Time-series foundation models for zero-shot financial trading
Fundamental Architectural Shifts in Time-Series Forecasting
The advent of the large language model (LLM) paradigm has catalyzed a corresponding architectural shift in the analysis of sequential numerical data, leading to the emergence of Time-Series Foundation Models (TSFMs). Traditionally, financial time-series forecasting relied on localized, task-specific architectures - ranging from classical econometric approaches like Autoregressive Integrated Moving Average (ARIMA) and Generalized Autoregressive Conditional Heteroskedasticity (GARCH) to specialized deep learning models such as Long Short-Term Memory (LSTM) networks and temporal convolutional networks 12. These traditional models require bespoke feature engineering, strict stationarity assumptions, and independent parameter estimation for every new instrument or dataset analyzed 23.
TSFMs fundamentally alter this modeling paradigm. Built primarily on transformer-based architectures utilizing either encoder-decoder or decoder-only configurations, these models are pre-trained on massive, heterogeneous corpora of temporal data. The training sets span highly diverse domains, including server observability metrics, retail demand curves, meteorological data, and financial sequences 445. The objective of this large-scale pre-training is to induce a universal representation of temporal dynamics, encompassing multi-frequency seasonality, trend components, volatility clustering, and cross-variable interactions 24.
Once pre-trained, TSFMs offer zero-shot forecasting capabilities - the ability to ingest previously unseen historical context windows and output accurate deterministic or probabilistic forecasts without any task-specific parameter updates or domain-specific fine-tuning 247. For quantitative finance, the theoretical appeal of zero-shot TSFMs is profound. If a single pre-trained network can accurately generalize across diverse asset classes, market regimes, and sampling frequencies, it could radically streamline algorithmic strategy development, risk modeling, and alpha generation 2.
Categorization of TSFM Architectures
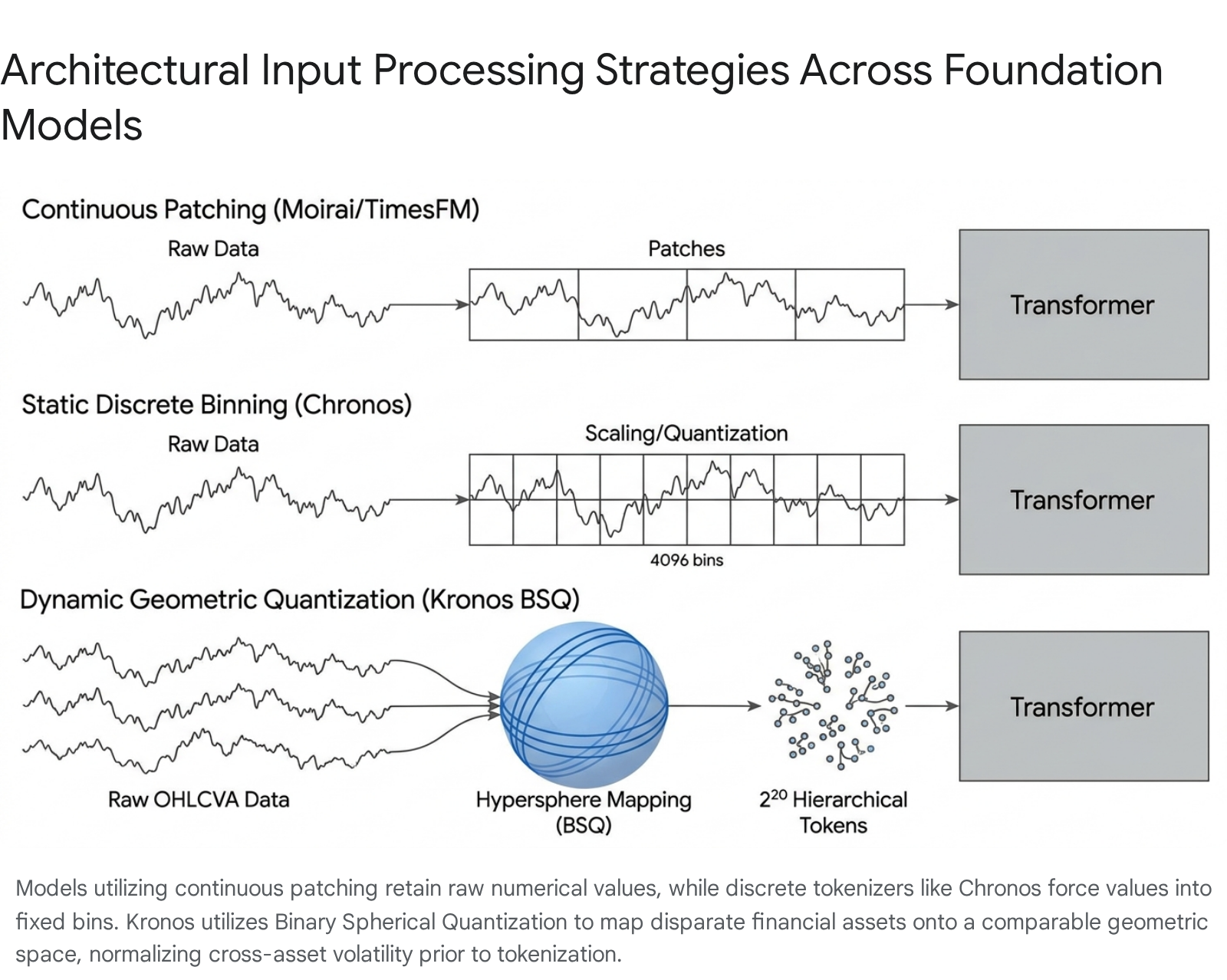
