Neural scaling laws in biological and artificial systems
Introduction to Scaling Dynamics
The mathematical relationship between the scale of a computational system and its resulting capabilities represents a fundamental inquiry that spans evolutionary biology, neuroscience, and artificial intelligence. In both biological organisms and artificial neural networks, performance characteristics and structural topologies do not scale linearly. Instead, they exhibit distinct power-law dynamics, phenomena collectively referred to as scaling laws. Within the domain of evolutionary biology, the study of how physiological, anatomical, and cognitive variables change in relation to overall body or brain size is formalized as allometry 123. In the context of machine learning, neural scaling laws describe the predictable mathematical phenomenon where a model's cross-entropy loss decreases as a power-law function of the number of training parameters, the volume of training data, and the applied computational budget 456.
While biological brains and artificial neural networks share superficial mathematical similarities - namely, the ubiquity of power-law relationships to describe their continuous growth trajectories - the underlying physical mechanisms, thermodynamic constraints, and evolutionary outcomes diverge significantly. Biological neural systems are strictly constrained by metabolic energy limits, physical cranium space, and long-term evolutionary fitness landscapes, leading to highly divergent cellular scaling rules across different taxonomic groups, such as the distinct scaling models seen in primates compared to rodents or avians 678. Conversely, modern artificial neural networks are currently bounded by silicon manufacturing capacities, global electricity generation limits, and the finite boundaries of human-generated training data 91012.
This report presents an exhaustive analysis of neural scaling laws, strictly comparing the mathematical rules governing the continuous expansion of biological brains with the empirical power laws dictating the optimization of artificial neural networks. By examining the theoretical foundations of biological allometry, the debate surrounding metric-induced emergent abilities, the extreme divergence in energy efficiency, and the formal mathematical frameworks underlying both substrates, this analysis establishes where the analogies between biological and artificial neural scaling mathematically align, and where their physical realities irreconcilably fracture.
Principles of Biological Allometry
Biological scaling dynamics are formally captured by allometric equations, which model the disproportionate, non-linear growth of biological variables relative to the organism's total mass. The formal study of allometry, originating from the foundational work of researchers such as Julian Huxley and D'Arcy Thompson in the early twentieth century, seeks to identify invariant mathematical properties across organisms of vastly varying sizes, from single-celled organisms to the largest marine mammals 1211.
The canonical allometric equation mathematically takes the form of a power law:
$$Y = Y_0 M^b$$
In this formulation, $Y$ represents a specific biological or physiological characteristic, such as total brain mass, basal metabolic rate, or total life span. $M$ represents the primary measure of body size or body mass, $Y_0$ acts as a normalization constant unique to the taxon or trait being measured, and $b$ represents the crucial allometric scaling exponent 11213. Mathematically, this power-law relationship expresses an underlying scale symmetry across evolutionary adaptations and can be derived as the solution to a proportional differential equation:
$$\frac{dY}{Y} = b \frac{dM}{M}$$
To analyze these complex biological relationships across diverse taxonomic groups, the power-law equation is typically transformed into a logarithmic form. When variables are plotted on a log-log graph, perfectly allometric relationships manifest as predictable straight lines, with the slope of the line corresponding directly to the scaling exponent $b$ 12314.
The most pervasive and historically debated physiological scaling law is Kleiber's Law, initially articulated in 1932, which dictates that the basal metabolic rate of mammals scales to the $3/4$ power of body mass ($b \approx 0.75$) 121112. Historically, biologists debated whether this exponent should mathematically be exactly $2/3$, an assumption derived from simple geometric scaling where surface area mediates heat dissipation relative to body volume. However, extensive empirical datasets encompassing mammalian field metabolic rates, as well as basal rates in vertebrates, invertebrates, and higher plants, consistently yield confidence intervals that explicitly include $3/4$ and exclude $2/3$ 121315.
The $3/4$ scaling exponent is theoretically hypothesized to originate from the physical constraints of fractal resource distribution networks. Cardiovascular and respiratory systems must deliver nutrients across three-dimensional biological tissue efficiently, minimizing the hydrodynamic resistance of blood flow. Mathematical models of these fractal branching networks naturally yield quarter-power scaling rules 111315. Consequently, specific physiological rates that are tightly coupled to metabolism, such as mammalian heart and respiratory rates, scale as $M^{-1/4}$, while biological time spans, such as overall longevity, scale inversely as $M^{1/4}$ 112. Furthermore, evolutionary dynamics dictate that the precise scaling exponent can shift based on population constraints; theoretical physics models suggest that populations subject to bounded growth constraints maximize metabolic rate leading to the $3/4$ exponent, whereas unbounded populations minimize metabolic rate, tending toward a $2/3$ exponent 15.
