What Happens After You Submit a Prompt to AI
When you submit a prompt to a large language model, your text is immediately converted into numerical fragments and sent to an inference server where it waits in a dynamic queue. The model then executes a massive, parallel mathematical operation to "read" your entire input at once and build a working memory, before shifting into a slower, memory-bound phase where it calculates and streams back your answer one word at a time.
Behind the illusion of a conversational chatbot lies a highly orchestrated pipeline of data transformations, memory management, and specialized hardware optimization. To understand what happens in the seconds between sending a query and receiving an answer, we must trace the lifecycle of a prompt as it moves from the user interface, down to the graphics processing units (GPUs), and back to your screen.
The Language of Machines: Tokenization
Large language models (LLMs) do not read text the way humans do. They do not possess a biological understanding of sentences, grammar, or even complete words. Instead, they process sequences of numbers. The vital first step in bridging human language and machine computation is a process called tokenization.
Tokenization is the mechanism of breaking your input text into smaller, predefined computational units called "tokens" 12. You can think of tokens as the basic LEGO blocks of language 13. The AI has a finite set of these blocks - its vocabulary - and every prompt must be assembled using only the pieces available in that predefined set.
Depending on the specific model and its chosen tokenization strategy (such as Byte-Pair Encoding, WordPiece, or Unigram), a token might represent a single character, a common syllable, or an entire word 14. For example, the simple word "cat" might be evaluated as a single token, while a complex word like "antidisestablishmentarianism" could be fractured into seven or more distinct tokens 3. Even emojis, spaces, and punctuation marks are converted into individual tokens 35.
The Vocabulary Trade-Off
The size and structure of these tokens dictate the fundamental performance characteristics of the AI. If a tokenizer cuts text into very small pieces (like individual letters), the model only needs a tiny vocabulary dictionary, but the sequences it must process become incredibly long 1. This requires vastly more computational power to evaluate. Conversely, if the tokenizer uses whole words, sequences are short and fast to process, but the model's vocabulary must be massive to account for every conceivable word in existence, drastically increasing the memory required to host the model 15.
Modern LLMs strike a pragmatic balance. They use subword tokenization, merging frequent character pairs (like "th" or "ing") into single tokens to optimize both sequence length and vocabulary size 1. Once your prompt is tokenized, each token is mapped to a unique integer ID and converted into a numerical vector representation 45. Only then is your prompt ready to be sent to the AI's neural network.
The Limits of the Context Window
Every LLM operates with a strict "context window," which is the absolute maximum number of tokens it can hold in its working memory at any given time 3. This limit includes both your input prompt and the model's generated output.
At each step of generation, the LLM can only reason over the tokens currently residing inside this context window 6. If a conversation drags on and exceeds this limit, older tokens are typically dropped, causing the model to "forget" earlier instructions and potentially hallucinate 6. Because processing power and financial cost scale alongside the number of tokens, minimizing the token footprint of your prompt is a crucial aspect of engineering robust AI systems.
Preparing the Request: Structural Parsing and Delimiters
Before the tokenized prompt is pushed to the GPUs, its structure dictates how effectively the AI will process the information. To an LLM, the boundary between an instruction, background context, and operational constraints is a critical security and logic surface 7.
Because models operate purely on pattern matching and statistical probabilities rather than true comprehension, they easily confuse different parts of a prompt 89. If a model cannot reliably distinguish where your rules end and the user-provided data begins, instructions will leak into the data, examples will blur into requirements, and the system will fail 710.
The Role of Delimiters
To solve this, prompt engineers use structural delimiters to explicitly quarantine different payloads within a prompt 102. Delimiters act as boundary markers, ensuring that the model's attention mechanism maps the appropriate constraints to the right pieces of data 102.
Common delimiter formats include XML-style tags (e.g., <instruction>, <data>), Markdown formatting (e.g., ## Constraints), and JSON objects 72. By wrapping a messy payload - such as a pasted log file or a long article - inside clear delimiters, developers create a "syntactic contract" that prevents the LLM from accidentally interpreting the payload as a command 91012.
