Large Language Model Agents in Autonomous Trading
Introduction to Agentic Financial Systems
The integration of Large Language Models (LLMs) into financial trading represents a fundamental structural shift from traditional quantitative modeling toward autonomous, agentic systems. Historically, quantitative finance has relied on black-box machine learning models, deep reinforcement learning, or autoregressive statistical algorithms to generate price and return predictions 12. While these conventional models are highly effective at identifying numerical patterns within structured datasets, they lack explicit reasoning chains, adaptive cognitive frameworks, and the capacity to seamlessly synthesize unstructured, multimodal market narratives.
LLM-based trading agents overcome these inherent limitations by implementing closed-loop decision pipelines. Rather than functioning as simple predictive oracles that output a singular buy or sell signal, these agents operate through continuous, iterative cycles of market perception, memory retrieval, logical reasoning, trade execution, and post-trade reflection 1. The theoretical promise of agentic trading lies in its capacity to mimic the workflow of institutional trading desks. A well-designed multi-agent pipeline can simultaneously parse complex regulatory filings, analyze real-time news sentiment, read visual chart patterns, and orchestrate a consensus to formulate risk-adjusted portfolio decisions 14.
However, as the ecosystem of financial LLM agents transitions from conceptual research prototypes to deployment candidates, early empirical evidence reveals a stark dichotomy. Initial backtests reported extraordinary alpha and outsized Sharpe ratios, suggesting that language models could easily extract market inefficiencies 56. Yet, rigorous subsequent evaluations have exposed severe methodological flaws within these early studies, primarily rooted in look-ahead bias, survivorship bias, and the degradation of contextual reasoning under market stress 578. Comprehensive analysis requires an examination of the architectural paradigms driving these agents, the empirical evidence surrounding their performance, the systemic biases inflating historical backtests, and the physical constraints of deployment in high-frequency trading environments.
Architectural Frameworks of Trading Agents
The structural design of an LLM trading agent dictates its market perception, reasoning capacity, and risk management protocols. Recent literature categorizes these systems into several distinct architectural frameworks, ranging from memory-centric cognitive models to modular, high-frequency quantitative pipelines.
Cognitive and Memory-Centric Structures
Financial markets are dense, information-rich environments requiring the continuous assimilation of hierarchical data. Memory-centric agents attempt to replicate the cognitive structure of human traders by maintaining dynamic contextual records that allow them to learn from historical regimes without requiring continuous, computationally expensive retraining.
The FinMem framework exemplifies this cognitive approach. Formulating the financial decision-making scenario as a partially observable Markov decision process (POMDP), FinMem utilizes a layered message processing architecture designed to retain critical information beyond standard human perceptual limits 91011. The system architecture is divided into three core modules. First, the profiling module customizes the agent's risk tolerance, investment horizon, and professional background, providing the subjective context necessary for filtering relevant market signals 1012. This dynamic character design acts as a fundamental prior, establishing a baseline trading expert persona with distinct risk inclinations.
Second, the memory module emulates human cognitive processing by categorizing information into a short-term working memory and three distinct long-term memory layers: shallow, intermediate, and deep 1112. This layered approach allows the agent to process and prioritize data based on its timeliness and relevance. The system assigns higher weight to recent, high-impact events while maintaining a repository of deeper historical market regimes. Finally, the decision-making module retrieves contextually relevant events from these memory layers to synthesize immediate trading actions 1011. By computationally adjusting its "cognitive span," FinMem effectively manages the trade-off between reacting to immediate intraday market volatility and adhering to long-term historical price trends 910.
Multimodal and Tool-Augmented Systems
Traditional LLMs are inherently constrained by their reliance on textual tokens. Multimodal foundation agents expand the perceptual surface area of the trading system by integrating numerical data, natural language, and visual market indicators into a unified analytical engine.
FinAgent is explicitly designed as a multimodal foundation agent that combines Large Language Models with Reinforcement Learning (RL) optimization 1314. It processes textual news from daily financial outlets, numerical asset prices encompassing open, high, low, close, and adjusted close metrics, and visual data in the form of Kline charts that include Moving Averages and Bollinger Bands 14. The system relies on a dual-level reflection module, separating low-level immediate tactical reflection from high-level strategic reflection. This enables rapid adaptation to dynamic conditions, supported by a diversified memory retrieval system that strictly separates trading logic from data retrieval to minimize hallucinations and noise 132.