Cellular Scaling Rules in Biological Brains
When applying the mathematical principles of allometry to cognitive capacity, classical neuroscience historically relied on total brain mass or the encephalization quotient as direct proxies for general intelligence. However, gross brain mass is an inherently flawed metric because the mathematical relationship between physical brain mass and the total number of constituent neurons varies drastically and systematically across different taxonomic orders 6816.
The methodological development of the isotropic fractionator - a technique that safely transforms structurally complex, anisotropic brain tissue into a uniform, isotropic suspension of free cell nuclei - has revolutionized comparative neuroanatomy. By counting neural nuclei in a defined volume of this suspension, researchers can accurately determine absolute cell counts without the sampling biases inherent to traditional stereological slice counting 781718. This methodology has definitively revealed that different species obey entirely different cellular scaling rules as their brains undergo evolutionary expansion.
In rodents and lagomorphs (the glires clade), evolutionary brain scaling follows a highly inefficient, non-linear trajectory. As the rodent brain increases in size, the average physical size of the individual neurons also increases, which proportionally decreases overall neuronal density. Specifically, the mass of the rodent cerebral cortex scales with the number of neurons raised to the power of 1.7 816. Because of this steep allometric exponent, a massive volumetric increase in a rodent brain yields only a marginal, diminishing return in the total neuron count. This mathematically explains why a capybara, despite possessing a significantly larger physical brain than a macaque monkey, harbors a drastically lower total number of cortical neurons 68.
In stark contrast, primate evolution stumbled upon a highly efficient, isometric cellular scaling rule. As primate brains grow larger across evolutionary time, the number of neurons increases in a direct, linear proportion to brain mass 6816. Throughout this expansion, primates maintain a relatively constant neuronal density and average cell size. This distinct, linear scaling law mathematically explains human cognitive dominance; the human brain, which weighs approximately 1.5 kilograms, contains roughly 86 billion neurons 61618. This total count is precisely the number expected for a generic primate brain scaled to human proportions. Humans do not possess a magically unique neurological substrate; rather, we possess an isometrically scaled-up primate brain, benefiting from an evolutionary scaling law that allows for massive neuron accumulation without catastrophic volumetric inflation 61618.
Avian species demonstrate yet another radical departure in biological scaling, optimizing for extreme density. Parrots and songbirds (corvids) pack neurons at densities that considerably exceed those found in any mammalian order. Empirical research utilizing the isotropic fractionator on 28 diverse avian species demonstrated that bird brains contain, on average, twice as many total neurons as primate brains of the exact same physical mass 71920. Because the evolutionary mechanics of flight impose strict aerodynamic weight limitations, avian evolutionary pressures constrained total brain mass while simultaneously selecting for high neuronal packing, particularly within the pallial telencephalon (the avian equivalent of the mammalian cerebral cortex) 71721. Consequently, large-brained birds like the macaw or the common raven possess a total forebrain neuron count comparable to that of a mid-sized macaque monkey, despite possessing an absolute brain size comparable to a walnut 71721.
| Taxonomic Group | Cortical Scaling Rule (Mass to Neurons) | Neuronal Density Trend During Brain Expansion | Cognitive Implications of the Scaling Rule |
|---|---|---|---|
| Rodentia (Rodents) | Non-linear ($Mass \propto Neurons^{1.7}$) | Decreases significantly as cell size inflates | Severe diminishing returns in computing power; larger brains do not guarantee high intelligence. |
| Primates (Apes, Humans) | Linear ($Mass \propto Neurons^{1.0}$) | Remains roughly constant across species | Highly efficient scaling; yields massive absolute neuron counts without prohibitive volume constraints. |
| Aves (Corvids, Parrots) | Dense Hyper-packing | Exceptionally high density maintained | Primate-level cognition achieved with fractional brain mass, satisfying strict evolutionary flight constraints. |
Architectural Innovation and Biological Efficiency
While the quantitative scaling of total neuron counts correlates strongly with general intelligence metrics across species, biological cognitive supremacy is not solely a product of scaling bulk parameters. It is equally driven by profound architectural innovations at the cellular and network levels 62122. Biological brains delegate adaptive control across a multiscale competency architecture, dynamically adjusting synaptic weights, neurogenesis rates, and precise regional specializations in response to environmental pressures 25232425.
