AI Scaling through Hardware and Training Budgets
Evolution of Training Compute Scaling Laws
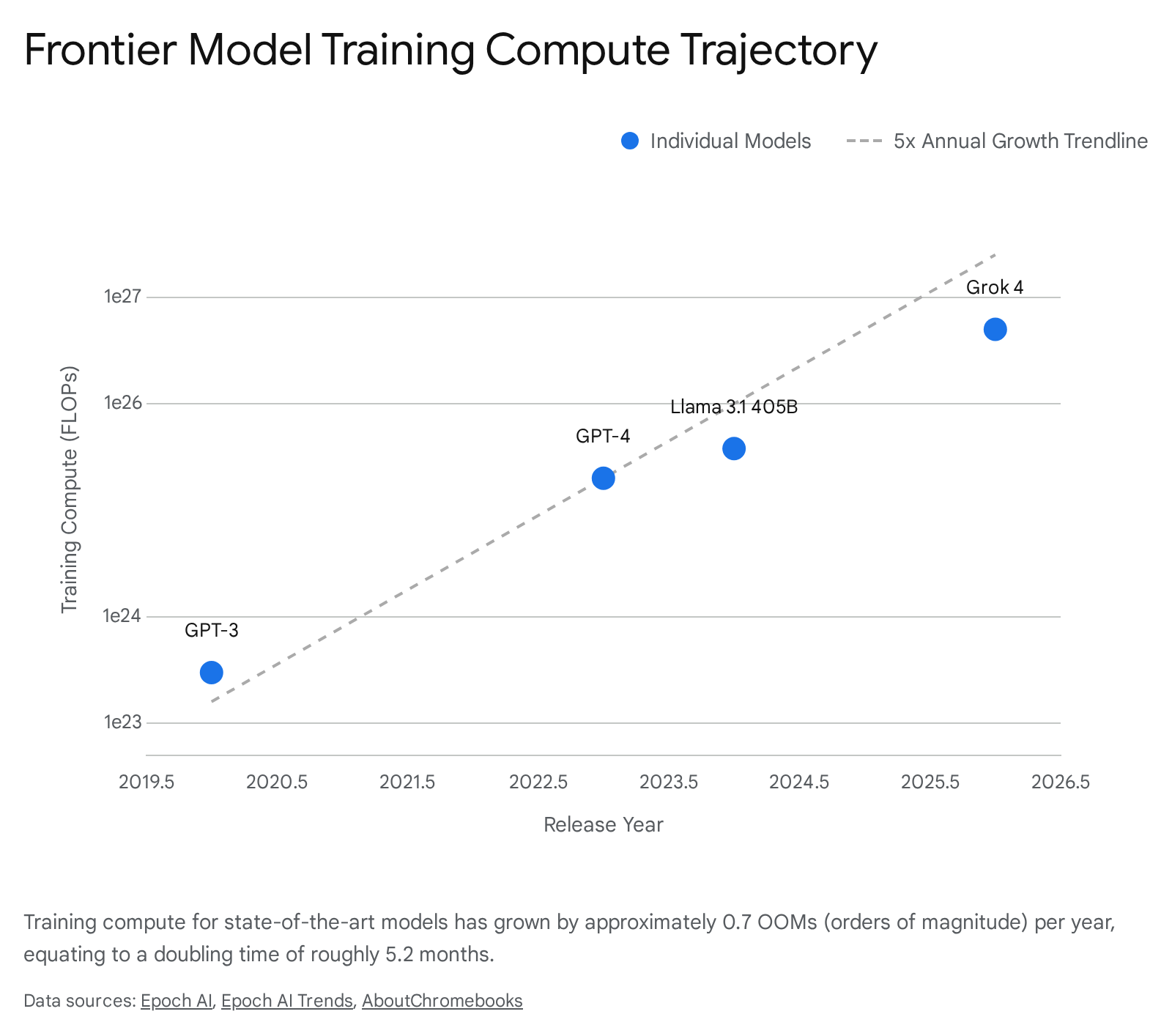
The foundational mechanism driving artificial intelligence capabilities over the past decade has been the exponential scaling of computational resources applied during model pretraining. Empirical observations of this phenomenon have formalized into neural scaling laws, which quantitatively define the relationship between training compute budgets, dataset sizes, model parameters, and resulting validation loss. Since 2020, the amount of compute used to train frontier language models has grown by a factor of 5 annually, doubling approximately every 5.2 months and exhibiting a steady growth rate of 0.7 orders of magnitude (OOMs) per year 12.
