What Happens Inside an LLM When It Reasons
At the most fundamental level, when a large language model (LLM) processes a prompt and generates a response, it is not "thinking" or "reasoning" in the biological sense; it is executing a highly complex mathematical operation known as probabilistic next-word prediction. During its pre-training phase, an LLM is exposed to massive corpuses of text and trained to minimize its cross-entropy loss, a mathematical measure representing the difference between the model's predicted probability distribution for a subsequent token and the actual token that appeared in the training data 1. When a user submits a query, the model processes the input through billions of parameters and generates raw numerical scores, called logits, for every possible next token in its vocabulary 23. These logits are transformed via a softmax function into a probability distribution, dictating the statistical likelihood of each potential ensuing word fragment 24. The model then selects a token, appends it to the original prompt, and feeds this new, longer sequence back into itself to predict the next token. This autoregressive cycle continues until a predefined stopping condition is met 56. The model does not formulate an overarching plan before it begins typing; it navigates a multi-dimensional probability space one token at a time, generating the illusion of coherent reasoning because it has meticulously mapped the syntactic and semantic structures of human language 78.
The "Strawberry" Paradox: An Everyday Hook into Tokenization
To comprehend the limits and capabilities of this probabilistic engine, one must examine a pervasive contradiction in modern artificial intelligence: how a model can easily pass the Uniform Bar Examination yet fail to correctly count the number of 'r's in the word "strawberry." This phenomenon is not an isolated glitch but a direct manifestation of how LLMs perceive input through subword tokenization 910.
Language models do not process text letter-by-letter. Because computing infrastructure relies on numerical matrices, raw text must be converted into numerical vectors 112. Algorithms such as Byte Pair Encoding (BPE) compress text into chunks known as tokens, which often correspond to syllables or common word fragments 13142. For example, the word "strawberry" is not fed into the model as ten discrete alphabetical characters. The tokenizer might fracture the word into separate tokens, such as ['straw', 'berry'] or ['str', 'aw', 'berry'], assigning each a unique numerical integer 91314.