One prominent architectural innovation tied to the scaling of advanced intelligence is the emergence of von Economo neurons. Found primarily in layer V of the anterior cingulate and frontoinsular cortices, these exceptionally large, spindle-shaped projection neurons represent a cellular specialization entirely absent in lower mammals. They are uniquely found in great apes, humans, cetaceans, and elephants - species universally characterized by large absolute brain sizes, complex social structures, and mirror self-recognition capabilities 23262728.
Von Economo neurons are morphologically distinct from standard pyramidal cells. They feature a remarkably narrow dendritic field and an unusually thick, fast-conducting axon designed for the rapid relay of macro-level outputs to distant subcortical regions 2628. Researchers hypothesize that these specialized neurons serve as the primary biological infrastructure for rapid social cognition, intuition, and interoception. Their convergent evolutionary presence in whales, elephants, and humans suggests that scaling to high-level, generalized intelligence requires structural topological shifts in the communication backbone of the brain, not merely the brute-force addition of standard, uniform processing nodes 2628.
Furthermore, the architectural complexity extends to the dendritic structures of individual processing units. Human supragranular pyramidal neurons possess significantly larger and more topologically complex dendritic trees than those found in macaques or mice. On average, human pyramidal dendrites are three times larger than those of rodents, featuring longer terminal branches and higher spine densities 27. This morphological complexity allows a single human neuron to perform independent, non-linear computations across its distinct dendritic branches. Consequently, detailed computational models demonstrate that a single complex biological neuron can behave mathematically similarly to an entire multi-layered artificial neural network 27.
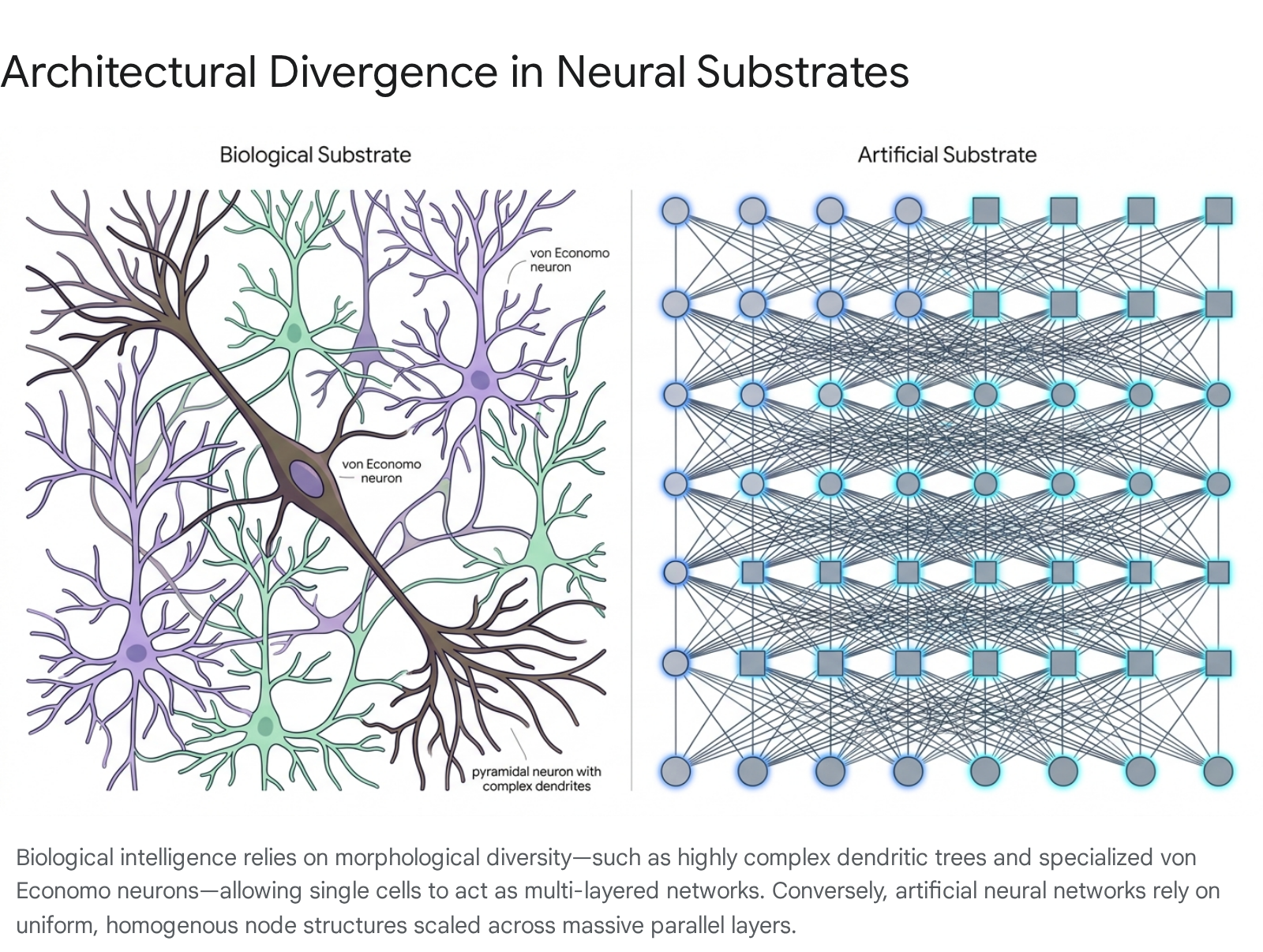
This constitutive advantage means that scaling in biological systems is intimately tied to phase changes in cellular morphology, enabling advanced processing efficiency that escapes purely quantitative scaling laws 2227.