Early Power Laws and Parameter Optimization
The initial formalization of neural scaling laws by Kaplan et al. (2020) at OpenAI established that language modeling performance improves smoothly and predictably as a power-law relationship with compute, data, and model size 34. Under the Kaplan framework, experiments suggested that given a fixed increase in a compute budget, the optimal allocation heavily favored increasing model parameter count over dataset size. Specifically, the Kaplan scaling coefficients indicated that optimal parameter count scaled as $N \propto C^{0.73}$, while optimal token count scaled as $D \propto C^{0.27}$ 3.
This paradigm incentivized the rapid development of massive, highly parameterized architectures. The immediate result was models like GPT-3, which utilized 175 billion parameters but was trained on a comparatively small dataset of approximately 300 billion tokens, establishing a parameter-to-token ratio of roughly 1:1.7 5. The assumption was that raw parameter scale was the primary driver of capability, leading to a race for trillion-parameter dense models prior to 2022.
The Chinchilla Correction and Data Balancing
In 2022, Hoffmann et al. at DeepMind published the "Chinchilla" scaling laws, fundamentally challenging the parameter-heavy consensus. The Chinchilla research demonstrated that previous frontier models, including GPT-3, were significantly undertrained. The revised scaling laws indicated that model parameters and training tokens should be scaled in equal proportions ($N \propto C^{0.50}$, $D \propto C^{0.50}$) 3. Under Chinchilla-optimal conditions, a model of 175 billion parameters would require approximately 3.5 trillion training tokens, effectively increasing the necessary data volume by a factor of 11 5.
Subsequent studies reconciling the Kaplan and Chinchilla findings revealed that the 2020 discrepancy stemmed primarily from methodological artifacts. Kaplan et al. calculated scaling coefficients based on non-embedding parameters rather than total parameters and extrapolated from comparatively small-scale models (under 1.5 billion parameters) 36. Furthermore, the original Kaplan models lacked an offset term accounting for the irreducible entropy inherent in natural language 6. Correcting for these factors aligns the two studies, cementing the requirement for massive, high-quality datasets to fully exploit expanding compute budgets 66. More recent research in 2024 from Llama 3 and Epoch AI suggests even higher optimal data ratios, pushing token-to-parameter ratios as high as 1,875:1 for highly optimized deployment models 5.
Empirical Trends in Frontier Training Runs
The current trajectory of frontier model development reflects an aggressive execution of data-parameter balancing, driving training compute costs into the hundreds of millions of dollars. The total computing power of the stock of AI chips is growing at a rate of 3.4x per year, while algorithms become more efficient - requiring roughly 3 times less compute to achieve identical performance year-over-year 12. However, the absolute scale of compute deployed has vastly outpaced these efficiency gains.
| Model Entity | Estimated Training Compute (FLOPs) | Estimated Compute Cost (USD) | Hardware Infrastructure |
|---|---|---|---|
| GPT-4 (OpenAI) | ~2e25 | ~$78,000,000 | ~10,000 A100 / H100 GPUs |
| Gemini Ultra (Google) | ~5e25 | ~$191,000,000 | Google TPU v4 / v5e |
| Llama 3.1 405B (Meta) | ~3.8e25 | ~$170,000,000 | 16,000 H100 GPUs |
| Grok 3 / Grok 4 (xAI) | ~5e26 | >$100,000,000 | >100,000 H100 GPUs |
| DeepSeek V3 (DeepSeek) | ~2.7e25 | ~$5,600,000 | 2,048 H800 GPUs |
Note: Compute cost estimates are derived from public disclosures, Epoch AI databases, and estimated cloud-equivalent hardware depreciation rates as of early 2026. Figures are subject to internal lab cost variability 278.
The Shift to Inference-Time Compute Scaling
While pretraining scale continues to define base knowledge and syntactic fluency, the period between 2024 and 2026 marked a structural paradigm shift toward "test-time" or inference compute scaling. As gains from simply expanding parameter counts and datasets began to exhibit localized diminishing returns, researchers discovered that allocating additional compute during inference - allowing a model to deliberate before generating an output - yields log-linear performance improvements on complex reasoning tasks 9111213.
