Integration of Alternative Data in LLM Trading Pipelines
The architecture of quantitative investment is undergoing a structural shift driven by the maturation of large language models (LLMs) and their capacity to ingest, structure, and reason over multimodal alternative data. Historically, quantitative analysts relied heavily on structured numerical data, such as price-volume metrics, financial ratios, and fundamental disclosures. Unstructured alternative data, including news sentiment, social graphs, and satellite imagery, previously required rigid, rules-based natural language processing (NLP) or extensive manual feature engineering. The integration of LLMs has replaced these fragmented processes with unified pipelines capable of transforming high-dimensional, unstructured inputs into actionable trading signals 12.
This transition involves embedding domain-specific foundation models, retrieval-augmented generation (RAG) architectures, and autonomous multi-agent systems directly into the trade execution lifecycle 234.
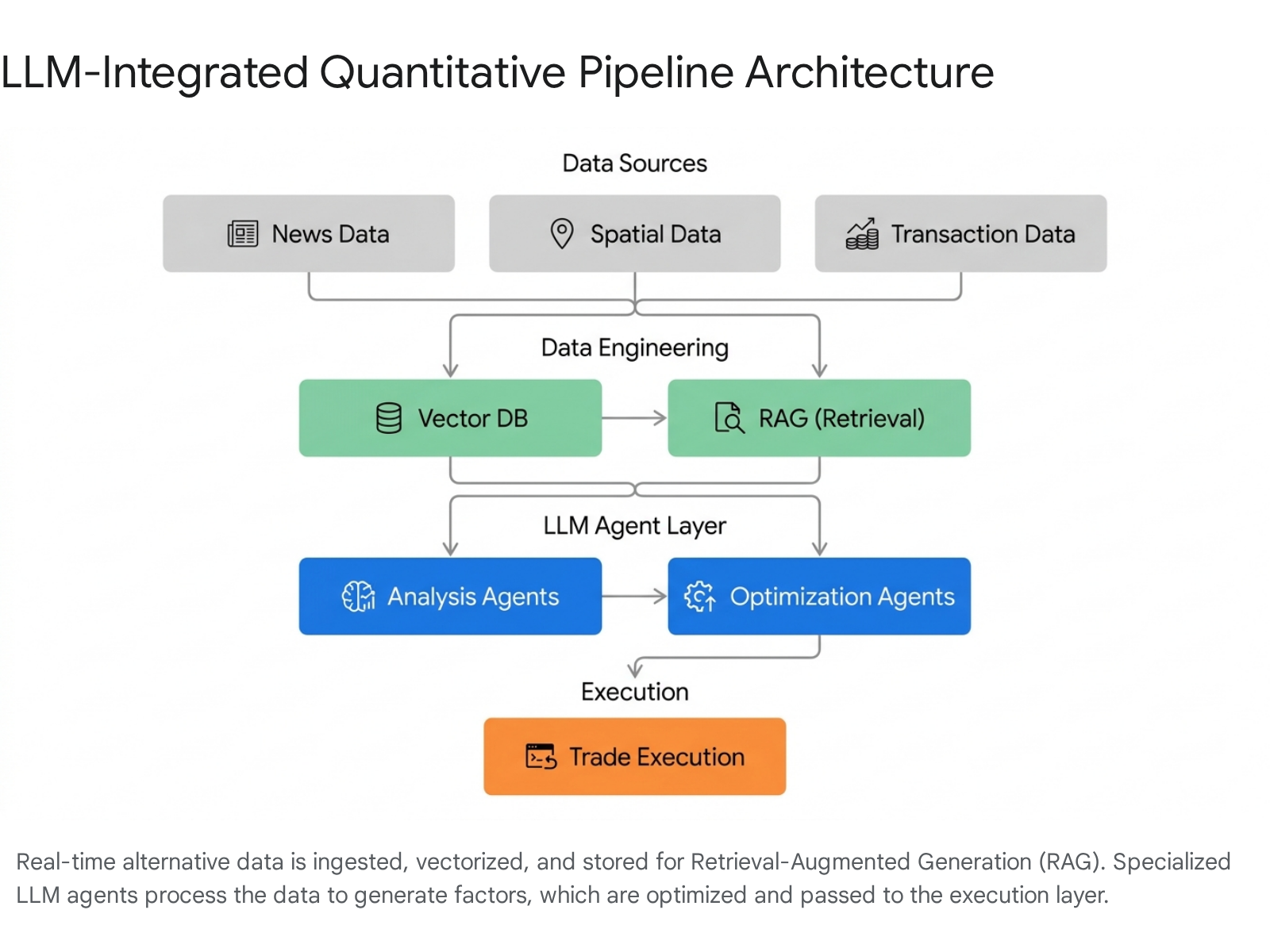
However, the deployment of these probabilistic systems within highly regulated and latency-sensitive financial environments introduces new complexities regarding data provenance, model risk management, and regulatory compliance.