Mathematical Formulations of Artificial Neural Scaling
In the field of artificial intelligence, scaling laws refer to the predictable, mathematical power-law improvements observed in a neural network model's cross-entropy loss. These improvements occur as functions of the number of non-embedding parameters ($N$), the size of the training dataset measured in tokens ($D$), and the total computational budget allocated for training ($C$). Just as biological allometry maps physiological traits to physical mass, artificial scaling laws map predictive performance to informational volume and processing power.
The empirical test loss $L$ of a typical autoregressive language model can generally be approximated by the following mathematical formulation:
$$L(N, D) \approx E + \frac{A}{N^\alpha} + \frac{B}{D^\beta}$$
Within this equation, $E$ represents the irreducible entropy inherent to the data distribution itself - the theoretical floor of the loss function that no model, regardless of size, can surpass. $A$ and $B$ are architectural constants, while $\alpha$ and $\beta$ represent the critical scaling exponents governing model parameters and data scale, respectively 45.
Theoretical frameworks established by researchers analyzing random feature models and teacher-student dynamics attribute these precise, predictable power laws to two distinct mathematical regimes: variance-limited scaling and resolution-limited scaling 5629.
The variance-limited scaling regime dominates when an optimization model lacks access to either an infinite volume of data or infinite internal layer width. Under these constrained conditions, the empirical estimates of the gradient updates routinely deviate from the optimal true gradient. By the statistical law of large numbers, the variance of this gradient estimate scales precisely as $1/D$. Because modern loss functions generally possess a quadratic dependence on these internal parameter deviations, the overall test loss naturally decays as a power law tracking the dataset size 629.
Conversely, the resolution-limited scaling regime relies on the mathematical assumption that the underlying real-world data distribution (such as human language or image pixels) actually resides on a much lower-dimensional smooth manifold of dimension $d$, despite being embedded in an enormously high-dimensional observation space. The artificial neural network effectively constructs a massive, piecewise-linear mathematical approximation of this low-dimensional manifold. As the network scales its parameters and ingests more data, the geometric size of the sub-regions it attempts to resolve continually shrinks. This leads to an approximation error that diminishes smoothly as a power law, theoretically scaling at rates such as $D^{-4/d}$ or $D^{-2/d}$ depending on the chosen loss function 5629.
These formal derivations demonstrate an important insight: the statistical structure of artificial evolutionary scaling is substrate-independent. The predictable improvements in an artificial system's fitness function are determined largely by the inherent topological structure of the data manifold and the mathematical landscape of the optimization space, rather than the specific biological or mechanical mechanism of selection 2930.
The Compute-Optimal Frontier
A pivotal theoretical evolution in the understanding of artificial neural network scaling occurred between the publication of the Kaplan et al. study in 2020 and the Hoffmann et al. study (commonly known as the Chinchilla analysis) in 2022 4313233. Both research initiatives sought to precisely define the compute-optimal scaling frontier: the exact mathematical formula dictating how to best allocate a fixed, multi-million-dollar computational budget ($C$) between scaling model parameters ($N$) and scaling the volume of training data ($D$).
The Kaplan et al. analysis initially concluded that model loss scales disproportionately better by aggressively expanding model parameter size while relatively starving the model of corresponding data. Based on their empirical testing, they estimated that the optimal parameter count should scale according to $N_{opt} \propto C^{0.73}$, whereas data volume should scale only at $D_{opt} \propto C^{0.27}$ 3233. This mathematical assertion dictated the dominant engineering paradigm from 2020 to 2022, prompting organizations to train enormously parameterized systems (such as the original 175-billion parameter GPT-3 architecture) on disproportionately small datasets containing roughly 300 billion tokens 433.