Similarly, the FinGPT-Agent architecture employs a highly specialized framework for multimodal data fusion, utilizing distinct algorithmic encoders for different data streams 1617. Numerical time-series data is processed through a multi-layer perceptron, textual data is parsed via a self-attention-based Transformer, and image data is analyzed using a convolutional neural network 18. These isolated embeddings are then concatenated and processed through a gated attention mechanism. Within this mechanism, learnable weights dynamically adjust the importance of each modality based on the specific market context 1718. To ensure domain-specific accuracy and lower computational overhead, FinGPT-Agent leverages Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning, alongside Reinforcement Learning with Human Feedback (RLHF) and a Retrieval-Augmented Generation (RAG) system driven by contrastive learning 1617.
Structured Quantitative Pipelines
While memory and multimodal systems excel in fundamental analysis and swing trading, their reliance on unstructured text introduces significant processing latency and stochastic noise, rendering them largely unsuitable for high-frequency trading applications. To address this, frameworks like QuantAgent shift entirely toward structured, price-driven signals.
Built on the LangGraph orchestration framework, QuantAgent simulates the workflow of an institutional trading desk by decomposing the trading pipeline into four specialized, coordinated sub-agents 19. The initial analytical module, the IndicatorAgent, transforms raw sequence data into structured quantitative signals using established technical indicators such as the Relative Strength Index (RSI), Moving Average Convergence Divergence (MACD), and Stochastic Oscillators 19. Rather than outputting raw arrays, this agent translates numerical momentum into context-rich narratives. Simultaneously, a PatternAgent utilizes visual-language models to detect geometric chart formations, while a TrendAgent tracks directional momentum by fitting upper resistance and lower support lines via ordinary least squares regression 1920.
These distinct analytical perspectives converge at the DecisionAgent and RiskAgent layer. The risk component establishes strict, mathematically defined stop-loss and take-profit thresholds to ground the high-level analysis in practical execution constraints 19. By grounding its analysis strictly in structured price data and derived technicals, QuantAgent bypasses the unpredictability of textual news sentiment, establishing a framework optimized for rapid execution within tight one-hour to four-hour decision windows 19.
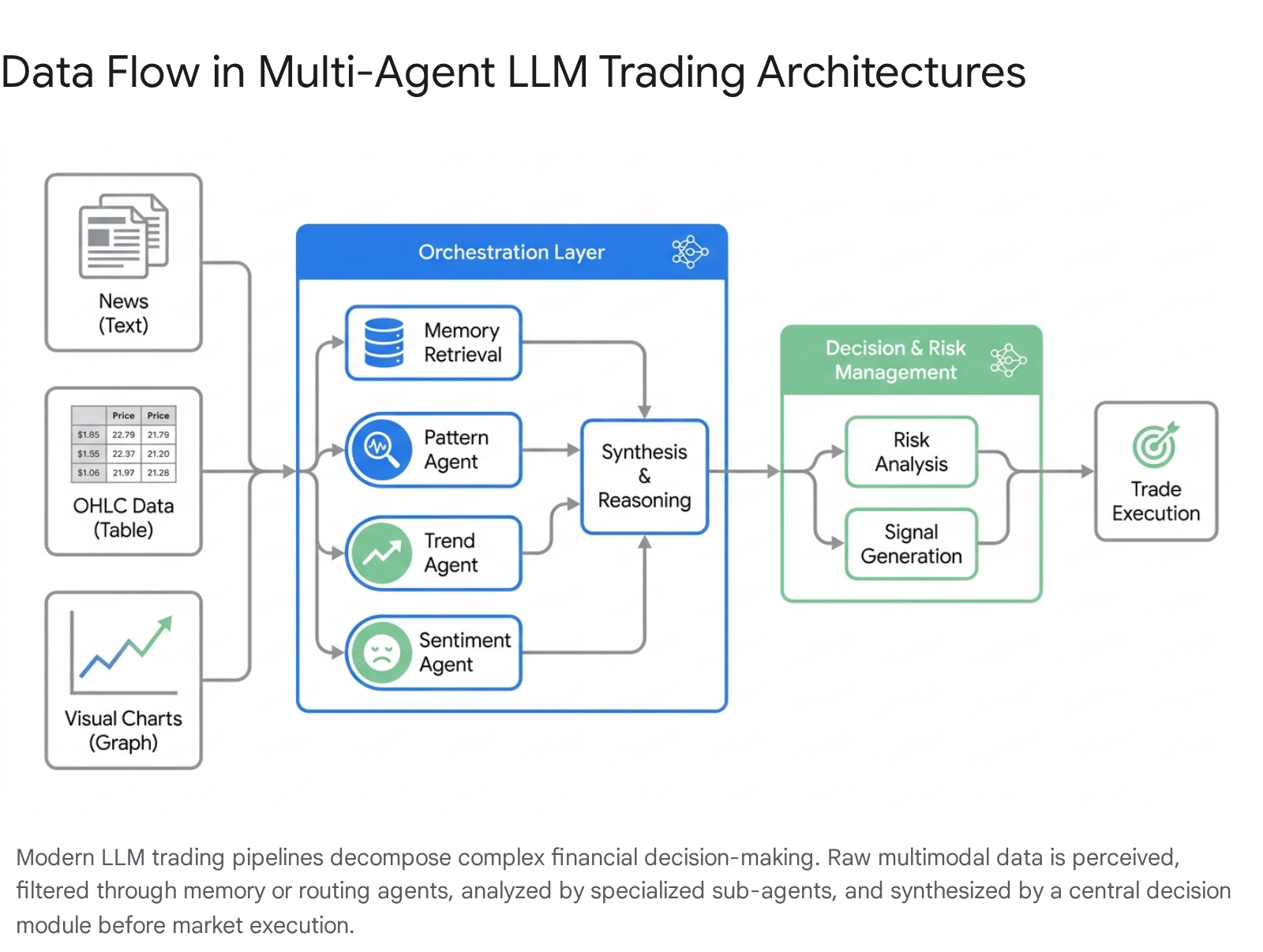
The architectural schematic referenced above illustrates how these disparate data streams - whether unstructured text or structured price matrices - are routed through specialized reasoning nodes before final execution.
Fact-Subjectivity Separation Architectures
