RAG Architectures for Real-Time Financial News and Trade Signals
Introduction to Financial Retrieval-Augmented Generation
The integration of advanced natural language processing into quantitative finance has fundamentally altered the paradigm of algorithmic trading. Historically, automated market microstructure analysis relied almost exclusively on structured datasets, such as limit order book feeds, historical price volume, and standardized fundamental metrics 11. However, financial markets increasingly price event-based outcomes in real time, reflecting geopolitical shifts, regulatory policy updates, and rapid corporate developments 1. The sheer volume and velocity of unstructured financial data - ranging from regulatory filings and earnings call transcripts to multinational news streams and localized social media sentiment - have outpaced the processing capabilities of traditional natural language toolkits 3.
While Large Language Models (LLMs) possess unprecedented contextual reasoning capabilities, their deployment in high-stakes financial environments is constrained by critical architectural limitations. Standard LLMs rely on static parametric memory, rendering them incapable of interpreting real-time market events without continuous, computationally prohibitive retraining 256. Furthermore, generative models exhibit a well-documented propensity for factual hallucination - fabricating data or interpolating numerical figures when confronted with knowledge gaps 789. In algorithmic trading, where a fabricated revenue metric or a misinterpreted compliance clause can trigger catastrophic automated execution, these limitations present unacceptable operational risks 93.
Retrieval-Augmented Generation (RAG) has emerged as the definitive infrastructural solution to these challenges 34. By dynamically retrieving contextually relevant, up-to-date information from external databases at inference time, RAG effectively grounds the language model's generative output in verifiable reality 675. The model ceases to act as an encyclopedic memory bank and instead functions as a reasoning engine, synthesizing external evidence to generate actionable intelligence 5.
However, generic open-domain RAG pipelines fail to meet the rigorous demands of institutional finance. Financial documents are highly heterogeneous, blending dense narrative prose with complex numerical tables and visual diagrams 6715. Furthermore, financial information is subject to rapid temporal decay and frequent contradiction, requiring systems to not only retrieve text but to weigh its chronological validity and source credibility 89. Finally, the execution of algorithmic trading strategies imposes strict sub-second latency budgets, rendering the multi-second processing times of standard RAG deployments obsolete 10.
This report provides an exhaustive analysis of the leading RAG architectures engineered specifically for real-time financial news ingestion and trade signal extraction. It examines the structural mechanics of advanced multi-path and multi-agent retrieval frameworks, details the methodologies for temporal grounding and conflict resolution, evaluates the underlying database infrastructures necessary for low-latency execution, and explores the multilingual adaptations required for cross-border signal extraction in dynamic Asian markets.
Multi-Path and Hierarchical Retrieval Systems
Standard RAG implementations typically rely on a linear "retrieve-then-read" pipeline utilizing a single dense embedding model for semantic search 719. This monolithic approach is inadequate for processing extensive corporate disclosures, such as 10-K filings or lengthy prospectus documents, where the precise answer to a query may depend on cross-referencing a localized compliance clause with a broader financial table 611. To address the limitations of single-path retrieval, quantitative researchers have developed sophisticated multi-aspect and hierarchical architectures.
The FinSage Multi-Aspect Framework
The FinSage framework represents a significant advancement in processing multi-modal financial documents for regulatory compliance and strategic analysis 26. Empirical evaluations demonstrate that FinSage achieves a 92.51% retrieval recall rate on complex financial datasets, surpassing leading baseline methodologies by 24.06% in end-to-end question-answering accuracy 2612. The architecture achieves this through three highly specialized components.
The first component is the Financial Filings Pre-processing (FFP) pipeline, designed to homogenize heterogeneous data formats 613. Standard text chunking methods frequently destroy the semantic integrity of financial tables by flattening them into unreadable text streams. The FFP pipeline circumvents this by utilizing parsing algorithms to isolate text, figures, and tables 2. Large vision-language models are then deployed to translate figures into structured captions and rewrite complex tables into coherent textual statements, preserving the numerical relationships 2. Following this, the pipeline applies redundant chunk de-duplication via cosine similarity thresholds and utilizes a language model to perform co-reference resolution, ensuring that pronouns within isolated chunks are replaced with their explicit entity antecedents 2. Finally, hierarchical metadata summaries are appended to every chunk to maintain document structure 2.
The core of the FinSage architecture is its Multi-Path Retrieval (MPR) system. Recognizing that different types of queries require different matching paradigms, the MPR executes four parallel retrieval strategies 2. The pipeline utilizes a BM25 sparse retriever to capture exact lexical matches, which is critical for highly specific regulatory acronyms or unique financial identifiers. Concurrently, a BGE-M3 dense retriever evaluates semantic similarity, while a dedicated metadata retriever executes searches across the high-level section summaries generated during pre-processing 2. The fourth path integrates Hypothetical Document Embeddings (HyDE), wherein an LLM generates a synthetic, hypothetical answer to the user's query, which is then embedded to retrieve structurally similar chunks from the database 2. Following retrieval, a chunk bundling module concatenates semantically adjacent text blocks to ensure the generative model receives cohesive context rather than fragmented sentences 2.
