What Fits in an AI Context Window and What It Costs
Modern artificial intelligence models can process millions of tokens in a single request, enabling them to analyze entire codebases, massive legal libraries, or hours of transcribed audio simultaneously. However, simply fitting data into a massive context window does not guarantee accurate retrieval, as models suffer from architectural biases that cause them to ignore or forget information buried in the middle of long documents. To deploy these systems effectively and economically in 2026, organizations must master context caching, cross-encoder reranking, and strategic prompt engineering to mitigate severe cost scaling and attention degradation.
The Reality of Tokenization and Capacity
In 2020, processing a ten-page document within a language model's 4,096-token working memory was considered an industry breakthrough. By mid-2026, the baseline context window for frontier models has shifted dramatically to 1 million tokens, with specialized architectures pushing effective context boundaries to 10 million tokens 123. This massive expansion fundamentally shifts enterprise application architecture, reducing the strict dependency on external vector databases and enabling new reasoning patterns where entire datasets are analyzed in a single forward pass 24.
However, the advertised token capacities of these models do not translate neatly into human-readable word counts. Language models perceive text through tokenization algorithms, most commonly Byte-Pair Encoding (BPE), which iteratively merges the most frequent character pairs into sub-word units 46. Because these algorithms were heavily optimized for English prose, the actual data capacity of a 1-million-token window varies wildly depending on the type of content being processed.
Standard English prose is highly efficient, averaging approximately 1.3 tokens per word 4. At this ratio, a 1-million-token context window can comfortably hold roughly 750,000 words, which is roughly equivalent to the entire Lord of the Rings trilogy and War and Peace combined 478. Technical writing, which is laden with specific jargon, abbreviations, and unique formatting, is slightly less efficient, averaging closer to 1.5 tokens per word 4.
The tokenization math becomes much more punitive when processing code and structured data. Programming languages like Python and JavaScript introduce heavy volumes of syntax, symbols, indents, and mathematical operators. Consequently, source code typically requires 2 to 3 tokens per word, meaning a 1-million-token window might hold a repository of approximately 40,000 lines of code, rather than an entire enterprise backend 24. Structured data formats, specifically JSON and XML, are even more bloated due to the constant repetition of brackets, quotation marks, and structural keys. JSON data averages 3 to 4 tokens per word, making raw database dumps highly inefficient for language model consumption 4.
Multilingual workflows reveal even starker discrepancies, particularly for Chinese, Japanese, and Korean (CJK) text. CJK characters often split into multiple tokens per character, fundamentally altering the economics of using AI in the Asia-Pacific region 49. In a benchmark comparing the translation of a 50-SKU product catalog from English to Traditional Chinese, GPT-4o consumed 23,400 tokens, Claude 3.5 Sonnet consumed 18,900 tokens, and Gemini 1.5 Pro consumed 21,100 tokens. This demonstrates that tokenization efficiency differs radically not just by language, but by the specific model's tokenizer dictionary 9.
Estimated Token Consumption by Data Type
| Content Type | Example | Average Ratio | Capacity in a 1M Token Window |
|---|---|---|---|
| Standard English | "Hello world." | ~1.3 tokens per word | ~750,000 words 4 |
| Technical English | "API endpoint." | ~1.5 tokens per word | ~660,000 words 4 |
| Source Code | def func(): |
~2.0 - 3.0 tokens per word | ~40,000 lines of code 246 |
| JSON / XML Data | {"key":"value"} |
~3.0 - 4.0 tokens per word | ~250,000 words 4 |
| CJK Languages | "你好世界" | ~2.0+ tokens per character | Varies heavily by tokenizer 49 |
The Architecture of Forgetting: The "Lost in the Middle" Phenomenon
While hardware and architectural improvements have enabled models to ingest millions of tokens, they have not fully solved the challenge of recalling that information. Just because a language model accepts a massive prompt does not mean it effectively utilizes the entirety of the text. As context windows expanded, researchers discovered a persistent and severe vulnerability in how attention is distributed over long sequences.