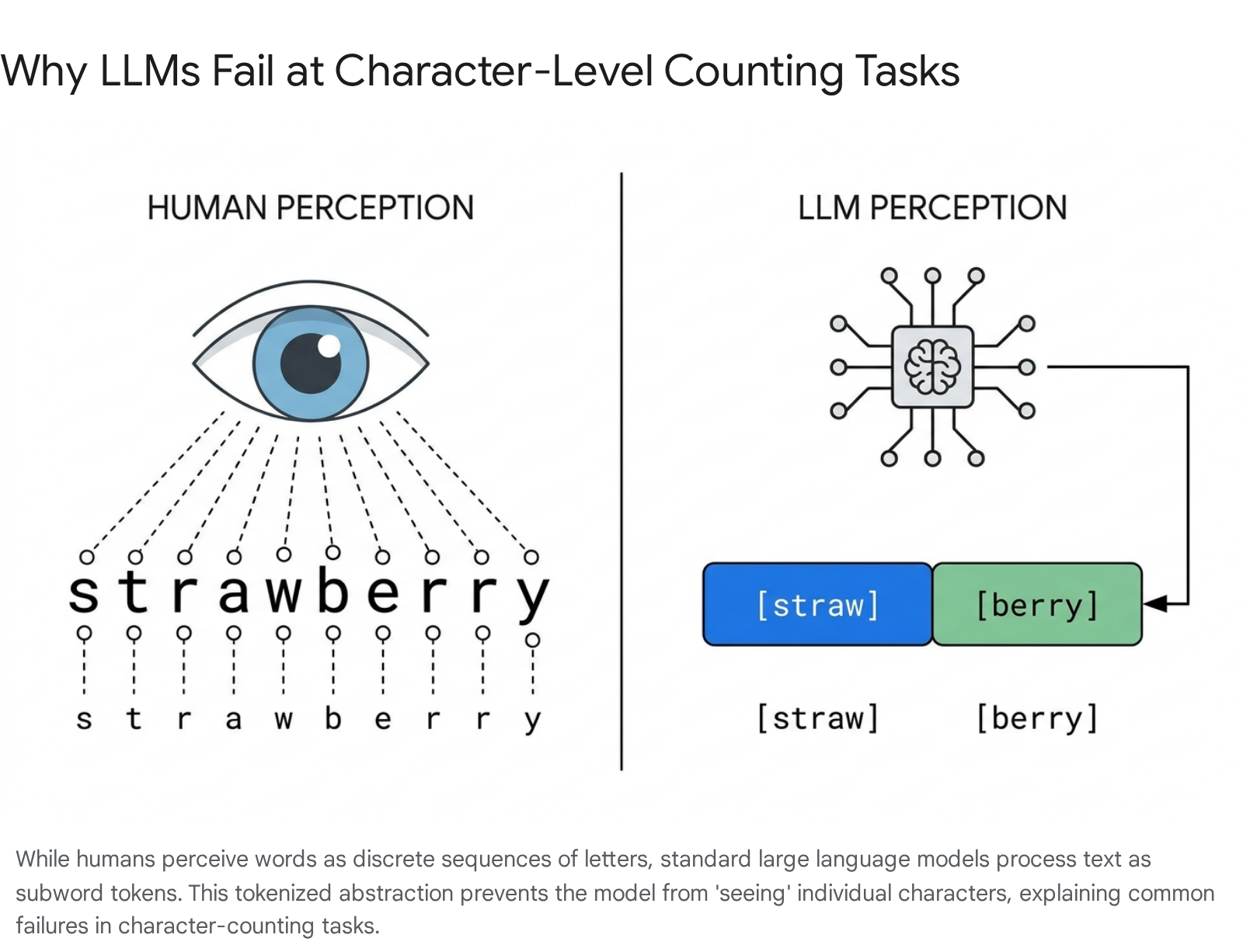
When prompted to count the letters, the model's self-attention mechanism operates exclusively on these tokenized abstractions 113. To the neural network, ['straw', 'berry'] is an opaque mathematical entity representing the semantic concept of a fruit, completely divorced from its orthographic spelling 1. The model suffers from a structural myopia; it literally cannot "see" the individual characters within the token 1013. Because its core objective is next-token prediction, it attempts to answer the counting query by relying on statistical correlations - guessing based on similar language patterns seen during training - which frequently results in confident but mathematically incorrect assertions 91013. Conversely, passing a bar exam requires matching vast, high-dimensional semantic patterns of legal text, a task perfectly aligned with the model's core architectural strengths.
Translating the Black Box: Embeddings and Self-Attention
To understand how an LLM navigates complex inputs, one must examine the internal mechanics of the Transformer architecture, specifically how tokenized text is converted into high-dimensional embeddings and processed via self-attention mechanisms 16173.
Once a word is assigned a numerical token ID, it is transformed into an embedding. An embedding is a dense mathematical vector - a coordinate in a massive, high-dimensional space 1920. Within this space, geometric distance equates to semantic meaning. The model learns these coordinates dynamically during pre-training by observing word co-occurrences. The vector representing "king" will be mathematically positioned near "queen," while unrelated concepts like "apple" and "spaceship" will be plotted far apart 23. The embedding space captures profound, implicit relationships, encoding grammar, sentiment, and factual associations directly into the geometry of the network 821. When the LLM generates text, it is essentially calculating a trajectory through this high-dimensional space, drifting from concept to concept based on statistical gravity.
The actual reasoning power of the model, however, is unlocked by the self-attention mechanism. Traditional sequential models, such as Recurrent Neural Networks (RNNs), processed data one step at a time, frequently losing the context of early words by the time they reached the end of a sentence 161722. Self-attention revolutionized this by allowing the model to evaluate the importance of every token relative to every other token simultaneously and in parallel 16323.