To distill the expanded candidate pool generated by the multi-path search, FinSage employs a Domain-Specialized Document Re-ranker (DRR) 13. The DRR functions as an intelligent cross-encoder filter, scoring the contextual alignment between the query and the retrieved chunks 2. This module is explicitly fine-tuned via Direct Preference Optimization (DPO) to prioritize chunks containing legally significant terminology and compliance-critical phrases 213. Furthermore, the DRR scoring mechanism incorporates a quantifiable time penalty, elevating the rank of documents with publication dates more closely aligned to the query's temporal context 2.
Hierarchical Table-Text Integration
While multi-path retrieval enhances recall, it does not inherently solve the challenge of joint reasoning across text and numerical tables - a frequent requirement in equity research. The HierFinRAG architecture was engineered specifically to address the complex interplay between narrative corporate reporting and structured financial statements 7.
Existing systems generally treat tables and text as isolated modalities. HierFinRAG introduces a Table-Text Graph Neural Network (TTGNN) that explicitly models the structural and semantic dependencies between individual table cells and the surrounding narrative paragraphs 7. The framework constructs a localized knowledge graph where numerical data points are directly linked to the sentences that explain their variance or methodology 7.
When processing queries that require arithmetic deduction (e.g., calculating year-over-year margin compression based on both a tabular figure and a footnote adjustment), HierFinRAG employs a Symbolic-Neural Fusion module. This mechanism dynamically assesses the query intent; if mathematical computation is required, the system routes the extracted numerical parameters to a deterministic symbolic calculator rather than forcing the generative LLM to perform arithmetic, which is a known source of hallucination 7. Benchmark testing on the FinQA dataset indicates that HierFinRAG achieves an Exact Match score of 82.5%, significantly outperforming generalized multimodal models while maintaining lower inference latency than heavily agentic approaches 7.
Addressing Granular Retrieval Failures
Even with advanced multi-path systems, retrieval failures frequently occur at the micro-level. Research decomposing retrieval errors in long-document financial analysis indicates a persistent gap between document discovery and granular chunk retrieval 1114. A system may successfully identify the correct 200-page SEC 10-K filing but fail to surface the specific sub-section containing the requisite data 11.
To close this gap, recent architectural adaptations introduce domain fine-tuned page scorers. These models treat the document page as an intermediate hierarchical unit between the macro-document and the micro-chunk 14. By fine-tuning a bi-encoder specifically to evaluate page-level semantic coherence within regulatory filings, these systems ensure that the subsequent chunk-level search is restricted to the most probabilistically relevant sections of the document, thereby reducing the noise injected into the generative model's context window 1114.
| Retrieval Architecture | Core Structural Innovation | Primary Retrieval Mechanisms | Targeted Failure Mode | Benchmark Advantage |
|---|---|---|---|---|
| FinSage | Multi-modal Pre-processing & DPO Re-ranking 26 | Sparse (BM25), Dense (BGE-M3), Metadata, and HyDE paths 2 | Missed compliance terminology and fragmented context 2 | 92.51% recall rate; 24.06% accuracy gain on FinanceBench 612 |
| HierFinRAG | Table-Text Graph Neural Network (TTGNN) 7 | Graph-based semantic linking & Symbolic-Neural Fusion 7 | Mathematical hallucination and isolated tabular data 7 | 82.5% Exact Match on FinQA; 3.5x faster inference 7 |
| Page-Scored RAG | Intermediate Bi-encoder Page Evaluation 1114 | Hierarchical filtering: Document → Page → Chunk 14 | Correct document identified but target chunk missed 11 | Quantifiable reduction in within-document search failures 14 |
Multi-Agent Orchestration Frameworks
While hierarchical and multi-path retrieval systems excel at factual extraction, autonomous algorithmic trading and comprehensive equity research require synthesis, multi-step logical deduction, and strategic planning. To move beyond isolated question-answering, financial engineering teams are increasingly deploying Agentic RAG systems 4. These architectures coordinate multiple specialized AI agents, utilizing Chain of Thought (CoT) prompting to emulate the sequential reasoning processes of human analysts 41525.
The FinRobot Enterprise Architecture
The FinRobot framework represents a comprehensive implementation of multi-agent orchestration for financial research and enterprise resource planning 151617. Unlike static, rule-based systems, FinRobot dynamically synthesizes workflows to handle both structured SQL data and unstructured market news 17.
