Engineering and Science of Long-Context Language Models
The expansion of context windows in large language models has fundamentally altered the trajectory of artificial intelligence research and deployment. Early transformer architectures were computationally bound by context windows of 2,048 to 4,096 tokens, limiting their utility to processing single documents or brief conversational exchanges 123. As the demand for complex agentic systems, comprehensive codebase analysis, and multi-document reasoning intensified throughout 2024 and 2025, research shifted toward achieving contexts of 128,000 to over 1,000,000 tokens 125.
This massive scale introduces severe computational and memory constraints. The fundamental mechanism of the standard transformer - self-attention - scales quadratically with sequence length in compute operations, while the intermediate state required for autoregressive generation grows linearly in memory 67. Achieving reliable 1,000,000-token context windows is not the result of a single algorithmic breakthrough, but rather a convergence of innovations across mathematical attention approximations, hardware-aware systems engineering, position encoding extrapolation, and synthetic data curricula.
Key-Value Cache Memory Dynamics
The primary hardware and mathematical bottleneck in serving long-context language models is the Key-Value (KV) cache. During autoregressive decoding, a transformer must attend to all previous tokens in the sequence to generate the next token 83. Recomputing the keys and values for the entire historical sequence at every step is computationally prohibitive. Instead, models cache these vectors in the high-bandwidth memory (HBM) of the accelerator. As the sequence length grows, the memory required to store this cache eventually dwarfs the memory required to store the static model weights 13.
Mathematical Scaling of the Cache
The absolute size of the KV cache is dictated by the model's structural dimensions, the sequence length, and the active batch size. The foundational formula for calculating the memory footprint of the KV cache in bytes for a single sequence is determined by multiplying the number of layers, the number of key-value attention heads, the dimension of each head, the sequence length in tokens, and the byte size of the floating-point precision 11. An initial factor of two is applied to account for the simultaneous storage of both the Key matrix and the Value matrix 11.
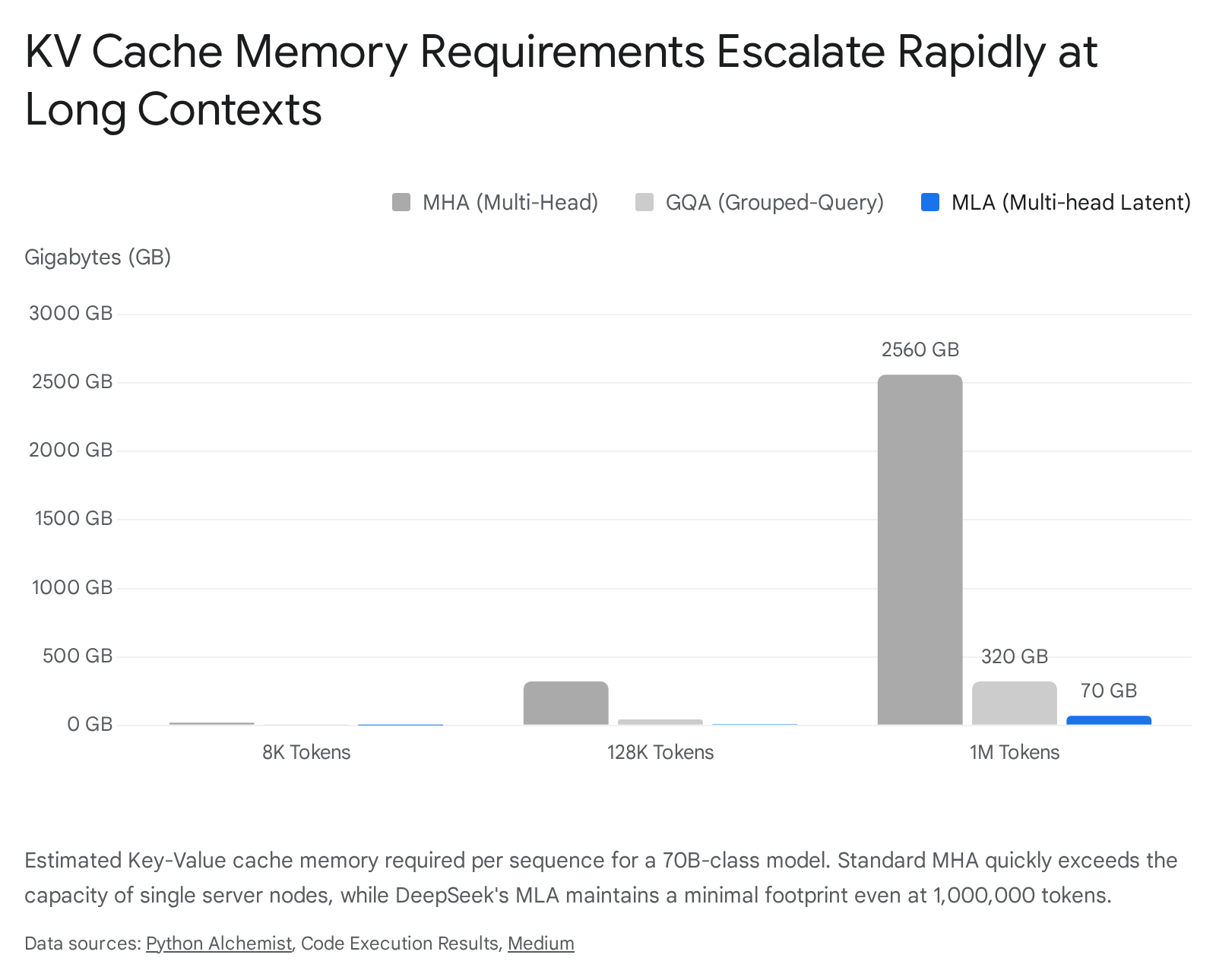
