How Retrieval-Augmented Generation Works
Retrieval-Augmented Generation (RAG) is an artificial intelligence architecture that improves the accuracy of large language models (LLMs) by fetching relevant, real-time data from an external knowledge base before answering a prompt. Instead of relying solely on frozen training data, the system performs a search, retrieves factual context, and instructs the language model to generate an answer grounded exclusively in that retrieved evidence.
The Core Problem RAG Solves
Modern large language models possess remarkable capabilities in reasoning, summarization, and natural language generation. However, their underlying architecture presents fundamental limitations when deployed in enterprise or knowledge-intensive environments. The most pressing limitation is the concept of knowledge cutoffs. Training state-of-the-art models demands massive computational resources, requiring large clusters of high-performance GPUs (such as NVIDIA H100s) to run for thousands of hours, consuming vast amounts of power to process petabytes of training data 1. Once training is complete, the model's knowledge is effectively frozen in time. An LLM trained in late 2023 has no inherent awareness of financial reports, internal company policies, or geopolitical events that occurred in 2024 or beyond 11.
Furthermore, when an LLM lacks the necessary information to answer a question, it frequently hallucinates. Advanced models are particularly prone to fabricating highly convincing, elaborately detailed answers rather than admitting ignorance 34. Researchers call this the "competence paradox" - highly sophisticated AI systems will confidently invent facts when missing context, while smaller systems are often more honest about their limitations 3. Without external grounding, deploying an LLM to answer specific domain questions, such as legal research or proprietary technical support, is highly unreliable.
Retrieval-Augmented Generation (RAG) was developed to bridge this gap. By separating the reasoning engine (the LLM) from the knowledge base (the vector database), RAG allows organizations to feed fresh, proprietary, and highly specific data into the model at the exact moment a user asks a question 12. The LLM no longer has to "remember" the answer; it only has to read the retrieved documents and summarize them.
The architecture of a RAG system operates in two distinct phases: Ingestion (preparing the data asynchronously) and Retrieval & Generation (answering the query in real-time).
