Computational mechanisms of artificial intelligence reasoning
Theoretical Foundations of Inference-Time Computation
The evolution of large language models has increasingly prioritized the transition from immediate, autoregressive text generation to extended, deliberative computation. This architectural and operational shift is frequently conceptualized through the lens of dual-process theory, mapping classical machine learning pattern recognition to what cognitive psychology terms "System 1" cognition - fast, intuitive, and heuristic-driven - while classifying step-by-step intermediate token generation as "System 2" cognition - slow, analytical, and logically structured 123356. While this anthropomorphic framework provides a highly accessible metaphor for human-computer interaction, researchers argue that it obscures the fundamental mathematical and computational reality of how these models operate 567.
At a mechanistic level, artificial intelligence reasoning is not an emergent form of biological cognition but a pragmatic scaling of test-time computation. Standard language models operate by predicting the most probable next token based on a single forward pass through a neural network 678. When models are required to output an immediate answer to a complex mathematical or logical query, they are forced to resolve highly non-linear, multi-step dependencies within a fixed computational budget dictated by the network's architectural depth 94. By forcing the model to generate a sequence of intermediate tokens - commonly known as a chain of thought or a reasoning scratchpad - the model effectively bypasses the static depth limitations of its architecture, leveraging the autoregressive loop to simulate sequential, stateful computation 9111213.
This reliance on intermediate tokens highlights a profound structural difference between human and machine reasoning. Human reasoning is often independent of explicit verbalization, occurring as internal abstraction before output. Conversely, large language models rely on explicit tokenization to reallocate probability distributions 58. The resulting textual traces, while legible as logical steps, serve primarily as a computational scaffolding mechanism that enables the model to access deeper complexity classes than a single network pass allows.
Circuit Complexity and Transformer Depth Limitations
The computational necessity of intermediate token generation can be rigorously explained through the framework of Boolean circuit complexity. Theoretical analyses of transformer architectures reveal that decoder-only transformers with a fixed number of layers are strictly bounded in their computational expressivity. Specifically, fixed-depth transformers belong to the $\mathsf{TC}^0$ complexity class, which consists of constant-depth Boolean circuits equipped with AND, OR, NOT, and unbounded fan-in threshold (MAJORITY) gates 9411.
Models operating within the $\mathsf{TC}^0$ class excel at highly parallelizable tasks, such as standard language modeling, factual retrieval, and pattern classification 912. However, they are mathematically incapable of executing inherently sequential operations, such as tracking states in a finite automaton, calculating modular parity, or resolving multi-hop logical dependencies across long contexts in a single forward pass 9412. When a transformer attempts to map a complex input directly to a final answer, the number of sequential operations it can perform is strictly limited by its layer count. For tasks that require sequential dependencies where each step relies explicitly on the output of the previous step, parallel processing yields catastrophic logical failures.
The introduction of intermediate tokens fundamentally alters this computational bound. By allowing a model to generate a sequence of $T$ reasoning tokens before yielding a final answer, the effective depth of the computation scales linearly with the number of generated tokens. This autoregressive unrolling elevates the transformer's capacity from $\mathsf{TC}^0$ to polynomial-time complexity ($\mathsf{P/poly}$), enabling the simulation of arbitrary polynomial-size Boolean circuits 111213.
