Multi-agent LLM systems for market microstructure simulation
The integration of Large Language Models (LLMs) into financial market modeling has transitioned from single-agent sentiment analysis pipelines to the deployment of complex, multi-agent societies designed to simulate intricate market microstructures and execute quantitative trading strategies. Historically, financial agent-based models (ABMs) relied on static, rule-based heuristics that failed to capture the adaptability, irrationality, and semantic processing capabilities inherent in human market participants 11. Multi-agent LLM systems address these theoretical limitations by acting as autonomous cognitive entities capable of perceiving unstructured market data, engaging in dialectical debate, and executing orders within high-fidelity simulation environments that enforce real-world microstructural constraints such as latency, slippage, and limit order book (LOB) dynamics 245.
This paradigm shift represents a synthesis of generative artificial intelligence, experimental behavioral finance, and quantitative execution modeling. By orchestrating specialized agents - ranging from fundamental analysts parsing SEC filings to portfolio risk managers computing conditional value at risk - these systems replicate the collaborative and adversarial dynamics of institutional trading floors 678. Furthermore, coupling these cognitive agents with advanced simulation engines and deep reinforcement learning (DRL) frameworks allows researchers to conduct counterfactual analyses, test execution strategies against generative market impact models, and optimize policies without exposure to actual financial risk 3104.
Organizational Topologies of Trading Agents
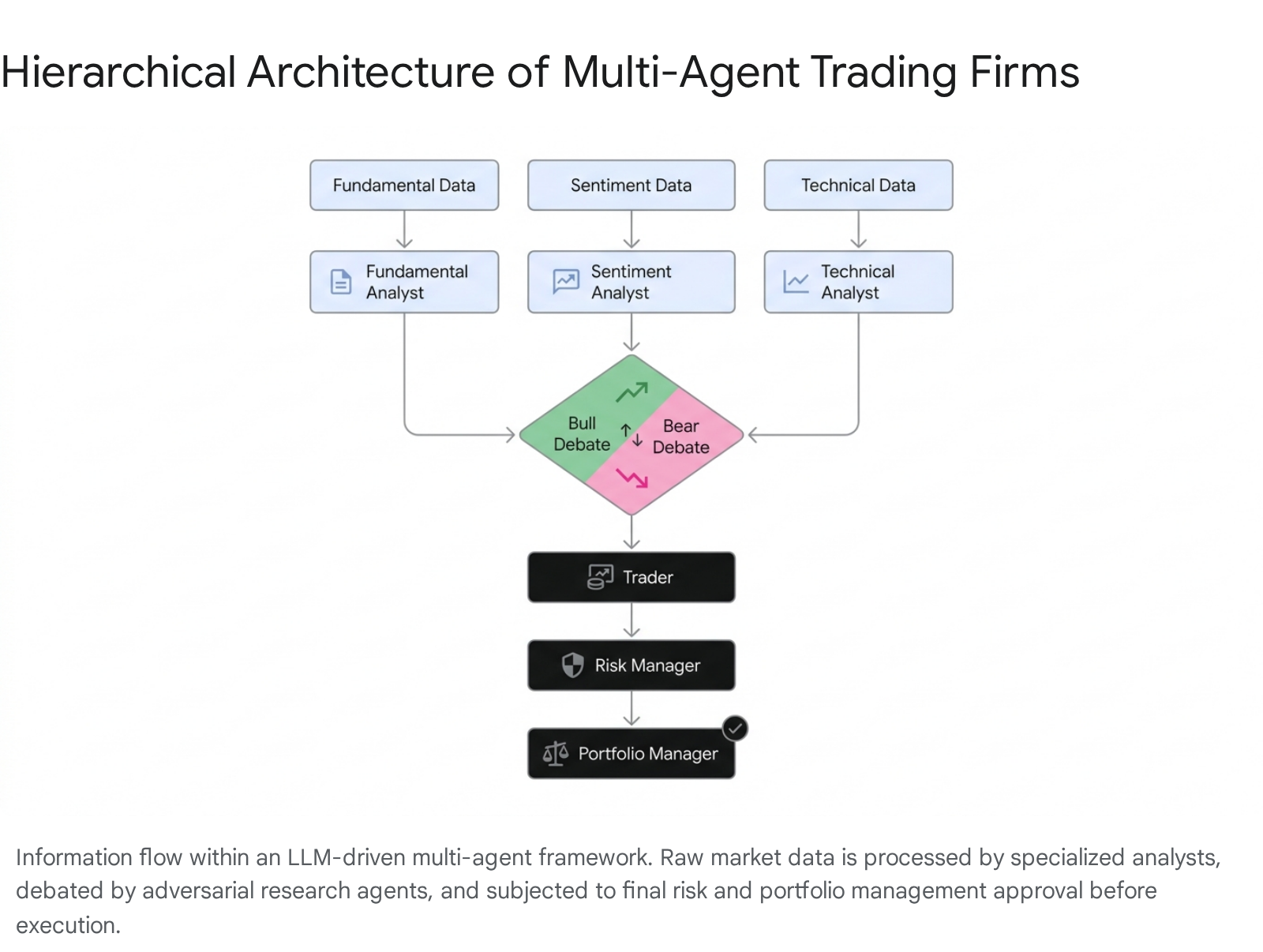
The architecture of multi-agent financial systems is explicitly modeled on the division of labor found within professional quantitative trading firms. By decomposing the monolithic task of market analysis into highly specialized roles, these frameworks mitigate the context-window limitations of individual LLMs and reduce the cognitive load required to process heterogeneous data streams 61213.
Functional Specialization and Cognitive Decomposition
In state-of-the-art frameworks, the information retrieval and analysis pipeline is distributed across distinct agent personas, each engineered to process specific data modalities. This decomposition is critical for maintaining reasoning stability over sequential financial decision-making tasks, which demand multiple interactions with highly volatile environments.