The system operates across a stratified architectural stack. The foundation is the LLMOps and DataOps layer, which manages continuous model fine-tuning and orchestrates real-time data ingestion pipelines 25. Above this sits the Financial AI Agents layer, which is governed by a "Smart Scheduler" that acts as a central director, routing specific sub-tasks to the most capable specialized agents based on continuous performance tracking against domain-specific datasets 25.
A critical innovation within the FinRobot ingestion pipeline is its Data Modeling Layer, which translates fragmented textual news and market updates into an event-centric representation utilizing the 5W3H1R schema (Who, What, Why, When, Where, How, How much, How long, Result) 17. By mapping unstructured paragraphs into this highly structured matrix, the system bridges the semantic gap, enabling the generative models to reason over market events as coherent, causal decision sequences rather than isolated keywords 17.
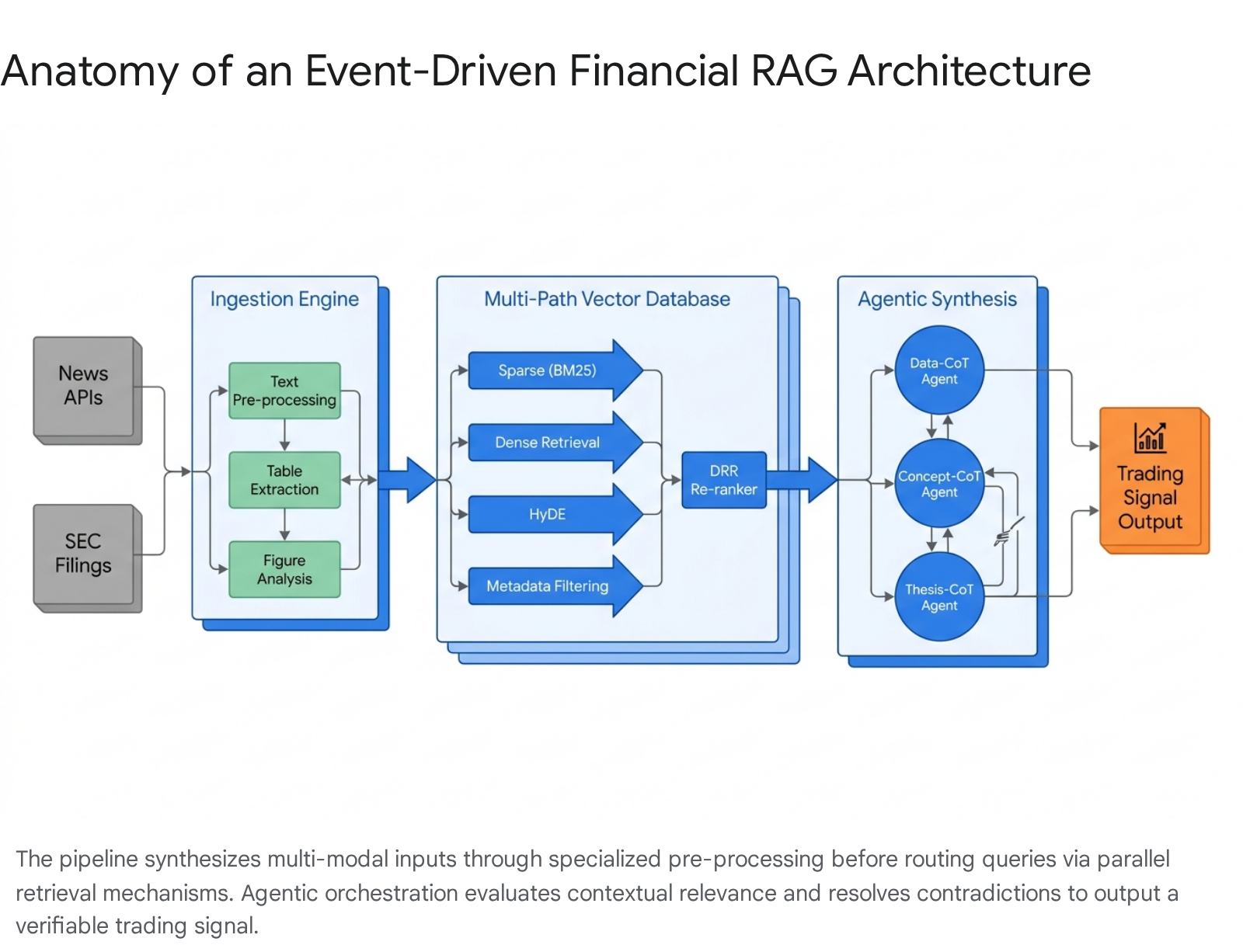
Sequential Chain of Thought Decomposition
Once data is ingested and structured, the FinRobot framework initiates a multi-layered Chain of Thought sequence driven by distinct agent personas 1516.