Regulatory Frameworks Governing Data Acquisition
The efficacy of an LLM-based trading pipeline is fundamentally constrained by the quality and legality of its data ingestion layer. As investment firms move away from relying solely on pre-packaged datasets from alternative data vendors and begin deploying direct, LLM-powered web scraping and document parsing, they expose themselves to a highly fragmented global regulatory landscape 56.
Intellectual Property and Scraping in Japan
Alternative data acquisition strategies operate in a legal gray area that varies significantly by jurisdiction. Japan has historically maintained one of the most permissive environments for artificial intelligence data acquisition. Under Article 30-4 of Japan's Copyright Act, amended in 2018, both commercial and non-commercial entities are permitted to use copyrighted works for information analysis and machine learning training without obtaining prior permission from copyright holders 8. This explicitly includes the ingestion of web-scraped alternative data for financial modeling, prompting the characterization of the jurisdiction as a highly favorable environment for model training 8.
However, this framework is facing intense scrutiny and is undergoing rapid evolution. In late 2025, major Japanese newspaper groups, including Yomiuri Shimbun, Nikkei, and Asahi Shimbun, filed lawsuits against AI search services alleging the unauthorized scraping of hundreds of thousands of articles 9. The Japan Newspaper Publishers & Editors Association has submitted formal requests demanding transparency on the origin of training data and the establishment of a licensing framework . The Japanese government is expected to address these intellectual property concerns in its 2025 Intellectual Property Strategic Program, which aims to balance global AI competitiveness with content protection, potentially narrowing the safe harbor provided by Article 30-4 10. Furthermore, the Financial Services Agency has issued discussion papers setting expectations for model risk management and explainability in financial institutions, signaling a move toward tighter sector-specific oversight 9.
Privacy Mandates in China and India
In contrast to Japan's historically flexible copyright approach, other major Asian economies have implemented stringent data privacy regimes that directly impact alternative data collection. China's Personal Information Protection Law (PIPL), effective since late 2021, unifies data privacy rules and applies extraterritorially to any entity analyzing the activities of people in China or providing them with goods and services 11122. The PIPL imposes strict data minimization principles and demands explicit, documented consent for the processing of sensitive personal data, which explicitly includes financial information and individual location tracking 111223. Financial institutions utilizing alternative data must pass security assessments by the Cyberspace Administration of China if transferring data internationally, and violations can result in severe penalties, including fines up to 50 million Yuan or 5% of the offending organization's annual revenue 11.
India's Digital Personal Data Protection Act (DPDPA) of 2023, which was fully operationalized through the DPDP Rules notified in November 2025, introduces phased compliance requirements that demand explicit consent for data collection 456. The DPDPA establishes clear distinctions between "Data Principals" (individuals) and "Data Fiduciaries" (entities deciding the purpose of data processing) 4. While the legislation contains an exemption under Section 3(c)(ii) for personal data made publicly available by the data principal, the government has suggested that scraping public data to train AI models may still breach Section 43 of the Information Technology Act (IT Act) if it involves unauthorized computer system access, creating significant compliance friction for data aggregation pipelines 618. The phased 18-month rollout ending in May 2027 mandates clear consent notices, data minimization, and robust security safeguards, reshaping how financial technology firms and hedge funds acquire consumer data 456.
Commercial Scraping Guidelines in Singapore
In jurisdictions like Singapore, there are no specific laws explicitly governing the act of web scraping, but the activity is regulated indirectly through copyright law, contract law (Terms of Service violations), and the Computer Misuse Act, the latter of which can impose criminal liability and fines up to SGD 50,000 for unauthorized access causing damage 1920. The Personal Data Protection Commission (PDPC) in Singapore has issued advisory guidelines clarifying when personal data can be used in AI recommendation and decision systems. Organizations can rely on a "Business Improvement Exception" to process personal data without explicit consent if the data is used to enhance existing products, provided that meaningful notification is given and strict data mapping, labeling, and provenance records are maintained 78.