This vulnerability was formally identified in a landmark study by researchers at Stanford University and the University of California, Berkeley, and is now widely known as the "Lost in the Middle" phenomenon 511. Through controlled multi-document question answering and synthetic key-value retrieval tasks, the researchers observed that a model's ability to recall information follows a distinct U-shaped performance curve 51213.
Models exhibit incredibly high accuracy when the relevant information is placed at the very beginning of the context (the primacy effect) or at the very end of the context (the recency effect) 511. However, when critical information is buried in the middle of a long document stack, accuracy drops precipitously, often degrading by 15 to 30 percentage points 1113.
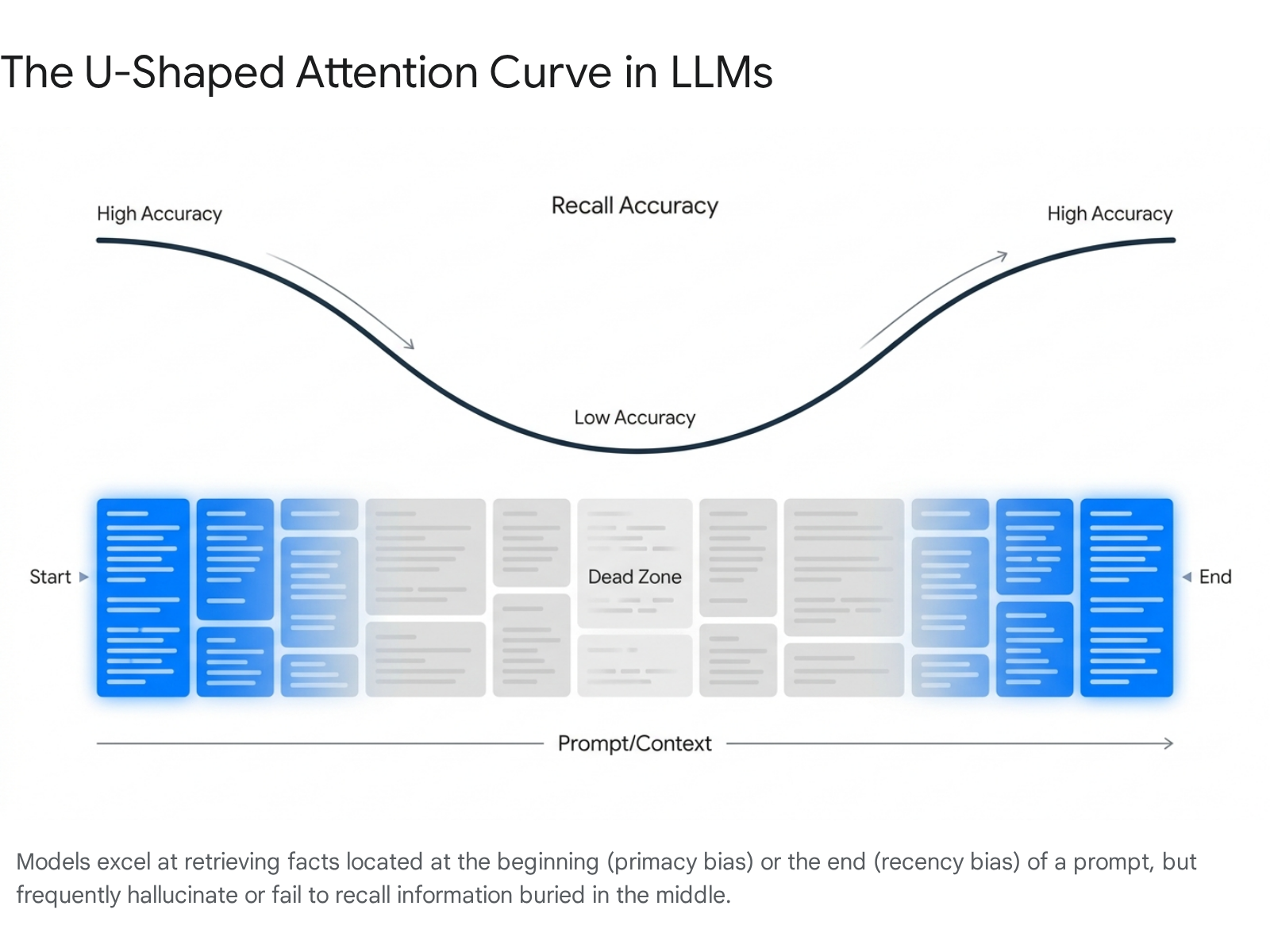
The "Lost in the Middle" effect is not an artifact of poor training data; it is a fundamental structural consequence of how modern Transformer architectures process information. There are three primary mechanisms driving this mid-sequence amnesia.
