What Is Tokenization and How AI Reads Your Text
When you type a sentence into a large language model, the artificial intelligence does not see individual letters, syllables, or words; instead, it processes "tokens," which are mathematically assigned numerical IDs representing statistically frequent chunks of text. This invisible translation layer dictates everything from how much an AI API costs to why highly advanced models inexplicably fail to count the number of letters in a simple word. Understanding tokenization provides the ultimate mechanical key to making sense of a language model's cognitive blind spots, its memory limits, and the inherent geographic biases baked into its architecture.
The Illusion of Words: How Machines Perceive Text
To understand generative artificial intelligence, you must first abandon the assumption that machines process language in a manner even remotely similar to human cognition. When a human reads the word "elephant," the brain instantly activates an interconnected semantic network: concepts of large grey mammals, trunks, ivory, Africa, and memory are retrieved simultaneously. Humans read for meaning, continuously parsing letters into morphemes and words into structural grammar.
When a large language model (LLM) like GPT-4 encounters the word "elephant," it perceives only a discrete numerical identifier - such as 37SELEphant or 4321 - drawn from a massive, predetermined vocabulary lookup table of roughly 100,000 entries 1. The machine does not "know" what an elephant is at this stage. The actual semantic understanding only emerges later, deep within the neural network's embedding layers and transformer attention heads, where these numbers are mapped into high-dimensional vector space to determine their relationships with other numbers 12. But the very first step - the literal perception of the text - happens through tokenization.
This translation from text to numbers is an absolute structural necessity. Neural networks are fundamentally massive calculators; they operate exclusively on continuous mathematics, calculus, and linear algebra. Before a model can process, predict, or generate language, that language must be converted into discrete numerical inputs. Long before the invention of the modern transformer architecture in 2017, computer scientists and linguists debated the optimal methodology for breaking down human language into machine-readable units 12.
The Character Age and the Sequence Length Problem
In the early days of computing, the most logical approach to this problem was character-level tokenization. The story begins in the 1960s with the American Standard Code for Information Interchange (ASCII), which assigned a specific numerical value to every uppercase letter, lowercase letter, punctuation mark, and digit 1. From a vocabulary management perspective, character-level tokenization possesses a beautiful, unassailable simplicity. An AI model would only need to memorize a tiny vocabulary of about 128 to 256 unique tokens to represent any text in the English language 1. Because every word is just a combination of these base characters, the model would never encounter an "unknown" word.
However, this method proved computationally devastating for early natural language processing (NLP). In a character-level model, sequences become insanely long. The simple sentence "The quick brown fox jumps over the lazy dog" requires 43 separate tokens just to be processed 13. A standard document translates into hundreds of thousands of tokens. Early neural architectures, such as Recurrent Neural Networks (RNNs), lacked the computational bandwidth to handle this. As they processed a text character by character, they suffered from the "vanishing gradient problem" - by the time the network reached the end of a long sentence, the mathematical weights prioritizing the beginning of the sentence had diluted to zero, causing the model to literally forget how the sentence started 1. Furthermore, individual characters carry no semantic weight. The letter "c" communicates absolutely nothing about a feline; the model wastes immense computational resources just trying to learn that c-a-t forms a coherent concept before it can even begin to learn grammar 14.
The Word-Level Explosion
To solve the sequence length problem, researchers pivoted to the opposite extreme: word-level tokenization. This approach seems highly intuitive because words are the natural, semantic units of human language 15. If models learned entire words as single tokens, sequence lengths would be drastically reduced. "The quick brown fox" would be just four tokens. This logic powered an entire generation of early NLP systems, including Bag of Words models, TF-IDF systems, and early Word2Vec embeddings 16.
Yet, word-level tokenization introduced a fatal flaw: vocabulary explosion 7. In a word-level system, a model requires a unique, discrete token ID for every possible variation of a word. "Run," "runs," "running," and "ran" are treated as completely unrelated mathematical entities, forcing the model to learn the semantic meaning of each one from scratch 478. When you factor in proper nouns, scientific jargon, typos, and newly coined internet slang, the required vocabulary size balloons into the millions. Managing an embedding table with millions of entries requires crippling amounts of memory.
