Financial knowledge graphs for language models in trading
Introduction to Semantic Alpha and Structural Determinism
The integration of Large Language Models (LLMs) into quantitative finance represents a paradigm shift in the extraction of alpha from unstructured data sources, including earnings call transcripts, regulatory filings, financial news, and supply chain reports. Historically, financial forecasting relied heavily on numerical time-series analysis - utilizing models such as Autoregressive Integrated Moving Average (ARIMA), Long Short-Term Memory (LSTM) networks, and traditional Graph Neural Networks (GNNs) to identify statistical regularities in asset prices 123. While these approaches provide robust short-term predictive capabilities, they are fundamentally limited in their capacity to capture the complex, semantic relational patterns, competitive dynamics, and qualitative nuances that drive long-term asset valuation 123.
LLMs inherently possess the natural language understanding required to parse this qualitative information. However, deploying pure, ungrounded LLMs for financial reasoning introduces critical systemic risks. Standard LLMs suffer from context blindness, an inability to reliably execute multi-step logical reasoning over long document contexts, and a severe propensity for hallucination - generating fluent but factually fabricated claims 34. In high-stakes trading environments, where decisions must be mathematically verifiable and auditable, the probabilistic nature of LLM generation requires structural constraints 45.
Furthermore, traditional Retrieval-Augmented Generation (RAG) paradigms, which rely predominantly on vector databases and cosine similarity search, fail to capture the topological complexity of financial markets 786. Vector embeddings excel at semantic matching but flatten explicit relational structures. For instance, a pure vector search can identify documents discussing "supply chain risks," but it struggles to traverse the specific multi-hop dependency graph necessary to determine how a disruption at a primary supplier impacts the forecasted revenue of a downstream manufacturer 61011.
To bridge the gap between semantic understanding and structural determinism, institutional architectures have converged on Knowledge Graphs (KGs) augmented by LLMs - a framework broadly termed GraphRAG 127. Knowledge graphs represent financial entities (e.g., corporations, macroeconomic indicators, executives) as nodes, and their interactions (e.g., supplier-of, competitor-to, managed-by) as explicitly defined edges. By grounding LLM reasoning in these deterministic graph structures, quantitative systems can enforce logical consistency, enable explainable investment reasoning, and drastically reduce hallucinations 12378.
This report details the current best practices for constructing, evaluating, and deploying financial knowledge graphs to augment LLM reasoning in trading. It synthesizes recent empirical advancements in hybrid retrieval architectures, token-efficient graph construction, ontology design, temporal sanitation, and ultra-low-latency execution frameworks, providing a comprehensive architectural blueprint for institutional-grade financial AI systems.
Hybrid Graph-Vector Retrieval Paradigms
The dichotomy between vector databases and native graph databases has resolved into a consensus within the financial AI community: neither architecture is sufficient in isolation for enterprise financial reasoning. Vector databases process high-dimensional embeddings with sublinear query time complexity but fail at multi-hop reasoning and relational logic 81415. Conversely, native graph databases support complex sub-graph pattern matching and explicit relationship traversal, but they struggle with ambiguous, semantic queries that do not strictly adhere to the predefined schema 1415.
Empirical benchmarks confirm the structural advantages of graph-augmented systems over pure vector retrieval for complex tasks. On the RobustQA benchmark, graph-based RAG approaches achieved 86% accuracy, compared to a mere 32% for baseline vector RAG 16. Furthermore, on schema-bound queries involving Key Performance Indicators (KPIs) and financial forecasts, standard vector RAG scored 0%, while graph-grounded systems maintained full performance capabilities 1617.
To harness the complementary strengths of both modalities, the current industry best practice is the implementation of Hybrid Graph-Vector frameworks.
The HybridRAG Architecture
HybridRAG architectures fuse the semantic flexibility of dense vector retrieval with the topological precision of graph traversal. In this framework, the retrieval process is typically bifurcated. A vector similarity search is first employed to identify semantically relevant entry points, or "pivot nodes," within the unstructured corpus or knowledge graph. Subsequently, a graph traversal algorithm expands the contextual retrieval by exploring explicitly connected edges, typically within a localized neighborhood of two to three hops 6101118.
Extensive empirical evaluations conducted by researchers at BlackRock and NVIDIA demonstrate the superior outcomes achieved by this hybrid approach in financial document analysis. Testing the HybridRAG system on a dataset of earnings call transcripts from companies listed in the Nifty 50 index (spanning infrastructure, healthcare, and financial services), the architecture significantly outperformed standalone VectorRAG and GraphRAG models 1819.
The HybridRAG implementation achieved a factual faithfulness score of 96% (0.96) and an answer relevance score of 96% (0.96), outperforming VectorRAG (0.91) and standalone GraphRAG (0.89) 18. While standalone GraphRAG excelled specifically in context precision (0.96), the HybridRAG system maintained this precision while also achieving a perfect context recall score of 1.0, matching VectorRAG 18.
