LLM Inference Pipelines for Real-Time Alpha Research
Architecture of Alpha Research Pipelines
The integration of Large Language Models (LLMs) into quantitative finance has fundamentally shifted the paradigm from manual feature engineering toward autonomous, multi-agent frameworks capable of end-to-end alpha generation. In modern AI-native hedge funds, traditional deep learning models have demonstrated limitations regarding adaptability to regime shifts and the processing of unstructured, multimodal data. Consequently, leading quantitative groups have transitioned toward dynamic agentic architectures that utilize LLMs as cognitive engines to iteratively hypothesize, code, backtest, and refine trading signals across continuous data streams 12.
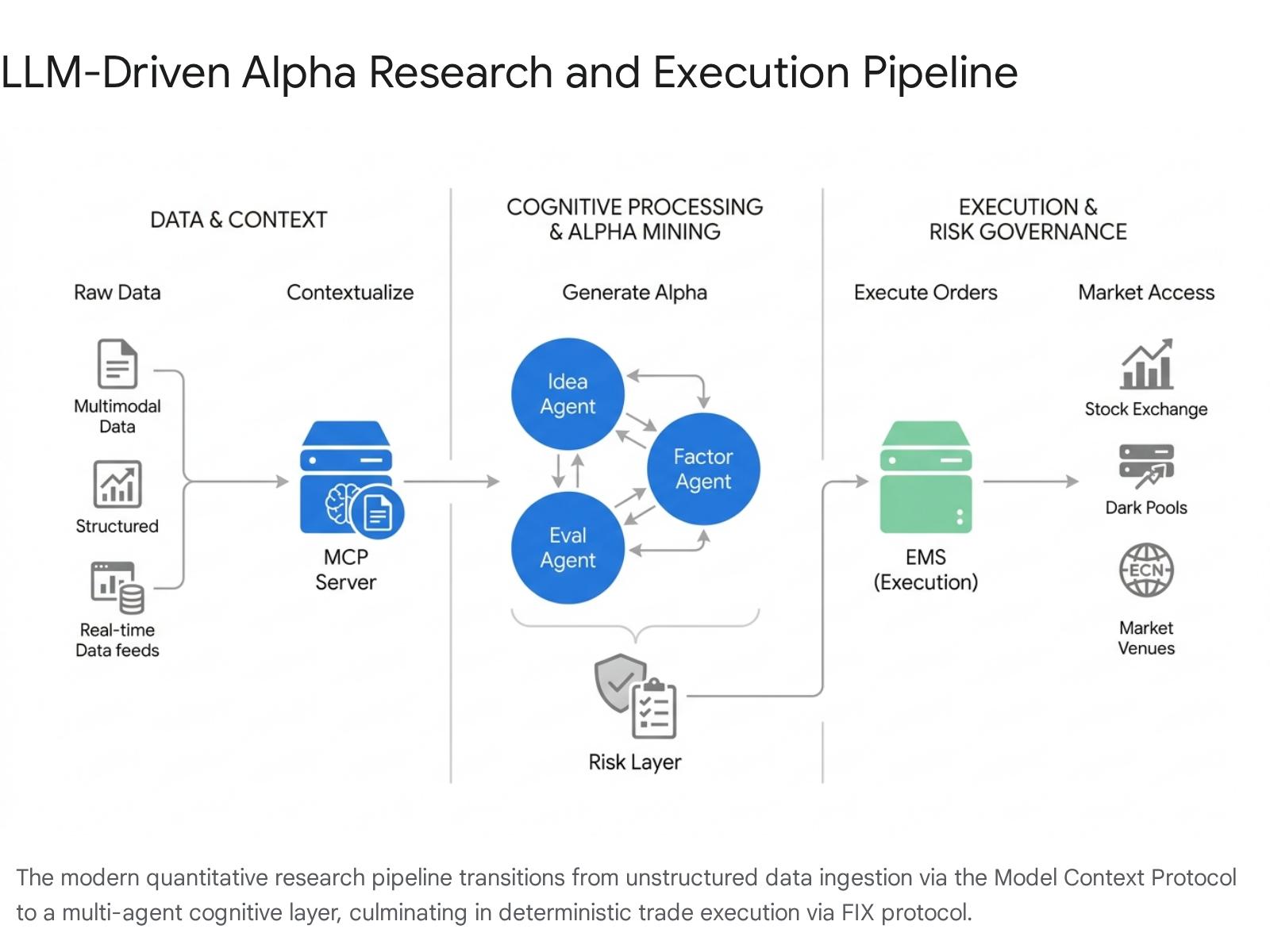
These systems decompose the quantitative research pipeline into specialized cognitive and execution phases. Current production architectures frequently employ a three-layer framework: a semantic processing layer utilizing LLMs for parsing unstructured financial texts and market sentiment, a multi-agent layer for collaborative intelligence and hypothesis generation, and a Deep Reinforcement Learning (DRL) or deterministic execution layer for adaptive weight optimization and trade routing 1. This deliberate separation of concerns allows quantitative funds to leverage the advanced reasoning capabilities of frontier LLMs while maintaining the strict deterministic parameters required for execution management.
Agentic Workflows and Alpha Mining
Within the multi-agent layer, the operational workflow mirrors the scientific method utilized by human quantitative researchers. Enterprise systems deploy autonomous agents - frequently operating on foundational models like GPT-4, Claude Opus, or specialized internal variants - that retrieve internal price data libraries, form hypotheses regarding market inefficiencies, generate Python code for factor construction, and independently evaluate performance in a secure sandbox 12. This capability effectively scales the ideation capacity of a fund without a proportional increase in human capital.