System 2 Thinking and Search Mechanisms
Models such as OpenAI's o1 and DeepSeek's R1 rely on reinforcement learning (RL) to develop latent reasoning strategies, effectively decoupling knowledge retrieval from logic-based problem solving 141510. Instead of executing a single forward pass (analogous to Kahneman's "System 1" intuitive thinking), these "System 2" aligned models generate extended reasoning traces, evaluate intermediate states, and backtrack from logical dead ends 11131417.
Several algorithmic approaches currently underpin test-time scaling: 1. Self-Consistency and Majority Vote: This method involves generating multiple independent chain-of-thought samples for a single prompt and aggregating the answers to determine a consensus. While highly parallelizable and simple to implement, this method encounters a hard upper bound dictated by the base model's single-sample capability threshold; if a model fundamentally lacks the semantic capacity to generate a correct step, no amount of resampling will yield the correct final state 141011. 2. Tournament and League Routing: These are multi-stage algorithms where multiple candidate solutions are generated and pitted against each other. A verifier model, or the reasoning model itself acting as a discriminator, evaluates candidates in a knockout tournament format. Theoretical proofs indicate that if a model can generate a correct solution with non-zero probability and compare pairs accurately, the failure probability decays exponentially or by a power law as test-time compute grows 122013. 3. Monte Carlo Tree Search (MCTS): Treating reasoning as a directed search tree, MCTS represents the most computationally aggressive approach. The model generates intermediate thoughts as nodes and executes four phases: selection, expansion, simulation, and backpropagation. By using past rollout results to focus compute on promising lines of thought rather than wasting equal compute on flawed branches, the tree structure allows later steps to override earlier weak choices 1315.
Mathematical Formulations and Limits of Test-Time Scaling
Recent empirical studies demonstrate that inference compute scaling follows predictable power-law dynamics, effectively unifying with pretraining scaling laws through the lens of conditional Kolmogorov complexity 22. Research indicates that a proportional increase in inference-time compute can reliably substitute for orders of magnitude of pretraining compute. For example, a 15x increase in inference-time compute can equate to a 10x increase in train-time compute, allowing a heavily deliberating small model to outperform a base model 14 times larger restricted to zero-shot inference 23.
However, test-time scaling is subject to severe diminishing returns. Analyses of reasoning models indicate that the highest marginal utility occurs within the first several hundred to thousand reasoning tokens. Generating tens of thousands of tokens per query continues to improve accuracy, but the computational cost scales exponentially relative to the linear gains in benchmark performance 1711.
To mitigate these bottlenecks, researchers have developed dynamic resource allocation frameworks such as SCALE (Selective Resource Allocation). SCALE operates by assessing sub-problem difficulty and selectively routing simple queries to standard single-pass inference, while reserving deep tree-search algorithms for computationally challenging scientific or mathematical operations. This approach reduces overall computational costs by up to 53% while achieving accuracy improvements of nearly 14 percentage points on advanced mathematics benchmarks compared to uniform scaling baselines 1714.
Hardware Architectures and the Memory Wall
The bifurcation of AI development into massive pretraining clusters and computationally intensive inference deployments has placed unprecedented strain on semiconductor architectures. The primary constraint governing modern AI performance is no longer strictly raw floating-point operations per second (FLOPs), but rather memory bandwidth and interconnect topologies 251516.
The Roofline Model and HBM3e Constraints
Inference workloads, particularly autoregressive token generation and the maintenance of the Key-Value (KV) cache for large context windows, frequently suffer from low arithmetic intensity. According to the Roofline model of compute performance, when the ratio of operations per byte of memory traffic falls below a chip's hardware balance point, the system becomes memory-bandwidth-bound rather than compute-bound 2516.
High Bandwidth Memory (HBM3e) has consequently emerged as the critical technological chokepoint in the AI supply chain. During autoregressive decoding, each generated token requires the model to sequentially load weights from DRAM into the compute units. While a single NVIDIA B200 GPU can deliver an extraordinary 9,000 TFLOPS of FP4 dense compute, it is fundamentally restricted by its 8.0 TB/s memory bandwidth when serving large-batch inference requests 17. Even with advanced quantization techniques, the sheer volume of data movement throttles the compute pipeline.