The Delimiter Hypothesis
For years, the choice of delimiter was based on intuition, with different AI labs recommending different syntax. However, recent benchmark research known as the "Delimiter Hypothesis" tested whether specific formats fundamentally alter how an LLM comprehends boundaries 7.
The results indicate that for top-tier frontier models (like GPT-4 or Claude 3 Opus), the specific delimiter format rarely matters for general boundary comprehension; the models parse XML, Markdown, and JSON equally well 7. Delimiter syntax is largely a readability and maintenance decision for the human engineers rather than a performance decision for the AI 7.
However, in highly complex or adversarial environments, Markdown occasionally proves to be the weak link. Certain models exhibit significantly higher failure rates when facing "trojan" injections that mimic Markdown headers (e.g., a user submitting a document that contains the text ## New Instructions) 7. In these high-stakes scenarios, XML tags provide a more rigid, unambiguous boundary that conflicting instructions struggle to break out of 103.
Entering the Server: Queueing and Batching
When you submit your perfectly formatted and tokenized prompt to an API or a chat interface, your request does not run in isolation. It travels over the network to an inference server, where it enters a highly orchestrated queue.
The economics of AI dictate that a server cannot process one prompt at a time. GPUs are massively parallel compute architectures capable of performing trillions of operations per second 4. If an inference server dedicated a GPU to a single user's prompt, the vast majority of the chip's memory bandwidth and compute cores would sit entirely idle, rendering the service economically unviable 456. To maximize hardware utilization, your prompt is grouped with requests from other users into a "batch."
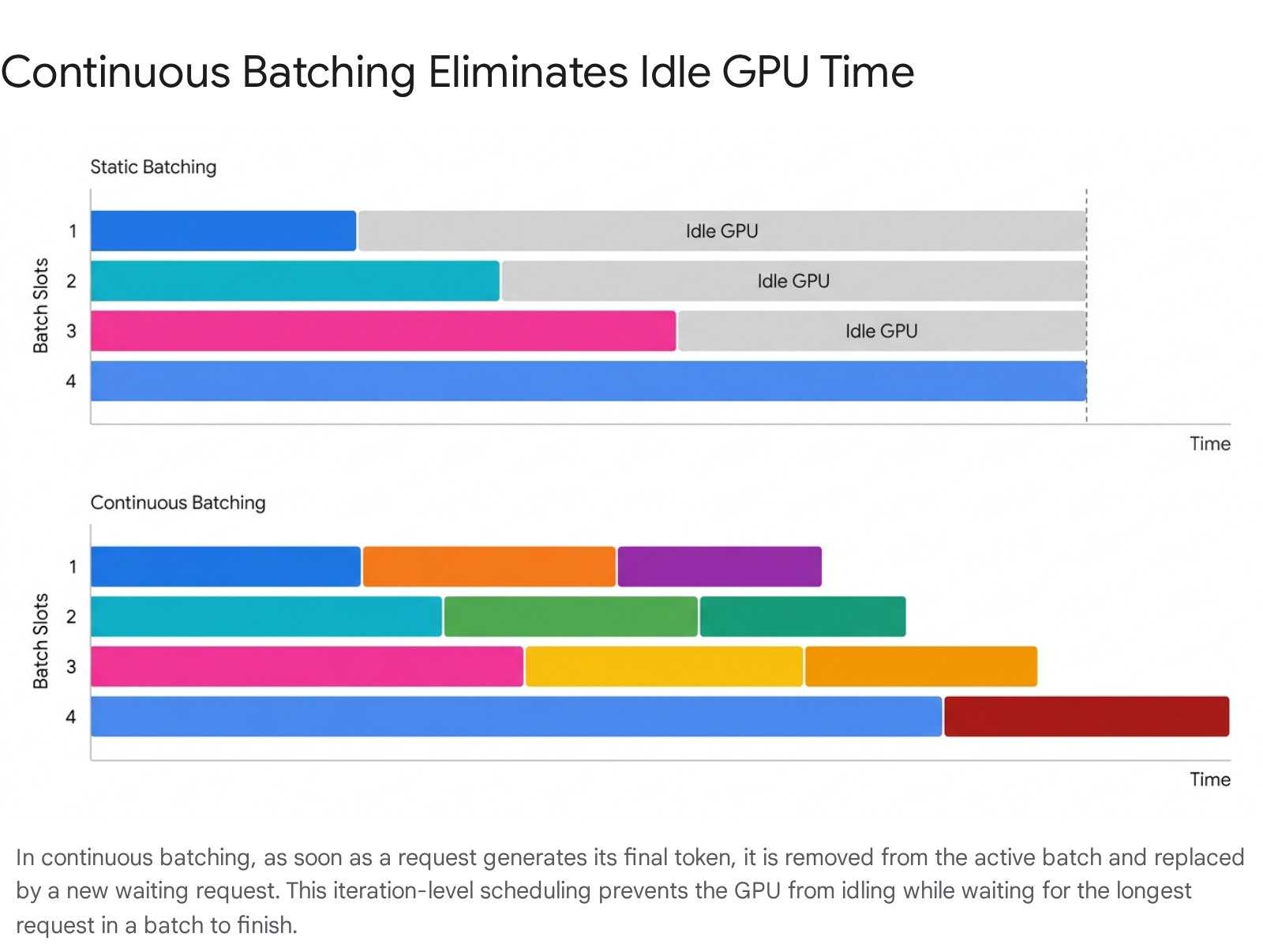
The Problem with Static Batching
Historically, inference engines utilized static batching. Under this paradigm, the server would wait for a predetermined number of requests to arrive, bundle them together, and process them simultaneously 46.
While this improved throughput compared to single-request processing, it was highly inefficient due to the variable length of human language 4. If a batch contained one user asking for a 5-token translation and another user asking for a 500-token essay, the static batch could not finish until the 500-token essay was complete 6. The first user's compute slot sat completely empty for 495 cycles, wasting valuable GPU resources 56.
Continuous Batching and Iteration-Level Scheduling
To solve the idle-time problem, modern inference engines - such as the open-source vLLM framework and Hugging Face's Text Generation Inference (TGI) - introduced a paradigm shift known as continuous batching (or dynamic iteration-level scheduling) 4177.