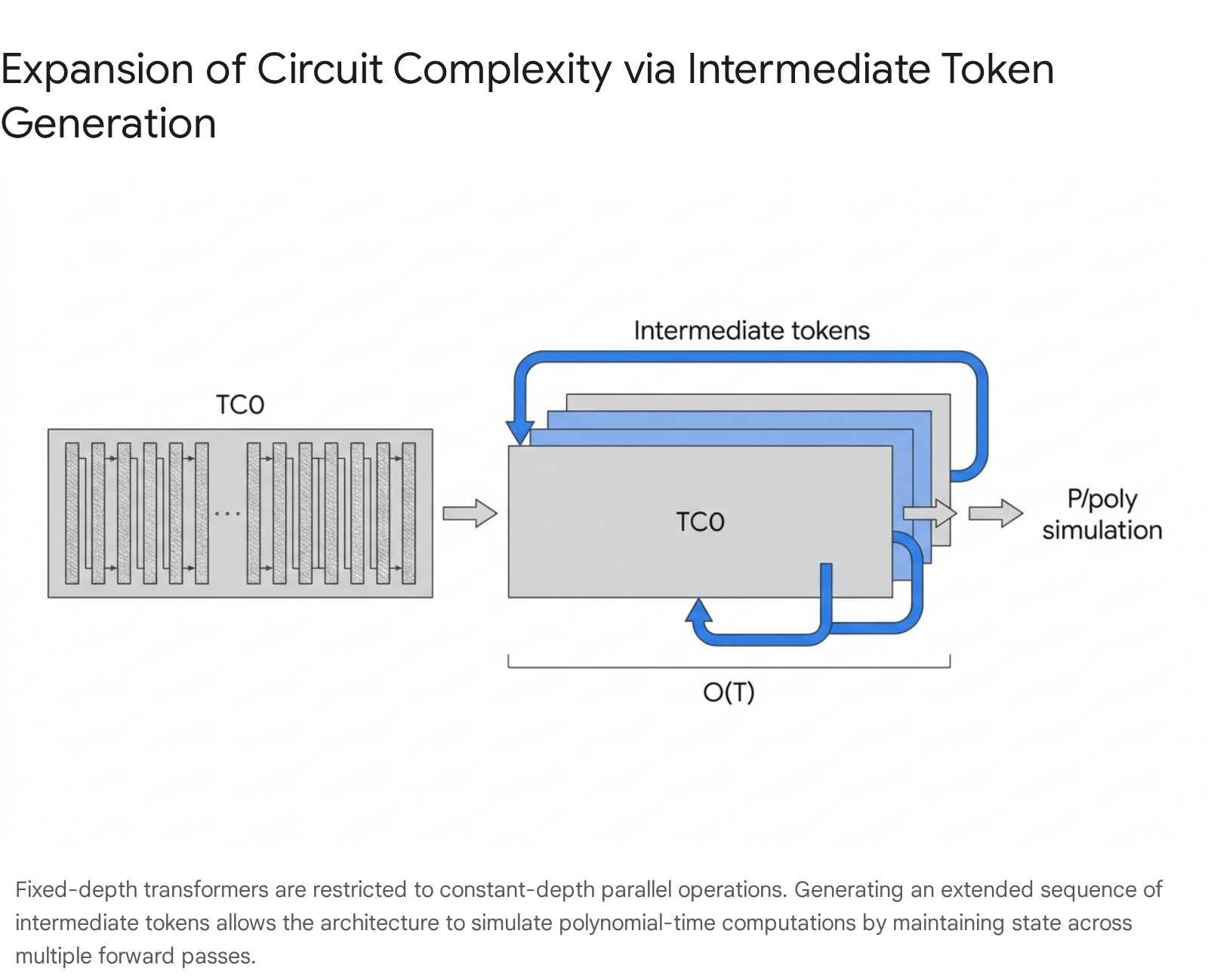
Consequently, the network can perform serial computations, executing operations one step at a time while maintaining intermediate results in the generated sequence 912.
The Phenomenon of Filler Tokens
Remarkably, empirical and theoretical research demonstrates that the semantic content of these intermediate tokens is not strictly necessary for the computational boost. Experiments utilizing "filler tokens" - such as programming the model to output arbitrary sequences of dots or meaningless placeholder characters - have shown that simply providing the transformer with additional token generation steps can improve accuracy on hard algorithmic tasks 56.