The optimal hybrid pattern retrieves context from both the vector database and the knowledge graph in parallel, merging the results using Reciprocal Rank Fusion (RRF) or weighted scoring mechanisms.
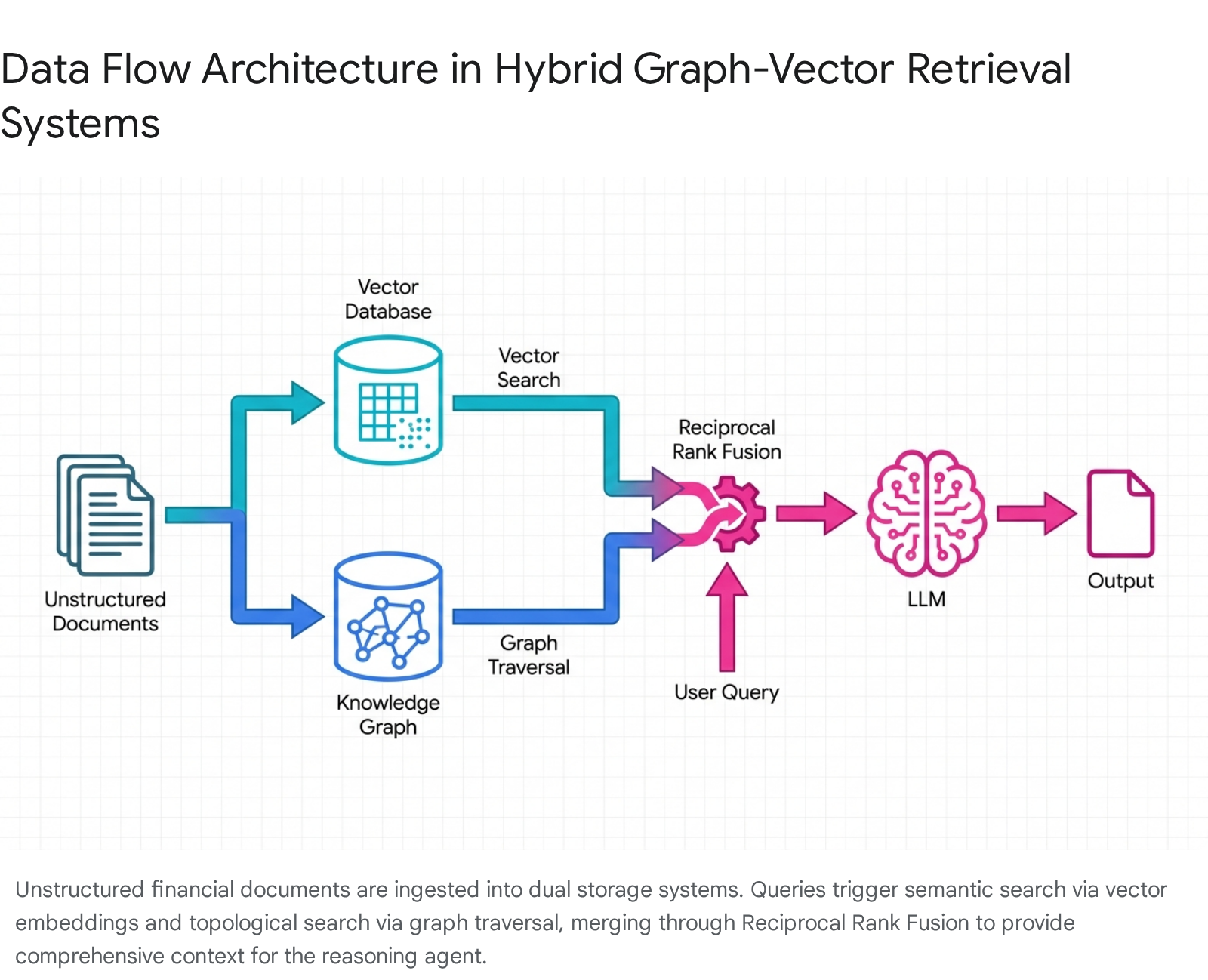
This fusion provides the LLM with a synthesized, highly relevant prompt containing both factual, schema-bound structure and semantic, narrative nuance 1019209.
Token Efficiency and Adaptive Retrieval Frameworks
While comprehensive global graph retrieval provides high accuracy and factual faithfulness, the computational cost of extracting, indexing, and querying multi-hop relationships at an enterprise scale is often prohibitive. Relying heavily on iterative LLM calls for node extraction, relationship definition, and schema induction results in staggering token consumption; indexing a mere 5 gigabytes of corporate or legal documents using standard methods has been estimated to cost upwards of $33,000 22. Furthermore, routing every simple query through a full graph traversal introduces unnecessary latency and expense.