- Data-CoT Agent: Acting as the analytical foundation, this agent aggregates the processed inputs, combining structured quantitative metrics (e.g., pricing data, fundamental ratios) with the qualitative insights extracted via the 5W3H1R schema 1517. It ensures that the subsequent reasoning agents receive a mathematically and semantically verified dataset.
- Concept-CoT Agent: Serving as the strategic core, this agent applies financial reasoning to contextualize the data 15. It performs competitive benchmarking, sentiment evaluation of the management's tone, and structural analysis of the industry landscape 1516.
- Thesis-CoT Agent: Operating at the synthesis level, this agent consolidates the localized insights into a comprehensive investment thesis 1516. It generates actionable trading recommendations, risk assessments, and valuation projections formatted to meet sell-side institutional research standards 15.
Through this rigorous separation of perception, analysis, and action, agentic RAG architectures mitigate the generative overreach common in monolithic models. Human expert panels evaluating the FinRobot outputs have scored the system at 9.5 out of 10 for analytical accuracy and 9.4 for logicality, demonstrating the viability of automated multi-agent reasoning for complex equity research 15.
Temporal Grounding and Knowledge Evolution
A fundamental vulnerability of basic RAG pipelines in the financial domain is the reliance on static vector databases. Financial reality is highly diachronic; corporate executives change, macroeconomic policies pivot, and market sentiment fluctuates constantly. If a RAG system processes a query regarding a company's current supply chain risks but retrieves a highly semantic, yet chronologically obsolete, analysis from three years prior, the resulting trade signal will be actively harmful 89. Ensuring "temporal grounding" - the capacity to retrieve evidence that is both topically relevant and temporally contiguous for the specific duration of the query - is a critical architectural requirement 818.
Time-Aware Retrieval Frameworks
Standard dense retrievers optimize exclusively for semantic similarity, fundamentally lacking the mechanisms to weigh the temporal validity of text chunks 918. To address this deficit, researchers have developed frameworks such as Time-Aware RAG (TA-RAG), designed explicitly to handle longitudinal queries 8.
The TA-RAG pipeline integrates temporal logic at the point of ingestion. It utilizes Named Entity Recognition (NER) algorithms, such as those provided by SpaCy, to execute explicit date filtering 818. This ensures that every text chunk ingested into the vector database is firmly anchored to a specific temporal identifier. When a user submits a query, the system parses the input to separate the semantic intent from the temporal constraints 8. The time-sensitive retriever then calibrates its search, dynamically balancing the cosine similarity of the embedding with the temporal relevance of the document's event interval 818.
The necessity for these architectures is highlighted by the Analytical Diachronic Question Answering Benchmark (ADQAB), a testing suite utilizing a hybrid corpus of real and synthetic financial news 818. Empirical testing on ADQAB indicates that the implementation of strict temporal routing and time-aware retrieval yields substantial gains, surpassing standard RAG implementations by 13% to 27% in answer accuracy for temporally constrained financial questions 818.
Dynamic Knowledge Graph Assimilation
While filtering query results by date improves accuracy, it does not address the underlying reality that financial relationships and entity states evolve. To track these shifting dynamics, advanced architectures integrate evolutionary reasoning systems, such as the EvoReasoner framework, augmented by dynamic knowledge graphs 192021.
Unlike conventional approaches that assume a static snapshot of a Knowledge Graph (KG), the EvoKG module continuously and incrementally updates the underlying graph structure as unstructured news and filings stream into the system 2021. This architecture supports "Global-Local Entity Grounding" 19. When a RAG system queries an entity subject to rapid change (e.g., the CEO of a volatile tech firm), the EvoReasoner performs a global grounding to the canonical entity that spans the entire history of the graph, alongside a local grounding to the specific surface-level context present in the most recent temporal snapshot 1921.
During the exploration phase, candidate information triplets are reranked based on their temporal alignment with the query's subgoals. Each candidate triplet is verbalized into a natural language string that includes its validity interval, allowing the system to compute a similarity score that accounts for both semantics and time 21. The efficiency gains from this architecture are profound; evaluations demonstrate that an 8-billion parameter LLM integrated with the EvoReasoner framework can match the reasoning performance of a massive 671-billion parameter model that relies on static prompting, simply by leveraging continuously updated, temporally grounded contextual data 1921.
Conflict Resolution and Contradictory Data Handling
In global financial markets, news ingestion pipelines frequently encounter overlapping reporting, speculative rumors, and direct contradictions. A single geopolitical event or corporate action may generate hundreds of news articles presenting conflicting data points or differing interpretations of market impact 3233. A generic RAG system will retrieve these conflicting chunks and pass them directly into the LLM's context window. Without algorithmic guidance, the generative model will typically either hallucinate a synthesis, average the conflicting numbers, or output a paralyzed, neutral response 5934.