First, autoregressive models utilize causal masking, ensuring that tokens can only attend to previous tokens to predict the next word. Because the very first tokens in a prompt are visible to every subsequent token across all layers, they serve as "attention sinks." These early tokens attract a disproportionate amount of attention mass regardless of their semantic relevance, naturally brightening the beginning of the context window and establishing the primacy effect 131415.
Second, modern Transformers utilize positional encodings, typically Rotary Position Embedding (RoPE), to provide the model with a sense of token order. RoPE introduces a distance-based decay mechanism. Tokens that are far apart have their attention scores naturally reduced. When a model reaches the end of a 1-million-token prompt and begins to generate an answer, the tokens situated in the middle are too distant to benefit from the recency effect, yet not early enough to serve as foundational attention sinks. They fall into a mathematical dead zone where their Key-Value (KV) cache is accessed less frequently, diminishing their influence on the output 131516.
Third, the effect is compounded by instruction fine-tuning. During the supervised fine-tuning phase, language models are overwhelmingly trained on human-generated examples where the core instruction is placed at the beginning, and the expected answer is positioned at the end. The models implicitly learn to treat the middle of a text block as filler context, further biasing their attention toward the edges 1517. This behavior strikingly mirrors the serial position effect observed in human psychology, where individuals recall the first and last items in a list much better than those in the middle 156.
The practical consequence of this phenomenon is that the effective capacity of an AI model is usually only 60% to 70% of its advertised maximum context window 12. A model claiming a 200,000-token window may reliably utilize only the first and last portions, suffering sudden performance cliffs rather than a smooth degradation when asked to retrieve facts beyond approximately 130,000 tokens 2.
Benchmarking Long-Context Retrieval
To quantify these architectural limitations, researchers and developers have moved beyond simple multiple-choice academic benchmarks, introducing rigorous tests designed specifically for long-horizon recall and agentic reasoning 19.
The original "Needle in a Haystack" (NIAH) test required models to find a single, explicitly inserted fact within a massive block of irrelevant text. However, top-tier models quickly saturated this benchmark. For instance, Google's Gemini 1.5 Pro demonstrated near-perfect recall (over 99.7%) for simple fact retrieval up to 1 million tokens across text, audio, and video modalities 7.
By 2026, evaluations have shifted to much harder metrics. The Multi-Round Co-Reference Resolution (MRCR) test requires models to follow scattered, multi-turn conversational clues over hundreds of thousands of tokens to synthesize an answer 7218. In this domain, the difference between model generations is stark. OpenAI's older GPT-5.4 model suffered a catastrophic collapse in MRCR performance past 128,000 tokens, scoring just 36.6% in the long-context bucket 823. Its successor, GPT-5.5, was heavily optimized for long contexts, maintaining a 74.0% accuracy rate across the 512K to 1M token range, demonstrating significant architectural improvements 823.
More brutal evaluations, such as the "Rusty Needle in a Polluted Haystack" benchmark, test whether models can recover a slightly altered target from a list of near-duplicates while knowing when to abstain if no valid answer exists. In these highly nuanced tests, smaller, highly-tuned models like Gemini 3 Flash and Doubao Seed 2.0 Lite often outperform larger, more confident models that tend to hallucinate or "over-guess" when confronted with ambiguity in long contexts 24.