However, the Hoffmann et al. study overturned this entire paradigm with the Chinchilla model, demonstrating conclusively that the Kaplan analysis had systematically overestimated the mathematical value of parameter scaling. The revised Chinchilla scaling laws established that parameters and data must be scaled in roughly equal proportions to achieve compute-optimal loss:
$$N_{opt} \propto C^{0.50} \quad \text{and} \quad D_{opt} \propto C^{0.50}$$
This correction implies a fixed operational ratio: for every single new parameter added to a model architecture, the network must process approximately 20 additional tokens of training data to reach optimal convergence ($D^/N^ \approx 20$) 4.
The severe mathematical discrepancy between the two foundational studies arose because the original Kaplan research suffered from specific, compounding methodological biases. Foremost, the Kaplan team counted only non-embedding parameters in their scaling equations, significantly skewing the curve for smaller models where embedding layers constitute a massive percentage of total parameters. Furthermore, their experimental design fixed a specific learning rate decay schedule that did not appropriately stretch to match the differing training horizons of various model sizes, inherently penalizing longer training runs on larger datasets. Finally, their scaling exponent extrapolations relied heavily on smaller, under-converged models. When independent researchers mathematically corrected these methodological artifacts and expressed the equations using total parameter counts, the original Kaplan data points aligned smoothly with the $0.50$ Chinchilla coefficients 4313233.
The Phenomenon of Emergent Abilities
As industrial artificial neural networks scaled linearly in absolute parameter count following these established laws, researchers observed what widely appeared to be "emergent abilities." These were defined as specific cognitive or mathematical capabilities - such as performing three-digit arithmetic, completing advanced logic puzzles, or translating complex languages - that were entirely absent in smaller iterations of models but appeared abruptly, sharply, and unpredictably in larger models upon crossing unseen computational thresholds 34383536. The sharp, discontinuous transitions in task performance fueled widespread industry hypotheses that artificial neural networks undergo sudden cognitive phase transitions akin to a biological awakening or punctuated leaps in understanding.
However, recent rigorous statistical analyses, most notably the 2023 research by Schaeffer, Miranda, and Koyejo, demonstrate that these purported emergent abilities are largely a statistical mirage. The illusion of sudden cognitive emergence is fundamentally caused by the human researcher's choice of evaluation metric, rather than an underlying architectural phase transition in the model's fundamental behavior 3438353637.
The sudden phase transitions overwhelmingly occur in the literature when researchers utilize strict, discontinuous, non-linear metrics to judge performance, such as "exact string match" or "multiple-choice grade" 3437. These binary metrics award absolutely no partial credit for intermediate cognitive processing. For example, if a model is tasked with generating a 10-character string correctly, and the network's underlying probability of predicting any single correct character improves slowly and linearly with model scale, the probability of generating the entire string perfectly is an exponential function of those individual probabilities. Consequently, the success rate will remain functionally at zero across many orders of magnitude of scale, only to spike violently upwards once the per-character probability crosses a high threshold.
When researchers analyzed the exact same generative outputs from the exact same language models using linear, continuous metrics (such as the Brier score, token-level log-loss, or algorithms that grant partial credit for predicting intermediate integers in an arithmetic equation), the sudden jumps completely vanished. Instead of sharp phase transitions, the models displayed smooth, continuous, and highly predictable improvements perfectly commensurate with standard power-law scaling dynamics 34383536. The underlying acquisition of intelligence in artificial neural networks is therefore gradual and linear relative to the loss function, mathematically contradicting the dramatic narrative of instantaneous, unpredictable technological singularities.
Punctuated Equilibrium in Cognitive Architectures
While parameter-driven capability improvements are mathematically smooth on a continuous loss curve, the broader historical evolution of AI architectures exhibits a macro-level pattern distinctly analogous to the biological evolutionary theory of punctuated equilibrium 38394041. Originally proposed by evolutionary paleontologists Niles Eldredge and Stephen Jay Gould in 1972, punctuated equilibrium postulates that biological species undergo massively extended periods of evolutionary stasis, characterized by minor, gradual adaptations. These long epochs are abruptly interrupted by rapid bursts of speciation driven by catastrophic environmental disruption or the sudden fixation of a radical architectural mutation 38394243.