To mitigate regulatory risk across these disparate jurisdictions, quantitative funds are increasingly deploying AI-driven data pipelines equipped with autonomous governance layers. These pipelines integrate compliance checks that respect robots.txt protocols, monitor for personally identifiable information, and maintain strict data lineage records to ensure auditability during regulatory examinations 6188.
| Jurisdiction | Primary Legislation | Regulatory Stance on AI Data Scraping | Key Compliance Requirements for Financial Data |
|---|---|---|---|
| Japan | Copyright Act (Article 30-4) | Highly permissive, though facing current legal challenges from publishers. | Currently allows unauthorized scraping for data analysis; expected revisions in the 2025 IP Strategic Program 910. |
| China | PIPL (Personal Information Protection Law) | Highly restrictive regarding personal and financial data. | Explicit consent required for sensitive data; mandatory Cyberspace Administration assessments for cross-border transfers 11122. |
| India | DPDPA (2023) & IT Act | Ambiguous; public data is exempt under DPDPA, but scraping may violate the IT Act. | Mandatory consent notices, data minimization, and breach reporting under a phased rollout concluding in 2027 4618. |
| Singapore | PDPA & Computer Misuse Act | Governed by existing contract and computer misuse laws. | Allowed under the "Business Improvement Exception" with meaningful notification and strict data provenance tracking 1978. |
Processing Modalities for Alternative Data
The ingestion layer of modern trading pipelines must normalize a diverse array of unstructured alternative data types. LLMs serve as the primary transformation mechanism, converting raw text, images, audio, and spatial data into structured features suitable for downstream predictive modeling. As the industry moves from experimentation to full-scale adoption, the focus has shifted toward data centralization, allowing both human analysts and AI agents to query a unified data warehouse 5.
Unstructured Text and Market Sentiment
Textual data remains the most widely integrated alternative asset class, encompassing financial news, corporate filings, earnings call transcripts, analyst reports, and social media sentiment. Early alternative data models relied on dictionary-based sentiment scoring, matching predefined lists of positive or negative words. LLMs introduce context-aware comprehension capable of detecting nuanced financial phenomena, such as forward-looking statements, executive tone, and complex sector-specific risk factors 2425.
Models processing social media data - such as platforms analyzing X (formerly Twitter), Stocktwits, and Reddit - have demonstrated substantial alpha generation capabilities by extracting retail investor sentiment 126. Advanced sentiment analysis of social platforms has been shown to predict short-term stock movements with high accuracy, contributing measurable improvements to trading models, particularly in highly volatile sectors and cryptocurrency markets 2627. Platforms like RavenPack, Context Analytics, and Eagle Alpha have built sophisticated infrastructures around transforming real-time unstructured media into structured, point-in-time sentiment indexes 9293031. The concept of point-in-time data is critical for quantitative backtesting, as it removes look-ahead bias and survivorship bias, ensuring that systematic trading algorithms evaluate historical events exactly as they appeared to the market at that moment 930.
However, LLM application in text extraction is not without limitations. Recent industry evaluations indicate that while single-document extraction is generally reliable, models consistently struggle with cross-company comparisons and longitudinal tracking over extended time horizons 31.
Logistics Documents and Supply Chain Telemetry
Beyond traditional text, LLMs are expanding the definition of alternative data to include spatial and operational metrics embedded in physical supply chain documents. In global logistics, AI is utilized to extract data from bills of lading (BOLs), shipping manifests, freight invoices, and customs declarations 3233.
Traditional optical character recognition (OCR) systems struggle with the high variability, unstructured formats, and handwritten annotations frequently found in these documents 34. Modern LLM-based intelligent document processing pipelines can distinguish between printed text and handwritten adjustments, parse complex multi-stop shipment arrays, and extract corrected values 3410. By defining extraction logic via natural language instructions rather than rigid templates, these systems achieve format independence, allowing them to process documents from thousands of different carriers 34. This automation converts physical shipping activity into real-time digital indicators of corporate health, reducing document processing latency from days to minutes and providing predictive insights into inventory levels, consumer demand, and supply chain bottlenecks 3436.
Geospatial and Multimodal Financial Inputs
The frontier of alternative data processing is the integration of Multimodal Financial Foundation Models (MFFMs). These architectures advance beyond text-only models to digest interleaved multimodal data, incorporating audio, visual, and spatial inputs 37.
