Large language models for trading and alpha generation
Evolution of Natural Language Processing in Finance
The integration of unstructured textual data into quantitative finance has fundamentally transformed algorithmic trading, allowing systematic strategies to process information that was historically the exclusive domain of human discretionary managers 12. Historically, the extraction of market signals from text relied on basic heuristic techniques, such as the Loughran-McDonald dictionary, which utilized simple "bag-of-words" methodologies to count positive and negative financial terms 34. While these lexicon-based approaches provided an initial mechanism to quantify sentiment, they suffered from significant structural limitations. They lacked context-awareness, struggled to process linguistic negations, and consistently failed to interpret the subtle contextual qualifiers routinely deployed in corporate disclosures and earnings calls 45.
The advent of transformer architectures, notably Bidirectional Encoder Representations from Transformers (BERT) and its finance-specific derivative, FinBERT, marked the first major evolution in financial natural language processing. FinBERT improved upon dictionaries by analyzing text bidirectionally, allowing for a deeper contextual understanding of financial news 166. However, early encoder models were still largely restricted to classification tasks and required extensive fine-tuning on manually labeled datasets, limiting their flexibility in dynamic market regimes.
The current paradigm shift is driven by Large Language Models (LLMs) featuring generative pre-trained transformer architectures operating with billions, or even trillions, of parameters. Unlike their predecessors, models such as OpenAI's GPT-4 and Anthropic's Claude 3 demonstrate zero-shot and few-shot reasoning capabilities, allowing them to perform complex financial deductions without explicit task-specific training 798. These models synthesize vast amounts of multimodal information - including news headlines, social media chatter, earnings call transcripts, and regulatory filings - extracting nuanced semantic signals, quantifying management tone, and identifying novel market events autonomously 21112. Consequently, the industry has rapidly transitioned from basic sentiment extraction to deploying LLMs as fully autonomous reasoning engines capable of generating formulaic alpha, optimizing portfolios, and acting as multi-agent algorithmic traders 9101112.
Mechanisms of Alpha Generation via Large Language Models
News Sentiment and Initial Market Reaction
The foundational application of large language models in quantitative alpha generation relies on their ability to ingest financial news and instantaneously classify its probable impact on asset prices. A highly influential 2023 study by Lopez-Lira and Tang established that GPT-class models, acting under the persona of a financial expert, could successfully predict the initial market response to news headlines 6813. By analyzing over 50,000 headlines published after the model's training data cutoff to theoretically eliminate look-ahead bias, the researchers found that GPT-4 could achieve daily portfolio hit rates of approximately 90% for correctly identifying the direction of initial price responses 8.
The simulated gross performance of these strategies was initially documented as unprecedented. A long-short portfolio driven entirely by GPT-4 news sentiment classifications yielded a reported 355% cumulative return over a two-year period, alongside a massive annualized Sharpe ratio of 3.05 614. This represented an alpha generation capability roughly nine times the contemporaneous Sharpe ratio of the value-weighted market portfolio (which stood at approximately -0.39 during the test period), decisively outperforming older dictionary-based methods and earlier models like FinBERT 67. The strength of this predictability was particularly pronounced among smaller-cap stocks and in the interpretation of negative news, aligning with established financial theories regarding limits to arbitrage and information diffusion frictions 78.
Subsequent iterations of this methodology expanded beyond simple polarity scoring (positive, negative, or neutral) to extract multi-label event classifications. Advanced LLMs dissect social media feeds and alternative data to identify specific drivers of market movements, such as retail investor buzz, regulatory inquiries, or rumors regarding mergers and acquisitions 24. Empirical backtesting indicates that portfolios built on these refined narrative structures exhibit robust information coefficients exceeding 0.05, demonstrating that LLMs capture complex linguistic features that traditional quantitative models miss 4.
