Transformer Models versus Statistical Arbitrage in Equity Markets
Introduction
Statistical arbitrage encompasses a sophisticated class of quantitative trading strategies that seek to exploit temporary pricing inefficiencies between correlated financial instruments. Grounded in the principle of mean reversion and the law of one price, traditional statistical arbitrage relies heavily on econometric models and linear algebra to construct market-neutral portfolios. By establishing a statistical relationship between two or more assets, quantitative researchers can generate alpha when these assets temporarily diverge from their historical equilibrium, shorting the outperforming asset and going long on the underperforming asset under the assumption that their prices will eventually converge.
However, financial markets operate as complex, non-linear dynamic systems characterized by high volatility, shifting macroeconomic regimes, and intricate cross-asset dependencies. As market efficiency increases, particularly in highly algorithmic developed equity markets, the excess returns generated by classical linear models have steadily compressed. The structural limitations of parametric models, which often assume strict stationarity and Gaussian error distributions, limit their capacity to process the massive scale of high-frequency data and alternative data sources now available to institutional investors.
To maintain a competitive edge, quantitative researchers have increasingly turned to deep learning architectures. Over the past decade, recurrent neural networks (RNNs) and long short-term memory (LSTM) networks were introduced to model the sequential nature of financial time series. More recently, the advent of the Transformer architecture, initially designed for natural language processing, has prompted a paradigm shift in financial modeling. Utilizing multi-headed self-attention mechanisms, Transformers offer an unprecedented ability to model long-range dependencies and complex non-linear patterns without the sequential processing bottlenecks of prior network designs.
This comprehensive research report evaluates the theoretical foundations, empirical forecasting accuracy, performance stability, and computational infrastructure requirements of Transformer-based models compared to traditional statistical arbitrage methodologies. Furthermore, the analysis explores the profound methodological challenges - such as look-ahead bias, the interpretability deficit, and hardware latency constraints - associated with deploying massive foundation models in live algorithmic trading environments.
Theoretical Foundations of Statistical Arbitrage
To evaluate the efficacy of deep learning in quantitative trading, it is necessary to first delineate the mathematical and structural frameworks of classical statistical arbitrage. These traditional methodologies form the baseline against which all modern neural architectures and foundation models are measured.
Traditional Econometric Methodologies
The cornerstone of classical statistical arbitrage is pairs trading, which relies heavily on the concept of cointegration. Cointegration identifies scenarios where two or more non-stationary time series are integrated in such a way that they cannot deviate from a long-term equilibrium 11. Nobel laureates Robert Engle and Clive Granger introduced the formalized cointegrating vector approach in 1987, arguing against the use of simple linear regression for time series analysis due to the risk of spurious correlation 12.
In modern quantitative trading, the primary econometric tool for identifying these relationships across multiple assets is the Johansen Cointegration Test. Unlike the Augmented Dickey-Fuller (ADF) test, which is restricted to pairwise comparisons, the Johansen procedure allows for the analysis of up to 12 simultaneous time series to determine if they share a common stochastic trend 145. The Johansen test relies on vector autoregressive models (VAR) and utilizes an eigenvalue decomposition to determine the rank of the relationship matrix. The test calculates trace statistics and sequential hypotheses to determine the number of independent portfolios that can be formed 15. If the trace statistic exceeds the critical value at a specified confidence interval, the null hypothesis of zero cointegrating relationships is rejected, indicating that a stationary linear combination of the assets exists 46.
Beyond isolated pairs or triplets, advanced traditional statistical arbitrage utilizes Principal Component Analysis (PCA) to extract latent risk factors from a broad universe of equities. Foundational frameworks, such as those developed by Avellaneda and Lee (2010), decompose market returns into systematic components (market factors) and idiosyncratic components (residuals) 349. These residual portfolios are mathematically modeled using an Ornstein-Uhlenbeck (OU) process, which represents a continuous-time mean-reverting stochastic process 3. Trading signals are generated mechanically when the residual diverges beyond a specified threshold from its equilibrium, operating under the strict mathematical assumption that the idiosyncratic price movement will revert to the mean 3.
