Retrieval-Augmented Generation for Financial Market Research
Retrieval-augmented generation profoundly alters how large language models process and synthesize financial intelligence. The architecture transitions artificial intelligence from a reliance on static parametric memory to dynamic, evidence-grounded inference 113. In quantitative finance, where alpha generation relies on rapid, error-free analysis of unstructured data, the probabilistic nature of standalone large language models introduces unacceptable risks, primarily through factual confabulations and outdated data representations 142. By decoupling the analytical engine from the knowledge repository, retrieval-augmented generation allows financial institutions to query real-time market data, regulatory filings, and macroeconomic indicators while maintaining a verifiable audit trail 267.
Applying baseline retrieval pipelines to financial markets introduces severe structural and temporal vulnerabilities 289. Capital markets operate on continuous numerical sequences, highly fragmented regulatory language, and dense tabular data - modalities that standard semantic text splitters systematically destroy 210. Furthermore, quantitative backtesting relies on strict temporal isolation to prevent look-ahead bias, a requirement that standard vector retrieval mechanisms violate by inherently favoring the most recently updated documents over point-in-time facts 91112. The deployment of retrieval-augmented generation in event-driven trading and systemic risk analysis requires advanced domain adaptations, including graph-based relational retrieval, bitemporal data indexing, and multi-agent coordination frameworks 68133.
Fundamentals of Financial Information Retrieval
The standard pipeline operates through a discrete sequence of data ingestion, embedding, indexing, retrieval, and generation 115. Documents are parsed and segmented into semantically coherent chunks, which are then processed by transformer-based embedding models to create high-dimensional vector representations 13. These vectors are stored in optimized databases that facilitate rapid similarity searches using metrics such as cosine similarity or Euclidean distance 1116. When a query is initiated, the system retrieves the nearest neighbors and augments the model prompt with this external context, forcing the system to generate a response grounded exclusively in the retrieved data 117.
While this architecture performs adequately for basic enterprise knowledge retrieval, it exhibits critical failure modes in quantitative finance 2. Financial filings, such as Form 10-K and 8-K reports, consist of highly structured, homogeneous text interspersed with dense numerical tables 1018. Naive character-based chunking truncates tabular structures, divorcing numerical values from their column headers and row stubs 2. Benchmarks measuring financial document extraction demonstrate that standard text retrieval accuracy can drop from over 90% on narrative text to below 45% when applied to tabular evaluation tasks 2.
Multimodal and Structural Synthesis
To resolve formatting constraints, modern financial pipelines utilize structural and semantic parsing 1. Optical character recognition systems and vision-language models process portable document formats into hierarchical markdown files, preserving section headers, parent-child relationships, and table boundaries 110. Instead of fixed-size chunks, the data is segmented based on logical headers, allowing the retrieval mechanism to process tables as indivisible, atomic units 19. Furthermore, metadata - such as publication dates, ticker symbols, and document types - is extracted and attached to each chunk, enabling hybrid retrieval strategies that combine dense vector search with sparse keyword matching and exact metadata filtering 34204.
To extract actionable intelligence from these documents, advanced pipelines have adopted multimodal frameworks 104. Architectures such as MultiFinRAG intercept tables and figures during the ingestion phase and route them to lightweight vision-language models 10. These models analyze the visual structure and generate structured JavaScript Object Notation representations alongside natural-language summaries of the underlying numerical trends 10. These generated summaries are then embedded and indexed in the vector database with modality-specific similarity thresholds 10.
During retrieval, tiered fallback strategies allow the system to initially search text contexts and dynamically escalate to retrieving charts and tabular data if the text alone fails to answer complex quantitative queries 10. Implementations of MultiFinRAG utilizing the Gemma 3 model demonstrate a total accuracy of 75.3% on complex financial queries involving mixed media, significantly outperforming baseline models operating without multimodal capabilities 10. Text-specific accuracy reaches 90.4%, while table-based accuracy hits 69.4%, demonstrating the viability of structural chunking 10.
