Is Deep Learning or Gradient Boosting Better for Trading
For the vast majority of structured, directional trading strategies, gradient boosting algorithms like XGBoost consistently outperform deep learning by extracting faint signals from noisy tabular data without catastrophic overfitting. However, advanced deep learning models - particularly Temporal Fusion Transformers and large language models - have become the undisputed leaders in processing unstructured alternative data, multi-horizon forecasting, and complex statistical arbitrage. Consequently, the most sophisticated institutional funds no longer choose between the two, instead deploying hybrid systems that leverage both architectures to generate and execute alpha.
The Core Challenge: Financial Data Is Not Like Image Data
To understand why a specific algorithm excels or fails in financial markets, it is necessary to first understand the unique physical and statistical properties of market data. The canonical success stories of modern artificial intelligence - such as image recognition, natural language translation, and protein folding - involve fundamentally stationary problems 1. In these scientific domains, the underlying rules do not spontaneously change; a cat looks like a cat today, tomorrow, and ten years from now.
Financial markets, however, are fundamentally different. They represent an adversarial environment where the data is actively trying to hide the signal, and where market participants are constantly adapting to eliminate edge. This creates a challenging modeling landscape defined by three distinct statistical hurdles.
The Low Signal-to-Noise Ratio (SNR)
The primary distinction between finance and other fields where artificial intelligence excels lies in the signal-to-noise ratio. In image recognition, the "signal" (the object being identified) is highly visible against the "noise" (background blur or variable lighting). Financial markets exhibit an exceptionally low signal-to-noise ratio 2.
According to leading quantitative researchers, a typical daily price series is roughly 80% to 99% noise 34.
When algorithms are fed low-SNR data, the highly expressive nature of complex deep learning models becomes a profound liability. Machine learning algorithms are mathematically designed to find patterns, and in the absence of a strong signal, they will enthusiastically memorize the noise 5. This is why annual Sharpe ratios of 0.5 to 1.0 for genuine market inefficiencies translate to incredibly tiny, fragile values in return prediction regressions 1. The faint, exploitable signal is easily buried under the weight of market randomness.
Non-Stationarity and Regime Shifts
Financial distributions shift constantly. A pattern that perfectly predicted the direction of an asset during a trending regime in 2021 might predict the exact opposite in a mean-reverting regime in 2023 3. This non-stationarity means that statistical properties like averages and variances are time-varying, not constant constants 2.
When a model is trained on historical market data, it learns the parameters of a specific market regime. As the macroeconomic environment changes, or as a specific quantitative strategy becomes crowded, the predictive alpha decays. Deep learning models, which often act as opaque neural networks, struggle to unlearn these embedded historical patterns quickly. By the time a deep neural network adapts to a new market regime, the opportunity has often passed, leading to poor out-of-sample generalization.
The Tabular Disguise of Financial Data
When quantitative developers build predictive models, they rarely feed raw price ticks directly into the algorithm. Instead, they rely heavily on feature engineering. Features like the Relative Strength Index (RSI), Average True Range (ATR), funding rates, moving average convergence divergence (MACD), and volume ratios are essentially data aggregations that compress a historical time window into a single numerical value 36.
By the time the data is ready for modeling, the sequential and temporal work has already been baked into the features. What remains is a structured, tabular dataset: one row per time bar, with columns representing the engineered features 3. Because the sequence information is already captured by the feature engineering, the ability of deep learning models to map temporal dependencies becomes largely redundant. This structural reality is the primary reason why decision-tree-based algorithms perform so exceptionally well in traditional trading environments.
Why Gradient Boosting Rules the Tabular Domain
Extreme Gradient Boosting (XGBoost) and its modern peers, such as LightGBM and CatBoost, operate on a fundamentally different paradigm than neural networks. Instead of passing data through hidden layers of neurons, gradient boosting trains decision trees sequentially. Rather than building independent trees like a Random Forest, gradient boosting adds trees one at a time, with each new tree explicitly optimized to correct the residual errors made by the combination of all previous trees 78.
For structured, tabular financial data, these tree-based ensemble methods routinely match or outperform complex deep neural networks while requiring a fraction of the computational overhead 9101112.
Data Scarcity and the Overfitting Trap
Deep neural networks require massive volumes of data - often millions of examples - to generalize effectively 3. Financial time series data is remarkably scarce by comparison. Even looking at the quarterly earnings statements of 1,000 major companies over a five-year period yields only 20,000 samples, creating what researchers call a high-dimension, low-sample-size (HDLSS) problem 13. Even three years of daily price bars equate to roughly 750 rows of data per asset 3.