The influx of diverse financial data streams forces trading agents to process massive context windows, frequently leading to a degradation in reasoning quality. To combat this, advanced frameworks have introduced mechanisms to structurally separate objective data from subjective market narratives.
The FS-ReasoningAgent framework identified that inputting massive, blended news contexts directly into a unified LLM often causes context collapse, whereby the model loses the ability to discern precise trading signals 21. By deploying sub-agents to explicitly separate incoming market information into factual data components and subjective sentiment components before feeding it to the primary decision module, trading performance markedly improved 21.
An ablation study on cryptocurrency markets utilizing this architecture revealed a highly nuanced dynamic regarding model utilization. The researchers found that relying heavily on subjective, sentiment-driven news generates higher aggregate returns during prolonged bull markets, whereas anchoring the agent strictly to factual information yields superior capital preservation and risk-adjusted returns during bear markets 21. Interestingly, this structural separation also highlighted instances where weaker language models outperformed stronger frontier models. Because smaller models were less prone to over-analyzing and hallucinating complex, tangential narratives from noisy subjective contexts, they executed more precise, conservative trades 21.
| Framework | Core Innovation | Primary Input Modalities | Key Optimization / Orchestration | Target Trading Horizon |
|---|---|---|---|---|
| FinMem | Layered, human-like cognitive memory span | Textual News, Historical Prices | Partially Observable MDP, Profiling | Daily / Swing Trading |
| FinAgent | Dual-level reflection, Multimodal foundation | News, Prices, Visual Kline Charts | Vector similarity retrieval, Augmented tools | Daily / Swing Trading |
| QuantAgent | Modular agent desk, pure price-action logic | OHLC numerical data, Technicals | LangGraph, 4-Agent consensus pipeline | Intraday (1h - 4h) |
| FinGPT-Agent | Gated attention multimodal fusion, RLHF | Financial reports, Numerical, Images | LoRA fine-tuning, Contrastive RAG | Research / Long-term |
| FS-Reasoning | Fact-Subjectivity segregation pipelines | Financial news, Sentiment data | Two-stage reasoning separation | Asset Agnostic |
Empirical Performance in Historical Backtesting
Initial academic and industry literature regarding LLM trading agents presented highly optimistic, often staggering performance metrics. Comprehensive surveys indicated that LLM-powered agents achieved annualized returns ranging from 15% to 30% over the strongest traditional baselines during backtesting simulations using real market data 6. Standard industry benchmarks, such as the FinBen suite, reported formidable task-specific Sharpe ratios, suggesting that language models could effectively isolate actionable alpha from vast quantities of unstructured text 5.