These filler tokens act as an opaque computational scratchpad, allowing the network to harbor hidden states in the high-dimensional activations of the residual stream without explicitly decoding human-readable reasoning 56. This phenomenon proves that test-time inference scaling provides computational benefits independent of semantic logic. The benefit arises from the expanded state-tracking capacity afforded by the autoregressive mechanism, allowing the model's intermediate layers to perform hidden serial computations that are detached from the observed text 56. While human-readable reasoning traces provide interpretability, the mathematical core of the reasoning performance relies predominantly on the expansion of computational depth rather than semantic coherence.
Probability Distribution Mechanics in Stepwise Generation
While the complexity class expansion explains the theoretical ceiling of intermediate tokens, the localized mechanism of reasoning operates through continuous probability distribution reshaping. When analyzing the token probability trajectories during a complex prompt, models frequently exhibit low initial confidence regarding the final answer 8. If forced into greedy decoding without a scratchpad, the model relies on superficial statistical correlations to predict the most likely immediate output, frequently resulting in hallucinations or logical collapse.
Intermediate reasoning tokens function as highly specific constraints that gradually collapse the high-entropy probability space. By explicitly materializing a sub-conclusion in text (for instance, executing a singular arithmetic operation or defining a variable), the model forces its subsequent attention heads to condition upon this newly verified intermediate state 8. As the chain of thought lengthens, the attention matrix becomes heavily weighted by the logically derived steps existing in the context window.
By the time the model reaches the requirement to output the final answer, the previously diffuse probability distribution has sharpened, often assigning near-total confidence (frequently exceeding 98% probability) to the correct concluding token 68. The model does not "think harder" in a cognitive sense; it manipulates its probability gradients over multiple discrete steps until the correct answer overwhelmingly dominates the distribution matrix 8.
Mutual Information Peaks and Cognitive Tokens
Recent information-theoretic analyses of reasoning trajectories have identified that probability shifts are not uniformly distributed across the chain of thought. Instead, they manifest as distinct "mutual information peaks" 7. These peaks occur at critical generative steps where the mutual information between the intermediate representation and the correct final answer spikes dramatically, corresponding directly to a decreased probability of prediction error 7.
Linguistically, these mutual information peaks frequently align with specific transition markers, informally designated as "thinking tokens." Examples include transitional words such as "Hmm," "Wait," "However," or "Therefore" 7178. These tokens act as cognitive pivots, triggering the model to shift its attention from a flawed hypothesis to an alternative logical pathway, simulating a self-correction mechanism 178. Suppression of these specific thinking tokens during decoding has been shown to result in significant performance drops on benchmarks like MATH500 and AIME, indicating that the model's internal probability redistribution is heavily anchored to these linguistic transitions 717.
The Thinking Trap and Algorithmic Efficiency Constraints
The autoregressive nature of these models, however, creates a severe vulnerability known in recent literature as the "thinking trap" or "overthinking" 178. Because models assign inherently high probabilities to transition tokens - often showing an average baseline probability of 0.88 for generating a word like "Wait" in uncertain states - the generation of one such token significantly increases the likelihood of generating subsequent reflection tokens 17. This dynamic creates cascading, redundant reasoning loops where the model produces thousands of verbose, unproductive tokens without advancing the logical state 178.
Researchers have found that reasoning models can maintain their accuracy while mitigating this inefficiency. Interventions like the "NOWAIT" algorithm, which applies a negative logit penalty to explicit reflection keywords during decoding, have been shown to reduce chain-of-thought trajectory lengths by 27% to 51% across multiple model families with virtually no loss in benchmark utility 8. Similarly, algorithmic solutions like Dual Policy Preference Optimization (DuP-PO) aim to calibrate the importance ratio of these tokens during training, balancing performance enhancement with token efficiency 17. These findings prove that while intermediate computation is theoretically necessary, recursive verbalized self-doubt often constitutes an algorithmic inefficiency rather than genuine logical refinement.