Continuous batching operates at the granularity of a single token generation step, rather than waiting for an entire request to finish 17. The core principle is fluid insertion and eviction: as soon as one user's prompt finishes generating its final token, the server immediately ejects that request from the active batch 417. In the exact same millisecond, the scheduler pulls a new pending prompt from the waiting queue and inserts it into the newly freed slot 417.
This ensures that the batch composition changes dynamically between any two consecutive iterations, and that the GPU is never waiting on a long-tail response 417. By eliminating synchronization barriers at the request level, continuous batching allows providers to achieve up to 23x higher token throughput compared to naive static batching 47.
Once your prompt is pulled from the queue and injected into an active continuous batch, the true neural network computation begins. From an engineering perspective, this computation is strictly divided into two fundamentally different phases that behave almost like entirely different applications: the Prefill phase and the Decode phase.
The Prefill Phase: Reading the Prompt
The first active stage of LLM inference is the prefill phase. This is the stage where the model "reads" your prompt and establishes the vast mathematical context necessary to formulate an answer 19821.
Remarkably, even if your prompt is thousands of words long, the LLM does not read it sequentially like a human reading a book. Instead, the model processes every single input token simultaneously in a massive, single forward pass through its transformer layers 82122.
During this pass, the model's self-attention mechanism compares every token in your prompt against every other token 2324. This cross-referencing is how the model calculates semantic relationships, context, and grammar - for example, determining that the word "apple" refers to the fruit rather than the technology company based on the surrounding adjectives 9.
Parallel Computation and the Compute Bound
Because all of the input tokens are available to the model upfront, the prefill phase is highly parallelizable 821. It relies heavily on the GPU's raw mathematical calculation speed.
During prefill, the workload is dominated by large, dense matrix multiplications that are perfectly suited for the thousands of cores on modern hardware 824. The GPUs will often run at 90% to 95% utilization during this phase, performing hundreds of arithmetic operations for every byte of memory they access 26. Because performance is dictated primarily by how fast the chips can crunch numbers, the prefill phase is classified as compute-bound 242610.
