical underrepresentation of Southeast Asian languages in AI, AI Singapore developed the SEA-LION (Southeast Asian Languages In One Network) family of open-source models 1426. A major technical innovation of SEA-LION is its aggressive, ground-up tokenizer redesign. Generic tokenizers derived predominantly from Western datasets heavily fragment non-Latin scripts and unique morphological structures, leading to massive computational bloat and debilitating semantic loss 1461. SEA-LION employs a custom-built SEABPETokenizer with an expansive 256,000-token vocabulary, drastically increasing the compression rate and tokenization fertility for complex languages like Thai, Burmese, and Indonesian 1422. Built on advanced decoder-only frameworks and incorporating GQA and RoPE, the SEA-LION initiative proves that deep structural efficiency combined with hyper-localized tokenization yields vastly superior regional performance and computational economy compared to utilizing globally scaled, predominantly Western models 142627.
Europe: Kyutai's Moshi and Full-Duplex Multi-Stream Audio
In Europe, the French non-profit frontier research lab Kyutai has radically expanded the Transformer's modality capabilities with the release of Moshi, the first open-source, full-duplex speech-to-speech dialogue model 2864. Traditional voice assistants rely on latent, cascaded pipelines - transcribing speech to text, generating a text response via an LLM, and synthesizing that text back into audio. This cascade inherently prevents natural human conversational dynamics, introducing massive latency and failing to process interruptions or non-linguistic emotional cues 2829.
Moshi completely eliminates this structural cascade utilizing a novel multi-stream architecture, allowing it to model two continuous audio streams simultaneously (the user's voice and the AI agent's voice) within the same parallel context window 2866. To manage the immense computational load of processing high-frequency discrete audio tokens (processing 32 tokens per 80ms timestep through its proprietary Mimi neural audio codec), Moshi introduces an innovative dual-transformer structure. It utilizes a 7-billion parameter Temporal Transformer to process broad semantic reasoning and long-term context, coupled with a highly efficient, smaller Depth Transformer that manages the complex inter-codebook dependencies at each specific micro-timestep 6667. Coupled with a unique "Inner Monologue" training mechanism - where the model explicitly predicts its own textual reasoning concurrently with its audio output to maintain logical coherence - Moshi achieves conversational latencies of roughly 160ms, operating efficiently on standard consumer-grade hardware 286667.
Africa: Participatory AI and Bypassing Resource Asymmetry
Across the African continent, research consortiums like the Masakhane initiative are forcefully emphasizing participatory NLP and structural architectural efficiency over the brute-force data scaling favored by Western labs 761. The vast majority of the continent's 2,000 living languages exist in severe sub-1GB data regimes, rendering standard massive pre-training methodologies mathematically and financially impossible 6168. Research originating from these collaborative networks demonstrates that profound algorithmic efficiency, sophisticated cross-lingual transfer mechanisms, and culturally aligned tokenizer adjustments yield significantly higher marginal returns than simply increasing parameter counts 6169. By centering linguistic typologies - such as the intense morphological richness characteristic of Bantu languages like Swahili, Zulu, and Duala - directly in the architectural design phase, these communities are pioneering robust frameworks for low-resource model compression and efficient adaptation. This approach challenges the dominant computational paradigms, proving that high-performance AI can be developed sustainably without relying on trillion-token datasets 536169.