The fundamental analyst agent is typically tasked with parsing highly structured SEC filings, quarterly earnings transcripts, and corporate balance sheets to extract intrinsic value metrics and identify underlying financial health indicators 85. Conversely, the news and sentiment analyst agents operate on high-velocity, unstructured text streams, aggregating global macroeconomic headlines, social media discussions, and specific entity announcements to gauge short-term market mood and behavioral anomalies 5156. Technical analyst agents are specifically designed to process numerical time-series data, interpreting historical price trajectories, volume profiles, and standard mathematical indicators such as Moving Average Convergence Divergence (MACD) and the Relative Strength Index (RSI) 2517.
Frameworks such as FinCon enforce a strict unimodal processing mandate within this hierarchy. To ensure high reasoning quality and reduce task load, each analyst agent in the FinCon architecture processes a single information source in a unimodal manner 13. This setup mirrors an effective human team structure, where each analyst specializes in a specific function and synchronously filters market noise to extract essential insights before transmitting structured reports to a centralized manager agent 1318.
Multimodal Data Integration
While early LLM trading agents relied exclusively on text and tabular data inputs, recent advancements have introduced multimodal foundation agents. The FinAgent architecture extends the boundaries of agent perception by directly interpreting visual information, such as candlestick (K-line) charts, volume graphs, and technical pattern visual representations 192021.
By processing visual trend data alongside textual sentiment and numerical state spaces, multimodal agents emulate the visual pattern recognition frequently utilized by human technical traders 723. In benchmark evaluations spanning six financial datasets including equities and cryptocurrencies, the incorporation of a multimodal market intelligence module allowed FinAgent to achieve significant improvements in profitability, yielding over a 36% average improvement against state-of-the-art single-modality baselines 2021.
Dialectical Coordination and Risk Filtering
The reliance on generative models introduces the pervasive risk of confirmation bias and the rapid amplification of hallucinated signals - a failure mode that can be catastrophic in high-frequency financial applications. To mitigate these risks, leading architectures mandate structured debate protocols and independent risk-filtering layers prior to trade execution.
Adversarial Debate Protocols
The TradingAgents framework addresses confirmation bias by implementing a dedicated "Researcher Team" comprising explicitly adversarial personas: a Bullish Researcher and a Bearish Researcher. These agents independently evaluate the consolidated quantitative and qualitative reports produced by the analyst layer 612. Instead of relying on a monolithic consensus generation, these agents engage in a dialectical debate to surface latent risks, challenge initial assumptions, and produce a balanced risk-reward synthesis 1215.