Worse, if a word-level model encounters a string of text it was not explicitly trained on, it has no fallback mechanism. It simply outputs a generic <UNK> (unknown) token, effectively blinding the AI to new expressions and severely degrading its utility in real-world applications 79101.
The Subword Solution: Byte-Pair Encoding
Modern LLMs require a pragmatic compromise: a tokenization system that keeps the total vocabulary size small and manageable (like character tokenization) while preserving the high semantic density and short sequence lengths of word tokenization 479.
The breakthrough that powers almost every major contemporary language model - including OpenAI's GPT-4, Anthropic's Claude, and Meta's Llama - is subword tokenization, driven primarily by an algorithm called Byte-Pair Encoding (BPE) 19112. BPE was originally developed as a simple data compression algorithm for general computer files, but in 2015, Rico Sennrich and his colleagues at the University of Edinburgh adapted it for NLP 1.
Byte-Pair Encoding operates on a brilliant, greedy statistical logic. Rather than telling the machine what a word is, the algorithm discovers the most efficient way to parse language by looking at raw data. The process works as follows: 1. The algorithm starts with a base vocabulary of individual characters. 2. It scans a massive training corpus and counts the frequencies of all adjacent pairs of characters. 3. It identifies the most frequent adjacent pair and merges it into a new, single token 913. 4. It updates the corpus with this new token and repeats the process.
For example, if the algorithm repeatedly sees the letters "h" and "e" next to each other, it merges them into a single token: "he". In the next iteration, if "t" and "he" frequently appear together, it merges them into "the" 7. The algorithm repeats this process tens of thousands of times until it reaches a target vocabulary size defined by the developer, typically between 32,000 and 200,000 unique tokens 101314.
This creates a highly optimized hybrid vocabulary. Highly frequent words - like "The," "apple," or "computer" - are merged into single, whole-word tokens, which keeps the sequence length short and efficient 9115. However, if the model encounters a rare word, a complex medical term, or a new slang word, it does not crash or throw an <UNK> error. Instead, it gracefully decomposes the unfamiliar word into smaller, highly recognizable subword chunks 91. For instance, the word "unhappiness" might be split into the tokens un, happi, and ness. The model can infer the meaning of the rare word by relying on the semantic weight of these common prefixes and suffixes, allowing it to "understand" words it has never explicitly seen before 162.
Byte-Level BPE: True Universality
In 2019, the release of GPT-2 introduced a critical evolution to this algorithm: byte-level BPE 1. Rather than starting with Unicode characters, which can be messy and massive, byte-level BPE drops down to the foundational building blocks of computing: raw UTF-8 bytes 118.
In UTF-8 encoding, any character that exists in any language can be represented by a sequence of 1 to 4 bytes. By setting the base vocabulary to all 256 possible byte values, developers ensured that the tokenizer could represent absolutely any text that exists or will ever exist - including rare alphabets, obscure mathematical symbols, and novel emojis 118. If a byte-level BPE tokenizer encounters a completely alien symbol, it simply falls back to rendering it as a sequence of base bytes. Because every text can be represented as bytes, and all bytes are in the vocabulary, the dreaded <UNK> token was effectively eradicated from modern architecture 1.
OpenAI's proprietary tokenizer implementation, tiktoken, relies heavily on byte-level BPE. Written in the Rust programming language for maximum speed, tiktoken utilizes heavily optimized vocabulary tables (such as cl100k_base for GPT-4 and o200k_base for GPT-4o) to rapidly compress and decompress text into numerical arrays before they hit the neural network 1141920.
Alternative Tokenization: WordPiece and SentencePiece
While BPE dominates the generative AI landscape, it is not the only subword algorithm in production. Understanding the alternatives is critical for AI engineers, as swapping a tokenizer fundamentally breaks a model's performance 14.
WordPiece Developed by Google and famously used in the BERT (Bidirectional Encoder Representations from Transformers) family of models, WordPiece shares BPE's bottom-up merging philosophy but changes the mathematical criteria for how merges are selected 101. While BPE is a "greedy" algorithm that blindly merges the most frequent pairs, WordPiece measures the likelihood of the training data. It evaluates a potential merge by dividing the frequency of the pair by the product of the individual frequencies of its parts 1.