Expert educators, including former OpenAI researcher Andrej Karpathy, frequently rely on the analogy of a networking event to demystify self-attention. Imagine a room full of professionals, representing the individual tokens in a sentence. Each professional possesses a specific background, known as their Key vector, and is actively searching for a specific type of expertise, known as their Query vector 3. Within the neural network's attention layers, every token computes a dot product between its Query and the Keys of all preceding tokens 316. If a token's Query closely matches another token's Key, they form a strong mathematical connection, represented as a high attention score 320. Once these connections are established, the tokens exchange their actual informational content, known as the Value vector, based on the strength of those connections 1617.
Consider the sentence, "The animal didn't cross the street because it was too tired." The token "it" contains an ambiguous meaning. Through self-attention, "it" broadcasts a Query searching for a singular noun 24. The token "animal" broadcasts a Key that perfectly aligns with this Query. The model learns that "it" refers to the "animal" and not the "street," dynamically re-weighting the context of the sentence before predicting the next word 1624. This process is repeated across dozens of layers and multiple "attention heads," allowing the model to simultaneously track grammar, tone, entity relationships, and factual dependencies 324.
Target and Debunk: Misconceptions of LLM Functionality
The fluency of modern language models has birthed several pervasive misconceptions regarding their cognitive architecture. Dismantling these myths is essential for understanding the true limitations of autoregressive generation.
The most common misconception is that LLMs operate as vast databases, looking up facts and retrieving them upon request 725. In reality, an LLM contains no internal reference documents, text files, or tabular data 725. Human knowledge is distributed diffusely across the billions of synaptic weights within the neural network 726. When a user asks for a specific fact, the model does not run a search query; it dynamically reconstructs the information by traversing the statistical patterns it absorbed during training 225. This reconstructive, probabilistic nature explains why the model is susceptible to confident fabrications, or hallucinations.
A second profound misunderstanding is the assumption of persistent memory 2627. When interacting with conversational agents, the system appears to recall details from earlier in the dialogue. Technically, the model itself is entirely stateless and suffers from absolute amnesia between each generation cycle 2627. The illusion of continuous memory is engineered by the application interface, which seamlessly concatenates the entire conversation history and re-submits it to the model's context window with every new prompt 2627. The neural network must mathematically process the entire dialogue from the first token to the last, every single time a user submits a query 27. If the conversation exceeds the model's token limit, the earliest information is permanently truncated and forgotten 27.
Furthermore, it is a fallacy to assume that base models utilize human-like deduction or causal logic 72528. When an LLM correctly states that the capital of France is Paris, it does not comprehend geopolitical borders or the concept of a nation-state. It merely recognizes that the high-dimensional vector for "capital of France" is statistically bound to the vector for "Paris" in its training distribution 228. The base model is a pattern-matching engine that recognizes statistical correlations in text, devoid of an inherent understanding of physical world mechanics or causal relationships 28.
The Mechanics of Chain-of-Thought Processing
If base LLMs are merely stochastic next-word predictors, the phenomenon wherein appending the phrase "think step by step" to a prompt radically increases logical accuracy requires rigorous technical explanation. The efficacy of Chain-of-Thought (CoT) prompting represents one of the most significant architectural discoveries in modern natural language processing, transforming standard autoregression into a simulated reasoning apparatus 5294.
The functional success of CoT is rooted in the statistical structure of the model's pre-training data, specifically a concept known as the "locality of experience" 315. Theoretical research into autoregressive density estimators trained on Bayes nets reveals that variables and concepts cluster locally within human knowledge; long, disjointed causal chains are rarely observed simultaneously in training distributions 533. Consequently, if a model is tasked with estimating the relationship between concept A and concept C, but those concepts rarely co-occurred in the training data, a direct prediction (Standard Prompting) will likely result in a probabilistic error 5. However, if the training corpus frequently linked concept A to B, and concept B to C, the model possesses the localized statistical dependencies required to bridge the inferential gap 533.