Architectural Alternatives and System Economics
Organizations deploying generative artificial intelligence for market research face an architectural decision between retrieval-augmented generation and model fine-tuning 12223. Fine-tuning involves updating the internal weights of a large language model using a curated dataset, allowing the model to internalize specific analytical patterns, formatting constraints, and domain expertise 22.
Retrieval augmentation is fundamentally optimized for environments characterized by high data volatility 22. Financial analysts require access to live earnings transcripts, breaking macroeconomic news, and real-time pricing - information that changes minute by minute 24. A retrieval system incorporates this data instantly by updating the vector database, without requiring the computationally expensive retraining of the foundation model 3623. Conversely, fine-tuning effectively locks knowledge at the specific point in time the training concludes, rendering it unsuitable for tasks requiring high temporal freshness 12526.
Operational Latency and Token Overhead
Retrieval systems introduce significant operational costs and latency penalties at scale 2227. Injecting retrieved context into a prompt dramatically inflates token consumption. A base prompt of fifteen tokens can expand to over five hundred tokens when populated with relevant document chunks, resulting in recurring inference costs that scale linearly with query volume 162227.
Furthermore, the retrieval process adds a computational bottleneck. Independent benchmarking reveals that retrieval mechanisms can account for approximately 41% of end-to-end pipeline latency, effectively precluding standard implementations from high-frequency execution environments 1623. Fine-tuning requires a substantial upfront investment - often requiring hundreds of hours of data preparation and specialized compute resources - but yields a lower operational cost per query, as it requires minimal context injection to generate accurate responses 2728.
| Architecture Strategy | Primary Advantage | Upfront Implementation Cost | Recurring Operational Cost | Inference Latency | Data Mutability |
|---|---|---|---|---|---|
| Retrieval-Augmented Generation | Real-time data freshness and verifiable source citations. | Moderate (Database setup, embedding pipeline, orchestration). | High per-query (Token bloat from context injection). | High (150-500ms retrieval plus generation overhead). | Immediate (Update vector database without model retraining). |
| Model Fine-Tuning | Low inference latency and deep internalization of domain patterns. | High (Data curation, graphics processing unit training cycles). | Low per-query (Minimal context required; smaller prompts). | Low (100-300ms generation without retrieval steps). | Static (Requires complete retraining cycle to update facts). |
| Hybrid Implementation | Combines dynamic knowledge retrieval with optimized task-specific behavior. | Very High (Requires both training pipeline and retrieval infrastructure). | Moderate (Balanced context sizes processed by optimized models). | Moderate to High (Dependent on retrieval pipeline complexity). | Immediate (Facts updated via retrieval, base behavior remains static). |
Hybrid Implementations
For tasks exhibiting low knowledge volatility but requiring high-volume execution, such as structured entity extraction from standard regulatory forms, fine-tuning presents a more economical long-term profile 2228. Consequently, financial institutions increasingly rely on hybrid architectures 22. In these systems, a highly efficient language model is fine-tuned specifically to comprehend financial terminology and execute complex logical evaluations 2930. At inference time, this specialized model is augmented with a streamlined retrieval pipeline that supplies the necessary real-time facts 2229.
Empirical studies demonstrate that hybrid systems consistently outperform both standalone fine-tuning and vanilla retrieval architectures 22. For example, the introduction of the FinSrag framework pairs a fine-tuned, 1-billion-parameter language model (StockLLM) with a specialized retriever (FinSeer) 30. The retriever utilizes a similarity-driven training objective to align queries with historically influential financial sequences, successfully capturing temporal dependencies essential for precise market prediction and outperforming purely textual or distance-based baselines 30. Similarly, when applied to financial sentiment analysis, retrieval-augmented models exhibit a 15% to 48% performance gain over traditional models like FinBERT, significantly improving both accuracy and F1 scores 29.