In simpler terms, WordPiece asks: "Is this combination of characters occurring far more often than we would expect by random chance?" If the tokens "g" and "s" appear together vastly more than their independent frequencies would predict, WordPiece merges them 1. WordPiece also uses a specific formatting quirk, adding a ## prefix to any subword that does not appear at the beginning of a word, helping the model keep track of word boundaries 1014.
SentencePiece and Unigram Another Google innovation, SentencePiece, is designed for true language independence. Most tokenizers rely on a "pre-tokenization" step, where text is split by spaces and punctuation before the subword algorithm is even applied 1221. However, relying on whitespace is a deeply Western-centric assumption; languages like Mandarin Chinese and Japanese do not use spaces between words 1921.
SentencePiece treats the space itself as just another normal character (often represented visually by an underscore _), completely bypassing the need for whitespace pre-tokenization 141922. This makes it vastly superior for multilingual models. SentencePiece is often paired with the Unigram language model algorithm, a "top-down" approach that starts with a massively bloated vocabulary of all possible substrings and iteratively removes the least useful tokens until it hits its target size, balancing the probabilities along the way 11923.
The Danger of Glitch Tokens
Because tokenizers are trained on massive datasets using statistical algorithms, they occasionally capture bizarre anomalies that embed themselves permanently into a model's architecture.
In 2023, researchers discovered a phenomenon known as "glitch tokens" across several major models, including GPT-3, GPT-2, and LLaMA 183. The most infamous example was a token corresponding to the string SolidGoldMagikarp. When users prompted GPT-3 to repeat or explain this string, the model would hallucinate wildly, evade the question, or spout incoherent garbage 3.
This catastrophic failure occurred because of a misalignment between the data used to train the tokenizer and the data used to train the actual language model. The tokenizer had ingested massive amounts of raw Reddit data, where "SolidGoldMagikarp" was a highly active user. Because the string appeared so frequently, the BPE algorithm dutifully merged it into a single, permanent token ID 18. However, when developers subsequently filtered and cleaned the dataset to train the actual neural network, they removed much of that Reddit data.
As a result, the token ID existed in the model's vocabulary, but the model had almost no training examples to learn what it meant. The embedding vector for SolidGoldMagikarp remained randomly initialized 183. When a user input that specific string, it injected pure mathematical noise into the neural network's attention mechanisms, causing the system to derail. This highlights a critical rule in AI development: tokenizer vocabularies must perfectly reflect the distributions of the model's training data 123.
The Strawberry Problem: Why AI Cannot Count
Because language models perceive the world strictly through the lens of subword tokens, they suffer from profound, structural cognitive blind spots regarding the granular makeup of text. This architectural quirk is the root cause of the viral "strawberry problem" that has plagued nearly all modern language models.
When a user asks standard models like GPT-4 or Claude, "How many 'r's are in the word strawberry?", the model confidently and incorrectly answers "two" 252627. To a human, this seems like an absurd failure of basic intelligence. To an AI engineer, it is a perfectly logical outcome of BPE tokenization.
When the word "strawberry" is passed through OpenAI's cl100k_base tokenizer, the model never sees the ten discrete letters s-t-r-a-w-b-e-r-r-y. Because "strawberry" is a relatively common word, the tokenizer has learned to compress it. It splits the word into three distinct token IDs representing the chunks str, aw, and berry (specifically, token IDs 496, 675, and 15717) 25.

From the model's perspective, "strawberry" is just a sequence of three opaque mathematical objects 325. Asking the model to count the individual letters inside those tokens is akin to asking a human to count the number of atoms in a brick while only being allowed to look at a completed wall 1528. The granular, character-level information simply does not exist in the model's direct line of sight; the tokenizer erased it before the neural network could analyze it.