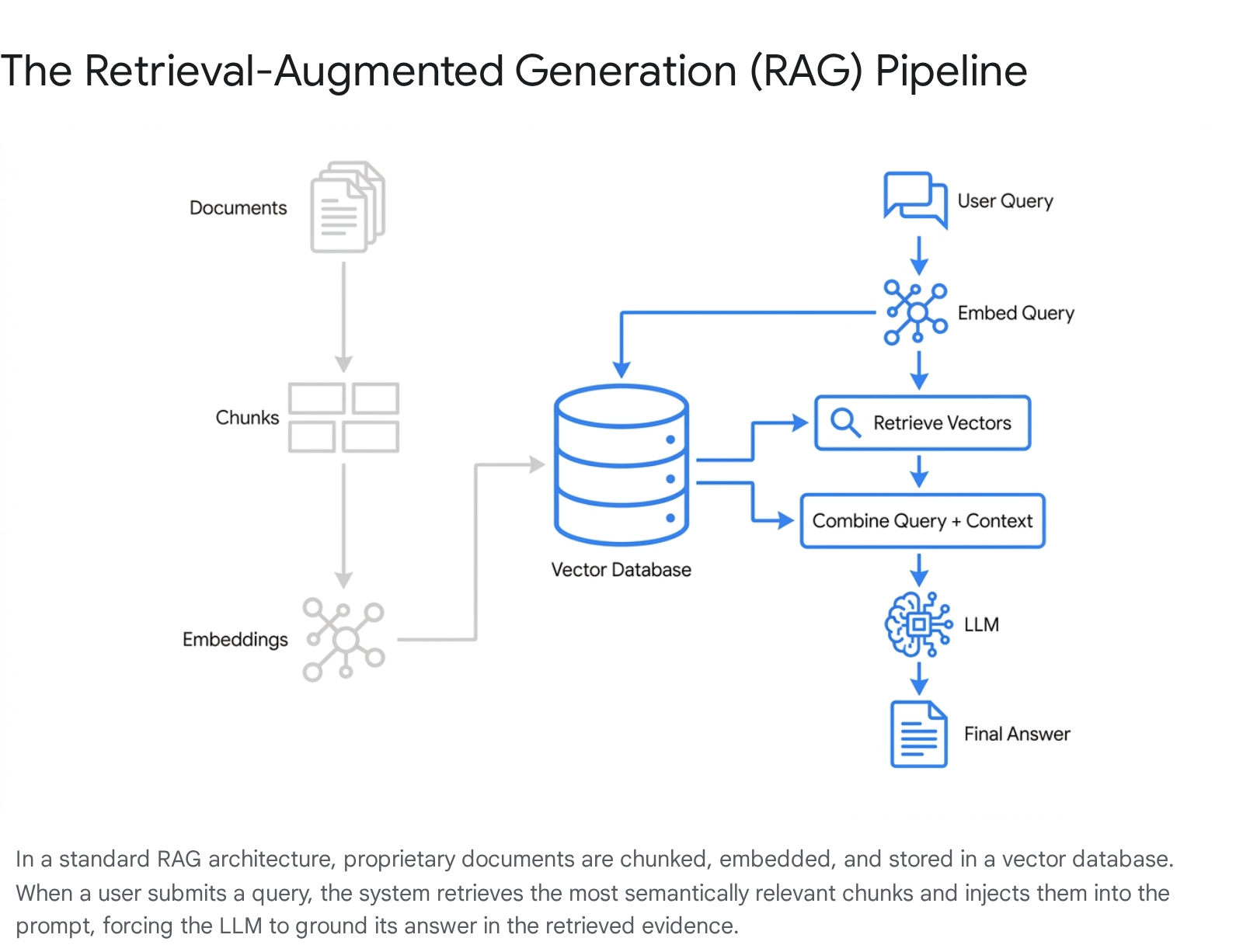
Understanding the mechanics of each phase reveals why some RAG systems perform flawlessly while others fail to retrieve the right information.
The Ingestion Phase: Preparing the Data
Before a system can retrieve information, the underlying unstructured data - PDFs, internal wikis, customer support logs - must be processed, organized, and stored. Large language models have finite context windows, which place a strict limit on the number of tokens (words or word fragments) they can process in a single request 6. While context windows are growing, feeding entire libraries of documents into an LLM for every single query remains computationally inefficient, slow, and financially prohibitive 63.
To solve this, documents are systematically broken down into smaller, searchable pieces.
The Critical Role of Document Chunking
Chunking is arguably the most critical preprocessing factor for RAG performance 64. The goal of chunking is to slice a massive document into smaller segments that isolate specific concepts, facts, or instructions. When a RAG system performs poorly, the issue is often not the language model or the retrieval algorithm; it is the chunks themselves 6. Even a perfect retrieval system fails if it searches over poorly prepared data.
If a chunk is too small (e.g., 50 to 128 tokens), it may lack the surrounding context required for the LLM to generate a coherent answer 14. The retriever might find a fragment perfectly matching the user's keywords, but the fragment itself gives the LLM too little context to synthesize a correct response. Conversely, if a chunk is too large (e.g., 2,048 tokens or more), it dilutes the relevance of the specific fact contained within it, introducing noise that can confuse the retrieval algorithm and bury the relevant information 45.
A poorly executed cut can permanently destroy the semantic meaning of a fact. Consider a scenario where a naive system slices a document exactly mid-sentence based purely on character counts: * Chunk 1: "Evaporation accounts for approximately..." * Chunk 2: "...90% of atmospheric moisture from oceans."
If a user queries, "What percentage of moisture comes from evaporation?", neither chunk independently contains the answer. The retrieval system fails because the core fact was severed during ingestion 10. At an enterprise scale - where databases hold hundreds of thousands of chunks - a 1% bad cut rate results in thousands of broken facts that the system can never retrieve correctly 10.