For enterprise managers, the most critical benchmarks in 2026 evaluate agentic efficiency - the ability of a model to act autonomously over a long context. SWE-bench Verified tests whether models can implement valid code fixes in real Python repositories, requiring them to read multiple files, plan a solution, and pass unit tests 2526. Terminal-Bench 2.0 evaluates models on their ability to execute complex command-line operations and operating system interactions 279. These benchmarks reveal which models can maintain coherent logical states over massive contexts without succumbing to the "Lost in the Middle" decay.
The 2026 Model Landscape: Capabilities and Limits
The AI landscape in mid-2026 is defined by a fierce arms race across context size, retrieval accuracy, and token pricing, resulting in profound market fragmentation where no single model dominates every use case 929.
The OpenAI GPT-5.5 Family
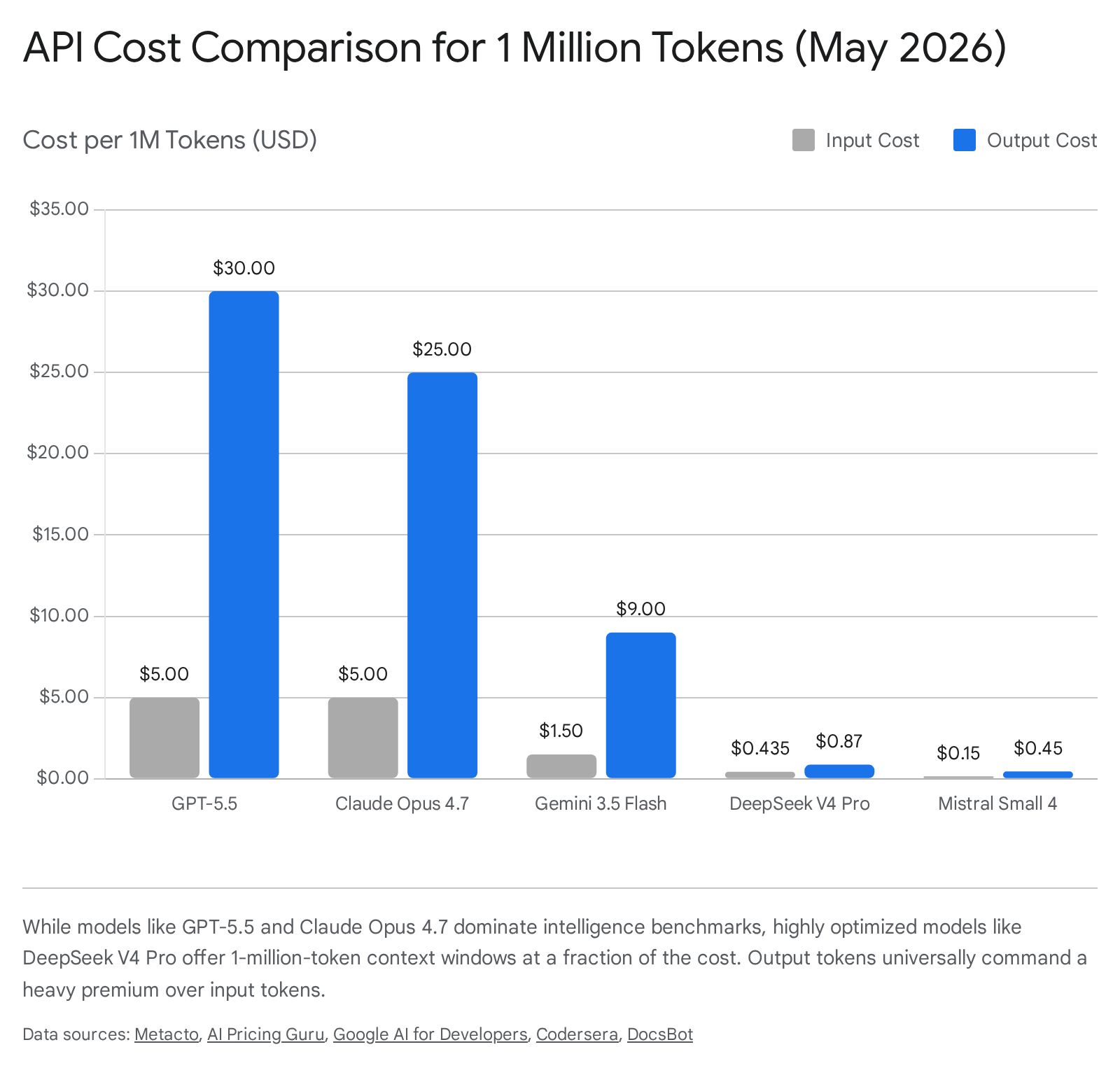
Released in April 2026, GPT-5.5 represents the first complete architectural rebuild of OpenAI's flagship line in two years 30. Available with a 1-million-token context window, it fundamentally resolves the long-context collapse that plagued GPT-5.4 823. GPT-5.5 leads the industry in agentic terminal automation, scoring 82.7% on Terminal-Bench 2.0, making it the premier choice for shell automation, DevOps, and multi-step reasoning 831. The Pro variant adds parallel test-time compute, allowing the model to run multiple reasoning chains simultaneously to achieve a 35.4% success rate on the infamously difficult FrontierMath Tier 4 benchmark 8831. However, this intelligence comes at a steep premium, with GPT-5.5 priced at $5.00 per million input tokens and $30.00 per million output tokens 3233.
Anthropic Claude 4.7 and 4.6
Anthropic's Claude family continues to prioritize robust, consistent codebase analysis and strict instruction adherence. Claude Opus 4.7, also featuring a 1-million-token window, is widely considered the most reliable model for multi-file coding agents, scoring an industry-leading 87.6% on SWE-bench Verified and 64.3% on the contamination-resistant SWE-bench Pro 3134. While GPT-5.5 wins in terminal operations, production reports indicate that Claude Opus 4.7 sustains longer agent traces before reliability decay sets in, making it superior for autonomous software engineering workflows 3110. Anthropic models are also highly optimized for context caching, offering a 90% discount on cached reads, which drops the effective input price of Opus 4.7 from $5.00 to $0.50 per million tokens 3637.
