Artificial Intelligence Model Quantization
Artificial intelligence model quantization encompasses a suite of mathematical and algorithmic techniques designed to compress neural networks by systematically reducing the numerical precision of their internal parameters. By transitioning models from standard 16-bit floating-point representations - specifically IEEE FP16 or Brain Floating Point (BF16) - to lower bit-width formats such as 8-bit, 4-bit, or sub-2-bit discrete representations, quantization directly addresses the critical bottlenecks of memory capacity and memory bandwidth that fundamentally constrain large language model architecture 1223.
The primary constraint governing the deployment of advanced neural networks is widely recognized as the memory wall. Inference, particularly the autoregressive token decoding phase inherent to generative language models, is predominantly a memory-bound operation rather than a compute-bound one 35. Consequently, the speed of token generation is strictly limited by how rapidly weight data can be streamed from High Bandwidth Memory to the accelerator's processing cores 3. Modern accelerators possess compute capabilities that vastly outpace their memory bandwidth interfaces, frequently leaving computational cores idle for up to 98% of the time during full-precision inference 3. Quantization bridges this physical gap by shrinking the data payload. A 70-billion parameter neural network, which natively requires approximately 140 gigabytes of memory in FP16, can be reduced to roughly 35 gigabytes at 4-bit precision 45. This enables frontier-class models to operate efficiently on single consumer-grade accelerators or highly economical cloud infrastructure configurations.
Foundational Mechanics of Numerical Precision Reduction
Quantization maps a high-precision continuous or quasi-continuous distribution of floating-point numbers into a significantly smaller, discrete set of representable values. This transformation inevitably introduces quantization error, which manifests as a loss of model accuracy or capability if not mathematically managed 126. The process generally involves defining a specific representational range and developing an algorithmic mapping strategy to compress the native parameters.
Mathematical Scaling and Zero-Point Mapping
The baseline approach to post-training quantization relies on calculating a scaling factor alongside an optional zero-point mapping to anchor the compressed numbers. Symmetric quantization represents the simplest implementation, wherein the dynamic range of the model weights is mapped symmetrically around an absolute zero 2. The scale is formulated by dividing the maximum absolute weight by the boundary of the integer range. For an 8-bit mapping, this results in values distributed precisely between -127 and 127. While computationally straightforward and highly optimized for basic hardware, symmetric quantization inherently wastes representational space if the underlying weight distribution is skewed heavily in a positive or negative direction 2.
To counteract this inefficiency, asymmetric quantization continuously calculates both the minimum and maximum values of the target tensor to dynamically shift the zero-point 2. This ensures that the full range of the low-bit integer format is utilized, regardless of where the native data is centered. For instance, if a specific neural network layer contains exclusively positive activation values, asymmetric quantization adjusts the scale to utilize the entirety of the 8-bit spectrum (0 to 255), effectively doubling the resolution compared to a symmetric approach that would leave the negative half of the spectrum empty 2.
Granularity of Quantization Operations
The fidelity of the quantization process is heavily dictated by its granularity - the specific architectural scope over which scaling factors are calculated 7. Applying a single, uniform scaling factor across an entire model, or even an entire dense layer tensor, yields unacceptable error margins. Neural networks contain outliers - isolated parameters possessing magnitudes significantly larger than the mean distribution 1011. Under a per-tensor quantization regime, a single massive outlier forces the scale to expand radically, which subsequently crushes all standard, lower-magnitude weights toward zero, effectively destroying the network's learned information 711.
Modern model compression avoids this through finer scaling resolutions. Per-channel quantization calculates distinct scaling parameters for each individual channel within a layer, thereby isolating the mathematical disruption caused by outliers strictly to their respective channels rather than allowing them to skew the entire matrix 7. The frontier of precision management utilizes per-block or microscaling quantization. By dividing the tensor into fine-grained, contiguous groups - typically blocks of 16, 32, or 128 elements - each subgroup receives its own independent scaling factor 7108. This extreme granularity allows the quantization format to adapt strictly to localized variance in the data distribution, forming the foundational mechanic that enables robust sub-4-bit precision 78.