Satellite imagery is processed using computer vision and multimodal vision-language models to track retail foot traffic in parking lots, industrial production at manufacturing plants, and agricultural yields 2638. By blending satellite data of retail locations with anonymized credit card transaction data, quantitative funds can forecast consumer spending patterns and estimate corporate earnings weeks before official quarterly reports are published 263839.
MFFMs such as FinLLaVA and FinTral demonstrate strong performance in multimodal instruction tuning, utilizing datasets of image-text pairs to interpret complex financial tables, candlestick charts, and scatter plots 37. Furthermore, these models are employed to analyze audio from earnings conference calls and monetary policy conferences, synthesizing the textual transcript with the auditory tone and hesitation of executives to gauge hidden sentiment 3740. Climate data, including satellite imagery of cloud coverage and precipitation, is similarly integrated into commodity trading models to anticipate market uncertainties 37.
Construction of Relational and Knowledge Graphs
One of the most complex and potentially lucrative applications of LLMs in alternative data is the construction of knowledge graphs and social graphs to systematically map inter-corporate relationships. Traditional stock prediction models rely on static, predefined industry classifications (e.g., GICS frameworks) or manually curated knowledge bases that fail to capture dynamic supply chain dependencies, hidden competitor overlaps, and evolving strategic partnerships 11.
Zero-Shot Entity Extraction
LLMs address the limitations of static classifications through zero-shot entity extraction. The architectural workflow begins with the ingestion of unstructured text from news and financial filings. This raw data is processed by an LLM tasked with zero-shot entity extraction to formulate semantic triples - identifying entities and their relational edges. This output forms a dynamic knowledge graph, mapping structural dependencies such as 'Supplier_of' or 'Competitor_of', which is subsequently fed into a Graph Neural Network (GNN) to generate interconnected, relationship-aware alpha signals 111243.
The process typically relies on a comprehensive multi-relational taxonomy derived from datasets such as the S&P Global Business Relationship Dataset. The LLM is prompted to act as a financial analyst, systematically querying every pair of companies within a defined stock universe (e.g., the S&P 500) to identify specific ties and output the data in structured JSON format 11.
Because LLM-generated graphs can introduce noise or hallucinated connections, frameworks like GraphJudge have been developed to enhance data quality. GraphJudge utilizes an entity-centric strategy to eliminate noisy information in documents and fine-tunes an LLM specifically as a graph evaluator to verify the extracted knowledge 12. Additionally, connectivity-based pruning and thresholding are applied to discard relation types with insufficient edge counts, ensuring the resulting adjacency matrices serve as a stable structural backbone 11.
Graph Neural Network Integration
Once the knowledge graph is constructed, quantitative researchers apply Graph Neural Networks (GNNs) to learn node representations and predict asset price movements. Two primary architectures are commonly employed in this domain 11:
- Relational Graph Convolutional Networks (RGCN): These models apply relation-specific transformations using basis decomposition to aggregate neighborhood information across different relationship types, ensuring that a supplier relationship is weighted differently than a competitor relationship 11.
- Relational Graph Attention Networks (RGAT): These networks utilize relation-aware attention mechanisms to adaptively weight the influence of neighboring nodes based on the specific type of interaction and current market context 11.
By processing these graph representations alongside historical price data and technical indicators, trading algorithms can factor in the "spillover effect" - predicting how a supply chain disruption, regulatory fine, or sentiment shift affecting one company will immediately impact its suppliers and competitors. This method reformulates stock prediction as a "learning to rank" problem, optimizing a hybrid loss objective to output a predicted ordering of stocks that generates actionable trading signals, significantly enhancing Sharpe ratios and overall investment returns compared to traditional methods 11.
Pipeline Architecture and System Design
The architectural paradigm for LLM-integrated trading systems has matured from simple prompt-based querying via generic chatbots to highly structured, deterministic data pipelines. Because generative AI models introduce probabilistic behaviors - such as inconsistent formatting, variance across runs, and factual hallucinations - financial enterprises must implement rigorous engineering patterns to ensure reliability in production environments 4445.
The Map-Reduce-Align Pattern
To prevent LLMs from hallucinating, losing context over lengthy documents, or generating unstructured responses, enterprise trading pipelines frequently utilize a structured "Map-Reduce-Align" pattern 44. This architecture borrows concepts from distributed computing but applies them to reasoning control:
- Map (Extraction): Raw alternative data inputs are split into small, manageable chunks. The LLM processes each chunk independently using a constrained prompt and a predefined JSON schema. The objective at this stage is strictly to extract atomic, cited candidate statements (e.g., identifying isolated risk factors, blockers, or forward-looking statements in a 10-K filing) without attempting to synthesize a broader narrative 44.
