Key-Value Cache in Large Language Model Inference and Economics
The deployment of large language models (LLMs) at scale has exposed a fundamental mismatch between the theoretical computational requirements of transformer architectures and the physical memory constraints of modern hardware. During the lifecycle of an LLM request, inference is divided into two distinct phases: the prefill phase, where the model processes the initial prompt, and the decode phase, where the model generates subsequent tokens autoregressively 1. While the prefill phase is primarily compute-bound, the decode phase is severely memory-bound 21.
The primary driver of this memory bottleneck is the Key-Value (KV) cache. In a standard autoregressive transformer, generating a new token requires computing attention scores across all preceding tokens. To avoid redundant matrix multiplications at every step, inference engines cache the previously computed Key and Value vectors for each token 23. However, as sequence lengths expand from thousands to millions of tokens, and as serving systems attempt to handle massive multi-tenant concurrency, the KV cache transitions from a minor operational optimization to the dominant cost factor in data center economics 67.
This report provides an exhaustive analysis of the KV cache bottleneck, examining the mathematical realities of context generation, system-level memory management solutions, architectural interventions, precision optimizations, and alternative sequence modeling paradigms.
The Mathematical Footprint of Context Generation
To understand the economic and technical severity of the KV cache, one must isolate the exact mathematical footprint it imposes on graphical processing unit (GPU) memory. In a standard transformer model, the attention mechanism generates a Key vector and a Value vector for every token, across every layer, and every attention head 8.
The total memory required for the KV cache can be calculated using a deterministic formula:
KV Cache Size = 2 * L * H_kv * d_h * S * B * P 74
The variables in this equation represent the architectural constants and runtime variables of the deployed model: * 2: Represents the two distinct tensors stored (one Key, one Value). * L: The number of hidden transformer layers in the model architecture. * H_kv: The number of key/value attention heads. * d_h: The dimension of each individual attention head (typically derived by dividing the hidden size by the total number of attention heads). * S: The sequence length in tokens, comprising both the initial prompt and the tokens generated thus far. * B: The batch size, representing the number of concurrent sequences being processed simultaneously. * P: The precision multiplier in bytes per parameter (e.g., 2 bytes for 16-bit precision such as FP16 or BF16, 1 byte for 8-bit precision such as FP8).
Hardware Limitations and Scaling Realities
When applying this formula to enterprise-scale models, the memory implications demonstrate why context scaling is economically prohibitive without optimization. The per-token memory tax remains constant for a fixed architecture, but the aggregate size grows linearly with the sequence length and linearly with the batch size, compounding the infrastructure requirements 174.
For instance, Llama 3 70B is configured with 80 layers, 8 KV heads, and a head dimension of 128. Under standard 16-bit precision (2 bytes), the mathematical per-token footprint is 2 * 80 * 8 * 128 * 2, which equals 327,680 bytes, or approximately 320 kilobytes (KB) per token 75. While this appears manageable for short queries, the scaling properties at modern context lengths are severe.
| Context Length (Tokens) | Single Request KV Cache Size (GB) | Concurrent Requests (Batch Size = 32) (GB) |
|---|---|---|
| 4,000 | 1.25 GB | 40 GB |
| 32,000 | 10.00 GB | 320 GB |
| 128,000 | 40.00 GB | 1,280 GB |
| 1,000,000 | 312.50 GB | 10,000 GB |
Data calculations based on standard Llama 3 70B architecture parameters at BF16 precision 675.
As the data indicates, an 80GB Nvidia A100 or H100 GPU provides sufficient High Bandwidth Memory (HBM) to host the model weights (~140GB across two GPUs in 16-bit precision) but rapidly exhausts its remaining capacity when managing context 1611. At a 128,000-token context window, a single request requires over 40 GB of KV cache memory. Attempting to batch 32 concurrent users at this context length inflates the cache requirement to 1.28 terabytes (TB) 75.