Dominant Post-Training Quantization Formats
Post-Training Quantization algorithms allow practitioners to compress models directly for inference without engaging in the computationally prohibitive and complex retraining processes. The landscape is currently dominated by four distinct algorithmic approaches, each optimized for specific hardware topologies and performance trade-offs.
Generalized Post-Training Quantization
Generalized Post-Training Quantization (GPTQ) compresses models layer-by-layer by independently quantizing each row of a weight matrix using approximate second-order mathematical information, specifically relying on an inverse-Hessian matrix to prioritize important parameters 91011. By analyzing the Hessian, GPTQ identifies how errors introduced by quantizing one specific weight will propagate through the network and affect the ultimate output. This permits the algorithm to adjust adjacent weights dynamically to actively cancel out the quantization noise introduced 711.
GPTQ is highly specialized for raw graphics processing unit (GPU) inference throughput, achieving speeds 2 to 4 times faster than full precision, and supports 8-bit, 4-bit, 3-bit, and even 2-bit formats 41011. Because the model is pre-quantized entirely before execution, it is favored for large-scale, batch-inference production environments. However, empirical evaluations indicate that GPTQ often suffers a slightly higher accuracy regression - generally experiencing a 1% to 3% perplexity degradation - when compared to competing activation-aware algorithms 412.
Activation-Aware Weight Quantization
Activation-Aware Weight Quantization (AWQ) operates on the empirical insight that neural network weights are not equally important; rather, less than 1% of a network's weights are "salient" and contribute disproportionately to generating accurate outputs 45. Instead of utilizing static analysis or uniform compression, AWQ executes a brief dynamic calibration pass using a minimal dataset - typically 128 to 512 context samples - to physically observe internal activation magnitudes 45.
Weights that trigger massive activations during this calibration are explicitly protected. The AWQ algorithm preserves these salient pathways by either mapping them with higher precision scales or entirely skipping quantization for those specific channels 45. The remaining 99% of the network weights are aggressively compressed to 4-bit integers. This channel-level granularity allows AWQ to shrink models by 75% while preserving 99% of the FP16 baseline accuracy 412. On NVIDIA H100 hardware, AWQ at 4-bits increases single-batch decode throughput by up to 3.1 times, making it the preferred format when available Video Random Access Memory (VRAM) is the strict binding constraint for deployment 12.
