Financial and General Large Language Models for Alpha Generation
Introduction to Semantic Alpha and Market Prediction
The integration of natural language processing into quantitative finance has fundamentally altered the landscape of algorithmic trading. Historically, financial sentiment analysis relied upon rigid, lexicon-based approaches, such as the Loughran-McDonald dictionary or VADER, to parse corporate disclosures and financial news 12. These methodologies mapped words to predefined sentiment scores, offering high interpretability but failing to capture context-dependent modifiers, complex financial terminology, and subtle shifts in corporate tone. The advent of transformer-based architectures has introduced a new paradigm of semantic arbitrage, enabling market participants to extract highly nuanced, context-aware signals from unstructured data streams, including earnings call transcripts, regulatory filings, and macroeconomic news.
A central debate within contemporary quantitative research centers on the comparative efficacy of domain-specific financial language models against state-of-the-art general-purpose large language models. Domain-specific models, such as FinBERT and BloombergGPT, are explicitly trained on financial corpora to master the unique lexicon of capital markets. Conversely, general-purpose models, including OpenAI's GPT-4, Meta's Llama 3, and Anthropic's Claude 3, leverage massive parameter scales and vast internet-scale training data to achieve emergent analytical capabilities. Evaluating these models for alpha generation requires an exhaustive analysis of their zero-shot accuracy on financial benchmarks, their translation into actionable trading signals, their resilience to transaction costs, their latency profiles in real-time execution, and their susceptibility to data contamination.
As institutional investors increasingly rely on these computational tools, understanding the structural advantages and limitations of each architectural approach is paramount. The objective is not merely to classify text accurately, but to synthesize unstructured narratives into profitable, risk-adjusted trading strategies while navigating the complex market microstructures that dictate trade execution.
Architectural Paradigms and Computational Scale
The performance differential between financial and general-purpose models stems directly from their architectural scale, pre-training methodologies, and the composition of their underlying datasets. The landscape is broadly categorized into compact domain-adapted encoder models, massive domain-specific decoder models, and general-purpose frontier models.
Compact Domain-Specific Encoders
Domain-specific models are engineered to address the distinct linguistic characteristics of financial texts, which frequently feature highly specialized terminology, forward-looking statements, and numerical contextualization. FinBERT represents the canonical encoder-only architecture in this space. Built upon the foundational BERT framework, FinBERT models typically operate with approximately 110 million parameters 34. Rather than being trained from scratch, the model is pre-trained and fine-tuned on specialized financial corpora, such as Reuters news, corporate reports, and the Financial PhraseBank 34. Due to its compact size, FinBERT offers highly efficient inference and serves as a robust baseline for basic sentiment classification, capturing financial semantics far more effectively than traditional dictionaries 35.
Large-Scale Domain-Specific Decoders
BloombergGPT represents a monumental scaling of the domain-specific paradigm. Announced in March 2023, it is a 50.6-billion-parameter decoder-only model trained on a hybrid dataset totaling 709 billion tokens 56. The model architecture features 70 transformer layers with 40 attention heads and a hidden dimension of 7,680 6. To achieve training efficiency, the development team utilized ZeRO-3 optimization, combining SMP and MiCS sharding with activation checkpointing, and employed mixed-precision training with BF16 computation over 1.3 million GPU hours on 512 NVIDIA A100 GPUs 6.
The training corpus, named FinPile, constitutes 51.27% of the total data (363 billion tokens) and comprises four decades of proprietary Bloomberg archives, including news, SEC filings, press releases, and financial web-scraped documents 56. The remaining 48.73% (345 billion tokens) was drawn from public datasets such as The Pile, C4, and Wikipedia 8. This mixed-dataset approach was explicitly designed to retain general natural language capabilities while optimizing the model for financial tasks, yielding superior performance over similarly-sized open models like GPT-NeoX and OPT-66B on named entity recognition and financial news classification 5910.