Analyzing Chunking Strategies
The AI engineering community has evolved from simple fixed-size splitting to sophisticated, AI-driven approaches that preserve context and meaning 6. A comprehensive 2024 benchmark study by NVIDIA tested multiple strategies across various datasets, revealing that there is no universal "best" approach; the optimal strategy depends heavily on the document structure and the anticipated query types 6511.
| Chunking Strategy | Mechanism | Benchmark Performance & Best Use Case |
|---|---|---|
| Fixed-Size (Token) Chunking | Splits text by a strict token or character count (e.g., exactly 512 tokens), usually with an overlap (e.g., 50 tokens) to prevent hard cutoffs 67. | Simplest to implement. NVIDIA's benchmark showed consistent accuracy around 0.603 - 0.645 5. Best for simple documents, meeting notes, or short emails 6. |
| Recursive Character Chunking | Attempts to split text at natural boundaries using a priority hierarchy: double newlines (paragraphs), single newlines, periods, and finally spaces 167. | Maintains semantic coherence far better than fixed-size splitting. Achieved 69% end-to-end accuracy in Vecta benchmarks 4. Excellent general-purpose starting point. |
| Document/Page-Level Chunking | Preserves the exact structural boundaries of the original file (e.g., one PDF page equals one chunk) 1011. | Achieved the highest average accuracy (0.648) in NVIDIA's benchmark 5. Perfect for structured PDFs, financial reports, or legal contracts where layout dictates meaning 108. |
| Semantic Chunking | Uses an embedding model to measure semantic distance between sentences, splitting the text only when a major topic shift is detected 46. | Improved recall by up to 9% in Chroma benchmarks, but produced fragments averaging only 43 tokens, hurting end-to-end RAG accuracy 411. Expensive and slow 9. |
| Code-Aware / Markdown Chunking | Splits strictly at H1/H2 markdown headers or Abstract Syntax Tree (AST) definitions for code 41010. | Free metadata allows systems to filter searches by section before vector matching even runs 10. Ideal for code repositories and structured APIs. |
Extensive industry benchmarks suggest that a target size of roughly 400 to 512 tokens, coupled with a 10% to 15% overlap between chunks, serves as the most reliable starting point for general narrative text 458. The NVIDIA research confirmed that 128-token chunks were generally too small (scoring a poor 0.421 in some knowledge graph tests), while 2,048-token chunks consistently underperformed the 1,024-token variants 45. However, for analytical queries over financial datasets, larger chunks (1,024+ tokens) or page-level chunking proved vastly superior, as financial metrics like gross profit and revenue must remain in the same chunk for the LLM to calculate margins 61011.
Embeddings: Translating Text to Mathematics
Once documents are appropriately chunked, the text must be translated into a format that computers can search via mathematical similarity. This is achieved through the generation of vector embeddings.
An embedding model (such as OpenAI's text-embedding-3, Voyage AI, or Cohere) processes a chunk of text and outputs a long, high-dimensional array of numbers - a vector - that represents the semantic meaning of that text 101112. By taking real-world text and translating it into numerical representations, these numbers can be fed into machine learning algorithms to determine semantic similarity 12.
In this high-dimensional space, concepts that are semantically related are positioned closer together. For example, the phrases "feline behavior" and "cat habits" do not share exact keywords, but a sophisticated embedding model understands their semantic equivalence and assigns them vector coordinates that are close to one another 1219. This is a massive leap over traditional lexical searches, which rely heavily on exact keyword overlap.
Vector Databases and the HNSW Algorithm
Once embeddings are generated, these numerical vectors are stored in a specialized infrastructure known as a vector database (such as Pinecone, Weaviate, Qdrant, or Milvus) 2013. Traditional scalar-based databases, which utilize inverted indexes to map specific words to documents, are highly efficient at finding exact keyword matches. However, they cannot keep up with the complexity and scale required to perform similarity calculations across thousands of dimensions 1113.
To search these vectors in milliseconds, vector databases utilize Approximate Nearest Neighbor (ANN) algorithms. The industry standard algorithm powering modern vector search is Hierarchical Navigable Small World (HNSW) 2013.
HNSW creates a hierarchical, tree-like structure where data is organized into a multi-layered network 2013. To understand this structure, imagine navigating a map of a massive city. The top layer of the HNSW graph contains only a few nodes, acting like broad interstate highways that get the algorithm close to the general destination. As the search descends into lower layers, the network becomes denser, resembling local roads, and finally, detailed residential streets 20.
When a query is executed, the algorithm enters the top layer, quickly identifying the general "neighborhood" of the semantic space based on a probability rule. It then drops down through the layers, executing a more thorough, localized search to find the exact nearest neighbors in the bottom layer 20. This layered, probabilistic routing allows the database to locate the most relevant documents among millions of entries without having to calculate the distance to every single vector individually. It creates a system that balances extreme speed with high retrieval accuracy, making massive-scale RAG possible 2013.