Confidence-Based Contradiction Resolution
To maintain the integrity of the knowledge base, architectures like EvoKG decouple factual consistency from pure semantic matching 2135. When the ingestion pipeline processes new documents, it does not indiscriminately overwrite existing facts based on recency, nor does it arbitrarily discard conflicting data 1921. Instead, it employs a robust confidence-based contradiction resolution mechanism 1920.
When multiple candidate values exist for a specific entity relationship (e.g., conflicting reports on a central bank's projected rate hike), the system retains all candidate assertions and computes a dynamic confidence score ($C(o)$) for each 21. This score is determined by a multivariate formula: 1. Frequency ($f(o)$): The normalized occurrence rate of the specific assertion across multiple, independent source extractions 21. 2. Temporal Decay ($\Delta t(o)$): The time elapsed since the fact was last observed, weighted by an algorithmic decay parameter that gradually reduces the influence of older information 21. 3. Source Credibility ($w(o)$): A pre-assigned weighting metric that prioritizes authoritative sources (e.g., regulatory databases or primary exchanges) over aggregated news portals or social media commentary 1921.
During the generation phase, the RAG system relies on weighted majority voting. It plots multiple reasoning routes and selects the final answer by aggregating the predictions based on their associated path confidence scores, thereby neutralizing the impact of isolated reporting errors or targeted market disinformation 2122.
Nugget-Based Validity Filtering
The evaluation and resolution of conflicting facts are increasingly handled through "nugget-based" architectural designs, a paradigm adapted from standardized evaluation frameworks like the TREC 2024 RAG Track 353839. In these systems, complex financial narratives are distilled into atomic, indivisible information units termed "nuggets" 939.
Each nugget is tagged with a specific validity interval. The system is designed to algorithmically detect conflicts downstream when multiple nuggets share the same semantic key but possess conflicting values and overlapping temporal validity 9. When a novel, contradictory fact is extracted from a single new document, it is temporarily isolated and flagged with a "Deprecated" or unverified state 9. The system's existing consensus remains "Active" until the new assertion accumulates sufficient corroboration across multiple independent sources to surpass an evidence redundancy threshold 9.
This conservative state-assignment logic ensures that a single hallucinated extraction or a piece of deliberate algorithmic manipulation cannot instantly corrupt the overarching trading strategy. Empirical testing demonstrates that while this strict conflict filtering marginally decreases the sheer volume of retrieved documents (a slight drop in recall), it significantly increases the governance score and the temporal accuracy of the resulting trade signals 9.
Data Infrastructure and Incremental Vector Indexing
The theoretical sophistication of multi-agent reasoning and temporal grounding is functionally irrelevant if the underlying database architecture cannot sustain the high-velocity data ingestion required by capital markets. Financial news feeds and exchange disclosures operate continuously. Consequently, the operational mechanisms governing how vectors are stored, updated, and queried dictate the ultimate viability of the RAG pipeline 640.
The Bottleneck of Batch Processing
A prevalent vulnerability in enterprise RAG deployments is the reliance on batch indexing. When a corporate knowledge base or a news corpus changes, standard practice has often involved periodically wiping the vector index and re-embedding the entire dataset from scratch 4142.
In a financial context, batch processing introduces severe systemic risks. Computationally, full re-indexing incurs prohibitive API costs and massive operational overhead 42. More critically, it creates a synchronization lag. During the window between batch updates, the vector store and the real-world source of truth are fundamentally misaligned; the trading algorithms operate on increasingly stale data, executing decisions based on obsolete market conditions 404243.
Real-Time Incremental Indexing and Database Selection
To support continuous algorithmic trading, financial data engineering has transitioned toward incremental, near-real-time updates and delta indexing 414223. Rather than rebuilding indices, modern pipelines detect granular changes (inserts, updates, deprecations) at the document level. Only the modified text is chunked, embedded, and natively upserted into the vector space, ensuring clean replacement without leaving orphaned data vectors 41.
This operational shift necessitates high-performance database architectures capable of managing continuous write-loads without degrading read latency.
| Database Architecture | Core Technology | Relevance to Financial RAG | Key Advantages for Ingestion |
|---|---|---|---|
| pgvector (PostgreSQL) | Block Range INdexes (BRIN) & WAL Streaming 4324 | Seamlessly replicates relational data updates to the vector index 43. | Atomic updates, zero impact on source databases, chronological indexing efficiency 4324. |
| LanceDB | Columnar format & Multi-modal Lakehouse | Unifies SQL, vector, and hybrid retrieval with metadata filtering . | High-speed analytical filtering combined with vector search; low-cost S3 durability . |
| Redis | In-memory caching & Tunable HNSW 40 | Handles massive concurrent loads (66,000 insertions/sec) with sub-millisecond latency 40. | Ultra-low latency for hybrid keyword/vector search in high-frequency environments 40. |
Furthermore, the implementation of bitemporal data modeling is becoming a standard requirement for quantitative RAG deployments 24. By strictly partitioning "valid time" (the exact moment an event occurred in the real world) from "transaction time" (the moment the data was successfully ingested and embedded into the database), systems can mathematically enforce chronological integrity 24. This prevents look-ahead bias and data leakage, ensuring that historical backtests of RAG-driven trading strategies accurately reflect the information available at the exact moment of the simulated trade 24.