A critical challenge in automated alpha mining is "alpha decay," wherein newly discovered factors rapidly lose their predictive power due to market adaptation or fundamental overfitting 3. To counteract this phenomenon, advanced frameworks such as AlphaAgent implement stringent structural constraints and ad hoc regularization throughout the generation loop. The framework utilizes three primary agents: an Idea Agent that synthesizes market hypotheses, a Factor Agent that constructs the code, and an Eval Agent that conducts rigorous backtesting 3. The system employs Abstract Syntax Tree (AST) similarity measures to evaluate the originality of newly generated code against existing internal factor libraries, preventing the system from producing mathematically redundant or overcrowded signals 3. Furthermore, it assesses the semantic alignment between the proposed economic hypothesis and the generated factor to ensure that the alpha relies on structural market logic rather than spurious, over-engineered correlations 3.
LLMs as Evolutionary Operators
The integration of LLMs has also revolutionized feature engineering by superseding traditional genetic programming algorithms. Historically, evolutionary algorithms utilized random mutations and crossover strategies to explore solution spaces, which often resulted in unexplainable outputs and severe convergence issues 6. Contemporary research indicates a shift toward utilizing LLMs as intelligent evolutionary operators. Because LLMs possess semantic understanding of financial theory and programmatic syntax, they can identify shortcomings in existing quantitative algorithms and propose targeted, causal improvements rather than blind permutations 6.
Systems like AlphaSharpe utilize this LLM-driven evolutionary framework to discover novel performance metrics that correlate more strongly with out-of-sample investment performance than traditional Sharpe ratios, while frameworks like AlphaQuant automate the generation and vectorized implementation of entirely new predictive features in frameworks such as PyTorch 6. Empirical validations of these agentic pipelines demonstrate substantial outperformance. During volatile testing periods across 2024 and 2025, experimental multi-agent frameworks operating on major global indices achieved annualized returns exceeding 50% with robust Sharpe ratios, significantly outpacing benchmark passive strategies and static deep learning models by dynamically adjusting portfolio weights based on real-time market regimes 148.