However, this parallel processing comes at a cost. The attention mechanism's complexity scales quadratically with sequence length 2324. Processing a 50,000-token prompt requires exponentially more math than processing a 5,000-token prompt, which is why long inputs can cause significant delays 222311.
Building the Key-Value (KV) Cache
The ultimate goal of the prefill phase is not actually to generate your answer. The goal is to build an internal state representation known as the Key-Value (KV) cache 1981029.
In a transformer architecture, tokens interact by generating "Queries," "Keys," and "Values" 2330. If the model were to discard these mathematical representations after reading your prompt, it would have to completely re-read and re-calculate your entire input - plus every word it has generated so far - just to predict the next single word 823. This redundant recomputation would scale disastrously and grind text generation to a halt 523.
To avoid this, the model calculates the Keys and Values for every token in your prompt during the prefill phase and stores them persistently in the GPU's memory 82330. This KV cache acts as the model's short-term working memory 1912. When the model needs to generate the next word, it simply references this cached memory rather than recalculating the past 8.
Prefix Caching and Reusing Context
If you are interacting with a chatbot that uses a massive "System Prompt" (a hidden set of instructions governing its persona and rules), running the compute-heavy prefill phase for that identical system prompt on every single user request would be a colossal waste of server energy.
Modern inference engines bypass this redundancy using Automatic Prefix Caching 3213. By hashing the prompt prefix block-by-block, the system can instantly check if it has already calculated the KV cache for a specific string of text in a previous session 131415.
If it finds a match - such as a standardized system prompt, a commonly retrieved RAG (Retrieval-Augmented Generation) document, or few-shot examples - it pulls the pre-computed KV cache directly from the global memory pool 3214. This skips the prefill computation entirely for that segment of text. For standard chatbot workloads with shared system prompts, cache hit rates can reach 80% to 95%, saving up to 97% of the initial prefill computation and dramatically speeding up response times 14.
Chunked Prefill for Long Prompts
Conversely, what happens if your prompt is entirely novel and incredibly long, such as uploading a 100-page legal contract?
Because the prefill phase requires massive parallel computation, a single user's long prompt can easily saturate a GPU's compute capacity 1617. In early continuous batching systems, a long prefill would monopolize the server, forcing all other users in the batch to wait - pausing their text generation mid-sentence until the large document was fully processed 261617.
To prevent these latency spikes, engines like vLLM implement Chunked Prefill 171819. Instead of attempting to process a massive prompt in one giant, uninterrupted gulp, the engine divides the input sequence into smaller, fixed-size chunks (e.g., 512 or 4,096 tokens) 1718. The scheduler then interleaves the computation of these chunks with the generation steps of other users 1719. While this slightly increases the time it takes to process the long document, it ensures the overall system remains responsive and prevents long prompts from starving the decode queue 161740.
The Decode Phase: Generating the Response
Once the prefill phase concludes and the initial KV cache is safely stored in memory, the model transitions into the decode phase. This is the stage where the AI actually writes your answer, predicting and streaming tokens one by one 19821.
Unlike the highly parallel prefill phase, decoding is strictly sequential and autoregressive 5721. The model must predict the first word, append it to the sequence, use that new word to predict the second word, and so on 72141. You cannot parallelize the creation of a sentence if you do not yet know how the sentence begins.
The Autoregressive Bottleneck
This sequential nature fundamentally shifts how the hardware operates. Because the model is only processing a single new token at a time, the GPU's massive array of compute cores finishes the required math in a matter of microseconds 2426.
However, to generate that single token, the system must load the model's entire set of parameter weights (which can exceed 140 gigabytes for large 70B+ parameter models) as well as the entire historical KV cache for the user's session 72426.
The GPU pulls this massive volume of data from its High Bandwidth Memory (HBM) into its compute cores, uses it for a fraction of a millisecond to guess the next word, and then must move all of that data again to guess the word after that 2426.
Why Decode is Memory-Bound
Because of this constant, heavy data movement paired with minimal mathematical computation, the decode phase is entirely memory-bandwidth bound 8241029.
During decode, the arithmetic intensity drops precipitously, and overall GPU compute utilization can fall to between 20% and 40% 2629. The compute cores literally sit idle, waiting for data to travel across the physical silicon of the chip. Consequently, the speed of text generation is determined not by how fast the AI can "think" or do math, but by the physical limits of memory latency and bandwidth 81029.