The TSFM ecosystem is currently divided by two primary design philosophies concerning how continuous numerical time-series data is ingested by transformer attention mechanisms. The first approach attempts to adapt existing NLP architectures by discretizing numerical values into fixed tokens. The second approach maintains the continuous nature of numerical data, utilizing patch-based sequence representations and specialized regression heads 89.
Continuous Patching and Embedding Models
Google Research's TimesFM is a decoder-only transformer pre-trained on an estimated 100 billion real-world time points sourced from platforms like Google Trends and Wikipedia 210. Operating with parameter counts of 200 million and 500 million, TimesFM utilizes a patch-based continuous representation rather than discrete tokenization. It generates point forecasts alongside quantiles directly via an autoregressive pass 1011. While the first iteration was restricted to a 512-point context, TimesFM 2.0 extended this capability to 2048 time points 11. The model exhibits competitive zero-shot performance across standard cross-domain benchmarks, establishing itself as an enterprise baseline for large-scale deterministic forecasting 11.
Salesforce's Moirai (Universal Time-Series Forecaster) differentiates itself through a mechanism termed "Any-Variate Attention." Unlike models restricted to univariate inputs, Moirai dynamically adjusts to multivariate time series without requiring fixed input dimensions, allowing it to process complex covariate relationships 12. It utilizes a patch-based encoder-decoder architecture and was trained on the LOTSA dataset, a massive corpus of 27 billion observations spanning nine domains 1213. Moirai approaches forecasting as a mixture distribution problem, outputting parameters for flexible distributions (such as Normal, Student-T, and Negative Binomial) to capture diverse data geometries 11. Available in checkpoints of 14M, 91M, and 311M parameters, Moirai supports extended context windows of up to 5,000 time steps 11.
Discrete Tokenization Models
Amazon's Chronos family represents a direct translation of time-series forecasting into an NLP sequence-to-sequence task. Built on the T5 encoder-decoder architecture, Chronos discretizes real-valued time-series data into a fixed vocabulary of 4,096 tokens through scaling and absolute binning quantization 91114. The model is trained utilizing standard cross-entropy loss to predict the next token in the sequence. To produce forecasts, Chronos autoregressively samples multiple future trajectories, natively yielding probabilistic Monte Carlo distributions 146.