At this scale, a deep learning model utilizing tens of thousands of parameters will inevitably overfit. It will memorize the training data perfectly, leading to strong in-sample accuracy, but will suffer catastrophic out-of-sample degradation, often falling to coin-flip accuracy within sixty days of live trading 3. XGBoost, conversely, regularizes highly efficiently at scales of 500 to 2,000 rows. Through hyperparameter controls like learning rate adjustments, maximum depth constraints, and random subsampling, gradient boosting mitigates the risk of overfitting in data-scarce environments 311.
Handling Discontinuous Regimes and Missing Data
Financial data is rife with hard thresholds and missing values. An economic indicator may suddenly flip from positive to negative, or a funding rate may cross zero, triggering a completely different market behavior. XGBoost inherently handles these discontinuous thresholds by explicitly splitting on exact feature values to find boundaries for regime flips 311. Deep learning models, however, are continuous function approximators that must attempt to infer these sharp boundaries through complex, smoothed parameter adjustments.
Furthermore, tree-based models naturally learn default directions for missing values. In real-world market data, missing prints or delayed reports are common. XGBoost preserves the information that data is missing, treating it as a signal in itself, whereas deep learning models typically require aggressive data imputation processes that can distort the underlying reality 11.
Interpretability and SHAP Values
A critical advantage of gradient boosting in an institutional setting is its interpretability. The "black box" nature of complex artificial intelligence algorithms creates a massive operational and regulatory risk in finance; a single unexplainable error can erase decades of returns 514. Regulatory bodies like the European Securities and Markets Authority (ESMA) and the U.S. Securities and Exchange Commission (SEC) are increasingly demanding model explainability 15.
Gradient boosting models integrate seamlessly with SHAP (SHapley Additive exPlanations) values, allowing portfolio managers to see exactly how much each specific feature contributed to a given prediction 89. If a model begins failing during live trading, risk managers can use SHAP to pinpoint which specific engineered feature has lost its predictive power due to a regime shift. This allows for rapid, targeted debugging that is virtually impossible with deep learning architectures 38.
Deep Learning: The Promise, Pitfalls, and Complex Reality
Deep neural networks - including Long Short-Term Memory (LSTM) networks, Convolutional Neural Networks (CNNs), and modern Transformers - process data through hierarchical layers to capture highly complex, non-linear representations 11. While this capacity has revolutionized language and computer vision, its application to financial markets remains highly contested.
The financial industry is currently engaged in a "complexity arms race," predicated on the assumption that markets contain non-linear patterns too subtle for linear models, and that sufficiently powerful neural networks can unearth them 4. However, in low-signal-to-noise environments, adding algorithmic complexity often yields diminishing or even negative returns.
The Failure of Raw Sequence Modeling
Because financial time series data looks like a sequence, the natural instinct for machine learning engineers is to apply sequence models like LSTMs or Transformers 3. However, these models were built for datasets with very different structural properties. The attention mechanism in a Transformer was originally designed for natural language, where the position of a 512-token sentence carries distinct semantic meaning. A 20-bar window of Open-High-Low-Close (OHLCV) market data possesses no equivalent positional structure 3.
When a multi-head attention mechanism or an LSTM is unleashed on raw price sequences, it often finds false temporal relationships, fitting noise with an expressive architecture and degrading to near-random out-of-sample accuracy 31. A comprehensive study analyzing 2.79 million observations across 2,439 Korean equities highlighted this danger. Researchers deployed an advanced pipeline utilizing Independent Component Analysis, Wavelets, and an LSTM with attention mechanisms. The highly complex deep learning model collapsed, predicting only the unconditional mean and achieving a Sharpe ratio of 0.07. In stark contrast, a simple parsimonious linear model utilizing market capitalization-normalized flows achieved a Sharpe ratio of 1.30 4.
