Latency constraints on large language models in trade execution
Introduction
In the domain of quantitative finance, the integration of artificial intelligence has historically been bifurcated into predictive modeling and execution logic. Predictive modeling focuses on alpha generation - identifying market inefficiencies through statistical analysis - while execution logic governs the mechanical interaction with the limit order book to minimize slippage and market impact. The advent of Large Language Models (LLMs) has introduced unprecedented capabilities in processing unstructured financial data, analyzing sentiment, and performing complex reasoning over time-series data. However, the deployment of LLMs directly within the execution loop of live trading environments remains severely restricted by the fundamental physics of latency and hardware architecture.
Financial markets operate on microsecond and nanosecond timescales. The infrastructure required to remain competitive in High-Frequency Trading (HFT) and algorithmic market making relies on custom silicon, proximity co-location, and deterministic execution environments. Conversely, the autoregressive architecture of LLMs imposes inference latencies measured in milliseconds or seconds. This operational incongruity creates a critical boundary condition: LLMs possess the semantic reasoning capacity required for sophisticated financial analysis, but they fundamentally lack the speed necessary for synchronous trade execution.
This report provides an exhaustive analysis of how latency constraints limit the practical application of LLMs in live trading. It examines the market microstructure that dictates latency budgets, the hardware and algorithmic bottlenecks inherent to transformer architectures, and the engineering paradigms - such as disaggregated inference, Field-Programmable Gate Array (FPGA) acceleration, and hybrid asynchronous architectures - developed to bridge this gap.
The Physics of Trading Latency and Signal Decay
To understand the limitations of LLMs, it is necessary to establish the operational realities of modern financial exchange infrastructure and the temporal decay of alpha signals. The latency budget of a strategy determines the viable technology stack for its execution.
High-Frequency Trading and Market Microstructure
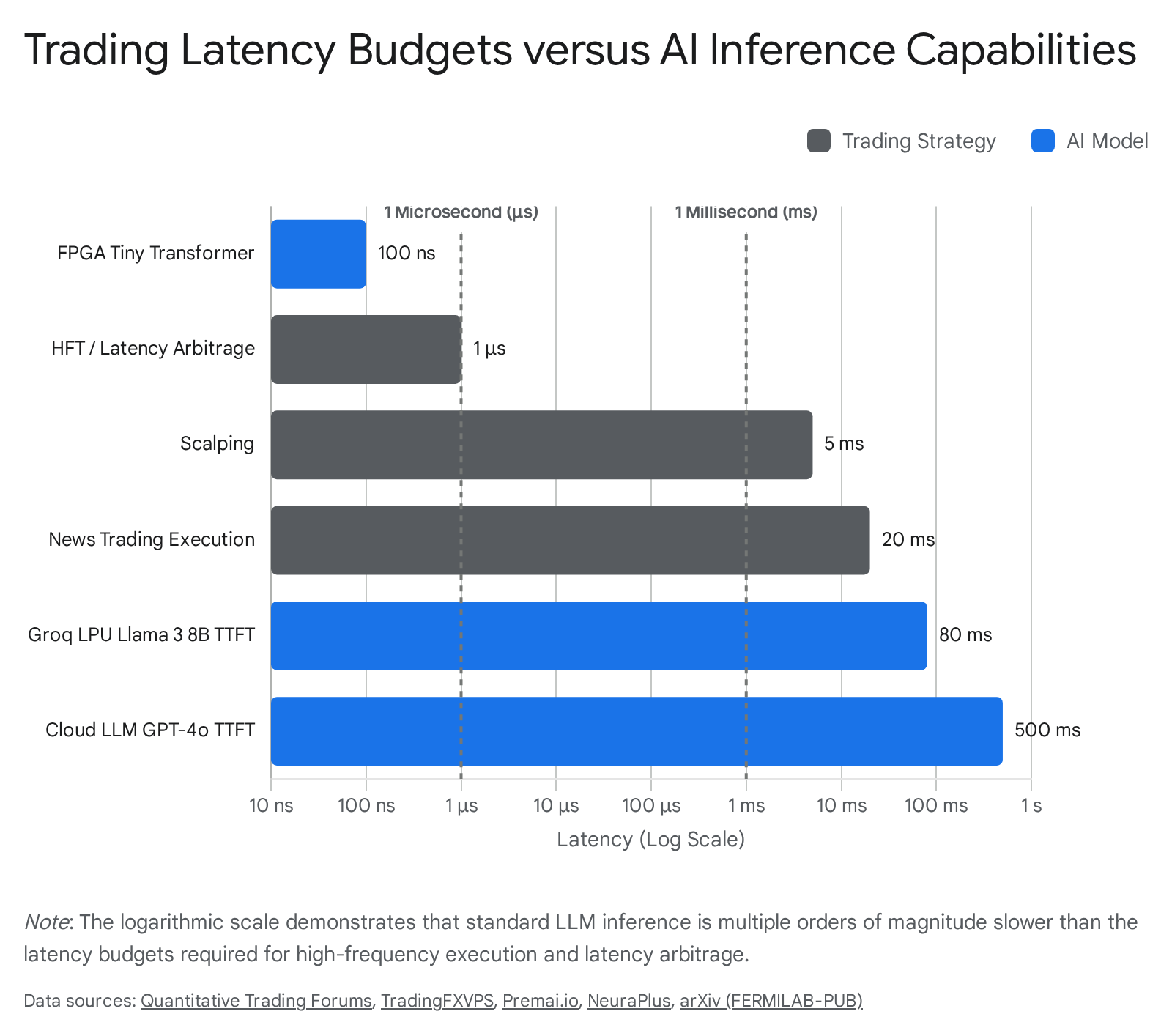
Trading strategies are strictly governed by their holding periods and the half-life of the information they exploit. High-Frequency Trading involves executing a large volume of trades in fractions of a second to capture fleeting pricing discrepancies 12. These strategies, including latency arbitrage and algorithmic market making, depend entirely on structural speed advantages. HFT firms utilize microwave transmission networks, which propagate signals at near the speed of light through the atmosphere, offering up to a 50% speed advantage over fiber optic cables 1. Within the data center, physical distance is meticulously managed; data transmission physics set fundamental limits, where every kilometer of fiber optic cable introduces approximately 4.9 microseconds of delay 4. For example, the theoretical fastest speed via fiber from Nasdaq to Secaucus data centers is roughly 162 microseconds, whereas wireless microwave transmission reduces this to 89 microseconds 1.
At this frequency, optimization is paramount. A software-based trading decision routed through standard operating systems may take roughly 10,000 nanoseconds; an FPGA can execute the identical logic in 100 nanoseconds 5. Furthermore, empirical evidence demonstrates that marginal speed improvements directly correlate with profitability; one quantitative firm documented a $2.3 million quarterly revenue increase resulting from a 3-nanosecond optimization in their trading architecture 5. Consequently, an LLM operating in a Python environment on a cloud GPU cluster is fundamentally incompatible with the physical realities of order book interaction.