Parsing Corporate Disclosures and Regulatory Filings
While high-frequency news headlines provide short-term sentiment signals, corporate disclosures such as SEC 10-K and 10-Q filings offer long-horizon alpha derived from fundamental business shifts. Traditional natural language processing pipelines struggle to capture the dense, legalistic narratives within SEC filings, but large language models excel at tracking "moving targets" - instances where corporate management subtly alters the metrics or risk factors they emphasize from one quarter to the next 5.
By employing an "LLM as extractor, embedding as ruler" framework, models isolate context-aware, metric-focused textual spans and quantify semantic changes over consecutive disclosure periods 5. This technique generates a signal that is highly predictive of cross-sectional stock returns. Analysis spanning three decades reveals the "Lazy Prices" anomaly: companies exhibiting significant year-over-year changes in their filing language ("big changers") underperform those with steady language by an average of 2.9% annually 15. This alpha signal has historically demonstrated resilience against rapid decay because it relies on structural market inefficiencies, including limited investor attention, the sheer complexity of dense regulatory text, and management's incentive to obscure negative developments through verbose rewrites 15.
Furthermore, LLMs drive efficiencies in the extraction of forward-looking metrics from earnings call transcripts. By quantifying business complexity through log probabilities or simulating managerial responses under stress, generative AI provides alternative data features that serve as critical inputs for downstream machine learning pricing models, integrating seamlessly into broader "quantamental" pipelines 1216.
Multi-Agent Architectures for Factor Mining
As the field matures, single-prompt sentiment analysis is being superseded by multi-agent LLM systems designed to mirror the organizational structure of quantitative hedge funds. Frameworks such as TradingAgents, FinCon, and FS-ReasoningAgent decompose the trading task into specialized, interacting roles 1012211718.
A typical multi-agent architecture features a Fundamentals Analyst evaluating corporate balance sheets, a Sentiment Analyst parsing social media noise, and a News Analyst interpreting macroeconomic events. These specialized nodes feed outputs into a central Portfolio Manager agent that synthesizes the competing narratives to generate final trading weights and risk-adjusted allocations 1121.
| Multi-Agent Framework | Primary Architecture and Roles | Key Mechanism for Alpha Generation | Reported Market Application |
|---|---|---|---|
| FinCon | Hierarchical selection agent and conceptual verbal reinforcement. | Balances risk-adjusted returns (Sharpe optimization) with portfolio diversification (low inter-stock correlation). | General equity markets; automated portfolio optimization 101819. |
| TradingAgents | Distributed specialist roles (Fundamentals, Sentiment, News, Risk). | Collaborative debate and hierarchical feedback to refine trading hypotheses before execution. | Broad asset class application; simulates a complete fund infrastructure 1221. |
| FS-ReasoningAgent | Bifurcated reasoning nodes separating factual data from subjective opinion. | Dynamic reliance on subjective sentiment in bull markets and factual constraints in bear markets. | Cryptocurrency markets; regime-aware dynamic trading 1725. |
A critical discovery in multi-agent financial reasoning is the necessary separation of factual data from subjective opinion. Empirical studies in cryptocurrency trading utilizing the FS-ReasoningAgent framework reveal that stronger LLMs generally default to preferring factual information over subjectivity 17. However, separating the reasoning process yields distinct regime-based advantages: relying on subjective news sentiment generates higher alpha during bull markets, whereas focusing strictly on factual, quantitative data yields superior protection and outperformance in bear markets 1725.
These agentic systems also employ advanced reinforcement learning methodologies, such as Proximal Policy Optimization (PPO), to dynamically rebalance the weights of multiple LLM-generated alpha factors (e.g., momentum, liquidity, and sentiment). This adaptive capability allows the system to shift its signal reliance based on evolving market conditions, theoretically mitigating factor decay and preventing strategy homogenization 11.
Performance Benchmarking and Model Comparisons
Domain-Specific Models Versus General-Purpose Models
The deployment of large language models in finance has triggered a rigorous debate between utilizing massively scaled, general-purpose frontier models (such as OpenAI's GPT-4 or Anthropic's Claude 3) versus highly specialized, domain-specific models (such as BloombergGPT or FinGPT).