The root cause is the KV-cache access pattern inherent to attention mechanisms. At inference time, each generated token must retrieve key and value vectors for all previous tokens, creating memory accesses that grow linearly with sequence length and are highly irregular in memory address space 25. This compute-to-bandwidth mismatch has driven manufacturers toward structural responses such as Processing-in-Memory (PIM) - moving computation directly into the HBM stack to eliminate the data-movement bottleneck at its source - and expanding on-chip SRAM capacities 251618. As the industry moves toward HBM4 in 2026, architectures will utilize 2048-bit interfaces across 32 channels to push per-stack bandwidth beyond 2.0 TB/s 19.
Interconnect Topologies: All-Reduce versus All-to-All
As models scale well beyond the physical memory capacity of a single accelerator, distributed computing strategies become mandatory. The network fabric binding these chips dictates the ultimate efficiency of the cluster. The choice of parallelism strategy directly informs the required network topology:
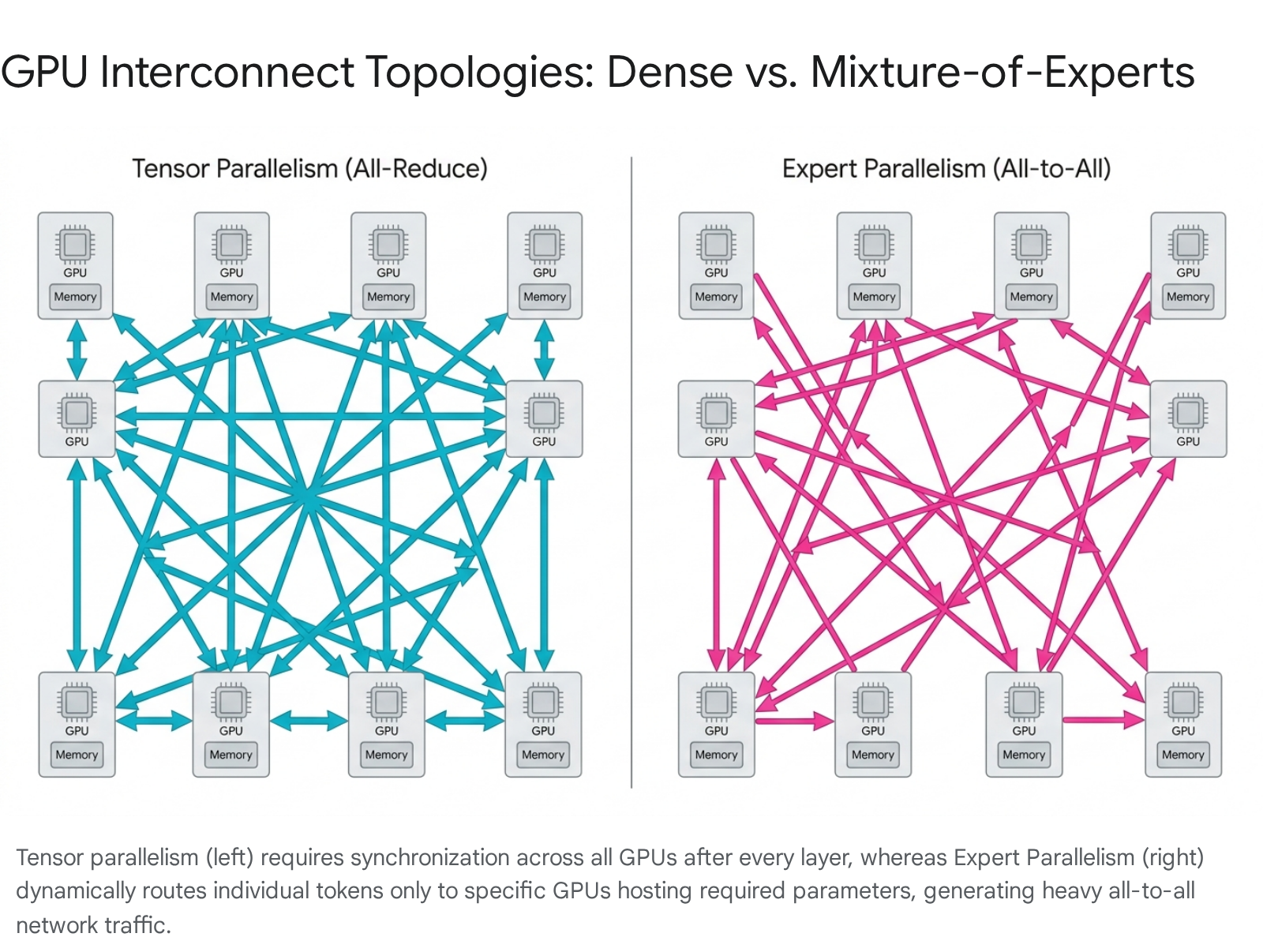
- Tensor Parallelism (TP): This strategy shards individual weight matrices across multiple GPUs. While TP allows for maximum interactivity and low latency at small batch sizes, it requires a synchronous "all-reduce" communication step after every single layer (column-parallel and row-parallel GEMMs). TP provides high throughput but suffers severe performance penalties if forced across slow inter-node networks, making intra-node bandwidth critical 312033.