To illustrate the severity of this constraint, one can evaluate the Llama 3.1 70B model operating at a context length of 131,072 tokens. The model features 80 layers, 8 KV heads, and a head dimension of 128. Using 16-bit precision (2 bytes), the KV cache for a single sequence requires approximately 42.9 gigabytes of memory 1. This cache size is larger than the parameter weights of many smaller foundation models and consumes more than half the VRAM of a standard 80GB NVIDIA H100 GPU 14.
If scaled to a 1,048,576-token context, the KV cache for that single Llama 3.1 70B sequence inflates to approximately 320 gigabytes, requiring tensor parallelism across at least four 80GB GPUs solely to hold the cache, before accounting for the 140 gigabytes needed for the FP16 model weights 3.
For the larger Llama 3.1 405B model, a 128,000-token context demands approximately 66 gigabytes of KV cache per sequence, and a 1,000,000-token context demands over 500 gigabytes 313.
The Memory Bandwidth Wall
The KV cache issue extends significantly beyond sheer capacity limits; it creates a severe memory bandwidth bottleneck that restricts inference speed. During the decoding phase, where tokens are generated sequentially, the arithmetic intensity of the workload is extremely low 34. For every single token generated, the inference engine must read the entire historical KV cache from HBM into the compute cores (SRAM) to perform the attention matrix multiplication against the new query 314.
Because modern GPUs process arithmetic floating-point operations exponentially faster than they can transfer data across the memory bus, the decoding phase becomes strictly memory bandwidth-bound. A single user query traversing a 128,000-token context in a 70B model forces the system to transfer over 40 gigabytes of data across the GPU memory bus for every subsequent output token generated 14. At a standard memory bandwidth of approximately 3.3 terabytes per second on flagship hardware, generating merely 10 tokens per second for this sequence consumes the entire theoretical bandwidth of the chip, rendering standard attention architectures economically unviable at the 1,000,000-token scale 345.
| Attention Architecture | Key-Value Cache Size per Token | Total Cache at 128K Context | Compression Ratio vs MHA |
|---|---|---|---|
| Multi-Head Attention (MHA) | ~2.6 MB | ~332.8 GB | 1x (Baseline) 3 |
| Grouped-Query Attention (GQA) | ~328 KB | ~41.9 GB | 8x 3 |
| Multi-head Latent Attention (MLA) | ~70 KB | ~8.9 GB | 37x 3 |
| Multi-Query Attention (MQA) | ~41 KB | ~5.2 GB | 64x 3 |
Structural Attention Compression Mechanisms
To circumvent the KV cache capacity and bandwidth bottlenecks, architectural research has continuously optimized how attention matrices are structured and stored in memory. The evolution from Multi-Head Attention to Multi-head Latent Attention charts the industry's progression toward supporting massive context windows.
