Recursive Hierarchical Tree Summarization and Knowledge Compression
Architectural Limitations of Language Model Inference
As large language models scale in parameter count and capability, the demand for processing increasingly lengthy context windows has become a primary engineering bottleneck. The foundational challenge lies within the quadratic computational complexity of the standard Transformer self-attention mechanism, combined with the linear memory scaling of the Key-Value (KV) cache during autoregressive decoding 12. During the token generation phase, the model must continually access this expanding KV cache to reference previously generated tokens. For models with billions of parameters operating on extended contexts - such as those exceeding 100,000 tokens - the memory footprint of the KV cache frequently exceeds the size of the model weights themselves, rendering the inference process heavily memory-bound and constrained by the bandwidth limits of High Bandwidth Memory (HBM) 23.
To circumvent these physical memory constraints and expand theoretical context capacities, researchers have developed various positional encoding extensions. Techniques such as Attention with Linear Biases (ALiBi) and Neural Tangent Kernel (NTK)-aware scaled Rotary Position Embedding (RoPE) extrapolate positional representations trained on short texts to far longer sequences 4. ALiBi demonstrates broad architectural applicability, though its extrapolation properties are somewhat constrained for models pre-trained specifically with RoPE mechanisms 4. Conversely, NTK-aware scaled RoPE enables models to handle sequences substantially larger than their training inputs without fine-tuning 4. More recent innovations, such as LongRoPE, have pushed the context limits of pre-trained models to 2048k tokens 26. LongRoPE achieves this through a progressive extension strategy that exploits non-uniformities in positional interpolation - specifically varying RoPE dimensions and token positions - providing superior initialization for fine-tuning that minimizes information loss 27.
However, expanding the theoretical context window does not natively solve the problem of information retrieval fidelity. Empirical research has identified a severe "Lost in the Middle" phenomenon, characterized by a U-shaped performance curve across document positions 89. Language models exhibit high recall rates for information positioned at the extreme beginning (primacy bias) and the extreme end (recency bias) of a sequence, but suffer dramatic performance degradation when critical evidence is located in the middle of a lengthy context 810. The Adobe Research NoLiMa benchmark demonstrated this degradation starkly: when queries and target content share minimal lexical overlap, 11 out of 12 tested models dropped below 50 percent of their baseline performance at just 32,000 tokens 910. In these tests, GPT-4 exhibited a 15.4 percent degradation when extending from 4,000 to 128,000 tokens, and its accuracy dropped from 99.3 percent to 69.7 percent in specific multi-document configurations 910.
While flagship models often claim near-perfect accuracy on synthetic "Needle in a Haystack" (NIAH) tests at 1-million-token contexts, these evaluations frequently rely on simplistic literal matching that understates real-world reasoning complexity 911. Advanced benchmarks, such as the NVIDIA RULER benchmark, evaluate multi-hop tracing, aggregation, and question answering, revealing that the effective context length of modern large language models is often only 50 to 65 percent of their marketed capacity 911. Because processing billions of tokens incurs prohibitive financial costs and exacerbates this context dilution, the field of artificial intelligence has increasingly pivoted toward extreme knowledge compression methodologies 10. These compression paradigms seek to distill essential semantic information into highly dense representations, optimizing both inference latency and downstream reasoning accuracy without relying solely on expanded context windows.
Recursive Hierarchical Tree Summarization
To mitigate the limitations of flat retrieval-augmented generation (RAG) models, which traditionally extract short, contiguous chunks of text and consequently miss overarching document narratives, researchers introduced Recursive Abstractive Processing for Tree-Organized Retrieval (RAPTOR) 1213. Traditional retrieval systems struggle to represent large-scale discourse structures, but RAPTOR restructures linear text into a multi-layered semantic hierarchy, allowing language models to perform complex multi-hop reasoning across vast documents at varying levels of abstraction 1214.