Temporal Integrity and Look-Ahead Bias Mitigation
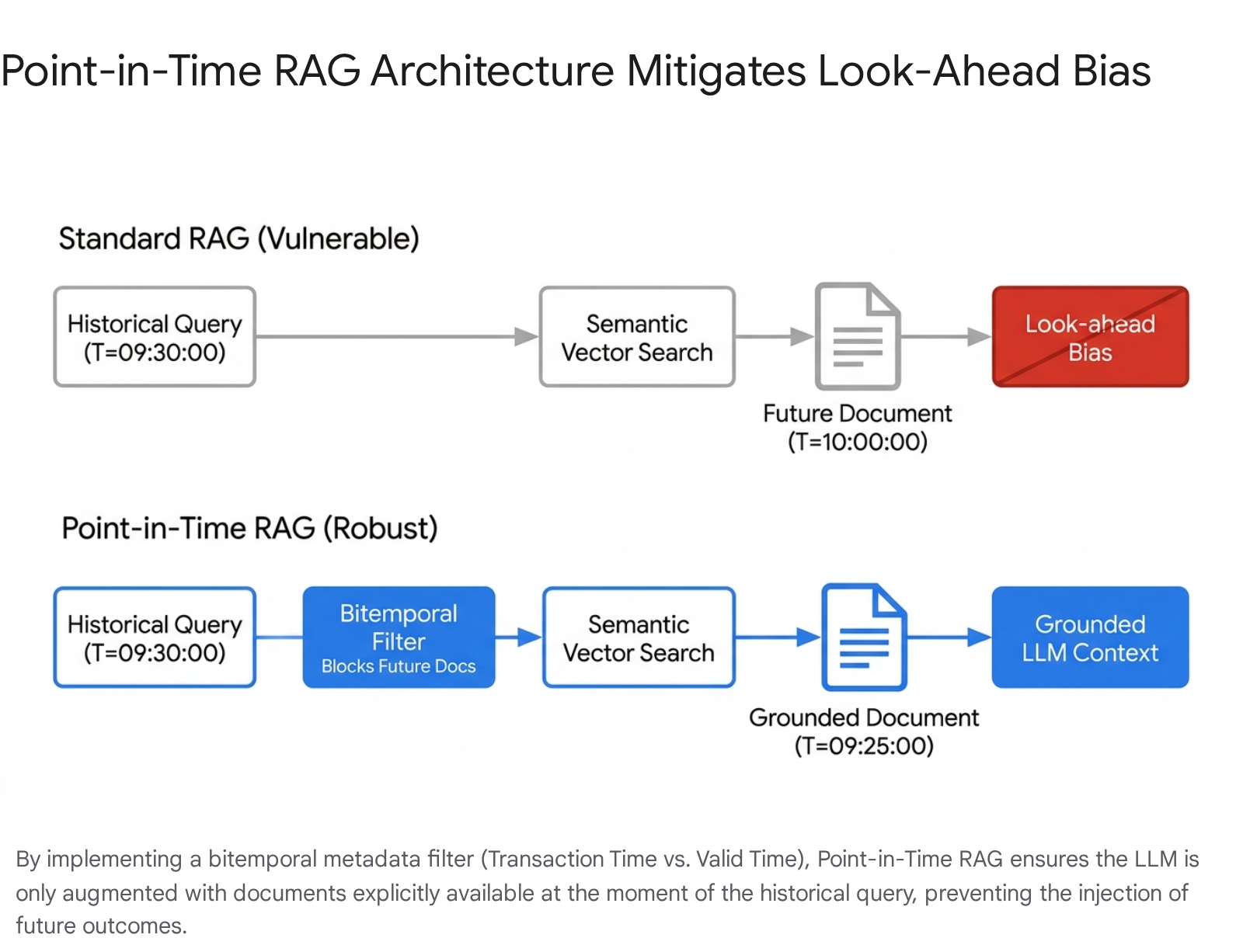
A foundational vulnerability in deploying these systems for quantitative finance involves the integrity of the temporal context 911. In standard applications, retrieval is designed to surface the most semantically relevant and up-to-date information 315. While beneficial for general search, this behavior is catastrophic when backtesting event-driven trading strategies or conducting historical market simulations 911.