Latency Optimization for Sub-Second Execution
In interactive enterprise applications and, more acutely, in automated trading environments, the speed of intelligence retrieval is as critical as its accuracy. While LLM capabilities have expanded dramatically, the computational overhead of embedding queries, executing semantic similarity searches across millions of vectors, retrieving context, and generating tokens introduces significant latency 24.
Industry benchmarks indicate that 68% of production RAG deployments currently exhibit P95 latencies exceeding 2 seconds 10. In algorithmic trading, a multi-second delay effectively renders the extracted signal obsolete, exposing the executing algorithm to severe market slippage and arbitrage risks 110. To remain competitive, quantitative teams are forced to architect RAG pipelines capable of sub-second execution.
The FLASH Framework Budget
To operationalize ultra-low latency, engineers have developed strict systemic methodologies, notably the Fast Latency Architecture for Streaming Hybrid retrieval (FLASH) framework 1047. The FLASH methodology rejects isolated component optimization in favor of a rigid, end-to-end latency budget 10.
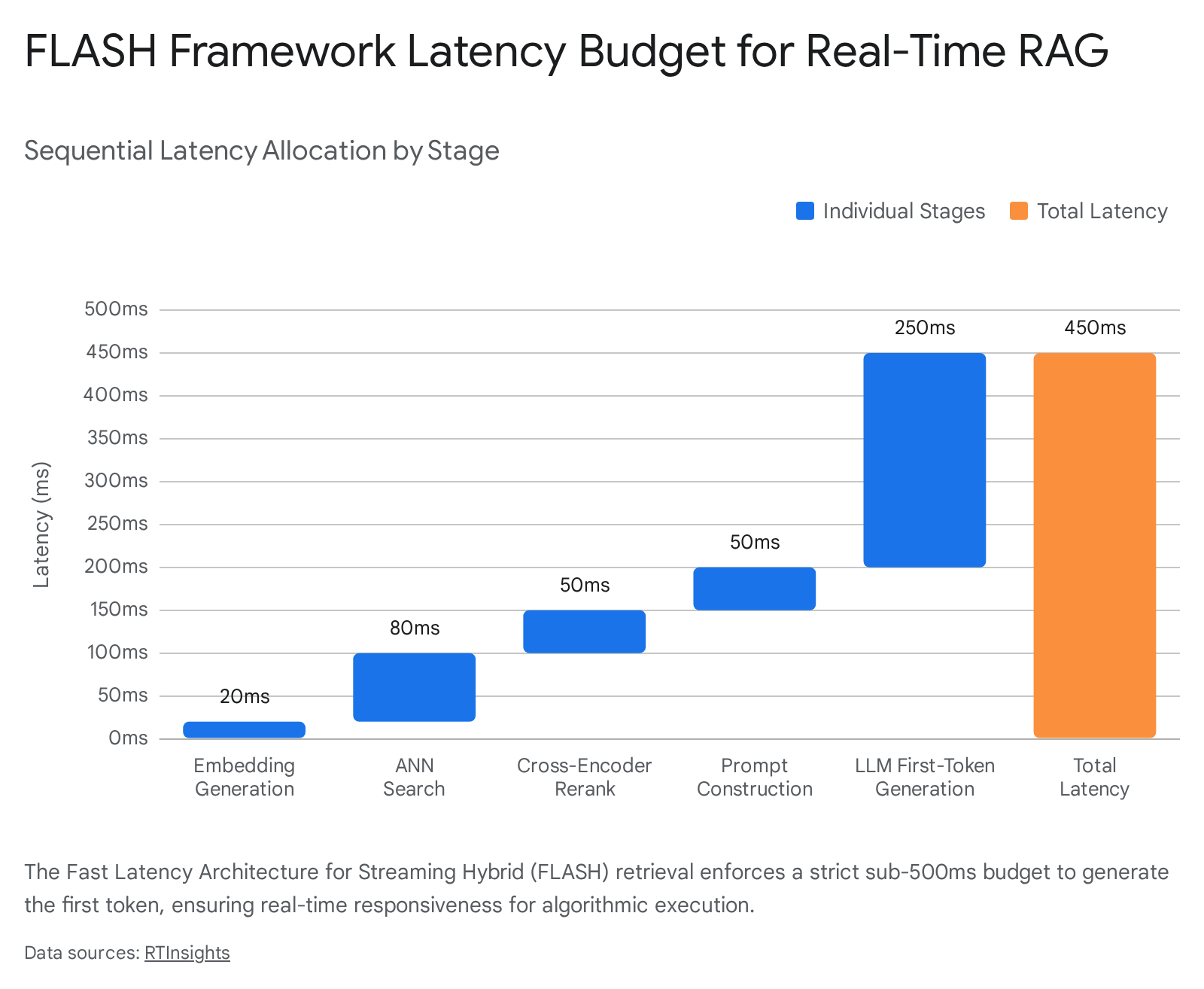
The framework surgically allocates processing time across the sequential steps of the RAG pipeline. The generation of the initial query embedding is restricted to 20 milliseconds 10. The subsequent Approximate Nearest Neighbor (ANN) search within the vector database is capped at 80 milliseconds 10. The retrieved chunks are then passed through a cross-encoder for re-ranking, a computationally dense process limited to 50 milliseconds 10. Prompt construction and context assembly are granted 50 milliseconds, leaving a maximum of 250 milliseconds for the language model to process the context and generate the first token of the response 10.