The architecture functions as a bottom-up hierarchical tree. The foundational layer consists of raw text chunks acting as leaf nodes. Through subsequent applications of embedding, dimensionality reduction, and soft clustering, these leaves are grouped and processed by a language model into summarized parent nodes. This middle layer of summarized clusters is then recursively processed until the hierarchy culminates in a single root node containing a high-level summary of the entire document corpus.
Foundational Segmentation and Vector Embedding
The construction of a RAPTOR tree begins with the segmentation of the retrieval corpus into short, contiguous text chunks. Unlike rigid token-splitting methods that disrupt semantic flow, RAPTOR typically caps these chunks at 100 tokens, but actively preserves contextual coherence by moving entire sentences to the subsequent chunk if they breach the limit 316. These foundational chunks form the leaf nodes of the tree structure. Each leaf node is subsequently vectorized into a dense semantic space using specialized embedding models, predominantly Sentence-BERT (SBERT) architectures such as the multi-qa-mpnet-base-cos-v1 encoder 316.
Dimensionality Reduction and Probabilistic Clustering
Because high-dimensional embeddings are computationally intensive to cluster directly, the framework applies Uniform Manifold Approximation and Projection (UMAP) to reduce the dimensionality of the vector space 17. This reduction is executed at both global and local levels; the global reduction identifies broad thematic groupings across the entire corpus, while the local reduction refines granular subgroupings within those global clusters 17.
Following dimensionality reduction, the text segments are organized using Gaussian Mixture Models (GMM) 143. A critical algorithmic innovation of the RAPTOR framework is its implementation of soft clustering. Unlike hard clustering techniques (such as K-means) that force each node into a single rigid category, soft clustering allows a single text segment to belong to multiple distinct clusters simultaneously 143. This probabilistic overlap mirrors the reality of natural language, where a single paragraph may contain multiple entities, concepts, and themes relevant to distinct topics. To prevent arbitrary grouping, the optimal number of clusters is determined dynamically using the Bayesian Information Criterion (BIC), which continuously balances model fit against mathematical complexity 1617.
Abstractive Summarization and Hierarchy Construction
Once the leaf nodes are probabilistically grouped, a language model is employed to generate an abstractive summary for each distinct cluster. These newly generated text summaries become the parent nodes in the subsequent tier of the hierarchy 1718. Unlike extractive summarization, which merely pulls verbatim sentences from the source material, this recursive abstractive processing synthesizes the underlying themes and condenses the information, minimizing redundancy while preserving critical context 17.
The system then enters a recursive loop. The new parent nodes (the cluster summaries) are re-embedded using SBERT, their dimensionality is reduced via UMAP, they are clustered again via GMM, and they are summarized by the language model to form the next architectural layer 1618. This recursive cycle continues upward until further clustering becomes mathematically unfeasible or unnecessary, ultimately culminating in a singular root node that encapsulates the macroscopic narrative of the entire ingested text 1618.
Retrieval Modalities
At inference time, the system leverages the generated embeddings of both the user's query and the nodes within the tree to retrieve context. RAPTOR utilizes two distinct traversal algorithms to navigate the hierarchy:
The first modality, Tree Traversal Retrieval, operates sequentially. The system evaluates the root nodes against the query using cosine similarity, selects the top-k most relevant nodes, and then progresses downward exclusively into the specific child nodes of those selected parents 319. The query is evaluated against this localized pool, and the process repeats layer-by-layer until reaching the leaf nodes 3. This approach captures a highly focused vertical slice of the hierarchy but can occasionally miss laterally related information.
The second modality, Collapsed Tree Retrieval, flattens the entire hierarchical structure into a single, comprehensive set containing nodes from every abstraction level 319. The system computes the cosine similarity between the query and every node in this unified space simultaneously. It then selects the global top-k nodes until a predefined token threshold is met 319. Empirical evaluations consistently demonstrate that Collapsed Tree Retrieval outperforms layer-by-layer traversal 1420. The superiority of this flattened approach suggests that complex thematic questions require a simultaneous blend of high-level macroscopic summaries and precise granular details, which rigid layer-constrained searches fail to provide 14.