This structured debate relies on natural language processing to emulate the adversarial scrutiny of a human investment committee. By forcing the LLMs to articulate and defend opposing viewpoints based on the same underlying market data, the framework reduces information degradation and preserves the benefits of collaborative reasoning, yielding more robust execution policies 2425.
Hierarchical Manager-Analyst Synchronization
Following the debate and synthesis phases, proposed trades are routed to a Risk Management node that operates independently of the profit-seeking mandate. This agent explicitly evaluates the proposed order against current portfolio exposure, market volatility regimes, and broader liquidity constraints.
In systems like QuantAgents and FinCon, this orchestration takes the form of scheduled meetings or structured synchronizations. QuantAgents requires agents to hold weekly market analysis and strategy analysis meetings, alongside dynamically triggered risk alert meetings 89. The FinCon framework utilizes a hierarchical manager-analyst structure where a risk-control component calculates metrics such as Conditional Value at Risk (CVaR). This manager agent possesses the authority to unilaterally reject, scale, or modify order parameters before transmitting them to a simulated exchange for execution, safeguarding the portfolio against tail-risk events driven by volatile agent behavior 813.
Memory Systems and Temporal Processing
The efficacy of any financial execution strategy is heavily dependent on the agents' ability to contextualize real-time volatility within broader historical regimes. Standard LLM context windows represent a "flat" memory structure, which struggles to prioritize temporal relevance and often suffers from information degradation over extended operational sequences 2829. Market microstructure simulation requires agents to process high-frequency order book updates without losing sight of long-term macroeconomic trends.
Hierarchical and Layered Memory Networks
To resolve these temporal processing constraints, frameworks such as TradingGPT and FinMem implement layered memory structures explicitly designed to mimic human cognitive processing and episodic recall. These systems typically partition historical data, price trajectories, and previous rationales into distinct hierarchical layers governed by custom mathematical decay functions:
- Short-term Memory: Captures highly volatile, tick-level data, real-time news alerts, immediate price changes, and the current state of the limit order book. This layer features an aggressive decay rate, ensuring agents are not anchored to stale intraday pricing signals 1031.
- Medium-term Memory: Archives persistent but evolving data structures, such as weekly strategy reports, recent portfolio rebalancing rationales, and quarterly earnings trends 31.
- Long-term Memory: Stores fundamental macroeconomic indicators, historical regime shifts (e.g., pandemic-era volatility, inflationary cycles), and core investment doctrines mapped to specific agent personas 1031.
By utilizing vector databases and retrieval-augmented generation (RAG) pipelines, agents selectively retrieve historical precedents that match current market embeddings. This architectural design allows the multi-agent system to draw analogies between contemporary market shocks and past historical events, resulting in superior automated trading outcomes by prioritizing immediate critical tasks without discarding strategic context 22832.
Conceptual Verbal Reinforcement
Standard reinforcement learning approaches in quantitative finance rely on numerical weight updates, adjusting a neural network based on a mathematical reward function. Multi-agent LLM systems introduce a novel optimization paradigm: text-based gradient descent.
The FinCon framework utilizes a mechanism termed "Conceptual Verbal Reinforcement" (CVRF) 833. Following a trading episode, the system initiates a self-critiquing process that compares the projected investment outcome against the actual realized market result. The agents extract conceptual insights from both successful and failed trading patterns, generating a natural language heuristic (e.g., "The technical breakout failed because macroeconomic sentiment indices indicated an impending contraction").
This conceptualized belief serves as verbal reinforcement. Instead of performing computationally expensive model fine-tuning, these updated beliefs are selectively propagated back into the prompt constraints of specific analyst agents. By continuously updating systematic investment beliefs through textual feedback, the system optimizes decision-making outcomes and adapts to non-stationary market environments with high efficiency 1811.
Market Microstructure Simulation Engines
While generating a logical, fundamentally sound trading decision is computationally complex, executing that decision in a realistic environment requires highly sophisticated market microstructure simulation. Evaluating an LLM agent's performance purely on historical closing prices ignores the mechanical realities of financial markets, rendering such backtests fundamentally flawed for real-world application. Recent algorithmic research has focused heavily on developing simulation engines that force LLMs to navigate execution realities.