- Reduce (Consolidation): The extracted candidates are aggregated and consolidated per section or theme, discarding irrelevant noise and combining duplicate insights 44.
- Align (Enforcement): The final output is rigorously checked against strict citation requirements, structural formats, and logical constraints to ensure the data is grounded in the source material and formatted correctly for the algorithmic trading engine or quantitative analyst 44.
This step-by-step approach systematically narrows the LLM's responsibility at each stage, separating the extraction of evidence from the synthesis of trading signals and drastically reducing the model's propensity to guess or hallucinate.
Retrieval-Augmented Generation and Vector Stores
Because pre-trained LLMs suffer from knowledge cutoffs and lack awareness of real-time market developments, financial pipelines depend heavily on Retrieval-Augmented Generation (RAG) 34. RAG systems convert real-time alternative data - such as breaking news, macroeconomic indicators, and recent corporate filings - into mathematical text embeddings, which are stored and indexed in specialized vector databases like Pinecone, Milvus, or ChromaDB 346.
When a trading algorithm requires context on a specific asset, the system queries the vector database for the most relevant historical and real-time data, passing it directly into the LLM's context window. This dynamically integrates external knowledge into the inference process, providing the model with up-to-the-minute factual grounding. This technique vastly improves the model's accuracy on domain-specific tasks, enables complex multi-hop reasoning across vast datasets, and serves as a primary defense against hallucinations 474849.
Continuous Integration for Probabilistic Models (LLMOps)
To safely deploy these pipelines, institutions are restructuring traditional software deployment methodologies into Continuous Integration and Continuous Deployment for LLMs (LLMOps) 45. In traditional MLOps, the focus is on optimizing metrics like accuracy through hyperparameter tuning. In LLMOps, the focus shifts to prompt engineering, RAG optimization, and balancing output quality against inference latency and API costs 45.
Enterprise LLMOps pipelines treat prompt templates, RAG parameters, and foundational model configurations as first-class code. When a change is made to an agent's logic or a data extraction schema, the pipeline triggers an automated evaluation run against a version-controlled "golden dataset" of historical financial scenarios 45. A separate, highly capable LLM acts as a judge, evaluating the new agent's output for semantic accuracy, alignment with risk tolerances, and reasoning quality. If the updated model hallucinates, violates predefined latency budgets (e.g., execution duration exceeding the 95th percentile limit), or breaches token expenditure parameters, the CI pipeline automatically turns red and blocks the deployment pull request 45. This multidimensional deployment gate ensures that only verified, safe models are permitted to interact with live market data.
Autonomous Multi-Agent Automation
The most significant advancement in LLM-based trading pipelines is the shift from utilizing models as passive feature extractors to deploying them as autonomous agents within sophisticated multi-agent systems (MAS) 250. In these frameworks, LLMs do not merely process data; they generate hypotheses, engage in structured debate, write execution code, and dynamically update their models in response to market feedback 25051.
Specialized Agent Roles
Enterprise-grade trading architectures utilize multi-agent orchestration to divide complex financial reasoning into specialized roles, mirroring the hierarchical structure of a traditional investment firm 2351. This structure typically involves the following specialized agents:
- Analyst Agents: These agents specialize in distinct data modalities and analytical approaches. A Fundamental Agent focuses on processing SEC filings and financial statements; a Sentiment Agent analyzes social media and news flow; and a Technical Agent interprets price-volume charts and momentum indicators 23.
- Manager / Debate Agents: The insights derived from various analyst agents are frequently contradictory. Multi-agent frameworks employ a "manager" agent to consolidate these disparate views. Through structured debate protocols and Chain-of-Thought (CoT) reasoning, the system self-critiques and refines the analysis, effectively mitigating the cognitive biases and logical inconsistencies that frequently plague single-prompt LLM outputs 2351.
- Trader / Execution Agents: Once a consensus is reached, the trader agent translates the insight into actionable investment signals (e.g., buy, sell, or hold decisions) and interfaces with order routing APIs to execute the trade, managing market impact and slippage 23.