Empirical Performance and Fidelity Limitations
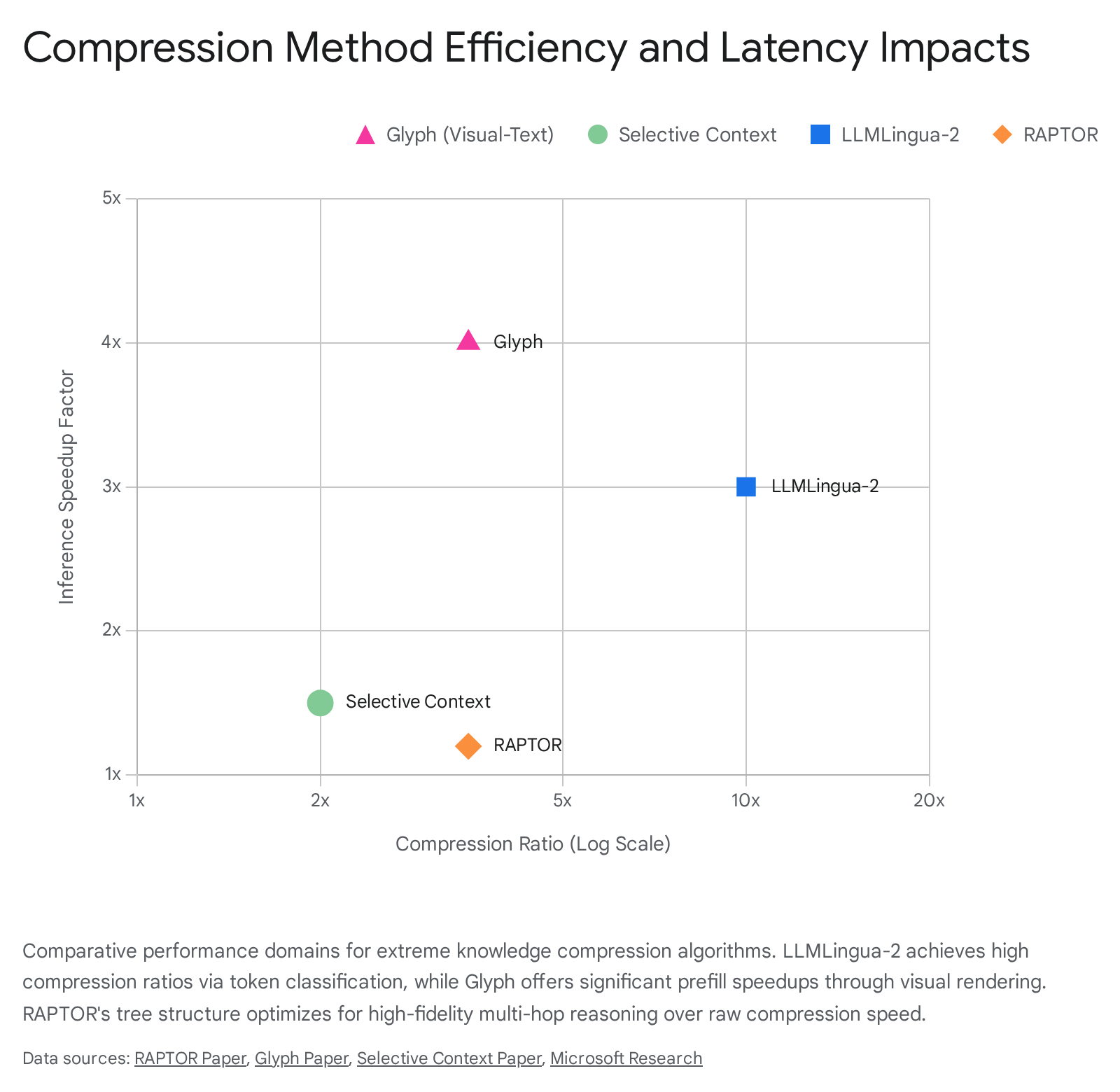
The hierarchical summarization framework yields a highly efficient data representation, operating at an average compression rate of 72 percent relative to the raw text 3. Statistical analysis indicates that the ratio between the length of a generated parent summary and the aggregate lengths of its child nodes averages 0.28, with summary lengths averaging approximately 131 tokens against a child node average of 85.6 tokens 3.