Limitations of Linear and Parametric Models
While mathematically elegant, computationally lightweight, and highly interpretable, traditional statistical arbitrage models suffer from distinct empirical limitations. Classical techniques generally assume linearity and rely heavily on the assumption that historical relationships will remain stationary 1011. However, equity time series are inherently non-stationary, frequently exhibiting volatility clustering, heavy-tailed return distributions, and sudden structural breaks 10125.
When macroeconomic regimes shift rapidly - such as during global financial crises or unexpected monetary policy adjustments - the historical covariance matrices utilized in PCA or Johansen tests often break down entirely, leading to severe drawdowns as supposedly cointegrated assets diverge indefinitely 11514. Furthermore, parametric models specify a rigid functional form, such as a single mean-reversion frequency or a predetermined lag window 3. This rigidity limits the model's capacity to recognize multi-scale temporal patterns, non-linear correlations, or asymmetric market behaviors, severely restricting the universe of viable trading signals.
| Analytical Framework | Mathematical Foundation | Core Assumptions | Primary Limitations in Equity Markets |
|---|---|---|---|
| Pairs Trading (ADF) | Augmented Dickey-Fuller Test | Bivariate linear cointegration. | Restricted to two assets; highly susceptible to regime shifts and structural breaks. |
| Multivariate Cointegration | Johansen Test (VAR models) | Linear combinations yield stationary residuals; constant variance. | Eigenvalue decomposition degrades in highly volatile environments; limited to ~12 concurrent series. |
| Statistical Factor Models | PCA & Ornstein-Uhlenbeck | Residuals follow a continuous-time mean-reverting stochastic process. | Imposes rigid parametric constraints; struggles with asymmetric price momentum and multi-frequency reversion. |
| Deep Learning Models | Non-linear Neural Architectures | Markets possess latent, complex dependencies unobservable by linear tools. | Requires massive datasets; prone to overfitting noise; lacks transparency regarding feature attribution. |
Transformer Architecture and Time Series Adaptation
The empirical limitations of econometric models catalyzed the integration of machine learning into quantitative finance. While early neural network implementations relied heavily on Convolutional Neural Networks (CNNs) and LSTMs, the Transformer model has redefined the boundaries of sequence modeling.
Self-Attention Mechanisms in Financial Data
Introduced by Vaswani et al. in 2017, the Transformer architecture abandons the sequential, step-by-step processing inherent in RNNs and LSTMs 1215166. Instead, it utilizes a multi-headed self-attention mechanism that processes entire sequences of data in parallel. Within this architecture, input data is projected into Query, Key, and Value matrices. The scaled dot-product attention computes the interaction between these matrices, allowing the model to dynamically prioritize the importance of every historical time step relative to the current prediction 6181920.
In the context of financial time series, self-attention provides a profound theoretical advantage. Traditional LSTMs compress historical sequences into a single hidden state vector, leading to information loss and vanishing gradients over long look-back windows 16722. Conversely, a Transformer can directly attend to a specific volatility spike, earnings announcement, or structural break that occurred months prior, establishing a direct mathematical path between distant historical events and the current market state 1819824. This parallelization enables the model to learn global, long-range dependencies - such as multi-month momentum superimposed with intraday reversion - far more effectively than any previous architecture 197824.
Evolution of Time Series Foundation Models
The success of Large Language Models (LLMs) has inspired the development of purpose-built Time Series Foundation Models (TSFMs). Unlike bespoke models trained on a single stock, TSFMs are pre-trained on billions of diverse time series data points across multiple domains (finance, energy, retail), utilizing self-supervised learning to acquire robust, zero-shot forecasting capabilities 25262728.