GPT-Generated Unified Format
The GPT-Generated Unified Format (GGUF), which evolved from the earlier GGML architecture, is heavily optimized for Central Processing Unit (CPU) inference, edge device deployment, and Apple M-series unified memory architectures 510. GGUF is deeply integrated into the llama.cpp ecosystem and employs highly flexible mixed-precision integer quantization 310.
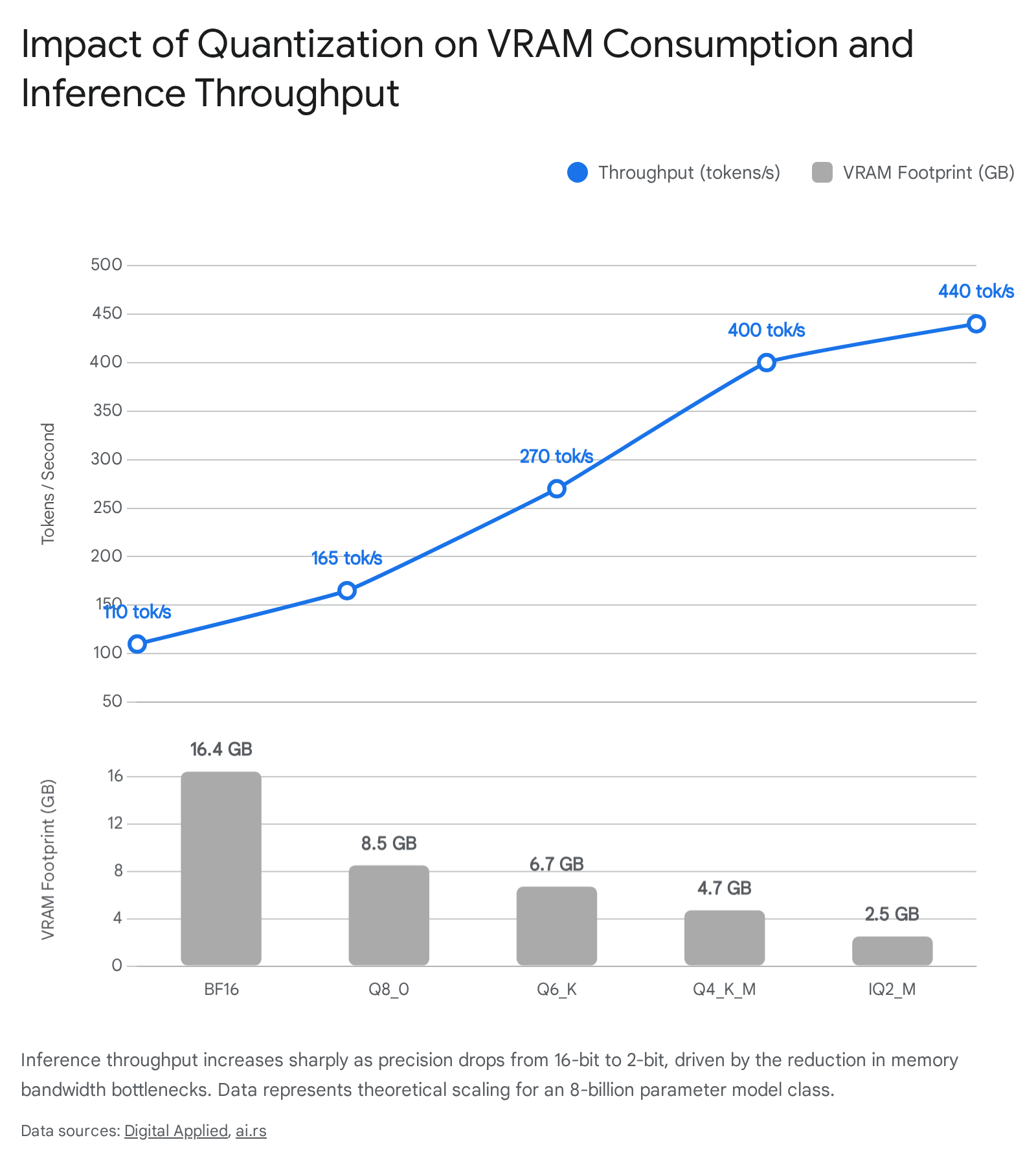
Rather than treating the entire model uniformly, GGUF utilizes sophisticated variable schemas known as "k-quants" which selectively allocate different bit-widths to different tensors based on their structural importance to the network 3. The Q4_K_M sub-format averages roughly 4.5 bits per weight and maintains up to 95% of original model quality while heavily compressing the model for basic edge execution. The Q6_K format operates at 6-bits and is widely considered the optimal production balance for CPU environments, maintaining 98% quality while doubling generation speeds relative to standard 16-bit processing 35.
However, GGUF exhibits noticeable integration overhead when forced into high-throughput GPU serving frameworks, running substantially slower than native GPU formats like AWQ 5.
ExLlama Version 2
The ExLlama Version 2 (EXL2) format takes a unique measurement-based approach that applies variable bit-rate allocation across individual model layers 317. During its pre-computation phase, the EXL2 algorithm evaluates the specific quantization error introduced at every dense layer of the architecture. It then dynamically distributes its total bit budget: critical layers retain high precision (e.g., 6 or 8 bits), while highly redundant or less critical layers are compressed aggressively (e.g., down to 3 bits) 31718.
This methodology allows systems engineers to target an exact average "bits per weight" (BPW) metric. A practitioner can specify a 4.65 BPW quantization strictly to maximize the available space of a 24-gigabyte consumer GPU without spilling over into system memory 1713. EXL2 heavily optimizes underlying VRAM layout and maximizes streaming utilization, frequently yielding generation rates that significantly outpace standard 4-bit models. The primary detraction is that the variable compression can induce minor non-determinism, prioritizing raw speed and physical memory utilization over absolute replicability in academic benchmarks 181320.