Grouped-Query and Multi-Query Interpolation
Standard Multi-Head Attention provisions unique Key and Value heads for every Query head, yielding high expressive quality but maximizing memory consumption 1617. Multi-Query Attention (MQA) represented the first severe compression technique, collapsing all Key and Value computations into a single shared head across all Queries 16. While MQA drastically reduced the cache footprint, it caused measurable degradation in generation quality and training stability as model capacity scaled, often struggling to route complex logic across varied semantic spaces 161718.
Grouped-Query Attention (GQA) emerged as the dominant compromise architecture, utilized heavily by models such as Llama 3.1, Qwen 2.5, and Mistral 116. GQA interpolates between MHA and MQA by clustering Query heads into discrete groups, with each group sharing a single Key and Value head 1617. A standard GQA ratio of 8:1 reduces the KV cache size by a factor of 8 compared to MHA, mitigating the memory bandwidth bottleneck while preserving the vast majority of the model's reasoning capabilities 118. However, at 1,000,000 tokens, even GQA fails to keep the cache within practical bounds. A 70B model using GQA still requires hundreds of gigabytes per sequence at the upper limits of the context window 3.
Multi-head Latent Attention
To push beyond the mathematical limits of GQA, the DeepSeek research team introduced Multi-head Latent Attention (MLA) in their V2 and V3 models 2166. Rather than reducing the number of stored keys and values by sharing heads, MLA fundamentally alters the data structure of what is stored. It utilizes low-rank joint compression to condense the Key and Value matrices into a unified, low-dimensional latent vector 161778.
In the MLA paradigm, the massive, full-resolution Key and Value tensors are never materialized in the KV cache. During the forward pass, the architecture projects the inputs down into a much smaller latent dimension, frequently configured to 512 dimensions 1169. At inference time, only these highly compressed latent representations are stored in HBM. When a specific attention computation is required during autoregressive decoding, the system reads the tiny latent vector into SRAM and applies an up-projection matrix to reconstruct the necessary full-dimensional Key and Value representations on-the-fly 7923.
This architectural pivot transitions the bottleneck from memory bandwidth to raw arithmetic compute. Reconstructing the keys and values requires additional matrix multiplications, actively increasing the total Floating Point Operations (FLOPs) per step 910. Because modern AI accelerators possess immense computational surpluses relative to their memory bandwidth, this trade-off is highly advantageous 29. Furthermore, MLA maintains positional integrity by decoupling the Rotary Position Embeddings (RoPE). Because RoPE relies on shift-invariant rotational matrices that are incompatible with low-rank linear compression, MLA maintains a separate, minimal cache explicitly for rotational keys alongside the latent vector 79.
The empirical results of MLA enable frontier performance at minimal deployment costs. DeepSeek-V3, a 671-billion parameter Mixture-of-Experts model, consumes approximately 70 kilobytes of KV cache per token - a 37x compression over equivalent MHA models 317. At a 128,000-token context, the KV cache footprint is reduced to roughly 9 gigabytes, enabling ultra-large models to process long contexts on limited accelerator hardware 38.
Sparse Attention and Indexing Constraints
Beyond compressing the cache data structure, models have introduced mechanisms to prevent computing attention over every historical token. Standard dense attention requires operations that scale quadratically; if the input sequence doubles, the computational cost quadruples 65.