Several distinct architectures have emerged to address the specific challenges of numerical sequence forecasting:
The TimeGPT model, developed by Nixtla, utilizes an encoder-decoder Transformer structure trained on over 100 billion diverse data points 2629. TimeGPT treats sequences of historical observations as "tokens" and directly extrapolates future values through its self-attention layers. The model excels at zero-shot inference, allowing quantitative analysts to generate forecasts on unseen financial datasets without requiring computationally expensive retraining 26. Furthermore, TimeGPT supports the inclusion of exogenous variables and utilizes conformal prediction methodologies to generate statistically rigorous confidence intervals, enabling real-time anomaly detection 252629.
Conversely, Google's TimesFM relies on a decoder-only architecture. Pre-trained on a massive corpus, TimesFM segments time series into discrete patches rather than processing individual time points 283031. By configuring the model to accept input patches of length 32 and output patches of length 128, the architecture predicts horizons of varying lengths with significantly reduced computational overhead, maintaining strong zero-shot performance across univariate forecasting tasks 31.
A highly influential open-source approach is the PatchTST model, which introduced two critical modifications to the standard Transformer architecture. First, it utilizes channel independence, meaning each channel in a multivariate time series is processed as an independent univariate sequence, preventing the model from confusing noisy cross-asset correlations during the initial encoding phase 93310. Second, PatchTST segments the continuous time series into localized subseries "patches" (e.g., a patch length of 16 time steps with a stride of 8) 3311. This patching mechanism preserves local semantic information and dramatically reduces the computational complexity of the attention matrix from quadratic $O(N^2)$ to $O((N/S)^2)$ 1136. This efficiency allows PatchTST to ingest exponentially longer historical look-back windows, deeply improving forecasting capability while mitigating the high memory costs that previously hindered Transformer application in finance 1136.
| Foundation Model | Architecture Type | Pre-training Scale | Key Architectural Innovations | Primary Analytical Use Case |
|---|---|---|---|---|
| TimeGPT | Encoder-Decoder | >100 Billion points | Local positional encoding; Conformal prediction. | Zero-shot forecasting; Out-of-the-box anomaly detection. |
| TimesFM | Decoder-only | ~100 Billion points | Patch-based input/output sizing; Highly scalable. | General-purpose univariate point forecasting. |
| PatchTST | Encoder-only | Dataset specific | Channel independence; Subseries patching ($O((N/S)^2)$). | Multivariate long-horizon forecasting; Representation learning. |
Natural Language Integration and Cross-Modal Arbitrage
Beyond numerical processing, Transformers unlock a dimension of statistical arbitrage wholly unavailable to traditional econometric models: textual sentiment and fundamental data ingestion. Large Language Models optimized for finance, such as BloombergGPT and FinGPT, allow for the real-time processing of earnings call transcripts, news headlines, and regulatory filings 37123940.
BloombergGPT, a proprietary 50-billion parameter causal language model, was trained on a massive corpus including 363 billion financial tokens curated from decades of financial documents 1239. It established new performance benchmarks for named entity recognition, sentiment analysis, and question-answering in the financial domain 3941. Alternatively, open-source initiatives like FinGPT democratize this capability using lightweight low-rank adaptation (LoRA) techniques, drastically reducing fine-tuning costs from millions of dollars to under $300 per cycle 3712.
By vectorizing qualitative sentiment, modern statistical arbitrage strategies align numerical price residuals with real-time semantic catalysts. Recent academic implementations have combined group-wise one-dimensional convolutional kernels for raw stock metrics with TinyBERT representations of full financial news articles. These cross-modal architectures demonstrate marked improvements over baseline models, achieving directional accuracy rates of 62.5% in out-of-sample tests and exhibiting highly stable normalized mean squared errors 13. This integration indicates that text-aware Transformers capture alpha embedded in market psychology that pure numerical models fundamentally ignore.
Empirical Forecasting and Trading Performance
The theoretical elegance of deep learning architectures does not guarantee profitability. The transition from theory to practice reveals nuanced realities regarding the performance of Transformer models compared to classical counterparts. Empirical outcomes in financial markets are heavily dependent on asset class characteristics, the specific parameters of the trading strategy, and the strictness of the out-of-sample evaluation protocol.