Because inference hardware such as the TPU v5e operates with only 16GB of memory per chip, and top-tier GPUs operate with 80GB to 144GB, long-context inference natively demands extensive multi-node distributed architectures. Specifically, serving 32 concurrent 128K requests for a 70B model would mathematically require dozens of GPUs strictly to hold the intermediate attention state, leaving hardware computationally idle but memory-saturated 175.
Structural Inefficiencies in Baseline Memory Allocation
Before the introduction of specialized memory management systems, early LLM serving frameworks treated the KV cache as a static, contiguous tensor array. Because the exact length of an autoregressive generation is entirely unknown prior to execution - a prompt might yield a 10-token response or a 2,000-token response - allocators reserved memory based on the model's maximum possible sequence length 81213.
This monolithic memory allocation strategy resulted in three severe forms of hardware waste: 1. Reservation Waste: Systems pre-allocated vast swaths of memory that were permanently locked for the duration of the request. If a system allocated 2,048 token slots but the generation concluded at 600 tokens, 1,448 slots remained entirely empty but unavailable to other processes 813. 2. Internal Fragmentation: Even within the actively utilized portion of a reserved slab, the KV cache grows dynamically step-by-step. During the early stages of generation, the vast majority of the reserved tensor space remains empty 8. 3. External Fragmentation: As diverse requests of varying lengths initiate and terminate, the GPU memory space becomes segmented. This creates a "Swiss cheese" effect, where significant total free memory exists in aggregate, but no single contiguous block is large enough to satisfy a new request's monolithic allocation requirement, resulting in out-of-memory (OOM) errors and rejected requests 8136.
Empirical measurements of legacy serving systems revealed the catastrophic impact of these inefficiencies. Due to fragmentation and over-reservation, production systems routinely utilized only 20% to 38% of their allocated KV cache memory 81278. The remaining 62% to 80% of the single most expensive component of LLM inference was held in reserve, effectively throttling the maximum concurrent batch size and drastically reducing the financial return on investment for GPU infrastructure 28.
Virtual Memory Systems and PagedAttention
To resolve the contiguous allocation bottleneck, the PagedAttention algorithm - which forms the foundation of the vLLM inference engine - adapted classical operating system concepts to neural network memory management 2139.
Operating systems historically solved dynamic memory allocation through virtual memory paging, dividing physical memory into discrete pages and mapping them to a contiguous logical address space 2138. PagedAttention applies this exact mechanism to the KV cache. Instead of allocating one massive continuous block per request, the system fragments the KV cache into non-contiguous, fixed-size physical blocks (pages). Each page typically contains the keys and values for a small, predefined number of tokens, standardly set to 16 tokens per block 689.
During execution, the serving engine maintains a per-sequence block table that acts as a translation layer. The custom CUDA attention kernels accept a list of block pointers, dynamically fetching the scattered physical pages and treating them mathematically as a concatenated, contiguous sequence for the matrix multiplication 69.
Impact on Utilization and Throughput
The architectural shift to paging fundamentally alters inference economics by eliminating external fragmentation entirely; any available page in the global memory pool can be allocated to any request 610. Furthermore, internal fragmentation is strictly bounded. The only unused memory per sequence is confined to the final, partially filled block. If the block size is 16 tokens, the absolute maximum internal waste per sequence is 15 token slots, reducing allocation waste from over 1,000 tokens in naive systems to a mathematically negligible fraction 8610.
By increasing effective memory utilization from a baseline of ~24% to a sustained ~98.5%, PagedAttention allows inference systems to fit significantly more concurrent requests into the same physical hardware 10. The original vLLM deployment benchmarks demonstrated a 2x to 4x increase in inference throughput without altering the underlying model weights 1278.
Memory Sharing and Copy-on-Write Semantics
Beyond mitigating fragmentation, PagedAttention introduces critical memory sharing capabilities. In production environments, numerous concurrent requests often share identical prefixes, such as lengthy system prompts or retrieved few-shot examples 127.