This token boundary blindness severely impacts other domains, most notably mathematics and arithmetic. Language models often fail at multiplying large, multi-digit numbers (like 2-digit by 5-digit multiplication) not because they lack deductive logic, but because the numbers are arbitrarily sliced into subword chunks based on frequency. For example, the number 12345 might be tokenized into 123 and 45, or 12 and 345 13. The mathematical carry-overs cross token boundaries that the model never explicitly sees, forcing the neural network to memorize complex patterns of chunked numbers rather than learning the underlying algorithmic rules of addition and multiplication 2829.
The Word Count Dilemma
Tokenization is also the primary reason why large language models are notoriously terrible at following strict length constraints, such as "write exactly 200 words for this essay."
To a human, counting 200 words is trivial. But an LLM does not possess an internal counter; it operates purely as an autoregressive sequence predictor, calculating the probability of the next optimal token based on the previous tokens 2431. The relationship between tokens and words is loose and highly variable. On average, one token equals roughly 0.75 words in standard English 1832. However, this ratio changes wildly depending on punctuation, formatting, capitalization, and the rarity of the vocabulary used.
Asking a language model to stop generating text at exactly 200 words is effectively asking a system that thinks in subword probabilities to dynamically monitor a secondary, invisible metric (word boundaries) while simultaneously executing complex semantic generation. As one metaphor accurately describes it, it is like asking a jazz musician to improvise a beautiful solo but forcing them to stop on exactly the 137th note without being allowed to count 33. The model has no structural mechanism to compute a global word constraint over an exponentially large space of possible token sequences 433.
Enter OpenAI o1: Bypassing Token Limits with Reasoning
To bypass the structural limitations imposed by subword tokenizers, AI researchers have begun developing models that integrate "Chain of Thought" (CoT) reasoning directly into the inference generation process. The most prominent example of this is OpenAI's o1 model series, released in September 2024 (previously rumored under the codenames Q* and Project Strawberry) 252634.
Rather than generating an immediate answer using rapid, intuitive "System 1" prediction, the o1 model is trained to engage in slower, analytical "System 2" deliberation 3435. When given a complex prompt, o1 does not immediately output text to the user. Instead, it utilizes a hidden "scratchpad" to generate a sequence of internal reasoning tokens 34537.
This process was achieved through a training breakthrough known as process supervision and reinforcement learning. Traditional models use outcome supervision, where the AI is rewarded solely if its final answer is correct. In process supervision, the model is rewarded for each correct, logical step it takes in a chain of thought, teaching it to break down complex tasks, recognize its own errors, backtrack, and try alternative strategies 2738.
Crucially, this hidden reasoning stage allows the o1 model to circumvent the "strawberry problem." When asked to count the letters in "strawberry," the model does not attempt to guess based on the opaque token IDs 496, 675, and 15717. Instead, it uses its reasoning tokens to explicitly spell out the word in its hidden context window (e.g., "S - T - R - A - W..."), effectively forcing the tokenizer to process each letter as a distinct token 2527. By laying the characters out individually, the model's self-attention mechanism can easily iterate over them, tally the 'r's, verify its logic, and then confidently output the correct answer 252739.
While this chain-of-thought architecture vastly improves performance in mathematics, physics, and coding - allowing o1 to exceed human PhD-level accuracy on benchmarks like GPQA - it comes with significant trade-offs 56. Reasoning tokens consume test-time compute. They are slower to generate, and because these invisible tokens are injected directly into the model's context window, they consume the user's available token budget and drive up inference costs significantly 3457.
The AI Language Tax: Tokenization's Geographic Bias
While byte-level BPE is computationally brilliant for English, its greedy, data-driven nature has created a severe global inequity in the AI ecosystem. This phenomenon is widely known among researchers as the "tokenization penalty" or the "language tax" 2342.
Tokenizer vocabularies are constructed by scanning massive training corpora to find the most statistically frequent character pairings. However, the datasets used to train models like GPT-4 or Llama 3 are overwhelmingly biased toward English and programming languages (for instance, Llama 3's training data was 95% English and code, with only 5% dedicated to all other world languages combined) 42438.
As a result, tokenizer vocabularies are saturated with English prefixes, suffixes, and whole words. In English, a common word usually maps cleanly to a single token. But for non-Latin scripts, low-resource languages, or languages with complex morphology - such as Arabic, Hindi, Burmese, or Mandarin - the tokenizer lacks the statistical frequency to have learned their common words 442439.