Limit Order Book Mechanics and Execution Frictions
Unlike macro-level simulators that accept abstract "buy" or "sell" commands at a continuous historical price point, high-fidelity engines like StockSim and MarS require agents to interact directly with a Limit Order Book (LOB) 5104. The LOB represents the dynamic queue of outstanding bids and asks at discrete price levels. When an agent decides to execute a trade, it must determine the specific order type (market versus limit), the exact price point, and the volume requested.
This level of granularity introduces critical market frictions that test the robustness of LLM trading strategies: * Slippage: The difference between the expected price of a trade and the price at which the trade is actually executed. In LOB simulations, slippage is dynamically calculated based on the available volume at the best bid or ask; large market orders will consume liquidity across multiple price tiers, resulting in higher execution costs 435. * Latency: The time delay between the generation of an LLM trading signal and the arrival of the order at the simulated exchange. Platforms like StockSim incorporate production-grade infrastructure, utilizing message brokers such as RabbitMQ to enforce asynchronous coordination. Because the simulation clock runs deterministically, the LOB state may shift during the LLM's inference time, thoroughly testing the agent's robustness to execution delays and stale data 536.
Generative Market Impact Modeling
One of the most profound challenges in algorithmic execution is market impact: the reality that the act of buying a large quantity of an asset inherently drives the price up, while selling drives it down. Training RL agents or LLMs on historical data where their actions do not influence prices creates a fundamental mismatch between the training environment and live deployment, often degrading performance significantly 3537.
The MarS (Market Simulation) engine addresses this deficiency through generative order-level simulation. Powered by a foundation model termed the Large Market Model (LMM), MarS does not simply replay historical data. Instead, it utilizes auto-regressive transformers for order-batch sequence modeling and causal transformers for specific order sequence modeling 438. When a user or an LLM agent injects an order into the system, the LMM dynamically simulates how the broader market and the simulated clearing house will react, blending historical context with the emergent market impact of the injected actions 439.
| Simulation Engine | Architecture / Base Mechanism | Primary Real-World Mechanics Simulated | Evaluation Focus |
|---|---|---|---|
| StockSim 4536 | Dual-mode simulator with RabbitMQ messaging for asynchronous multi-agent coordination. | Limit-order book (LOB) dynamics, latency, slippage, deterministic time progression. | NLP research evaluation, decision consistency under microstructure stress, multi-agent coordination. |
| MarS (LMM) 10440 | Large Market Model utilizing generative order and order-batch sequence modeling. | Real-time transient market impact, multi-asset dependencies, flash liquidity events. | High-resolution market forecasting, strategy stress-testing, validation of Square-Root Law. |
| QuantAgents 89 | Manager-led coordination with real-world vs. simulated trading dual reward loops. | Forward-looking trend prediction, risk control analysis across continuous meetings. | Strategy adaptability, bridging the gap between post-reflection and anticipatory policy. |
Table 1: Comparison of prominent financial market simulation engines utilized for multi-agent LLM evaluation.
Mathematical Foundations: The Square-Root Law
Crucially, researchers have validated that the synthetic market trajectories generated by the MarS engine naturally adhere to the Square-Root Law of transient market impact, a foundational principle in quantitative finance 104. The law postulates that the price change ($\Delta$) caused by a trade is proportional to the asset's volatility ($\sigma$) and the square root of the normalized trading volume ($Q/V$), expressed as:
$$\Delta \propto \sigma \sqrt{\frac{Q}{V}}$$
By accurately modeling this concave, square-root dependence on order size and participation rate, generative simulators force multi-agent systems to behave realistically. To minimize their footprint and mitigate adverse market impact, LLM execution agents must learn to fragment large institutional orders into smaller tranches over time, frequently utilizing Time-Weighted Average Price (TWAP) or Volume-Weighted Average Price (VWAP) strategies, exactly as human execution traders do 1035. Furthermore, access to high-fidelity synthetic impact data allows researchers to use symbolic regression and genetic algorithms to discover new laws explaining market impact and long-term dynamics beyond standard empirical formulas 4.
Endogenous Economics and Bilateral Negotiation
While engines like MarS blend generative impacts with historical data, an emerging branch of simulation removes historical market data entirely, placing LLM agents in closed, endogenous experimental markets. In frameworks such as StockAgent and the bilateral negotiation platforms developed at NTU Singapore, prices are not replayed from historical exchanges; they emerge solely from the strategic interactions, bidding, and alternating-offer negotiations of the agents themselves 1242.