The Retrieval Phase: Finding the Needle
When a user submits a query to the RAG system, the ingestion phase is complete, and the runtime retrieval phase begins. The user's text query is instantly converted into a vector using the exact same embedding model that was used during the ingestion phase 11.
The vector database then performs a mathematical operation - most commonly calculating the cosine similarity - to measure the distance between the user's query vector and the millions of document vectors stored in the database 1022. The chunks with the shortest distance (the highest similarity scores) are retrieved as the potential context for the LLM.
Semantic vs. Lexical (Hybrid) Search
While vector embeddings are excellent at understanding broad concepts, user intent, and synonyms, they occasionally struggle with exact entity retrieval. If a user queries an exact serial number, a highly specific acronym, or an uncommon proper noun, pure semantic search might fail because the embedding model generalizes the concept rather than looking for the exact string 1424.
To counter this, modern production RAG systems deploy Hybrid Search. This approach combines dense semantic vector search with traditional sparse keyword-based lexical search - most commonly using the BM25 algorithm 1415.
BM25 is an advanced evolution of TF-IDF (Term Frequency-Inverse Document Frequency) 1415. It measures word importance by evaluating how frequently a term appears in a specific chunk (term frequency) relative to how rarely it appears across the entire database (inverse document frequency) 1415. If a user searches for the exact phrase "Novorossiya," traditional RAG relying solely on vector embeddings might retrieve chunks about geopolitical regions that "look similar" semantically but fail to locate the exact term 24. BM25 ensures the exact term is prioritized. By fusing the dense semantic retrieval of embeddings with the sparse keyword retrieval of BM25, the system ensures that both conceptual questions and specific keyword lookups return highly accurate candidate chunks 141526.
The Reranking Step: Optimizing Precision
Even with hybrid search, the initial retrieval phase is optimized for recall (finding all potentially relevant documents) rather than absolute precision 27. Vector databases calculate similarity rapidly, but they do so in a somewhat coarse manner, comparing compressed mathematical representations of text. As a result, the initial top-50 results often contain a mix of highly relevant facts and tangential noise 28.
Passing 50 to 100 chunks of varying quality directly to the language model creates severe bottlenecks. It increases API costs, raises generation latency, and actively harms the model's ability to answer correctly by burying the true answer in noise 2816. The solution to this is an intermediary stage known as Reranking.
Rerankers are highly specialized models (known as cross-encoders) that act as a strict filter just before the LLM generation step. While the initial vector search scores the query and the documents separately (a bi-encoder approach), a cross-encoder evaluates the user's query and each retrieved document together 3031. The cross-encoder applies deep attention mechanisms to understand the exact logical relationship between the prompt and the document 31.
The reranker assigns a highly calibrated relevance score to each document, reordering the list so that the most genuinely useful context sits at the very top. The system then discards the lower-ranked items, passing only the absolute best chunks (typically the top 5 or 10) to the LLM 272830.
Industry benchmarks from late 2025 and early 2026 demonstrate the dramatic impact of rerankers. Adding a reranking stage to a two-stage retrieval pipeline typically improves retrieval precision (NDCG@10) by 15% to 40% compared to semantic search alone 2731. The benchmark data reveals clear tradeoffs between quality, latency, and cost across different reranker models.
| Reranker Model | Architecture Type | Latency (p95) / Cost | Benchmark Performance & Best Use Case |
|---|---|---|---|
| Cohere Rerank 3 & 4 | Hosted API / Closed Weights | Low Latency / ~$2 per 1k requests | Enterprise RAG requiring the highest quality English and multilingual precision. Considered the industry gold standard for out-of-the-box accuracy 272830. |
| Jina Reranker v2 / v3 | Open Weights / Self-Hosted | Fast (~188ms) / ~$0.50 per 1k requests | Excellent speed-accuracy tradeoff. Ideal for latency-sensitive applications, multilingual corpora, and teams requiring data privacy through self-hosting 27283032. |
| BGE-Reranker-Large v2 | Cross-Encoder / Open | Moderate (~145ms) / ~$0.35 per 1k queries | Teams looking for the absolute best open-source quality per dollar, running on dedicated GPU infrastructure. Scores very close to Cohere on nDCG benchmarks 273031. |
| MiniLM-L-6-v2 | Cross-Encoder / Open | Extremely Fast (~55ms) / ~$0.08 per 1k queries | Ultra-low latency requirements and strict compute budgets. Great baseline model, but sacrifices top-end reasoning compared to larger cross-encoders 30. |
The Generation Phase and RAG Failure Modes
In the final phase of the RAG pipeline, the highly curated, reranked text chunks are injected directly into the LLM's system prompt alongside the user's original question. The LLM reads the provided evidence, synthesizes the information, and generates a fluid, natural-language response.
