What AI Parameters, Tokens, and FLOPs Actually Measure
When evaluating an artificial intelligence model, three numbers tell the core story of its capability and cost: parameters measure the model's raw knowledge capacity, tokens define its vocabulary and working memory, and FLOPs calculate the sheer computational muscle required to build or run it. Understanding these metrics is essential to separating marketing hype from engineering reality, as they directly dictate whether an AI can run locally on a laptop or requires a billion-dollar data center.
The New Physics of Artificial Intelligence
For years, the artificial intelligence industry operated under a brutally simple assumption known as the "scaling law": increasing the size of the numbers associated with a model would reliably and predictably increase its intelligence 1. If a developer doubled the data fed into a system and doubled the size of the neural network, the model's error rates would drop in a mathematically predictable curve 2. This physical reality drove a global arms race, pushing technology companies to build the largest computing clusters in human history.
However, as we progress through 2026, the landscape of large language models (LLMs) has fundamentally shifted. The pursuit of scale has collided with the harsh realities of physics, memory bandwidth, and electricity costs. We have entered an era where raw numbers are no longer comparable across different architectures 34. A model with 400 billion parameters might now be cheaper and faster to run than an older model with 70 billion parameters 35. A system promising a million-token memory might struggle to remember a fact hidden in the middle of a document 6.
To navigate the modern AI ecosystem - whether you are a developer deploying an agentic workflow, an enterprise deciding on cloud infrastructure, or an enthusiast building a local computer rig - you must look past the headline figures. You must understand the underlying mechanics of tokens, parameters, and floating-point operations (FLOPs).
What Are Tokens? The Vocabulary and Memory of AI
Language models do not read or generate text in the way human beings do. They process mathematical vectors, which require text to be broken down into discrete numerical units called "tokens."
The Building Blocks of Language
A token can be an entire word, a syllable, or just a single character, depending on the language and the specific tokenization engine used by the model 3. As a general rule of thumb in the English language, one token is roughly equivalent to three-quarters of a word 89. For example, the phrase "KiwiGPT is awesome" might be sliced into the tokens ["Ki", "wi", "GPT", " is", " awesome"] 8.
In modern multimodal models, the concept of a token has expanded far beyond text. An image is sliced into visual patches and converted into "vision tokens." Audio is sampled and transformed into "audio tokens." For instance, Google's Gemini 2.5 Pro processes video by ingesting it at a rate of 66 tokens per frame, allowing the model to "watch" and reason about moving pictures 10.
When analyzing AI model specifications, the word "token" is utilized to measure two entirely distinct concepts: the volume of the model's training data, and the size of its real-time working memory (the context window) 114.
Training Tokens: The Volume of Knowledge
During the pre-training phase, an AI model is fed vast amounts of data scraped from the internet, digitized books, scientific papers, and code repositories. The size of this dataset is measured in trillions of tokens.
The training token count represents the volume of "reading material" the AI consumed to learn grammar, facts, reasoning, and world knowledge. Historically, the Chinchilla scaling laws suggested a strict ratio: models should be trained on approximately 20 tokens of data for every one parameter in the neural network 11. Following this math, a 400-billion parameter model would optimally require about 8 trillion tokens of data.
However, modern developers have discovered that "over-training" smaller models on massive amounts of data yields highly efficient systems. Meta's Llama 3 was trained on roughly 15 trillion tokens, defying the standard ratios 11. The subsequent Llama 4 family pushed this boundary even further, training on an unprecedented 30 to 40 trillion tokens of text, image, and video data 51415.
The sheer volume of training tokens is not the only factor; data quality is arguably more important. A model trained on fewer tokens of meticulously curated, high-quality data can vastly outperform a model trained on a larger volume of garbage data 11. Microsoft's Phi-4, a compact 14-billion parameter model, achieves frontier-level reasoning by focusing almost exclusively on "textbook quality" synthetic data generated by other advanced AI systems 67.
The Context Window: AI's Fragile Short-Term Memory
While training tokens represent the model's permanent, long-term knowledge, the context window represents its short-term, working memory during a live interaction 418.