Under a monolithic memory scheme, each request requires an independent copy of the KV cache for these shared prompts. Under a paged system, the block table can map the logical blocks of multiple distinct requests to the same physical memory blocks 139. The system implements "copy-on-write" semantics; the shared memory is treated as read-only during generation, and new physical blocks are only allocated when a specific request diverges and generates unique tokens 9. This deduplication yields profound memory savings in highly concurrent applications like Retrieval-Augmented Generation (RAG) and multi-agent simulations.
Multi-Tenant Inference and Distributed Cache Systems
As models scale toward million-token contexts, efficient local memory management via PagedAttention becomes insufficient. The total required KV cache for highly concurrent workloads mathematically exceeds the capacity of any single node, prompting the development of distributed KV cache management architectures and storage offloading.
Storage Offloading and File System Bandwidth
To prevent aggressive cache eviction and recomputation when the GPU DRAM is saturated, modern multi-tenant systems attempt to offload the KV cache to CPU RAM or distributed storage backends (e.g., NVMe drives or high-performance file systems like IBM Storage Scale and Dell RDMA) 3411.
While offloading extends the effective capacity of the KV cache to petabyte scales, it introduces latency bottlenecks tied to the interconnect bandwidth (e.g., PCIe limits versus NVLink or RDMA). When a request resumes and requires historical context, the time-to-first-token (TTFT) is directly proportional to how quickly the storage backend can deliver the KV data back to the GPU 1112. Empirical models demonstrate that standard storage systems averaging 8 GB/s of sustained throughput cause noticeable TTFT degradation 11. Consequently, efficient multi-tenant deployment requires intelligent cache-aware schedulers that prioritize requests based on their localized KV cache hit rates, minimizing the necessity of cross-bus data transfers 12.
Disaggregated Inference Architectures
The distinct computational profiles of the prefill phase (compute-bound) and the decode phase (memory-bound) have led to disaggregated inference models, such as DistServe 1. In these systems, prefill computations are isolated on dedicated GPU instances optimized for dense matrix multiplications, while the autoregressive decode phase is handled by separate nodes optimized for high memory capacity 1.
The critical challenge in disaggregation is the rapid transfer of the massive KV cache generated during the prefill phase over the network to the decode nodes. Solutions to this involve distributed memory allocators (such as Jenga) that utilize multi-level paging strategies to ensure differing KV cache shapes from heterogeneous models can be transferred and co-located efficiently across a cluster 1.
Architectural Interventions: Query Head Grouping
While system-level paging and offloading optimize how memory is managed, architectural modifications aim to reduce how much memory the model natively requires by fundamentally altering the H_kv variable (number of KV heads) in the memory equation.
Multi-Head vs. Multi-Query Attention
Standard Multi-Head Attention (MHA), introduced in the original Transformer architecture, assigns an independent Key and Value projection to every individual Query head 1314. While MHA maximizes modeling capacity, it scales poorly. To mitigate this, Multi-Query Attention (MQA) was developed. MQA forces all Query heads to share a single, global Key head and a single Value head 151625.
MQA yields the maximum possible memory compression for standard transformers, reducing the KV cache size by a factor equal to the number of original heads (e.g., a 64x reduction). However, this aggressive compression severely limits the model's capacity to represent nuanced relationships in complex text, leading to measurable degradation in perplexity, training instability, and poor downstream task accuracy 7151617.
The Emergence of Grouped-Query Attention (GQA)
Grouped-Query Attention (GQA), formalized by Ainslie et al. (2023), serves as a precise structural interpolation between MHA and MQA 15161828. Rather than reducing all heads to one, GQA partitions the Query heads into discrete groups. Each group shares a single set of Key and Value heads 152819.