| Quantization Format | Primary Architectural Target | Core Optimization Mechanism | Typical VRAM Reduction (4-bit Target) | Operational Weaknesses |
|---|---|---|---|---|
| GGUF | CPU, Apple Silicon, Edge Devices | Mixed-precision integer block scaling via k-quants | ~70-75% | Demonstrates high latency overhead when forced into GPU-native serving engines like vLLM 510. |
| AWQ | GPUs (Accuracy Preservation) | Protects the 1% most salient weights based on activation magnitudes | ~75% | Conversion requires a calibration dataset pass, increasing initial setup time 45. |
| GPTQ | GPUs (Peak Batch Throughput) | Inverse-Hessian mathematical error compensation | ~75% | Exhibits a slightly higher accuracy and perplexity regression compared directly to AWQ 41112. |
| EXL2 | Consumer GPUs (VRAM Fitting) | Measurement-based variable per-layer bit allocation | Custom (Targets exact VRAM capacity) | May introduce mild non-determinism; heavily reliant on the singular exllamav2 backend 31320. |
Empirical Accuracy Degradation and the Four-Bit Inflection Point
The process of quantization inherently induces a degradation in model capability; precision is traded directly for operational efficiency. Extensive academic and production evaluations across leading open-weight foundation models - including Llama 3.1, Qwen2.5, DeepSeek, and Mistral - demonstrate that this degradation is neither linear across decreasing bit-widths nor uniform across different cognitive task types 1415.
The Universal Four-Bit Inflection Point
Extensive empirical studies consistently identify 4-bit quantization as the critical inflection point for optimal production economics, beyond which the capability of standard architectures degrades precipitously 122316.
Quantizing a neural network from 16-bit to 8-bit precision results in statistically negligible capability loss. On metrics evaluating general reasoning and knowledge retention, 8-bit models maintain between 99.5% and 99.9% accuracy recovery, effectively rendering FP16 inference obsolete for standard production deployments outside of pure research 141517. Advancing to 4-bit precision - utilizing techniques like AWQ-4 or GGUF Q4_K_M - reduces memory footprints by up to 75% while exhibiting highly manageable regression. Across a cohort of 70-billion parameter class models, 4-bit quantization triggers an accuracy drop of only 1.3 to 1.9 points on rigorous benchmarks like MMLU-Pro 12. This minor variance is generally indistinguishable from statistical run-to-run noise in real-world chat applications. A dedicated study of the Mistral-7B architecture noted that the Q4_K_M format delivered a 43% absolute compression ratio with only a 0.51% increase in measurable perplexity 16.
However, as weight precision drops into sub-4-bit territories, specifically 3-bit, 2-bit, or standard binary, models experience catastrophic capability collapse 23. Perplexity scores spike exponentially as the network loses structural coherence, rendering the outputs unusable. In the Mistral-7B evaluation, dropping from Q4_K_M down to Q2_K triggered a massive 7.94% penalty in perplexity 16. Furthermore, model scale dictates resilience; highly parameterized models (such as the 70B and 405B classes) demonstrate significantly higher resistance to aggressive quantization noise than smaller 7B to 14B models, which lack the internal redundancy to absorb the rounding errors 1517.
Task-Specific Degradation Sensitivities
Different cognitive capabilities decay at highly divergent rates when models undergo compression.
Mathematics and Logic Planning: Complex mathematical reasoning, numerical computation, and logical planning represent the highest vulnerabilities for quantized models 1418. Studies analyzing the MATH and GSM8K reasoning benchmarks indicate that aggressive 4-bit algorithms can trigger up to a 32.39% accuracy degradation (averaging 11.31%) in specific logical reasoning paths for models in the Llama-3 class 18. This severe drop occurs because mathematical reasoning requires absolute numerical determinism; rounding a floating-point multiplier incorrectly early in a multi-step logic chain cascades into severe execution failure by the final output 18.
Coding and Software Development: Conversely, code generation capabilities show high resilience to 8-bit and 4-bit quantization, but fail sharply below that threshold. Advanced code-specialized models, such as the Qwen2.5-Coder 32B iteration, are designed explicitly for programming logic. In full precision, Qwen2.5-Coder 32B achieves a state-of-the-art 73.7 pass rate on the rigorous Aider code repair benchmark, matching proprietary models like GPT-4o 1920. It achieves similar dominance on LiveCodeBench and EvalPlus 1929. Under standard 4-bit compression, performance on standard HumanEval tasks recovers to approximately 98.9% of the baseline, proving entirely reliable for real-world software engineering applications 15. However, deploying such models at extreme 3-bit or 2-bit levels heavily breaks the rigid syntactic coherence required for executable programming languages 17.