When a prompt enforces Chain-of-Thought, the model is compelled to generate the intermediate token sequence representing variable B. Because the architecture is autoregressive, the generated tokens for B are appended to the input sequence 531. The model's self-attention layers are subsequently conditioned on both A and B, providing a mathematically robust foundation to successfully predict C 534. CoT allows the model to incrementally chain accurate local inferences, effectively bridging the "reasoning gap" for variables that were not explicitly linked in the training corpus 5636.
From a purely mechanistic standpoint, researchers have proven that CoT acts as a probability funnel 3437.
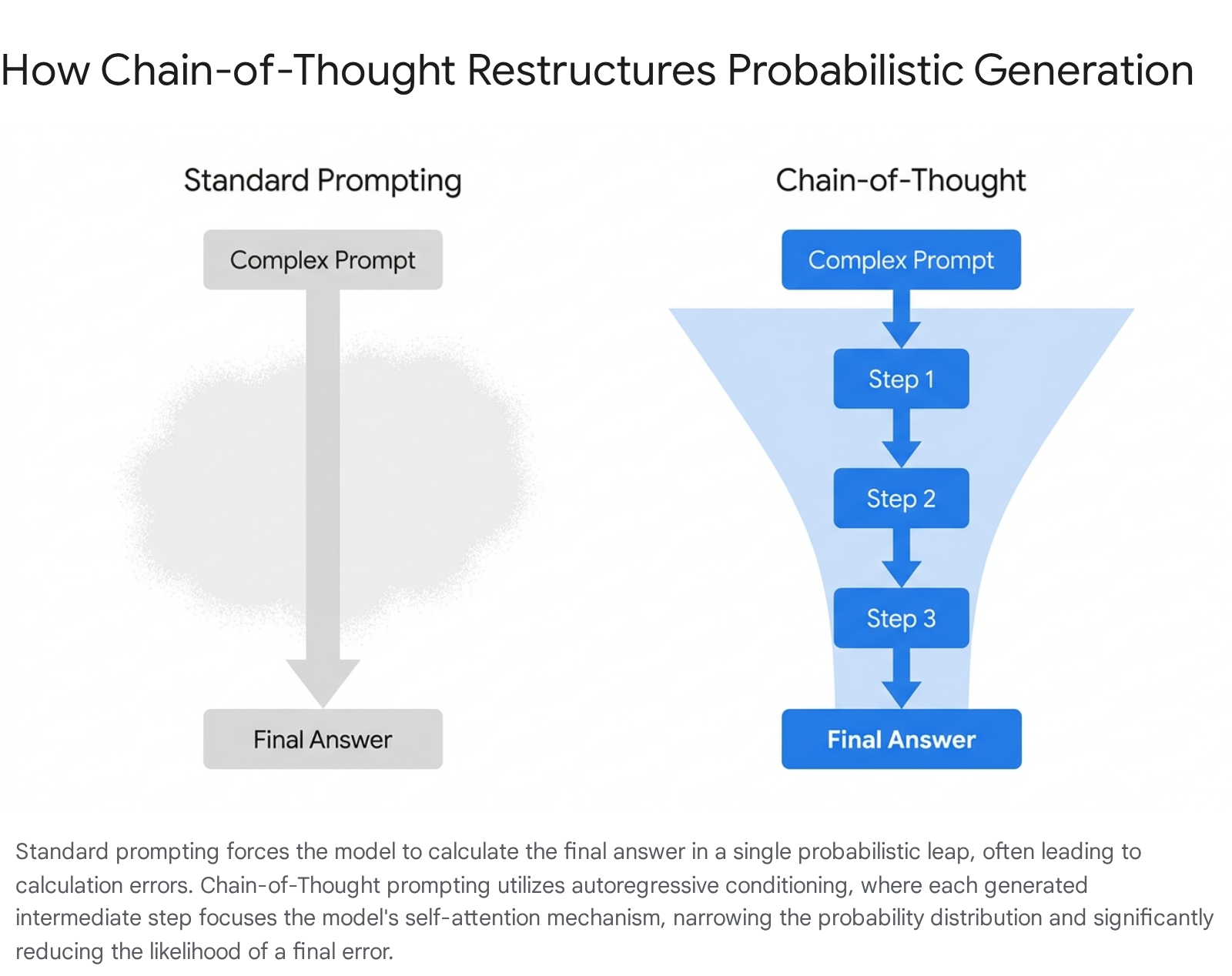
Generating intermediate logical tokens concentrates the probability distribution of the next word tightly onto the correct answer. By externally articulating the problem-solving steps in the context window, the model avoids holding complex, uncalculated variables within its hidden internal states. This structural decomposition significantly reduces the informational entropy of the final generated token, decreasing the uncertainty of correct answers by up to 50 - 80% on logic-heavy tasks 34.