BloombergGPT initially set the standard for domain-specific models. It was developed as a 50-billion parameter model trained on a massive mixed corpus: a proprietary 363-billion token financial dataset sourced from four decades of financial documents, combined with 345-billion tokens from public general datasets 6112620. The infrastructure required to train BloombergGPT was substantial, utilizing 512 NVIDIA A100 GPUs over 53 days, representing an estimated computational investment of $3 million to $10 million 20. The model demonstrated a significant advantage in specialized, highly structured tasks like Named Entity Recognition (NER) and entity disambiguation, outperforming general models on targeted financial corpora 2620.
Simultaneously, open-source initiatives like FinGPT sought to democratize domain-specific capabilities. FinGPT utilizes Parameter-Efficient Fine-Tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA), to fine-tune foundational models continuously on real-time financial data. This methodology maintains contextual relevance and dissemination awareness without the prohibitive cost of training an entire model from scratch 628.
| Model Name | Parameter Scale | Training Data Composition | Key Capabilities and Design Philosophy |
|---|---|---|---|
| BloombergGPT | 50.6 Billion | 363B proprietary financial tokens; 345B general public tokens. | Closed-source. Excels in structured tasks like Named Entity Recognition. High initial compute investment 112620. |
| FinGPT | Variable (LoRA based) | Dynamic real-time internet-scale financial data curation. | Open-source. Emphasizes lightweight adaptation and continuous updating to prevent temporal knowledge decay 628. |
| InvestLM | 65 Billion (LLaMA base) | Curated financial investment datasets and instruction tuning. | Focuses on advanced investment reasoning, bridging open-source accessibility with commercial-grade performance 619. |
Despite the specialized architecture of domain models, empirical evidence increasingly shows that as general-purpose models scale, they dominate complex financial reasoning. Studies matching BloombergGPT against GPT-4 reveal that despite lacking specialized financial pre-training, GPT-4 vastly outperforms the domain model on financial question-answering tasks. For example, GPT-4 achieved 68.79% zero-shot accuracy on the FinQA benchmark compared to BloombergGPT's 43%, and similarly dominated the ConvFinQA benchmark (76% versus 43%) 20. The current consensus across rigorous benchmarks suggests that proprietary, general-purpose LLMs hold a distinct advantage over both open-source and early domain-specific models, particularly in volatile market conditions requiring multi-step logical deductions rather than simple entity extraction 10.
Evaluating Financial Numerical Reasoning
To rigorously evaluate how models handle complex, multi-step quantitative reasoning involving financial concepts, asset pricing formulas, and temporal statement analysis, researchers utilize specialized, highly challenging datasets like the FinanceReasoning benchmark. This benchmark moves beyond simple classification, requiring models to process longitudinal tracking, cross-entity comparisons, and precise numerical logic across thousands of financial documents 21223132.
Recent evaluations on the "Hard" subset of these benchmarks highlight the current frontier of artificial intelligence capabilities, showing high performance from the Claude and GPT families, alongside the token efficiency of varying architectures.
| LLM Model | Accuracy on FinanceReasoning (%) | Token Consumption | Architectural Notes and Efficiency |
|---|---|---|---|
| Claude Opus 4.8 | 89.08% | 113,434 | Highest overall accuracy; extremely high token efficiency compared to peers 22. |
| OpenAI o1 (with PoT) | 89.10% | N/A | Highest absolute performance achieved using Program-of-Thought (PoT) prompting methods 32. |
| GPT-5 (Aug 2025) | 88.23% | 829,720 | Strong accuracy but highly resource-intensive in output token generation 22. |
| Claude Opus 4.6 | 87.82% | 164,369 | Near-top performance with moderate token consumption, providing strong cost-efficiency 22. |
| GPT-5-Mini | 87.39% | 595,505 | Strong alternative within the GPT ecosystem for balancing speed and logic 22. |
| Gemini 3.5 Flash | 86.97% | 1,191,757 | Highest accuracy in Google's Flash line, but the heaviest token consumer among top-tier models 22. |
Despite these high scores, LLMs continue to exhibit severe vulnerabilities in practical deployment. When tasks shift from single-document analysis to cross-entity longitudinal analysis, model accuracy systematically degrades by 14% to 19% 2133. This degradation is driven by rising "comparison hallucinations," time mismatches, and entity conflation 2133. Furthermore, evaluations using the Zero-Error Horizon (ZEH) metric demonstrate that even state-of-the-art models like GPT-5.2 occasionally fail on foundational algorithmic tasks, such as determining the parity of short binary strings or tracking basic parentheses balancing, underscoring the risk of relying on LLMs for unsupervised numerical execution in live trading environments 34.