Mechanics of Temporal Hallucination
Look-ahead bias occurs when a predictive model utilizes information that would not have been available at the exact moment a historical decision was simulated 91231. This is a severe methodological failure that systematically inflates backtested returns 9. Large language models exacerbate this risk because their pre-training corpora inherently contain future outcomes of past events 631. Even when base models are subjected to strict point-in-time pre-training, standard retrieval pipelines reintroduce look-ahead bias through unstructured data fetching 69.
When an autonomous trading agent queries a vector database to evaluate market conditions on a specific historical date, a standard semantic search will prioritize relevance over temporal boundaries 912. The system may retrieve a revised corporate filing issued two weeks after the event, an analyst report summarizing the eventual market recovery, or subsequent news articles detailing the long-term impact 9. By providing the model with hindsight disguised as context, the pipeline induces a temporal hallucination 9. The model generates a highly accurate but procedurally invalid response, reacting to data it mathematically should not possess 9.
Bitemporal Data Architecture
To conduct rigorous financial research, infrastructure must enforce point-in-time textual alignment 1232. This requires migrating from uni-temporal vector stores, which only recognize the current state of a document, to bitemporal modeling 33. A bitemporal context graph tracks two distinct chronologies: valid time, which notes the period during which a fact was true in the real world, and transaction time, which notes the exact millisecond the data was recorded and made accessible in the database 33.
In this framework, every query is anchored to a specific historical timestamp 1112. The retrieval engine applies a hard metadata filter, discarding any embedding with a transaction timestamp subsequent to the query's anchor time, regardless of its semantic similarity 9.
For example, in streaming event processing, architectures utilizing tools like Apache Flink apply event-time watermark strategies, explicitly handling out-of-order data and establishing strict lateness windows - often limited to thirty seconds - to ensure features generated for trading models reflect network realities rather than theoretical perfection 11.
Advanced event-driven pipelines further decouple retrieval from static text by incorporating external Bayesian source memory 325. Rather than ranking evidence solely by textual relevance, these adaptive systems track the historical utility of specific document types, dynamically assessing whether current filings or news headlines yield more accurate residual-return predictions for specific event categories 32. As market outcomes mature, the Bayesian memory updates the utility weights of these source families 32. During inference, the language model acts as a frozen reader, while the retrieval layer dynamically selects evidence based on demonstrated predictive power, significantly enhancing the downstream portfolio Sharpe ratio from 0.52 to 0.84 compared to static retrieval methods 32.
Knowledge Graphs and Systemic Contagion
Traditional vector-based retrieval relies fundamentally on dense embeddings and nearest neighbor similarity 12. It extracts isolated chunks of text that mathematically align with the query's phrasing 113. While highly efficient for direct question-answering, vector search is structurally blind to global relationships 1335. When attempting to assess macroeconomic themes, trace corporate ownership structures, or identify supply chain dependencies, standard retrieval yields fragmented, disjointed context 213.
Overcoming Vector Limitations
Graph-based retrieval addresses these limitations by substituting flat vector databases with highly structured knowledge graphs 213356. During the ingestion phase, specialized models analyze the document corpus to extract distinct entities such as corporations, executives, regulatory bodies, and physical commodities, and explicitly map the relationships between them 133537. These relationships form the nodes and edges of an interconnected graph 1338.
The primary advantage of graph networks in financial research is their capacity for multi-hop logical deduction 353940. Analysts frequently pose complex queries that require synthesizing information across dozens of separate documents 639. For instance, determining the secondary market exposure of a semiconductor manufacturer requires identifying direct suppliers, mapping those suppliers to specific raw materials, and cross-referencing those materials with geopolitical risk reports 397.