Standard Generation versus Chain-of-Thought Processing
The divergence in computational pathways between standard direct queries and CoT-enabled queries showcases how generation methodology fundamentally alters the model's reliability.
| Feature | Standard LLM Generation | Chain-of-Thought Processing |
|---|---|---|
| Output Trajectory | Single-step direct leap to the final answer. | Multi-step sequential generation of intermediate tokens. |
| Autoregressive Conditioning | Final answer is conditioned solely on the user's initial prompt. | Final answer is conditioned on the initial prompt and the model's own intermediate logic. |
| Probability Distribution | High entropy; wide distribution of possible next tokens resulting in higher hallucination risk. | Low entropy; generation probability funnels tightly toward the correct token sequence 34. |
| Attention Mechanism Focus | Broad attention distributed across the entire initial prompt. | Sequentially focused attention; each step acts as a firm checkpoint to anchor the next calculation 6. |
| Data Efficiency | Prone to failure on complex tasks unless specifically fine-tuned on vast datasets for that exact task type. | Highly data-efficient; leverages localized statistical structures to solve novel problems without task-specific fine-tuning 29315. |
| Token Utilization | Low token consumption (lower latency, faster inference). | High token consumption (slower inference, elevated computational cost) 3839. |
The Paradigm Shift: Test-Time Compute and Reinforcement Learning
For several years, the prevailing hypothesis in AI development was that intelligence scaled linearly with parameter count and pre-training data volume. However, by late 2023 and early 2024, researchers observed diminishing returns when relying solely on pre-training scaling laws for advanced reasoning tasks 404142. The frontier of artificial intelligence subsequently shifted toward maximizing inference-time compute - often referred to as test-time compute 414344.
Test-time compute operates on the principle that a model's performance on complex, open-ended tasks improves substantially if the system is allocated a fixed, non-trivial amount of computational power to "think" dynamically during inference, rather than generating a response immediately 43457. This realization birthed a new class of specialized reasoning models, spearheaded by OpenAI's o-series (o1, o3, o4-mini) and DeepSeek's open-weight R1 model 47488.
Unlike legacy generalist models such as GPT-4, which are heavily optimized via supervised fine-tuning to deliver instantaneous, conversational outputs, modern reasoning models undergo extensive post-training utilizing large-scale Reinforcement Learning (RL) 143951. Through algorithms such as Proximal Policy Optimization (PPO), these models are intrinsically aligned to execute implicit, hidden chains of thought before delivering a final response to the user 435253.
This reinforcement learning process trains the model to proactively break down complex problems, identify logical dead-ends, and iteratively refine its strategy without requiring the user to prompt "think step by step" 7953. Crucially, advanced test-time scaling involves the use of Process Reward Models (PRMs) alongside traditional Outcome Reward Models (ORMs) 525410. A PRM evaluates the logical validity of each individual step within the model's internal scratchpad, allowing the architecture to perform tree-search algorithms and back-track when it detects a hallucination or mathematical error mid-generation 405254. Research demonstrates that allocating optimal test-time compute in this manner enables smaller, highly efficient base models to outperform legacy models that possess 14 times more parameters 4510.