To address the limitations of one-size-fits-all retrieval, the industry has developed adaptive, token-efficient, and agentic retrieval frameworks that escalate computational effort proportionally to query complexity.
Adaptive Agentic Graph Retrieval (A2RAG)
A2RAG is a state-of-the-art framework designed to decouple answer-level reliability control from retrieval-level progressive evidence acquisition. The architecture consists of an Adaptive Control Loop and an Agentic Retriever that operates on a local-first policy 4517.
The Adaptive Control Loop manages the lifecycle of a query to ensure cost-efficiency. Before invoking any expensive retrieval process, a lightweight gate estimates if the query falls within the scope of the corpus by computing a similarity score against precomputed document summaries. If the score fails to meet a specific threshold, the system abstains from answering, saving budget and preventing the ingestion of spurious evidence 5. If the query proceeds, the Agentic Retriever moves through a monotonic escalation policy:
- Local Evidence Collection: The system first attempts a highly inexpensive local expansion around entity and relation seeds extracted from the query, restricted to a 1-hop graph neighborhood 5.
- Bridge Discovery: If the controller's stage-wise sufficiency check determines the local evidence is inadequate, the retriever escalates. It searches for "bridge nodes" that connect multiple entity seeds through short multi-hop paths to locate missing structural connectors 5.
- Global Fallback and Provenance Map-back: As a last resort for highly complex queries, the system utilizes global diffusion techniques, such as Personalized PageRank (PPR), to locate distributed evidence. Crucially, A2RAG maps these graph signals back to the original source text chunks. This "provenance map-back" mechanism recovers fine-grained qualifiers - such as numerical thresholds or precise temporal constraints - that are often lost during the structural abstraction of graph construction, ensuring high-precision answering 45.
This progressive escalation pattern reduces the average number of LLM calls per query from 4.2 to 2.3 on benchmark datasets 1617. Experiments on the HotpotQA and 2WikiMultiHopQA datasets demonstrate that A2RAG achieves absolute gains of +9.9% and +11.8% in Recall@2, respectively, while simultaneously cutting token consumption and end-to-end latency by approximately 50% relative to standard iterative multi-hop baselines 45.
Alternative Token-Efficient Graph Frameworks
Beyond A2RAG, several other frameworks have been engineered to optimize the cost-to-accuracy ratio of financial knowledge graphs:
- TERAG: This framework focuses on minimizing token consumption during the graph construction phase. Rather than relying on multiple rounds of expensive LLM reasoning, TERAG uses lightweight prompts to extract multi-level named entities and document-level concepts, which are then structured using non-LLM clustering methods. During retrieval, it applies Personalized PageRank to the graph. This methodology reduces output token usage by 89% to 97% compared to heavy graph-based RAG methods while achieving at least 80% of their baseline accuracy 22.
- LightRAG: Designed for dynamic knowledge bases, LightRAG achieves comparable accuracy to traditional GraphRAG with a 10x reduction in token consumption through a dual-level retrieval system. It natively supports incremental updates, allowing the system to ingest streaming financial news without requiring full corpus reprocessing, resulting in less than a 5% accuracy degradation in benchmarks while cutting costs by 65 - 80% for large monthly document volumes 1623.
- HippoRAG: Inspired by the neurobiological function of the human hippocampus, HippoRAG separates entity nodes from passage nodes and utilizes Personalized PageRank for associative memory retrieval. Rather than retrieving fixed neighborhoods via multiple LLM calls, PPR propagates activation across the graph topology in a single traversal. This approach delivers multi-hop reasoning that is 10 to 30 times cheaper and 6 to 13 times faster than iterative retrieval methods 1617.
- PathRAG: This architecture utilizes flow-based pruning to extract only the most reliable relational paths from the knowledge graph. By discarding low-probability edges, PathRAG cuts the context window size by 44% while maintaining answer quality, making it highly efficient for integration with smaller parameter LLMs 17.
| Architecture | Primary Retrieval Mechanism | Cost/Efficiency Profile | Ideal Financial Use Case |
|---|---|---|---|
| HybridRAG | Vector pivot + Graph traversal + Rank Fusion | High cost, moderate speed | Complex document analysis requiring optimal factual faithfulness (e.g., earnings call synthesis). |
| A2RAG | Adaptive stage-wise escalation with Provenance Map-back | Moderate cost, dynamic latency | Mixed-difficulty workloads; prevents budget waste on simple queries while maintaining high precision. |
| TERAG | Lightweight concept extraction + Non-LLM clustering | Very low construction cost | Large-scale knowledge base construction where token budgets are strictly constrained. |
| LightRAG | Dual-level retrieval with incremental updates | Low retrieval cost, fast updates | Dynamic market environments requiring continuous ingestion of live news feeds without reprocessing. |
| HippoRAG | Personalized PageRank (PPR) associative memory | Low cost, high speed for multi-hop | Discovering hidden associative thematic links across massive, highly interconnected document corpora. |
Financial Taxonomy and Schema Ingestion
A financial knowledge graph is structurally bound by the schema that defines its ontology. In the financial domain, data is heterogeneous, heavily regulated, and requires strict adherence to standardized terminologies. Constructing an effective schema requires balancing the formal logical rigor necessary for deterministic algorithmic reasoning with the flexibility required to extract insights from unstructured corporate narratives.