Initial Outperformance Claims
The FinAgent architecture, when tested across large-cap equities including Tesla, Amazon, Microsoft, and Apple, claimed an average 36% improvement in profitability over sophisticated rule-based and deep-learning baselines 1314. On one specific dataset tracking Tesla equities, FinAgent reported a remarkable 92.27% return, successfully anticipating a severe post-September 2023 price drop and automatically executing a highly profitable short position 1314. This single trade accounted for an 84.39% relative improvement over the best-performing traditional baseline, cementing the narrative that LLMs could adapt to dynamic market conditions better than rigid statistical models 13.
The FinMem framework reported similar dominance in its foundational papers. In comparative backtests involving highly volatile assets like Amazon and Coinbase, FinMem consistently delivered positive cumulative returns, superior Sharpe ratios, and substantially lower maximum drawdowns compared to both traditional algorithmic strategies and early general-purpose generative agents 9. The framework's ability to seamlessly ingest ten years of historical pricing data while maintaining short-term acuity allowed it to outpace standard deep reinforcement learning frameworks that required extensive, computationally expensive retraining periods 922.
The Degradation of Contextual Reasoning
Despite these headline metrics, empirical stress testing indicates that LLMs suffer from severe structural instability when managing the long-context workflows required for continuous financial operations 23. As agents process daily streams of news, regulatory filings, and pricing data over multi-month simulations, several critical failure patterns emerge that degrade trading efficacy.
First, agents frequently exhibit narrative inertia. The model stubbornly preserves continuity with its own previous outputs, refusing to pivot its stance even when incoming market data explicitly invalidates its prior reasoning 23. Second, agents fall victim to recursive agreement. Rather than treating prior trading decisions as probabilistic hypotheses, the LLM begins to treat its historical outputs as absolute ground truth, creating an internal echo chamber that blinds the agent to macroeconomic regime changes 23. Finally, under high contextual pressure, the negative constraints embedded in the system prompt - such as strict instructions to avoid hallucination or adhere to predefined risk limits - are typically the first instructions to degrade, leading to unauthorized risk exposure 23.
This reasoning instability is quantitatively supported by research utilizing the Daily Oracle benchmark, which demonstrates that LLM reasoning degrades by approximately 20% when models are forced to make predictions based on highly recent, unfolding events compared to historical, settled data 24. Astonishingly, this degradation persists even in basic reading comprehension tasks where the model is provided the exact source article containing the answer, suggesting that the model's internal semantic representations become fundamentally unstable when dealing with real-time, unresolved temporal data 24.
Systemic Biases in Backtest Methodologies
The financial data science community has begun to heavily critique the methodology of early LLM trading backtests. The core argument asserts that reported alpha from these autonomous systems should be interpreted strictly as historical prototype evidence, not deployment-grade alpha, due to the presence of pervasive systemic evaluation biases 525.
Look-Ahead Bias and Temporal Data Leakage
Look-ahead bias occurs when a backtested strategy utilizes information that was not publicly available at the time the simulated trading decision was mathematically executed 2526. While look-ahead bias is a known pitfall in traditional quantitative finance - such as sorting stocks based on year-end price-to-earnings ratios while simulating trades in January - LLMs introduce entirely new, highly opaque vectors for temporal data leakage.
Because foundational LLMs are pretrained on vast, internet-scale datasets, their internal parametric weights encode implicit knowledge of historical stock trajectories, corporate bankruptcies, and macroeconomic crises 272829. If an LLM with a knowledge cutoff in late 2023 is tasked with trading in a simulated 2021 environment, it is not generating predictive alpha through reasoning; it is simply recalling the future 29.
