Neural Scaling Laws and Artificial Intelligence Progress
Artificial intelligence development over the past decade has been dominated by the paradigm of scale. The foundational hypothesis - that increasing computational power, dataset size, and model parameters leads to predictable improvements in model performance - was formalized into empirical power-law functions. These formulas relate a language model's cross-entropy loss to the resources expended during its training. By charting the predictable decline in loss as resource limits expand, researchers forecast the capabilities of highly resource-intensive models before committing to multibillion-dollar training runs.
The consensus surrounding these mathematical formulas has evolved significantly. The initial framework established by Kaplan et al. heavily favored scaling model parameters over training data. This was subsequently upended by the Chinchilla study, which demonstrated that model size and data volume must be scaled in equal proportion. As the industry adopted the Chinchilla paradigm, a new wave of overtraining emerged. Driven by the economic realities of inference deployment, developers began pushing models far past compute-optimal training limits to minimize operational costs.
Today, the trajectory of artificial intelligence progress approaches an inflection point. The brute-force scaling of pre-training compute is colliding with absolute physical and infrastructural limits, including the exhaustion of high-quality human text, the thermodynamic constraints of high-bandwidth memory, and the capacity limits of the global electrical grid. In response, the field is undergoing a fundamental shift toward architectural sparsity and inference-time scaling - often referred to as System 2 processing or test-time compute - to extract superior performance from existing parameter bounds. This document provides an exhaustive analysis of the mathematical foundations of scaling formulas, the physical bottlenecks constraining them, and the algorithmic and economic shifts redefining the future of artificial intelligence.
Mathematical Foundations of Pretraining Scaling
Scaling formulas are empirical regressions rather than immutable physical axioms; they describe the regime in which they were fitted but can shift under architectural changes, data repetition, or distribution shifts 1. The primary objective of these formulations is to determine the optimal allocation of a fixed compute budget across the number of model parameters and the number of training tokens to minimize the cross-entropy loss.
The core observation underlying all scaling frameworks is that performance improvements follow predictable log-linear trajectories. However, the precise rate of improvement and the optimal allocation of resources have been subjects of intense empirical study and revision.
The Kaplan Scaling Framework
In 2020, researchers published a seminal study establishing that language model performance improves smoothly as a power law with scale 23. The Kaplan framework suggested that when not bottlenecked by other factors, the empirical performance of a model has a power-law relationship with each individual variable: model size, dataset size, and training compute.
The mathematical observation dictated that loss scales as power laws in parameters, data, and compute. The specific exponents derived in the 2020 study were approximately 0.076 for parameters, 0.095 for data, and 0.050 for compute 14. When solving the constrained optimization problem of how to allocate a fixed compute budget - where total compute is approximately equal to six times the product of parameters and tokens - the Kaplan framework concluded that the optimal allocation should strongly favor increasing model size. Specifically, the study predicted that for a compute-optimal model, the number of parameters should scale proportionally to the compute budget raised to the power of 0.73, while the training dataset should scale only to the power of 0.27 45.
This conclusion fundamentally shaped the development of early massive language models, most notably GPT-3. Based on the Kaplan framework, GPT-3 was scaled to 175 billion parameters but trained on a relatively modest 300 billion tokens 67. The prevailing paradigm from 2020 to 2022 operated on the assumption that massive, sparsely trained parameter networks were the most efficient path to superior performance 1.
The Chinchilla Compute Optimal Framework
In 2022, researchers at DeepMind published findings that fundamentally challenged the Kaplan consensus 89. The DeepMind team investigated the optimal model size and number of tokens by training over 400 language models ranging from 70 million to over 16 billion parameters on datasets of 5 to 500 billion tokens 10.
The resulting Chinchilla scaling formula established a different expression for the loss function, separating the irreducible baseline entropy of the natural language dataset from the loss penalties incurred by the model being too small or the dataset being too small 11. The researchers fitted the exponents for the parameter penalty at approximately 0.34 and the data penalty at approximately 0.28 1. Because the two exponents are nearly equal, the Lagrangian optimization of the compute budget yields a radically different conclusion from the Kaplan study: for compute-optimal training, the model size and the number of training tokens should be scaled equally. Both the optimal parameter count and the optimal data count should scale in proportion to the compute budget raised to the power of 0.50 459.