The context window is a hard limit on the total number of tokens a model can actively hold in its awareness at any given moment 38. This limit must encompass everything involved in your current session: 1. The System Prompt: The hidden instructions guiding the AI's behavior. 2. Conversation History: Every message you have sent and every response the AI has generated so far. 3. Injected Data: Any PDFs, codebases, or database retrievals you have uploaded. 4. The Output Generation: The new tokens the model is currently predicting 48.
All of these elements compete for the same limited space. The context window functions as a first-in, first-out (FIFO) ring buffer 4. If a model has a context limit of 100,000 tokens and your conversation reaches 100,001 tokens, the very first token from the beginning of the conversation is truncated and permanently deleted from the model's awareness 68.
When users complain that a chatbot has suddenly become "stupid," forgotten its original instructions, or started hallucinating mid-conversation, it is almost always because the context window has overflowed 98.
The Evolution of Massive Context Windows
In 2023, a context window of 4,000 tokens (roughly 3,000 words) was standard 8. By 2025 and 2026, the industry experienced an explosion in context lengths, completely altering the types of applications that AI could handle.
| Frontier Model (2025/2026) | Advertised Context Window | Notable Use Cases & Capabilities | Sources |
|---|---|---|---|
| OpenAI GPT-5.2 | Up to 400,000 tokens | Standard persistent memory for advanced professional chat and deep analysis. | 8 |
| Mistral Large 3 | 256,000 tokens | Processing 300-400 pages of technical documentation; native OCR for PDFs. | 20219 |
| Alibaba Qwen 3.7 Max | 1,000,000 tokens | Long-horizon agentic workflows; sustaining 35-hour autonomous coding tasks. | 231011 |
| Google Gemini 2.5 Pro | 1,000,000+ tokens | Native multimodality capable of processing up to 3 hours of continuous video. | 102612 |
| Meta Llama 4 Scout | 10,000,000 tokens | Ingesting massive enterprise codebases; multi-document deep synthesis. | 52813 |
The Mathematical Penalty of Infinite Context
Advertising a 1-million or 10-million token context window is a formidable marketing feat, but utilizing it comes with severe engineering penalties.
In a standard Transformer architecture, the attention mechanism scales quadratically - meaning that every time you double the input length, the computational power required to process it quadruples 314. To avoid recalculating the entire history for every new word, the model stores the representations of previous tokens in the GPU's memory. This is known as the Key-Value (KV) Cache 3115.
As the conversation grows, the KV cache grows linearly. Processing a 1-million-token prompt can cause the KV cache to snowball to hundreds of gigabytes, requiring massive clusters of hardware just to hold a single conversation in memory 15. Furthermore, models dealing with immense context windows often suffer from the "lost in the middle" phenomenon. If you bury a crucial detail on page 500 of a 1,000-page document, the AI's attention mechanism may diffuse, causing it to ignore the fact entirely when answering questions 63.
To solve the context overflow problem, researchers have developed multiple workarounds: * Retrieval-Augmented Generation (RAG): Instead of dumping a massive document directly into the context window, the document is stored in an external vector database. When the user asks a query, the system performs a semantic search to retrieve only the most relevant paragraphs, injecting them into the AI's prompt just in time 1433. This bypasses the need for massive context windows entirely. * Sliding Window Attention: A technique where tokens only "look back" at a fixed number of recent tokens (e.g., the last 4,096) rather than the entire history, drastically reducing compute costs while propagating information forward through the neural layers 31. * Advanced Attention Compression: Models like DeepSeek V4 utilize hybrid mechanisms, combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to slash the KV cache memory footprint. At a 1-million-token context, DeepSeek V4 Pro requires only 10% of the KV cache footprint compared to previous generations 3435. * Infini-attention: Experimental architectures that replace the linearly growing KV cache with a fixed-size "global compressive memory matrix," reducing memory requirements by over 100x while retaining the ability to recall historical context 15.
What Are Parameters? The Neural Connections
If training tokens represent the books an AI has read, parameters represent the neural connections forged in its brain during the reading process.
A parameter is a discrete numerical value - a weight or a bias - embedded within the layers of the neural network 1. When a user submits a prompt, that text is tokenized and passed through billions of mathematical equations. The parameters dictate how heavily the model should weigh specific concepts, relationships, and grammatical structures to predict the next token accurately.