To break this quadratic scaling, architectures incorporate sparse attention mechanisms, effectively pruning the context space. DeepSeek-V3.2 introduced DeepSeek Sparse Attention (DSA), which utilizes a two-stage routing approach driven by a lightning indexer 51112. Operating in highly efficient FP8 precision, the indexer rapidly scans the entire context to compute approximate relevance scores for all historical tokens relative to the current query 511. A fine-grained selection mechanism then retrieves only the top fraction of the most relevant key-value entries 511. By restricting the dense attention calculation to a fixed number of retrieved tokens, DSA reduces the asymptotic complexity of the attention mechanism, linearizing the compute cost as the context scales toward 1,000,000 tokens without degrading performance on complex retrieval tasks 51112.
Linear and Recurrent Architectures
While latent and sparse attention mechanisms optimize the traditional transformer, alternative architectures seek to discard the standard attention mechanism entirely in favor of recurrent algorithms that natively scale linearly with sequence length.
Kimi Delta Attention and Hybrid Architectures
In late 2025, Moonshot AI published technical documentation on Kimi Linear, a hybrid architecture combining Multi-Head Latent Attention with a novel mechanism termed Kimi Delta Attention (KDA) 271329. Pure linear attention models historically suffer from degraded in-context learning and exact retrieval capabilities compared to full quadratic attention 2914. Kimi Linear addresses this by interleaving different attention paradigms.
KDA refines the delta rule of linear attention by incorporating a highly granular, channel-wise gating mechanism 131415. Previous hardware-efficient linear models relied on coarse, head-wise or scalar forget gates, where an entire memory state for a specific attention head decays uniformly 1416. This uniform decay often results in either excessive memory retention or catastrophic forgetting of vital context 14. KDA resolves this by assigning an independent forgetting rate to each individual feature dimension using a specialized variant of Diagonal-Plus-Low-Rank transition matrices, enhancing the utilization of hardware tensor cores 131416.
By interleaving three layers of KDA for every one layer of MLA, the Kimi Linear architecture delegates strict local context modeling to the linear layers and global retrieval to the full attention layers 291415. Additionally, Kimi Linear removes positional encoding from the MLA layers entirely, routing all positional awareness through the recurrent KDA mechanism 2914. This hybrid structure reduces KV cache usage by an additional 75% relative to pure MLA and achieves up to a six-fold increase in decoding throughput at the 1,000,000-token boundary 271316. Validation testing demonstrates that deploying this architecture provides a 1.25x efficiency advantage over equivalent models, requiring 20% less training computation to achieve matching downstream performance 1633.
State Space Models: Mamba and RWKV
State Space Models (SSMs) treat sequence processing as a continuous-time signal problem, compressing historical context into a fixed-size hidden state. Because the state size remains constant, SSMs require stable, constant memory during autoregressive inference and scale in linear time, inherently solving the infinite-context dilemma 717.
The Mamba architecture advanced SSMs by introducing a selective scan mechanism. Unlike early state space models which applied static convolutional kernels, Mamba's parameters are data-dependent; the model dynamically decides whether to update its internal state or ignore the current input token based on its semantic relevance 717. This selective filtering allows the network to disregard noise in massive documents, retaining only critical information 17. Mamba has proven effective as the foundation for specialized reasoning models. Researchers have successfully distilled transformer-based reasoning models into Mamba variants using reinforcement learning frameworks, matching transformer-level mathematical reasoning while delivering generation speedups of over 2.5x 35.
Similarly, the Receptance Weighted Key Value (RWKV) architecture operates as a linear-time recurrent neural network during inference but relies on parallel computation during training, mimicking a transformer 717. RWKV models utilize linear time-mixing and channel-mixing functions to avoid the quadratic attention matrix entirely 17. Recent implementations, including visual and language variants, demonstrate that these recurrent architectures exceed standard transformers in generation throughput at massive context lengths, although they generally require hybridization to match the exact relational recall of full attention models on complex benchmarks 1736.
Positional Encoding Extrapolation
Transformers possess no inherent sense of sequence order; they rely entirely on positional encodings injected into the input embeddings to understand syntax and structure. The industry standard is Rotary Position Embedding (RoPE), which encodes absolute position with a rotation matrix and naturally captures relative token distances 1819.