Foundational Ontologies and Logical Consistency
For foundational structural consistency, best practices dictate anchoring the core of the knowledge graph to established industry ontologies rather than relying solely on LLMs for autonomous, ad-hoc schema induction.
The Financial Industry Business Ontology (FIBO) is the preeminent conceptual model for the domain, developed by the Enterprise Data Management Council (EDMC) and standardized by the Object Management Group (OMG) 72410. FIBO is specified using the Web Ontology Language (OWL) and Resource Description Framework (RDF), which ensures that every financial concept is framed through Description Logic. This renders the ontology unambiguous and machine-readable, providing precise meaning to financial instruments, legal entities, corporate hierarchies, and market indicators 7241026.
However, FIBO contains over 2,000 specific classes and hundreds of properties, creating a vast and dense structure 26. Injecting the entirety of FIBO into an LLM context window is mathematically inefficient and reliably causes token exhaustion, degrading the model's instruction adherence 262711. The optimal solution involves utilizing intelligent context management tools. For example, plugins like VidyaAstra, designed for the Protégé ontology editor, integrate LLM capabilities by dynamically extracting only relevant subgraphs based on the user's specific query. This hybrid approach preserves the formal OWL semantics and explicit relationships that prevent hallucination, while leveraging the LLM for natural language exploration of the data 27.
Regulatory Formats and Deterministic Data Pipelines
Regulatory reporting frameworks mandate structured formats that serve as highly reliable, deterministic data ingestion points for knowledge graphs. Relying on LLMs to extract precise numeric data from unstructured PDFs is fundamentally flawed, as it introduces probabilistic errors into deterministic financial statements 2912.
In European markets, the European Single Electronic Format (ESEF) mandates that issuers subject to the Transparency Directive report their annual financial reports using Inline XBRL (eXtensible Business Reporting Language) 1213. Inline XBRL embeds machine-readable tags directly into human-readable HTML documents, allowing machines to navigate financial statements seamlessly, accessing both the raw numbers and their contextual definitions 12.
The 2024 ESEF Taxonomy is based heavily on the FULL IFRS (International Financial Reporting Standards) Taxonomy. The core schema file, esef_cor.xsd, defines specific extension elements, guidance placeholders, and integrates the XBRL International Legal Entity Identifier (LEI) taxonomy to deterministically verify the identity of the reporting issuer 13. Furthermore, the ESEF taxonomy incorporates rigorous data quality checks, including 18 ESEF-specific value assertions and 153 value assertions derived from the IFRS taxonomy, ensuring that the relationships between facts, footnotes, and reporting periods are logically sound 13.
By parsing Inline XBRL directly into the knowledge graph via the esef_all-pre.xml presentation linkbase and calculation linkbases, quantitative systems can guarantee 100% extraction accuracy for foundational financial metrics (e.g., revenue, operating income, net income). This allows system architects to reserve computationally expensive, probabilistic LLM extraction solely for unstructured narrative elements, such as Management Discussion and Analysis (MD&A) sections or forward-looking risk disclosures 29121314.
Similar structured disclosure mandates are accelerating globally. The Tokyo Stock Exchange (TSE), for instance, has implemented new rules effective April 2025, making it mandatory for companies listed on the Prime Market to disclose financial results and timely disclosure information simultaneously in Japanese and English 1534. As Asian markets enforce more rigorous English-language disclosure standards, the volume of parseable financial data for global knowledge graph integration will expand significantly, driving demand for specialized extraction techniques capable of handling cross-lingual financial terminologies 15343516.
Schema-Guided Iterative Extraction from Unstructured Text
For unstructured texts where XBRL tags do not exist - such as financial news, analyst reports, earnings call transcripts, and specialized ESG disclosures - the construction of a reliable knowledge graph requires robust, multi-stage LLM-driven extraction pipelines governed by strict quality control mechanisms 173839.