Superposition: The Geometry of Knowledge
For years, AI researchers knew empirically that adding more parameters to a model made it smarter, but the exact mechanical reason was a subject of intense study. Why does a 70-billion parameter model reason so much better than an 8-billion parameter model?
An MIT study presented at NeurIPS in 2025 provides a compelling geometric explanation centered on a concept called "superposition" 2. Language models must pack tens of thousands of vocabulary words and millions of abstract facts into an internal mathematical space that possesses only a few thousand dimensions 2. In a strict mathematical sense, a three-dimensional space can only perfectly hold three concepts without interference.
To overcome this limitation, LLMs store multiple concepts simultaneously within the same dimensions. This causes their mathematical representations to overlap slightly, a phenomenon known as "squeezing" or superposition 2. In smaller models, this severe overlap creates interference, leading to hallucinations, prediction errors, and an inability to untangle complex logic.
When engineers increase the parameter count, they effectively expand the dimensionality of the model's internal geometry 2. This provides the AI with a larger spatial canvas, allowing it to represent concepts more cleanly without destructive overlap 2. The MIT researchers demonstrated that the scaling laws dictating AI performance are a direct result of how language models organize meaning geometrically; as parameters scale up, the error caused by cramped, overlapping representations steadily vanishes 2.
The Mixture of Experts (MoE) Revolution
Historically, neural networks were "dense." In a dense architecture, every single parameter in the model is activated to process every single token 536. If you asked a 400-billion parameter dense model to generate the word "hello," it had to run calculations across all 400 billion parameters.