The original Chronos-T5 models scale from 8 million parameters (Tiny) up to 710 million parameters (Large) 1116. However, the token-by-token autoregressive generation process creates a strict computational bottleneck, limiting the context window to 512 tokens 177. To address this latency, Amazon subsequently released the Chronos-Bolt family (ranging from 9M to 205M parameters), which abandons step-by-step rollout in favor of direct multi-step quantile prediction over patched historical data. This methodology makes Chronos-Bolt up to 250 times faster and 20 times more memory-efficient than Chronos-T5, while delivering marginally improved zero-shot accuracy 11148.
Univariate Models with Specialized Covariates
Lag-Llama adapts the open-source LLaMA text architecture into a decoder-only foundation model explicitly designed for univariate probabilistic forecasting 12910. With an exceptionally lean parameter count of 2.5 million, Lag-Llama diverges from continuous patching by leveraging engineered lag features (e.g., past daily, weekly, or yearly values) alongside temporal datetime covariates 1011. Trained on 352 million time windows, it utilizes a distribution head to output the parameters of a Student's t-distribution, ensuring robust uncertainty quantification 1011.
TimeGPT, developed by Nixtla, is one of the earliest purpose-built foundation models for time series, trained on a proprietary corpus exceeding 100 billion data points 42312. Because it is a closed-source, API-gated model, its exact parameter count and detailed pre-training distribution remain undisclosed 2325. Utilizing an encoder-decoder architecture, TimeGPT detects long-term dependencies and outputs future trajectories alongside non-parametric confidence intervals based on conformal prediction frameworks 71314. It achieves rapid inference speeds of approximately 0.6 milliseconds per series on GPU hardware, making it suitable for high-throughput enterprise pipelines 25.
| Model Family | Architectural Base | Parameter Scale | Input Tokenization Strategy | Context Window | Output Paradigm |
|---|---|---|---|---|---|
| Chronos-T5 | T5 Encoder-Decoder | 8M - 710M | Discrete bins (4,096 vocab) | 512 steps | Probabilistic (Monte Carlo) |
| Chronos-Bolt | Distilled T5 | 9M - 205M | Patched multi-quantile | 512 steps | Multi-quantile distribution |
| Moirai | Transformer (Salesforce) | 14M - 311M | Any-variate patched | Up to 5000 steps | Parametric mixture modeling |
| Lag-Llama | LLaMA Decoder-only | 2.5M | Continuous + Lags | Variable | Student-t parameters |
| TimesFM | Transformer (Google) | 200M - 500M | Continuous patching | 512 - 2048 steps | Point + Quantiles |
| TimeGPT | Encoder-Decoder | Undisclosed | Continuous features | Variable | Point + Conformal intervals |
Domain Generalization versus Financial Specificity
On general-purpose benchmarks such as GIFT-Eval (which features 144,000 time series across retail, systems observability, and energy domains) and BOOM, models like Moirai, Toto, and Chronos regularly outperform both statistical baselines and task-specific deep learning models 51516. For instance, on the GIFT-Eval leaderboard, models utilizing multi-variate patching often dominate zero-shot evaluations against traditional ARIMAX implementations 530.
However, applying general-purpose TSFMs to raw financial data in a zero-shot setting exposes severe domain incompatibilities. Financial data is characterized by extremely low signal-to-noise ratios, non-stationary distribution shifts, heavy-tailed return profiles, and continuous adversarial evolution driven by market participants 43117. An empirical study evaluating 34 years of daily excess-return data across 94 countries demonstrated a distinct performance gap. When benchmarked on out-of-sample financial datasets, TimesFM (500M) yielded a zero-shot R2 of -2.80% and a corresponding portfolio strategy return of -1.47% 3334. Similarly, the large variant of Chronos yielded an R2 of -1.37% 33.
The Root Causes of General TSFM Underperformance
This underperformance in the financial domain is not indicative of architectural failure, but rather of a severe misalignment between generic pre-training methodologies and financial market mechanics. The primary limitations include:
- Improper Normalization and Absolute Binning: Models like Chronos utilize strict scalar quantization, mapping continuous values into predefined, absolute bins 9. In finance, absolute price levels are largely irrelevant; relative volatility, momentum, and cross-asset correlations contain the predictive signal. A model pre-trained to track absolute variations in server CPU loads will struggle to extract signal from the micro-structural variance of an equities spread 8.