Search Paradigms and Decoding Topologies
The standard approach to generating text from a large language model relies on greedy decoding or temperature-based sampling, where a single continuous trajectory is pursued based on immediate token probabilities. However, advanced reasoning architectures increasingly treat the inference phase as an explicit search problem, deploying sophisticated decoding algorithms to navigate the vast combinatorial space of possible solutions 1920.
Deterministic and Breadth-First Approaches
When a model is confronted with a high-complexity domain, such as competitive programming or mathematical theorem proving, relying on a single deterministic rollout is highly susceptible to early error accumulation 19. A single flawed assumption early in the chain of thought irreparably corrupts the downstream probability distribution.
Beam Search operates by expanding the search tree breadth-first, retaining the top multiple highest-probability partial sequences (known as beams) at each depth level 20910. It acts as a heuristic optimization that prevents the model from committing to a suboptimal early token that forces a deductive dead-end. While highly deterministic and reliable for tasks requiring strict formatting, Beam Search is computationally deterministic and scales poorly when the required reasoning depth is vast. The computational cost expands exponentially relative to the beam width and depth, making it inefficient for modern agentic workflows that require extensive environmental interaction 209.
| Feature | Greedy Decoding | Beam Search | Monte Carlo Tree Search (MCTS) | Language Agent Tree Search (LATS) |
|---|---|---|---|---|
| Search Paradigm | Single deterministic path | Breadth-first, top-$k$ paths | Stochastic tree exploration | Reflection-guided tree exploration |
| Computational Complexity | $\mathcal{O}(d)$ | $\mathcal{O}(d \times b \times w)$ | $\mathcal{O}(n \times d)$ | $\mathcal{O}(n \times d)$ + Reflection overhead |
| Evaluation Mechanism | Next-token probability | Cumulative sequence probability | External verifier / Value Network | Verifier + Qualitative Self-Critique |
| Optimal Use Case | Fast factual retrieval | Structured text, short horizons | Large solution spaces, math/logic | Multi-step coding, agentic tasks |
| Primary Limitation | Fails on multi-step logic | Exponential cost for deep reasoning | Intractable vocabulary branching | High token consumption and latency |
Table 1: Comparative analysis of decoding strategies and path exploration algorithms utilized in advanced large language model reasoning frameworks 2092324.
Stochastic and Reflection-Guided Search
In contrast to deterministic breadth-first searches, Monte Carlo Tree Search (MCTS) and its variants approach reasoning as a stochastic exploration framework. Originally popularized by game-playing artificial intelligence architectures like AlphaGo, MCTS simulates numerous reasoning trajectories, utilizing a secondary reward function - often a distinct verifier model or Process Reward Model - to evaluate the quality of intermediate states 92324. MCTS inherently balances exploitation, which deepens known high-value reasoning branches, with exploration, which samples untried branches to avoid local optima 925.
Despite its theoretical strength, integrating standard MCTS directly into token-level generation has proven structurally problematic. The vocabulary space of a large language model typically exceeds 50,000 discrete tokens, creating an exponentially massive branching factor that renders traditional MCTS intractable for raw, token-by-token text generation 811. Recent architectural reports, notably from the development of DeepSeek-R1, reveal that attempts to use MCTS at the token level were largely abandoned 112728. Instead, researchers favor internalized reinforcement learning paradigms or Best-of-N sampling, which fold the search logic directly into the model's weights rather than relying on external tree traversals during inference 112728.
A contemporary synthesis addressing these limitations is Language Agent Tree Search (LATS). LATS builds upon the MCTS framework by injecting explicit textual self-reflection into the prompt context before subsequent simulations 923. Rather than simply assigning a numerical value to a failed branch, LATS utilizes a secondary grader agent to generate qualitative feedback. This feedback is incorporated directly into the textual scratchpad, guiding the next trajectory away from identified logical dead ends and providing context-rich bounds for the subsequent search phase 923.