When queried, the system translates natural language into graph traversal algorithms 13. It anchors onto the primary entity and traverses the edges to retrieve connected subgraphs, capturing both immediate dependencies and distant hierarchical relationships 13. Modern implementations utilize community detection algorithms to group related entities into conceptual clusters, generating hierarchical summaries of entire market sectors 242. Techniques such as HippoRAG employ PageRank-based random walk strategies across the knowledge graph, simulating associative human recall to uncover hidden semantic connections that standard cosine similarity would overlook 42.
Modeling Market Contagion
The ability to map explicit relationships makes graph networks uniquely suited for modeling systemic risk and financial contagion 13844. Traditional econometric models often treat assets independently or rely on static correlation matrices, severely understating tail risk during periods of market stress 844. Historical crises demonstrate that risk propagates through multidimensional channels involving credit exposures, overlapping portfolios, and information cascades 8.
By representing the financial system as a dynamic knowledge graph, systems can track evolving interdependencies 89. Nodes representing banking institutions, clearinghouses, and cryptocurrency exchanges are connected by weighted edges representing exposure levels 844. As new regulatory communications, filings, and news articles are ingested, the textual signals are semantically aligned with the network evolution, dynamically updating the edge weights 13844.
When assessing the potential fallout from a localized default, the retrieval engine does not merely search for articles mentioning the defaulted entity; it extracts the entire affected network topology 13. It identifies second- and third-order exposures - entities that may not hold direct debt but are critically dependent on shared liquidity providers 388. Empirical validation indicates that dynamic graph-based risk models, when coupled with semantic data processing, improve predictive accuracy by 19.2% and provide earlier warnings of systemic stress by up to 2.7 months compared to traditional actuarial approaches 8. Furthermore, compliance graphs leverage this structure to map regulatory requirements directly to internal policies and technical enforcement controls, automatically flagging coverage gaps and ensuring audit readiness 38.
Cross-Border Regulatory Processing
The complexity of global market research demands systems capable of synthesizing vast repositories of non-textual and non-English financial disclosures 10184610. The proliferation of stringent environmental, social, and governance reporting requirements compels thousands of global enterprises to publish dense, multifaceted regulatory reports 484911.
European Sustainability Reporting Standards
The implementation of the Corporate Sustainability Reporting Directive across the European Union radically expands the volume of required disclosures 484912. The directive applies not only to entities headquartered within the region but also to non-EU global groups generating minimum revenue thresholds within the jurisdiction 491113. These mandates enforce detailed reporting on how corporate activities impact environmental metrics and how sustainability factors affect cash flows, utilizing a principle of double materiality 13.
The sheer volume of these unstructured, multi-jurisdictional reports makes manual extraction resource-intensive and error-prone 48. Specialized processing pipelines generate question-and-answer pairs from sustainability reports by integrating semantic chunk classification and table-to-paragraph transformations 48. However, structurally homogeneous corpora - where hundreds of filings share identical boilerplate legal phrasing - cause severe cross-document chunk confusion 18. A query targeting one entity's risk factors may inadvertently retrieve another entity's disclosures due to overwhelming semantic overlap in the regulatory language 18.
Hybrid Document-Routed Retrieval resolves this precision trade-off 18. Rather than searching the entire database globally, this protocol utilizes a language model to perform semantic file routing, first identifying the specific documents relevant to the query, and subsequently restricting the chunk-level similarity search exclusively to the boundaries of those identified files 18. Controlled evaluations indicate this routing architecture achieves an average score of 7.54 across complex benchmark queries, significantly lowering failure rates and increasing perfect-answer precision over standard chunk-based retrieval 18.
Multilingual Semantic Alignment
Event-driven trading strategies routinely exploit pricing inefficiencies across international borders, necessitating the rapid analysis of non-English regulatory filings, central bank statements, and local press releases 461014. Constructing multilingual processing pipelines introduces complex architectural decisions regarding tokenization, translation, and semantic alignment 4610.
Translating all foreign-language documents into a primary language prior to indexing standardizes the dataset but introduces fatal failure modes in legal and financial contexts 4610. Precise phrasing, statutory definitions, and nuanced regulatory terminology must be preserved immutably, as a subtle mistranslation of a regulatory provision can entirely invalidate an event-driven thesis 46.