Methodological Flaws in Large Language Model Backtesting
While gross performance metrics reported in early academic literature appear revolutionary, deploying these LLM-driven strategies into live trading environments routinely reveals catastrophic performance decay. This discrepancy is largely attributed to severe methodological flaws in LLM backtesting. Researchers have formally categorized these flaws as the "Five Sins" of financial LLM evaluation: look-ahead bias, survivorship bias, narrative bias, objective bias, and cost bias 23. These biases frequently compound to create an "illusion of validity," where strong performance numbers coexist with systems that are mechanically impossible to deploy 23.
Look-Ahead Bias and Training Data Contamination
The most pervasive and damaging flaw in current financial LLM research is look-ahead bias, which manifests primarily through training data contamination 3624252627. Financial forecasters traditionally isolate testing data strictly out-of-sample, ensuring a predictive model cannot peek into the future. However, foundation models are pre-trained on internet-scale corpora containing decades of historical pricing, global news events, and post-hoc market analyses up to their specific knowledge cutoff dates 362526.
If a quantitative backtest runs a simulation over the year 2021 using an LLM trained on data scraped through 2023, the model has already "seen" the future 242528. It possesses latent parametric knowledge of ensuing earnings surprises, macroeconomic shifts, regulatory interventions, and ultimate stock trajectories 2328. Consequently, the model generates spectacular, inflated backtest returns not because it possesses superior financial reasoning, but because it is successfully reciting memorized history 2528. The mere existence of a stated knowledge cutoff does not guarantee the exclusion of post-cutoff information, as temporal knowledge boundaries in closed-source models remain highly opaque 23.
The Scaling Paradox in Financial Forecasting
The profound impact of look-ahead bias gives rise to a phenomenon documented in the benchmark study Look-Ahead-Bench as the "Scaling Paradox" or "Inverse Scaling" 2527. When contaminated foundation models are pushed past their temporal knowledge cutoffs into genuinely unseen market regimes, their performance completely collapses.