As the industry chased greater intelligence, models became too large to run efficiently. To solve this, researchers universally adopted the "Sparse Mixture-of-Experts" (MoE) architecture 512.
In an MoE model, the neural network is fragmented into distinct sub-networks, or "experts." When a token enters the system, a specialized gating or routing network analyzes the input and dynamically forwards it to only the most relevant experts 536.
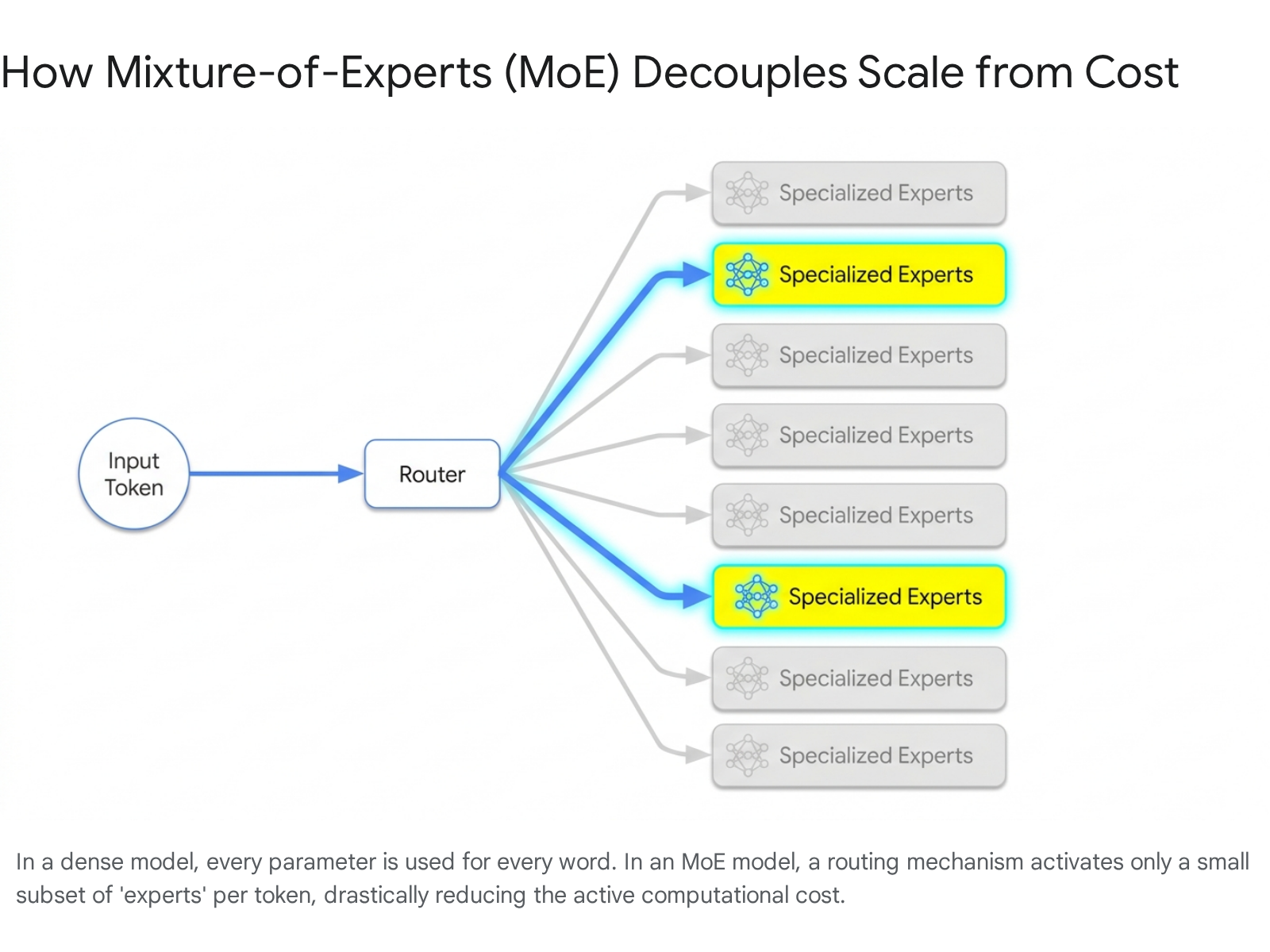
This breakthrough means that evaluating a modern AI model requires understanding two completely distinct numbers: * Total Parameters: The total amount of world knowledge, code patterns, and linguistic nuance stored across all the experts combined 937. * Active Parameters: The number of parameters actually fired up and used during a single inference step 520.
By routing tokens selectively, an MoE model can possess the immense reasoning capacity of a trillion-parameter system while operating with the speed, latency, and cost of a much smaller model 321.
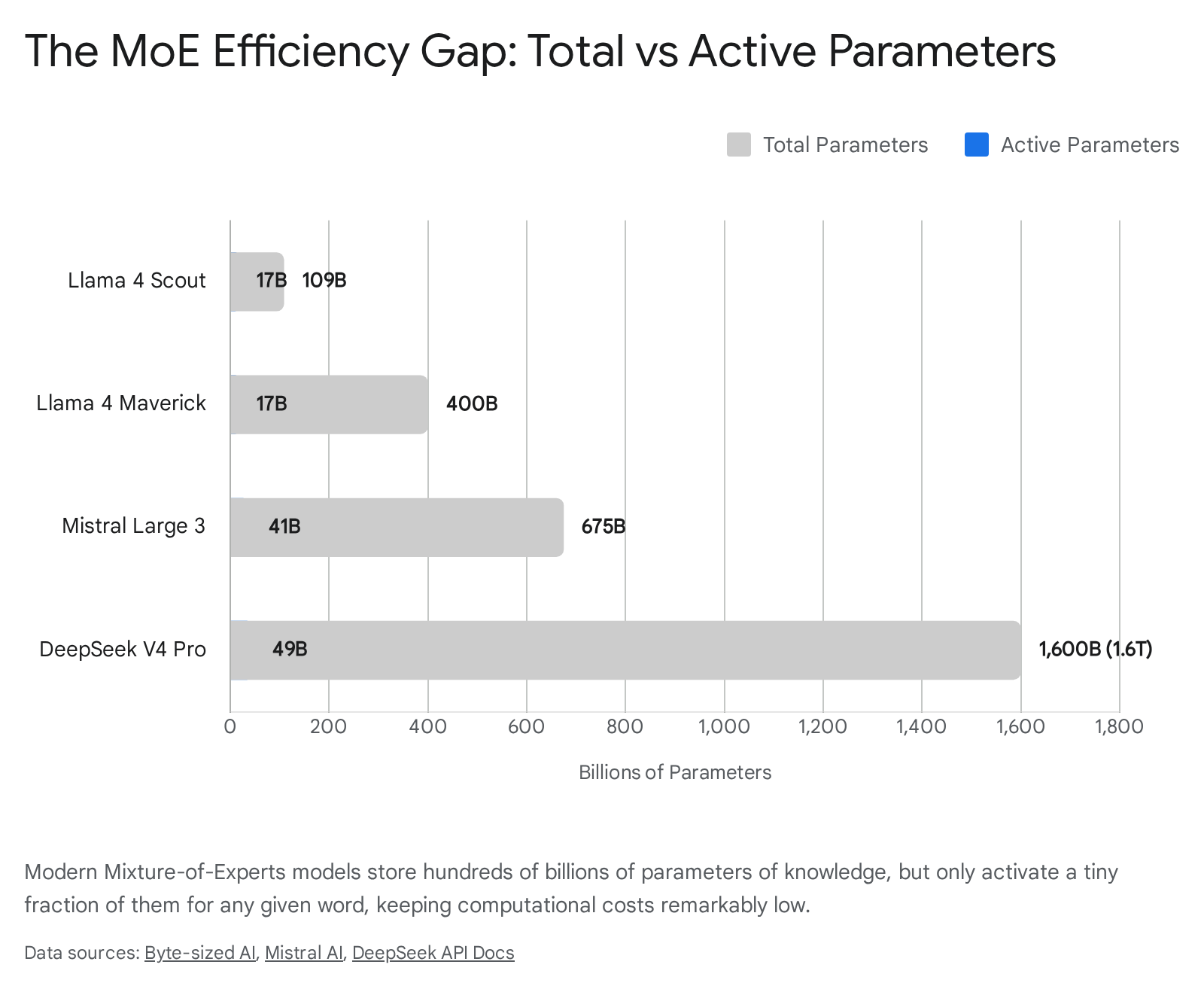
The scale of this divergence in 2026 is profound. Consider the architectural specifications of the leading open-weight models: * DeepSeek V4 Pro houses an astonishing 1.6 trillion total parameters, but activates a mere 49 billion parameters per token 3416. * Mistral Large 3 contains 675 billion total parameters, but its router ensures only 41 billion are active during inference 2021. * Meta Llama 4 Maverick utilizes 128 distinct experts, totaling 400 billion parameters. However, its dynamic routing activates only 2 experts per token (one shared and one task-specialized), resulting in an active footprint of just 17 billion parameters 514.
Because only a fraction of the network is invoked for any given token, the computational overhead - and therefore the cost to the user - drops precipitously, allowing frontier intelligence to be deployed at scale without bankrupting enterprises 536.
What Are FLOPs? The Raw Computational Muscle
While parameters represent the brain and tokens represent the diet, FLOPs represent the sheer caloric expenditure of artificial intelligence.