Benchmark Efficacy
When evaluated on multi-hop reasoning and reading comprehension tasks, RAPTOR demonstrates profound performance gains over traditional flat-retrieval systems. On the QuALITY reading comprehension benchmark - a dataset specifically designed to test multi-step reasoning over long texts - RAPTOR coupled with GPT-4 achieved a state-of-the-art accuracy of 82.6 percent, representing a 20 percent absolute improvement over prior baselines 12133. On the QASPER dataset, the framework achieved a 55.7 percent F-1 Match score, and on NarrativeQA tasks utilizing UnifiedQA, it generated a 30.87 percent ROUGE-L score and a 19.20 percent METEOR score 143. Furthermore, the computational overhead for constructing the RAPTOR tree scales linearly with document length, maintaining feasibility on consumer-grade hardware for documents containing up to 80,000 tokens 319.
Hallucinations and Semantic Entropy
Despite its demonstrated efficacy, recursive abstractive summarization introduces specific fidelity risks native to generative language models. The iterative summarization process creates a vector for cascading hallucinations, where errors in lower-level summaries are compounded as they propagate up the tree 214. A manual annotation study of sampled RAPTOR nodes identified a baseline hallucination rate of 4 percent, though these confabulations were typically categorized as minor and did not severely impact downstream question-answering accuracy in tested scenarios 35.
Hallucinations - or confabulations - are considered an inherent architectural feature of autoregressive prediction mechanisms, stemming from undecidability and the probabilistic nature of token generation 424. To combat this, researchers have developed advanced metrics such as semantic entropy, which detects confabulations by evaluating the uncertainty in the meaning of generated answers rather than merely assessing lexical variations 2425. By clustering generated sequences based on bidirectional entailment, semantic entropy frameworks can flag when a model is likely generating arbitrary or unsupported responses, allowing systems to apply safety thresholds during the recursive summarization phase 25.
A secondary fidelity risk is semantic smoothing. Abstractive summarization fundamentally relies on compression, which can inadvertently flatten out domain-specific nuances, rare intent signals, or minority viewpoints present in the source text 21. In enterprise settings, aggressive recursive compression without strict confidence thresholds can result in the loss of critical, highly specific data points necessary for accurate multi-hop reasoning 21.
Topological Enhancements and Graph Clustering
Recent research has identified that the static, fixed-token chunking strategy employed by baseline RAPTOR models can lead to semantic fragmentation 6. When logical units are arbitrarily split, the subsequent clustering and summarization tasks operate on incomplete conceptual foundations 6. To resolve this, researchers propose Semantic Segmentation to generate more coherent foundational leaf nodes, utilizing metrics like cosine distance to infer paragraph boundaries based on meaning rather than mere token counts 6.
Additionally, the reliance on Gaussian Mixture Models has been critiqued for producing relatively flat tree structures that may not adequately represent complex topological relationships in highly technical documents 56. Adaptive Graph Clustering (AGC) strategies, such as those leveraging the Leiden algorithm with layer-aware dual-adaptive parameter mechanisms, dynamically tailor clustering granularity 6. These graph-topological approaches have been shown to outperform traditional distance-based methods, increasing accuracy on the QuALITY benchmark to 65.5 percent while simultaneously reducing the number of required summary nodes by up to 76 percent 6.