In the context of artificial neural networks, the classical scaling laws (the premise that simply increasing parameters and data yields better performance) represent the periods of evolutionary stasis. During these phases, the field observes the gradual, continuous accumulation of capability within a fixed architectural paradigm - such as steadily scaling up the parameter count of a standard dense Transformer 38404445. However, absolute physical and structural limits eventually restrict this smooth advancement, forcing sudden system-level reorganizations.
The mechanism of "recursive drift" operates as a form of computational evolution. Small mutations via hyperparameters and ablations act as productive instability, while loss functions act as constructive decay, selecting for optimal patterns 3941. When pure parameter scaling collides with hard constraints, the system experiences a saltative branching event. Architectural innovations such as the shift from dense networks to sparse Mixture-of-Experts (MoE) routing, or the transition from autoregressive prediction to test-time chain-of-thought compute loops, represent these sudden evolutionary leaps 44046.
In this "Institutional Scaling Law" framework, overall institutional fitness is mathematically non-monotonic relative to pure scale. Tightly coupled, domain-specific models trained on targeted schema and coordinated through adaptive routing can rapidly outcompete bloated, generalized frontier models. This dynamic heavily mirrors how explosive biological radiation rapidly fills distinct ecological niches following an environmental disruption, proving that architectural adaptation eventually supersedes brute-force scaling 3045.
The Data Exhaustion Bottleneck
The empirical discovery that compute-optimal artificial neural network scaling requires massive, proportional increases in high-quality training data has exposed a severe physical limit confronting the AI industry: the impending total exhaustion of human-generated text 95152.
Extensive quantitative forecasting by research institutes such as Epoch AI estimates that the total effective global stock of quality, repetition-adjusted, human-generated public text available for training is approximately 300 trillion tokens 952. Given the aggressive, exponential scaling trajectory maintained by frontier AI laboratories, extrapolative models project that this entire stock of human language will be fully utilized at some point between 2026 and 2032, with a high-confidence median estimate pointing directly to the year 2028 952.
This impending data starvation is exacerbated by modern deployment economics. Because state-of-the-art inference models are frequently "overtrained" - intentionally trained on data ratios far exceeding the compute-optimal 20 tokens per parameter to artificially suppress post-deployment inference latency and costs - the rate of global data consumption is accelerating vastly faster than theoretical compute boundaries alone would predict 951.
If empirical scaling laws plateau abruptly due to this data starvation, the artificial intelligence industry will face a severe "constitutive gap" where pure algorithmic parameter scaling strikes an absolute physical ceiling 22514754. Continued progress beyond 2030 will necessitate profound architectural innovations - such as shifting toward heavy reinforcement learning, integrating self-play mechanisms, or developing sophisticated synthetic data generation pipelines that avoid model collapse. Such a transition would fundamentally mirror the architectural leaps seen in biological evolution when ecological limits forced life to develop entirely new metabolic pathways 2225405154.
Thermodynamic Constraints and Energy Efficiency
The most profound and unyielding mathematical divergence between biological scaling algorithms and artificial scaling laws lies within the domain of energy metabolism and thermodynamic efficiency. While theoretical computational scaling models often treat digital FLOPs (floating-point operations) and biological synaptic events as conceptually interchangeable units of information processing, their respective thermodynamic realities dictate entirely different physical constraints 484950.