Inference Hardware and Scale Economics
The deployment of sophisticated multi-agent pipelines at scale is heavily constrained by the underlying physical infrastructure. The computational demands of processing multimodal financial documents and running continuous reasoning loops require specialized clusters characterized by immense memory bandwidth and tensor processing capabilities. Quantitative funds must optimize hardware configurations to balance extreme throughput requirements against escalating operational costs 56.
Processor Selection and Throughput Dynamics
The hardware foundation for real-time LLM inference in 2026 is dominated by NVIDIA's Hopper architecture, with the H100 and H200 accelerators serving as the primary engines for large-scale operations. The fundamental bottleneck in generative LLM inference, particularly during the autoregressive decoding phase where tokens are generated sequentially, is memory bandwidth rather than sheer arithmetic compute capacity 11. The H100 SXM features 3.35 TB/s of memory bandwidth across 80 GB of HBM3 memory, providing a critical 64% bandwidth advantage over the preceding A100 architecture 611.
This bandwidth superiority directly translates to increased throughput under heavy concurrent loads. For instance, an H100 processing a 70 billion parameter model can sustain double the token-per-second throughput of an A100 across varying batch sizes, while simultaneously reducing the prefill time required for document ingestion by factors of two to three 1112. While an individual H100 instance commands a price premium of approximately 60% over an A100, its ability to handle larger batch sizes without saturating the memory bus ultimately delivers an 18% to 45% reduction in total inference cost for high-volume, concurrent quantitative workloads 11.
For operations requiring lower parameter counts or utilizing aggressively quantized models, the Ada Lovelace architecture (specifically the L40 and L40S) offers a compelling economic alternative. The L40 consumes roughly half the power of an H100 (320W versus 700W) and significantly reduces hourly inference costs 56.
| GPU Architecture | Memory Bandwidth | Memory Capacity | TDP (Power) | FP16/FP8 Support | Optimal Use Case in Quant Pipelines |
|---|---|---|---|---|---|
| NVIDIA H100 SXM | 3.35 TB/s | 80 GB HBM3 | 700 W | Full FP8 Support | Frontier model hosting, dense document processing, long-context analysis 611. |
| NVIDIA A100 SXM | 2.039 TB/s | 80 GB HBM2e | 400 W | FP16 Support | Batch processing, smaller model routing, cost-constrained parallel generation 1112. |
| NVIDIA L40S PCIe | 864 GB/s | 48 GB GDDR6 | 350 W | Full FP8 Support | Real-time classification, quantized model serving, localized edge processing 56. |
Hardware selection must also account for the latency mechanisms inherent in data transfer. The implementation of Trusted Execution Environments (TEE) on the H100 architecture has allowed hedge funds to process highly confidential proprietary data securely. TEE operations encrypt data transfers between the CPU and GPU via the PCIe bus. Benchmarking indicates that the performance penalty associated with this encryption is heavily dependent on sequence length; for typical LLM queries, the overhead remains below 5%, and as token lengths increase, the throughput penalty approaches zero, enabling secure confidential computing without compromising high-frequency throughput 13.
Serving Frameworks and Memory Management
Raw silicon performance is heavily dependent on the optimization of the serving frameworks. Inference engines such as vLLM and TensorRT-LLM have become industry standards for deploying financial models. These engines leverage PagedAttention algorithms to dynamically manage the Key-Value (KV) cache, preventing memory fragmentation when processing highly variable lengths of financial texts such as dense 10-K filings or fragmented social media sentiment feeds 1415.
At the kernel level, these frameworks integrate FlashAttention-3, an algorithm specifically optimized for Hopper GPUs to accelerate exact attention computation 7. By exploiting the FP8 data formats natively supported by the H100's Transformer Engine and optimizing asynchronous data transfers within the GPU memory hierarchy, FlashAttention-3 drastically reduces the Time to First Token (TTFT). For a system evaluating real-time macroeconomic news, minimizing the TTFT during the initial prefill stage ensures that the cognitive agent can begin reasoning on market shocks milliseconds after the data is ingested 11127.