- Risk Management Agents: Operating in parallel, these agents continuously assess the portfolio's exposure against predefined limits and the firm's overall risk tolerance. They act as automated circuit breakers, overriding trades that violate compliance parameters or exceed volatility thresholds 3.
Frameworks for Strategy Execution
Several prominent frameworks have emerged to structure these multi-agent interactions. The FINMEM architecture introduces a system that emulates human cognition by establishing a customized profiling module (defining the agent's professional background and risk inclination), a working memory for temporary data storage, and a layered long-term memory for retaining historical market insights 251.
Other platforms, such as FinRobot and Alpha-GPT, focus on automating the alpha research stage. These agents propose novel factor ideas, refine them based on human-AI interactive dialogues, and generate executable Python code to backtest and implement the strategies 23. The InvestorBench framework provides a standardized methodology to evaluate these diverse agents across perception, profiling, memory, and action modules 2.
Reinforcement Learning and Optimization
To bridge the gap between qualitative text analysis and quantitative asset allocation, researchers are combining LLM agents with Deep Reinforcement Learning (DRL) algorithms. While LLMs excel at understanding market context and estimating the magnitude of potential stock price fluctuations, they occasionally struggle with precise directional forecasting 5213.
To resolve this, frameworks utilize algorithms like Proximal Policy Optimization (PPO). The LLM generates initial return predictions based on news sentiment and alternative data, and the reinforcement learning agent then dynamically allocates portfolio weights. The RL agent adjusts the strategy based on real-time market feedback and financial risk metrics, such as Value at Risk (VaR) and Conditional Value at Risk (CVaR) 5213. Experimental results indicate that this synergistic combination - LLM-generated signals refined by adaptive DRL optimization - yields highly stable risk-adjusted performance, superior Sharpe ratios, and smaller maximum drawdowns compared to baseline momentum or equal-weighted approaches 52.
Systemic Risks and Market Microstructure Implications
The integration of agentic AI into live trading environments introduces unprecedented operational vulnerabilities and systemic risks. As these models transition from assisting human analysts to executing trades autonomously, financial institutions and regulatory bodies are demanding increasingly stringent governance frameworks 5014.
Model Hallucination and Risk Management
A primary operational concern is the "hallucination problem," wherein an LLM generates plausible-sounding but factually incorrect analysis - fabricating data, asserting false causal relationships, or displaying unwarranted overconfidence in its predictions 2512. Because financial markets possess an inherently low signal-to-noise ratio, relying on fabricated sentiment or mischaracterized supply chain data can lead to catastrophic capital misallocation 37. Industry consensus holds that no standalone model currently achieves error rates low enough for unsupervised use in professional finance applications, necessitating hybrid approaches and continuous verification 15.
Regulators in jurisdictions like Hong Kong have proactively addressed this model risk. The Securities and Futures Commission (SFC) classifies the use of AI for investment recommendations, advice, and research as "high risk" activities 565758. For these high-risk use cases, licensed corporations are mandated to continuously monitor model performance, implement robust cybersecurity controls against adversarial testing, and enforce a strict "human-in-the-loop" approach to review all AI-generated output before any trading outcome is actioned 565758. Systems utilizing algorithmic trading must include pre-trade controls, comprehensive audit trails, and circuit breakers that automatically suspend trading when predefined risk thresholds are breached 59.
Algorithmic Herding and Financial Stability
Furthermore, as autonomous LLM agents become widespread, they pose a potential systemic risk to market microstructure and global financial stability. In academic simulations tracking financial theories with LLM agents, models processing alternative data demonstrated the ability to discover pricing inefficiencies, provide strategic liquidity, and generate outsized returns (up to 3000% in controlled, simulated environments) 50.
However, the International Monetary Fund (IMF) and industry analysts have warned that if multiple quantitative funds deploy similarly trained LLM agents reacting to the same alternative data signals, the resulting algorithmic herding could drive asset correlations to extremes 5014. This uniform reaction to unstructured data could increase market turnover, amplify volatility, and trigger rapid algorithmic flash crashes 14. The IMF also notes that the high fixed costs associated with developing and deploying these advanced AI architectures may lead to disparate speeds of adoption, potentially creating fragmentation risks where emerging markets are less able to benefit from AI-driven liquidity than advanced economies 14.
Ultimately, the successful integration of alternative data into LLM trading pipelines relies not merely on the sophistication of the foundational models, but on the rigor of the data engineering, the robustness of the multi-agent debate structures, and the unyielding discipline of the associated regulatory and risk management frameworks.