Predictive Accuracy on Baseline Metrics
When evaluated on broad, standardized multivariate time-series forecasting benchmarks, Transformer models frequently demonstrate state-of-the-art predictive accuracy. In controlled academic evaluations, models utilizing patch-based tokenization have shown substantial reductions in forecasting errors over earlier deep learning benchmarks. For example, the PatchTST model recorded a 21.0% reduction in Mean Squared Error (MSE) and a 16.7% reduction in Mean Absolute Error (MAE) relative to standard Transformer variants across multiple long-horizon forecasting tasks 3311. The model's capacity for representation learning, particularly when utilizing self-supervised pre-training, allows it to capture abstract, multi-layered data representations that simpler linear models cannot process 3336.
However, when forecasting foundation models are tested specifically on highly noisy, non-stationary financial data (such as daily stock returns), the dominance of Transformers is not absolute. Comparative performance metrics highlight an ongoing tension between high model complexity and robust forecasting accuracy.
A comprehensive out-of-sample walk-forward validation across US equities by Li & Liu evaluated ARIMA, Random Forest, LSTM, CNN, and Transformer models for next-day log-return forecasting 7. The study revealed that classical baselines remained remarkably difficult to beat. ARIMA produced the lowest forecasting errors for the majority of individual stocks tested, excelling in environments where short-term linear momentum was the dominant factor 7. Random Forest also remained a highly competitive baseline, frequently outperforming deep learning architectures on highly volatile assets (such as Tesla) due to its inherent robustness to extreme non-linear outliers 7.
Furthermore, Recurrent Neural Networks continue to show strong utility in specific configurations. Extensive testing comparing GRU, LSTM, and Transformer models on a panel of technology stocks demonstrated that GRUs frequently yielded the lowest MAE, reflecting superior prediction precision for short-term variance 43. While the Transformer showed promise in handling complex cross-sectional relationships, it struggled with the severe volatility of certain individual assets, leading to lower R-squared values and higher error rates than the recurrent models 43.
These findings suggest that while Transformers possess unparalleled capacity, their raw point-forecasting capability on individual, highly efficient assets often succumbs to overfitting the pervasive noise inherent in financial time series 7814.
Implementation in Statistical Arbitrage Strategies
While raw price prediction is challenging, Transformers demonstrate profound utility when integrated into a structured statistical arbitrage framework. A landmark study on deep learning statistical arbitrage by Guijarro-Ordonez, Pelger, and Zanotti utilized a hybrid model combining a Convolutional Neural Network (CNN) with a Transformer to extract trading signals from the residual portfolios of US equities 345.
In this framework, the researchers did not feed raw returns into the neural network. Instead, they constructed arbitrage portfolios by extracting latent asset pricing factors via a statistical factor model (such as IPCA), effectively stripping away systematic market risk 345. The resulting idiosyncratic residuals were then fed into the deep learning time-series filter. The CNN component detected local, short-term data structures (such as smooth trends and localized momentum), while the Transformer component utilized self-attention to identify global dependencies and long-range mean-reversion patterns across the asset cross-section 3.
