Impact of Tokenization on Large Language Models
Mechanics of Language Model Tokenization
Tokenization serves as the foundational preprocessing layer of modern large language models, dictating the fundamental boundaries of how artificial neural networks perceive natural language. Before a transformer architecture can process text, the raw string of characters must be systematically transformed into a discrete sequence of numerical identifiers 123. Language models operate entirely through mathematical operations on high-dimensional vector spaces; they possess no inherent understanding of syntax, orthography, or character relationships 456. Consequently, the tokenization process defines the absolute atomic units of the model's linguistic universe. The segmentation boundaries established by a given tokenizer constrain downstream performance, computational efficiency, multilinguality, and logical reasoning capabilities 27.
The pipeline from raw text to computable inputs involves three distinct phases: text segmentation, integer vectorization, and dense vector embedding 238.
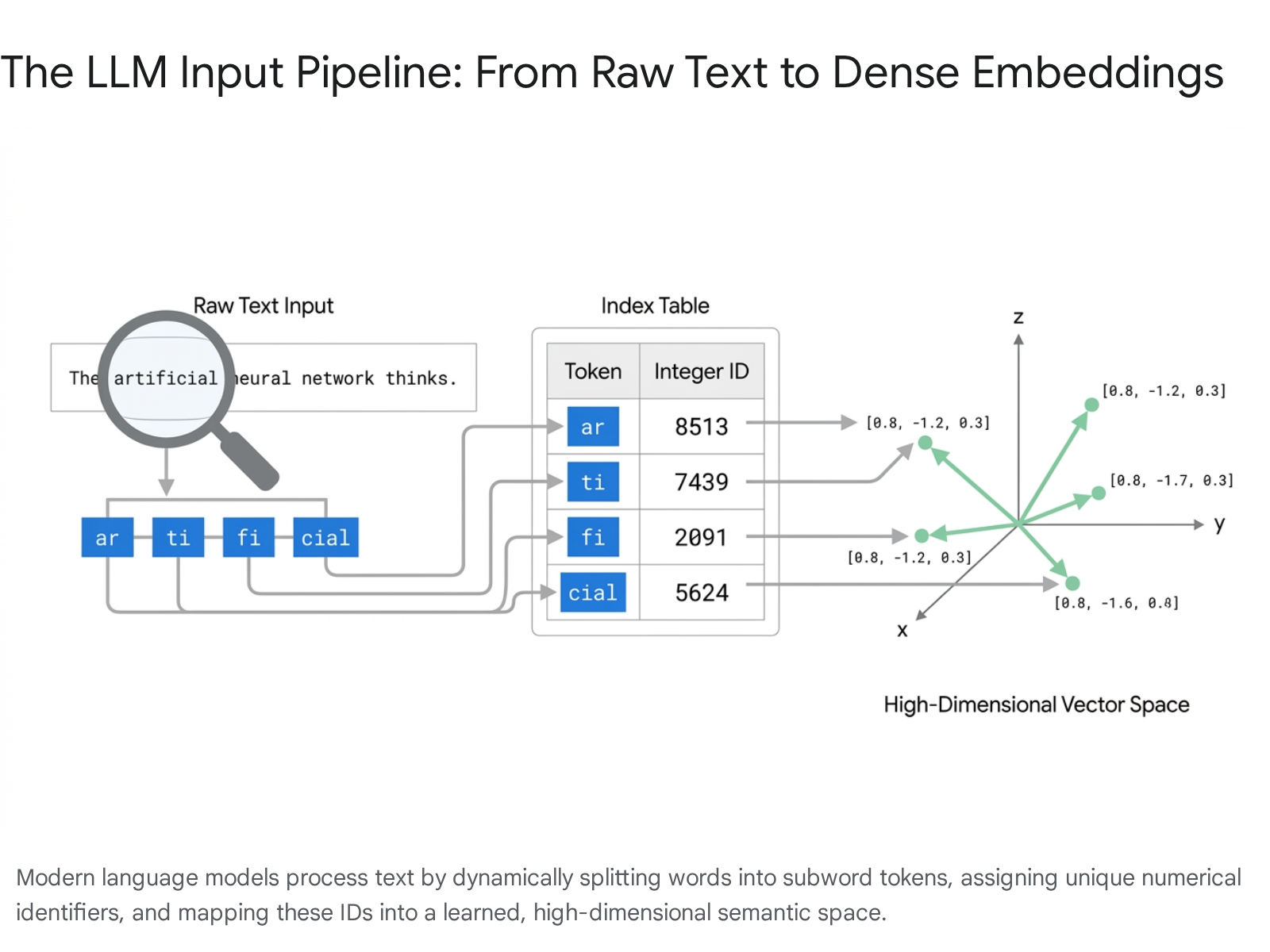
Initially, raw text is partitioned into smaller constituent chunks, known as tokens, utilizing a predefined statistical algorithm 19. Depending on the specific tokenizer architecture, a token may encompass an entire word, a morphological subword, a single character, or an individual raw byte 1910.