The commercial impact of test-time scaling has been immense. OpenAI's o1 model established the baseline in late 2024, heavily disrupting benchmarks in physics, chemistry, and competitive programming 953. By 2025, the release of the o3 and o4-mini models refined this architecture, drastically reducing the latency associated with "long thinking" while introducing native multimodal reasoning and the ability to autonomously execute tool use during the reasoning chain 8565711.
Simultaneously, DeepSeek-R1 validated that open-source architectures could achieve frontier-level reasoning 4748. Utilizing a Mixture-of-Experts (MoE) architecture, DeepSeek-R1 selectively activates only 37 billion of its 671 billion parameters for any given token, maintaining high computational efficiency 4851. By combining this sparse activation with autonomous RL-driven test-time compute, R1 achieved benchmark parity with OpenAI's frontier models at a fraction of the computational and financial cost 3848.
Measuring Intelligence: Benchmark Performance
The superiority of reasoning models is empirically validated across highly constrained academic benchmarks designed to measure logical deduction, mathematical accuracy, and scientific competence. Benchmarks such as the Graduate-Level Google-Proof Q&A (GPQA), MATH-500, and the American Invitational Mathematics Examination (AIME) reveal profound improvements derived from test-time compute 425960.
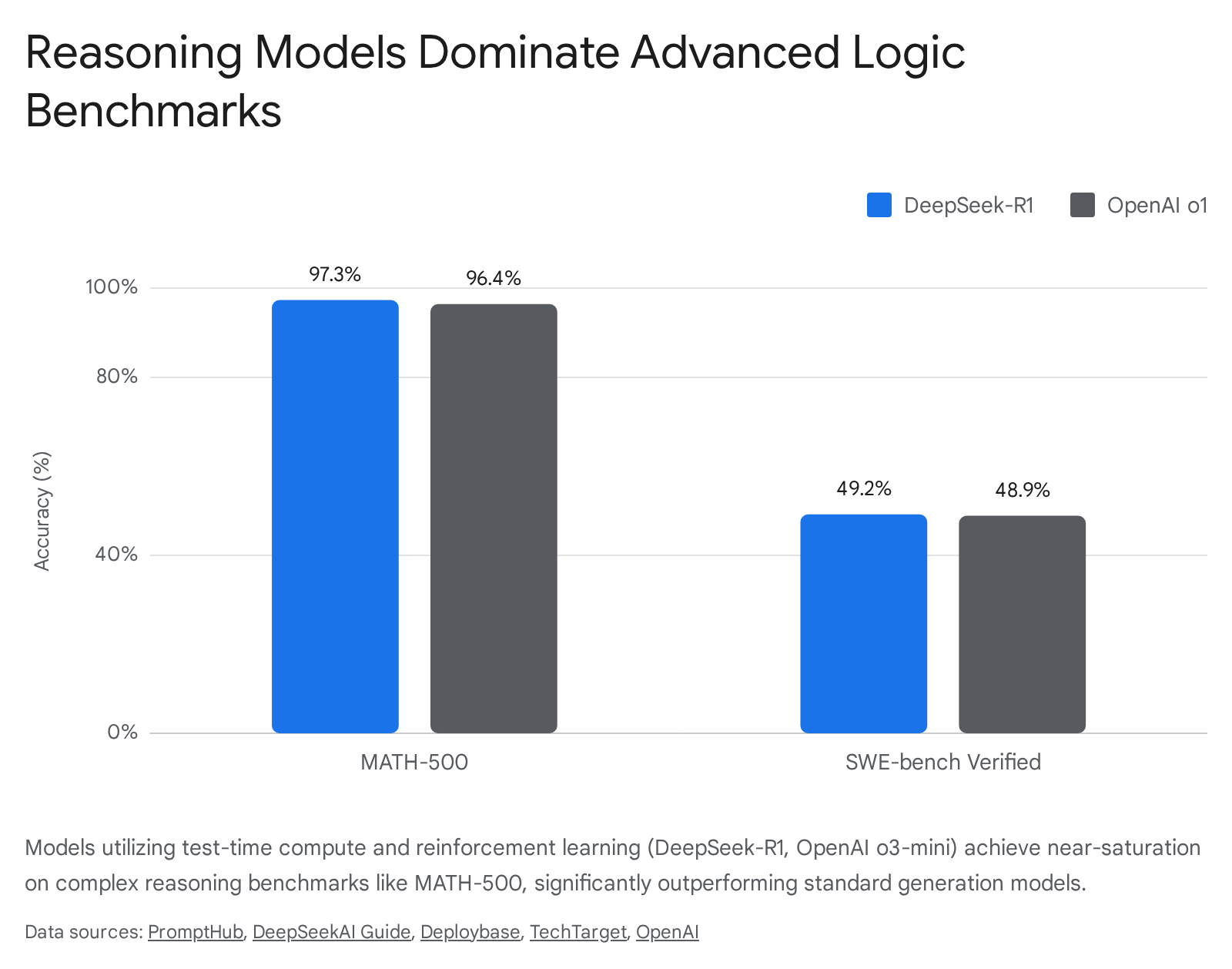
| Benchmark | Focus Area | DeepSeek-R1 Accuracy | Legacy OpenAI o1 (0912) |
|---|---|---|---|
| AIME 2024 (Pass@1) | Elite high school mathematics competition 3848. | 79.8% 48 | 79.2% 48 |
| MATH-500 | Broad collegiate and competition-level mathematics 3847. | 97.3% 3848 | 96.4% 48 |
| SWE-Bench Verified | Real-world software engineering and bug fixing 48. | 49.2% 48 | 48.9% 48 |
While mathematical domains show parity between open-source and proprietary labs, newer proprietary iterations continue to push boundaries. As of 2025 and early 2026, OpenAI's o3 model achieved 88.9% on the AIME 2025 evaluation, while models like Gemini 3.1 Pro established dominance on the notoriously difficult GPQA Diamond benchmark (scoring 94.3%), confirming that test-time scaling combined with immense base knowledge produces systems capable of PhD-level scientific reasoning 861.