Multilingual Degradation: Large language models allocate their internal representational capacity proportionally to their pre-training data distributions. Because English text dominates global training corpora - often accounting for over 50% of the ingested tokens - English syntax and vocabulary are deeply and redundantly entrenched in the network's weights 3. When subjected to 4-bit and 3-bit compression, low-resource languages lack the parameter redundancy to survive the scaling and rounding errors. Consequently, performance on multilingual benchmarks (such as the Chinese-focused C-Eval) drops steeply, routinely bleeding 10% to 20% of accuracy in formats like INT4 and GGUF Q4, disproportionately fracturing non-English language generation while English performance remains stable 314.
| Analytical Benchmark Category | Primary Evaluation Metric | FP16/BF16 Baseline Status | 4-Bit Regression Profile (e.g., AWQ / GGUF Q4) | Quantization Sensitivity Level |
|---|---|---|---|---|
| General Knowledge & Chat | MMLU | High Fidelity | Minimal (< 2% drop); indistinguishable in standard use 1214. | Low 1214. |
| Code Generation | HumanEval | High Fidelity | Moderate (~2-4% drop); viable for production applications 1517. | Medium 1517. |
| Advanced Mathematics | GSM8K / MATH | High Fidelity | Severe (Up to 11-32% drop depending on model scale and format) 18. | Very High 1418. |
| Multilingual Reasoning | C-Eval | Varies heavily by Model | Severe (Up to 10-20% drop for non-dominant pre-training languages) 314. | High 314. |
The Transition to Eight-Bit Floating Point Arithmetic
As datacenter hardware architectures evolve, the artificial intelligence industry is aggressively transitioning from traditional fixed-point integer quantization (such as standard INT8 and INT4) toward specialized 8-bit floating-point (FP8) representations for both massive pre-training and real-time inference. Unlike integer formats, floating-point numbers allocate bits to an exponent, allowing them to expand or contract their scaling dynamically to handle the extreme numerical variability and long-tail outlier distributions inherent to advanced transformer layers 630.
Structural Differences Between E4M3 and E5M2
FP8 is not a singular, uniform standard. It consists of two distinct data formats that balance precision and dynamic range by dividing the 8 available bits (allocating 1 bit for the mathematical sign, and dividing the remaining 7 between the exponent and the mantissa) 83121:
The E4M3 format allocates 4 bits to the exponent and 3 bits to the mantissa. Dedicating 3 bits to the mantissa provides significantly finer-grained numerical precision, but the 4 exponent bits restrict the total dynamic range to a maximum representable value of approximately ±448 268. E4M3 is generally preferred for the forward pass of deep learning workloads, specifically for storing fixed weights and forward activations, as these layers require high fidelity and precision but do not typically suffer from explosive scale variations 83121. Detailed inference benchmarks executed on hardware like Intel Gaudi accelerators indicate that E4M3 strictly outperforms E5M2 for LLM inference accuracy and generation quality 21. Furthermore, studies demonstrate that while some accelerators support stochastic rounding, standard round-to-nearest (RTN) logic combined with E4M3 maintains the highest zero-shot integrity 21.
Conversely, the E5M2 format allocates 5 bits to the exponent and only 2 bits to the mantissa. This vastly expands the dynamic range to ±57,344, mathematically matching the range profile of standard FP16 floating-point 68. The tradeoff is a severe loss of granular precision. Due to this wide range, E5M2 is almost exclusively utilized in the backward pass during foundational model training to store gradients 831. Gradients are notoriously susceptible to extreme scaling outliers and vanishing effects, making the expanded range essential, while being highly resilient to minor precision rounding caused by the reduced mantissa 831.
Microscaling and Advanced Hardware Formats
The fundamental flaw of traditional FP8 quantization applied universally across a tensor is its vulnerability to localized outliers. Because the dynamic range of E4M3 is relatively small (±448), a single large outlier requires the system to establish a massive scaling factor, effectively crushing all smaller surrounding values to zero and inducing quantization collapse 1130.