Biological Synaptic Energy Costs
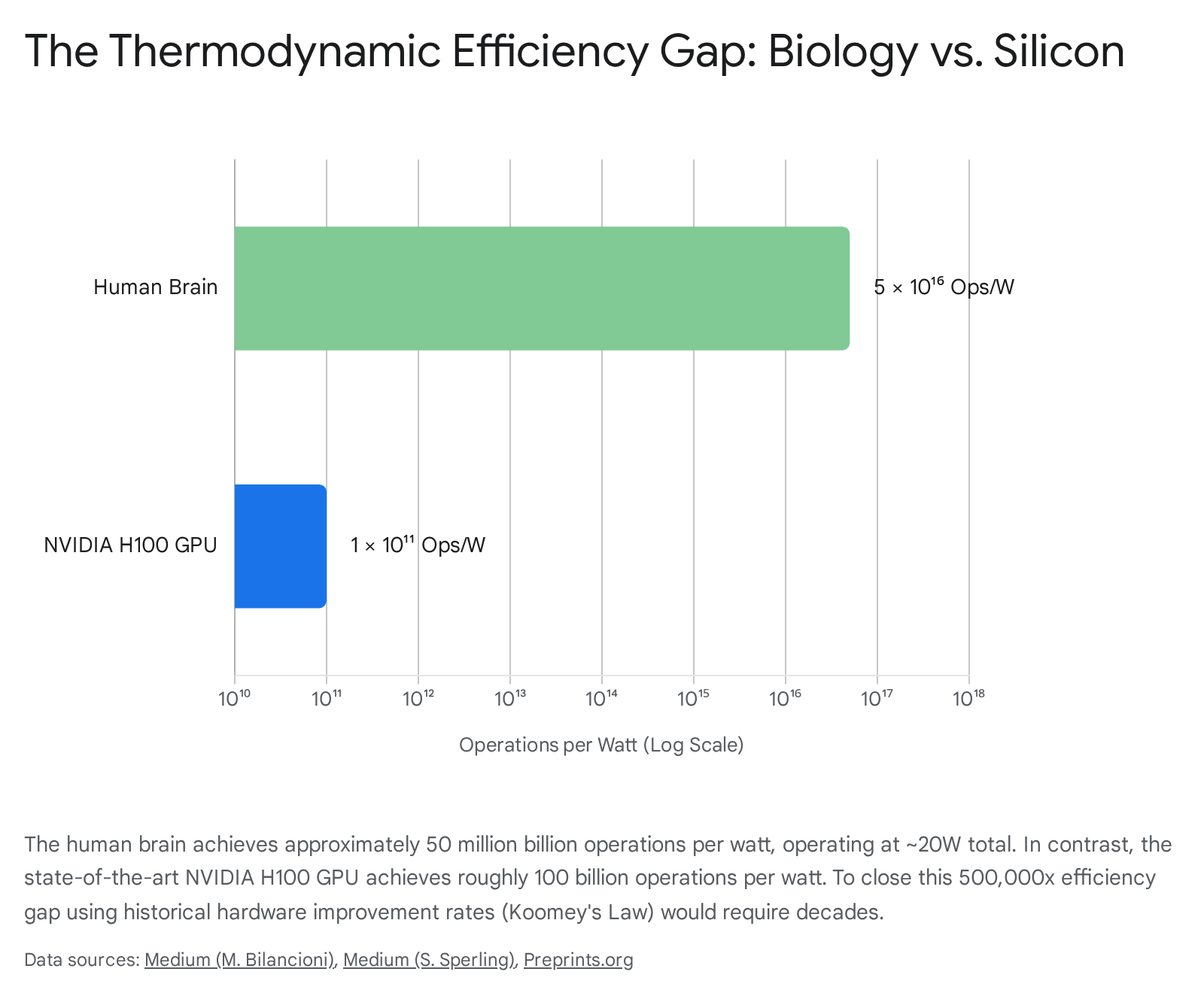
Biological brains evolved under strict, unrelenting metabolic budgets. The adult human brain operates continuously on approximately 20 watts of power - roughly equivalent to the energy required to illuminate a single, dim LED reading bulb 49505159. Despite this extreme power limitation, the highly parallel architecture of the human brain executes an estimated one quintillion ($10^{18}$) functional operations every second 50.
At the microscopic, neurochemical level, a single biological synaptic transmission consumes a remarkably minimal amount of energy, empirically estimated at $1$ to $10$ femtojoules (fJ) ($10^{-15}$ Joules) per event 59525354. The entire brain relies on a massive parallel broadcast structure, where an average individual neuron physically projects to roughly 7,000 distinct postsynaptic targets simultaneously. Consequently, the brain incurs a remarkably low system-level cost of approximately 0.2 picojoules (pJ) per operation, even when rigorously factoring in all baseline cellular metabolic overhead and maintenance 59.
To sustain this unparalleled energy efficiency, biological neural networks employ sophisticated, localized optimization algorithms that are functionally absent from basic artificial neural networks utilizing standard backpropagation. For example, biological systems heavily utilize mechanisms like "synaptic caching" and "competitive plasticity" - parsimonious, localized energy models that restrict structural synaptic plasticity to only a small subset of highly critical routing paths. This distributes learning over highly labile transient connections and stable persistent ones, drastically minimizing the metabolic cost of long-term memory formation. This extreme efficiency is a vital evolutionary adaptation, given that unrestrained, network-wide perceptron learning algorithms would incur a catastrophic caloric debt fatal to the organism 48555665.
Artificial Computational Hardware Constraints
By direct contrast, the silicon hardware executing modern artificial neural networks operates at energy scales located orders of magnitude away from biological efficiency limits. The current state-of-the-art AI accelerator driving frontier models, the NVIDIA H100 Tensor Core GPU, carries a standalone thermal design power (TDP) rating of 700 watts. When scaling to industrial clusters, this consumption rapidly inflates to approximately 1500 watts per GPU unit to account for necessary data center liquid cooling, networking infrastructure, and server overhead 12505758.