Adhering to this 450-millisecond cumulative budget necessitates significant architectural compromises. Teams frequently utilize in-memory Redis caches tuned with specific Hierarchical Navigable Small World (HNSW) parameters to accelerate the ANN search 40. Furthermore, achieving a 250-millisecond first-token generation time generally precludes the use of massive, unoptimized foundation models, forcing the adoption of smaller, highly quantized, or parameter-efficient local models hosted on dedicated GPU clusters 10.
Sentiment Analysis Models and Trade Signal Generation
The ultimate objective of a financial RAG pipeline is the extraction of actionable intelligence. The retrieved and verified news context must be translated into a quantifiable metric - typically a sentiment polarity score or an event-impact vector - that can be ingested by the downstream trading algorithm 4849. The industry is currently characterized by a dichotomy in model selection for this task: ultra-fast, domain-specific encoder models versus highly capable, generative Large Language Models.
The Baseline: FinBERT and Traditional Encoders
For years, the standard for financial sentiment analysis has been FinBERT, an encoder model pre-trained on a vast corpus of corporate communications, analyst reports, and Reuters news streams 505152. FinBERT natively understands the highly specialized vocabulary of capital markets 51. It correctly interprets that terms like "uncertainty" or "liability" within an SEC filing carry distinct, heavily weighted risk implications that differ substantially from their conversational usage 51.
In comparative testing, FinBERT achieves precision rates of 96% to 98% across financial sentiment categories, vastly outperforming generalized BERT models or traditional lexicon-based tools like VADER 51252655. More importantly for trading infrastructure, its lightweight architecture enables sentiment scoring with latencies under 100 milliseconds, allowing seamless integration into high-frequency execution systems 5155. However, its capacity is strictly limited to discriminative classification; it cannot synthesize complex, multi-document narratives or perform the multi-hop reasoning required to evaluate cascading macroeconomic events 5055.
Large Language Models and Parameter-Efficient Fine-Tuning
The expansion of context windows and the advent of advanced prompting techniques have positioned generative LLMs (such as the GPT-4 family, Llama-3, and Qwen) as superior tools for holistic market analysis 51555657. While a traditional model evaluates a single headline, a RAG-backed LLM can ingest an entire Reddit comment thread, a dense 10-K filing, and a breaking news alert simultaneously, synthesizing the data to output a nuanced event-impact score 4855.
Recent empirical evaluations indicate that cutting-edge generative models, operating in zero-shot or few-shot contexts, consistently outperform discriminative transformer-based models across comprehensive financial evaluation metrics 2526. However, the deployment of models with hundreds of billions of parameters incurs severe latency and memory costs, rendering them impractical for real-time applications 5052.
To resolve this, quantitative researchers employ Parameter-Efficient Fine-Tuning (PEFT) techniques to optimize smaller, open-weight models for financial tasks 57.
| Model Architecture | Implementation Approach | Key Advantages | Operational Limitations |
|---|---|---|---|
| FinBERT | Direct deployment / Domain pre-trained 5152 | Ultra-low latency (<100ms); highly accurate on targeted financial syntax 5155. | Lacks generative capacity; limited context windows prohibit multi-document synthesis 5055. |
| GPT-4o / Claude 3.5 | API-based RAG integration 2526 | Deep reasoning; superior handling of complex, overlapping financial narratives 5125. | Prohibitive latency for HFT; high API token costs; privacy concerns for proprietary data 5058. |
| Llama-3.1-8B / Qwen-3-8B | LoRA / QLoRA fine-tuning 57 | Balances high accuracy (up to 88.9% on PhraseBank) with low GPU memory footprint 57. | Requires significant engineering overhead to fine-tune; Mixture-of-Experts routing adds complexity 57. |
By applying Low-Rank Adaptation (LoRA) or Quantized LoRA (QLoRA) to models like Llama-3.1-8B or Qwen-3-8B, engineers update only a minimal subset of the model's parameters using financial datasets 57. The results are highly effective: fine-tuned, 8-billion parameter models achieve up to 88.9% accuracy on the Financial PhraseBank benchmark, matching the capabilities of massive proprietary models while maintaining rapid inference speeds 57.