Following segmentation, each discrete token is mapped to a unique integer identifier corresponding to its exact index within the tokenizer's fixed, pre-compiled vocabulary 389. For example, the complex word "untokenizable" might be fractured into the subword components "un", "token", and "izable", which are subsequently assigned arbitrary integer identifiers from the vocabulary matrix 3.
The final, mathematically critical step is the projection of these integer identifiers into dense, continuous vectors known as embeddings. The embedding layer functions as an expansive lookup matrix, with dimensions determined by the total vocabulary size multiplied by the model's chosen hidden dimension parameter 811. An embedding captures profound semantic relationships, grammatical roles, and contextual nuances learned iteratively during the model's pretraining phase 1. During this phase, models learn to map tokens with similar semantic weight into close proximity within the multi-dimensional embedding space 68. Ultimately, the tokenization protocol directly governs the granularity and structural integrity of the semantic representations the language model relies upon for text generation and comprehension.
Evolution of Subword Algorithms and Vocabulary Architectures
Historically, natural language processing frameworks relied primarily on word-level or character-level tokenization paradigms. Word-level tokenization preserves high semantic value but suffers from catastrophic out-of-vocabulary rates 37. To accommodate conjugation, varying punctuation, and morphological richness, word-level tokenizers require unmanageably large vocabulary matrices 37. Conversely, character-level tokenization resolves the out-of-vocabulary problem by utilizing a highly constrained vocabulary restricted to individual letters and symbols, but it heavily inflates the sequence length of the input data 7. Because the computational cost of the transformer's self-attention mechanism scales quadratically relative to sequence length, character-level processing rapidly exhausts memory buffers and severely limits the model's capacity to learn long-range semantic dependencies 71213.
Modern large language models bridge this operational gap by utilizing subword tokenization algorithms, most notably Byte-Pair Encoding and its advanced variants such as WordPiece and SentencePiece 231415. Adapted for neural machine translation in 2016, Byte-Pair Encoding relies fundamentally on data compression principles 314. The algorithm initializes with a base vocabulary of individual characters or raw bytes, then iteratively scans a massive reference training corpus to identify the most frequently occurring adjacent pairs of symbols. The most statistically common pair is merged into a single new subword symbol, which is permanently added to the evolving vocabulary 215. This greedy merging process repeats iteratively until the vocabulary expands to a predetermined target size 2315.
The result is a highly efficient linguistic representation. Common, high-frequency elements are preserved intact as single tokens, ensuring computational efficiency 35716. Simultaneously, rare, complex, or entirely unknown words are fragmented into recognizable subword pieces 317. By operating at the foundational byte level, modern tokenizers ensure that any arbitrary string of text - including executable code snippets, emojis, mathematical formatting, and non-Latin scripts - can be encoded losslessly without returning a definitive out-of-vocabulary error 31617.
The selection of a tokenizer's overall vocabulary size introduces a profound architectural trade-off regarding model parameters and computational overhead. Smaller vocabularies result in fewer neural network parameters required for the embedding and prediction layers, but they generate longer, highly fragmented token sequences, thereby inflating inference computation costs 14. Larger vocabularies compress text more efficiently into fewer tokens, allowing models to process more contextual information within their fixed context windows 14. However, vast vocabularies demand massive embedding matrices. For example, specific commercial architectures utilizing a hidden dimension of 12,288 alongside a sprawling vocabulary of 256,000 tokens require approximately 6.3 billion model parameters solely dedicated to maintaining the embedding and prediction layers 14.