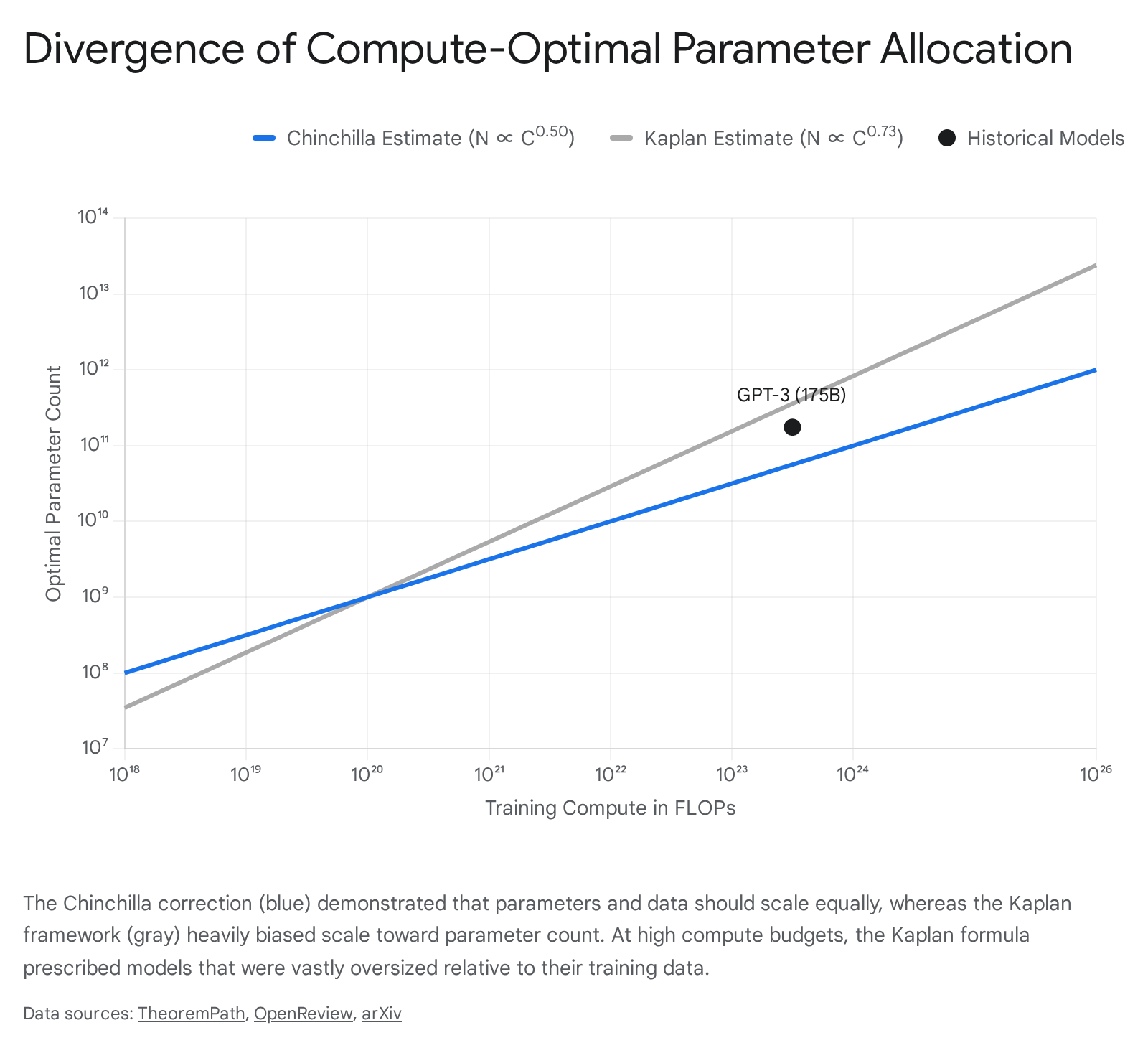
The Chinchilla study proved that contemporary models like GPT-3, Gopher at 280 billion parameters, and Megatron-Turing NLG at 530 billion parameters were significantly undertrained. The compute-optimal ratio was found to be approximately 20 training tokens per model parameter 1611. To validate this, DeepMind trained Chinchilla - a 70 billion parameter model - on 1.4 trillion tokens, utilizing the exact same compute budget as the 280-billion-parameter Gopher model. Despite being a quarter of the size, Chinchilla uniformly and significantly outperformed Gopher, GPT-3, and Jurassic-1 across a vast array of downstream evaluation tasks 7810.