The FinReflectKG framework exemplifies the state-of-the-art methodology for processing highly complex documents like SEC 10-K filings. To overcome the heterogeneity of these disclosures, FinReflectKG utilizes a "reflection-agent-based" extraction mode that moves definitively beyond naive, single-pass extraction 18. The pipeline operates through a continuous, multi-turn feedback loop:
- Initial Extraction: An extraction LLM (e.g., Qwen2.5-72B-Instruct) processes table-aware text chunks and generates an initial set of entity and relationship triples based strictly on the predefined financial schema 18.
- Critic Evaluation: A separate "critic" LLM reviews the extracted triples. It assesses schema compliance, flags ambiguous pronouns (e.g., "we", "it", "the company"), filters out contradictory or low-value information, and returns structured feedback in a JSON schema detailing specific issues 18.
- Correction and Iteration: A correction LLM revises the triples based on the critic's feedback. This cycle iterates until no further issues are identified or a maximum step limit is reached 18.
To mathematically ensure extraction quality, pipelines like FinReflectKG implement rigorous rule-based compliance checks (termed CheckRules) that verify entity length constraints and relationship schema adherence 18. Furthermore, the extraction is evaluated using information-theoretic metrics - such as Shannon Entropy and Schema-Normalized Entropy - to measure the global semantic diversity of the extracted graph 18. Finally, an "LLM-as-a-Judge" methodology compares extraction modes across dimensions of precision, faithfulness, comprehensiveness, and relevance. Empirical evaluations demonstrate that this reflection-agent-based mode consistently attains the highest compliance scores (64.8% against strict rule-based policies) while significantly outperforming baseline single-pass methods 18.
Evaluative Methodologies and Systemic Biases
As LLM-augmented financial systems transition from theoretical research to live trading environments, rigorous backtesting has exposed severe structural flaws in standard evaluation methodologies. Practices imported from general natural language processing fail to account for the unique temporal boundaries, survival dynamics, and economic execution constraints of capital markets 41.
The Structural Validity Framework and the Five Sins
A comprehensive review of 164 financial LLM papers published between 2023 and 2025 revealed that no single systemic bias is adequately discussed in more than 28% of studies 41. Researchers have identified five recurring biases - termed the "five sins" - that consistently and artificially inflate reported backtest performance, rendering the results useless for actual capital deployment 41. To combat this, backtests must strictly adhere to the Structural Validity Framework, establishing minimum pass/fail requirements for bias diagnosis 41.
| The "Five Sins" (Systemic Biases) | Mechanism of Failure in LLM Systems | Structural Validity Framework Mitigation |
|---|---|---|
| Look-Ahead Bias | Model pre-training includes future knowledge; temporal data leakage in RAG vector retrieval. | Temporal Sanitation: Enforce non-anticipativity; mandate explicit knowledge cutoffs and time-stamped archival data snapshots. |
| Survivorship Bias | Querying current equity indices for historical backtests silently drops delisted, bankrupt, or merged firms. | Dynamic Universe Construction: Define a time-indexed tradable universe for every decision point; include historical failures. |
| Narrative Bias | LLMs generate highly fluent, coherent causal explanations for market movements that are factually fabricated. | Rationale Robustness: Treat model explanations as testable objects; factual claims must be traceable to specific retrieved passages. |
| Objective Bias | Alignment processes reward confident completions, discouraging safe refusal or acknowledgment of uncertainty. | Epistemic Calibration: Score the model's ability to abstain from trading; include explicit "Do Not Know" action spaces. |
| Cost Bias | Evaluating models based on gross returns, assuming zero transaction costs, latency, or LLM inference expenses. | Realistic Implementation Constraints: Report net utility accounting for execution slippage, fees, and API/hardware inference costs. |
Look-Ahead Bias and Historical State Reconstruction (HSTR)
Look-ahead bias is the most pervasive and insidious failure mode in financial AI. It occurs when a quantitative model utilizes information that was not mathematically available at the historical decision time ($t$). In LLMs, this occurs through two distinct vectors: temporal leakage in the RAG retrieval mechanism (e.g., fetching a June document to justify a May trade) and implicit leakage encoded within the model's pre-trained parametric weights 4119432021.
Because commercial LLMs internalize world knowledge up to their training cutoff date, an LLM trained in 2024 inherently "knows" the outcome of every earnings surprise, regulatory shift, and macroeconomic shock from 2021 through 2023 432146. The severity of this issue was demonstrated in the Look-Ahead-Bench study, which applied commercial LLMs to stock selection across two matched six-month periods with similar market-wide returns.
The results exposed a massive degradation in out-of-sample performance. A strategy utilizing DeepSeek 3.2 generated a seemingly exceptional +20.73% annualized alpha during the in-sample period (which fell within the model's training data). However, during the out-of-sample period (falling after the training cutoff), the alpha swung to -1.04%, representing a catastrophic decay of -21.77% 21. Similarly, Llama 3.1 8B dropped from +13.81% alpha in-sample to -3.42% out-of-sample 21.