- Expert Parallelism (EP): Exclusively utilized in Mixture-of-Experts (MoE) architectures, EP shards individual experts across the cluster to exploit sparsity. EP avoids layer-by-layer all-reduce operations but necessitates a complex "all-to-all" communication protocol where tokens are routed dynamically to specific GPUs housing the required experts. As MoE models scale to hundreds of experts, all-to-all communication volume scales linearly with the number of participating chips 312033.
- Data Parallelism (DP): The simplest form of scaling, DP replicates the entire model across groups of GPUs and load-balances requests. While it requires simple all-reduce gradient synchronization during training, it is highly inefficient for inference memory usage at the frontier scale 3133.
The distinction between these communication protocols defines hardware procurement. For instance, NVIDIA's GB200 NVL72 architecture addresses MoE bottlenecks by connecting 72 GPUs within a single rack via fifth-generation NVLink, establishing a 130 TB/s all-to-all bandwidth domain 2135. This allows massive MoE models (such as the 671-billion parameter DeepSeek R1) to perform expert routing entirely within the high-speed NVLink fabric, bypassing standard 400 Gbps (50 GB/s) InfiniBand networking bottlenecks which are approximately 2,600 times slower 3135.
Comparative Assessment of Accelerator Silicon
The datacenter hardware market is currently defined by a sharp division between highly flexible, general-purpose GPUs and highly optimized Custom Silicon (ASICs) developed vertically by hyperscalers.
| Accelerator Platform | Peak Compute (Selected Precision) | Memory & Bandwidth | Interconnect Protocol | Primary Deployment Strategy |
|---|---|---|---|---|
| NVIDIA B200 (Blackwell) | 9,000 TFLOPS (FP4) / 4,500 (FP8) | 192 GB HBM3e @ 8.0 TB/s | NVLink 5 (1.8 TB/s per chip) | Unconstrained MoE training & generalized inference 17. |
| NVIDIA H100 (Hopper) | 1,979 TFLOPS (FP8) | 80 GB HBM3 @ 3.35 TB/s | NVLink 4 (900 GB/s per chip) | Legacy dense model training and fine-tuning 1722. |
| Google TPU v5p / Trillium | 4,614 TFLOPS (FP8) | ~192 GB HBM3e | Optical Circuit Switches (OCS) | Internal Google workloads; massive synchronous clusters 373823. |
| AWS Trainium 3 | 2.52 PFLOPS (FP8) | 144 GB HBM3e @ 4.9 TB/s | Elastic Fabric Adapter (EFA) | Cost-optimized managed cloud training on AWS 2038. |
| Groq LPU | 750 TOPS (INT8) | ~230 MB SRAM @ 80 TB/s | Real-time proprietary interconnect | Ultra-low latency, batch-1 LLM inference 3824. |
| Intel Gaudi 3 | 1,835 TFLOPS (BF16) | 128 GB HBM2e @ 3.67 TB/s | Standard Ethernet Integration | Budget training (Discontinued post-2026) 38. |
NVIDIA Blackwell Microarchitecture
The NVIDIA Datacenter Blackwell GPU (SM100) represents a profound microarchitectural shift optimized explicitly for post-training and inference efficiency. The B200 utilizes a dual-die configuration comprising 208 billion transistors, unified by the NVIDIA High-Bandwidth Interface (NV-HBI) to present a coherent 192 GB memory space to software 4142.
A critical divergence from the Hopper generation is the shift in thread scheduling. Blackwell replaces warp-synchronous MMA operations with tcgen05.mma, a single-thread instruction that removes warp-level synchronization, enabling true per-thread scheduling for tensor operations 4143. Additionally, the introduction of the Tensor Memory (TMEM) subsystem provides a dedicated on-chip memory pathway for tensor data movement, reducing reliance on shared memory (SMEM) during matrix-intensive operations 4143. Combined with native FP4 acceleration via fifth-generation Tensor Cores, the B200 delivers a 15x improvement in performance over Hopper for specific inference workloads 1721.