Other notable open-source financial frameworks include FinMA (part of the PIXIU project), which is instruction-tuned on broad financial datasets to support multi-task financial context awareness, and FinGPT, a framework utilizing Low-Rank Adaptation (LoRA) to fine-tune existing models on financial data for rapid, cost-effective updates 11.
General-Purpose Frontier Models
In contrast, general-purpose models achieve financial competency as a byproduct of their immense scale and diverse training data. Models such as Llama 3.1 and GPT-4 operate on vastly different scales compared to legacy encoders. Llama 3.1, for instance, encompasses models ranging from 8 billion to 405 billion parameters, trained on over 15 trillion tokens 1213. GPT-4, while its exact parameter count remains proprietary, is estimated to operate at the trillion-parameter scale 6.
These models rely on extensive multi-domain exposure rather than exclusive financial pre-training. Their massive context windows - up to 128,000 tokens for GPT-4o and 131,072 for Llama 3.1 8B Instruct - allow them to process entire 10-K filings, extensive earnings call transcripts, or multiple research reports in a single prompt 715. While BloombergGPT outperforms comparable mid-sized general models on specific financial extractions, frontier models like GPT-4 consistently surpass domain-specific models in complex problem-solving, largely due to their parameter scale and advanced instruction-tuning 6.
| Model Specification | BloombergGPT | FinBERT | Llama 3.1 8B Instruct | GPT-4o |
|---|---|---|---|---|
| Parameter Count | 50.6 Billion | ~110 Million | 8 Billion | Proprietary (Est. >1T) |
| Training Tokens | 709 Billion | Task-Specific Finetuning | 15 Trillion | Proprietary |
| Context Window | 2,048 tokens | 512 tokens | 131,072 tokens | 128,000 tokens |
| Financial Data Mix | 51.27% Proprietary FinPile | 100% Financial Text | Unknown % of 15T | Unknown % |
| Access Model | Proprietary | Open Source | Community License | Proprietary API |
Performance on Financial Sentiment Benchmarks
To systematically quantify the capabilities of these models, the academic and quantitative finance communities utilize standardized natural language benchmarks, most notably the Financial PhraseBank (FPB) and the Financial Question Answering Sentiment Analysis (FiQA-SA) datasets. These datasets provide a rigorous environment for assessing a model's ability to interpret market sentiment, separating positive, negative, and neutral financial phrasing.
Zero-Shot and Few-Shot Evaluation Accuracy
Empirical evaluations demonstrate that advanced general-purpose models match or exceed the performance of domain-specific models on basic sentiment classification. In target-based financial sentiment analysis tasks, generative models such as ChatGPT-4, ChatGPT-o1, and DeepSeek-R1 have been shown to outperform discriminative transformer models like FinBERT and DistilFinRoBERTa across precision, recall, and F1-score metrics without requiring task-specific fine-tuning 289.
A comparative evaluation of FinMA, BloombergGPT, and GPT-4 reveals highly competitive zero-shot and few-shot capabilities. FinMA-7B achieves F1-scores of 87.0% on FPB and 79.0% on FiQA-SA in zero-shot settings, improving to 93.4% and 82.6% respectively in 5-shot configurations 18. However, GPT-4 and Llama-3 variants frequently approach or exceed these metrics. In specific sector-based news sentiment analyses, prompt-engineered implementations of GPT-4o outperformed FinBERT by up to 10% in accuracy depending on the sector 19. Even smaller open-weight models, such as Llama-3-8B, have demonstrated stable accuracy nearing 88.9% on PhraseBank and 81.7% on FiQA-SA when utilizing parameter-efficient fine-tuning techniques like QLoRA 20.
The Overthinking Paradox in Sentiment Classification
While general models exhibit superior complex problem-solving capabilities, explicit cognitive mechanisms can occasionally degrade performance on straightforward financial sentiment tasks. A comprehensive study comparing GPT-4o, GPT-4.1, o3-mini, and FinBERT on the Financial PhraseBank dataset tested the efficacy of Chain-of-Thought (CoT) prompting (simulating deliberate, step-by-step logic) versus direct classification (simulating fast, intuitive deduction) 4.