- Optimization for Mean Squared Error (MSE): General TSFMs are heavily optimized for statistical metrics like MSE or Mean Absolute Error (MAE) during pre-training. In financial data containing heavy tails, optimizing for MSE creates a strong inductive bias toward the mean, leading to "forecast collapse" - a phenomenon where the model outputs flat-line forecasts or premature mean reversion during periods of structural volatility 48.
- Lack of Multivariate Covariate Awareness: Most early foundation models are strictly univariate, predicting an asset's future trajectory based solely on its own history 3. Financial markets are inherently interconnected. The inability to attend to exogenous covariates - such as interest rates, macroeconomic indices, or cross-asset price behavior - strips the model of vital predictive context required for tasks like statistical arbitrage 335.
Architectures Tailored for Financial Data
Recognizing the structural limitations of generic time-series modeling, researchers have developed TSFMs explicitly designed and pre-trained on financial market data. These domain-specific models address the unique quantization and non-stationarity challenges of asset pricing.
The Kronos Framework and Binary Spherical Quantization
Presented at AAAI 2026 by researchers at Tsinghua University, Kronos is a decoder-only foundation model trained strictly on the "language" of financial markets: candlestick (K-line) sequences encompassing Open, High, Low, Close, Volume, and Amount (OHLCVA) data 21837. Pre-trained on a corpus of 12 billion K-line records from over 45 global exchanges, Kronos resolves the volatility scaling problem inherent to financial data by utilizing Binary Spherical Quantization (BSQ) 733.
BSQ maps disparate financial assets (e.g., highly volatile micro-cap equities versus stable large-cap indices) onto a normalized high-dimensional unit hypersphere. A transformer autoencoder then quantizes these continuous geometric representations into a discrete vocabulary of $2^{20}$ (approximately 1 million) hierarchical tokens 33. This enables the Kronos model (scaling from 4.1M to 499.2M parameters) to process financial structure natively while filtering out pervasive market noise 733.
In zero-shot benchmark tests against 25 competing models, Kronos boosted the Rank Information Coefficient (RankIC) by 93% over the leading general TSFM, and achieved a 9% reduction in Mean Absolute Error (MAE) for volatility forecasting compared to heavily tuned econometric models 333839. Furthermore, its ability to generate high-fidelity synthetic K-line sequences (+22% generative fidelity over baselines) demonstrates that it has successfully mapped the underlying generative distribution of the market 3339.
FinCast and Token-Level Sparse Mixture-of-Experts
FinCast, introduced at CIKM 2025, represents a billion-parameter scale approach to financial non-stationarity. To overcome the tendency of generic foundation models to suffer from forecast collapse during regime shifts, FinCast introduces a Point-Quantile Loss (PQ-Loss) function that jointly optimizes deterministic targets and probabilistic bounds 4. Architecturally, it employs a Token-Level Sparse Mixture-of-Experts (MoE) system, dynamically routing specific temporal tokens to specialized internal expert layers 4. This allows the model to isolate sudden volatility bursts or non-linear trend breaks without contaminating the shared representations used for stable trending periods 4.
Evaluated on a massive zero-shot dataset of 4.38 million financial scalar time points, FinCast achieved a 20% average reduction in MSE and a 10% reduction in MAE compared to state-of-the-art general-purpose models like TimesFM and Chronos 4.
| Financial Foundation Model | Total Parameter Scale | Primary Pre-Training Corpus | Unique Architectural Mechanism | Zero-Shot Performance Delta |
|---|---|---|---|---|
| Kronos | Up to 499.2M | 12 Billion OHLCVA K-lines | Binary Spherical Quantization | +93% RankIC over general TSFMs |
| FinCast | > 1 Billion | Broad Financial Asset Data | Sparse MoE + PQ-Loss | -20% MSE vs general TSFMs |
Market Microstructure and Trading Execution Viability
A critical flaw in the academic literature evaluating TSFMs in finance is the over-reliance on idealized statistical metrics - such as MAE, CRPS (Continuous Ranked Probability Score), and theoretical zero-friction Sharpe ratios 12. A forecast that achieves high statistical significance is not inherently economically exploitable. If a foundation model predicts a 0.05% directional move over a 15-minute horizon, the signal is mathematically accurate but economically destructive once execution costs are applied.