FLOPs stands for "Floating-Point Operations." It is a fundamental unit of computing power that measures the total number of fractional mathematical calculations (such as additions and multiplications) executed by a system's hardware 11. In the realm of AI, measuring FLOPs is the most objective way to determine the true scale, cost, and effort invested into training a model.
Calculating the Energy of Intelligence
To estimate the computational burden of training a dense language model, researchers traditionally rely on a heuristic derived from the Chinchilla scaling laws. The formula is expressed as:
FLOPs ≈ 6 * Parameters * Training Tokens 11
For example, a dense model with 8 billion parameters trained on 15 trillion tokens requires approximately $7.2 \times 10^{23}$ FLOPs to train 11. Executing operations at this scale requires massive arrays of specialized hardware, such as NVIDIA H100 or H200 GPUs, running constantly for weeks or months, drawing megawatts of electricity and costing tens of millions of dollars 2039.
The 1e25 FLOP Threshold
In the AI industry, crossing the $10^{25}$ FLOP training threshold marks the boundary of true frontier models.
The very first model to be trained at this monumental scale was OpenAI's GPT-4, released in March 2023 39. Since then, the race to build ever-larger clusters has accelerated dramatically. By mid-2025, tracking organizations like Epoch AI had identified over 30 publicly announced AI models - including Anthropic's Claude 3.5 Sonnet, xAI's Grok 3, and Meta's Llama 3.1 405B - that surpassed the $10^{25}$ FLOP training compute threshold 39.
FLOPs as a Regulatory Proxy
Because FLOPs represent an objective measure of the hardware and capital required to build an AI, governments have seized upon the metric for regulation. Frameworks authored by both the United States and the European Union have utilized FLOPs as a threshold proxy to determine which models represent systemic risks and must be subjected to stringent safety audits 11.