Notably, this study revealed a "Scaling Paradox": larger parameter models exhibited worse alpha decay than smaller models 21. Because larger models possess greater memorization capacity, they develop stronger priors from their training data. When these rigid priors encounter novel, out-of-sample market conditions, the model attempts to recall the future rather than dynamically reason about the present data, turning its massive parameter count into a liability 21.
To decouple the reasoning agent from its embedded future knowledge and solve temporal leakage in RAG retrieval, system architects employ Historical State Reconstruction (HSTR) 20. Rather than relying on the LLM's parametric memory or executing dynamic, unstructured document retrieval during a backtest, HSTR proactively compiles the exact, objective state of the knowledge graph as it existed at a precise microsecond in history 20.
The HSTR framework pre-computes historical snapshots by applying sequential chronological deltas to a base state. By the time the trading agent evaluates time $t$, it is provided with a localized, JSON-formatted sub-graph - typically 2 to 4 kilobytes in size - that represents entities, relationships, and sectoral constraints 20. This mathematically guarantees that the agent perceives only information physically published prior to $t$, eliminating look-ahead bias while simultaneously compressing the context window payload 20.
Market Execution and Latency Constraints
While the analytical rigor of multi-hop knowledge graph reasoning is unparalleled, its operational deployment must reconcile with the extreme physical constraints of market microstructure. In institutional digital trading, speed is a strategic currency. Latency - the delay between the initiation of a trading signal and its execution on the exchange - is measured in milliseconds (ms), microseconds ($\mu$s), and nanoseconds (ns) 474822.
The latency standards vary by strategy, but high-frequency equities trading strictly requires latency under 100 milliseconds, with professional setups often aiming for sub-20 millisecond execution 48. The data transmission time across network infrastructure can introduce 150 to 500 milliseconds of delay, requiring co-location services (hosting servers physically inside exchange data centers) and specialized FPGA (Field Programmable Gate Array) hardware to achieve deterministic, ultra-fast performance 4748. In these environments, nearly 27.2% of trades are executed against posted orders within half a second; a delay of merely a few nanoseconds can result in missing optimal pricing, suffering severe slippage, or falling behind in the order queue 47482223.
Standard agentic RAG architectures are fundamentally incompatible with these latency constraints. The sequential execution of multiple reasoning agents, dynamic vector similarity scans, and iterative multi-hop graph queries can take seconds or even minutes to process, rendering them entirely unsuitable for live trading paths 20.
To deploy graph-based intelligence in live trading without incurring devastating cost bias and slippage, institutions must structurally decouple the heavy computational cost of context acquisition from the latency-sensitive critical path of decision-making. The HSTR framework achieves this by delivering its pre-computed historical and relational context to the execution agent in approximately 50 milliseconds 20. This decoupling enables the deployment of "Hybrid Agents" that instantly load the pre-compiled graph sub-state and perform a single, optimized reasoning pass, effectively bridging the gap between deep structural analysis and the high-frequency demands of capital markets 20.
Alpha Decay and Economic Signal Extraction
The ultimate objective of integrating LLMs with financial knowledge graphs is to systematically harvest market inefficiencies (alpha) while strictly managing portfolio risk. However, alpha is intrinsically perishable.
The Degradation of Semantic Arbitrage
When an investment strategy is discovered and deployed by multiple market participants, the resulting collective trading activity shifts asset prices, effectively arbitraging the inefficiency away. This phenomenon, known as alpha decay, is an inescapable reality of adaptive markets 2452255455. A landmark 2016 study demonstrated that, on average, the returns from popular stock market strategies drop by 58% following public disclosure of their methodologies 24.
Empirical studies on systematic trading strategies quantify this decay explicitly. Research simulating mean-reversion strategies over 15 years of historical data indicates that alpha decay costs traders an average of 5.6% annually in U.S. equities and 9.9% in European markets 52. Furthermore, the speed of this decay is accelerating. The annual rate of increase in the cost of alpha decay is approximately 36 basis points (bps) in the US and 16 bps in Europe, driven by the rapid dissemination of information and advancements in computational trading power 52. Researchers note a strong positive correlation between decay costs and market volatility; during volatile periods, information is priced into securities faster, exponentially increasing the penalty for trading on stale signals 52.
Text-based financial networks and knowledge graphs initially emerged to circumvent standard numerical alpha decay by identifying highly complex, multi-hop economic linkages that are invisible to traditional time-series analysis 12. However, as more institutions deploy automated NLP pipelines to parse SEC filings and news sentiment, the alpha derived from primary semantic relationships (e.g., a simple, direct supplier-customer link) is also decaying rapidly. To maintain a sustainable edge, systems must continuously adapt, utilizing advanced reasoning to discover deeper, non-obvious thematic graphs 545526.