Prompt Compression and Redundancy Pruning
While recursive hierarchical summarization restructures a corpus offline prior to retrieval, inline prompt compression operates dynamically at inference time. These methodologies compress the user prompt and the retrieved context before they enter the language model, pruning redundant or non-essential tokens to minimize the KV cache footprint and dramatically accelerate the decoding phase. Modern prompt compression techniques broadly divide into information-theoretic algorithms and neural token classification models.
Information-Theoretic Compression: Selective Context
The Selective Context methodology evaluates the informativeness of text by measuring its self-information, rooted in classical information theory 2728. In this framework, a base causal language model evaluates the negative log-likelihood of specific vocabulary units - ranging from individual tokens to phrases and entire sentences 2729. Units that possess high self-information represent rare or unpredictable data, whereas units with low self-information are highly predictable given the surrounding context and thus convey minimal novel semantic value 2730.
By establishing a specific percentile threshold, Selective Context prunes the redundant vocabulary units, significantly condensing the input size 2729. Empirical testing demonstrates that Selective Context can achieve a 50 percent reduction in context cost, translating directly to a 36 percent reduction in inference memory usage and a 32 percent decrease in generation latency 2831. Remarkably, this aggressive compression yields negligible degradation in downstream task performance; benchmarks show only a minor drop of 0.023 in BERTscore and 0.038 in faithfulness across complex tasks including summarization, question answering, and dialogue generation 2831. The computational overhead required to calculate self-information is highly efficient and easily parallelizable, taking approximately 46 milliseconds to execute, which is vastly offset by the thousands of milliseconds saved during the subsequent autoregressive decoding phase 31.
Perplexity-Based Coarse-to-Fine Compression: LLMLingua
The LLMLingua family of models represents an evolution in context compression, initially utilizing perplexity-based metrics via a smaller language model (e.g., LLaMA-7B) to evaluate and prune tokens with low information entropy 307. The original LLMLingua architecture introduced a sophisticated budget controller to balance sensitivities across different segments of a prompt 107. To preserve functional integrity, it applied varying compression ratios dynamically: user instructions received light compression (10 to 20 percent) to maintain operational clarity, few-shot examples received heavy compression (60 to 80 percent) due to inherent structural redundancy, and the core questions received minimal pruning (0 to 10 percent) to preserve intent 10. The original LLMLingua achieved up to 20x compression with only a 1.5 percent performance loss on strict reasoning tasks 107.
For specifically long contexts and retrieval-augmented applications, LongLLMLingua introduced question-aware coarse-to-fine compression 1033. This variant actively reorders retrieved documents based on contrastive perplexity to combat the positional bias of the "Lost in the Middle" phenomenon 1033. By dynamically adjusting compression ratios based on the relevance of the text to the core question, LongLLMLingua demonstrated a 21.4 percent performance improvement on NaturalQuestions using only one-quarter of the original tokens, facilitating up to a 94 percent cost reduction 10.
Bidirectional Token Classification: LLMLingua-2
Despite the efficacy of perplexity-based pruning, traditional autoregressive models evaluate tokens sequentially, which can lead to critical contextual errors. For instance, a unidirectional model might assign low perplexity to a word without realizing that a subsequent word (such as a negation) fundamentally alters the semantic meaning of the preceding text 34.
To address this, Microsoft Research pivoted the architecture with LLMLingua-2, abandoning perplexity calculations in favor of treating prompt compression as an explicit binary token classification problem (preserve versus discard) 1035. LLMLingua-2 utilizes a small bidirectional Transformer encoder - specifically XLM-RoBERTa - fine-tuned on compression data generated by GPT-4 1035. By analyzing both the preceding and succeeding context for every token simultaneously, the model prevents the erroneous pruning of critical logical operators and structured data markers 3435.
LLMLingua-2 achieves profound operational speeds, functioning 3 to 6 times faster than the original LLMLingua while maintaining an accuracy retention rate of 95 to 98 percent 1035. The efficiency of the bidirectional encoder allows the compression step to process 1,000 tokens in under 30 milliseconds on standard inference hardware (e.g., NVIDIA T4), making it highly viable for real-time production environments 34.