Robust architectures employ cross-language information retrieval utilizing natively multilingual embedding models 4610. Documents are indexed in their original languages, allowing the high-dimensional vector space to capture semantic similarities across linguistic boundaries 4610. A system can process a query in one language and retrieve the relevant passages in another based on vector proximity without relying on intermediate translation layers 4610. For highly precise legal queries, sparse vector mechanisms are combined with dense embeddings, ensuring that both cross-lingual semantic concepts and exact local legal terms are accurately retrieved 46.
Safety Guardrails and Hallucination Reduction
While external data retrieval was initially championed as the definitive solution to model hallucinations, empirical deployment in capital markets reveals that augmenting generation merely alters the mechanism of hallucination rather than eradicating it 491554. Probabilistic models carry an inherent reliability ceiling; when confronted with retrieved text, an algorithm may misinterpret a numerical table, conflate adjacent concepts, or generate a syntactically perfect but factually fabricated aggregation 454.
In financial analytics, these errors are particularly insidious. A fabricated revenue figure that matches formatting expectations and falls within standard deviation limits triggers no immediate suspicion, seamlessly integrating into downward decision chains and resulting in mispriced risk or unauthorized execution 54. Furthermore, enterprise deployment introduces strict compliance mandates; producing a trading recommendation without verifiable attribution is an actionable regulatory violation 267.
Amplified Risks in Context Injection
Counterintuitively, the very mechanism that powers retrieval systems - the automated injection of external context - can increase a model's susceptibility to unsafe or erratic behavior 1516. Research evaluating the safety profiles of state-of-the-art foundation models reveals that systems exhibiting high safety alignments in isolated testing become markedly more vulnerable when integrated into retrieval pipelines 1516.