Model Scale and Semantic Routing
Deploying a monolithic, frontier-scale LLM for every computational task within a hedge fund is economically prohibitive and introduces unacceptable latency into trading operations. Consequently, AI-native infrastructure relies on sophisticated routing frameworks that dynamically assign tasks across a spectrum of model sizes based on complexity, required context windows, and latency tolerances 17188.
Edge Small Language Models
Small Language Models (SLMs), typically characterized by parameter counts ranging from 1 billion to 15 billion, are deployed for narrow, highly structured tasks. Models such as Llama 3.2, Gemma 2, and Phi-4 demand significantly less memory, deliver faster token throughput, and can be hosted entirely on-premises without relying on external cloud APIs 91011. This localized deployment drastically reduces the cost-per-million queries and mitigates data leakage risks associated with transmitting proprietary portfolio positions or algorithmic logic to third-party providers 17912.
In practice, SLMs execute high-frequency operations such as real-time financial sentiment analysis, continuous news parsing, named entity recognition, and data normalization. When fine-tuned on specialized financial corpora, SLMs frequently match or outperform generalized frontier models on discrete classification tasks 171824. Furthermore, their compact size enables processing speeds measured in tens of milliseconds, a prerequisite for integration into low-latency market making or rapid signal generation pipelines 1718.
Frontier Models and Inference Routing
Conversely, massive frontier models (exceeding 100 billion parameters) such as GPT-5 or Claude Opus are reserved for open-ended reasoning, deep macroeconomic synthesis, and multi-step agentic planning. These tasks require the emergent reasoning capabilities and expansive context windows (frequently exceeding 100,000 tokens) that SLMs lack 171810. While SLMs exhibit high accuracy on defined boundaries, they are prone to severe degradation and "accuracy collapse" when tasked with novel logic or cross-referencing expansive legal and financial documents without explicit retrieval-augmented chunking 18.
The bifurcation of labor is managed by intelligent semantic routers. Frameworks like the vLLM Semantic Router dynamically evaluate incoming workloads, classifying them by intent and complexity before directing them to the optimal local or cloud-based model 8. This architecture ensures that funds maintain a competitive edge through superior reasoning on complex trades while preserving capital and operational speed on routine data extraction.

Speculative Decoding Accelerations
To circumvent the inherent latency constraints of autoregressive generation, quantitative infrastructure teams have widely adopted Speculative Decoding (SD). The core premise of standard SD involves utilizing a highly efficient, lightweight draft model to rapidly propose a sequence of candidate tokens. A larger, more capable target model subsequently evaluates these drafted tokens in a single parallel forward pass, accepting or rejecting them based on the target distribution. This parallel verification substantially reduces the total number of target model invocations, driving down the aggregate latency 252627.
Advanced Decoding Architectures
While standard SD provides measurable acceleration, it remains bottlenecked by the sequential dependency between the draft and target models; the draft model remains idle while the target model performs verification 2528. To extract further efficiency, researchers have developed "Speculative Speculative Decoding" (SSD). In an SSD framework, the draft model does not pause during the verification phase. Instead, it predicts the probable outcomes of the ongoing verification and preemptively prepares subsequent speculations based on those anticipated results. If the target model's verification aligns with a predicted outcome, the draft model immediately injects the pre-speculated sequence, effectively eliminating drafting overhead and delivering speedups of up to 30% over optimized standard SD architectures and five-fold improvements over traditional autoregressive decoding 252829.
Further innovations address the structural limitations of draft models themselves. Frameworks such as Budget EAGLE (Beagle) replace the traditional self-attention Transformer decoders commonly utilized in draft architectures with a cross-attention-based system. This structural simplification eliminates the need for auxiliary fusion layers, significantly enhancing training convergence and maintaining stable memory footprints during runtime simulation, while preserving acceleration performance comparable to state-of-the-art models 27.