A critical vulnerability of RoPE emerges when a language model trained on 8,000 tokens is abruptly exposed to 100,000 tokens during inference. During pre-training, the model never observes the high-frequency and low-frequency rotations corresponding to positions beyond its initial training window 1839. Consequently, the attention mechanism encounters out-of-distribution rotational values, causing the model's perplexity to collapse and generating incoherent text when the context exceeds the pre-training limit 1839.
Position Interpolation and NTK-Aware Scaling
Initial attempts to extend context windows relied on Position Interpolation. Instead of forcing the model to extrapolate to unseen positions, Position Interpolation mathematically compresses the incoming long sequence into the short range the model recognizes 1939. This is achieved by multiplying all position indices by a scaling factor representing the ratio of the old context length to the new context length 1939. While effective for minor extensions, severe compression squeezes adjacent tokens too closely together, destroying the model's ability to differentiate fine-grained local relationships 1839.
To resolve this degradation, researchers applied Neural Tangent Kernel (NTK) theory, which demonstrates that neural networks struggle to learn high-frequency information in low-dimensional spaces 39. NTK-aware scaling modifies the rotary base frequency, spreading the interpolation pressure unevenly across the hidden dimensions 1939. By scaling the base according to the sequence length, NTK-aware methods preserve the high-frequency dimensions, which represent critical local token relationships, while aggressively interpolating the low-frequency dimensions that represent broad, long-range macro relationships 1939.
The YaRN Framework
The definitive mathematical solution to RoPE extension is the YaRN (Yet another RoPE extensioN) framework 1839. YaRN segments the hidden dimensions of the RoPE embeddings into three distinct groups based on their wavelength: pre-critical high-frequency dimensions, post-critical low-frequency dimensions, and an interpolation transition zone 3920.
YaRN applies a piecewise scaling function across these segments. High-frequency dimensions are left entirely untouched, ensuring local text comprehension remains flawless 1819. Furthermore, YaRN addresses the attention entropy problem. In massive contexts, the attention softmax distribution becomes overly diluted across hundreds of thousands of tokens, causing the model to lose focus and hallucinate 1839. YaRN introduces a temperature scaling parameter directly into the attention formulation, which re-sharpens the attention scores across vast distances 1839. Using YaRN, models can be extended from short contexts to 128,000 tokens or beyond with only a few hundred fine-tuning steps, ensuring accurate retrieval without catastrophic forgetting 1839. Alternative models, such as Baichuan 2, bypass RoPE entirely, achieving 192,000-token contexts using Attention with Linear Biases (ALiBi) dynamic position coding 2142.
Systems Engineering and Sequence Parallelism
While architecture dictates the theoretical mathematical limits of long-context modeling, distributed systems engineering makes it physically executable. Processing 1,000,000 tokens in a single batch requires immense VRAM that exceeds the capacity of any single GPU. This necessitates Sequence Parallelism, a technique that shards a single continuous input sequence across a massive array of interconnected accelerators 4344. Standard Tensor Parallelism splits the model weights across GPUs but duplicates the sequence activations across all devices, offering no memory relief for massive context lengths 343.
Ring Attention and DeepSpeed Ulysses
Ring Attention solves the sequence memory bottleneck by partitioning the input sequence into discrete chunks distributed across a cluster of GPUs arranged in a logical ring topology 434522. During the self-attention calculation, each GPU processes its local chunk of the Query sequence. The Key and Value blocks are then passed peer-to-peer around the ring. As long as the computation of a block takes longer than the network transfer of the next block, the communication latency is entirely masked by the computation 4522. This zero-overhead overlapping allows the context length to scale linearly with the number of GPUs added to the ring, enabling theoretically near-infinite contexts provided the interconnect bandwidth is sufficient 2247.