Context Embeddings and In-Context Learner Mixtures
Beyond token pruning, researchers are exploring methods that compress text directly into continuous embedding spaces or manipulate the attention mechanisms over prompt demonstrations.
The COCOM (COntext COmpression Model) framework circumvents lexical token filtering entirely by compressing lengthy contexts into a minimal set of highly dense context embeddings 8. By utilizing specialized pre-training tasks involving auto-encoding and language modeling from these embeddings, COCOM employs the exact same model for both the compression phase and the answer generation phase 8. This unification ensures that the generative decoder is perfectly tuned to interpret the compressed context vectors, balancing decoding speed against exact match accuracy across multi-document datasets 8.
Similarly, the Mixtures of In-Context Learners (MoICL) methodology addresses the quadratic memory scaling caused by long demonstration prompts 37. Instead of concatenating all examples into a single massive prompt, MoICL divides the demonstrations into smaller, specialized subsets known as "experts" 37. A dynamic weighting function merges the predictive outputs of these expert subsets based on task requirements, which optimizes memory utilization while improving resilience to noisy data by 38 percent and boosting accuracy on classification tasks by up to 13 percent compared to standard in-context learning 37. The Recurrent Context Compression (RCC) approach follows a comparable ethos, utilizing a decoder to chunk and compress fixed-size input pieces, demonstrating a 32x context compression rate while achieving nearly 100 percent accuracy on passkey retrieval tasks spanning sequences of 1 million tokens 3.
Multimodal Visual-Text Compression
A radical paradigm shift in long-context modeling circumvents token-based limits entirely by transforming text processing into a multimodal optimization challenge. The Glyph framework scales context length by rendering vast amounts of textual sequence into compact, high-density images, which are then processed by advanced Vision-Language Models (VLMs) such as GLM-4.1V-9B 383940.
By treating text as a spatial visual representation, Glyph fundamentally alters the physical space the data occupies within the model's memory, achieving substantial input-token compression while preserving semantic information 3839. To maximize the density and readability of the rendered text, Glyph incorporates an LLM-driven genetic search algorithm that identifies the optimal typographical configurations - adjusting page layout, font sizing, and line spacing to balance optical character recognition (OCR) fidelity against maximum visual compression 3940.
The compression ratios achieved by Glyph are heavily dependent on the visual rendering resolution (DPI). Benchmarks indicate that at 72 DPI, Glyph achieves an average compression ratio of 4.0x (peaking at 7.7x), while higher fidelity renderings at 96 DPI yield a 2.2x ratio, and 120 DPI yields a 1.2x ratio 41. Across standard long-context benchmarks like LongBench, Glyph maintains an average effective compression ratio of 3.3x 41.
This visual-text compression translates into immediate and profound computational efficiency gains. The framework achieves approximately a 4x acceleration in both prefilling and decoding speeds compared to the uncompressed text baseline, while Supervised Fine-Tuning (SFT) executes twice as fast 3941. Crucially, because the underlying KV cache scales linearly with sequence length, the token reduction results in approximately 67 percent savings in memory usage 41. Under extreme compression configurations, Glyph enables a model with a 128,000-token context window to successfully ingest and handle 1-million-token datasets, making it highly competitive for real-world document understanding tasks 3941.
Parameter Compression and Semantic Retention Metrics
While prompt compression and visual rendering algorithms manipulate the input tensors dynamically at inference, parameter compression techniques - such as quantization, pruning, and low-rank factorization - permanently shrink the actual weight matrices of the model. These techniques drastically reduce storage requirements, lower energy consumption, and accelerate floating-point operations (FLOPs) 4243.