Google Gemini 3.5 Flash and 3.1 Pro
Google maintains dominance in sheer context capacity and multimodal integration. Gemini 3.1 Pro natively supports a 2-million-token window, with capabilities extending to audio, video, and PDF ingestion without relying on external OCR pipelines 3839. The breakout release of 2026, however, is Gemini 3.5 Flash. Built on a sparse mixture-of-experts (MoE) architecture, 3.5 Flash democratizes the 1-million-token window by offering near-frontier intelligence at a fraction of the cost ($1.50 per million input tokens) 3911. It excels in tool orchestration, scoring 83.6% on MCP Atlas multi-step tasks, and achieves over 280 output tokens per second, making it the optimal choice for high-volume, latency-sensitive pipelines 812.
The DeepSeek V4 Revolution
The most economically disruptive model of 2026 is DeepSeek V4. The Pro variant offers a 1.6-trillion-parameter MoE architecture that rivals Claude Opus 4.7 in coding and reasoning tasks, scoring 80.6% on SWE-bench Verified, yet it costs only $0.435 per million input tokens and $0.87 per million output tokens 251314. DeepSeek achieved this massive cost reduction through structural innovations: a hybrid Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) architecture. This design requires only 27% of the inference FLOPs and exactly 10% of the KV cache memory compared to its predecessor, fundamentally altering the price-performance math for 1-million-token inference 211315.
Open-Weight Alternatives: Mistral, Alibaba, and AI21
For organizations requiring data sovereignty, the open-weight market offers highly specialized alternatives. Mistral's Small 4 model unifies reasoning, multimodal, and coding capabilities in a 119B parameter MoE architecture with a 256,000-token context window, priced at an ultra-low $0.15 per million input tokens 454616. Alibaba's Qwen 3 Max pushes efficiency in the Asian market, offering exceptional CJK language processing over a 262,000-token window 4849.