Hyperscaler ASICs and the Margin Gap
While NVIDIA dominates raw performance and ecosystem maturity via CUDA, hyperscalers (Google, Amazon, Meta) are aggressively deploying custom silicon to bypass NVIDIA's profit margins. Analysis of normalized hardware economics reveals a massive pricing disparity: NVIDIA charges an estimated $21,163 per H100-equivalent unit of compute, whereas Google pays approximately $6,919 for a TPU v5p, and Amazon pays roughly $5,041 for a Trainium 2 unit 44.
Because hyperscalers pay manufacturing costs rather than market prices, their custom ASICs effectively receive a 50-70% discount compared to procuring NVIDIA hardware 2444. While TPUs and Trainium chips may lack the "hero specs" of peak TFLOPS seen in the B200, they are engineered for system-level yield, utilizing custom liquid cooling and optical fabrics to maximize sustained throughput and total cost of ownership (TCO) across internal fleet deployments of 50,000+ chips 372324.
Hyperscale Capital Expenditure and Return on Investment
The intersection of compute scaling laws and hardware procurement realities has triggered the largest industrial mobilization since the post-war era. The Big Five hyperscalers are projected to allocate $602 billion in capital expenditures in 2026 alone, a 36% year-over-year increase, with roughly 75% directed exclusively toward AI infrastructure 45.
Trajectory Toward the Trillion-Dollar Cluster
Forward-looking projections extrapolate current power-law scaling to compute clusters of unprecedented physical and financial scale. If training compute continues its established 3x to 5x annual growth trajectory, the capital required for individual training clusters will escalate dramatically. Projections indicate that the industry is on a path toward $100 billion individual training clusters by 2028 (requiring approximately 10 gigawatts of power capacity). By 2030, strict adherence to the scaling paradigm points toward a $1 trillion cluster 46252649.
The physical realities of these clusters dictate a profound shift in energy and industrial policy. A theoretical 100-gigawatt training cluster would consume the equivalent of more than 20% of current United States electricity production 252649. Consequently, infrastructure planning has pivoted from mere silicon procurement to securing long-term baseload power. This is evidenced by initiatives such as Amazon's acquisition of a data center campus directly adjacent to a nuclear power plant, and the Stargate Initiative spearheaded by OpenAI and Microsoft 454626. To circumvent localized grid density limits, researchers are also validating the feasibility of decentralized training across wide-area networks, demonstrating that a 10 GW training run distributed across multiple sites spanning thousands of kilometers is theoretically viable without catastrophic latency degradation 27.
Capital Expenditure and the 2026 Productivity Clock
The sustainability of this infrastructure buildout remains a subject of intense macroeconomic debate. While total AI capital investments are projected to exceed $1 trillion annually by 2027, the return on investment (ROI) relies entirely on the assumption that reasoning models will generate sufficient economic value via automated software engineering, scientific R&D, and widespread enterprise productivity gains 252649.
Market analysts project 2026 as a critical checkpoint for the AI industry's "productivity clock." The core question is whether the diffusion of generative AI will manifest in measurable macroeconomic productivity growth beyond the preliminary 1.3% improvements estimated by some central banks 28. If applications fail to deeply penetrate enterprise workflows and generate commensurate software revenue, the 94% cash-flow-to-capex ratios maintained by the hyperscalers will likely trigger severe capital market tightening 4528.
Furthermore, the introduction of highly efficient architectures like DeepSeek has introduced systemic risk to the "compute-is-king" thesis. By achieving state-of-the-art reasoning capabilities for approximately $5.6 million in compute on restricted hardware, such models demonstrate that algorithmic brilliance and open-source diffusion can temporarily subvert brute-force capital scaling 745. If the marginal value of massive compute scaling degrades due to architectural workarounds, the valuation models underpinning the current hardware super-cycle may face significant downward pressure 745.
Geopolitical Fragmentation and Export Controls
The foundational nature of AI compute has elevated silicon infrastructure from a commercial commodity to a matter of acute national security. The United States has aggressively deployed export controls under a "small yard, high fence" doctrine to restrict adversarial access to frontier hardware, accelerating the fragmentation of the global technological ecosystem 2930.