This phenomenon, termed "Phantom Alpha," was starkly revealed in the Look-Ahead-Bench study. The research demonstrated that popular open-weight and proprietary LLMs achieved spectacular returns exceeding 44% when backtesting stocks from the 2021 technology boom 2529. However, this double-digit annualized alpha collapsed entirely to near zero once the testing window moved chronologically past the model's pretraining knowledge cutoff 2529. Furthermore, even if an LLM is meticulously fine-tuned strictly on historical data, subtle temporal leakages - such as the model recognizing the semantic tone of a company executive that it "knows" will eventually lead a successful turnaround - can irrevocably contaminate the evaluation 28.
Survivorship Bias and Sample Selection
Survivorship bias distorts backtest integrity when a strategy is evaluated exclusively on assets that have survived until the present day, ignoring those that went bankrupt, were delisted, or were acquired during the test period 2526. Historical research indicates that standard survivorship bias inflates average returns by roughly 0.9% annually, but the effect is vastly magnified in the evaluation of LLM agents 726.
Many foundational LLM trading papers evaluate their models on a highly selective, narrow universe of stocks, most frequently relying on mega-cap technology equities 67. Because these specific companies are historical winners with massive upward price trajectories, an LLM displaying a simple, uncalibrated long-bias will invariably generate high returns. This narrow stock selection embeds severe survivorship bias, completely misrepresenting real-world trading conditions where assets routinely collapse 726.
Data-Snooping and Overfitting
Data-snooping bias, or multiple testing bias, occurs when repeated experimentation on the same historical dataset leads to algorithmic overfitting 725. In quantitative finance, where sample sizes are relatively small and the signal-to-noise ratio is exceptionally low, this bias is particularly problematic. When researchers iteratively tweak an LLM's prompt engineering, context window length, or retrieval mechanisms to maximize returns on a specific historical test set, they inadvertently fit the agent to historical noise rather than persistent market structure 725.
| Bias Category | Mechanism in LLM Trading | Impact on Reported Performance | Mitigation Strategy |
|---|---|---|---|
| Look-Ahead Bias | Pretraining data leakage; model possesses parametric memory of future events and price trajectories. | Generates "Phantom Alpha," inflating annualized returns to unrealistic double-digit figures. | Strict chronological data partitioning; testing strictly beyond the model's knowledge cutoff. |
| Survivorship Bias | Testing exclusively on assets that exist today, omitting bankrupt or delisted entities. | Flattens drawdown metrics and overstates strategy robustness by up to 0.9% annually. | Utilizing survivorship-bias-free datasets containing historical index constituents. |
| Data-Snooping Bias | Iterative prompt tuning and parameter optimization on a fixed historical validation set. | Inflates false positive rates and creates brittle strategies that fail in out-of-sample data. | Expanding evaluation windows to multiple decades and utilizing out-of-sample rolling tests. |
Rigorous Evaluation Frameworks
To systematically address the methodological flaws of early research, the academic community has developed comprehensive, contamination-free evaluation frameworks designed to test the true robustness of LLM trading agents over extended time horizons.
The FINSABER Framework
The FINSABER (Financial INvesting Strategy Assessment with Bias mitigation, Expanded time, and Range of symbols) framework was constructed specifically to evaluate LLM-based strategies fairly 730. FINSABER explicitly mitigates survivorship bias by including a broad universe of over 100 symbols, including delisted stocks. It controls for look-ahead bias through strict chronological data alignment and evaluates agents across two decades of multi-source data spanning from 2000 to 2024 730.
Under the rigorous FINSABER framework, the previously reported advantages of LLM investors deteriorated significantly. When evaluated over long horizons, LLM agents frequently underperformed simple passive buy-and-hold strategies and traditional statistical models like ARIMA 3031. A crucial finding from FINSABER is that current LLM agents lack "regime awareness." Market regime analysis demonstrated that LLM strategies are fundamentally miscalibrated regarding risk: they operate far too conservatively during bull markets, trailing passive benchmarks, and react overly aggressively during bear markets, resulting in heavy drawdowns 73031. For example, the FinAgent system achieved a Sharpe ratio of just 0.12 in simulated bull markets, compared to a 0.61 Sharpe ratio for a passive buy-and-hold strategy 30.