Despite this immense parameter cost, the trajectory of artificial intelligence engineering has aggressively favored larger vocabularies to maximize compression rates, reduce sequence length, and enhance multilingual representation.
| Model Architecture | Tokenizer Implementation | Approximate Vocabulary Size | Primary Tokenization Algorithm | Architectural Notes |
|---|---|---|---|---|
| GPT-3 / GPT-3.5 | r50k_base / p50k_base |
50,257 | Byte-Pair Encoding (BPE) | Early generation tokenizer architecture utilized for OpenAI Codex and the original GPT-3 series 32018. |
| GPT-4 / GPT-4 Turbo | cl100k_base |
100,256 | Byte-Pair Encoding (BPE) | High-speed tokenizer implemented via the open-source tiktoken library. Highly optimized for English prose and code generation 161819. |
| GPT-4o / o1 / o3 | o200k_base |
199,997 | Byte-Pair Encoding (BPE) | Substantially improves compression across non-English scripts, averaging four characters per token in English text 161719. |
| Llama 1 / Llama 2 | Custom SentencePiece | 32,000 | SentencePiece (BPE) | Features a constrained vocabulary that struggled with out-of-domain text and non-Latin scripts 15. |
| Llama 3 / 3.1 | Custom TikToken | 128,256 | Byte-Pair Encoding (BPE) | Integrated 100,000 standard tokens and 28,000 dedicated non-English tokens, yielding a 15% reduction in token sequence lengths compared to previous iterations 202122. |
| Mistral / Mixtral | Tekken | 131,072 | Byte-Pair Encoding (BPE) | Expanded vocabularies explicitly designed to support multilingual deployment efficiently across European languages 1523. |
| Aya-Expanse | Custom Multilingual | 255,029 | Byte-Pair Encoding (BPE) | Massively expanded vocabulary engineered to force token parity across diverse global languages 24. |
Table 1: Vocabulary Size and Tokenizer Architecture Across Modern Large Language Models 151618192021222324.
Sublexical and Structural Processing Limitations
While subword tokenization elegantly balances the rigid computational constraints of transformer self-attention mechanisms with the semantic richness of natural language, the methodology fundamentally obscures the internal structure of words from the model's perception 11. Because the language model only evaluates sequences of integer identifiers referencing atomic subword units, it lacks inherent awareness of character counts, morphological roots, acoustic phonology, and numerical positional notation 1128.
Character-Level Manipulation and Orthographic Failures
A thoroughly documented failure mode across leading language models is their inability to reliably perform character-level manipulation or rigorous orthographic analysis. This representational deficiency is popularly characterized by the "strawberry problem," a pervasive phenomenon wherein highly capable models consistently miscalculate the number of 'r' characters in the word "strawberry" 625.
This specific error arises because the model does not ingest the literal string sequence of characters. Depending on the exact Byte-Pair Encoding vocabulary utilized, the word is segmented into discrete tokens. OpenAI's implementations may split the word into ["straw", "berry"] or further into ["Str", "aw", "berry"] 62825. Within the high-dimensional embedding space, these individual tokens represent broad semantic concepts such as fruit, sweetness, and the color red, rather than phonetic boundaries or orthographic character clusters 628. Consequently, when tasked with counting characters, the model must deduce the internal composition of a token based entirely on statistical associations absorbed during pretraining, rather than programmatically inspecting the string array 2825.
This representational gap causes significant brittleness in tasks demanding precise sub-lexical accuracy. Determining whether a word contains double letters, generating exact acronyms, reversing strings, and spelling complex words backwards consistently fall outside the natural scope of subword embeddings 2825. Furthermore, the probabilistic text generation mechanisms of transformers inherently prioritize predicting the most statistically likely semantic continuation. This leads models to frequently sacrifice strict orthographic and formatting accuracy in favor of contextual plausibility, resulting in hallucinations of spelling when forced into constrained formatting requirements 630. Subword regularization techniques, such as BPE-dropout during training, can marginally improve resilience to typographical variation, but the fundamental blindness to character structures remains a persistent structural limitation 1130.
Deficiencies in Mathematical and Arithmetic Reasoning
Language models notoriously struggle with mathematical calculations and multi-step quantitative reasoning, not because their underlying neural architectures inherently lack the capacity for logic, but because their input mechanism shatters numerical data unpredictably 5. Tokenizers are engineered to compress human language by grouping highly frequent character sequences, but numerical strings do not follow the morphological or syntactic rules of natural language text 5.