Enhancing Risk-Adjusted Returns via LLM Edge Filtering
A pervasive issue in constructing text-based financial networks for signal generation is the creation of spurious, economically meaningless edges. Standard embedding-based semantic similarity models often link firms simply because their business descriptions share overlapping vocabulary, even if no actual commercial or competitive relationship exists 57. Trading on these spurious correlations degrades portfolio performance.
Recent research demonstrates that utilizing an LLM to actively reason over and filter the edges of a candidate knowledge graph drastically improves the economic fidelity of the network, directly translating to superior trading metrics. In a comprehensive study evaluating U.S. equities (S&P 500 universe, 2011 - 2019), researchers utilized a two-stage "Retrieve-then-Reason" framework 57.
First, a sparse candidate graph was generated by calculating cosine similarity between the textual embeddings of firms' 10-K filings. Second, a large language model (DeepSeek-Chat) acted as an economic reasoner to classify these candidate edges into mutually exclusive categories: competitor, supply chain, complementary, substitute, peer, or unrelated 57. Crucially, the filtering logic removed "competitor" edges entirely, operating on the hypothesis that price divergence between direct competitors often reflects long-term structural market-share shifts rather than temporary, exploitable mean-reverting dislocations 57. "Substitute" edges were similarly down-weighted.
The refined, LLM-filtered graph was then used to aggregate pair-level mean-reversion signals (z-scores) into stock-level signals using relation-aware and distance-based weights (specifically utilizing the Gatev distance metric) 57. The empirical results confirmed the immense value of this structural filtering.
By removing economically spurious edges, the LLM-augmented framework increased the long-short portfolio's annualized Sharpe ratio from 0.742 (the baseline semantic network) to 0.820, representing a highly significant 10.5% improvement in risk-adjusted returns 57. Concurrently, the refined network improved tail-risk behavior, reducing the maximum drawdown from -10.47% to -7.85% (an improvement of 262 basis points) 57.
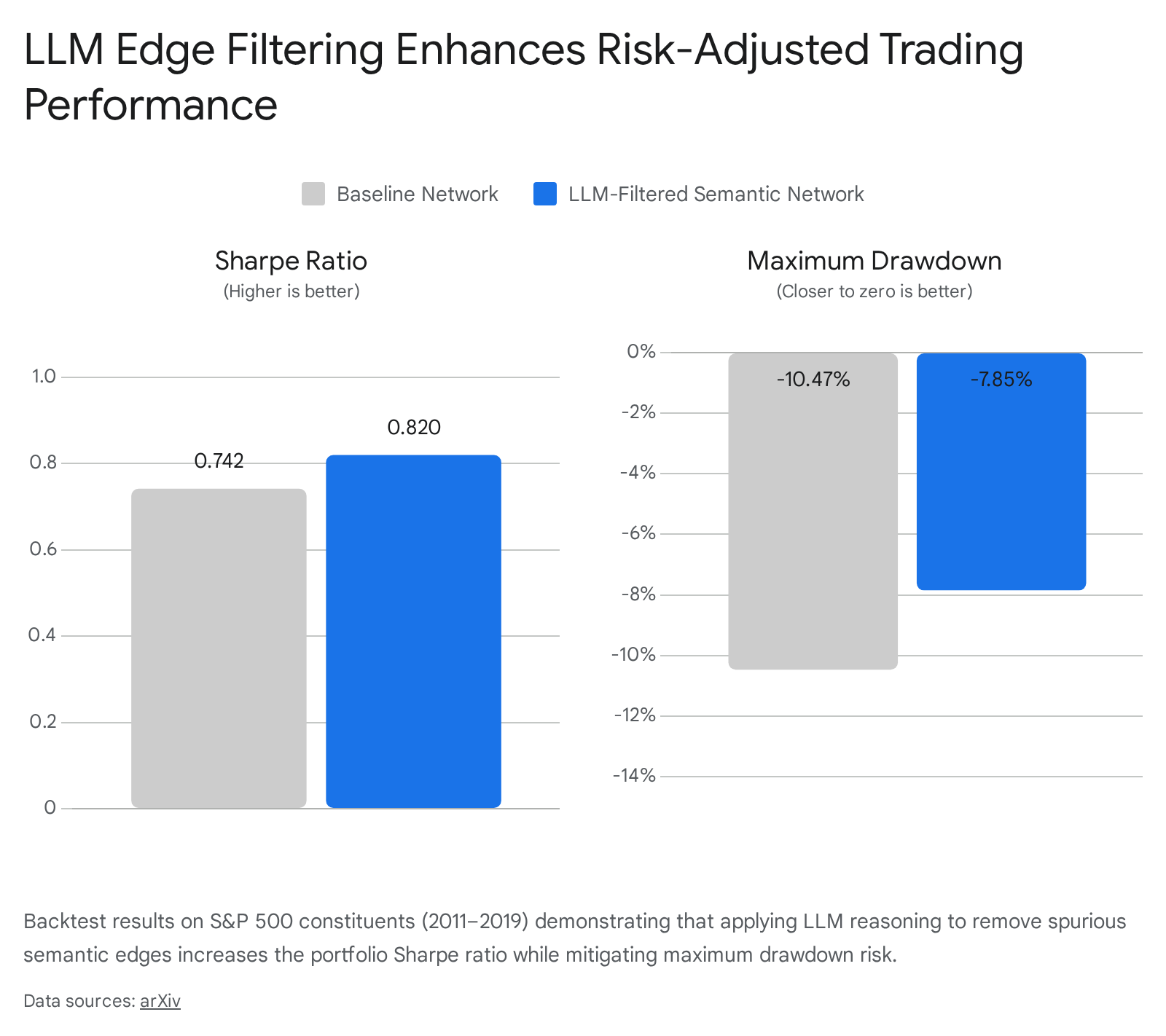
The LLM-filtered network substantially outperformed both random graphs (Sharpe 0.541) and traditional Standard Industrial Classification (SIC) based industry networks (Sharpe 0.792) 57.