Consequently, when a user prompts a model in a non-Western language, the tokenizer shatters the text into tiny, inefficient fragments. Because Arabic or Hindi characters live in high Unicode blocks, they require multiple UTF-8 bytes to represent a single character 43910. An English-first tokenizer, having never seen these characters frequently enough to merge them, defaults to a byte-level fallback, splitting a single non-Latin character into two, three, or even four separate tokens 910.
The impact of this bias is measurable and financially punishing. When we translate a simple English sentence into various languages and process it through OpenAI's cl100k_base tokenizer, the token count explodes for non-Western scripts 1928.
Token Count Comparison by Language
| Language | Translated Sentence (Meaning: "The quick brown fox jumps over the lazy dog") | Token Count | Cost Multiplier |
|---|---|---|---|
| English | The quick brown fox jumps over the lazy dog. | 10 | 1.0x |
| Spanish | El zorro marrón rápido salta sobre el perro perezoso. | 11 | 1.1x |
| German | Der schnelle braune Fuchs springt über den faulen Hund. | 13 | 1.3x |
| Mandarin | 敏捷的棕色狐狸跳过懒狗。 | 18 | 1.8x |
| Japanese | 素早い茶色の狐は怠け者の犬を飛び越えた。 | 23 | 2.3x |
| Hindi | तेज़ भूरी लोमड़ी आलसी कुत्ते के ऊपर कूदती है। | 41 | 4.1x |
| Burmese | မြန်ဆန်သော အညိုရောင်မြေခွေးသည် ပျင်းရိသောခွေးကို ခုန်ကျော်သွားသည်။ | 58 | 5.8x |
Note: Token counts approximate based on standard BPE implementations for modern LLMs (e.g. GPT-4/o1). Ratios accurately reflect the fragmentation penalty 181928.
This token over-fragmentation acts as a silent tax on the developing world 23.
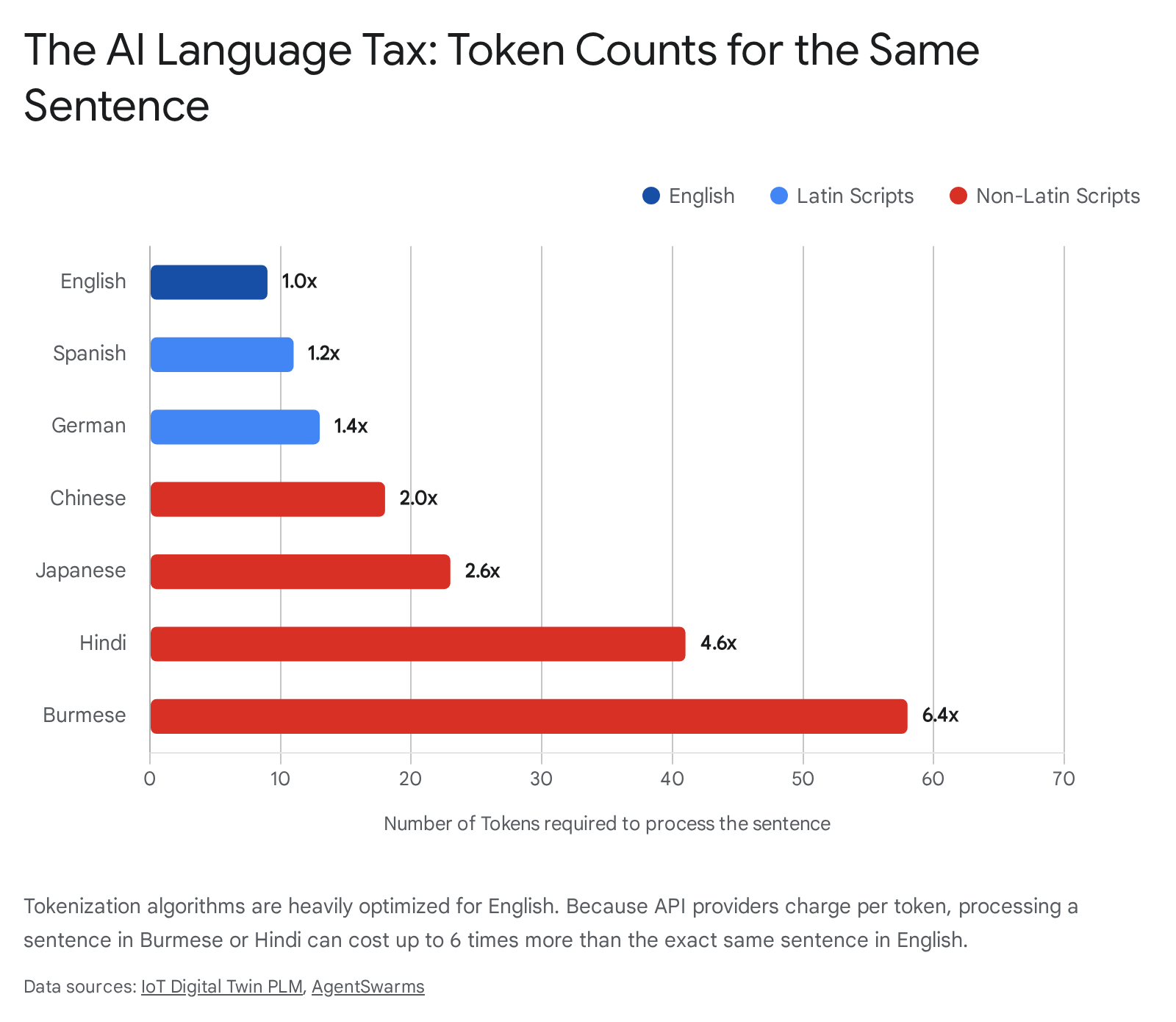
Because commercial AI API providers (like OpenAI, Anthropic, and Google) bill customers based strictly on the volume of tokens processed, a sovereign government or enterprise operating in Hindi or Arabic pays drastically more to process the exact same semantic information as an English counterpart 234210.