Reconciling Methodological Discrepancies
The discrepancy between the Kaplan and Chinchilla frameworks resulted from methodological differences in the original 2020 study. Recent analytical reconstructions have identified the precise causes of the overestimation of the parameter exponent 4512.
First, the 2020 study calculated its scaling formulas based on the non-embedding parameter count, whereas the 2022 study utilized the total parameter count. In smaller models, embedding parameters make up a highly disproportionate percentage of the total network. Second, the early study restricted its empirical training runs to models up to approximately 1.5 billion parameters, failing to capture dynamics at larger scales. Finally, the researchers used a fixed cosine cycle length and learning rate schedule that did not scale appropriately with the training horizon 112. By not training smaller models to full convergence, the analysis inherently biased the scaling exponents toward larger models.
Simulating the Chinchilla study exclusively on non-embedding parameters within the 1,000 to 1.5 billion parameter regime perfectly reproduces a local power-law scaling coefficient of 0.78, closely matching the original 0.73 finding 4. This analytical reconciliation solidifies the Chinchilla formulation as the definitive representation of compute-optimal pre-training dynamics for dense transformer architectures.
| Scaling Law Framework | Optimal Parameter Scaling | Optimal Data Scaling | Tokens-to-Parameter Ratio | Primary Finding / Consequence |
|---|---|---|---|---|
| Kaplan (2020) | Proportional to $C^{0.73}$ | Proportional to $C^{0.27}$ | Varies (Low) | Strongly favored scaling model size over training data; led to massive, undertrained models like GPT-3 (175B parameters / 300B tokens). |
| Chinchilla (2022) | Proportional to $C^{0.50}$ | Proportional to $C^{0.50}$ | $\approx 20:1$ | Proved parameters and data must scale equally; established that contemporary language models were critically undertrained. |
The Overtraining Paradigm in Language Models
While the Chinchilla scaling formula dictates the compute-optimal allocation for the training phase, it does not optimize for the total lifecycle cost of a deployed model. In commercial environments, the energy and computational cost of an artificial intelligence system is heavily amortized through its usage for inference 89. Consequently, a model trained strictly to Chinchilla-optimal standards may achieve the lowest possible training loss for a given budget, but it will be unnecessarily large and expensive to serve in production.
This economic reality catalyzed the overtraining paradigm, in which researchers intentionally break Chinchilla scaling ratios by pushing the token-to-parameter ratio to extremes 713. By training a smaller model on an exponentially larger dataset, laboratories produce systems that match the capabilities of their massive counterparts but require a fraction of the compute and memory bandwidth to execute user queries.
Inference Efficiency and Data Saturation
The Llama 3 technical report provides explicit documentation of the overtraining strategy. Under optimal assumptions, an 8-billion-parameter model should be trained on approximately 200 billion tokens 1416. However, developers trained the Llama 3 8B and 70B models on 15 trillion tokens - yielding a token-to-parameter ratio of 1875:1 for the 8B model 1315.
The scaling analysis conducted during development yielded a critical finding: model performance continues to improve log-linearly even after the model is trained on two orders of magnitude more data than the compute-optimal baseline 1416. While larger models can match the performance of these smaller overtrained models using less total training compute, the smaller models are massively preferred due to their constrained inference footprint 14. The engineering teams established detailed sub-scaling formulas specifically to predict downstream benchmark accuracy under these extreme data density conditions 16.
Other modern developments reflect similar deviations. The Qwen 2.5 series expanded pre-training datasets from 7 trillion to 18 trillion tokens to maximize capabilities within strict parameter boundaries 1718. Conversely, models like Falcon 180B strictly adhered to the optimal allocations of the 2022 DeepMind study without heavy upsampling or overtraining, utilizing 3.5 trillion tokens to achieve state-of-the-art results for its parameter class 1920.
| Model Architecture | Parameter Count | Training Tokens | Token-to-Parameter Ratio | Strategy Classification |
|---|---|---|---|---|
| GPT-3 (2020) | 175 Billion | 300 Billion | 1.7:1 | Undertrained (Kaplan-era) |
| Chinchilla (2022) | 70 Billion | 1.4 Trillion | 20:1 | Compute-Optimal Baseline |
| Falcon 180B (2023) | 180 Billion | 3.5 Trillion | 19.4:1 | Compute-Optimal Strict |
| Llama 3 8B (2024) | 8 Billion | 15 Trillion | 1875:1 | Extreme Overtraining |
Catastrophic Overtraining Degradation
Despite the benefits of dense data application, empirical studies warn that scaling pre-training tokens indiscriminately is not strictly beneficial. As models are pushed deeper into sub-optimal data-to-parameter ratios, they face the risk of catastrophic overtraining 21.