This stark contrast between prefill and decode is the defining engineering challenge of modern LLM inference.
| Feature | Prefill Phase | Decode Phase |
|---|---|---|
| Primary Task | "Reads" the prompt in a single forward pass to build context. | "Writes" the response one token at a time in a sequential loop. |
| Execution Style | Massive, dense parallel computation. | Sequential, autoregressive generation. |
| Hardware Bottleneck | Compute-bound (limited by tensor math speed). | Memory-bound (limited by data transfer bandwidth). |
| GPU Utilization | Very high (keeps all compute cores busy). | Low (compute cores wait on memory reads). |
| User Experience Impact | Determines initial wait time before the response begins. | Determines the speed at which text streams to the screen. |
8241029172021
Managing the KV Cache: PagedAttention
As the decode phase churns through a response, the KV cache grows larger with every new word generated 530. Managing this ever-expanding memory footprint is one of the hardest challenges in AI infrastructure.
Historically, inference systems had to guess how long a user's conversation might get and pre-allocate a massive, contiguous block of GPU memory for the KV cache right at the start of the request 18.
The Memory Fragmentation Problem
This contiguous allocation created severe memory fragmentation 44. If the system reserved 2,000 tokens of memory but the AI ultimately only replied with a 50-token answer, the remaining 1,950 slots of pre-allocated memory were entirely wasted 44. Because GPU High Bandwidth Memory is the most expensive and constrained resource in an AI server, this fragmentation severely limited how many users could be batched together concurrently, driving up the cost of inference 45.
Virtual Memory for AI
Developed by researchers at UC Berkeley, the open-source vLLM inference engine solved this fragmentation crisis by introducing PagedAttention 444522.
PagedAttention borrows a classic concept from computer operating systems: virtual memory with paging 44. Instead of demanding a single, contiguous block of memory for a user's prompt, PagedAttention divides the KV cache into small, fixed-size logical blocks (typically containing 16 tokens each) 1847.
The system dynamically allocates these blocks on the fly as the text is generated 1847. These physical blocks do not need to sit next to each other on the GPU; they can be scattered wherever free space exists. The engine tracks them via a centralized block table, mapping the logical sequence to the physical memory addresses seamlessly 1847.
By allocating memory strictly on-demand, PagedAttention nearly eliminates waste and fragmentation. This allows inference servers to cram vastly more concurrent requests into the GPU's memory, yielding massive improvements in throughput and lowering the economic cost of serving LLMs at scale 444522.
Advanced Inference Optimizations
Because the physics of memory bandwidth place a hard ceiling on how fast an LLM can generate text, AI engineers have developed several brilliant architectural optimizations to bypass these hardware limitations.
Disaggregated Serving
In standard deployments, a single server handles both the compute-heavy prefill phase and the memory-heavy decode phase 26. As discussed, this causes friction: a large prefill request can spike compute usage and interrupt the steady cadence of token generation for other users 2616.
To resolve this, large-scale deployments increasingly use Disaggregated Serving (or Prefill-Decode Disaggregation) 52629. This architecture physically separates the two phases onto entirely different machines 2629.
A "Prefill Pool" of GPUs, optimized for high-throughput matrix multiplication, is dedicated solely to processing incoming prompts and building the KV cache 2629. Once the prefill is complete, the KV cache tensors are rapidly transferred over high-speed networks (like NVLink or InfiniBand) to a separate "Decode Pool" of GPUs 526. These decode GPUs are optimized strictly for high memory bandwidth and handle nothing but autoregressive token generation 26.
By decoupling the workloads, companies can scale prefill and decode hardware independently, preventing latency spikes and significantly reducing operational costs 2629.
Speculative Decoding
If the decode phase is fundamentally bottlenecked by the slow process of loading massive model weights into memory for every single token, how can text generation be accelerated for the end user? The answer is Speculative Decoding 2349.
Speculative decoding leverages two models simultaneously: your massive, slow "Target Model" (e.g., a 70-billion parameter LLM) and a tiny, lightning-fast "Draft Model" 2349.