When processing numbers, a subword tokenizer parses the input arbitrarily based on training data frequency rather than mathematical significance 5. A highly frequent number like "100" or "2024" likely exists as a single, distinct token within the vocabulary, allowing the model to process it cohesively. Conversely, an arbitrary large integer, such as "87439," might be fragmented into ["874", "39"], or even reduced to individual character tokens 5.
This unstructured numerical tokenization permanently destroys positional notation. The tokenizer's assignment of abstract integer IDs to these numerical fragments strips away any inherent quantitative semantics or scale 5. To the model, the token representing the string "874" is an abstract mathematical entity devoid of inherent magnitude, functionally indistinguishable in the embedding layer from the tokens corresponding to words like "apple" or "cloud" 5. As a result, the model must attempt to execute complex arithmetic by mimicking statistical text patterns observed in the training corpus rather than by applying the deterministic, axiomatic rules of addition or multiplication 531. Rare numbers trigger unfamiliar token combinations, resulting in cascading logical failures, misintegration of problem constraints, and the hallucination of non-existent mathematical features during complex reasoning chains 532.
Constraints on Phonological Processing and Rhyming
Subword tokenization is exclusively optimized for the efficient statistical modeling of written graphemes within a massive text corpus; it rarely aligns with the linguistically meaningful phonological or syllabic units of spoken language 2627. Because Byte-Pair Encoding greedily merges characters based strictly on textual frequency, the resulting tokens arbitrarily cross phonetic syllable boundaries and strip away the underlying acoustic properties of the word 2627.
Extensive evaluations utilizing phonological benchmarks demonstrate that language models perform sub-optimally compared to human baselines on tasks requiring direct phonemic awareness, including grapheme-to-phoneme conversion, precise syllable counting, and complex rhyme generation 262728. Research indicates a substantial gap in capability: models exhibit significantly higher accuracy on phonological tasks when the target vocabulary serendipitously aligns with whole-word tokens, compared to instances where the target words are fragmented into split-word tokens 26. The profound disconnection between written subword embeddings and acoustic realities severely impedes the reliable deployment of text-only models in poetry generation, speech-synthesis reasoning tasks, and accurate phonetic transcription applications without targeted architectural interventions 2627.
The Multilingual Token Tax and Infrastructure Bias
The frequency-based, statistical nature of Byte-Pair Encoding introduces severe technical and economic inequities when models are deployed across global languages. Tokenizer vocabularies are heavily biased by their reference training corpora, which are overwhelmingly composed of English texts and specialized programming code 2329. As a consequence, tokenizers aggressively optimize subwords for English syntax, allocating the vast majority of their vocabulary slots to English morphological patterns while marginalizing low-resource languages 243031.
Quantifying Disparities Through Token Fertility
The primary metric utilized in computational linguistics for measuring the efficiency of a tokenizer across different languages is "token fertility," which is formally defined as the average number of subword tokens required to accurately represent a single semantic word unit 12233139.