The development of GQA proved that language models do not require a 1:1 ratio of queries to key-value pairs to maintain representational fidelity. Furthermore, Ainslie et al. demonstrated that existing, fully trained MHA checkpoints could be efficiently "uptrained" into GQA variants utilizing only 5% of the original pre-training compute budget 15171820. During this conversion process, the original MHA projection matrices are mean-pooled to initialize the new, smaller GQA matrices, followed by rapid fine-tuning 1821.
| Attention Mechanism | Number of KV Heads | KV Cache Size (Relative) | Perplexity & Accuracy |
|---|---|---|---|
| Multi-Head Attention (MHA) | Equal to Query Heads ($H$) | 100% | Baseline Maximum |
| Grouped-Query Attention (GQA) | Intermediate ($1 < G < H$) | ~12.5% - 25% | Near-Baseline (Minimal Degradation) |
| Multi-Query Attention (MQA) | 1 | < 5% | Noticeable Degradation |
Comparison of attention mechanisms indicating the trade-off between memory footprint and modeling quality 15162832.
Modern deployments have overwhelmingly adopted GQA as the default architecture. For example, Mistral 7B utilizes 32 query heads but only 8 KV heads, resulting in a 4x reduction in cache size while outperforming equivalent MHA models (like early Llama versions) across major benchmarks 133343522. Similarly, the Llama 3 architecture family natively relies on GQA, establishing it as the standard equilibrium point for high-throughput enterprise serving 713.
Low-Rank Representation and Multi-Head Latent Attention
Despite the efficiency of GQA, the scale of models exceeding 100 billion parameters (and supporting hundreds of thousands of context tokens) necessitates compression far beyond an 8x reduction. The DeepSeek series (V2 and V3) introduced a paradigm shift in cache economics with Multi-Head Latent Attention (MLA), a mechanism that abandons explicit Key/Value storage in favor of low-rank matrix decomposition 23383924.
The Compress-then-Decompress Mechanism
In standard attention variants, the hidden state of each token is passed through large weight matrices to explicitly compute the Key and Value vectors, which are then written to the VRAM cache 384125.