Current Debates: Stochastic Parrots vs. Emergent World Models
The evolution from simple autoregressive completion engines to dynamic test-time reasoners has heavily polarized the computational linguistics community. The foundational question remains: do these models actually "think," or are they merely highly sophisticated statistical mimics?
For years, critics have leaned on the "Stochastic Parrot" hypothesis, a term coined by prominent linguists to argue that LLMs simply stitch together linguistic forms based on probabilistic correlations without any grounding in meaning or objective reality 626364. Prominent researchers, including Yann LeCun, point out that despite their fluency, standard models fundamentally lack a physical world model, struggle with genuine causal reasoning, and hallucinate violently when confronted with out-of-distribution logic puzzles 2862. According to this view, passing a bar exam or coding a website does not indicate intelligence, but merely reflects the density of legal and programming data in the pre-training corpus 6312.
However, by late 2024 and beyond, mechanistic interpretability research began to challenge the stochastic parrot framing 64126613. Researchers at Anthropic utilized dictionary learning techniques to map the internal "mind" of Claude, discovering that the model possesses highly structured internal representations - referred to as features - for abstract concepts 661415.
When prompted with a query such as "The capital of the state containing Dallas is...", Anthropic's circuit tracing proved that the model does not merely rely on surface-level word correlations 1415. The model internally activates a feature representing the concept of "Texas," and subsequently uses that abstract conceptual activation to calculate the final output token "Austin" 1415. When researchers surgically intervened and altered the internal activation from "Texas" to "California," the model reliably output "Sacramento" 14.