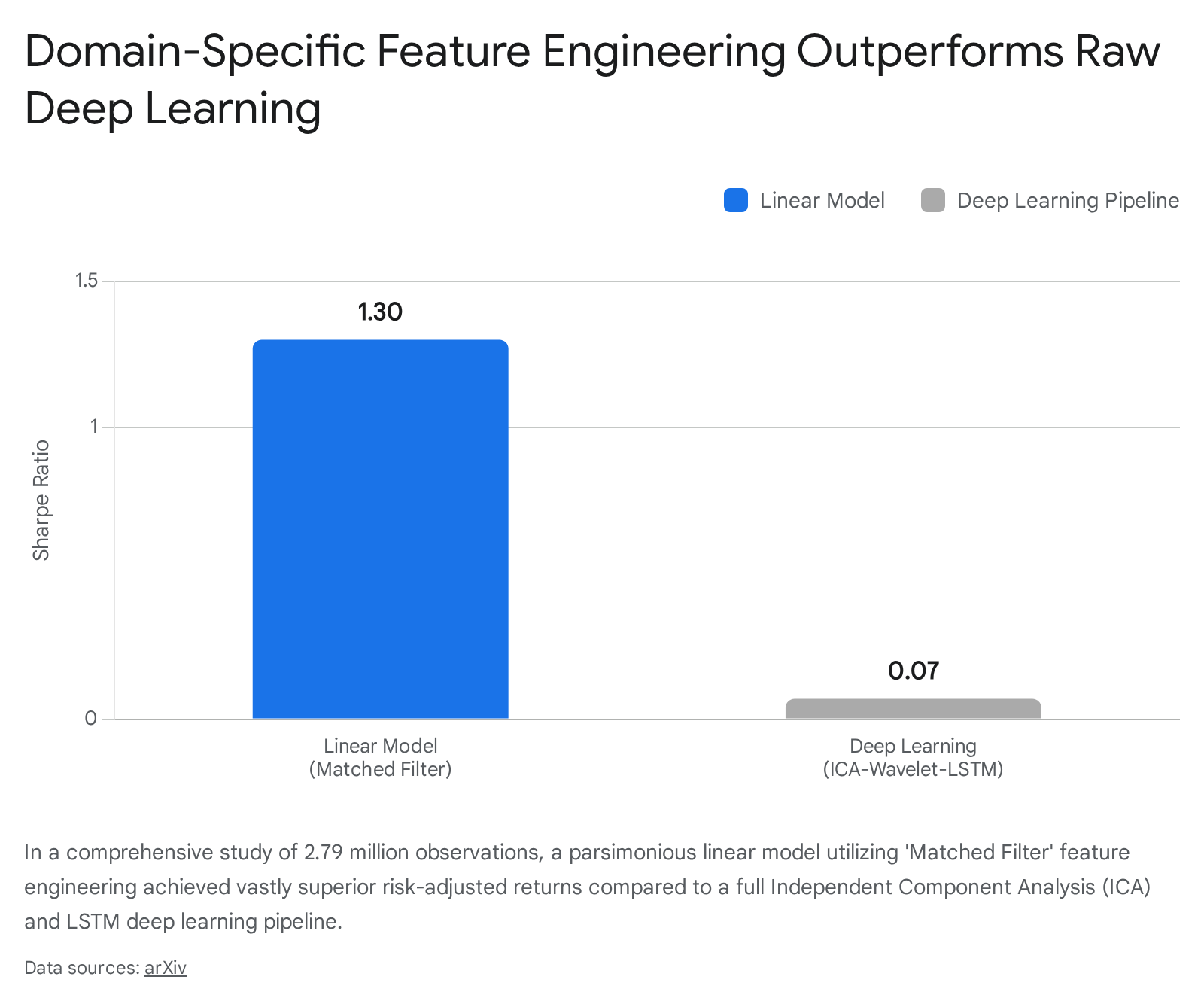
The researchers concluded that algorithmic complexity destroys information in environments where the true signal is below five percent.
Injecting Economic Constraints
Despite these pitfalls, deep learning does not have to fail in structured finance. The key to unlocking its potential lies in constraining the neural network with established economic theory, rather than letting it search blindly for correlations.
A landmark study utilizing a Generative Adversarial Network (GAN) demonstrated that deep learning can significantly outperform traditional models when properly guided 2. Researchers at AQR Capital Management achieved this by embedding the fundamental economic "no-arbitrage" condition directly into the learning algorithm as a criterion function. By forcing the deep neural network to focus exclusively on explaining risk premia rather than just raw price variation, the model successfully mapped the complex, non-linear interaction effects between hundreds of macroeconomic time series 2. The economically constrained GAN achieved an out-of-sample Sharpe ratio of 2.6, vastly outperforming the classic Fama-French linear benchmark, which achieved only 0.8 2. This proves that deep learning's flexibility is highly valuable, provided it is anchored by rigorous financial logic.