Additionally, quantitative analysts are integrating Entropy-Aware Speculative Decoding (EASD) to manage uncertainty. Standard SD is inherently constrained by the target LLM's performance ceiling; if the draft model is excessively aligned with a flawed target model, errors persist 26. EASD applies a dynamic penalty based on the entropy of the sampling distribution at each step. By quantifying the uncertainty of the model's outputs, the system halts the propagation of low-confidence tokens. In strict financial contexts, preventing the cascade of hallucinated or probabilistically weak assumptions during intermediate reasoning steps ensures that trading agents construct logic chains with higher verified fidelity 26.
Execution Integration and Network Protocols
Extracting predictive signals is only a partial solution; to capitalize on alpha, AI-native funds require robust architectures that bridge probabilistic intelligence with deterministic execution venues. The integration of LLMs into core financial infrastructure historically required bespoke, rigid point-to-point connections prone to failure.
Model Context Protocol Implementation
To resolve the complex $N \times M$ integration problem - where every new LLM must be custom-linked to disparate databases, ERPs, and live market feeds - funds are rapidly adopting the open-source Model Context Protocol (MCP) 303132. Formulated as a standardized JSON-RPC interface, MCP establishes a universal communication layer between intelligent clients (the LLM agents) and external resources.
By deploying lightweight MCP servers atop internal factor libraries, proprietary data lakes, and compliance repositories, developers expose standardized capabilities to any authorized agent 3334. Rather than continuously training models on dynamic financial data or loading massive contexts in individual prompts, MCP allows agents to query precise, real-time datasets securely. This architecture preserves strict governance and auditability, ensuring that every data request made by an autonomous agent is logged, validated, and restricted to appropriate permission scopes, mitigating the risk of agents acting on stale or hallucinated data 323313.
Execution Management System Integration
Once a multi-agent system validates an alpha hypothesis and generates a trading signal, the information transitions from the cognitive layer to the execution layer. To prevent probabilistic models from issuing erroneous orders directly to exchanges, funds utilize a hard separation enforced by execution middleware 3614.
The LLM pipeline transmits a structured data payload containing the asset, target exposure, and confidence interval. This payload is received by a deterministic rule engine - often termed a risk governance dashboard - which applies strict boundaries regarding maximum position sizing, trailing drawdowns, and daily loss limits 36. Approved signals are translated into standard Financial Information eXchange (FIX) protocol messages and transmitted to an Execution Management System (EMS) 1438. Advanced EMS platforms, such as the TORA EMS, utilize rule-based smart order routing to split the aggregate order across multiple broker APIs, dark pools, and alternative trading systems to minimize market impact, reduce slippage, and obscure the fund's algorithmic intent from broader market participants 14.
On-Chain Autonomous Trading
In parallel to traditional equities, digital asset funds are developing completely native execution frameworks utilizing Agent-Native Account Abstraction (A-AA) on blockchain networks. In systems such as the B2 Network, traditional wallet primitives are upgraded to support autonomous AI agents. These agents utilize polymorphic key stacks and zero-knowledge state capsules to hold digital assets natively, execute lightning-fast arbitrage settlements via automated smart contracts, and quantify their activities into on-chain signals. These signals integrate with Proof of Signal (PoSg) consensus mechanisms, allowing the economic output of the AI pipeline to contribute directly to the network's cryptographic security 39.
Regulatory Frameworks and Compliance
The deployment of autonomous AI agents executing financial transactions necessitates strict adherence to an increasingly complex and divergent global regulatory landscape. AI-native funds must navigate distinct compliance mandates across North America, the European Union, and Asian markets.
European Union Artificial Intelligence Act
In the European Union, algorithmic trading systems are primarily governed by MiFID II, which mandates stringent pre-trade controls, algorithmic testing environments, and documentation of any material changes to code logic 15. While general algorithmic trading is currently excluded from the High-Risk AI System (HRAIS) classifications under the EU AI Act, systems that intersect with creditworthiness, biometric categorization, or certain critical infrastructure elements must adhere to the Act's rigorous transparency and monitoring mandates 1541.