Efficacy of Silicon Blockades and Total Processing Performance
Since October 2022, the U.S. Bureau of Industry and Security (BIS) has utilized Total Processing Performance (TPP) metrics and interconnect bandwidth limits to block the export of advanced accelerators to Tier 3 nations, primarily targeting the People's Republic of China 3155. The geopolitical strategy operates under the assumption that restricting leading-edge hardware will permanently throttle China's ability to train models that rival U.S. defense and commercial capabilities 2932.
The empirical effectiveness of these controls is nuanced. On the raw hardware layer, the blockade has inflicted measurable damage on Chinese domestic production capabilities. Constrained by restricted access to extreme ultraviolet (EUV) lithography and advanced electronic design automation (EDA) software, domestic alternatives lag significantly. Huawei's current flagship, the Ascend 910C, remains generations behind NVIDIA's B200 architecture. Furthermore, Huawei's projected 2026 silicon (the Ascend 950PR) exhibits a lower total processing performance than its current flagship, indicating severe yield or architectural constraints under semiconductor equipment embargoes 2933. Forecasters estimate that by 2027, the performance gap between the best U.S. and Chinese chips will widen to 17x 29.
Adaptation and Algorithmic Circumvention
Despite hardware deficits, China has adapted by pivoting away from brute-force hardware scaling. Labs have optimized memory management, heavily utilized synthetic data pipelines, and innovated in reinforcement learning to train frontier-class models on constrained, older-generation hardware. The DeepSeek R1 model, trained on restricted NVIDIA H800s, utilized custom PTX instructions and FP8 mixed precision accumulation to bypass the interconnect bandwidth limits explicitly targeted by U.S. export controls 73258.
Additionally, Chinese entities continue to exploit the "rental compute" loophole, utilizing cloud instances hosted in Tier 2 nations to access prohibited Blackwell and Hopper infrastructure 59. In late 2025, the U.S. administration modified the regulatory framework, shifting from a strict security blockade to a trade-and-taxation strategy. The new regulations permitted the sale of H200 chips to China - effectively raising the allowable TPP threshold by 13x - subject to strict volume caps (50% of U.S. domestic shipments) and a 25% revenue share 313461. This policy acknowledges that the H200 is rapidly becoming a commodity relative to internal U.S. capabilities, allowing U.S. firms to capture Chinese market capital to fund the next leap in domestic infrastructure 3461.
The Proliferation of Sovereign Artificial Intelligence Ecosystems
As the United States leverages its control over the AI hardware supply chain, allied and non-aligned nations are heavily investing in "Sovereign AI" to prevent long-term reliance on foreign tech giants. These initiatives are driven by mandates over data residency, cultural alignment, public sector security, and basic economic competitiveness 626335.
Regional Infrastructure Mobilizations
The sovereign AI paradigm is shifting the landscape from a centralized model dominated by a handful of Silicon Valley platforms to a distributed, multi-polar network of sovereign computing hubs: * The Middle East: The Gulf states are aggressively transitioning from consumers of AI to exporters of compute capacity. The UAE (via entities like G42 and the MGX investment vehicle) is developing massive infrastructure campuses like Project Stargate, while Saudi Arabia's Public Investment Fund (PIF) has launched the HUMAIN platform to control the full AI stack. These nations are leveraging their competitive energy economics to build gigawatt-scale data centers capable of hosting localized, Arabic-first LLMs 633637. * Europe: Moving beyond the regulatory posture of the AI Act, the European Union has initiated an industrial policy aimed at closing the compute gap. The EuroHPC Joint Undertaking has launched the "AI Factories" program, targeting the construction of three to five gigafactories, each endowed with at least 100,000 state-of-the-art AI chips. These facilities aim to support onshore model training (e.g., Mistral in France) and retain cloud revenues and digital value within the European bloc 623538. * Asia-Pacific: Sovereign wealth funds and governments in Japan, Australia, and Southeast Asia are shifting investments toward localized data centers and on-premise GPU clusters. These environments are tailored for highly regulated sectors such as defense, telecommunications, and healthcare, where maintaining strict onshore data governance is prioritized over the pure economic efficiency of hyperscale public clouds 62633940.
These investments underscore a fundamental reality of the current era: compute has become a primary strategic asset. As inference scaling laws push the demand for intelligent processing into every facet of the digital economy, the physical infrastructure - silicon, energy, and interconnect fabrics - will dictate the geopolitical and economic hierarchy of the coming decades.