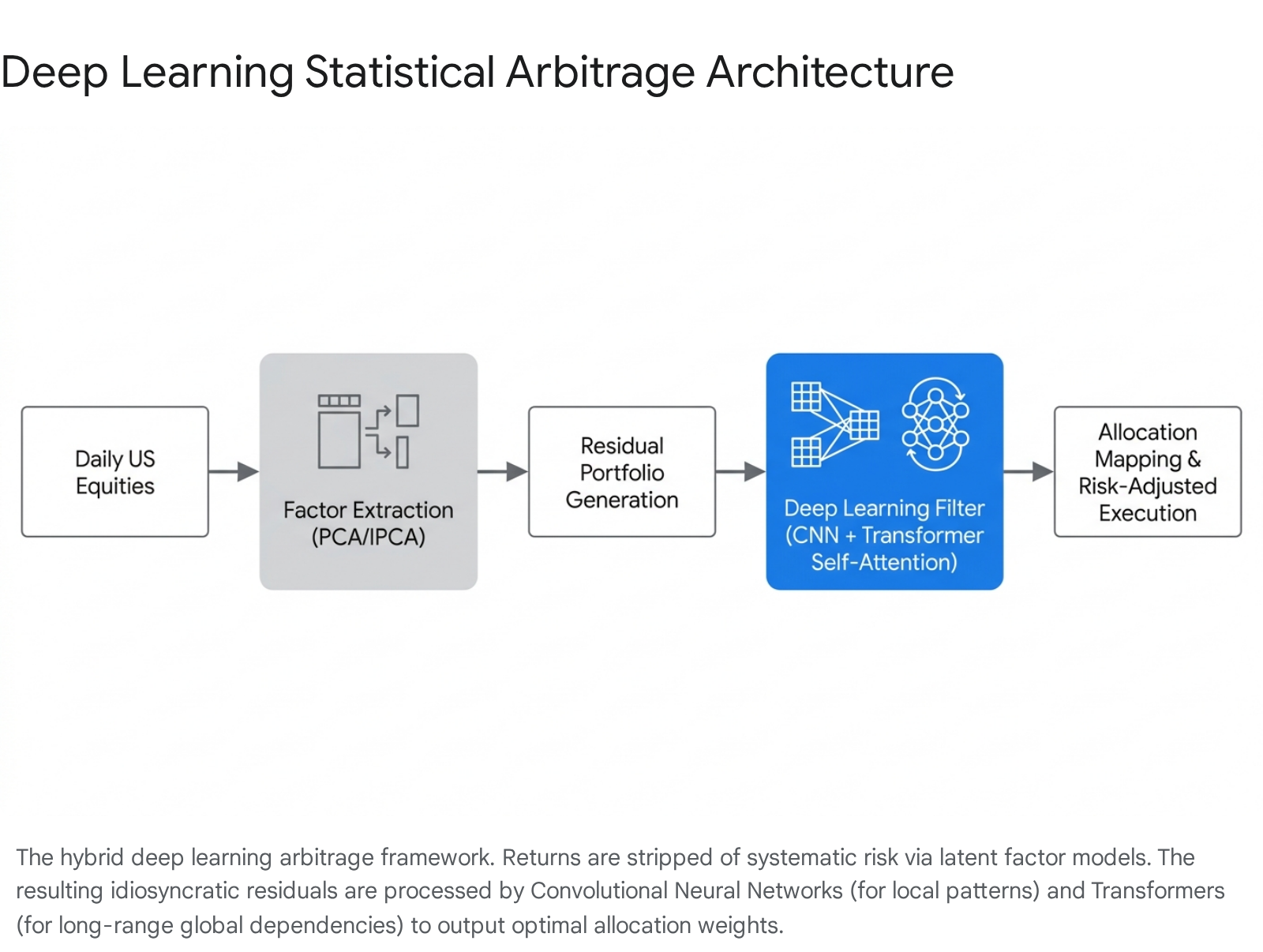
The trading results of this hybrid Transformer methodology were exceptional. The strategy achieved an annual Sharpe ratio of 4.0 and generated mean annual returns of approximately 20% with less than 6% volatility in out-of-sample testing 3. This deep learning approach outperformed traditional parametric models (such as the Ornstein-Uhlenbeck process with threshold rules) by a factor of four, demonstrating that flexible, data-driven time-series filters can vastly improve execution timing and signal extraction 3. Notably, the model exhibited highly asymmetric trading behavior - reacting aggressively to rapid downtrends and trading cautiously during uptrends - a complex dynamic policy that is mathematically impossible to replicate using standard linear econometric models 3.