While a single H100 GPU can theoretically execute a staggering peak of up to $9.89 \times 10^{14}$ raw FLOPs per second in low-precision formats, the energy required per individual operation remains vast compared to biological chemistry 57. Optimized hardware estimates indicate that the H100 executes roughly $1.4 \times 10^{12}$ FLOPs per Joule of energy consumed, mathematically equating to approximately $0.7$ picojoules (pJ) per raw floating-point operation 125958. However, raw FLOP efficiency is highly deceptive. When scaling up to the massive matrix multiplications and the relentless, high-bandwidth memory access movements required by Transformer-based large language model inference, the effective system-level energy cost per parameter update or generated token is vastly higher due to the friction of moving data across physical silicon architectures 596859.
When standardizing computational capability into a strict, comparable operations-per-watt metric, the human brain achieves an astronomical rate of roughly $5 \times 10^{16}$ operations per watt. In stark contrast, the state-of-the-art H100 GPU achieves only $1 \times 10^{11}$ operations per watt under optimal synthetic conditions 50. This staggering $500,000\times$ efficiency gap highlights the fundamental thermodynamic reality: pure parameter scaling in artificial systems will rapidly and unavoidably collide with global energy grid constraints long before achieving true parity with the density of biological cognition 105450.
| Computing Substrate | Baseline Operating Power | Isolated Synaptic / FLOP Energy Cost | Standardized Operations per Watt | Core Architectural Paradigm |
|---|---|---|---|---|
| Human Brain | ~20 Watts | 1 to 10 femtojoules (fJ) | $\sim 5 \times 10^{16}$ | Co-located memory and processing, asynchronous analog spiking, extreme fan-out connectivity. |
| NVIDIA H100 GPU | ~700 Watts (TDP) | ~0.7 picojoules (pJ) | $\sim 1 \times 10^{11}$ | Von Neumann physical separation, strict synchronous clocking, dense digital matrix multiplications. |
To actively bridge this massive thermodynamic gap, vanguard hardware research into neuromorphic computing seeks to directly emulate the biological integration of memory and processing. By utilizing advanced phase-change memory (PCM) elements, organic nanofiber transistors, and analog ferroelectric memristors to act as physical artificial synapses, experimental neuromorphic chips have successfully achieved sub-picojoule synaptic events (e.g., ~1.8 pJ down to 1.23 fJ in highly controlled lab settings) 4952537060. These hardware advancements strongly signal that sustaining AI scaling laws into future decades will require entirely abandoning the digital von Neumann architecture in favor of biologically inspired, low-voltage material physics 497060.
Conclusion
The mathematical rules governing the systemic growth of neural architectures reveal deep structural symmetries between biological evolution and machine learning optimization, accompanied by irreconcilable physical and thermodynamic differences. Both domains rigorously adhere to strict power-law scaling relationships. In the realm of biology, allometric scaling dictates precisely how metabolic rates and total neuron counts alter in relation to expanding physical body mass, manifesting in diverse but mathematically rigid formulas like Kleiber's Law and the specific cellular density formulas separating primates from rodents. In artificial intelligence, scaling laws mathematically bind a model's test loss strictly to the scale of its parameters and data corpus, mapping exactly to theoretical variance-limited and resolution-limited optimization constraints upon high-dimensional data manifolds.
However, the elegant mathematical analogy shatters completely at the physical hardware layer. Biological systems are thermodynamic marvels forged by millions of years of scarcity, utilizing synaptic caching, morphologically diverse and highly specialized neurons, and ultra-low-energy biochemistry to achieve generalized intelligence operating at merely 20 watts. Artificial systems, bound by the rigid limits of silicon manufacturing and von Neumann data-transfer bottlenecks, achieve mathematically smooth reductions in cognitive error at an exorbitant, and ultimately unsustainable, global energy cost.
The future trajectory of artificial neural scaling cannot rely indefinitely on the brute-force expansion of variables. Confronted with the impending exhaustion of human-generated training data and severe thermodynamic grid constraints, the artificial intelligence industry faces an evolutionary bottleneck. As clearly demonstrated by the evolutionary adaptation of avian neuronal density and the architectural emergence of primate von Economo cells, the next era of scaling will absolutely demand fundamental, punctuated transitions in both network architecture and physical computation substrates.