Quantization compresses models by converting high-precision floating-point numbers (e.g., 16-bit or 32-bit floats) into lower-bit formats (e.g., 8-bit or 4-bit integers) 44. Methods such as W8A8 (8-bit weights and activations) and W4A16 (4-bit weights, 16-bit activations) offer massive memory savings; W8A8 achieves approximately 2x compression with near-lossless accuracy, while W4A16 delivers up to 3.5x compression and 2.4x speed boosts with minimal degradation 4546. Advanced frameworks utilizing Activation-aware Weight Quantization (AWQ) or GPTQ ensure that the most salient weights are preserved, allowing 4-bit models to recover up to 98.9 percent of their original accuracy on complex coding evaluations like HumanEval 4546.
However, evaluating the true quality degradation of highly compressed models remains challenging. Traditional metrics, such as intrinsic Perplexity (PPL), frequently fail to capture the subtle deterioration of complex reasoning capabilities; heavily compressed models may maintain perplexity scores similar to their dense counterparts while completely failing at knowledge-intensive downstream tasks 4347.
To provide a more accurate evaluation framework, researchers introduced the Semantic Retention Compression Rate (SrCr), a metric designed to explicitly quantify the trade-off between physical memory reduction and the preservation of semantic capabilities 48. The SrCr metric is composed of two distinct mathematical formulations: * The Pruning Component ($SrCr_p$): Defined as $\sqrt{p} \cdot Sr_p$, where $p$ is the sparsity percentage and $Sr_p$ is the semantic retention rate. The application of the square root function provides higher resolution across the practically viable pruning range of 0 to 50 percent 47. * The Quantization Component ($SrCr_q$): Defined as $\frac{-\log_2(q/16)}{4} \cdot Sr_q$, where $q$ is the bit-width. This formulation accurately reflects the exponential relationship between bit-width and computational precision 47.
By combining these components into a unified multiplicative joint metric ($SrCr_j$), researchers can optimize hardware configurations across the Pareto frontier. Empirical evaluations using the SrCr metric reveal that joint compression strategies consistently outperform single-method approaches. For example, applying a joint configuration of 25 percent pruning combined with 4-bit quantization yields a 20 percent performance increase in semantic retention compared to a purely 3-bit quantized model operating at the exact same Theoretical Compression Rate (TCr) of 81.25 percent 4748.
Furthermore, architectural design plays a significant role in compression resilience. Studies utilizing the SrCr framework indicate that models like Mistral exhibit greater resilience to aggressive compression than highly complex, multilingual models like LLaMA 47. Across all tested models, mathematical reasoning (measured via benchmarks like MATH) proved to be the cognitive task most sensitive to aggressive parameter compression, demonstrating catastrophic collapse when quantization dropped below 4 bits (e.g., 2-bit formats) 4749. This underscores the reality that while basic text generation can survive extreme parameter decimation, multi-hop logic and mathematical deduction rely heavily on the full fidelity of the parameter space.
Integration Within Advanced Retrieval Architectures
To safely operationalize extreme knowledge compression and maximize context efficiency, standard RAG pipelines are rapidly evolving into sophisticated, multi-stage architectures designed specifically for complex enterprise reasoning tasks 5051.
- Adaptive and Modular RAG: Rather than subjecting every user prompt to an intensive retrieval and compression pipeline, Adaptive RAG utilizes a lightweight query classifier to route questions based on their inherent complexity 5152. Simple factual questions are answered directly using the model's parametric memory, avoiding retrieval entirely. Moderate queries trigger standard single-step RAG, while highly complex reasoning tasks trigger multi-step iterative retrieval protocols 51. This intelligent routing mitigates unnecessary latency and compute costs across high-volume systems 52.
- GraphRAG: To overcome the limitations of flat vector similarity searches, GraphRAG constructs a deterministic knowledge graph from the source documents offline. By extracting entities and using community detection algorithms to map relationships, the system creates hierarchical summaries of entity clusters 51. When a query is initiated, the system navigates this graph to retrieve both structured relational data and unstructured textual content, enabling deep multi-hop reasoning that purely semantic embeddings cannot support 5051.