However, relying strictly on FLOPs is an imperfect regulatory strategy. The assumption that more compute automatically equals a more dangerous or capable model ignores a critical variable: the quality of the training data 11. A developer can expend a massive amount of FLOPs training a model on low-quality, poorly curated data and yield a fundamentally inferior system 11. Conversely, highly efficient models trained on smaller, pristine datasets can achieve frontier-level intelligence while remaining well below regulatory FLOP thresholds 11.
Beyond Brute Force: The Shift to Small Language Models (SLMs)
As the limits of raw scale become apparent in both cost and latency, the industry experienced a pronounced efficiency pivot heading into 2026. The ethos of "bigger is always better" has been challenged by the meteoric rise of Small Language Models (SLMs) 44017.
Efficiency Over Scale
An SLM is typically categorized as a model containing between 500 million and 15 billion parameters 18. While they cannot match the broad, encyclopedic world knowledge of a trillion-parameter giant, they deliver 10x to 30x efficiency gains in latency, energy consumption, and infrastructure costs 4.
For the vast majority of enterprise workflows - such as analyzing internal documents, parsing log files, or driving customer service chatbots - using a massive LLM is equivalent to hiring a team of PhDs to sort mail 4. Processing a million conversations monthly might cost $75,000 using a frontier LLM API, compared to a mere $800 utilizing a self-hosted SLM 4.
The Power of Specialized Training
The surge in SLM performance is driven entirely by advances in training techniques rather than raw FLOPs. Developers realized that a small parameter footprint could be highly capable if the training diet was perfectly optimized.
Microsoft's Phi-4, a 14-billion parameter model, exemplifies this trend. Instead of scraping the open web for organic data, Microsoft trained Phi-4 almost entirely on synthetic, "textbook quality" data generated by larger models like GPT-4 67. Furthermore, its reasoning capabilities were enhanced via a specialized supervised fine-tuning (SFT) and reinforcement learning (RL) regimen 19. As a result, this 14B SLM reliably outperforms much larger legacy models (like Llama 3 70B) on highly complex math, coding, and STEM benchmarks 1920.
The Hybrid Architecture
In 2026, the most sophisticated deployments are not exclusively relying on SLMs or LLMs, but a hybrid orchestration of both 18.
In a multi-agent system, SLMs act as the frontline workers. They handle high-frequency, repetitive tasks such as routing user queries, extracting entities from text, and performing retrieval-augmented generation (RAG) lookups 18. Only when a task requires deep, multi-step logical synthesis is the query escalated to a massive, expensive LLM. This architectural pattern drastically reduces compute budgets while maintaining high-end capabilities 18.
Running Models Locally: The Hardware Reality
The democratization of AI means that researchers, developers, and privacy-conscious enterprises increasingly want to run models locally on their own hardware rather than relying on cloud APIs. When executing inference locally, the model's parameter count translates directly into physical hardware requirements - specifically, the Video RAM (VRAM) of a Graphics Processing Unit (GPU) 4521.
Understanding VRAM Requirements
If you attempt to run an open-weight model like Llama 4 or Qwen 3.7, the entire neural network (its weights) must be loaded into your GPU's memory. If a model does not fit entirely into VRAM, it spills over into the system's standard RAM, causing inference speeds to plummet from rapid-fire text generation to an agonizing crawl 21.
At standard "full precision" (FP16 or BF16), a parameter requires 2 bytes of memory 21. Therefore, an 8-billion parameter model requires 16 GB of VRAM, and a 70-billion parameter model requires a staggering 140 GB 21. Because high-end consumer GPUs (like the NVIDIA RTX 4090) max out at 24 GB of VRAM, running full-precision models locally is impossible for most users 4748.
Quantization: Shrinking the Model
To fit capable models onto standard hardware, the AI community relies on quantization 21. Quantization is a mathematical process that reduces the precision of the model's weights - for example, converting 16-bit floats into 4-bit integers.
This process sacrifices a minute fraction of the model's accuracy but drastically reduces its physical footprint. In 2026, the community standard is 4-bit quantization (specifically formats like Q4_K_M), which preserves up to 95% of the model's reasoning capabilities while slashing VRAM requirements by over 70% 45.