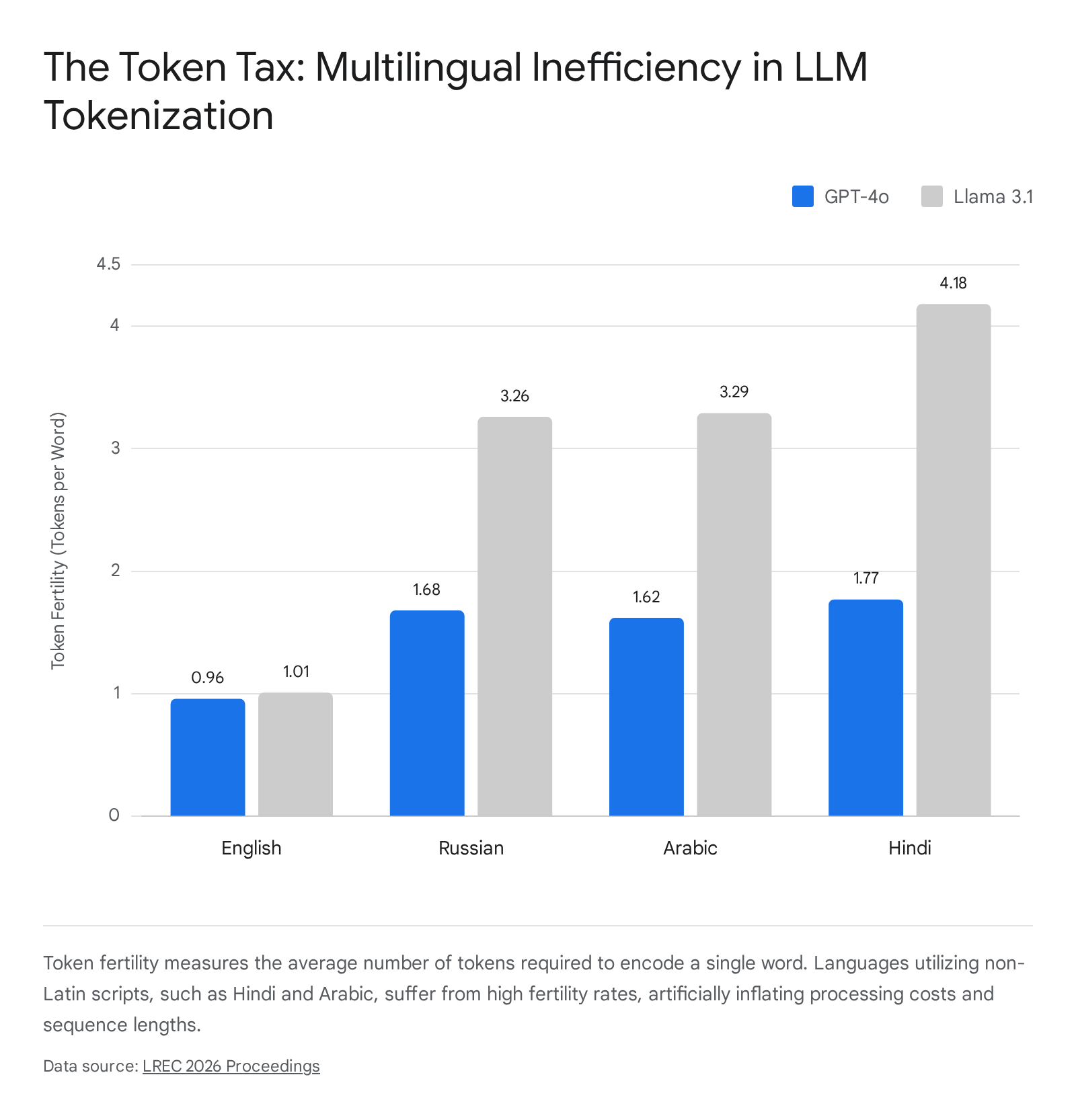
For high-resource languages like English, modern tokenizers generally maintain a highly efficient fertility rate near 1.0 to 1.4, indicating that most common words map cleanly to one or two tokens 2440.
However, for languages featuring rich morphology, including agglutinative languages such as Swahili, Zulu, or Turkish, as well as languages utilizing non-Latin scripts like Arabic, Korean, and Hindi, token fertility spikes dramatically 7123132. Complex abugida writing systems are particularly vulnerable; a single semantic word in Malayalam or Telugu may be shattered into six or more distinct, meaningless tokens 303142. In many cases, these languages break down to individual bytes or erratic fragments purely because their script was critically underrepresented during the tokenizer's initial training phase 3132.
| Linguistic Classification | Language | GPT-4o Token Fertility | Llama 3.1 (8B) Token Fertility | Analytical Notes |
|---|---|---|---|---|
| High-Resource Latin | English | 0.96 | 1.01 | Serves as the base reference; benefits from highly optimized single-token mappings. |
| High-Resource Latin | Spanish | ~1.10 | ~1.15 | Closely mirrors English token distribution and compression efficiency. |
| Cyrillic Script | Russian | 1.68 | 3.26 | Cyrillic text fragments heavily in Llama 3 compared to the expanded vocabulary of GPT-4o. |
| Abugida Script | Hindi | 1.77 | 4.18 | Suffers severe fragmentation due to complex combining marks and codepoint splits. |
| Connected Script | Arabic | 1.62 | 3.29 | High fertility driven by complex morphology and specific orthographic constraints. |
| Low-Resource Indo-Aryan | Urdu | 1.60 | 3.50+ | Morphologically complex and historically low-resource in massive pretraining corpora. |
Table 2: Comparative Token Fertility Ratios Across Selected Languages and Model Tokenizers 23403334.