Testing conducted by financial engineering teams utilizing thousands of targeted queries demonstrated large increases in unsafe responses when operating with retrieved context 1516. If the retrieval mechanism surfaces documents containing adversarial prompts, highly biased sentiment, or logically flawed financial data, the model is explicitly instructed by its system prompt to ground its response in that retrieved text 41516. Consequently, the model's internal safety guardrails are overridden by its directive to comply with the provided context 1516. This highlights the critical reality that the pipeline is only as reliable as its retrieval precision and the sanitization of its underlying document store 457.
Neurosymbolic Verification
Mitigating these systemic risks requires a defensive architecture that extends far beyond baseline prompt engineering 458. High-stakes enterprise environments implement a trade-off triangle balancing accuracy, latency, and operational cost, deploying specific guardrails calibrated to the use case's risk tier 5859.
| Mitigation Technique | Implementation Layer | Hallucination Reduction Potential | Latency Overhead | Primary Trade-off |
|---|---|---|---|---|
| Hybrid Document Retrieval | Data Ingestion & Search | 35% - 60% | 50ms - 150ms | Requires highly optimized vector databases; increases infrastructure complexity. |
| Provenance Tracking & Citations | Prompt Generation | 40% - 65% | 10ms - 50ms | Increases token consumption; models may still misinterpret cited text. |
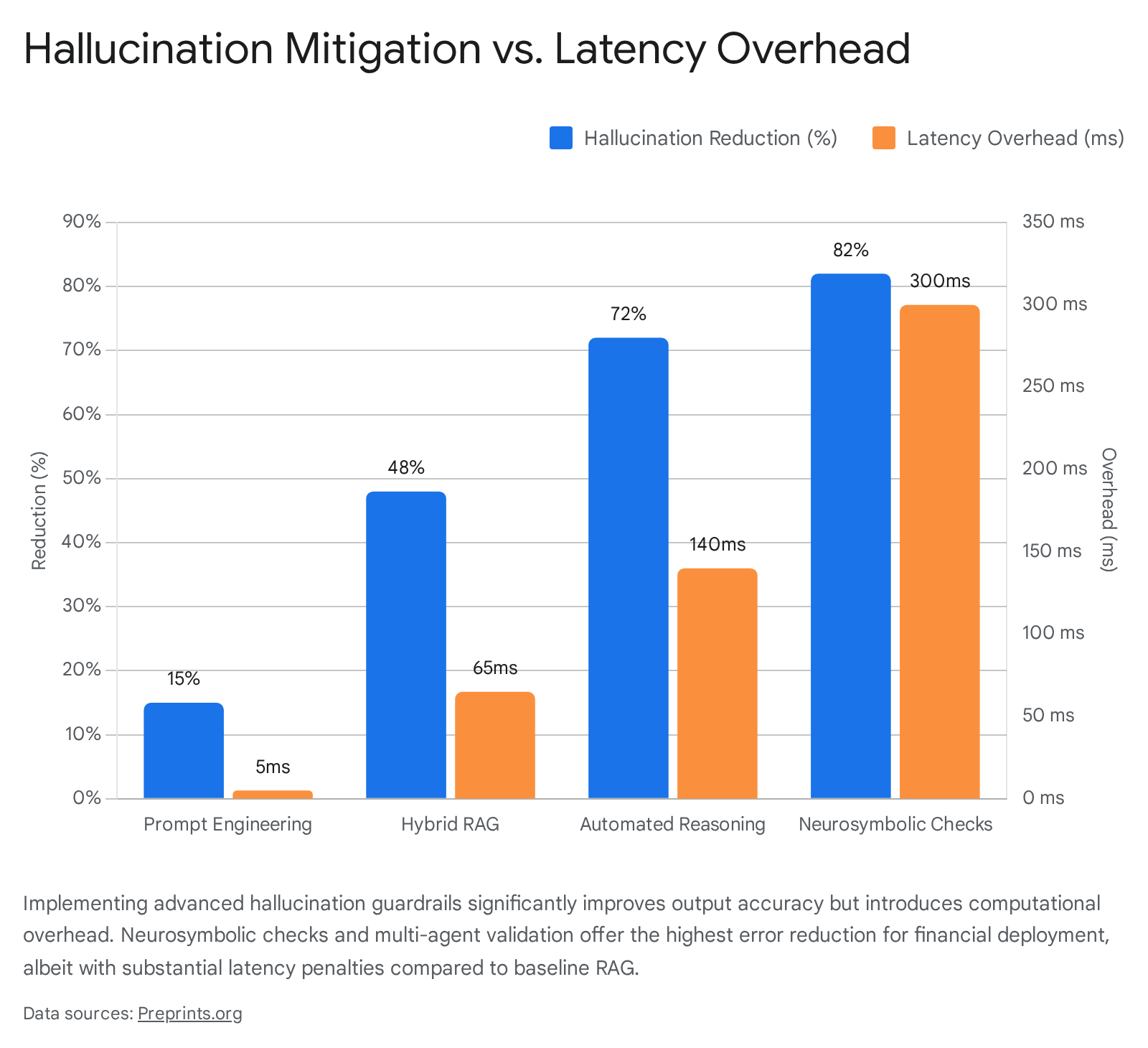
| Automated Reasoning Checks | Post-Generation Output | 70% - 82% | 140ms - 300ms | Substantial latency penalty; unsuitable for high-frequency trading execution. |
| Neurosymbolic Validation | Multi-Agent Orchestration | 85% - 95% | 200ms+ | Highest computational cost; requires complex state management and validation loops. |
At the foundational level, hybrid retrieval combining dense vector search and sparse matching prevents the model from attempting to extrapolate patterns from irrelevant data 4. Cross-encoder re-rankers are applied to the retrieved context to filter out marginal results, drastically narrowing the factual universe the model must process 460. During generation, the system enforces strict provenance tracking 59. The architecture is constrained to generate explicit citations linking every factual assertion to a specific source document identifier 17. If the model is unable to ground an answer, abstention thresholds are triggered, compelling the model to refuse the query rather than confabulate a response 2058.