Furthermore, this inefficiency actively degrades model performance. NLP researchers measure this using two metrics: Tokenization Parity (TP) and Information Parity (IP) 9. When a language suffers from poor TP, the model is forced to dedicate vast amounts of its computational depth just to assemble basic linguistic concepts from raw byte fragments. This leaves the model with less attention bandwidth available for higher-level semantic reasoning, resulting in slower inference latency and degraded performance in complex tasks like reading comprehension or summarization 4389.
Recognizing this critical bottleneck, AI developers are actively attempting to mitigate the language tax. Newer generations of models have drastically expanded their token vocabularies. Meta's Llama 3 increased its vocabulary to 128,000, while OpenAI's o200k_base tokenizer expanded to 200,000 tokens 1522. Google's Gemma 3 tokenizer utilizes a 256,000 vocabulary size specifically to keep African and Indic language tokenization penalties under a 3x multiplier 19. Similarly, regional models like Qwen (optimized for Chinese) and Falcon (optimized for Arabic) rely on custom vocabularies built specifically around those character distributions, resulting in vastly improved regional compression 1510.
Context Windows and the Memory Bottleneck
Understanding how tokenization compresses (or fragments) language is vital for navigating the operational limits of AI systems, most notably the "context window."
A large language model is inherently stateless. It possesses no persistent, episodic memory of past interactions 4748. When you are chatting with an AI, the only reason it remembers what you said three messages ago is because the application interface invisibly re-sends the entire history of the conversation back into the model with every new prompt 4849. The context window is the absolute maximum amount of text - measured strictly in tokens, not words - that the model can hold in its working memory at a single time 474849.
As sequences grow longer, processing them becomes computationally expensive. To prevent the model from recalculating the mathematics of every previous token from scratch each time a new word is generated, models utilize a Key-Value Cache (KV Cache) 1050. The KV cache temporarily stores the attention calculations for past tokens. However, this cache requires significant hardware VRAM.