The analysis revealed a counterintuitive pattern: prompting large models to engage in explicit step-by-step logic reduced their alignment with human-annotated sentiment labels, particularly in low-ambiguity cases 4. The highest agreement with human annotations was achieved by GPT-4o utilizing a "No-CoT" strategy, effectively mirroring fast, intuitive decision-making 4. Models inherently optimized for internal logical chains, such as o3-mini, yielded the lowest performance on these direct classification tasks. This suggests that excessive cognitive overhead introduces misalignment in binary or ternary classification environments - a phenomenon researchers categorize as "overthinking" 4. FinBERT, trained exclusively for direct classification, remains highly competitive in these environments by bypassing unnecessary generative logic sequences 410.
| Task & Dataset | FinMA-7B (Zero-Shot) | FinMA-7B (5-Shot) | GPT-4o / Llama 3 (Prompted) | FinBERT (Fine-Tuned Baseline) |
|---|---|---|---|---|
| FiQA-SA (F1-Score) | 79.0% | 82.6% | ~81.7% (Llama-3-8B) | ~75.0% |
| FPB (F1-Score) | 87.0% | 93.4% | ~88.9% (Llama-3-8B) | ~86.0% |
| News Headline Classification | 97.0% | 93.5% | Dominant across tests | Moderately lower accuracy |
Signal Generation and Simulated Portfolio Performance
The ultimate utility of financial language models is not measured by cross-entropy loss or static F1-scores, but by their capacity to generate economically meaningful trading signals (alpha) when deployed in simulated or live markets. These models transform unstructured text - such as news headlines, earnings calls, or macroeconomic reports - into directional market vectors.
Directional Forecasting from Financial News
A common quantitative methodology involves instructing a model to evaluate whether a news item is positive, negative, or neutral for a specific company's stock price, focusing the analysis on the immediate short-term horizon. Academic research investigating GPT-4's predictive capacity on U.S. equities demonstrated striking results using post-knowledge-cutoff headlines. By parsing these headlines, GPT-4 achieved a portfolio-day hit rate of approximately 90% for capturing the initial market reaction 1112. Furthermore, the sentiment scores significantly predicted subsequent price drift over the following trading days, particularly for small-cap stocks and negative news events 1112.
When formalized into systematic long-short portfolios, these sentiment signals yield substantial theoretical returns. A study utilizing the GPT-3-based OPT model alongside FinBERT to analyze 965,375 U.S. financial news articles over a 13-year period found that the OPT model predicted stock market returns with 74.4% accuracy 1. A daily-rebalanced, zero-cost long-short strategy based on these signals yielded a cumulative return of 355% over a two-year out-of-sample period (August 2021 to July 2023), achieving an exceptional Sharpe ratio of 3.05 113. FinBERT also demonstrated strong predictive power, achieving a Sharpe ratio of 2.07 in the same framework, which significantly outperformed traditional lexicon dictionaries that posted a Sharpe ratio of only 1.23 13.