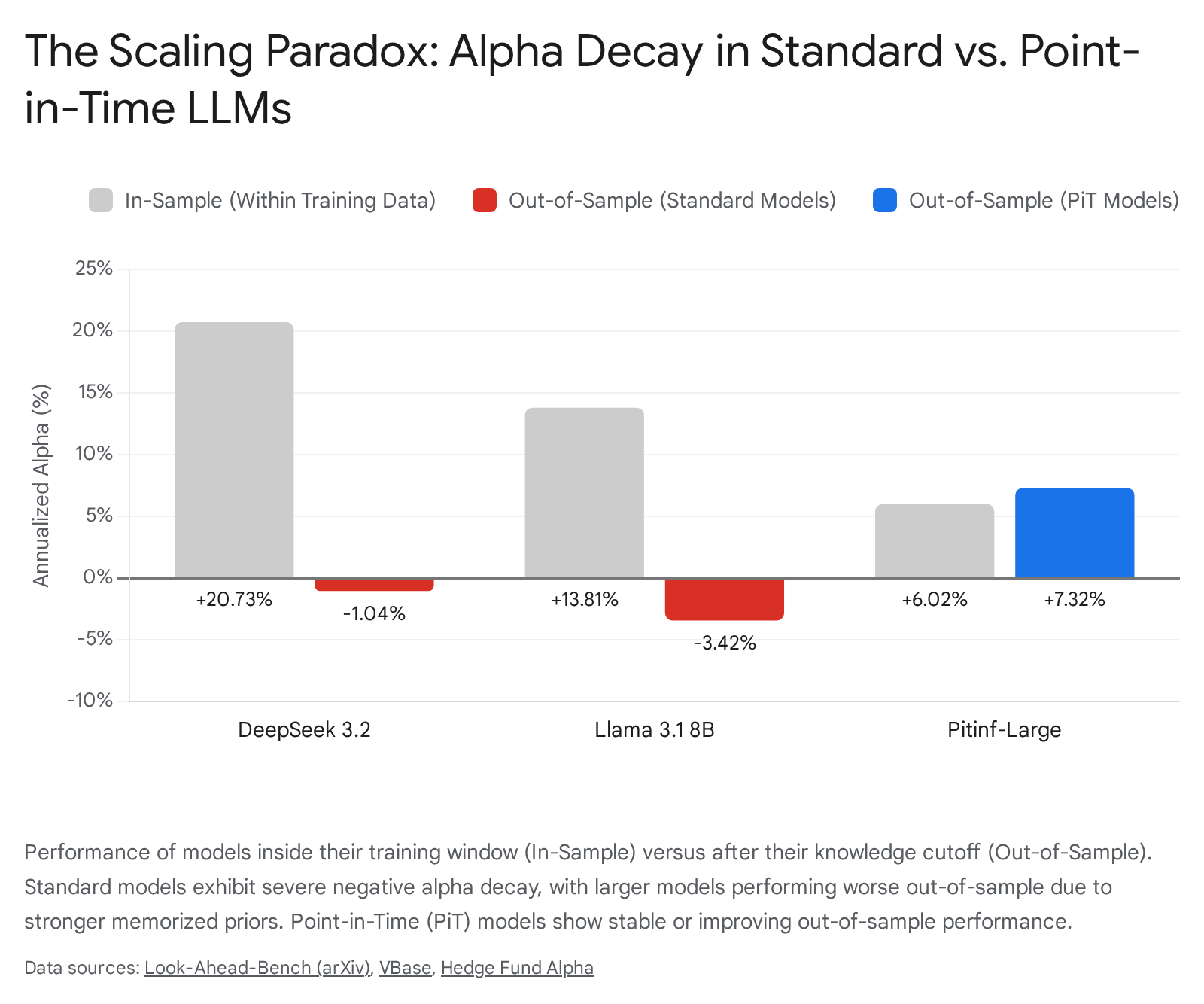
Standard assumptions in machine learning scaling laws dictate that larger models inherently yield better reasoning capabilities. However, rigorous out-of-sample testing proved the opposite for contaminated models: the 70-billion parameter version of Llama 3.1 actually performed worse out-of-sample than the much smaller 8-billion parameter version 2527. DeepSeek 3.2, utilizing 671 billion parameters, exhibited the highest in-sample annualized alpha (+20.73%) due to its vast memory, but suffered a catastrophic out-of-sample decay of -21.77 percentage points, dropping to a negative alpha of -1.04% 262728.
The paradox occurs because larger models have vast memorization capacities, developing rigid, "photographic" priors of historical data. When these models encounter genuinely new market conditions outside their training windows, these rigid priors become a profound liability, overriding the model's ability to adapt to new regimes 252728.
Evaluating Point-in-Time Architectures
To construct deploying strategies, quantitative researchers are increasingly shifting toward "Point-in-Time" (PiT) models. These specialized LLMs are designed with strict chronological data partitioning, ensuring their knowledge cutoffs strictly precede any testing period, thereby eliminating temporal data leakage by design 242526.