MLA replaces this process by projecting the input hidden state into a highly compressed, low-dimensional "latent" vector (denoted as $c_t$). In DeepSeek-V3, while the total hidden dimension across heads is massive, the latent vector size ($d_c$) is aggressively reduced to just 512 dimensions 253843. During the autoregressive generation phase, only this condensed latent vector is appended to the KV cache 232544.
When the model needs to compute attention scores against historical tokens, the inference engine fetches the tiny latent vector from the cache and utilizes separate, learned up-projection matrices ($W^{UK}$ and $W^{UV}$) to dynamically reconstruct the full-dimensional Key and Value representations on the fly 38254445.
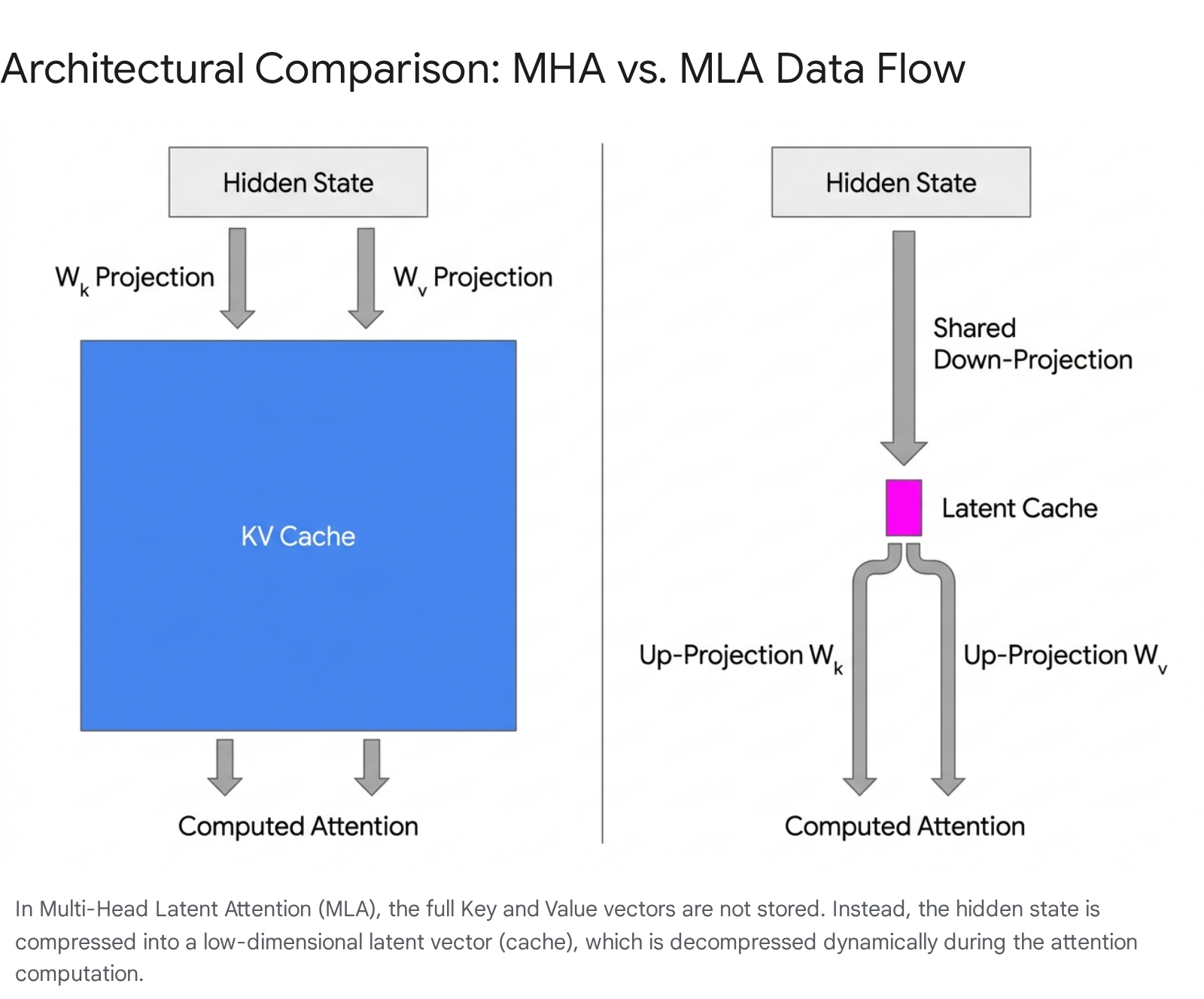
To optimize computation, the system leverages an "absorption trick" where the decompression matrices can be mathematically folded into the standard query and output matrices, minimizing the FLOP overhead of the reconstruction step 384346.
Decoupled Rotary Positional Embeddings (RoPE)
A significant architectural hurdle to latent compression is its incompatibility with standard positional encoding mechanisms. Modern transformers utilize Rotary Positional Embeddings (RoPE) to inject relative positional information into the query and key vectors prior to the dot product 252326. Low-rank compression destroys this precise geometrical relationship 3845.
To solve this, MLA implements a "Decoupled RoPE" strategy. Instead of injecting positional data into the compressed content vector, the architecture extracts a separate, dedicated RoPE sub-vector ($d_R$) 383945. The final cached representation for a single token consists of the compressed latent content vector ($d_c = 512$) concatenated with the decoupled RoPE vector (e.g., $d_R = 64$) 3848.
The Mathematical Impact of MLA
The efficiency gains of MLA scale geometrically. If DeepSeek-V3 (671B parameters, 128 attention heads) relied on standard MHA, a single token would require caching 32,768 distinct values 412548. Under MLA, the cache stores only $512 + 64 = 576$ values per token 4827.
This equates to an astonishing 98.4% reduction in per-token cache storage relative to MHA 43, or approximately 70 KB per token overall 727. Consequently, the total cache size for a 128,000-token context drops from an untenable 213.5 GB under MHA to a highly manageable 7.6 GB under MLA 25. This innovation allows massive frontier models to be deployed on single nodes, thoroughly decoupling parameter size from memory-bound context limitations 6725.