Computational and Economic Consequences
The phenomenon of high token fertility across non-English texts directly translates into a systemic infrastructure bias widely categorized in computational linguistics as the "Token Tax" 123045. Because commercial LLM API providers price their services strictly by the total volume of tokens processed for inputs and outputs, native speakers of high-fertility languages are economically penalized 121830. Translating token inflation directly to economics, the financial cost required to generate the exact same semantic paragraph in languages like Telugu or Amharic can be between three and six times more expensive than generating it in English 123046.
Beyond financial penalties, extreme token inflation cripples computational efficiency and hardware utilization. The memory footprint, latency, and overall compute demands of the transformer's self-attention mechanism scale quadratically ($O(n^2)$) relative to the length of the token sequence 1235. Consequently, a language presenting a token fertility of 2.0 does not merely double the processing time; it theoretically quadruples the required computational resources, memory bandwidth, and associated energy emissions during both the training and inference phases 123548.
High fertility also tangibly degrades the effective context window and ultimate model accuracy. A fixed context window of 8,192 tokens can hold extensive software documentation in English, but it may only process a fraction of that exact same material in Burmese or Zulu before catastrophically truncating the input 213032. Extensive evaluations across massively multilingual benchmarks, such as AfriMMLU, consistently reveal that high token fertility operates as a reliable, negative predictor of downstream LLM accuracy and reasoning capabilities 124535. Subword fragmentation forces the model to expend substantial attention-head capacity merely attempting to reassemble cohesive words from disparate character pieces, rather than engaging in higher-order semantic reasoning or following complex instructions 731. Researchers have observed that reasoning-focused models, which allocate more computation time during generation, can partially mitigate this accuracy gap, but the structural inefficiencies persist 1235.
Security Vulnerabilities Originating from Tokenization
The structural disconnect between the algorithms utilized to construct a tokenizer vocabulary and the algorithms used to train the language model's parameters introduces specific, highly exploitable blind spots within the neural network. Because the tokenizer vocabulary is rigorously fixed before the LLM begins its foundational training phase, the model is forced to map deep semantic representations onto tokens it may rarely - or completely never - encounter within its curated training corpus.
Glitch Tokens and Vocabulary Blind Spots
In 2023, security researchers uncovered a highly disruptive class of anomalous inputs formally designated as "glitch tokens" 495051. The most canonically cited example of this phenomenon is the token string SolidGoldMagikarp 50513653. This string was initially scraped into the vocabulary of the GPT-2 and GPT-3 tokenizers because it frequently appeared as an active username within a specific, highly repetitive Reddit community dedicated to sequential counting 5153. However, the actual text corpus utilized to train the subsequent language model parameters systematically excluded that specific forum data to prioritize higher-quality text 5153.
As a direct result of this dataset discrepancy, the high-dimensional embedding vector associated with the SolidGoldMagikarp token ID was initialized but never meaningfully updated through gradient descent during the model's pretraining phase 515354. The token essentially became a "dead zone" in the model's mathematical representation space 51. When users prompted the model to process, repeat, or explain this specific token, the LLM attempted to execute complex linguistic logic over an untrained, noisy vector. This resulted in highly erratic and unpredictable behavior. The model would output hallucinatory gibberish, hurl unexpected insults, generate policy-violating text, or default to completely unrelated concepts (for example, outputting the word "distribute" in place of the input string) 4950515355.
Research subsequent to the initial SolidGoldMagikarp discovery has utilized gradient-based discrete optimization frameworks, such as GlitchMiner, to automatically mine models for these anomalies 4956. Studies have successfully identified thousands of these untrained tokens clustering in the remote embedding spaces of major commercial and open-weights models 495157. Glitch tokens pose a serious alignment and safety risk because they fundamentally disrupt semantic comprehension, allowing deterministic, erratic failures to be triggered by seemingly innocuous input strings 495355.