When evaluated under the Look-Ahead-Bench framework, PiT models do not exhibit the Scaling Paradox. Because they are untainted by future data, they are forced to rely on genuine deductive reasoning rather than memorized history 252628. Consequently, PiT models display positive alpha decay - meaning their performance remains highly stable or improves slightly when transitioning to out-of-sample data 2728. Furthermore, they follow normal scaling laws: larger PiT models achieve higher out-of-sample alpha than smaller PiT models, yielding excess returns of approximately 7% over passive buy-and-hold baselines across diverse test periods 2528.
| Model Category | Model Name | In-Sample Alpha (Apr-Sep 2021) | Out-of-Sample Alpha (Jul-Dec 2024) | Alpha Decay (Percentage Points) |
|---|---|---|---|---|
| Standard LLM | DeepSeek 3.2 | +20.73% | -1.04% | -21.77 pp 262728 |
| Standard LLM | Llama 3.1 8B | +13.81% | -3.42% | -17.23 pp 252627 |
| Standard LLM | Llama 3.1 70B | +19.27% | +4.02% | -15.25 pp 252627 |
| Point-in-Time (PiT) | Pitinf-Small | +3.12% | +3.43% | +0.31 pp 27 |
| Point-in-Time (PiT) | Pitinf-Large | +6.02% | +7.32% | +1.30 pp 2728 |
Market Frictions and the Cost Bias
Even if a large language model is chronologically uncontaminated, the performance metrics widely reported in academic literature frequently suffer from cost bias by relying exclusively on gross returns rather than net returns. In quantitative finance, the economically relevant quantity is the net return ($R_{net}$), mathematically defined as the gross return ($R_{gross}$) minus transaction costs ($C_{trans}$) and model inference and operational costs ($C_M$) 23. A system that appears to generate massive alpha in a frictionless theoretical environment often yields devastating negative returns once realistic transaction costs, API inference pricing, and execution slippage are applied 2342.
Inference Latency and Execution Slippage
Systematic academic backtests routinely assume a zero-delay instantaneous execution between the generation of a trading signal and its fill in the market. However, LLM inference is inherently computationally heavy and time-consuming 2343. The processing time required for thousands of tokens to generate, combined with multi-step chain-of-thought reasoning and data retrieval processes, introduces a measurable generation latency ($\Delta_{gen}$) 23.
In fast-moving financial markets, this latency results directly in execution slippage. By the time an LLM concludes its reasoning process and issues a trade command via an API, the market price has already shifted from the original observation price ($P_t$) to a new, often less favorable execution price ($P_{t+\Delta_{gen}}$) 234445. For short-horizon momentum strategies attempting to trade on breaking news, an inference delay of mere seconds can erode the entire informational advantage 623. Studies indicate that failing to model this implementation delay artificially inflates gross output and completely obscures the net economic utility of the AI agent 23.
Transaction Costs and Turnover Constraints
LLM-driven sentiment strategies typically exhibit extremely high turnover, generating frequent trading signals based on intraday news flows or rapidly evolving social media sentiment. High-frequency rebalancing incurs substantial explicit transaction costs, including brokerage commissions, exchange fees, and regulatory taxes, alongside severe implicit costs such as bid-ask spread crossing and the market impact of moving large volumes of capital 4445.
While the average annual transaction cost for a traditional actively managed U.S. mutual fund is estimated at 1.44%, the friction for hyper-active algorithmic strategies is vastly more severe 29. Research analyzing daily-rebalanced Global Tactical Asset Allocation models demonstrates that the simple act of executing rapid trades can erode returns by up to 6.2% annually, turning theoretical backtest profits of 3.9% into deep cumulative losses over a decade 42. Momentum-based LLM signals are particularly vulnerable to this form of slippage, as they structurally attempt to acquire liquidity in the exact same direction the market is already rapidly moving 44.
Consequently, deployment-ready frameworks must incorporate rigorous turnover constraints, optimal execution algorithms, and slippage-aware reinforcement learning environments to ensure survival in live markets 4229. When rigorous cost models are applied to agentic frameworks like TradingAgents or QuantAgent, portfolio Sharpe ratios frequently drop by more than half, often ending below simple passive buy-and-hold benchmarks 47.