Token-Wise Sparse Attention and Context Windowing
If architectural reductions (GQA, MLA) attack the KV head count and dimensionality, sparse attention mechanisms attack the sequence length variable (S), explicitly reducing the number of historical tokens that the current query token must attend to.
Sliding Windows and Static Sparsity
Early iterations of sparsity relied on hard truncation. Mistral 7B introduced Sliding Window Attention (SWA), which restricts each query token to attend only to a fixed subset of the most recent preceding tokens (e.g., a window size of $W = 4096$) 33343528. The inference engine maintains a rolling buffer cache of size $W$, continuously overwriting the oldest keys and values as generation proceeds 333551.
While SWA fundamentally caps the maximum memory footprint, changing the computational cost from $O(N^2)$ to $O(N \cdot W)$ 28, it induces a severe representational penalty. Older contextual information is entirely purged from the explicit memory state 3429. While stacked transformer layers allow information to theoretically propagate upward through the network, SWA struggles on complex, long-range retrieval tasks (such as "needle-in-a-haystack" benchmarks) where verbatim recall of distant prompt information is required 73453.
Dynamic Token-Wise Sparsity (DSA)
To resolve the blind spots of SWA, next-generation models implement dynamic, token-wise sparsity. DeepSeek-V3.2 and V4 utilize a framework termed DeepSeek Sparse Attention (DSA) 483055. Rather than relying on rigid positional windows, DSA maintains the full compressed KV cache in memory but dynamically selects which subset of tokens to activate for the heavy attention calculation 2953.
The mechanism relies on a "lightning indexer," a highly optimized, low-overhead function that calculates a rough semantic relevance score between the current query and all previous tokens by performing a cheap dot-product in the compressed latent space 485556. Based on these scores, a Top-K selector identifies a specific budget of the most relevant tokens (e.g., 2,048 tokens) 4855. The full, expensive mathematical attention reconstruction is performed exclusively on this sparse subset 5355.
By decoupling memory storage from computational participation, DSA reduces the compute cost per token by up to 73% compared to dense attention models at extreme contexts, while preserving the ability to retrieve explicit facts from the beginning of a one-million token prompt 3056.
Data Precision and Hardware-Native Quantization
Optimization of the final variable in the KV cache equation - P (Precision) - is achieved through quantization. Historically, KV caches were maintained in standard 16-bit floating-point formats (FP16 or BF16) to prevent numerical underflow and preserve gradient integrity 11157. Quantization schemes forcefully compress these numerical representations into lower bit-widths.
Integer and Floating-Point Trade-offs
Compressing the cache from 16-bit to 8-bit formats - either 8-bit integer (INT8) or 8-bit floating point (FP8) - halves the memory footprint immediately 21157. The Open Compute Project defines two primary FP8 formats: E5M2 (5 exponent bits, providing larger dynamic range) and E4M3 (4 exponent bits, providing higher precision for values clustered near zero) 2.
Extensive benchmarking indicates that 8-bit quantization is largely a "free" optimization. Converting the KV cache to FP8 or INT8 doubles concurrent serving capacity with less than a 1% drop in overall model accuracy on standard academic benchmarks (such as MMLU) 575831. Because the decode phase is memory-bound, the reduction in required memory bandwidth directly translates to proportional increases in token throughput, often speeding up generation by 1.5x to 2.0x 115831.
Pushing the envelope to 4-bit quantization (INT4 or experimental FP4/MXFP4) quarters the baseline memory footprint 211. However, this extreme compression introduces highly non-linear accuracy degradation. The loss of precision compounds over long sequences, leading to notable failures in tasks requiring rigid syntax, such as zero-shot coding (HumanEval) or multi-step mathematical reasoning 25758. Benchmarks for INT4 KV caches record performance drops exceeding 8 percentage points on structured code generation tasks, making 4-bit storage highly application-sensitive 5758.