NVIDIA's subsequent Blackwell architecture circumvents this physical limitation by abandoning tensor-wise scaling and introducing hardware-native microscaling formats such as MXFP8 and NVFP4. Instead of forcing a single scaling metric for millions of dense parameters, MXFP8 dynamically assigns a distinct scale to contiguous blocks of 32 elements 68. NVFP4 pushes this further, scaling blocks of 16 elements 8. This architecture isolates any severe outliers to a microscopic 32-parameter radius, preserving the mantissa precision of the surrounding network and allowing for the highly accurate representation of unpredictable transformer tensors 68.
FP8 Compression for Key-Value Caches
The memory constraints of LLMs are not limited solely to the static weights; the dynamic context window relies on a massive Key-Value (KV) cache that stores attention data for every processed token. Extended context models rapidly exhaust VRAM purely through cache expansion.
The Yi-1.5 model family illustrates the necessity of cache management. Yi-1.5, built on 6B, 9B, and 34B parameter baselines, was continually pre-trained on 5 billion length-upsampled tokens to achieve an immense 200,000-token context window with high needle-in-a-haystack retrieval accuracy 333422. Executing a 200K context window in FP16 is often mathematically impossible on standard hardware. However, quantizing the KV cache directly into the FP8 E4M3 format slashes the cache memory footprint by half. Because E4M3 maintains high precision via its 3-bit mantissa, it requires only a per-tensor scalar to maintain fidelity. This enables high-throughput serving engines like vLLM to effectively double the concurrent context capacity with minimal degradation to the model's retrieval reasoning 23.
Mixed-Precision Training Frameworks: The DeepSeek Paradigm
While FP8 has proven highly effective for inference processing, achieving stable pre-training of massive foundation models entirely within an FP8 architecture has historically been mathematically precarious. The strict limits of the datatype frequently result in underflow errors and accumulation divergence over billions of training steps 37. The technical architecture underlying DeepSeek-V3 represents a paradigm shift, utilizing a custom FP8 mixed-precision framework to successfully train an immense 671-billion parameter Mixture-of-Experts (MoE) model entirely from scratch 3839.
To successfully execute this without degrading model convergence or suffering from irrecoverable loss spikes, the DeepSeek framework innovated across multiple vectors. Standard industry practice dictates a hybrid approach (using E4M3 for forward passes and switching to E5M2 for backward gradient passes) 10. The DeepSeek engineers abandoned this entirely, opting for universal E4M3 utilization to maximize precision uniformly across all training stages 1039.
This universal format was only possible through extreme fine-grained online quantization. Instead of pre-calculating boundaries, DeepSeek scales activations dynamically on a microscopic 1x128 tile basis (calculated per token, per 128 channels). Simultaneously, the network weights are scaled on a 128x128 block basis during the training flow 10. Furthermore, to circumvent the hardware limitations of NVIDIA's Hopper Tensor Cores - which use a fixed-point accumulation strategy limited to roughly 14 bits of precision, causing mathematical inaccuracies at massive scales - DeepSeek periodically promoted partial matrix multiplication (GEMM) results directly into FP32 memory registers to preserve accuracy 1011.
By successfully navigating this custom FP8 regime, the DeepSeek-V3 architecture was completely pre-trained using only 2.788 million H800 GPU hours. This yielded unprecedented capital efficiency, with total training compute estimated at under $6 million, while achieving empirical performance that rivals proprietary models costing tens of millions more to train in BF16 3839.
Extreme Compression and Sub-Two-Bit Architectures
As conventional post-training integer quantization reaches absolute diminishing returns at the 3-bit threshold, artificial intelligence researchers have been forced to pioneer radically different computational architectures to compress models safely below 2 bits per parameter.
The 1.58-Bit Paradigm: BitNet b1.58
Introduced by researchers at Microsoft, BitNet b1.58 is a modified Transformer architecture designed to be trained from inception using ternary weights. Every single parameter within the neural network is mathematically constrained to one of exactly three values: {-1, 0, 1} 4041. Formally representing three distinct states requires log2(3) bits of data, which calculates to exactly 1.58 bits of information per weight, lending the architecture its name 4042.