DeepSpeed Ulysses takes a different topological approach utilizing all-to-all sequence sharding. Instead of passing sequence blocks in a sequential ring, Ulysses shards the input sequences and utilizes highly optimized collective communication protocols to distribute the attention heads themselves across GPUs 4323. Each GPU calculates the full sequence length for a specific subset of the attention heads. A key advantage of this approach is that its communication cost is inversely proportional to the sequence parallelism degree, making it highly efficient within tightly coupled nodes 4323.
| Sequence Parallelism Strategy | Communication Topology | Architectural Strengths | Primary Limitations |
|---|---|---|---|
| Ring Attention | Peer-to-Peer Ring (Sequential) | Scales context length linearly with device count; hides communication latency behind compute operations. 452224 | Highly sensitive to hardware interconnect bandwidth; a slow network link halts the entire ring process. 22 |
| DeepSpeed Ulysses | All-to-All (Collective) | Extremely fast for models with high head-counts; highly efficient within a single high-speed NVLink domain. 4323 | Less efficient across slow cross-node links due to massive all-to-all scatter/gather requirements. 43 |
| Blockwise Parallel Transformer | Hierarchical Block Fusion | Fuses Attention and Feed-Forward Network logic to bypass activation memory limits; dramatically reduces overhead. 2526 | Requires precise mathematical tuning of block sizes; complex integration with existing standard frameworks. 25 |
Blockwise Parallel Transformer Mechanics
The Blockwise Parallel Transformer (BPT) extends memory optimization beyond the attention layer directly into the Feed-Forward Network. Standard sequence processing materializes massive activation tensors in the FFN layer, often reaching sizes of 8 times the batch size, sequence length, and hidden dimension 222627. BPT computes both self-attention and the subsequent FFN operations in a fused, block-by-block manner 2227.
By preventing the full materialization of the entire attention matrix and interleaving the FFN processing while the data is still resident in SRAM, BPT reduces memory demands drastically 2627. Implementations utilizing these blockwise fusions report training on sequences 16 to 64 times longer than vanilla frameworks on equivalent hardware, sustaining high Model Flops Utilization (MFU) even when processing 2,000,000 tokens 252627.
Training Methodologies and Synthetic Data
Expanding the theoretical capacity of the context window is only half the engineering challenge; a model must be explicitly taught how to reason accurately across millions of tokens. The primary barrier to training is the scarcity of high-quality, organic long-context data. While the internet contains endless short-form content, structurally coherent documents containing complex, cross-referenced logic at the 500,000 to 1,000,000 token scale are exceedingly rare 2854.
Synthetic Data Generation and Co-Evolution
To train frontier models, AI laboratories rely heavily on synthetic data generation pipelines 2855. Frameworks such as WildLong synthesize realistic long-context instruction data by utilizing larger teacher models to extract meta-information from vast corpora and construct multi-document reasoning tasks 56. These pipelines generate complex multi-turn simulated conversations, document-grounded task constructions, and verifiable instruction-response pairs 2856. By dynamically controlling the difficulty progression and stylistic variation, synthetic data prevents models from overfitting to the limited styles of organic books or massive codebase dumps 285657.
Furthermore, advanced synthetic curricula employ a self-instruct co-evolutionary loop. A model generates variations of a complex reasoning prompt, evaluates its own answers, and filters out low-quality context chunks using LLM-as-a-judge protocols 5458. This self-improvement loop effectively bootstraps reasoning capabilities without human annotation, solving the data bottleneck required to train models on extreme inputs 5459.
Curriculum Learning and Multi-Token Prediction
Training a model on 1,000,000 tokens from initialization is computationally wasteful and mathematically unstable. Instead, laboratories employ curriculum learning techniques. Models are first pre-trained on standard sequence lengths of 4,000 to 8,000 tokens. Once base language modeling converges, the sequence length is incrementally stepped up during a specialized continued pre-training phase, adjusting the positional encodings at each step 1157.
To maximize the efficiency of this computationally expensive training phase, architectures like DeepSeek-V3 incorporate Multi-Token Prediction. Instead of predicting a single next token, the model utilizes specialized auxiliary heads to predict multiple future tokens simultaneously 27. This objective packs denser gradient signals into every training step, significantly improving data efficiency. It forces the model to plan its reasoning further into the long-context future, aligning internal representations before the auxiliary prediction modules are discarded prior to inference deployment 7.