The efficacy of combining robust RAG retrieval with advanced sentiment analysis is evident in live market applications. Validation studies analyzing institutional order flow (LSEG Trading Flow) demonstrate that real-time trade classifications, augmented by predictive intelligence, can forecast institutional portfolio adjustments (13F filings) with a 65.5% directional accuracy rate, providing algorithmic traders with a 45- to 135-day informational advantage over public disclosures 27.
Multilingual Processing and Asian Market Nuances
By 2026, the macroeconomic landscape is increasingly dictated by events outside the traditional Western financial nexus. Geopolitical volatility, localized energy shocks resulting from Middle Eastern conflicts, and shifts in semiconductor supply chains demand that global quantitative funds ingest and analyze signals from Asian markets in real time 286162. Implementing a RAG architecture for this environment introduces profound linguistic and structural challenges.
The Translation Bottleneck and Native Regional Models
Historically, the standard approach to processing foreign financial news involved utilizing an automated translation layer before feeding the English text into a traditional NLP model. In modern high-frequency RAG architectures, this is an unacceptable bottleneck. AI translation introduces significant latency and frequently degrades domain-specific semantic nuance - a critical failure point when parsing complex regulatory shifts in Japanese or structural policy nuances from Chinese state media 6364.
Consequently, the architecture of global RAG systems has fundamentally shifted toward native multilingual embeddings and localized Foundation Models 6365. Modern multilingual RAG frameworks utilize highly specialized embedding models capable of encoding text from dozens of languages into a unified, high-dimensional vector space 6364. This preserves semantic parity; an English query regarding "Taiwanese semiconductor export limits" will retrieve the mathematically identical vector representation of the original Mandarin policy document without requiring an intermediate translation step 6364.
Furthermore, to process these natively retrieved documents, the industry is pivoting away from English-dominated LLMs toward models explicitly trained on regional linguistic data 65. * SEA-LION (South East Asian Languages In One Network): Developed to ensure equitable linguistic representation, this architecture natively supports 11 Southeast Asian languages, including Indonesian, Vietnamese, Thai, and Malay, providing deep contextual understanding of regional corporate communications 65. * SeaLLM: Developed by Alibaba DAMO Academy, optimized for the broader Asian linguistic footprint to capture localized market sentiment 65. * Bhashini: An expansive Indian initiative supporting over 350 localized AI models, critical for parsing the unstructured data generated by the rapid digitization of India's financial sector 65.
Cross-Border Signal Extraction
The capacity to execute native, low-latency RAG across multiple Asian languages acts as a distinct differentiator in alpha generation. For example, assessing the macroeconomic impact of crude oil price shocks on the Asian region requires a highly localized approach. Economies such as South Korea, the Philippines, and Thailand possess unique primary energy mixes and distinct central bank policies 62.
To accurately predict the depreciation of the Thai Baht (THB) or the Korean Won (KRW) amid geopolitical escalation, a RAG system must simultaneously ingest and synthesize overlapping domestic news reports, localized supply chain updates, and regional policy announcements in their native languages 62. By leveraging multilingual vector spaces and region-specific foundation models, automated trading systems can bypass the translation bottleneck, extract localized sentiment vectors, and execute cross-border currency and equity trades based on real-time, culturally nuanced insights 626364.
Conclusion
The architecture of Retrieval-Augmented Generation for financial news ingestion and trade signal extraction has evolved far beyond basic semantic search. In 2026, the leading frameworks are defined by their capacity to systematically manage complexity, ambiguity, and velocity.
Systems like FinSage and HierFinRAG demonstrate that the accurate parsing of heterogeneous financial filings requires multi-modal pre-processing, multi-path retrieval strategies, and specialized table-text graph integration to prevent mathematical hallucination. Concurrently, FinRobot establishes that actionable trading insights are best generated through multi-agent, sequential Chain of Thought reasoning, mitigating the generative overreach of monolithic LLMs.
Crucially, the integrity of these systems relies on their temporal awareness and infrastructural efficiency. The implementation of bitemporal data models, incremental vector indexing, and the strict latency budgets prescribed by the FLASH framework are not merely operational optimizations; they are fundamental prerequisites for executing trades in real time. Furthermore, the integration of algorithmic conflict resolution - utilizing confidence-weighted nuggets to filter contradictory news - ensures that the resulting signals reflect verified market consensus rather than isolated noise.
As global markets continue to transition toward continuous, event-based pricing, the integration of these advanced RAG architectures with parameter-efficient, multilingual language models will remain the primary driver of automated alpha generation, allowing institutions to instantly synthesize chaotic, global data streams into precise, executable strategies.