A reliable formula for predicting local hardware needs at 4-bit quantization is to budget 1.2 GB of VRAM for every 1 billion active parameters 47. However, this only accounts for the weights. You must also reserve 2 to 5 GB of VRAM for the framework overhead and the KV cache, which expands linearly as the conversation context grows 214749.
GPU Tiers and Local Capabilities (2026 Landscape)
Matching your hardware to the right model is a critical balancing act between VRAM capacity, parameter size, and quantization levels.
| Consumer GPU VRAM | Optimal 4-bit Quantized Models | Realistic Local Use Cases | Sources |
|---|---|---|---|
| 8 GB VRAM (e.g., RTX 3060, 4060) | Llama 3.1 8B, Qwen 2.5 7B, Phi-4 Mini | Basic chat, local document summarization, coding autocomplete. | 4547 |
| 12 GB VRAM (e.g., RTX 4070 Ti) | Llama 4 Scout 17B, Qwen 2.5 14B, Phi-4 | Strong reasoning and coding. MoE models (like Scout) fit perfectly here. | 4547 |
| 16 GB VRAM (e.g., RTX 4080) | Devstral Small 24B, Llama 3.1 8B (Full Precision) | High-quality local assistant, agentic coding workflows. | 4547 |
| 24 GB VRAM (e.g., RTX 4090) | Qwen 2.5 32B, Mistral Large 3 (Heavy Quantization) | Future-proofed for large contexts; near frontier-level quality. | 474849 |
It is worth noting that for users intending to process long contexts (such as analyzing 8,000+ tokens of text at once), 24 GB of VRAM is practically a necessity. The KV cache required to sustain long-term memory on 30B+ parameter models will easily bottleneck smaller 12 GB and 16 GB cards 49.
Measuring Speed: TTFT and TPS
Once a model is successfully loaded into VRAM, its performance is evaluated by two critical user-experience metrics 22:
- Time to First Token (TTFT): This is the latency measured from the exact millisecond you submit a prompt to the moment the first generated word appears on your screen. TTFT is the primary driver of perceived responsiveness; if a model boasts high throughput but takes four seconds to start typing, the user experience feels sluggish 22.
- Tokens Per Second (TPS): This measures the output speed of the model once generation has begun. Because the average human reads at roughly 4 to 5 words per second, any local hardware setup achieving above 10 to 15 TPS will feel comfortably fast and natural 22.
The Frontier of AI Architecture in 2026
As parameter counts, context windows, and compute budgets hit their physical and economic ceilings, the focus of AI development has pivoted from raw scale to architectural ingenuity and autonomous utility.
The Rise of Thinking Agents
The current benchmark for a frontier model is no longer its ability to write a poem or pass a bar exam, but its capacity to act as an autonomous agent. "Agentic AI" refers to models capable of reasoning, planning, and executing complex, multi-step workflows over extended periods using external tools 115123.
Alibaba's Qwen 3.7 Max was explicitly designed for this "agent frontier" 1151. By leveraging its 1-million-token context window and a massive output limit of 65,536 tokens, Qwen 3.7 Max demonstrated the ability to run fully autonomous kernel optimization routines for 35 continuous hours, executing over 1,100 tool calls without human intervention 115153.
Similarly, Google's Gemini 2.5 Pro architecture natively integrates "thinking" - a reinforcement-learning trained process that utilizes inference-time compute to ponder a problem before responding 1012. In demonstrations of its agentic endurance, Gemini 2.5 was able to autonomously complete the video game Pokémon Blue over the course of 406 hours, relying heavily on its massive context window and tool-use capabilities to maintain its place in the game world 1026.
Bottom line
The numbers behind artificial intelligence have matured from brute-force bragging rights into complex engineering trade-offs. Parameters dictate a model's underlying knowledge capacity, tokens define its vocabulary and fragile real-time memory, and FLOPs measure the immense energetic and financial cost of training it. As innovations like Mixture-of-Experts, synthetic data training, and advanced attention mechanisms break the old rules of neural scaling, evaluating an AI is no longer about blindly seeking the absolute largest numbers. Instead, it is about matching the model's active footprint and architectural efficiency to your specific hardware constraints and operational goals.