However, presenting the LLM with the correct facts does not guarantee a correct answer. Extensive research has uncovered critical flaws in how language models process retrieved context, proving that "grounding does not equal accuracy" 33. RAG significantly reduces hallucinations, but failure modes still persist where the retrieval is correct, the model cites the correct chunk, but the generation still invents the underlying rule 33.
The "Lost in the Middle" Phenomenon
The most pervasive generation failure mode is driven by how LLMs allocate attention across long prompts. In 2023, a landmark study by researchers at Stanford University (Liu et al.) titled "Lost in the Middle: How Language Models Use Long Contexts" identified a severe vulnerability in LLM architecture 341718. The researchers designed controlled experiments to observe what happens when the exact document containing the answer is placed at different positions within the LLM's input context 34.
The findings revealed a distinctive U-shaped performance curve.
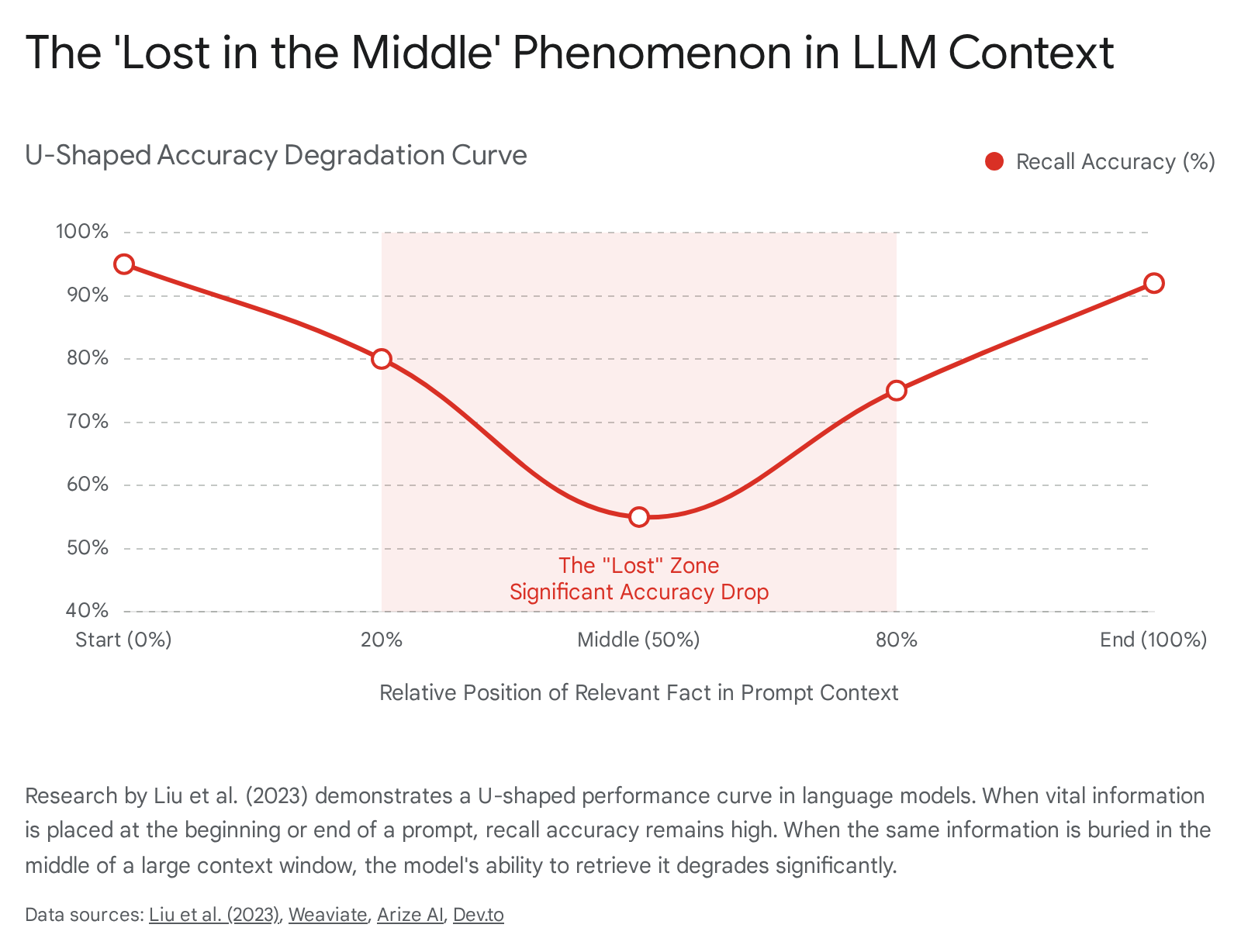
When the relevant fact was placed at the very beginning (primacy bias) or at the very end (recency bias) of the provided context, the model's accuracy was remarkably high 3418. However, when the critical fact was buried in the middle of the retrieved chunks, accuracy plummeted - sometimes degrading by more than 20 to 30 percentage points 4341837. In the middle positions, models often underperformed even a closed-book baseline, meaning the long context actively hurt performance if the crucial text sat mid-prompt 34.
The implications of this study are profound for RAG pipeline design. It proved that simply expanding a model's context window - feeding it 100,000 tokens instead of 4,000 - does not make it smarter or more robust 3437. In fact, passing too many retrieved documents to the model without strict prioritization actively harms performance, as the true answer gets "lost in the middle" of lower-quality chunks 416.
Reproducibility studies in 2026 confirmed that despite massive advancements in model architecture (such as models boasting 1-million token windows), the U-shaped degradation curve persists. As researchers note, bigger context windows simply create "more middle to lose things in" 37. A May 2026 analysis reported that for multi-fact retrieval, average recall in a 1-million token window sat around 60%, even if single-fact "needle-in-a-haystack" recall was 99.7% 33.