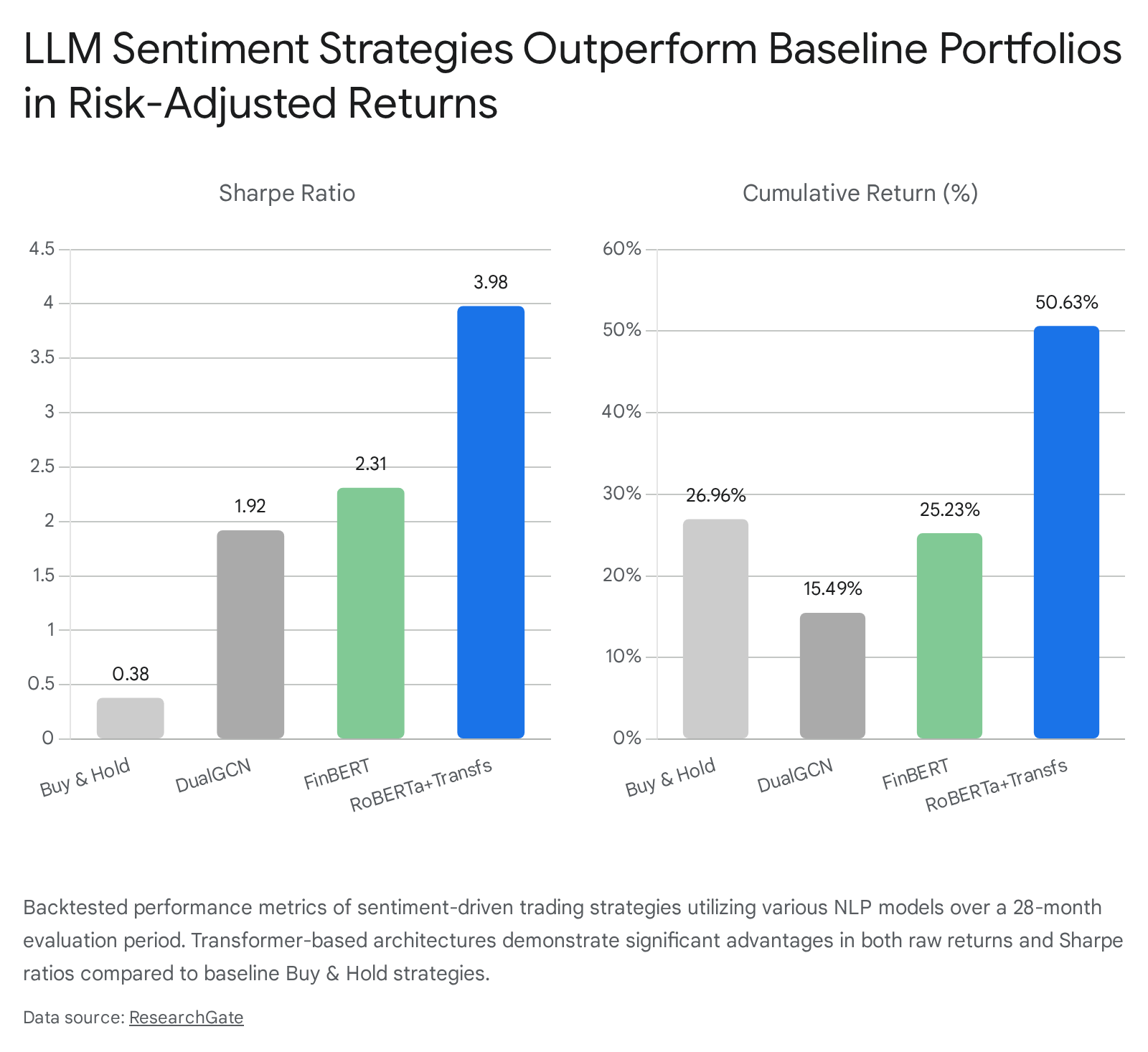
Hybrid Integration and Multi-Stage Filtering
Despite generating high absolute returns in isolated backtests, standalone sentiment strategies possess inherent vulnerabilities. Sentiment evaluation alone is often noisy, as models may fail to differentiate between genuinely market-moving news and routine corporate announcements 25. To mitigate this, advanced quantitative frameworks deploy hybrid architectures that merge high-throughput classification with deep contextual filtering.
One such multi-stage AI framework integrated FinBERT for high-throughput initial filtering and Google Gemini for deep contextual evaluation to surface high-conviction signals from over 9 million SEC filings and financial news items 14. These signals were subsequently executed within a dollar-neutral long/short framework, augmented by macroeconomic regime filters and technical trend confirmations. Over a 16-year testing period, this hybrid model generated a mean excess return of 51.02% per annum net of transaction costs, achieving a Sharpe ratio of 1.06 and a Sortino ratio of 2.61 14. The significant divergence between the Sharpe and Sortino ratios highlights the strategy's highly asymmetric risk profile, effectively capturing upside volatility while strictly limiting downside risk 14.