Evaluation Frameworks and Benchmark Realities
As context windows expanded, the industry standard evaluation - the Needle In A Haystack test - became insufficient for measuring intelligence. This test evaluates whether a model can retrieve a specific fact randomly inserted into a massive body of text 5660. While foundational, models rapidly achieved near-perfect retrieval accuracy up to 1,000,000 tokens, rendering the benchmark obsolete for distinguishing advanced reasoning 55661.
RAG Latency Overheads
When native long-context models are unavailable, systems often rely on Retrieval-Augmented Generation (RAG). RAG utilizes external embedding databases to fetch relevant text chunks to insert into a short context window 6162. However, systems engineering research indicates that RAG pipelines introduce severe latency overheads, accounting for over 45% of Time-To-First-Token (TTFT) latency due to the encoding and retrieval processes 362. Native long-context models bypass this latency, though they incur massive KV cache constraints. Novel approaches like InfiniRetri attempt to bridge this gap by leveraging the LLM's internal attention distribution to execute precise retrieval directly over infinite-length tokens without relying on external embedding models 61.
The RULER Benchmark and Frontier Performance
To rigorously assess 1,000,000-token capabilities, researchers rely on the RULER benchmark. RULER evaluates models using multi-needle aggregation, complex reasoning across disparate context blocks, and cross-document comparison 29. Performance on RULER tasks plummets significantly compared to simple retrieval, exposing the reality that synthesizing logic from data spread across a million tokens remains a volatile challenge 6029.
In the current landscape, closed-source models and highly optimized open-source architectures contest the frontier. Google's Gemini 1.5 Pro reliably supports context windows ranging from 1,000,000 to 2,000,000 tokens, excelling in multi-modal retrieval and maintaining dominance in high-volume, long-context aggregation tasks 560. However, open-weight models have rapidly closed the gap. Qwen 2.5 72B and DeepSeek-V3 exhibit exceptional long-context reasoning, outperforming older models on educational and professional benchmarks at a fraction of the computational training cost 3065. Similarly, Moonshot's Kimi Linear achieves Pareto-optimal speed and performance on the 128,000-token RULER boundary, operating dramatically faster than traditional attention mechanisms 1631.
| Long-Context AI Model | Advertised Context Window | RULER (128K) Score | Long-Context Architecture / Technique | Primary Deployment Strategy |
|---|---|---|---|---|
| Gemini 1.5 Pro | 1,000,000 to 2,000,000 | 94.4% | Sparse MoE, Proprietary Attention | Closed API, High-volume processing 2967 |
| DeepSeek-V3 | 128,000 (API extends to 1M) | Near-frontier | MoE, MLA (Latent Attention), MTP | Open-weight, Cost-efficient inference 1230 |
| Kimi Linear (48B) | 1,000,000 | 84.3% | Hybrid Linear, KDA (Channel-wise gate) | Agentic workflows, High throughput 1631 |
| Qwen 2.5 (14B) | 1,000,000 | 92.2% | RoPE Extrapolation, Advanced GQA | Open-weight, Complex coding tasks 29 |
| Llama 3.1 (70B) | 128,000 | 66.6% | Grouped-Query Attention (GQA) | General purpose, Broad ecosystem 29 |
*Note: RULER scores reflect weighted averages of multi-task performance measured at the 128,000-token context boundary. Specific frontier models exhibit rapid degradation past this point depending on task complexity 2965.
Conclusion
The realization of 1,000,000-token context windows in language modeling represents a triumph of cross-disciplinary engineering and applied mathematics. The fundamental quadratic limitations of the traditional transformer architecture have been systematically dismantled. Key-Value cache memory walls are being scaled through Multi-head Latent Attention and Hybrid Linear architectures, compressing the gigabytes of required memory into manageable footprints. Recurrent algorithms offer glimpses into a highly efficient post-attention future, while sequence parallelism techniques distribute massive computational burdens across interconnected hardware topologies. Coupled with synthetic data curriculum learning and mathematically scaled positional encodings, these innovations have transformed large language models from short-form text generators into encyclopedic reasoning engines.