Research utilizing controlled setups demonstrated that extending pre-training far beyond the optimal token budget can eventually degrade performance on downstream fine-tuning tasks. For example, when pre-training for the OLMo-1B model was extended from 2.3 trillion to 3 trillion tokens, the model suffered a 3% performance drop on the AlpacaEval benchmark and a 2% drop on the ARC benchmark 21. To mitigate this deceleration in sub-scaling regimes, researchers rely on a derived Over-Training Ratio to generalize the scaling formulas and accurately predict the inflection points where additional data ceases to yield capability gains 22.
Emerging Data Memory and Power Constraints
The continuation of performance gains via scaling assumes an infinite supply of raw inputs: data, memory bandwidth, and electrical power. As models reach the trillion-parameter scale and ingest tens of trillions of tokens, the industry is rapidly accelerating toward hard physical and logistical boundaries.
Human Data Exhaustion and Synthetic Alternatives
The most immediate constraint facing pre-training scaling formulas is the finite nature of human-generated text. Training datasets for general-purpose artificial intelligence have recently grown at an annual rate of 2.7x, doubling in size roughly every ten months 2324. Epoch AI updated comprehensive estimates on data exhaustion in 2024, finding that the total effective stock of high-quality, repetition-adjusted, human-generated public text data is approximately 300 trillion tokens, with a 90% confidence interval spanning 100 trillion to 1,000 trillion tokens 25.
If current scaling and overtraining trends continue, language models will fully exhaust this entire global stock of textual data between 2026 and 2032 2526. Epoch AI projects that the total effective stock of high-quality human text will be fully utilized by frontier models within this window, forcing a reliance on synthetic and multimodal data to sustain scaling trajectories. The data trajectory shows an exponential growth curve in dataset demand, originating from roughly 1 billion tokens in 2018 for early models, expanding to 15 trillion for Llama 3 and 18 trillion for Qwen 2.5, and crossing the 300 trillion threshold as models continue to scale 132325.
To bypass the data wall, developers have initiated two primary pivots. First, integrating visual and audio data can significantly expand the training pool. Epoch AI estimates that images and video on the internet represent roughly four quadrillion visual tokens. Factoring this in, the total available multimodal stock expands to between 400 trillion and 20 quadrillion tokens, temporarily delaying exhaustion 2427. Second, laboratories are increasingly utilizing highly capable frontier models to generate synthetic intermediate logic traces, worked examples, and structured logic to serve as training data for subsequent models 2331. However, extensive reliance on synthetic data risks producing degradation loops if not carefully curated using critic models to enforce quality control 1531.
The Memory Wall and Hardware Limitations
While parameter counts scale with compute, the ability to deploy and utilize these models scales strictly with memory bandwidth and capacity. This fundamental divergence has transformed the hardware landscape from a computation-constrained economy to a bytes-per-FLOP economy 32.
The memory wall - a concept originally postulated in 1995 highlighting that processor speeds improve exponentially faster than memory access latency - has become the binding physical constraint for deployment 3228. At massive scales, the challenge shifts from the speed of computation to the energy efficiency of data movement. High-speed serializer and deserializer components and long copper traces consume immense power that does not scale linearly with bandwidth, causing power and heat to concentrate and limit cluster topology 29.
To address this, the industry relies heavily on high-bandwidth memory, which stacks multiple DRAM dies vertically utilizing through-silicon vias to provide thousands of simultaneous data connections 30. The bandwidth evolution has been rapid: the NVIDIA H100 utilized 80 gigabytes of HBM3 delivering 3.35 terabytes per second, while the subsequent Blackwell B200 advanced to 192 gigabytes of HBM3E at 8.0 terabytes per second 2830. The upcoming Rubin architecture targets HBM4, expanding the interface width from 1024 bits to 2048 bits and pushing bandwidth to an estimated 13 to 15 terabytes per second 3036.