Signal Crowding and Alpha Decay
The Compression of Signal Half-Lives
As large language models become universally adopted across the asset management industry, the market fundamentally alters the longevity of semantic alpha. Alpha decay refers to the rate at which a trading signal loses its predictive power as market participants discover and exploit the inefficiency 48. In the pre-LLM era, alternative data alpha derived from dense regulatory filings or unstructured text could survive for days, weeks, or even years because very few institutions possessed the specialized quantitative infrastructure necessary to parse it at scale 61549.
The proliferation of LLMs has violently compressed this timeline. Market tracking data indicates that the directional accuracy of GPT-4 on trading news sentiment started 2024 at a highly predictive 62%, but ground down to a statistical coin-flip (approximately 51%) by late 2025 6. As thousands of market participants run identical models over the exact same real-time Reuters and Bloomberg API feeds, the window to fade or follow a news event shrinks from hours to mere milliseconds 6. The 355% gross returns documented in the seminal 2023 papers represent a temporal anomaly - a brief window of successful, monopolistic arbitrage before the technology became an industry standard 6.
This decay dynamic extends beyond news sentiment into regulatory data. Institutional positioning data, such as SEC Form 13F filings, which operate on a 135-day reporting lag, are completely arbitraged away by AI flow-tracking models well before the filings become public, rendering the regulatory transparency effectively useless for delayed alpha generation 30.
Algorithmic Monoculture and Systemic Equilibrium
This rapid decay is a direct mathematical consequence of "algorithmic monoculture." When multiple quantitative funds train foundation models on the exact same historical datasets, utilize identical fine-tuning architectures, and draw from the same open-source prompt repositories, their resultant trading signals become highly correlated 1249.
This institutional convergence triggers a signal extinction cascade. Advanced mathematical models of AI-driven alpha decay show that the half-life of a signal is convex-decreasing relative to AI adoption metrics in the market 49. Under baseline calibrations for modern technological adoption rates, the half-life of medium-frequency predictive factors has collapsed from 5 to 7 years in the pre-AI era to approximately 18 months today, with high-frequency news signals decaying almost instantly upon publication 49.
This paradigm creates a systemic "Red Queen" competition: asset managers must heavily invest millions in LLM infrastructure and compute simply to maintain performance parity with their peers, yet in the resulting monoculture equilibrium, the aggregate net alpha generation approaches zero despite the massive technological expenditure 49.
Synthesis and Future Outlook
Large language models represent an undeniable paradigm shift in financial analysis, successfully bridging the historical gap between rigorous quantitative mathematics and fundamental, narrative-driven investing. GPT-class models have definitively proven their capacity to parse complex corporate disclosures, quantify nuanced sentiment, and extract previously inaccessible signals from massive troves of unstructured text.
However, the assertion that LLMs can easily and consistently generate tradable, net alpha is heavily qualified by empirical reality. The spectacular backtested returns found in early research are largely illusory - artifacts of pervasive look-ahead bias, training data contamination, and a widespread academic failure to account for real-world execution frictions such as latency, slippage, and transaction costs. The Scaling Paradox clearly demonstrates that standard frontier models often regress in genuinely novel market regimes due to their reliance on memorized historical priors, necessitating a permanent pivot toward strictly isolated Point-in-Time architectures for any serious deployment.
Ultimately, market efficiency is a direct byproduct of technological adoption. As LLM capabilities become ubiquitous, the alpha generated from fast-moving news sentiment is rapidly arbitraged away by competing algorithms, compressing the half-life of information to near zero. The enduring value of large language models for trading analysts does not lie in low-latency news arbitrage, but in their ability to process slow-moving, highly complex, and long-horizon alternative data, serving as sophisticated, auditable tools within a broader, rigorously governed quantitative pipeline.