- Hierarchical RAG (HRAG) and Iterative Frameworks: Frameworks like HRAG index documents at multiple levels of granularity (e.g., document, section, and fact levels). Retrieval operates top-down, first identifying relevant documents based on high-level abstractions before zooming into specific passage-level chunks, effectively eliminating the noise associated with flat retrieval 5253. Complementary Iterative RAG architectures utilize the language model as an active reasoning engine between retrieval rounds; the model evaluates the compressed retrieved context, identifies knowledge gaps, and generates refined sub-queries to fetch missing evidence until it achieves a high-confidence answer 52.
Comparative Evaluation of Compression Modalities
The landscape of extreme knowledge compression is highly differentiated, with distinct methodologies optimizing for separate variables - ranging from offline structural fidelity to real-time inference latency and hardware memory minimization.
| Methodology | Primary Mechanism | Average Compression Ratio | Inference Latency / Speedup | Principal Advantages | Key Limitations |
|---|---|---|---|---|---|
| RAPTOR | Hierarchical soft clustering (GMM) and recursive abstractive summarization. | ~72% reduction (varies by tree depth). | Slower offline build time; highly efficient retrieval at inference. | Synthesizes overarching narratives; achieves state-of-the-art on multi-hop QA (e.g., QuALITY). | ~4% hallucination rate in generated summaries; semantic smoothing. |
| Selective Context | Pruning vocabulary units based on self-information (entropy) via base LLMs. | 35% - 50% context reduction. | 32% reduction in generation latency; ~46ms overhead. | Easy implementation; retains semantic integrity for dialogue and standard QA. | Performance degradation at aggressive compression ratios (>50%). |
| LLMLingua-2 | Bidirectional token classification (preserve vs. discard) via XLM-RoBERTa encoder. | 5x - 20x token reduction. | 3x - 6x faster inference than perplexity-based methods. | Preserves complex reasoning, logical operators, and structured data with high fidelity. | Requires secondary local transformer pipeline to execute compression. |
| Glyph | Visual-text rendering; context processed spatially via Vision-Language Models. | 3x - 4x average (up to 8x extreme). | ~4x faster prefilling and decoding; 67% KV cache memory reduction. | Completely bypasses token sequence limits; enables massive dataset ingestion. | Requires VLM architecture; OCR degradation at extremely high text-density resolutions. |
| Parameter Compression | Joint moderate pruning (e.g., 25%) and INT4 quantization. | 75% - 85% memory footprint reduction. | Up to 2.4x speed boost (hardware dependent). | Permanent memory reduction; ideal for local edge deployment and cost savings. | Loss of capability on complex mathematical/logical reasoning at sub-4-bit levels. |
Conclusion
The pursuit of extreme knowledge compression in large language models is fundamentally a response to the computational physics of the Transformer architecture and the inherent cognitive limitations of long-context attention. While extending theoretical context windows to the multi-million token scale via RoPE extrapolation is mathematically feasible, the documented reality of the "Lost in the Middle" phenomenon dictates that simply feeding an LLM an expanding sequence of tokens does not equate to enhanced comprehension or retrieval accuracy. Memory constraints, latency overhead, and positional biases necessitate intelligent data distillation.
Modern AI pipelines must therefore deploy targeted compression strategies contingent upon specific workload constraints. For offline corpus organization and applications requiring deep, multi-hop reasoning, recursive hierarchical structures like RAPTOR establish necessary semantic relationships that flat vectors cannot replicate. In high-throughput, latency-sensitive production environments, token classification models such as LLMLingua-2 provide an optimal balance, preserving bidirectional intent while aggressively slashing inference costs. Concurrently, novel paradigms like the visual-text rendering of the Glyph framework and the optimized parameter reductions dictated by the SrCr joint compression metrics indicate that the future of language model efficiency will likely rely on multimodal spatial representations and highly calibrated, hardware-aware architectural precision. As foundational models continue to scale in parameter count and ambition, integrating these advanced compression modalities into dynamic, agentic architectures will remain the most critical pathway for deploying reliable, fast, and economically viable artificial intelligence systems.