Conversely, when Transformer forecasts are plugged into simplistic trading rules without rigorous portfolio optimization layers, the results can be detrimental. Backtests evaluating a naive forecast-linked Transformer strategy revealed an unstable equity trajectory characterized by severe mid-sample drawdowns when compared to a simple, rule-based moving average crossover benchmark 7. This dichotomy reinforces a fundamental tenet of modern quantitative finance: forecast quality alone is insufficient. The forecast-to-trade mapping, position sizing, and risk control layers are just as critical as the neural network generating the signal 7.
Computational Infrastructure and Latency Constraints
The theoretical advantage of a complex statistical arbitrage model is rendered irrelevant if it cannot be executed within the stringent latency constraints of market microstructure. In modern algorithmic trading, infrastructure dictates strategy viability.
The High-Frequency Trading (HFT) Ecosystem
Traditional high-frequency statistical arbitrage relies on capturing transient order book imbalances that exist for mere microseconds. To achieve execution speeds capable of beating institutional competitors and avoiding adverse selection, HFT firms rely on specialized hardware, primarily Field-Programmable Gate Arrays (FPGAs) and Application-Specific Integrated Circuits (ASICs) 46474849.
Unlike standard CPUs or GPUs that rely on operating system scheduling, software layers, and sequential instruction pipelines, FPGAs are programmed directly at the hardware level using Hardware Description Languages (HDL) such as Verilog or VHDL 4950. By configuring logic blocks (CLBs) and Lookup Tables (LUTs) into custom parallel data paths, FPGAs perform market data ingestion, order book reconstruction, and execution logic simultaneously as data flows through the silicon 49.
This architecture allows for completely deterministic, hardware-level execution. By bypassing the operating system kernel entirely (utilizing technologies like DPDK or Solarflare OpenOnload), network interface latency is reduced from tens of microseconds to between 1 and 5 microseconds 474849. Consequently, an FPGA-based system can achieve end-to-end tick-to-trade latencies of 150 to 500 nanoseconds 474950. Traditional statistical arbitrage strategies, which rely on computationally light mathematical formulas (e.g., executing a trade when a simple spread calculation crosses a static threshold), fit seamlessly onto FPGA fabric, allowing firms to exploit pricing anomalies instantly 5051.
Inference Latency of Transformer Models
Deploying deep learning models, particularly Transformers, in a low-latency environment introduces severe computational bottlenecks. The complexity of the self-attention mechanism scales quadratically with sequence length, requiring massive floating-point operations (FLOPs) and significant memory bandwidth to compute the necessary matrices 155354.
Even with highly optimized software environments, the inference latency of a Transformer is orders of magnitude slower than classical HFT logic. A standard Transformer processing a 512-token context window typically requires 10 to 50 milliseconds (equivalent to 10,000,000 to 50,000,000 nanoseconds) for a single forward pass on high-end hardware 5354. This latency renders pure Transformer models wholly unsuited for the nanosecond-level execution required in primary market-making or pure HFT statistical arbitrage 4653.
However, the hardware ecosystem is rapidly evolving to accommodate heavy neural networks for slightly slower, high-frequency "stat-arb" strategies that operate on millisecond or second-level horizons: * GPU Acceleration: Data center GPUs are specifically engineered for AI inference. The NVIDIA H100 (Hopper architecture) features a dedicated Transformer Engine and high-bandwidth memory (HBM3), delivering unmatched throughput for large models 55165717. For more cost-effective inference at the edge, the NVIDIA L4 (Ada Lovelace architecture) acts as an energy-efficient, low-profile accelerator, providing optimal cost-per-token efficiency for smaller 7-billion parameter models 55165717. * Quantization and Distillation: To reduce latency, quantitative developers utilize reduced-precision inference, quantizing model weights from standard FP32 (32-bit floating point) down to FP16 or FP8. Hardware support for FP8 on the H100 allows for inference speeds roughly 37% faster than 16-bit operations, enabling faster execution with minimal accuracy loss 5718. Furthermore, model distillation compresses massive foundation models into smaller, latency-appropriate variants for production deployment 46. * State Space Models (SSMs): Emerging architectures like Mamba offer sequential modeling with $O(N)$ linear complexity, avoiding the quadratic bottleneck of self-attention. Practitioners report Mamba inference times dropping to 1 to 3 milliseconds for 512-token windows, pushing complex non-linear sequence modeling much closer to the latency budget of high-frequency trading systems 5354.