Other studies confirm that combining real-time sentiment analysis from GPT-2 and FinBERT with classic technical indicators (such as dual MACD configurations and time-series models like ARIMA) creates a synergistic effect. The sentiment layer captures the fundamental "why" behind market moves, while the technical layer filters out sluggishness and provides the specific trade timing 15.
Market Regime Dependency and Drawdown Risks
Empirical evaluations spanning broader cross-sections - analyzing decades of data across hundreds of equity symbols - reveal that autonomous trading strategies exhibit severe market regime dependency. Research utilizing the FINSABER backtesting framework found that timing-based strategies are overly conservative during bull markets, frequently underperforming passive long-only benchmarks 1629. Conversely, these same strategies become excessively aggressive during bear markets, failing to implement adequate risk controls and incurring heavy losses 1629.
To achieve consistent alpha generation, sentiment signals must be strictly conditioned on market regimes rather than applied unconditionally. Strategies that employ volatility indices (such as the VIX) as threshold indicators can dynamically switch between sentiment-prone and sentiment-immune portfolios depending on prevailing market conditions 13. By exploiting behavioral inefficiencies - specifically delayed arbitrage - through systematic regime detection, researchers successfully extracted 20% to 40% annualized returns in environments where unconditional sentiment strategies generated net losses 13.
Furthermore, cross-market tests indicate that regime dependency breaks down when the underlying market microstructure differs. Replications of VIX-conditioned sentiment strategies in Chinese equity markets failed to produce alpha due to differences in valuation variance and strict short-selling constraints, confirming that semantic signals are fundamentally tethered to the specific structural mechanics of the target market 13.
Transaction Costs and Execution Friction
A critical flaw in much of the academic literature surrounding simulated alpha generation is the gross underestimation of trading frictions. Discovering a semantic signal that correlates with asset returns is entirely insufficient if that correlation cannot overcome the economic realities of brokerage commissions, execution slippage, and market impact 3031.
The Illusion of Zero-Cost Execution
Backtests assuming zero transaction costs vastly overstate achievable returns, manufacturing theoretical profits out of minor statistical edges 32. Realistic quantitative modeling requires the rigorous integration of execution costs. While flat transaction cost models accurately reflect basic brokerage fees, they completely fail to capture slippage (the difference in price between decision time and execution time) and liquidity constraints 31. Large block trades require quadratic transaction cost models to accurately represent non-linear market impact, as trading substantial volume inevitably moves the underlying asset price unfavorably 31.
When researchers impose strict transaction cost hurdles on sentiment strategies - such as a standard 10 basis point (bps) per-trade assumption (20 bps round-trip) combined with daily rebalancing - the economic viability of many semantic signals contracts sharply 1317. However, highly performant models still demonstrate validity under stress. In the aforementioned Lopez-Lira and Tang study, increasing transaction costs from 5 bps to 10 bps, and eventually up to 25 bps per transaction, systematically eroded total profits 17. Yet, even under these conservative slippage assumptions, the GPT-4 strategy maintained positive cumulative returns 17.
The Correlation Profitability Threshold
To avoid expensive and misleading backtests, quantitative analysts rely on a correlation-based profitability threshold. This framework assesses the intercept from the signal regression, the correlation coefficient between the semantic signal and asset returns, return volatility, and signal volatility 30. By calculating the explicit correlation threshold required for profitability, analysts can definitively reject weak semantic signals early in the research pipeline. If the empirical correlation falls below the calculated threshold, the signal is mathematically guaranteed to fail against trading costs, regardless of subsequent portfolio optimization 30.
Furthermore, empirical observations demonstrate that semantic alpha exhibits rapid decay. Strategy returns consistently decline as the adoption of advanced models rises across the institutional industry, driving faster information incorporation into asset prices and establishing new, higher baselines for market efficiency 1112.
Inference Latency and Computational Infrastructure
For institutional deployment in live markets, the absolute analytical accuracy of a model must be continuously balanced against the physical constraints of infrastructure costs and inference latency. The deployment of dedicated computational infrastructure is bound by a fundamental trilemma: optimizing for throughput, minimizing latency, and controlling hardware capital and operational expenditures 34.