Conquering Alternative Data and Natural Language
While gradient boosting dominates the structured tabular data of daily price bars, deep learning is the undisputed leader in unstructured alternative data. Deep learning frameworks, particularly Large Language Models (LLMs) and advanced Natural Language Processing (NLP) architectures like Bidirectional Encoder Representations from Transformers (BERT), are increasingly utilized to parse unstructured information across the global economy 153.
Modern deep learning models can ingest central bank communications, parse earnings call transcripts, analyze geopolitical news feeds, and evaluate satellite imagery in milliseconds 15. By translating qualitative human sentiment and massive textual datasets into actionable quantitative signals, deep learning extracts a form of alpha that traditional statistical methods and decision trees simply cannot access 34. In these high-dimensional, multi-modal applications, the raw representational power of deep learning is irreplaceable.
The Rise of Temporal Fusion Transformers (TFTs)
In the ongoing debate between tree-based models and recurrent neural networks, a relatively new architecture has emerged as a powerful middle ground: the Temporal Fusion Transformer (TFT). Developed specifically to address the shortcomings of earlier deep learning models in time-series forecasting, the TFT architecture integrates the local sequence-learning capabilities of LSTMs with the global relationship tracking of attention mechanisms 202122.
Crucially, TFTs are designed from the ground up to handle the specific realities of financial data. They can simultaneously process multi-horizon forecasts, integrate static covariates (like a company's sector), and account for known future inputs (like scheduled earnings dates) 235. Furthermore, by utilizing a quantile loss function, TFTs output probabilistic prediction intervals rather than single-point deterministic estimates, providing traders with built-in uncertainty metrics critical for risk management 2223.
Bridging the Interpretability Gap
One of the TFT's most significant contributions to quantitative finance is its built-in interpretability. Unlike standard black-box deep learning models that obscure their decision-making process, the TFT utilizes variable selection networks and self-attention layers to provide clear insights into which features the model is weighting heavily at any given time step 222526. This structural transparency satisfies regulatory compliance requirements while allowing researchers to trust the model's logic.
Performance in Real-World Trading
Recent academic benchmarks show TFTs consistently matching or exceeding the accuracy of both LSTMs and XGBoost across highly complex datasets. In a 2025 multi-asset cryptocurrency trading study evaluating Bitcoin, Ethereum, and other major assets, researchers introduced a TFT-based forecasting framework 6. By integrating on-chain data (such as active addresses and exchange net flows) with technical indicators, the TFT successfully captured volatile behavioral patterns, outperforming traditional Support Vector Regression and XGBoost benchmarks to deliver optimized tactical trading signals 6. Similarly, in energy market applications forecasting day-ahead electricity prices, the TFT demonstrated superior performance over ARIMA and XGBoost baselines due to its ability to natively produce probabilistic bounds 23.
Time Series Foundation Models: Chronos vs XGBoost
The monumental success of Large Language Models has sparked a race among tech giants to build "Foundation Models" specifically for time series data. These models are pre-trained on billions of data points across diverse domains - finance, weather, retail, and energy - and are designed to be deployed "zero-shot" on entirely new financial datasets without requiring task-specific retraining 2728.
Zero-Shot Forecasting and Tokenization
Amazon's Chronos has emerged as a prominent example of this new paradigm. Chronos approaches time series forecasting by framing it as a language classification problem. It scales and quantizes continuous time series data, transforming it into discrete tokens similarly to how an LLM tokenizes words in a sentence 296. The model is trained on a massive corpus containing approximately 84 billion individual observations using a categorical cross-entropy loss function 6. When presented with new financial data, it autoregressively samples multiple trajectories to obtain a predictive probability distribution 29.
Empirical Benchmarks and the Execution Reality
Foundation models offer an incredibly fast, low-effort starting point and show strong resistance to context-related degradation, maintaining accuracy even as the historical context length increases 297. However, empirical benchmarks reveal that they are not yet a complete replacement for purpose-built algorithms.
In rigorous evaluations reflecting real-world operational forecasting systems, a highly tuned, domain-specific XGBoost model still frequently achieves superior accuracy. For instance, in a 2026 study evaluating system imbalances, a production-grade XGBoost model achieved an RMSE of 59.38, outperforming the zero-shot Chronos model, which scored 66.34 27. While foundation models are rapidly closing the gap and are excellent for rapid prototyping, they still struggle to match the precision of an XGBoost pipeline that has been subjected to extensive, domain-specific feature engineering 2728.