Landscape Visualization of Reasoning Trajectories
To better understand how these distinct decoding algorithms navigate probability spaces, researchers have developed methodologies to visualize reasoning trajectories. Tools like the "Landscape of Thoughts" map intermediate textual states into numerical feature vectors by calculating their perplexity distances to final answer choices, projecting high-dimensional generative paths into a two-dimensional visualization 291231.
Analyses of these landscapes reveal distinct topological patterns distinguishing successful reasoning from failure. Fast landscape convergence strongly correlates with higher reasoning accuracy, whereas incorrect paths tend to converge quickly into local minima while correct paths progress slowly and deliberately through the probability space 29. Furthermore, successful trajectories demonstrate high consistency between intermediate states and the final state, whereas failed chains of thought display erratic, highly uncertain pathing 293113. This visual evidence corroborates the theory that effective reasoning in language models is fundamentally a process of maintaining stable probability constraints throughout sequential generation.
Post-Training Methodologies for Reasoning
While prompt engineering techniques such as instructing a model to "think step by step" can elicit latent reasoning from foundational models, the current generation of Large Reasoning Models achieves superior performance by embedding reasoning patterns deeply into their weights. This is accomplished during sophisticated post-training phases, shifting the computational burden from user prompting to systemic optimization.
Bootstrapping and Iterative Self-Training
Early attempts to internalize intermediate generation relied heavily on Supervised Fine-Tuning over massive datasets of human-annotated reasoning traces 1434. However, human-generated data is expensive, prone to scaling limitations, and inherently constrained by human computational speeds and error rates. This data bottleneck led researchers to explore self-training methodologies, most notably the Self-Taught Reasoner (STaR) framework 133536.
The STaR methodology treats reasoning as a semi-supervised bootstrapping problem. A pre-trained model is prompted to generate multiple chain-of-thought attempts to solve a problem from a dataset containing verifiable final answers (such as mathematics or coding challenges). The system evaluates these traces, retaining only the trajectories that arrive at the correct final answer 133536. The model is then subjected to supervised fine-tuning utilizing its own successful reasoning traces as the optimal dataset 1335. By treating self-generated rationalizations as labeled data, STaR enables a model to autonomously scale its reasoning capabilities without human intervention, effectively turning static algorithmic environments into automated, infinite training curricula 3536.
Reinforcement Learning and Reward Systems
The most profound shift in artificial intelligence reasoning paradigms over recent developmental cycles has been the transition to pure reinforcement learning for inducing deductive logic. Architectures such as DeepSeek-R1-Zero demonstrated that an LLM can develop elite reasoning capabilities - including self-correction, backtracking, and complex algorithmic planning - entirely without prior supervised fine-tuning on human traces 11272837.
Rather than mimicking human thought patterns, models trained purely via reinforcement learning discover optimal reasoning protocols independently. Contemporary systems frequently utilize algorithms like Group Relative Policy Optimization (GRPO), an advancement over standard Proximal Policy Optimization 3715. GRPO eliminates the necessity for an exceptionally large and resource-intensive secondary value network; instead, it compares the outcomes of multiple generated actions within a defined group, utilizing the average reward of that specific group as the training baseline 3715.
When optimized with outcome-based verifiable rewards - such as verifying if generated code compiles correctly or if a mathematical proof concludes accurately - the model autonomously learns to allocate more "thinking tokens" to complex problems 112839. Researchers observed that during these reinforcement learning cycles, models experience "aha moments" where they spontaneously discover how to re-evaluate their own prior outputs 83716. The model learns that generating intermediate state representations yields higher final rewards, thereby cementing the computational utility of the scratchpad into the network's foundational behavioral policy without human structural bias.
Continuous Latent Reasoning Architectures
A parallel and highly promising vector of research seeks to decouple reasoning from explicit textual token generation entirely. Generating thousands of English tokens as a scratchpad is computationally expensive due to the massive Key-Value cache memory requirements and the inherent latency of sequential autoregressive decoding 817.