Speed and Latency in High-Frequency Environments
In high-frequency and latency-sensitive trading environments, processing delays measured in milliseconds dictate the ability to capture alpha. Massive general-purpose models like GPT-4 face substantial operational bottlenecks compared to smaller, specialized counterparts due to the stateful nature of inference and the limits of memory bandwidth 34.
FinBERT, operating at roughly 110 million parameters, processes textual inputs with minimal computational overhead, making it highly suitable for sweeping thousands of daily headlines in real-time 310. Conversely, massive API-bound models generate significant Inter-Token Latency (ITL) and limit overall throughput. Standard benchmarks indicate that the GPT-4 API throughput hovers around 36 tokens per second 3536.
However, recent advancements in open-weight models and specialized hardware have disrupted this dichotomy. Meta's Llama 3.1 8B Instruct, when deployed on highly optimized processing units (such as Groq's LPU architecture), achieves extraordinary throughput ranging from 147 to over 300 tokens per second 353637.
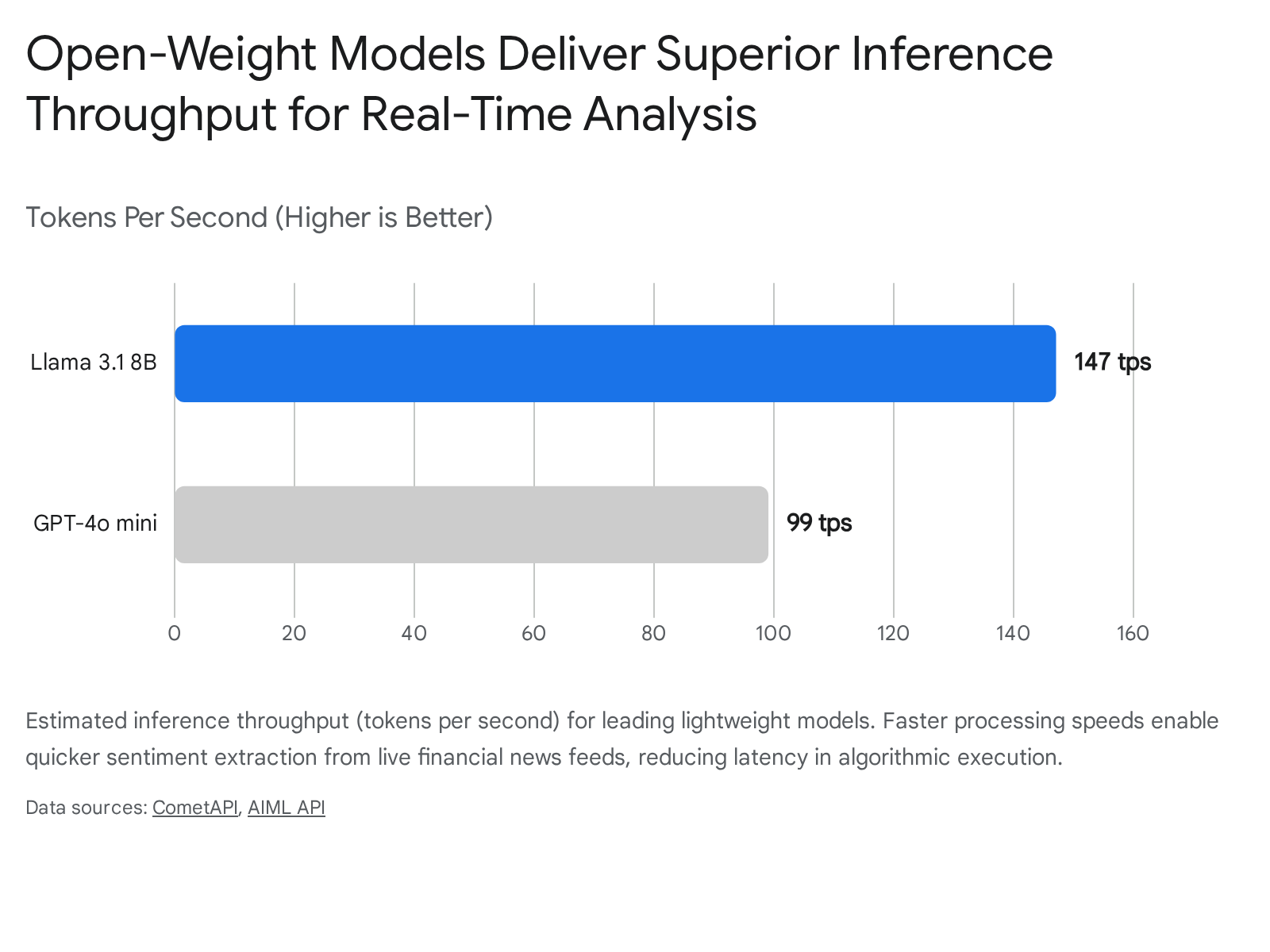
For real-time applications such as live document parsing or immediate headline reaction trading, the 9x speed advantage of an 8-billion parameter open-weight model over a massive proprietary model represents a definitive structural edge in trade execution 36.
The Economics of API versus Local Deployment
The financial economics of inference heavily favor open-weight and smaller-scale models for high-volume tasks. Analyzing millions of financial documents incurs prohibitive costs when utilizing proprietary APIs.
Processing data via the GPT-4o API costs approximately $2.50 per 1 million input tokens and $10.00 per 1 million output tokens 15. By contrast, locally hosted instances of Llama 3.1 8B drop these costs to roughly $0.03 per million tokens, rendering GPT-4o over 83x more expensive for input processing and 333x more expensive for generation 15. Even the highly efficient GPT-4o-mini, priced at $0.15 (input) and $0.60 (output) per million tokens, remains 5x