Massively Multi-Agents Role Playing (MMARP)
This endogenous methodology eliminates the pervasive issue of "test-set leakage," a critical vulnerability in LLM research where a model leverages latent memorization of historical financial events acquired during its pre-training phase, falsely inflating its apparent predictive capabilities 543.
In these closed environments, research has demonstrated that market-level properties - such as price levels, liquidity depth, and aggregate surplus - are heavily dictated by the informational environment and institutional matching rules, rather than relying solely on the session-level bargaining behavior of individual agents 12. To bridge the gap between individual irrationality and collective market intelligence, researchers deploy Massively Multi-Agents Role Playing (MMARP) methods. MMARP leverages the LLM-generated next-token weights to simulate repetitive prompting across vast populations of distinct buyer and seller personas. By analyzing the intersection of response curves between massive populations of LLM agents, the system filters out individual numerical hallucinations and approximates highly accurate, aggregate market dynamics 44.
This framework extends beyond equities trading. LLM-driven multi-agent simulations are increasingly applied to broader socio-economic modeling, such as simulating strategic data marketplaces where agents autonomously plan, search, price, and purchase datasets, successfully reproducing the emergence and evolution of complex market trends without predefined, rigid rules 45. Similarly, Perception-Deliberation-Action (PDA) loops powered by Chain-of-Thought reasoning have been utilized to model coupled epidemic-economic dynamics, demonstrating the versatility of LLM agents in complex, non-stationary simulation environments 1.
Optimization via Reinforcement Learning
The synthesis of multi-agent LLM systems with established Deep Reinforcement Learning (DRL) algorithms represents the current frontier in automated strategy optimization. In these hybrid architectures, the LLM provides semantic reasoning, intent formulation, and unstructured feature extraction, while the DRL algorithm handles the strict mathematical optimization of the execution policy and capital allocation.
Proximal Policy Optimization Integration
In advanced three-layer frameworks, the multi-agent LLM ecosystem is utilized to process heterogeneous data (news, SEC filings, sentiment) and output daily, quantifiable factor scores through a sophisticated Model Context Provider (MCP) mechanism 313. The MCP manages conflict resolution protocols and maintains a distributed context store of historical analysis patterns. These semantic factor scores are subsequently fed as the state space into a Proximal Policy Optimization (PPO) algorithm.

PPO, a highly stable reinforcement learning algorithm, iteratively updates the execution policy to maximize expected returns while penalizing excessive risk and drawdowns. Empirical validation of this specific hybrid approach across five US equities, using strict temporal partitioning to prevent look-ahead bias, demonstrated extraordinary results. Over a highly volatile out-of-sample test period spanning July 2024 to June 2025, the framework achieved an average annualized return of 53.87% and a Sharpe ratio of 1.702, vastly outperforming the buy-and-hold benchmark's 26.08% return and 0.765 Sharpe ratio 313.
Crucially, comprehensive ablation studies confirm that the synergy of semantic LLM processing and DRL execution significantly reduces maximum drawdown (averaging 12.54% compared to 30.24% for passive strategies), proving particularly resilient during market regime shifts and periods of high volatility where traditional quantitative models suffer severe degradation 313.
Dual Reward Mechanisms and Anticipatory Formulation
While DRL optimizes execution, optimizing the multi-agent cognitive process requires sophisticated reward mechanisms. Advanced systems such as QuantAgents optimize execution strategies by embedding agents simultaneously in two environments: a real-world market observation layer and a virtual simulated trading layer. This necessitates a dual reward mechanism.
Agents receive structured feedback based on two distinct criteria: their historical accuracy regarding real-world market outcomes, and their predictive execution success within the simulated trading sandbox 89. By forcing agents to formulate strategies that perform well in a forward-looking simulation, the framework aggressively counters the inherent LLM tendency toward "post-reflection" - the cognitive habit of simply generating plausible explanations for past adverse outcomes rather than proactively altering behavior for future, unseen market conditions 9. This dual reward system fundamentally forces the agents away from retrospective rationalization and into anticipatory policy formation, yielding overall returns approaching 300% over extended three-year backtesting windows 947.