Following the May 2026 political agreement on the "AI Act Omnibus" amendments, regulatory timelines for high-risk systems have been extended to provide operational relief. Compliance obligations for Annex III (use-based) High-Risk AI Systems have been delayed by 16 months to December 2027, while Annex I (product-regulated) deadlines have been shifted to August 2028 1617. Furthermore, the amendments stipulate that generative AI models must mark and label synthetic content outputs in a machine-readable format by December 2026, forcing funds to ensure comprehensive audit trails for any client-facing reports generated by LLMs 1618.
| Regulatory Requirement (EU AI Act) | Original Deadline | Revised Deadline (May 2026 Omnibus) | Impact on Quantitative Funds |
|---|---|---|---|
| Annex III High-Risk Systems Compliance | August 2026 | December 2027 1617 | Provides funds extensive temporal relief to align multi-agent audit trails and bias detection systems. |
| Annex I High-Risk Systems Compliance | August 2027 | August 2028 16 | Delays stringent product safety integration requirements for embedded algorithmic software. |
| Generative Content Transparency Labeling | August 2026 | December 2026 1618 | Requires immediate integration of watermarking capabilities for AI-generated financial reporting and analysis. |
North American Supervisory Standards
In the United States, the Securities and Exchange Commission (SEC) and the Financial Industry Regulatory Authority (FINRA) apply technology-neutral frameworks to AI oversight, requiring that existing risk management and supervision mandates (e.g., FINRA Rule 3110) fully govern LLM and generative AI deployments 1920. FINRA's 2026 Regulatory Oversight Report specifically isolates generative AI as an emerging vector for cyber-enabled fraud and manipulative trading, stressing that broker-dealers must establish enterprise-level protocols to detect algorithmic drift, mitigate hallucination risks, and secure model weights against adversarial extraction 1921. The SEC continues to prioritize examinations of firms utilizing AI for portfolio management and trading, scrutinizing both the operational safeguards and the transparency of disclosures to retail investors to prevent "AI washing" 1922. Concurrently, structural market rules continue to evolve; recent amendments replacing legacy day-trading margin frameworks with real-time intraday deficit monitoring systems force funds to upgrade their execution layers to support continuous, millisecond-level position calculations 23.
Asian Market Microstructure Regulations
The Asian regulatory environment presents significant fragmentation regarding AI and programmatic trading. The China Securities Regulatory Commission (CSRC) has aggressively tightened oversight on quantitative activity to preserve market stability and limit high-frequency speculation. Entering 2026, the CSRC defined program trading under strict parameters - specifically, algorithms executing five or more orders within a single second on at least five occasions per day - mandating intensive reporting obligations, colocation governance, and heightened scrutiny over direct market access. Overseas investors operating via QFIs must complete extensive software filing requirements before commencing automated strategies, with final compliance transitions concluding in April 2026 24252627. Furthermore, the CSRC maintains an absolute prohibition on crypto-assets and Real World Asset (RWA) tokenization within the mainland 24.
In contrast, other regional hubs are actively fostering AI-driven financial ecosystems. The Hong Kong Securities and Futures Commission (SFC) released updated circulars bridging global liquidity pools for Virtual Asset Trading Platforms (VATPs) and deployed Generative AI sandboxes to support responsible LLM utilization 5456. Japan's Financial Services Agency (FSA) similarly accelerated its modernization efforts by publishing updated AI Guidelines in March 2026 addressing multi-step workflow automation and system-specific hallucination risks 57. This regulatory clarity supported a landmark May 2026 initiative by Japan's ruling Liberal Democratic Party to establish a nationwide framework integrating AI agents with tokenized yen and blockchain infrastructure, laying the groundwork for a fully autonomous, 24/7 on-chain financial settlement system managed entirely by intelligent software 5859.