The Impact of Transaction Costs and Slippage
The practical viability of a zero-shot model lies in its net performance after accounting for execution frictions: slippage (the difference between expected execution price and actual fill price), exchange commissions, bid-ask spread crossing, and localized market impact 210.
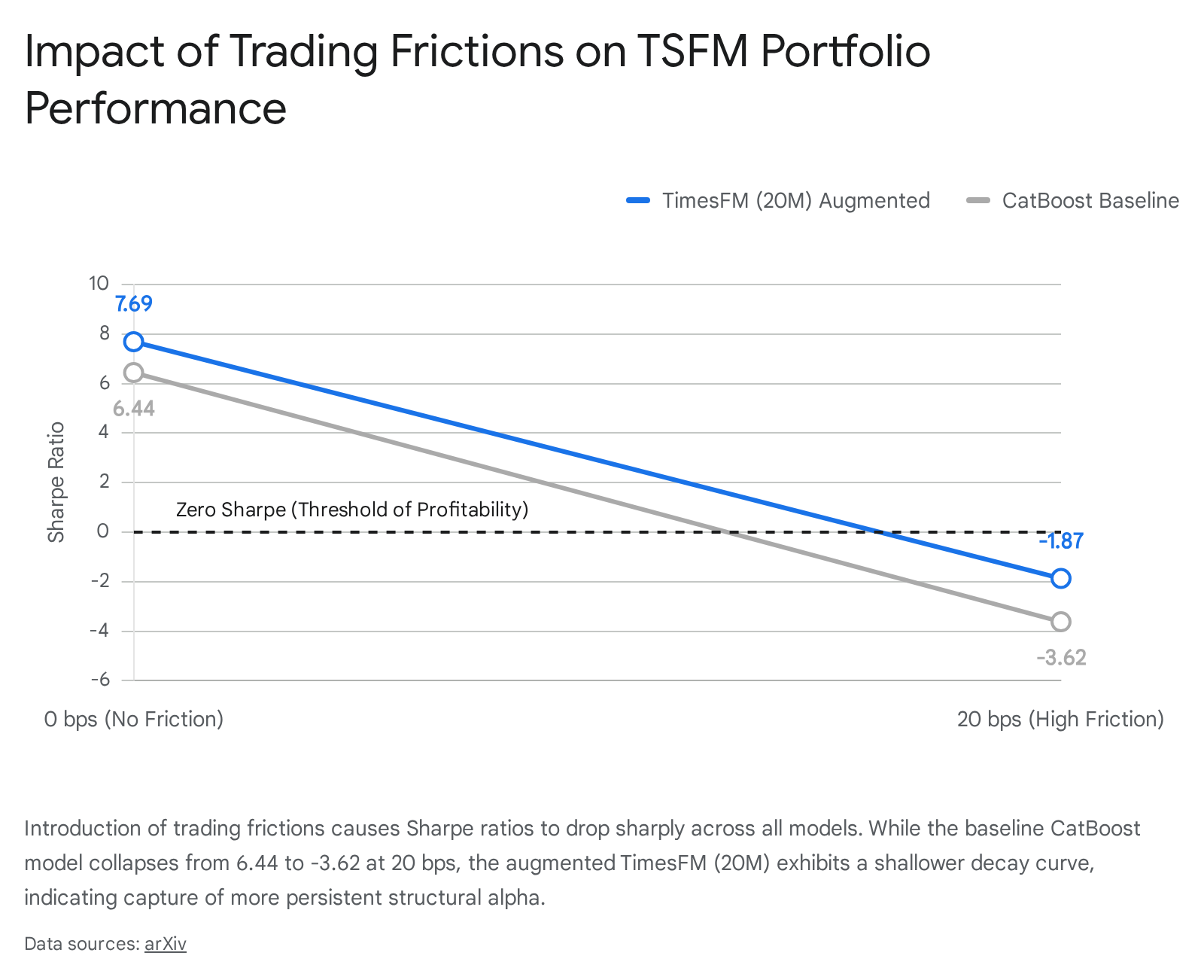
When empirical studies introduce simulated trading frictions, the performance of TSFM-generated portfolios degrades dramatically. In a global evaluation of long-short portfolios constructed from TSFM predictions, a baseline statistical model's Sharpe ratio collapsed from 6.44 at zero transaction costs to -3.62 when a realistic 20 basis point (bps) execution cost was introduced 34.