Instead of forcing the massive Target Model to generate one word at a time, the tiny Draft Model races ahead, quickly guessing the next sequence of tokens (often 3 to 5 at a time) 2324. Because the Draft Model is small, its memory overhead is negligible, and it can generate these tokens almost instantly.
These speculative guesses are then grouped together and fed into the massive Target Model 2324. Because checking existing work is highly parallelizable compared to generating work from scratch, the Target Model can verify all the guessed tokens in a single, memory-efficient forward pass 2324.
If the Target Model agrees with the Draft Model's guesses (the "acceptance rate"), all the tokens are accepted and instantly streamed to the user, effectively bypassing the sequential memory bottleneck 2324. If the Target Model spots an error - say, it disagrees with the third guessed token - it accepts the first two, corrects the third, and discards the rest 24.
Because the superior Target Model always has the final say, this technique offers a 2x to 3x speedup in token generation without any degradation in the final output quality or accuracy 492425. The success of speculative decoding hinges on finding a Draft Model that is significantly faster than the Target Model (high speed ratio) while maintaining a reasonably high accuracy rate 24.
Streaming the Output: Server-Sent Events (SSE)
As the decode phase or speculative decoding process churns out verified tokens, users expect immediate feedback. Waiting 10 to 30 seconds for a complete paragraph to arrive before displaying anything would feel unacceptably sluggish 2026. To make the AI feel responsive, applications stream the text to your screen in real-time, word by word 2627.
This streaming is almost universally handled via a web protocol called Server-Sent Events (SSE) 262829.
When you submit your prompt via an API or chat interface, the server holds the HTTP connection open, tagging it with a Content-Type: text/event-stream header 28. As the GPU's decode phase finalizes each token, the server wraps that text string in a small JSON payload and immediately pushes it down the open HTTP connection as a discrete event 2628. Your browser receives these micro-updates and paints the tokens to the Document Object Model (DOM) sequentially, creating the familiar "typing" effect 2628.
Why Not WebSockets?
While WebSockets are famous for real-time applications, they are often overkill for standard AI chatbots. WebSockets establish a heavy, persistent, bidirectional TCP connection, allowing both the client and server to push messages at any time 2829.
For simple prompt-in, tokens-out generation, bidirectional communication is unnecessary. SSE operates over standard HTTP, avoiding complex handshake overhead while natively handling one-way, server-to-client event pushing 2829. However, as AI moves toward multi-modal capabilities - such as real-time voice interruption or agentic workflows that require user approval mid-generation - architectures are beginning to shift toward WebSockets to accommodate persistent, two-way signaling 2829.
Latency Metrics: TTFT and TPOT
For engineers managing these inference systems, the user experience of this entire pipeline is quantified using two critical latency metrics that map directly back to the prefill and decode phases 221221:
- Time to First Token (TTFT): This is the delay between hitting enter and seeing the first word appear on your screen 2021. It measures network latency, queue waiting time, and the heavy, compute-bound processing of the prefill phase 2021. If you paste a massive document into the prompt, your TTFT will spike because the prefill phase requires more matrix math to process the larger input 211217.
- Time Per Output Token (TPOT): Also known as Inter-Token Latency (ITL), this metric measures the average pause between each generated word as it streams to your screen 22111221. This is driven entirely by the memory bandwidth constraints of the decode phase 111221.
Because overall generation time scales linearly with output length, asking an AI for a 2,000-word essay will take drastically longer to finish than asking for a 50-word summary, even if the model's typing speed (TPOT) remains perfectly constant 2211. Output length dominates latency far more than input length 22.
Bottom line
The journey from hitting enter to reading a response is a tale of two distinct computational phases operating under the hood of continuous batching. Your prompt is first tokenized and processed in a highly parallel, compute-heavy prefill phase to establish a working memory known as the KV cache. The system then shifts into a memory-bound decode phase, laboriously pulling that cached data back and forth from the GPU memory to stream one token at a time to your screen via Server-Sent Events. While invisible to the user, managing this shift through architectural innovations like PagedAttention, chunked prefill, and speculative decoding is what makes modern, instantaneous AI economically and technically possible.