The Necessity of Fused Attention Kernels
The practical viability of quantization is entirely dependent on backend hardware support and fused kernel execution. If an inference engine compresses the cache into 4-bit integers for storage, but must dynamically dequantize those values back into 16-bit precision in standard memory to perform the attention matrix multiplication, the computational overhead becomes catastrophic 231.
Frameworks like TurboQuant, which pack 3-bit and 4-bit structures but lack fully native execution paths, suffer throughput reductions ranging from 40% to 52% compared to non-quantized baselines 31. Conversely, optimized implementations leverage specialized hardware. NVIDIA's NVFP4 specification utilizes block-based microscaling - where a single 8-bit scaling factor is shared across blocks of 32 4-bit elements - allowing the Tensor Cores on Blackwell architectures to execute native math on the compressed structures 232. When perfectly fused, 4-bit quantization can yield a 2.7x speedup with negligible TTFT penalties 5832. Presently, however, FP8 remains the safest, most widely supported default for enterprise inference, maximizing throughput without risking the semantic collapse of the model's reasoning capabilities 75731.
Alternative Paradigms: Eliminating the Cache via State Space Models
The most radical solution to the KV cache bottleneck is the abandonment of the self-attention mechanism entirely. A new class of architectures, led by State Space Models (SSMs) and specifically the Mamba architecture, propose replacing the quadratic $O(T^2)$ scaling of transformers with linear time $O(T)$ processing 3334.
Mamba utilizes a Selective State Space mechanism governed by continuous-time differential equations 3463. Instead of maintaining a discrete, infinitely growing cache of every historical token, Mamba operates much like a sophisticated recurrent neural network, maintaining a single, fixed-size internal hidden state 3463. As each new token is ingested, the model utilizes input-dependent parameters to dynamically select which semantic features to absorb into the persistent state and which extraneous data to overwrite and discard 3463.
Because the hidden state vector does not grow as the sequence lengthens, Mamba's memory footprint during generation is strictly $O(1)$ 3463. This total elimination of the KV cache allows Mamba models to achieve up to 5x higher inference throughput than comparably sized transformers on long-context tasks, while scaling to million-token contexts without triggering out-of-memory errors on standard hardware 3334.
The Compression versus Retrieval Trade-off
While SSMs solve the memory economics of inference, they introduce a severe representational trade-off. Transformers excel at complex reasoning because the KV cache provides an uncorrupted, explicit database of everything the model has seen; it performs lossless retrieval 6364.
Mamba, conversely, forces all historical context through a highly compressed bottleneck. Empirical evaluations demonstrate that while SSMs rival transformers on standard language modeling perplexity, they fail severely on in-context learning (ICL) tasks, sparse parity learning, and zero-shot retrieval where the model must extract exact, non-standard information buried deep within a massive prompt 336435. Because the selective mechanism inherently compresses data, explicit facts can be overwritten and lost.
To capture the economic benefits of SSMs while preserving the reasoning capabilities of transformers, research is rapidly pivoting toward hybrid architectures. Frameworks such as MambaFormer or IBM's Granite variants weave efficient state-space layers for tracking broad temporal dynamics with intermittent, localized attention layers for exact retrieval 633566. These hybrid models promise to maintain strict bounds on KV cache memory without sacrificing the emergent cognitive properties that define modern LLMs.
Conclusion
The Key-Value cache represents the ultimate arbiter of large language model deployment economics. As the industry pushes toward multi-agent systems and unbound context windows, inference is firmly established as a memory-bound, rather than compute-bound, discipline. The evolution of mitigation strategies - from the operating system-inspired paging of vLLM, to the architectural brilliance of Grouped-Query and Latent Attention, down to hardware-native 8-bit quantization - demonstrates that scaling intelligence is fundamentally an exercise in memory management.
Looking forward, the economic viability of frontier AI will rely entirely on compound optimizations. Future inference stacks will inevitably feature hybrid SSM-Attention architectures, utilizing multi-head latent compression stored in heavily quantized FP8 precision, distributed seamlessly across heterogeneous hardware nodes via dynamic block-paged allocators.