However, fine-tuned or heavily augmented foundation models exhibit notable resilience to these execution costs. The TimesFM (20M) model, when pre-trained from scratch on augmented financial data and synthetic factors, managed to maintain a Sharpe ratio of -1.87 under a mixed-cost structure (11.2 bps for large caps, 21.3 bps for small caps) - significantly outperforming the -2.96 Sharpe of the baseline under the same friction constraints 34. While still negative overall in this specific high-cost simulation, the slower decay in performance suggests that correctly augmented TSFMs are capturing deeper, more persistent structural alpha rather than fleeting micro-structural noise that vanishes instantly upon execution 34.
Probabilistic Modeling and Uncertainty Filtration
To deploy a zero-shot or few-shot TSFM in production, quantitative practitioners must construct execution pipelines that utilize uncertainty filtering. Models that only output deterministic point estimates are highly vulnerable to volatile regimes. In contrast, models like Lag-Llama and Chronos output full probability distributions 1214.
In financial engineering, the assumption underlying many traditional time-series models is that asset prices follow a log-normal distribution. Empirical reality dictates that asset returns exhibit "fat tails" or stable distributions characterized by an exponent $\alpha < 2$ (where $\alpha = 2$ represents a true Gaussian) 17. Lag-Llama utilizes a distribution head that explicitly projects its extracted features into the parameters of a Student's t-distribution 1011. Because the Student-t distribution features heavier tails than the Gaussian, the model is significantly less prone to underestimating extreme market shocks, allowing its predictive intervals to widen appropriately during high-volatility regimes 11.
Recent frameworks like ProbFM and Deep Evidential Regression (DER) explicitly separate epistemic uncertainty (model ignorance due to lack of training data) and aleatoric uncertainty (inherent statistical noise in the data) 1440. By restricting algorithmic trading execution solely to high-confidence quantiles where epistemic uncertainty is minimized, trading systems can artificially increase the required hurdle rate, ensuring the predicted directional move is large enough to safely clear the transaction cost barrier 40.
Temporal Bias and Cross-Validation Paradigms
The most pervasive and insidious risk in deploying time-series foundation models for financial trading is temporal contamination, manifesting as data leakage and look-ahead bias 4142.
Look-ahead bias occurs when a model is given access to information that would not have realistically been available at the exact moment of prediction 4119. With the advent of massive TSFMs pre-trained on billions of web-scraped data points, look-ahead bias has evolved into a structural flaw. Foundation models trained on public web text, Wikipedia pageviews, or historical financial archives inherently memorize the future 241.
When a generic LLM-adapted TSFM is asked to perform a zero-shot backtest on the 2008 or 2020 market crises, it is highly likely that the model has already ingested post-hoc analyses, specific price paths, and macroeconomic outcomes of those exact events during its pre-training phase 41. In these instances, the model is not engaging in predictive temporal reasoning; it is engaging in entity memorization and fact retrieval 41. Researchers have demonstrated empirically that training data can be extracted directly from model weights, proving that temporal leakage persists and scales with model size unless explicitly mitigated by rigorous training cutoffs 41.