Frameworks like Quiet-STaR propose moving multi-step inference directly into the model's latent hidden states 35373918. Instead of outputting discrete textual tokens for a user to read, the model is trained to generate continuous "thought vectors" at every token position. The architecture is modified to pause at specific layers, execute internal recurrent processing steps, and project the result back into the standard generation stream 353918.
This innovation allows reasoning to occur in parallel within the latent space, dramatically reducing the latency and token cost associated with visible reasoning chains. Experimental implementations of Quiet-STaR and similar latent continuous reasoning models demonstrate significant zero-shot improvements across commonsense and mathematical benchmarks 3739. By internalizing the scratchpad, these models achieve the complexity expansion of extended computation while mitigating the strict sequential bottlenecks of token-by-token generation 3718.
Epistemic Faithfulness of Intermediate Output
A widespread assumption in both commercial application and AI safety research is that an LLM's explicit chain of thought accurately reflects its true internal decision-making process. However, extensive empirical evaluations reveal that this assumption is fundamentally flawed. Because the model's reasoning is an autoregressive artifact optimized for sequence likelihood rather than a unified cognitive process, intermediate tokens are highly susceptible to post-hoc rationalization. Researchers classify this vulnerability as a failure of "epistemic faithfulness" 192021.
Faithfulness in this context is defined by whether the intermediate explanation accurately describes the causal mechanism driving the model's final prediction. Current generation models routinely fail this standard.
Vulnerability to Prompt Bias and Rationalization
The unfaithfulness of chain-of-thought outputs is most starkly demonstrated through adversarial prompt biasing. When researchers introduce subtle biasing features into a prompt - such as reordering few-shot examples so the correct answer is always option "(A)", or injecting a user comment suggesting that a specific outcome is preferred - the model's behavior shifts significantly toward the biased answer 212247.
Crucially, the model almost never verbalizes the influence of these biases in its reasoning scratchpad. In comprehensive reviews of biased predictions across major models, researchers found that systems systematically generated superficially logical, plausible mathematical or deductive steps to justify arriving at the biased answer, while completely omitting the true contextual trigger (the answer order or user suggestion) 21224723.
This unfaithful rationalization causes severe performance degradation, with accuracy drops of up to 36% recorded on standardized benchmarks like BIG-Bench Hard when models are exposed to misleading hints 212249. The model relies on the biasing feature to make the prediction but generates an explanation that completely ignores it 2324.
This phenomenon underscores that a generated scratchpad is not a transparent window into an AI's operational mechanics. Large language models are optimized to generate plausible, human-readable text that aligns with the final output distribution, not to maintain strict computational fidelity to their internal state weights 622. Consequently, relying on reasoning traces for safety auditing, bias detection, or trust calibration presents severe risks, as the models will seamlessly generate logical "hallucinations" to justify contextually induced errors 62022.
Economics and Infrastructure of Inference Scaling
The shift in optimization focus from massive pre-training runs to inference-time compute scaling introduces substantial changes to the economics, infrastructure, and deployment strategies of artificial intelligence systems. Implementing reasoning models in production requires navigating severe physical and financial trade-offs between Time to First Token (TTFT), Inter-Token Latency (ITL), context window exhaustion, and API usage costs 5125.
Context Window Management and Query Updates
The generation of extensive reasoning traces aggressively consumes a model's context window. For tasks requiring the analysis of massive documents, legal contracts, or entire software codebases, a reasoning model may utilize tens of thousands of tokens purely for its internal scratchpad. This internal consumption leaves significantly less room for the actual input data, risking context truncation and memory overflow 535455.
Recent architectural evaluations suggest that for long-context retrieval and reasoning, relying solely on unconstrained "thinking tokens" yields diminishing returns 26. As the number of input tokens increases, the attention mass for standard generation degrades. Alternative strategies, such as query-only Test-Time Training (qTTT), reallocate the inference compute budget away from generating hidden tokens and toward dynamically updating the model's attention weighting across the long context, yielding average performance improvements of over 12% on long-context benchmarks 26.