| Infrastructure Component | Architecture Type | Processing Paradigm | Typical Tick-to-Trade Latency | Optimal Trading Application |
|---|---|---|---|---|
| FPGA | Reconfigurable Silicon | Hardware-level parallel data paths; bypasses OS kernel. | 150 - 500 Nanoseconds | Pure HFT; Market Making; Linear Statistical Arbitrage. |
| NVIDIA L4 GPU | Ada Lovelace Architecture | Massively parallel software execution; optimized for energy/cost. | 1 - 10 Milliseconds (model dependent) | Millisecond Stat-Arb; Edge inference; Sentiment classification. |
| NVIDIA H100 GPU | Hopper Architecture | Extreme bandwidth (HBM3); dedicated Transformer Engine; FP8. | < 50 Milliseconds (for large LLMs) | Complex multivariate forecasting; Deep Learning Stat-Arb. |
Ultimately, an architectural bifurcation exists in modern trading: traditional linear models and simple decision logic rule the nanosecond (FPGA) execution tier, while Transformers and deep neural networks dominate the millisecond-to-minute (GPU) predictive signal generation tier.
Market Efficiency and Regional Variations
The performance gap between traditional methods and Transformers is highly sensitive to the underlying efficiency of the specific equity market being traded.
Developed Market Constraints
In highly developed markets, such as the US S&P 500, liquidity is abundant, and regulatory frameworks are deeply entrenched. These markets are heavily arbitraged by thousands of institutional participants utilizing the aforementioned ultra-low-latency FPGA systems 101119. Consequently, market efficiency is exceedingly high. Shocks are absorbed almost instantaneously, and predictable price components are minuscule. In these environments, simple statistical arbitrage signals degrade within fractions of a second, and even advanced Transformer models struggle to consistently extract excess alpha net of transaction costs without incorporating massive amounts of alternative data to gain an informational edge 1011719.
Emerging and Frontier Market Dynamics
In contrast, emerging and frontier markets exhibit greater informational asymmetries, evolving regulatory structures, higher political risk, and substantially lower liquidity, rendering them systematically less efficient 91119. Empirical studies dividing global stock indices into developed and emerging groups demonstrate that statistical arbitrage systems generally achieve higher profitability in emerging regions. Comparative historical analyses show systems achieving an average Compound Annual Growth Rate (CAGR) of 12.46% in emerging markets, compared to just 5.65% in developed markets 9.
The non-linear capabilities of Transformers make them uniquely suited to exploit the structural inefficiencies of these regions. Emerging market equities are often highly vulnerable to foreign capital movements, rapid inflation fluctuations, and idiosyncratic domestic issues 115. Hybrid Transformer models that integrate localized econometric indicators (such as exchange rates or regional volatility indices) directly into the self-attention pipeline alongside price data can capture the complex, multifaceted nature of these markets far more effectively than rigid traditional econometric models 1112. The ability of deep learning to model behavioral overreactions and asymmetric momentum is particularly valuable in markets where retail participation remains high and institutional arbitrage is less pervasive 125.
Methodological Challenges and Systemic Risks
The integration of advanced neural networks into financial modeling introduces systemic risks that do not apply to transparent, parsimonious econometric models. If mismanaged, these risks can lead to catastrophic capital misallocation.
Look-Ahead Bias and Data Contamination
The most critical threat to the validity of deep learning financial research is look-ahead bias - the inadvertent inclusion of future data during the training phase, resulting in model predictions based on information that would not have been available at the simulated point in time 72062.