Addressing Context Loss
To mitigate the "Lost in the Middle" pathology and other generation failures, RAG developers apply several strategies at the generation stage: * Context Compression: Using rerankers to aggressively filter out noisy chunks, compressing the remaining context to fit the model's optimal token budget so evidence remains at the highly attentive edges of the prompt 2616. * Long Context Reordering: Algorithms logically reorder the retrieved chunks after reranking. They place the highest-scoring chunks at the very beginning and the very end of the prompt, intentionally burying the lower-scoring chunks in the middle where the LLM is least attentive 2638. * Stale Index Prevention: Stale data is a high-risk hallucination vector. Implementing document versioning and timestamp-filtered retrieval ensures the model generates answers based on the most recent policies, preventing it from hallucinating based on outdated chunks 4.
Advanced RAG: Contextual Retrieval and Late Chunking
As the baseline "Naive RAG" architecture matured, researchers identified persistent failure modes that standard semantic chunking could not solve. Specifically, traditional chunking strips away the broader context of the document.
The Problem with Anonymous Chunks
A fundamental flaw in traditional RAG is the loss of document-level context. If a financial report is split into small fragments, a specific chunk might simply read: "The company's revenue grew by 3% over the previous quarter." 14.
When embedded in isolation, this chunk is essentially anonymous. It lacks the entity name, the time period, and the intent of the original document. If a user asks about "ACME Corp's Q2 2023 performance," semantic search will likely fail to retrieve this chunk because the embedding contains no mathematical connection to ACME Corp 1526.
Anthropic's Contextual Retrieval Breakthrough
In late 2024, AI research firm Anthropic introduced a mechanism called Contextual Retrieval to solve this isolation problem. The method elegantly enriches each chunk with additional explanatory context before it is ever embedded 1519.
During the ingestion phase, the system passes every single chunk, alongside the entire parent document, to a fast, inexpensive LLM (such as Claude 3 Haiku). The LLM is instructed via a specific prompt to write a 50-to-100 token contextual description situating the chunk within the broader document 926.