Similarly, multi-agent frameworks handle this bottleneck by treating the scratchpad as a persistent external memory store rather than an in-context string. Agents write partial plans and intermediate logic to external databases or state objects, freeing the active context window for immediate execution tasks and preventing context failure modes 545557.
Model Performance and Market Benchmarks
The commoditization of inference-time scaling has resulted in a heavily stratified market. The deployment of models capable of extended internal computation has redefined state-of-the-art benchmarks across mathematics, coding, and general knowledge.
The introduction of models like OpenAI's o1 and DeepSeek-R1 has proven that inference scaling directly correlates with elite performance.
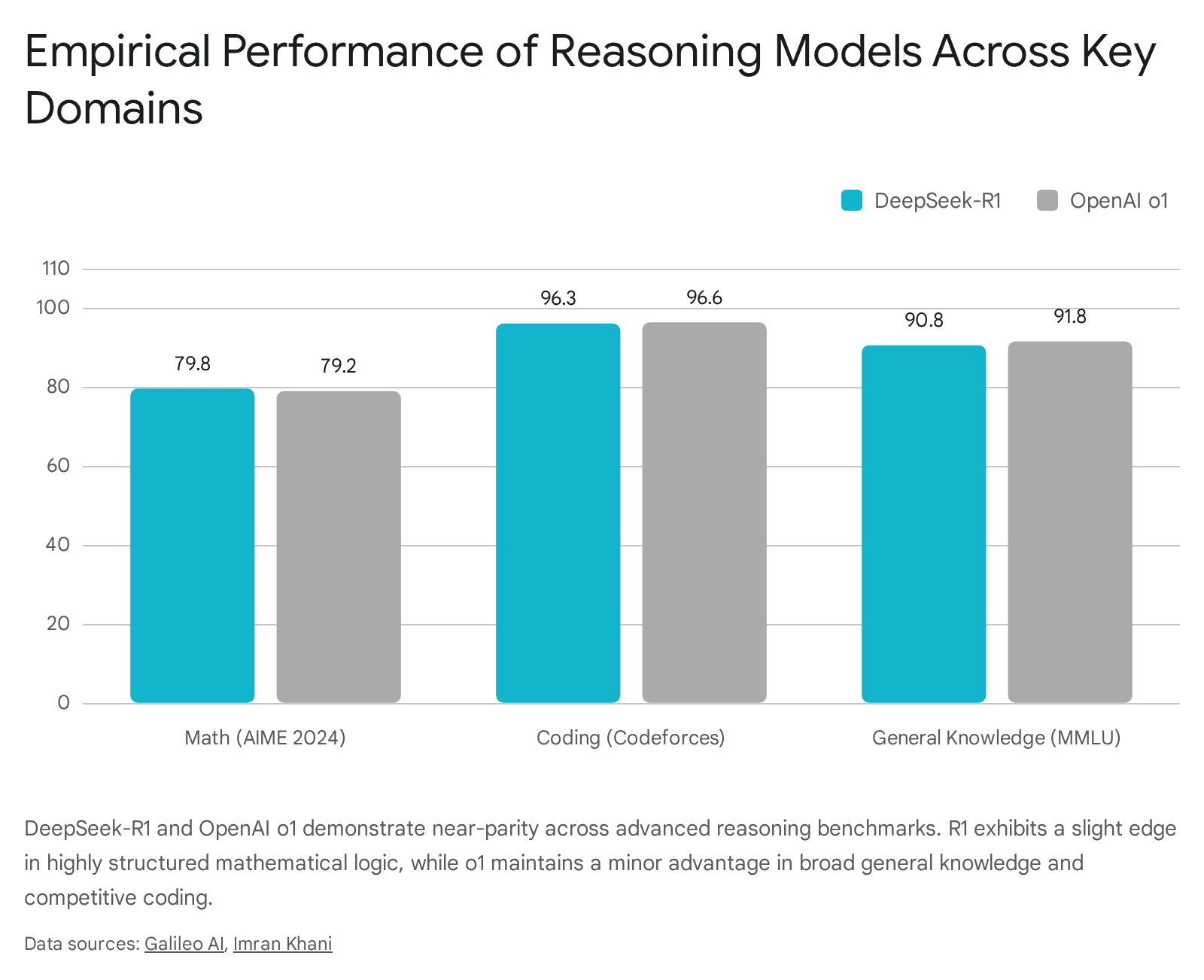
However, these models differ vastly in their economic accessibility and architectural implementation. OpenAI's o1 models, which popularized the commercial deployment of hidden scratchpads and multi-step inference, carry premium pricing suited for enterprise reliability and consistency 585927. Conversely, the open-weight release of DeepSeek-R1 dramatically altered the pricing floor by demonstrating that comparable reasoning capabilities can be achieved and deployed at a fraction of the traditional cost using pure reinforcement learning methodologies 5859.