to 20x more expensive than deploying an 8-billion parameter open model 1338. While self-hosting requires significant capital expenditure - a robust cluster with H100 GPUs can cost upwards of $70,000 monthly in cloud infrastructure - the crossover point where open-source economics surpass API fees typically occurs at a volume of 50 to 100 million tokens per month 36.
Furthermore, attempts to bridge the knowledge gap of smaller models via Retrieval-Augmented Generation (RAG) introduce new operational costs. Implementing RAG pipelines on models like GPT-4o-mini can increase absolute accuracy on financial reasoning benchmarks by roughly 10 percentage points, but this augmentation expands total token consumption by 18x and increases total execution time by a factor of 20 18. Consequently, deploying a fine-tuned, lightweight model locally often yields the optimal frontier for cost, speed, and data privacy in systemic quantitative workflows 3640.
Data Leakage and the Contamination of Benchmarks
Perhaps the most critical threat to evaluating general-purpose language models in finance is the pervasive issue of data contamination, also known as data leakage. Because models like GPT-4, Llama 3, and Claude 3 are trained on vast, opaque snapshots of the public internet (such as Common Crawl snapshots from 2021 through 2023), prominent financial datasets like FPB, FiQA, and extensive historical pricing data frequently bleed into their pre-training corpora 411920.
When a model is evaluated on a dataset it has already memorized during training, zero-shot accuracy metrics become artificially inflated. This violates the foundational machine learning principle of out-of-distribution testing, creating a false sense of model capability 21. Researchers probing data contamination utilize specialized protocols like "Testset Slot Guessing" (TS-Guessing), wherein models are prompted to fill in missing metadata or blank options within a benchmark. Applying these probes, researchers discovered that GPT-4 could guess missing benchmark data with an exact match rate of 57%, indicating severe memorization of the underlying test sets 19.