This profound compression is achieved via an "absmean" quantization function implemented during Quantization-Aware Training. The weight matrix is divided by its overall mean absolute value, and the resulting figures are rounded and clamped strictly to the ternary set 4042. The inclusion of the zero value distinguishes this framework from prior 1-bit binary models. The zero acts as an explicit feature filter, providing the network with a native sparsity mechanism to forcefully drop irrelevant inputs and noise during the forward pass 404143.
Hardware Arithmetic Simplification
The true structural advantage of BitNet b1.58 is its overhaul of hardware arithmetic. Standard matrix multiplication in language models relies heavily on computationally expensive floating-point multiplication modules. In a ternary model, complex multiplication is eliminated entirely. If a weight registers as +1, the activation is passed forward identically; if it registers as -1, the activation's sign is simply inverted; if it registers as 0, the activation is bypassed entirely 4044.
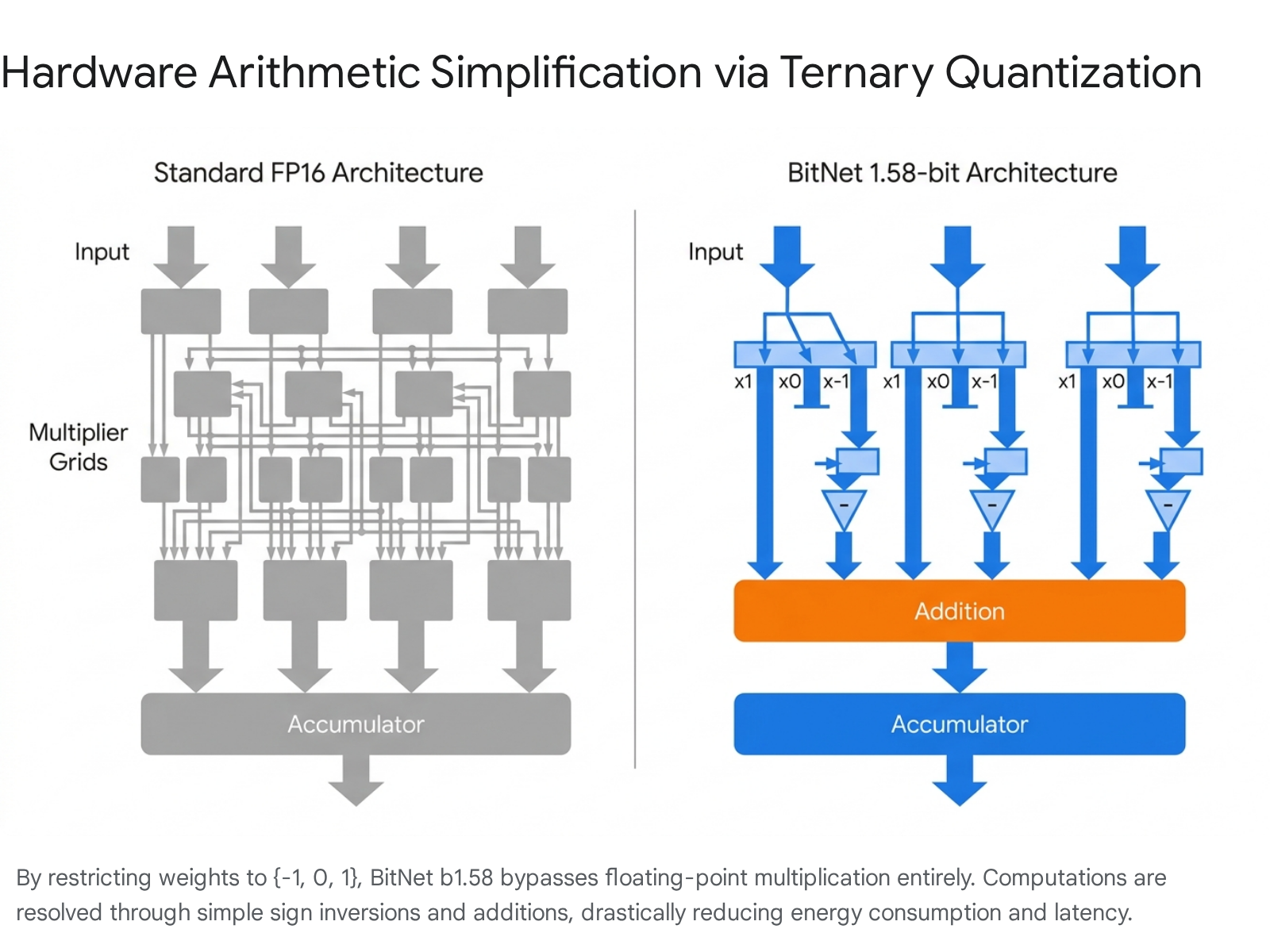
Because the neural network resolves all internal operations using exclusively 8-bit integer additions and sign flips, the energy expenditure per processed token plummets. Benchmarks indicate that BitNet b1.58 reduces the total arithmetic operational energy consumption for matrix multiplication by 71.4 times on 7-nanometer silicon when compared directly to standard FP16 baselines 4124.