Advanced Reasoning and Multi-Modal Integration
Beyond topological filtering, knowledge graphs provide critical structural support for specific reasoning tasks where LLMs traditionally struggle. Numerical reasoning - the interpretation of quantitative figures and ratios within financial contexts - remains a significant bottleneck for standard LLMs 5859. However, recent studies utilizing the FinQA benchmark demonstrate that integrating structured KG augmentations improves LLM mathematical execution. By grounding an open-source model (Llama 3.1 8B Instruct) in a schema specifically extracted from the target document, execution accuracy for complex numerical reasoning tasks improved by approximately 12% relative to the vanilla LLM baseline 5859.
Furthermore, specialized RAG frameworks are expanding the scope of KG utility in financial modeling. The RAG-FLARKO pipeline introduces a multi-stage retrieval process tailored for asset recommendation. By issuing SPARQL queries over two distinct knowledge graphs - a personal transaction KG (modeling user behavior) and a broader market history KG - the system constructs a highly compact, temporally filtered subgraph. This methodology optimizes the context window footprint, allowing smaller, more efficient LLMs to outperform full-KG ingestion models in behavioral alignment and recommendation profitability 11.
Similarly, in cryptocurrency markets, multi-modal architectures like Graph-R1 are mapping real-time price feeds, order books, on-chain metrics, and social media sentiment into unified knowledge hypergraphs 60. By utilizing an end-to-end reinforcement learning framework, the agent is trained to align its multi-turn reasoning loops ("think, query, retrieve, answer") directly with risk-adjusted outcomes, such as the Sharpe ratio and maximum drawdown, mirroring human-like analysis across diverse trading strategies 60. The Two-stage FKG-based Retrieval (TFR) framework has similarly demonstrated success in financial market analysis by employing a cluster-based triple extraction algorithm that filters irrelevant "noise" before feeding selected facts to the reasoning LLM, thereby significantly improving the logical consistency and accuracy of the generated market analysis reports 27.
Conclusion
The current best practice for constructing financial knowledge graphs to augment LLM reasoning requires abandoning naive, vector-only RAG pipelines in favor of sophisticated, cost-aware hybrid architectures. Frameworks such as HybridRAG and A2RAG optimally fuse the semantic breadth of dense vector search with the topological exactitude of explicit graph traversal. By utilizing adaptive, local-first escalation policies and Personalized PageRank (PPR), these systems navigate the complex trade-offs between computational expense, latency, and the necessity for multi-hop reasoning.
Robust data ingestion remains paramount. The ontology must be anchored by rigorous industry standards, leveraging deterministic formats like ESEF Inline XBRL and established conceptual models like FIBO for structural consistency. Unstructured text ingestion requires multi-agent reflection loops (e.g., FinReflectKG) and strict rule-based compliance checks to ensure extraction fidelity and prevent knowledge graph degradation.
Critically, any application of these systems for alpha generation must aggressively combat financial evaluation biases. The Structural Validity Framework must be applied to backtests, utilizing methodologies like Historical State Reconstruction (HSTR) to enforce strict temporal sanitation, thereby eliminating the severe look-ahead biases inherent in pre-trained LLMs. By applying LLMs as economic reasoners to filter spurious relationships from semantic networks, practitioners can achieve mathematically significant improvements in risk-adjusted returns while minimizing drawdowns. Ultimately, the successful deployment of these cutting-edge architectures in live capital markets hinges on decoupling the computationally intensive graph extraction processes from the ultra-low latency execution demands of modern trade routing.