In quantitative finance, look-ahead bias acts as a silent killer, inflating backtest performance metrics and Sharpe ratios to unrealistic levels, setting the stage for massive failures in live trading 62. This problem is exponentially magnified in modern Time Series Foundation Models and Financial LLMs. Because these models are pre-trained on massive, internet-scale datasets spanning decades, they have inherently "memorized" historical stock returns, earnings data, macroeconomic crises, and post-event sentiment 2063. Consequently, when researchers run a historical backtest (e.g., simulating a trading strategy in 2018 using a foundation model trained on data collected through 2023), the model benefits from severe test-set contamination. It utilizes verbatim and semantic knowledge of the future to predict the past, rendering the backtest mathematically invalid 206263.
While classical ARIMA or Johansen cointegration models trained strictly via rolling-window cross-validation on local, user-provided datasets are inherently safe from internet-scale data leakage, Transformers require complex mitigation strategies 7. Since retraining a massive foundation model from scratch for every specific historical knowledge cutoff is financially and computationally prohibitive, recent research has focused on inference-time solutions. Advanced techniques involve dynamic logit adjustments - using specialized smaller models fine-tuned on information to be "forgotten" to mathematically suppress the probabilities of memorized future knowledge during inference - allowing for rigorous, bias-free backtesting without retraining the base model 20.
The Interpretability Deficit
In institutional quantitative finance, risk management relies heavily on model interpretability. When a traditional statistical arbitrage strategy suffers a drawdown, risk managers can query the PCA factor loadings, the OU reversion thresholds, or the Johansen cointegration vectors to mathematically pinpoint exactly why the historical correlation broke down 58.
Transformers, however, operate as high-dimensional black boxes, creating significant compliance and risk oversight challenges 821. While attention mechanisms are frequently cited as providing "ante-hoc" interpretability - by allowing researchers to visualize attention weights and observe which historical time steps the model focused on - mathematical proofs demonstrate that this is often misleading 202421. Detailed post-hoc analyses show that the final linear projection layers of a Transformer can completely override or modify the token influence implied by the raw attention weights 20. Consequently, while a heat-map of attention weights might show a model focusing heavily on a specific volatility spike, this does not guarantee that the spike was the causal driver of the final trading signal 20.
The safe deployment of Transformer models in trading therefore requires rigorous post-hoc interpretability frameworks, such as SHapley Additive exPlanations (SHAP) or Local Interpretable Model-agnostic Explanations (LIME), to provide a more accurate, model-agnostic understanding of feature attribution and ensure that the neural network is not trading based on spurious correlations 2021.
Conclusion
The evolution of statistical arbitrage in equity markets illustrates a continuous arms race between computational complexity, market efficiency, and execution latency. Traditional econometric methods - rooted in cointegration, PCA, and mean-reversion - provide mathematically sound, highly interpretable, and computationally lightweight frameworks. Due to their simplicity, they remain the undisputed standard for ultra-low-latency environments, where FPGAs execute trades in nanoseconds, and they continue to serve as highly robust baselines for short-horizon univariate price forecasting.
However, as alpha decays in efficiently arbitraged markets, Transformer-based models present a compelling and necessary frontier. Through self-attention mechanisms and advanced patch-based tokenization, Transformers capture long-range temporal dependencies, cross-asset non-linearities, and multi-modal signals (such as text sentiment) that classical linear models fundamentally ignore. Frameworks that effectively combine traditional risk factor isolation with deep learning time-series filters have demonstrated the capacity to generate market-neutral portfolios with historically exceptional risk-adjusted returns.
Ultimately, Transformers do not render traditional statistical arbitrage obsolete. Instead, they demand a hybrid architecture. The optimal deployment of capital relies on using classical methods for strict risk factor modeling and deterministic HFT execution, while leveraging the immense pattern-recognition capabilities of Transformer networks to predict broader market regimes and extract latent alpha. As hardware acceleration narrows the latency gap, the successful quantitative trading firms of the next decade will be those that effectively navigate the complex intersection of deep learning representation, rigorous mitigation of look-ahead bias, and ultra-fast physical infrastructure.