Comparative Efficiency of Ternary Models
The end-to-end memory requirements of the 1.58-bit paradigm enable unprecedented edge deployment. A 2-billion parameter BitNet model (specifically the 2B4T variant trained on 4 trillion tokens) consumes merely 0.4 GB of storage memory, enabling rapid operation with extremely low latency overhead on standard devices using frameworks like bitnet.cpp 404344.
When scaled appropriately, the accuracy convergence of the ternary structure is highly robust. Below 3 billion parameters, ternary networks show a slight cognitive deficit compared to FP16 models. However, starting at the 3-billion parameter threshold, BitNet matches the zero-shot accuracy, perplexity, and reasoning capabilities of standard FP16 LLMs of identical size 4142.
| Benchmark Metric | BitNet b1.58 (2B Params) | Standard FP16 Baseline (Llama 3.2 1B) | Efficiency Gain / Deficit |
|---|---|---|---|
| Total Memory Footprint | 0.4 GB | 2.0 GB | 80% Reduction 4044. |
| Inference Latency | 29 ms | 48 ms | 1.65* Speed Increase 4044. |
| Energy Consumption (per token) | 0.028 Joules | 0.258 Joules | 9.2* Energy Reduction 4044. |
| MMLU Accuracy Score | 53.17% | 45.58% | +7.59% Improvement 44. |
| GSM8K Math Score | 58.38% | 38.21% | +20.17% Improvement 44. |
Infrastructure Economics and Hardware Scaling
The practical implementation and economic viability of model quantization are intrinsically tied to the underlying physical architecture of data center accelerators. The rapid industry shift from post-training integer methodologies toward native FP8 quantization has been largely catalyzed by the specific architectural leap between NVIDIA's Ampere (A100) and Hopper (H100) GPU generations 646.
The older A100 architecture relies on 3rd-generation Tensor Cores and peaks at a maximum of approximately 2.0 Terabytes per second (TB/s) of memory bandwidth 4647. Furthermore, the A100 lacks any native silicon support for the FP8 format. Conversely, the H100 was designed explicitly for transformer acceleration, integrating a dedicated Transformer Engine with native FP8 support and a vastly expanded 3.35 TB/s of HBM3 memory bandwidth 4647.
Because autoregressive inference is aggressively throttled by memory streaming rates, the H100's superior bandwidth inherently accelerates token generation unconditionally. However, when paired directly with advanced FP8 quantization or AWQ 4-bit models, the H100 exploits its native silicon format to process compressed weights with virtually no arithmetic overhead 64647. Independent datacenter benchmarking demonstrates that this synergistic combination enables the H100 to stream between 250 and 300 tokens per second for a 70B parameter model. By comparison, an A100 serving the same architecture reaches a hard ceiling of approximately 130 tokens per second 4748.
For foundational training operations, leveraging FP8 on the H100 yields up to a 2.4 to 3.0 increase in overall mathematical throughput, vastly reducing the total operational expenditures and server uptime required for frontier model development 464748. When pure inference cost-efficiency is the sole objective rather than absolute scale, the L40S accelerator frequently presents a lower cost-per-token rate than the A100, capitalizing on lower operational pricing despite slightly slower raw tensor speeds 4849. Ultimately, applying correct quantization formatting to target hardware - matching GGUF to edge CPUs, AWQ to Ampere, and FP8 to Hopper - dictates the economic sustainability of artificial intelligence deployments.