Model Comparison Matrix
The decision to deploy deep learning versus gradient boosting is rarely a binary choice in modern finance. Different market challenges require distinct algorithmic properties. The following table summarizes the operational tradeoffs between the dominant architectures.
| Feature / Capability | Extreme Gradient Boosting (XGBoost / LightGBM) | Long Short-Term Memory (LSTM) | Temporal Fusion Transformer (TFT) |
|---|---|---|---|
| Primary Architecture | Sequential decision trees correcting prior residual errors. | Recurrent neural networks with sophisticated gating mechanisms. | Hybrid architecture: LSTMs merged with multi-head attention mechanisms. |
| Data Requirements | Highly effective on small, structured tabular datasets (< 10,000 rows). | Requires massive sequential datasets to avoid catastrophic overfitting. | Requires substantial data but manages diverse input types more efficiently. |
| Feature Engineering | Essential. Requires heavy manual feature creation to capture time dependencies. | Can process raw sequences, but struggles with pure financial noise. | Handles both static covariates and time-varying inputs directly in architecture. |
| Computational Cost | Very low. Trains in seconds on standard CPUs, allowing rapid iteration. | High. Requires GPU acceleration and long training times. | Very high. Complex architecture necessitates heavy GPU infrastructure. |
| Interpretability | High. Achieved post-hoc via feature importance and SHAP values. | Low. Operates largely as a "black box," frustrating risk managers. | High. Built-in variable selection and attention weights provide transparency. |
| Optimal Use Case | Daily/intraday directional prediction on heavily engineered tabular market data. | Natural language processing; analyzing high-frequency order book data. | Multi-horizon forecasting; complex multi-modal data integration. |
The Institutional Playbook: Two Sigma, Man Group, and Hybrid Systems
Top-tier quantitative funds, including Two Sigma, Renaissance Technologies, Citadel, and Man Group, do not rely on a single algorithm in isolation. In 2024 alone, global investment in AI and machine learning trading infrastructure exceeded $4.2 billion, driving the adoption of complex, hybrid architectures that blend the strengths of multiple models 15.
Orchestrating the Tech Stack
At the institutional level, the line between systematic and discretionary trading is dissolving 32. Firms are combining XGBoost for rapid, efficient feature selection with deep learning models for signal generation 933. Deep learning is used as an ingestion engine to process vast troves of unstructured alternative data - such as satellite imagery, supply chain disclosures, and real-time consumer behavior. Once these neural networks have distilled the unstructured data into clean, quantitative signals, robust, computationally efficient gradient boosting algorithms act upon them to make final execution decisions 158.
Furthermore, institutional quants understand that the core of alpha generation often relies more on portfolio variance and covariance matrix optimization than on raw directional prediction 35. While a model might predict the direction of an asset accurately, managing the interacting volatility of a thousand-stock portfolio requires distinct mathematical frameworks.
Statistical Arbitrage and Deep Reinforcement Learning
For statistical arbitrage, advanced funds utilize Deep Reinforcement Learning (DRL) to dynamically adjust positions based on evolving market states. Rather than just predicting prices, reinforcement learning algorithms learn a dynamic policy that maps market states directly to portfolio allocations, actively learning from the rewards and penalties of simulated trades 136.
However, these systems require rigorous, institutional-grade risk management. DRL models are notoriously prone to overfitting, often achieving near-perfect win rates in backtesting only to fail in live markets. To combat this, institutions implement twin delayed critics, uncertainty-based exploration, adaptive temperature optimization, and strict training-testing data separation 35.
The Cost of Complexity
Deploying these advanced models is not without severe friction. The integration of generative AI and deep learning into legacy financial infrastructure poses massive operational risks. Firms like Morgan Stanley and BlackRock have identified model hallucination and unexplainable outputs as prominent risks, instituting daily regression tests specifically designed to "break" their platforms 37. Furthermore, the computational demands are staggering. Despite achieving significant software speedups using distributed computing clusters, leading quantitative funds still cite massive GPU capital expenditures and high computational costs as major barriers to scaling deep learning strategies 37.
Retail AI Trading Bots: Democratization or Danger?
The democratization of algorithmic trading has brought machine learning out of the hedge fund and into the retail investor's portfolio. The market for retail predictive AI platforms is expected to balloon from $831.5 million in 2024 to $4.1 billion by 2034, driven by individual traders seeking an institutional edge 9.