Computational Routing and Model Selection
Simulating high-frequency microstructure dynamics with multi-agent ecosystems introduces immense computational overhead and severe latency constraints. In an order-driven market environment where conditions and limit order queues shift in milliseconds, waiting for a massive 400-billion parameter foundation model to generate a comprehensive fundamental analysis report before executing a trade is mathematically untenable.
To balance reasoning depth with operational execution speed, sophisticated frameworks like TradingAgents implement strategic model routing based on task complexity. This approach separates operations into distinct computational tracks: * Quick-Thinking Track: Models optimized for exceptionally low latency and high throughput (e.g., GPT-4o, GPT-4o-mini) are deployed for rapid data retrieval, format conversion, API interactions, tabular data structuring, and basic text summarization 2448. * Deep-Thinking Track: Models explicitly architected for complex multi-step logical deduction and chain-of-thought reasoning (e.g., OpenAI's o1-preview) are strictly reserved for complex fundamental analysis, adversarial dialectical debate generation, and final execution decision-making 2425. * Specialized Auxiliary Track: Smaller, domain-specific models fine-tuned extensively on financial corpora are utilized exclusively for discrete tasks such as isolating sentiment polarity from SEC filings or earnings calls 24.
| Computational Track | Typical Models Deployed | Assigned Multi-Agent Tasks | Primary Operational Benefit |
|---|---|---|---|
| Quick-Thinking | GPT-4o, GPT-4o-mini | Data summarization, API calls, tabular-to-text conversion. | Minimizes inference latency for high-volume data streaming. |
| Deep-Thinking | o1-preview, Claude-3.5 Sonnet | Evidence-based report writing, multi-step decision logic, risk-reward debates. | Enhances logical soundness and depth of analytical reasoning. |
| Specialized Expert | FinBERT, Domain-specific LLMs | Nuanced sentiment analysis, anomaly detection, regulatory text parsing. | Maximizes accuracy on narrow, domain-specific classification tasks. |
Table 2: Strategic LLM routing architecture utilized to balance reasoning depth and execution latency within the TradingAgents framework.
This hierarchical model selection is critical for latency arbitrage and operational viability in simulated environments. By restricting computationally expensive reasoning models to the final synthesis layer, the system can parse massive volumes of intraday data without suffering from compounding inference delays. Empirical backtesting of this specific routing strategy within the TradingAgents framework demonstrated exceptional performance, yielding cumulative returns of over 26% on baseline tech equities (e.g., AAPL) and generating massive Sharpe ratios, while consistently providing highly explainable natural-language rationales for its execution timing 2425.
Structural Limitations and Future Directions
Despite significant empirical successes in bridging natural language processing and quantitative finance, the deployment of multi-agent LLM systems in market microstructure simulation remains constrained by several structural and mathematical limitations.
Foremost is the pervasive risk of test-set leakage and look-ahead bias. Because foundational LLMs are trained on vast, uncurated corpora of internet data - which inherently include historical financial datasets, news archives, and historical price tickers - simulating past market events often tests the model's latent memory recall rather than its analytical reasoning 543. While platforms like StockAgent attempt to mitigate this via purely endogenous, isolated simulation, any testing over recognizable historical periods (e.g., the 2008 financial crisis or the 2020 pandemic crash) remains highly susceptible to look-ahead bias, as the agent may implicitly "know" the macroeconomic outcome 342.
Furthermore, while LLMs possess exceptional semantic processing capabilities, their native mathematical literacy remains unreliable. Market execution inherently involves complex numerical forecasting, portfolio risk sizing, and rapid floating-point arithmetic within the limit order book. Researchers have repeatedly noted that agents can occasionally hallucinate numerical values, fail to correctly parse deep limit order book volumes, or struggle with precise probability distributions 44.
Finally, while current generative simulations effectively capture transient market impact and basic slippage, capturing the full complexity of predatory algorithmic trading, multi-asset statistical arbitrage dependencies, and deep-tier liquidity fragmentation presents an ongoing computational bottleneck 540. Future research directions strongly point toward hybrid architectures where LLMs operate strictly as high-level strategic orchestrators - processing news, reading balance sheets, and formulating qualitative hypotheses - while entirely offloading the mathematical execution optimization, risk calculation, and sub-millisecond LOB interaction to deterministic quantitative models and deep reinforcement learning engines 2313.