Meanwhile, AI21 Labs has attacked the Transformer architecture directly with Jamba 1.5. Built on a hybrid SSM-Transformer framework, Jamba interleaves traditional attention layers with Mamba state-space layers. Unlike standard Transformers, which require quadratic increases in processing power as context length grows, Mamba layers scale linearly. This allows Jamba to maintain a 256,000-token window while delivering 2.5x the throughput of comparable models and requiring 10x less KV cache memory, bypassing the GPU bottlenecks that traditionally plague long-context deployments 17511853. Furthermore, research suggests that hybrid SSM models inherently compress state over time, potentially reducing the severity of the "Lost in the Middle" phenomenon 654.
The Economics of Memory: Caching vs. Generation
As context windows have expanded, the pricing structures of API providers have evolved to reflect the underlying computational realities. Across the industry, output tokens are universally more expensive than input tokens, typically by a ratio of 4x to 6x, because generating novel text autoregressively requires significantly more compute than reading an existing prompt in parallel 5556.
The most consequential economic development in 2026 is the widespread adoption of context caching (also known as prompt caching). When an AI processes a massive document, it must calculate and store Key-Value (KV) tensors for the entire sequence in the "prefill" stage before it can generate a response 57. Caching allows infrastructure providers to retain these pre-computed tensors in memory. If a user sends the exact same prompt prefix - such as a static corporate policy, a massive codebase, or an intricate set of system instructions - the model bypasses the prefill computation entirely 5758.
Caching reshapes the financial viability of long-context applications. OpenAI, Anthropic, and Google all offer caching discounts that slash the cost of reading repeated inputs by 50% to 90% 375559. For example, under standard pricing, feeding a 100,000-token prompt to Claude Opus 4.7 costs $0.50. If that context is cached, the cost drops to $0.05 3760. DeepSeek V4 Flash takes this further, offering cached input pricing at an astonishing $0.028 per million tokens 13.
Beyond cost, caching significantly improves user experience by reducing the Time to First Token (TTFT). Research benchmarking agentic workflows demonstrates that prompt caching improves TTFT by 13% to 31%, accelerating the responsiveness of AI systems analyzing static repositories 57. Without context caching, executing multi-step agent loops against a 1-million-token codebase is economically unworkable. With it, static context becomes virtually free after the first read 356.
Cost and Context Specifications by Model (May 2026)
| Model | Context Limit | Input ($/1M) | Output ($/1M) | Cached Input ($/1M) |
|---|---|---|---|---|
| GPT-5.5 Pro | 1,000,000 | $30.00 | $180.00 | N/A |
| GPT-5.5 | 1,000,000 | $5.00 | $30.00 | $0.50 |
| Claude Opus 4.7 | 1,000,000 | $5.00 | $25.00 | $0.50 |
| Claude Sonnet 4.6 | 1,000,000 | $3.00 | $15.00 | $0.30 |
| Gemini 3.1 Pro | 2,000,000 | $2.00 / $4.00* | $12.00 / $18.00* | ~90% discount |
| Gemini 3.5 Flash | 1,000,000 | $1.50 | $9.00 | $0.15 |
| DeepSeek V4 Pro | 1,000,000 | $0.435 | $0.87 | ~$0.04 |
| Mistral Small 4 | 256,000 | $0.15 | $0.45 | N/A |
| Qwen 3 Max | 256,000 | $1.20 | $6.00 | $0.156 |
*Gemini 3.1 Pro pricing doubles for contexts exceeding 200,000 tokens 3861.
RAG vs. Long Context: The New Paradigm
Before 2025, the strict limitations on context windows forced developers to rely almost entirely on Retrieval-Augmented Generation (RAG). RAG architectures work by slicing large documents into small "chunks," storing them in a vector database, performing semantic search against a user's query, and passing only the top handful of relevant chunks into the AI's prompt 458.
With models now capable of ingesting millions of tokens natively, a common misconception is that RAG is obsolete. However, industry adoption proves otherwise; the two strategies have bifurcated to solve different problems, dictated by constraints on cost, latency, and retrieval accuracy 3.