If a trading system relies on a TSFM whose knowledge window extends past the testing period, the resulting backtest will produce artificially inflated Sharpe ratios and directional accuracies 41. Once the model is deployed into live, out-of-sample trading - an environment where the future is genuinely unwritten - the performance frequently collapses 41.
Mitigating Bias via Purged Validation
To validate whether a TSFM possesses genuine zero-shot forecasting capabilities, researchers must abandon standard machine learning validation techniques. Traditional K-Fold Cross Validation assumes that data points are Independent and Identically Distributed (IID). In financial time series, extreme temporal dependencies and structural breaks violate this assumption 31. If standard K-Fold CV is used, data from the "future" folds will contaminate the training of "past" folds, resulting in severe data leakage 31.
The requisite methodological solution is Purged K-Fold Cross-Validation accompanied by an Embargo Period 3142. First, purging forcefully removes all training observations whose evaluation periods overlap with the designated test set 31. Second, because financial variables are highly autocorrelated, the test set influences the period immediately following it. An embargo period strips out all training data that occurs immediately after the test window to prevent residual future information from seeping backward into the model's representations 3142. Zero-shot evaluations of specialized models like FinCast explicitly verify that benchmark datasets are categorically excluded from the pre-training corpus to ensure strict temporal hygiene 4.
Application to Diverse Market Contexts
The efficacy of zero-shot forecasting is highly dependent on the temporal resolution and asset class being evaluated. Independent evaluations of TSFMs reveal significant variance in performance across sampling frequencies.
In tests utilizing generic foundation models on low-frequency macroeconomic and commodity data (e.g., yearly and quarterly frequencies), models like TimeGPT, Chronos, and Moirai frequently perform identically to or worse than naive seasonal benchmarks 44. However, performance improves dramatically on monthly data, where Chronos has demonstrated the ability to outperform traditional statistical champions like the Theta method 44.
When transferred to specific financial tasks such as forecasting US 10-year Treasury yield changes, EUR/USD volatility, and equity spread predictions, zero-shot TSFMs exhibit mixed results. In evaluations of the Tiny Time Mixers (TTM) architecture and Chronos, TSFMs successfully outperformed naive baselines in zero-shot volatility forecasting and equity spread prediction 8. However, specialized sequential deep learning models and tree-based methods matched or exceeded the zero-shot foundation models in the majority of tasks 8. This dynamic suggests that while TSFMs capture broad, transferrable temporal representations, achieving competitive edge in specialized, data-constrained financial tasks still requires domain-specific fine-tuning or full architectural adaptation 8.
Forward Outlook on Foundation Model Trading
General-purpose Time-Series Foundation Models - such as Chronos, Moirai, TimesFM, and Lag-Llama - represent monumental architectural advancements in forecasting. Their ability to generalize across disparate domains via patched contexts and discrete tokenization demonstrates that sequential temporal patterns possess a universal, learnable grammar.
However, these generic models cannot reliably trade financial markets in a strict zero-shot capacity. When subjected to the realities of heavy-tailed asset distributions, microscopic signal-to-noise ratios, and the friction of basis-point transaction costs, the theoretical accuracy of generic zero-shot TSFMs degrades rapidly. Their absolute-value scaling techniques destroy relative volatility contexts, and their pre-training on generalized web data leaves them structurally vulnerable to look-ahead bias and temporal leakage.
Conversely, domain-specific foundation models like Kronos and FinCast demonstrate that the foundation paradigm is highly viable for quantitative finance, provided the model is pre-trained exclusively on the native mechanics of the market. By utilizing specialized techniques like Binary Spherical Quantization to normalize cross-asset volatility, and Token-Level Sparse Mixture-of-Experts to isolate non-stationary regime shifts, financial TSFMs achieve zero-shot predictive accuracy that meaningfully surpasses classical econometric baselines. Ultimately, time-series foundation models function not as standalone trading agents, but as highly advanced signal-generation engines that must be constrained by strict probabilistic risk overlays and rigorous execution logic to extract genuine market alpha.