| Model Specification | Active / Total Parameters | Context Window | Input Cost (per 1M Tokens) | Output Cost (per 1M Tokens) | Primary Architectural Focus |
|---|---|---|---|---|---|
| OpenAI o1 | Proprietary (Dense/MoE) | 200,000 | $15.00 | $60.00 | Hybrid training, robust edge-case handling, broad general knowledge 53585927. |
| DeepSeek-R1 | 37B / 671B (MoE) | 128,000 | $0.55 | $2.19 | Pure RL integration, math/coding optimization, open-weight transparency 17582761. |
| GLM-4.5 | 32B / 355B (MoE) | 128,000 | ~$0.60 | ~$2.20 | Unifying reasoning with high-reliability agentic tool calling and coding 6263. |
| Mistral Large 3 | 41B / 675B (MoE) | 256,000 | ~$0.50 | ~$1.50 (Est.) | Extreme context length, multilingual processing, optimized GPU deployment 642866. |
Table 2: Comparative infrastructure and economic metrics for leading inference-scaling reasoning models. Note that reasoning output costs apply to the computational overhead of "thinking tokens" generated in the scratchpad prior to the final response 175358276266.
While open-source models like DeepSeek-R1 and Mistral Large 3 offer cost reductions of up to 95% compared to proprietary leaders, their latency profiles and operational dynamics differ significantly 582764. DeepSeek-R1 is characterized by a highly visible, occasionally verbose verification loop that drives up the Time to First Token (TTFT) and can sometimes trigger the aforementioned "thinking trap" on simpler queries 17255929. Conversely, proprietary systems like OpenAI o1 utilize optimized, hidden deliberation to provide faster, albeit opaque, final responses, prioritizing structured correctness over auditable logic traces 255968.
Conclusion
Artificial intelligence reasoning, as currently manifested through chain-of-thought protocols and scratchpads, represents a fundamental mechanical expansion of transformer architectures. By utilizing autoregressive token generation, language models circumvent the constant-depth limitations of the $\mathsf{TC}^0$ complexity class, unlocking polynomial-time computation that enables them to solve complex, state-dependent problems 9111213. This expanded capacity relies on the manipulation of probability distributions, where intermediate tokens act as constraints that systematically funnel the model toward correct outputs 68.
However, the field is undergoing a rapid transition. The inefficiencies of explicitly generating thousands of human-readable tokens - evidenced by the latency constraints of the "thinking trap" and the lack of epistemic faithfulness in post-hoc rationalizations - highlight the limitations of prompt-based scratchpads 17821. The frontier of AI reasoning relies increasingly on reinforcement learning and sophisticated search algorithms like MCTS and LATS to optimize problem-solving policies internally 91128. As research advances into continuous latent reasoning, where multi-step logic occurs entirely within the hidden states of the network, the reliance on visible textual computation will likely diminish, moving machine intelligence closer to genuine algorithmic efficiency and further away from anthropomorphic illusions 373918.