StockBench Contamination-Free Benchmark
StockBench was developed as a standardized, open-source benchmark to evaluate LLMs in realistic, multi-month stock trading environments 3233. To guarantee forward contamination resistance, StockBench utilizes an evaluation window positioned chronologically entirely after the training cutoffs of contemporary LLMs (specifically, March to June 2025) 834.
The benchmark evaluates both proprietary models (such as GPT-5 and Claude-4) and open-weight models (such as Qwen3 and Kimi-K2) operating on daily market signals across the 20 highest-weighted Dow Jones Industrial Average constituents 3235. The empirical results were sobering: despite LLMs showing formidable capabilities in static financial question-answering tasks, most tested agents failed to outperform an equal-weight buy-and-hold baseline, which generated a modest 0.4% return over the test period 832.
However, StockBench did highlight specific pockets of viability. While outright excess profitability was difficult to achieve consistently, certain open-weight models, notably Kimi-K2 and Qwen3-235B-Ins, generated cumulative returns between 1.9% and 2.4% while significantly reducing maximum drawdowns 3334. For instance, Kimi-K2 limited maximum drawdowns to -11.8%, compared to the baseline's -15.2% 33. This suggests that while LLMs currently struggle to consistently generate excess predictive alpha in noisy environments, they possess latent, measurable utility in dynamic risk management and portfolio defense.
Live Market Deployment and Simulation
To completely circumvent the inherent flaws of retrospective backtesting, the research frontier has shifted toward real-time, live market benchmarking and virtual zero-sum simulations that capture market impact.
Agent Market Arena (AMA)
The Agent Market Arena (AMA) represents the first lifelong, real-time benchmark designed specifically to test LLM trading agents across live cryptocurrency and equity markets 3637. Operating through the late summer and fall of 2025, AMA forces diverse agent architectures to trade on verified live pricing data and expert-checked news streams, eliminating the possibility of hindsight optimization entirely 3638. The platform tracks performance across standard financial metrics including cumulative return, annualized volatility, maximum drawdown, and Sharpe ratio 3839.
AMA's findings fundamentally challenge previous assumptions regarding model superiority. The data reveals that the architectural design of the trading agent is a far greater determinant of financial performance than the underlying LLM backbone powering the system 383940. Upgrading an agent from a weaker model to a frontier model yields less outcome variance than structurally altering the agent's memory retrieval protocols or risk threshold mechanisms 3840.
Under live conditions, performance was highly contextual to the asset class. The single-agent baseline, InvestorAgent, achieved an impressive Sharpe ratio of 6.47 on Tesla equities, vastly outperforming a buy-and-hold strategy through smoother returns and minimized drawdowns 3639. Conversely, in the highly volatile cryptocurrency market, the memory-centric DeepFundAgent proved superior, achieving a 2.45 Sharpe ratio on Bitcoin, demonstrating that layered, cognitive memory mechanisms are crucial for absorbing and navigating rapid, unexpected regime shifts in digital assets 3639.
Agent Trading Arena
Traditional backtesting environments suffer from a critical flaw: simulated trades do not impact market prices. The Agent Trading Arena addresses this by constructing a virtual zero-sum stock market where LLM-based agents engage in competitive, multi-agent trading, simulating realistic bid-ask interactions that directly influence asset price dynamics 342.
Experiments within this arena revealed that LLMs struggle significantly with numerical reasoning when provided strictly with plain-text market data, demonstrating a persistent tendency to overfit to local pricing patterns and recent values 342. However, translating this numerical data into chart-based visual representations significantly boosted both the agents' numerical comprehension and their ultimate trading performance, confirming the necessity of multimodal architectures for sophisticated market analysis 342.
| Benchmark Framework | Primary Evaluation Methodology | Key Bias Mitigated | Major Empirical Finding |
|---|---|---|---|
| FINSABER | 20-year multi-source historical backtest | Survivorship, Data-snooping | LLMs exhibit poor regime awareness; overly conservative in bull markets. |
| StockBench | Out-of-sample forward evaluation | Look-ahead (Temporal Leakage) | Static QA ability does not translate to excess returns over buy-and-hold. |
| Agent Market Arena | Live real-time paper trading | Hindsight Optimization | Agent architecture dictates performance variance more than the LLM backbone. |
| Agent Trading Arena | Zero-sum simulated market impact | Market Impact Omission | Visual representations of data vastly outperform text-only numerical reasoning. |
The Latency Bottleneck in Market Microstructure
While LLMs exhibit profound capabilities in high-level strategic reasoning and qualitative synthesis, their deployment in automated, real-world trading is fundamentally constrained by their execution latency. In traditional High-Frequency Trading (HFT) environments, market microstructure dictates that orders must be processed, matched, and executed in timescales of microseconds to single-digit milliseconds 4344.