Adversarial Token Boundary Manipulation and Filter Evasion
The rigid and predictable nature of tokenizer boundaries provides a highly effective vector for adversarial exploitation, particularly in the context of bypassing automated safety filters and alignment guardrails 585960. Standard safety classifiers, keyword blacklists, and internal alignment prompt-injections rely heavily on the assumption that specific harmful concepts will reliably trigger recognized token IDs (e.g., the specific token assigned to "bomb" or "methamphetamine") 5159.
Attackers explicitly exploit subword algorithms using token boundary attacks. By strategically inserting spaces, zero-width characters, or homoglyphs (visually identical Unicode characters sourced from different scripts, such as Cyrillic), a threat actor can force the tokenizer to slice a strictly prohibited word into unfamiliar, fragmented tokens 596061. For example, injecting a specific character combination might break a restricted keyword into benign fragments like ["synt", "he", "size"] 5960.
Because the safety filter evaluates the input at the token ID level rather than analyzing the raw string text, the fragmented IDs successfully evade the blacklist and enter the model 5159. However, the deeper layers of the transformer, which utilize sophisticated context and self-attention, often piece the semantic meaning of the fragments back together, successfully generating the restricted or harmful content 596061. Studies measuring character-level adversarial robustness reveal that these techniques reduce refusal rates by up to 22% across modern frontier models 61. Furthermore, advanced techniques like Seamless Spurious Token Injection (SSTI) allow attackers to weaponize special control tokens (such as <SEP> or end-of-sequence markers) to alter how the LLM determines the boundary between user input and overarching system instructions, effectively hijacking the model's internal control flow and decision-making logic 62.
Post-Tokenization Architectures and Future Paradigms
The compounding technical constraints of the multilingual token tax, sublexical processing failures, and token-level security vulnerabilities have spurred intense research into tokenizer-free architectures. Operating directly on the absolute fundamental representation of digital text - raw bytes - eliminates the need for predefined, static vocabularies. This architectural shift inherently resolves the out-of-vocabulary problem, ensures equitable processing across diverse global languages, and provides innate resistance to spelling errors and complex token boundary attacks 101314.
The Challenge of Byte-Level Processing and Dynamic Patching
Historically, training LLMs directly on individual bytes was deemed computationally unfeasible due to the severe sequence length explosion it causes. A single English word requires an average of 4.7 characters, meaning a strictly byte-level transformer would process sequences roughly five times longer than a standard BPE-tokenized model 13. Given the quadratic scaling of attention computation relative to sequence length, pure byte-level LLMs were prohibitively expensive to train and deploy at scale 101314.
Recent architectural innovations aim to overcome this fundamental scaling limitation by decoupling the sequence length from the model's overall depth. Instead of relying on static token assignments, researchers are implementing dynamic patching mechanisms. This sophisticated approach feeds raw bytes through a lightweight, localized encoder network that groups consecutive bytes into variable-length "patches" before passing them to the primary, computationally heavy global transformer 106337.
The Byte Latent Transformer
A prominent and successful example of this paradigm shift is the Byte Latent Transformer (BLT), an architecture developed by researchers at Meta and the University of Washington 101365. The BLT abandons static tokenization entirely. It models language directly from the raw byte stream and utilizes an advanced entropy-based patching algorithm to dynamically group bytes based on informational density 6365.
The BLT system continuously calculates the predictability, or entropy, of the incoming byte sequence. When the sequence is highly predictable (presenting low entropy, such as the middle characters of a common word or a long string of whitespace), the BLT aggressively groups many bytes into a single, long patch 6365. Conversely, when the input is complex, unpredictable, or highly information-dense (presenting high entropy), the model forms much smaller, granular patches 6365.
This dynamic allocation ensures that the model expends intensive computational resources only where the data complexity actually demands it, strictly conserving processing FLOPs on trivial or highly predictable sequences 101365. Empirical evaluations of the Byte Latent Transformer demonstrate that, when operating under compute-optimal training regimes, these byte-level models can match or even exceed the scaling behavior of state-of-the-art token-based models like Llama 3 136566. Tokenizer-free architectures exhibit superior performance on character-level manipulation tasks, enhanced robustness to noisy or heavily misspelled inputs, and significantly improved modeling of the "long tail" of low-resource languages. These results strongly suggest a viable, near-term pathway to eliminating the architectural bottleneck of tokenization entirely, yielding more universally capable foundation models 10131465.