Platforms such as TradeIdeas, Kavout, TrendSpider, and Tickeron offer retail traders access to pre-built AI agents, automated technical analysis, and real-time pattern recognition without requiring coding skills 939. The marketing surrounding these platforms is aggressive, with some vendors claiming specific intraday algorithms can achieve annualized returns exceeding 200% on specific equities 40.
The Performance Reality of Retail AI
While the marketing promises massive wealth, empirical academic studies paint a more nuanced and sobering picture. Research across multiple market cycles indicates that while early AI-driven funds generated significant excess returns (alpha), that outperformance declined consistently over time 41. When millions of market participants trade on correlated machine learning signals, they compete for the exact same mispricing opportunities. As Larry Swedroe of Alpha Architect noted, an individual AI bot is not competing against humans; it is competing against the collective decision-making of millions of other AI models, causing the exploitable alpha to rapidly decay 41. Furthermore, systematic literature reviews of robo-advisors show that they frequently fail to outperform basic market indexes over the long term 42.
However, AI does provide distinct structural advantages for retail investors. Primarily, AI bots strip human emotion - panic selling and greed - out of the execution process 9. In the 2022 bear market, academic research found that AI-driven funds demonstrated superior downside protection, dropping 17% compared to the 30.7% drop experienced by human-managed funds. This protection was largely derived from the AI's strict adherence to systematic algorithmic hedging and automated stop-loss mechanisms 41.
The ChatGPT Experiment and Information Costs
Beyond direct trading execution, generative AI is reshaping how retail investors process information. A recent study utilizing account-level brokerage data examined the behavior of retail investors during a temporary ban on ChatGPT in Italy in 2023. The researchers found that when access to generative AI was removed, investors concentrated their trades in fewer assets and shifted toward highly popular, easy-to-understand stocks 43.
This demonstrates that AI's greatest immediate value to the retail sector may not be in generating secret trading signals, but in acting as an information intermediary. By drastically reducing the cognitive cost of analyzing earnings reports, macroeconomic data, and company fundamentals, AI allows nonprofessional investors to comfortably diversify their portfolios into harder-to-value assets and broader market sectors 43.
Systemic Risks and the Erosion of Alpha
The widespread integration of artificial intelligence into algorithmic trading systems introduces profound systemic risks to global financial markets. While AI-driven trading enhances short-term market efficiency and execution speed, it also creates new dimensions of market fragility.
Algorithmic Herding and Market Fragility
Deep learning models, particularly those trained on specific historical financial shocks, may struggle to adapt to evolving, unprecedented market dynamics 44. Because many quantitative funds rely on similar alternative data inputs and foundational machine learning models, there is a severe risk of algorithmic herding. If multiple AI systems detect the same latent signal and execute massive sell orders simultaneously, they can exacerbate liquidity dry-ups and trigger flash crashes - scenarios that traditional heuristic rule-based systems might have avoided 4445. To combat this, regulatory bodies are pushing for real-time market surveillance tools capable of analyzing sub-second network relationships to detect systemic anomalies 44.
Multi-Agent Learning Frictions
Perhaps the most insidious risk of AI trading is how it alters the very market it seeks to exploit. A recent theoretical and experimental study highlighted a severe learning friction that occurs when multiple Deep Reinforcement Learning agents interact in a live market setting 10.
In isolation, an AI trader appears to learn successfully and enhance market efficiency. However, as the presence of AI traders grows, their collective exploratory actions inject noise into the price process. This endogenous feedback loop distorts the portfolio-return signals that the agents rely upon to learn. Consequently, the presence of other AI agents impairs the learning ability of the entire ecosystem, leading to reduced trading profits, degraded market liquidity, and lower overall market efficiency 10. This research highlights the danger of trusting partial-equilibrium backtests; strategies that look phenomenal in a historical vacuum often degrade significantly when deployed in a live, multi-agent environment where every algorithm is reacting to every other algorithm.
Bottom line
For the vast majority of directional trading strategies based on historical price and volume data, Extreme Gradient Boosting remains the superior and most reliable tool. Its ability to extract insights from small, noisy tabular datasets rapidly, combined with its high interpretability via SHAP values, makes it the standard workhorse of the quantitative finance industry. Deep learning, conversely, shines brightest when applied to massive, unstructured alternative datasets - such as natural language sentiment and multi-horizon forecasting via Temporal Fusion Transformers - where its capacity to model complex, non-linear interactions justifies its immense computational cost. Moving forward, the most successful trading operations will not choose a single winner, but will deploy sophisticated hybrid architectures that leverage deep learning for feature extraction and gradient boosting for robust, interpretable execution.