Furthermore, evidence suggests that large models spontaneously develop internal "world models" to navigate tasks. Studies evaluating models trained exclusively on text describing the moves in the board game Othello revealed that the neural network independently constructed a two-dimensional spatial map of the board state within its hidden layers to predict accurate legal moves 13. Similarly, in complex language tasks, models have been found to encode distinct spatial and temporal coordinates 13. These findings indicate that while LLMs lack biological consciousness, they possess a functional form of introspection and abstract conceptual manipulation that transcends mere stochastic parroting 131671.
Applied Autoregression: Practical Takeaways for Prompt Engineering
The technical realities of tokenization, attention mechanisms, and test-time compute directly translate into practical strategies for end-users seeking to optimize LLM performance. Understanding the model's architecture allows for the precise engineering of prompts that mitigate errors and harness the system's full cognitive potential.
First, users must recognize the limitations of subword tokenization and actively avoid utilizing LLMs for strict character-level manipulation. Because the model processes clustered vector blocks rather than individual letters, tasks requiring exact string reversal, anagram generation, or granular letter counting will frequently result in probabilistic failures 913142. For such requirements, modern workflows should leverage models capable of tool-use, invoking external code interpreters to execute deterministic string functions rather than relying on the neural network's internal estimations 1457.
Second, users must structure prompts to exploit the mathematical behavior of the self-attention mechanism. Attention layers allocate computational weight based on the proximity and clarity of contextual markers 1624. When submitting lengthy context windows containing reference documents, users should utilize clear XML tags or Markdown headers to explicitly separate instructions from the data. Crucially, because the autoregressive engine places the heaviest mathematical focus on the most recently ingested tokens prior to generation, the most critical instructions and output constraints should always be placed at the absolute end of the prompt 416.
Finally, the advent of specialized reasoning models necessitates a recalibrated approach to Chain-of-Thought prompting. Historically, appending the phrase "think step by step" was universally recommended to force standard models to generate intermediate tokens, thereby narrowing the probability distribution and preventing logical leaps 634. However, recent evaluations reveal that manually forcing CoT on modern architectures can actually degrade performance 3917. For contemporary, non-reasoning models, explicit CoT prompts provide marginal gains but introduce significant variability and response latency 17. For dedicated reasoning models (such as o3 or DeepSeek-R1), which are already optimized via reinforcement learning to execute internal test-time compute, adding manual CoT instructions is redundant 3917. It increases token consumption and latency without corresponding improvements in accuracy, and can even induce errors through overly verbose rationalizations 391773. Modern prompt engineering requires matching the task complexity to the model type: utilizing fast, standard models for factual retrieval and summarization, and reserving test-time reasoners for high-complexity mathematical and logic domains without artificially constraining their internal search processes 39717.
Conclusion
The architecture of artificial thought is defined by the transition from static pattern recognition to dynamic, iterative problem solving. The historical critique of large language models as mere "stochastic parrots" - systems limited to regurgitating statistical correlations - has been largely dismantled by advances in mechanistic interpretability and reinforcement learning. By translating raw text into high-dimensional embeddings and applying self-attention mechanisms, modern neural networks construct functional, abstract representations of concepts that mirror genuine deduction.
The industry's pivot toward test-time compute and reinforcement learning architectures, exemplified by models like OpenAI o3 and DeepSeek-R1, represents a paradigm shift in machine intelligence. Providing a neural network the computational budget to generate intermediate reasoning chains, evaluate its own logic via Process Reward Models, and backtrack from errors effectively bridges the gap between probabilistic text generation and rigorous analytical reasoning. Recognizing these underlying mathematical realities - from the myopia of tokenization to the probability funnel of autoregressive conditioning - is essential for accurately evaluating, safely deploying, and effectively interacting with the next generation of artificial intelligence.