Context Caching is superior when: * The corpus is massive but static: Analyzing an entire codebase, a set of financial regulations, or a long-running chat history is highly efficient with caching. Once the initial 1-million-token payload is processed, subsequent queries against that exact data are cheap and lightning-fast 356. * The task requires holistic reasoning: Questions like "What is the overarching thematic shift in this author's 10-book series?" cannot be answered by RAG. Semantic search only retrieves isolated paragraphs containing keywords; it cannot synthesize broad concepts that span the entirety of a text. Deep reasoning requires passing the whole document into the model simultaneously 3.
RAG is superior when: * The dataset exceeds 2 to 5 million tokens or updates constantly: If an enterprise needs to query a continuously updating intranet or a multi-terabyte database, loading it into an AI context window is computationally impossible. RAG is mandatory for infinite scale and dynamic data 3. * Precision and budget are strict constraints: Running semantic search to extract 2,000 highly relevant tokens is mathematically cheaper and faster than forcing a frontier model to read 200,000 tokens of raw context to find the exact same answer. Furthermore, RAG provides explicit auditability, allowing systems to easily cite the specific source chunk used for generation 362. * Combating positional bias: By filtering a massive dataset down to only 3 to 5 highly relevant documents, RAG effectively eliminates the "Lost in the Middle" problem. The AI is not distracted by hundreds of pages of irrelevant filler 1663.
Context Engineering: Mitigating the Bias
Because the "Lost in the Middle" decay is baked into the architecture of modern Transformers, it cannot be fixed by simply writing a clever prompt. Resolving this issue requires "Context Engineering" - the practice of treating the prompt as a dynamic, highly structured data pipeline rather than a static text box 6465.
If an organization is building production systems handling long contexts in 2026, the data indicates that four specific engineering techniques measurably mitigate positional bias and improve overall accuracy:
- Strategic Document Ordering: The simplest and most effective mitigation is to avoid feeding data to the model in chronological or alphabetical order. In advanced RAG pipelines, developers use cross-encoder reranking models to evaluate the retrieved documents. The absolute highest-confidence documents should be explicitly injected at the very beginning and the very end of the prompt context, deliberately exploiting the model's primacy and recency biases. Irrelevant or lower-confidence documents should be buried in the middle 131516.
- Aggressive Context Reduction: Sending more context actively harms a model's performance if the supplementary information is not highly relevant. Research indicates that systems should retrieve generously during the initial search phase to cast a wide net, but then filter aggressively during reranking. Keeping only the top 3 to 5 most relevant documents in the final prompt dramatically increases accuracy by reducing the noise that dilutes attention 1516.
- Prompt Compression and Hierarchical Summarization: Instead of dumping raw, unedited transcripts or endless code files into a flagship model, sophisticated systems use smaller, cheaper models (or specialized tools like LLMLingua) to compress text. In hierarchical summarization, a long document is chunked into sections, each section is summarized independently, and only the condensed meta-summaries are passed to the expensive reasoning model. This shrinks the context footprint while preserving the critical narrative 155964.
- Isolating Constraints: Because a model's attention dilutes over a massive window, critical system instructions - such as "Output only in valid JSON format" or "Do not use external libraries" - are frequently forgotten if they are placed at the beginning of a long prompt. To ensure compliance, these core constraints must be injected dynamically at the very end of the prompt, immediately before the model begins generating its response. This guarantees the rules benefit from recency bias 2965.
Bottom line
The AI industry has successfully shattered the context window barrier, expanding from thousands of tokens to capacities capable of ingesting millions of words simultaneously. However, assuming an AI model functions as a perfect database is a critical error; structural biases like the "Lost in the Middle" phenomenon guarantee that models will occasionally ignore or hallucinate data buried deep within a prompt. The most successful AI deployments in 2026 combine massive capacity with rigorous context engineering - leveraging cross-encoder reranking, exploiting prompt caching for 90% cost reductions, and recognizing that while a model can process a million tokens, its attention remains inextricably drawn to the edges.