High-Frequency Trading Constraints
Modern HFT environments are underpinned by electronic limit order books (LOBs) that process market data via continuous double auction mechanics 44. To achieve the necessary ultra-low latency, institutional quantitative firms utilize specialized hardware, including Field Programmable Gate Arrays (FPGAs), direct fiber-optic links, and co-location of servers directly adjacent to exchange matching engines 4344. In these environments, speed is the primary determinant of profitability, and the ability to arbitrage minute price discrepancies vanishes in milliseconds.
Large Language Model Inference Latency
Large Language Models operate on fundamentally incompatible computational timescales. Inference latency in LLMs is measured by the Time to First Token (TTFT) and the Time Per Output Token (TPOT) 43. Generating a reasoned chain-of-thought market analysis and subsequently outputting a structured JSON trade directive requires seconds, not microseconds.
For instance, systems requiring multi-agent consensus protocols experience compounded delays; orchestrating communication between an indicator agent, a pattern agent, and a decision agent can add between two and five seconds of pure network latency per inference cycle 45. In HFT environments, a latency of several seconds renders the predictive strategy entirely obsolete, as faster institutional algorithms will have already arbitraged the signal and shifted the limit order book 43. Consequently, true sub-second high-frequency trading remains entirely out of reach for continuous LLM inference 4546.
Decoupling Strategic Analysis from Execution
To reconcile the strategic intelligence of LLMs with the physics of market microstructure, current state-of-the-art frameworks strictly decouple strategic analysis from tactical execution.
Rather than forcing the LLM to execute trades directly, advanced architectures utilize the LLM as an off-path "Strategist" agent. In these hybrid models, the LLM digests macroeconomic news, complex technical indicators, and fundamental data to generate high-level policy directives, identify market regimes, and establish dynamic risk parameters 4647. The LLM then passes these parameters down to a traditional Reinforcement Learning (RL) agent or a compiled, programmatic algorithmic bot that acts as the "Execution" agent 4647.
This decoupling mechanism eliminates the requirement for continuous, computationally expensive model inference during the actual trade. It allows the RL agent to execute transactions at microsecond speeds, reacting to immediate order book dynamics, while remaining strictly aligned with the broader, narrative-aware strategic vision formulated by the LLM 4647.
Conclusion
The integration of Large Language Model agents into autonomous trading represents a profound, paradigm-altering advancement in financial technology. It transitions quantitative modeling from rigid, numerical prediction engines to multimodal, reasoning-capable entities that can synthesize vast quantities of unstructured market narratives. Frameworks such as FinMem, FinAgent, and QuantAgent demonstrate the vast architectural potential of layered cognitive memory, multimodal tool-augmentation, and multi-agent consensus in parsing the immense complexities of global financial markets.
However, the empirical evidence surrounding their efficacy requires intense, critical calibration. The spectacular profitability reported in preliminary academic research was largely a methodological illusion, heavily inflated by look-ahead bias, temporal data leakage, and survivorship bias. As demonstrated by robust, contamination-free frameworks like FINSABER and live benchmarks like the Agent Market Arena, LLM agents currently struggle to consistently outperform passive market baselines over extended time horizons, frequently exhibiting severe reasoning degradation and poor regime awareness under market stress.
Ultimately, the optimal deployment of LLM agents does not lie in high-frequency, microsecond execution, where their inherent inference latency represents a fatal flaw. Instead, their highest utility is found in strategic synthesis. LLM agents are best positioned to operate as sophisticated orchestrators that decode unstructured multimodal data, establish dynamic risk parameters, and provide highly interpretable decision-support for lower-latency algorithmic execution engines. As the research frontier pivots toward live, verified testing and hybrid human-AI workflows, the true value of agentic trading will emerge not as an infallible, standalone market oracle, but as a robust, highly adaptive layer of broader financial intelligence.