When tokenization is inefficient, the context window fills up rapidly, burning through the KV cache. For example, if a model has a 128,000 token limit, it can hold roughly 96,000 standard English words 18. But if a user inputs complex medical terminology, raw source code, or a non-Latin language like Arabic, the tokenizer fractures the text 11843. Medical jargon might inflate token counts by 50%, effectively shrinking the usable context window down to 85,000 tokens 1. Once the absolute token limit is breached, the model begins to drop older information, leading to the frustrating phenomenon where an AI suddenly "forgets" foundational instructions provided at the beginning of a long session 4849.
To circumvent this hard mathematical limit, developers employ Retrieval-Augmented Generation (RAG). Instead of pasting a massive, 500-page PDF directly into the prompt (which would exhaust the context window and the token budget), a RAG system uses a vector database to search the document for only the most relevant paragraphs 4850. It then injects those highly specific tokens directly into the LLM's context window alongside the user's question, providing the model with the exact information it needs without overflowing its working memory 48.
From Probabilities to Text: Decoding Strategies
Once the model has ingested the tokenized prompt and processed it through its transformer layers, it must output an answer. However, the model does not output a single, definitive text string; it outputs a massive probability distribution, scoring every single token in its 100,000+ vocabulary on how likely it is to be the next word 51. The process of converting these probabilities back into human-readable text is called "decoding."
If the model simply selected the single most probable token every time - a method known as "greedy decoding" - the resulting text would be incredibly flat, repetitive, and robotic (e.g., getting stuck in loops like "I am sorry I am sorry I am sorry") 51.
To introduce natural variation and creativity, engineers apply sampling algorithms that dictate how the model chooses from the distribution of probabilities 51:
- Top-K Sampling: The model restricts its choice to only the K most likely tokens (e.g., the top 50 choices). It completely ignores all other tokens, preventing it from selecting bizarre or hallucinatory words 51.
- Top-p (Nucleus) Sampling: Instead of a fixed number, the model looks at the cumulative probability. If p is set to 0.90, the model considers only the subset of tokens whose combined probabilities equal 90%. This dynamically adapts: if the model is highly confident, it might only consider 2 tokens; if it is uncertain, it might consider 40 tokens 51.
- Min-p Sampling: A newer, highly effective strategy popular in open-source frameworks. Rather than using a fixed probability mass, Min-p looks at the probability of the absolute top token and sets a dynamic cutoff threshold. If the top token has a 60% probability, and Min-p is set to 0.1 (10%), it throws away any token that has less than a 6% chance (10% of 60%) 51.
- Temperature: This is a mathematical scalar applied to the raw scores (logits) before they are turned into probabilities. A low temperature (e.g., 0.2) sharpens the distribution, making the most likely tokens even more dominant, resulting in strict, analytical output. A high temperature (e.g., 0.9) flattens the distribution, giving lower-probability tokens a higher chance of being selected, which increases creativity but also the risk of hallucinations 51.
Practical Security Implications
Because LLMs respond exclusively to token IDs rather than rendered text, tokenization presents unique vulnerabilities for prompt injection and cybersecurity.
Malicious actors frequently use invisible Unicode characters, homoglyphs (such as a Cyrillic 'a' instead of a Latin 'a'), or zero-width joiners. To a human reviewer looking at a screen, the text appears normal or harmless. However, the tokenizer processes these invisible characters as entirely different numerical tokens, allowing attackers to smuggle hidden instructions into the model 28. For engineers building safety guardrails, it is imperative to inspect the actual token array the model receives, rather than relying on human-readable strings 28.
Bottom line
Large language models do not comprehend human language; they process statistical relationships between numbered, subword tokens. This foundational architecture allows artificial intelligence to compress and generate text at incredible scale, but it creates rigid, structural blind spots. Because tokenizers merge letters into opaque subword chunks, models naturally struggle with character-level reasoning, accurate arithmetic, and strict word counts. Furthermore, the statistical bias of tokenizers imposes a heavy "language tax" on non-Western text, skyrocketing API costs and depleting context windows for billions of global users. While developers are actively mitigating these flaws through larger vocabularies and hidden "reasoning tokens," the fundamental reality of AI remains unchanged: to master these systems, you must first understand the invisible numerical pieces they use to construct the world.