In live trading simulations, this contamination manifests as the "Profit Mirage." Autonomous trading agents report extraordinary double or triple-digit annualized returns when backtested on historical data that aligns with their pre-training window 45. However, the FinLake-Bench evaluation framework demonstrated that moving these agents just one step beyond their knowledge cutoff triggers a dramatic performance collapse. Re-evaluating agents on fresh market data released after the underlying model's cutoff date resulted in Sharpe ratio decays ranging from 51.48% to 62.23%, with total returns decaying by up to 71.85% for specific agent architectures 45.
These models suffer from high "Prediction Consistency" against counterfactual perturbations, proving they memorize historical outcomes rather than learning robust, causal financial principles 45. To combat this, the industry must rely heavily on air-gapped deployment, specialized counterfactual testing simulators (such as the FactFin framework), and uncompromising temporal validation - ensuring backtests strictly utilize data published after the model's exact knowledge cutoff date 174522.
Global Generalization and Geographic Bias
The performance of sentiment models degrades precipitously when shifted away from U.S. equity markets and English-language corpora, highlighting systemic geographic and linguistic biases embedded within global training sets.
General-purpose frontier models developed by U.S. technology firms predominantly rely on English-centric pre-training data. Consequently, they exhibit profound "foreign bias" in global financial prediction 23. Research comparing U.S.-based ChatGPT to China-based DeepSeek revealed that ChatGPT is systematically more optimistic about Chinese equities than local models, yet significantly less accurate in directional forecasts 23. This discrepancy is driven by an information-availability mechanism: Western models lack exposure to granular local media coverage and analyst sentiment, forcing them to fall back on broader, generalized heuristics. Crucially, researchers demonstrated that artificially injecting translated local Chinese financial news into the context window eliminates this prediction gap, proving the limitation is data-driven rather than architectural 23.
The imbalance extends to standard non-English datasets. The Language Ranker metric - which benchmarks internal model representations across languages - confirms a strong correlation between a model's operational accuracy and the volumetric proportion of a language within its pre-training corpus 2449. High-resource languages (such as English, German, and French) yield superior sentiment extraction, while models struggle significantly with cultural nuances, idioms, and local financial jargon in low-resource linguistic environments 24.
For global applicability, localized domain adaptation is essential. In European and Asian markets, local organizations either fine-tune open-weight models on regional financial documents or develop bespoke systems capable of understanding region-specific regulations and central bank communications 25. For example, the development of KPI-BERT allowed for the advanced extraction of key performance indicators from German financial documents, a task general models handled poorly due to linguistic drift 25. When assessing non-U.S. markets, models explicitly aligned with local information ecosystems inherently exhibit better calibration and alpha-generation capability than generalized models operating out-of-distribution 2351.
Conclusion
The pursuit of alpha generation through natural language processing has successfully evolved from elementary lexicon counting to deep semantic inference. General-purpose models, particularly GPT-4 and Llama 3, demonstrate extraordinary capabilities in parsing unstructured financial text, frequently matching or exceeding the baseline accuracy of domain-specific models like FinBERT and BloombergGPT on standardized evaluation benchmarks. Their massive scale grants them deep emergent analytical capabilities, allowing for advanced synthesis of complex market dynamics.
However, the application of general language models to systematic trading is fraught with systemic risks. The profit mirage caused by data contamination and look-ahead bias severely inflates backtested performance, demanding rigorous out-of-sample testing strictly past the model's knowledge cutoff date. Furthermore, raw sentiment accuracy is entirely insufficient for profitability; semantic signals must be integrated with dynamic risk management, conditional market regime filtering, and uncompromising execution cost analysis to overcome the friction of live trading.
Ultimately, the choice of model is dictated by infrastructure economics and latency requirements. While massive frontier models dominate complex, low-frequency analytical tasks - such as in-depth report summarization and regulatory document parsing - parameter-efficient models like FinBERT and 8-billion-parameter open-weight models offer the superior throughput, sub-second latency, and cost-effectiveness required for high-frequency, real-time alpha generation. As financial technology matures, the most robust quantitative strategies will likely feature hybrid architectures: deploying lightweight, highly efficient models for continuous news stream ingestion, escalated to larger proprietary models exclusively for high-conviction contextual verification.