Manufacturing these components presents formidable engineering challenges. Scaling memory to the 16-high stacks required for next-generation models requires reducing individual wafer thicknesses from approximately 50 micrometers down to 30 micrometers while maintaining structural and thermal integrity 30. The industry is rapidly approaching the absolute 720 to 775 micrometer package thickness limits allowed by JEDEC standards, forcing research into complex hybrid bump-less bonding techniques to circumvent physical space constraints 3637. Memory bandwidth is particularly critical for generation, where the forward pass is limited by the speed at which model weights can be read from memory arrays.
| Memory Generation | Interface Width | Maximum Bandwidth (Per Stack) | Timeline |
|---|---|---|---|
| HBM2E | 1024 bit | ~460 GB/s | 2018-2020 |
| HBM3 | 1024 bit | ~819 GB/s | 2022-2023 |
| HBM3E | 1024 bit | 1.2 TB/s | 2024-2025 |
| HBM4 | 2048 bit | 1.5 - 2.0 TB/s | 2026 and beyond |
Energy Infrastructure Constraints
The physical footprint of artificial intelligence compute is placing unprecedented strain on the global power grid. As models scale, their energy consumption scales non-linearly. A single complex query leveraging deep analytical processing can demand up to 45 watt-hours, compared to roughly 0.3 watt-hours for a traditional web search 38.
Current projections outline an impending infrastructure crisis. Goldman Sachs forecasts that global power demand from data centers will increase 165% by 2030, rising from a baseline of roughly 55 gigawatts in 2023 to over 84 gigawatts by 2027 3132. Other projections suggest that by 2030, overall data center capacity could hit 225 gigawatts, consuming approximately 945 terawatt-hours of electricity annually 3233.
Expanding transmission capacity is plagued by supply chain bottlenecks, permitting delays, and high infrastructure costs. The International Energy Agency predicts that up to 20% of data center capacity could face grid connection delays between 2025 and 2030 33. To support this growth, an estimated 720 billion dollars in grid infrastructure investments will be required through the end of the decade 3132.
Economic Pressures and Architectural Co Design
The astronomical costs of scaling and the emergence of physical bottlenecks have fundamentally altered the economics of frontier development. While performance continues to scale, it does so at the cost of exponentially diminishing marginal returns.
Flattening Benchmark Gains
Empirical metrics from 2024 to 2026 indicate a visible plateau in the raw capability gains achieved purely through parameter scaling. For example, moving from GPT-3 to GPT-4 required an estimated 55x increase in training compute, pushing the model's accuracy on the Massive Multitask Language Understanding benchmark from roughly 44% to 86% 34. However, subsequent models have struggled to push past the 88% to 90% accuracy ceiling. Derivative analyses of the compute scaling curve demonstrate a severe fall-off in return on investment: each full decade increase in computing power now yields only a 1 to 2 percentage point improvement in broad benchmark accuracy 343544.
This dynamic poses severe financial risks to hyperscalers and enterprises. Global venture capital and corporate investment in infrastructure routinely top hundreds of billions annually, with specific hyperscalers committing upwards of 500 billion dollars to capital expenditure to secure power and hardware 4436. Yet, if base model capabilities require exponential cost for marginal gain, the pricing models for deployment face an unbridgeable gap. Current estimates suggest the industry requires an estimated 600 billion dollars in annual downstream revenue simply to justify the existing infrastructure build-out - a figure highly sensitive to the erosion of margins in enterprise use cases where continuous transaction costs mount quickly 3546.
Mixture of Experts and Hardware Convergence
To maintain the illusion of scaling while adhering to economic and hardware limits, frontier laboratories have broadly adopted the Mixture-of-Experts architecture. These models drastically scale total parameter counts to capture vast knowledge representations while sparsely activating only a small subset of expert parameters for any given token during inference. This effectively decouples model capacity from computational cost.
The DeepSeek-V3 technical report stands as a prime example of breaking traditional scaling constraints via strict architectural co-design. DeepSeek-V3 scaled its expert network to 671 billion total parameters, yet activates only 37 billion parameters per token 4737. This architecture allows the model to be trained on 14.8 trillion tokens in under 2.8 million GPU hours, costing roughly 5.6 million dollars in compute - orders of magnitude cheaper than equivalent dense models 4749. Developers achieved this through hardware convergence, utilizing FP8 mixed precision training, multi-head latent attention to compress key-value caches by over 90%, and the DualPipe algorithm 4737. The DualPipe algorithm maintains a constant computation-to-communication ratio across GPU nodes, thereby masking the severe network bottlenecks usually associated with scaling expert routing algorithms across multi-plane network topologies 373839.