The system prepends this generated string to the chunk. For example, the anonymous revenue chunk becomes:
"This chunk is from an SEC filing on ACME Corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter." 15.
This newly enriched chunk is then passed to the embedding model. Because the embedding now captures both the micro-fact and the macro-context, retrieval accuracy skyrockets 19. According to Anthropic's published metrics, utilizing Contextual Embeddings alone reduced the top-20 chunk retrieval failure rate by 35% (from 5.7% to 3.7%). When combined with BM25 hybrid search, the failure reduction reached 49%. Finally, adding a reranking step pushed the total failure reduction to an impressive 67% (dropping failures to just 1.9%) 915.
While this technique adds a one-time preprocessing cost during ingestion (reported at approximately $1.02 per million document tokens using prompt caching), the permanent boost to semantic retrieval quality is considered highly cost-effective for enterprise applications 9.
Late Chunking
An alternative approach to preserving context is "Late Chunking." Rather than splitting the document first and creating isolated embeddings, Late Chunking works backward. It starts by feeding the entire document into a long-context embedding model (capable of 8,192+ tokens) 7. This creates detailed, token-level embeddings that understand the full picture of the document. Only after this global embedding is created does the system split the document into retrieval chunks 7. Because each chunk's embedding was formed while attending to the entire document, a pronoun like "Its" maintains a strong vector connection to the subject (e.g., "Berlin") mentioned pages earlier, providing significant gains in standard retrieval benchmarks 10.
GraphRAG: Connecting the Dots Across Documents
While Contextual Retrieval fixes the isolation of individual chunks, standard RAG still struggles with "global" or multi-hop queries. If an analyst asks a holistic question like, "What are the common themes among our top-spending customers in Q4?" or "How do these five separate research projects intersect?", baseline RAG fails 4041.
Vector search is fundamentally designed to find specific paragraphs that match a query; it cannot connect disparate dots scattered across thousands of distinct documents to synthesize a macro-level insight 2021. To address this, the tech community developed approaches that marry RAG with structured networks.
The Microsoft Research GraphRAG Framework
Developed and open-sourced by Microsoft Research in 2024, GraphRAG abandons the pure vector-text paradigm and introduces knowledge graphs (KGs) to the retrieval process 202223.
Instead of merely chunking text and embedding it, a GraphRAG pipeline utilizes an LLM heavily during the ingestion phase. The LLM reads the unstructured source documents and extracts specific entities (people, organizations, locations, concepts) and the explicit relationships connecting them 402122. This structured data is used to construct a massive network graph where entities are nodes and relationships are edges 41.
The true innovation of GraphRAG lies in its graph partitioning phase. The architecture applies graph machine learning algorithms - specifically the Leiden algorithm - to detect "communities" within the network 244024. These communities represent clusters of densely interconnected nodes that exhibit stronger relationships among themselves than with the rest of the graph 24. The LLM then pre-generates analytical summaries for each of these hierarchical communities before any user ever asks a question 244024.
Local vs. Global Search
At runtime, GraphRAG can execute two distinct types of queries: 1. Local Search: For questions about specific entities, the system performs a targeted subgraph retrieval. It locates the nodes corresponding to the query, then traverses the graph to gather directly linked entities, relationship descriptions, and the immediate community summary 2247. 2. Global Search: For holistic, sensemaking questions across the entire dataset, GraphRAG retrieves the pre-generated community summaries. This allows the LLM to reason across the entire topology of the data simultaneously, rather than trying to piece together a narrative from 50 random text chunks 2424.
Benchmarks show GraphRAG delivering up to a 3.4x accuracy improvement over traditional RAG in complex enterprise scenarios, enabling AI systems to answer macro-level questions that were previously impossible to resolve (achieving 80% correct answers versus 50% for traditional RAG in specific enterprise benchmarks) 40.
However, this power comes at a steep infrastructural cost. The indexing pipeline requires intense LLM compute to extract entities and generate summaries, resulting in substantial token costs and slower ingestion times. Furthermore, updating the system with new, dynamic data requires complex re-indexing of the graph relationships, making it less suitable for rapidly changing data streams compared to naive RAG 2124.