Before the response reaches the user or execution engine, secondary automated reasoning checks or neurosymbolic frameworks independently evaluate the output against the retrieved context to detect factual inconsistencies or logic drift 5859. While these layers reduce error rates by up to 82%, they incur heavy computational overhead, potentially adding up to 300 milliseconds of latency per query, thereby forcing quantitative trading desks to carefully balance execution speed against safety 59.
Multi-Agent Financial Architectures
The operational paradigm is evolving from a static, single-turn retrieval mechanism into autonomous, multi-agent workflows 861. Traditional monolithic prompts struggle to simultaneously execute macroeconomic identification, earnings quality assessment, and mathematical risk modeling within a single evaluation cycle 31. Modern implementations deconstruct these complex workflows, distributing the analytical load across cooperating, role-specific agents 319.
Autonomous Workflows
In an agentic financial architecture, user queries are not routed directly to a vector database 8. Instead, a gatekeeping protocol intercepts the request, testing for ambiguity and decomposing complex financial questions into a sequence of executable sub-tasks 819.
A prompt analyzing semiconductor headwinds and revenue impact is routed to specialized sub-agents 19. A librarian agent queries internal policy databases using semantic search; an analyst agent executes database queries to retrieve point-in-time pricing data from structured arrays; and a scouting agent interacts with live application programming interfaces for breaking news 1962. These agents utilize iterative retrieval, evaluating the context they uncover, identifying gaps, and reformulating their queries dynamically until sufficient evidence is amassed 8.
This architecture allows for sophisticated stress testing and contextual nuance 362. Frameworks such as Context-Enriched Agentic RAG deploy distinct personas to evaluate the same dataset 3. A historical performance agent assesses trajectory, while a secondary agent intentionally scans retrieved risk disclosures to highlight regulatory headwinds, counterbalancing the narrative bias often found in corporate guidance 362. Finally, an auditor agent synthesizes the outputs, checking for logical consistency across the deduction chains before authorizing the final investment summary 19.
Institutional Deployment
The integration of autonomous retrieval is actively reshaping institutional quantitative research operations 176418. Advanced quantitative funds, including Two Sigma, Citadel, and D.E. Shaw, increasingly rely on deep learning, machine learning pipelines, and natural language processing to extract market signals from unstructured global financial reports and alternative data 1764666768. Statistical arbitrage strategies process vast repositories of earnings transcripts, supply chain logistics, and alternative datasets to forecast asset prices, requiring highly optimized data ingestion engines capable of discerning subtle market shifts 176466.
Standardized Evaluation and Benchmarking
Validating the efficacy of these advanced architectures requires rigorous evaluation protocols that extend beyond basic accuracy measurements 3218. Assessing financial retrieval systems involves tracking precision and recall while simultaneously measuring their impact on downstream economic outcomes 3161.
Institutional Competitions
Academic and industry platforms heavily emphasize the creation of standardized testing frameworks. The ACM-ICAIF FinanceRAG Challenge tasks participants with building systems capable of accurately retrieving relevant contexts from vast collections of financial documents, addressing specific hurdles like financial terminology, numerical data extraction, and abbreviation handling 326970. The primary metric utilized to evaluate the retrieval process is Normalized Discounted Cumulative Gain, which measures the ranking quality of the returned search results against an ideal ranking of relevant documents 7071.
Datasets utilized in these evaluations, such as FinDER, FinanceBench, and TATQA, specifically test a model's capacity for multi-step mathematical reasoning, detecting factual inconsistencies in Form 10-K reports, and answering complex conversational queries based on earnings transcripts 41920. Empirical evaluations show that while agent-driven retrieval introduces significant latency - often processing for several seconds per query compared to sub-second responses in baseline setups - the gains in analytical precision are substantial 816. By forcing systems to plan, traverse structured knowledge graphs, and cross-reference data sources, these architectures dramatically reduce catastrophic evaluation failures and align automated market impact predictions more closely with professional financial scrutiny 8318.