Similarly, Alibaba's Qwen 2.5 series utilizes proprietary expert architectures to match or exceed the performance of massive dense models like Llama 3 405B in complex evaluation tasks, while keeping inference overhead economically viable 3840. Sovereign initiatives, such as Naver's HyperCLOVA X Think in South Korea, also leverage compute-memory-balanced Transformer designs. Parameterized by maximal update parametrization protocols, these models achieve parity in localized linguistics and specialized laws using a fraction of the compute utilized by broader international equivalents, scoring exceptionally well on regional benchmarks like KMMLU and KoBALT-700 41424344.
Test Time Compute and Inference Scaling
Faced with diminishing returns in pre-training and hard physical ceilings on data and power, developers have unlocked a new orthogonal axis for scaling: inference-time computation.
This shift transitions generative systems from rapid, pattern-matching generation to slow, methodical, step-by-step logical processing 4546.
The Mechanics of System 2 Processing
The fundamental premise of test-time compute is that a model's performance on complex, open-ended tasks can be significantly enhanced if it is allowed to expend a non-trivial amount of computational effort before generating a final answer 474861. Instead of increasing parameter counts, researchers increase the number of tokens the model is permitted to generate internally as a scratchpad or intermediate sequence trace.
Research demonstrated that optimizing test-time compute dynamically can yield extraordinary efficiency gains. In specific tasks, a smaller base model armed with extensive test-time compute can outperform a model 14 times its size that operates under standard zero-shot constraints 474862. This changes the economic equation, suggesting that optimizing computational steps at test time rather than scaling model parameters provides superior performance for logic-heavy benchmarks 49.
Sequential and Parallel Scaling Algorithms
Test-time computation operates primarily across two distinct dimensions, each suited for different categories of problem difficulty 5051.
Sequential scaling enhances test-time computation by generating progressively longer solutions along the sequence dimension. The model breaks down problems into sequential steps, generating intermediate traces and utilizing iterative refinement to backtrack upon detecting logical inconsistencies. This methodology is heavily utilized in models like OpenAI's o1 and DeepSeek-R1, which rely on reinforcement learning to teach the model how to construct productive logical paths 464950.
Parallel scaling involves generating multiple responses independently and evaluating them against one another. This is particularly effective for highly complex problems requiring the exploration of various high-level approaches. Methods include standard majority voting, Best-of-N generation, and tree search algorithms. Candidates are often scored and pruned dynamically by process reward models to allocate compute solely to promising pathways 48525354.
Recent theoretical work has established provable inference scaling laws using tournament-style algorithms. For example, researchers developed knockout-style and league-style algorithms where generated candidate solutions compete against one another. Provided the base model possesses a non-zero probability of generating a correct step initially, mathematical proofs demonstrate that the probability of the algorithm failing to arrive at a correct solution decays either exponentially or via a power law as the total number of test-time generation calls increases 51.
However, the efficacy of test-time compute is critically dependent on problem difficulty. For simpler problems, compute-optimal strategies dictate utilizing simple sequential revisions. For mathematically dense logic puzzles, parallel tree-search against dense verifiers is vastly superior. By adaptively allocating the correct type of test-time compute based on estimated prompt difficulty, architectures can achieve greater than a 4x efficiency improvement over naive baselines 474855.
Conclusion
The evolution of neural scaling formulas illustrates an industry consistently pivoting to circumvent the physical and mathematical limits of computation. What began as the Kaplan framework's mandate to build massive, sparsely-trained parameter networks was swiftly corrected by the Chinchilla realization that models were fundamentally starved for data. As the field adapted, extreme overtraining became the standard, trading expensive compute during the training phase for hyper-efficient, highly capable systems during inference.
However, the laws of physics and economics dictate that exponential growth curves cannot run indefinitely. The impending exhaustion of human text, the thermodynamic limits of the electrical grid, and the persistent manufacturing barriers of the memory wall indicate that brute-force pre-training is nearing a hard asymptote. The diminishing returns on benchmark performance relative to the billions invested in power and hardware further underscore the unsustainability of pure scale.
In response, artificial intelligence is transitioning toward its next epoch: System 2 logical processing. By leveraging highly sparse expert architectures to mitigate base costs, and dynamically scaling test-time compute to enable algorithmic search and step-by-step intermediate generation, the frontier of capabilities continues to advance. The future of computational scaling is no longer defined strictly by how many trillions of tokens a model has ingested, but by how efficiently it can route its internal computations, evaluate its own intermediate outputs, and deliberately process its way to a conclusion.