Architecture Showdown: RAG vs. Fine-Tuning vs. Long Context
As organizations mature in their AI deployment, a common architectural debate emerges regarding how best to inject private, proprietary data into an LLM. The choice typically falls between three paradigms: Retrieval-Augmented Generation, Model Fine-Tuning, and Long-Context Prompting 3.
The Fine-Tuning Misconception
A prevalent misconception in AI development is that fine-tuning is the optimal path for teaching a model new facts 248. As OpenAI's CEO noted in late 2024, rushing to fine-tuning is one of the most common organizational mistakes 48.
Fine-tuning alters the internal parameters and weights of a pre-trained model by continuing its training on a custom dataset 23. This process is exceptionally effective for changing a model's behavior, style, or tone. For example, fine-tuning is the correct choice if you need an LLM to respond exactly like a specific brand's customer service persona, output valid JSON structures exclusively, or learn a proprietary coding syntax 23.
However, fine-tuning does not reliably encode factual data. A fine-tuned model will still confidently hallucinate when asked for specific facts, and any data baked into its weights instantly becomes stale if the underlying reality changes (e.g., pricing updates) 225. Fine-tuning teaches an LLM how to think; RAG changes what an LLM knows at query time 2.
The Long-Context Alternative
Alternatively, Long-Context Prompting bypasses retrieval architecture entirely by taking advantage of newer frontier models boasting massive context windows. Models like Google's Gemini 1.5 Pro support up to 2 million tokens, while Claude 3 and Llama 3.1 support hundreds of thousands of tokens 326.
The theory behind long-context is simple: skip the vector databases and chunking strategies entirely. Just drop the entire corporate knowledge base directly into the prompt and let the LLM's sophisticated attention mechanism find the answer 127.
While conceptually elegant, this brute-force approach faces severe limitations in production volume. Injecting 100,000 tokens on every single user query incurs astronomical API costs - long context is estimated to be 20 to 24 times more expensive than RAG at scale 3. It also significantly increases generation latency 1. Furthermore, as demonstrated by the "Lost in the Middle" research, forcing a model to read an entire manual for a simple question degrades reasoning quality 37.
A comprehensive comparison reveals the strengths and weaknesses of each approach:
| Feature | Retrieval-Augmented Generation (RAG) | Model Fine-Tuning | Long-Context Prompting |
|---|---|---|---|
| Primary Purpose | Injecting factual, dynamic external knowledge at query time 23. | Altering model behavior, tone, style, or specific reasoning patterns 23. | Global reasoning over a single, bounded artifact (e.g., a massive legal contract) 1. |
| Data Freshness | High. Data can be updated instantly in the vector database without retraining the model 5253. | Low. Knowledge is permanently frozen at the time of training 2. | High, but requires reloading the entire dataset on every single API query 1. |
| Cost at Scale | Low inference cost (prompts remain small). Upfront embedding cost is paid once 152. | High upfront training cost. Inference costs remain standard 3. | Exorbitant at volume. Processing massive prompts on every query is up to 24x more expensive 3. |
| Hallucination Risk | Reduced through factual grounding, though poor retrieval can cause failures 425. | High for factual recall. Fine-tuning cannot reliably force a model to memorize documents 32. | Moderate to High. Prone to missing facts due to "Lost in the Middle" attention degradation 37. |
In advanced production environments, these approaches are rarely mutually exclusive. The most robust enterprise AI systems utilize a hybrid architecture: they deploy a lightweight, fine-tuned model to enforce specific conversational behaviors, power that model with a dynamic RAG pipeline for cheap, real-time factual retrieval, and reserve long-context processing strictly for complex reasoning over single, massive documents that fit perfectly within the window 13275253.
Bottom line
Retrieval-Augmented Generation remains the architectural bedrock for deploying reliable, grounded AI applications on proprietary data. While the core concept - embedding text and performing vector search - is conceptually straightforward, engineering a production-grade system requires meticulous decisions regarding chunking parameters, hybrid semantic/lexical search, and cross-encoder reranking to combat inherent LLM attention limitations. As language models continue to evolve, RAG is maturing alongside them, integrating pre-processing innovations like Contextual Retrieval and GraphRAG to move beyond simple fact-fetching and enable deep, multi-hop reasoning across vast enterprise networks.