Exchange Matching Engine Benchmarks
The underlying exchange infrastructure further defines the baseline execution speed. Matching engines - the central software processing incoming orders - have evolved to operate with near-zero latency. For example, in 2010, the Singapore Exchange (SGX) launched the "Reach" trading engine, utilizing InfiniBand switches and kernel bypass software (VMA Message Accelerator) to achieve an average order response time of less than 90 microseconds door-to-door 6.
Exchanges continuously upgrade infrastructure to accommodate rising trading volumes and complex risk management without degrading latency. SGX is currently developing its next-generation engine, Iris-ST, slated for the second half of 2027 78. Iris-ST will introduce advanced pre-trade risk controls (PTRC) and enhanced auction price collars 89. The implementation of PTRC systems within the matching engine places rigorous demands on institutional participants to maintain corresponding low-latency pre-execution checks on their own dedicated gateways 710.
In broader equity markets, the Securities Information Processors (SIP) exhibit reporting latencies averaging 1.13 milliseconds for quotes and 22.84 milliseconds for trades 11. While this represents the public data feed, institutional traders rely on direct exchange feeds to calculate the National Best Bid and Offer (NBBO) locally, bypassing SIP latency to exploit price dislocations that last an average of 1.5 milliseconds 11. Any execution logic requiring longer than 1.5 milliseconds is systematically vulnerable to adverse selection.
Information Half-Life and Alpha Persistence
Every trading signal possesses an information half-life - the duration required for the signal's predictive power to decay by 50% 12. The mathematical persistence of a signal determines the maximum allowable latency between signal generation and order execution.
If an alpha signal $x_t$ follows an autoregressive process $AR(1)$, its autocorrelation decays exponentially. The half-life $T_{1/2}$ dictates the operational horizon. Microstructure imbalances, such as queue positioning, order book pressure, or order flow toxicity, have half-lives measured in milliseconds or microseconds 1213. Attempting to trade these signals using an inference engine that takes 500 milliseconds to process data results in executing on stale information.
Conversely, statistical arbitrage operates on a slightly longer horizon, ranging from minutes to weeks 14. While StatArb models capture mean-reversion or momentum across a basket of correlated assets, they still rely on low-latency infrastructure to execute trades efficiently and avoid execution slippage 1415. Macroeconomic shifts, structural corporate events, and broad social sentiment exhibit much longer half-lives. Research indicates that sentiment shocks transmitted via news or social media propagate into stock prices within an hour and remain economically relevant for up to 33 hours 16. This extended persistence creates a viable window for slower, computationally intensive models like LLMs to process unstructured data and generate profitable signals, provided those signals are not deployed for sub-second execution 1217.
Large Language Model Inference Mechanics and Bottlenecks
To understand why LLMs are confined to asynchronous roles, one must examine the computational bottlenecks inherent to the transformer architecture during inference. Unlike model training, which is highly parallelizable and heavily compute-bound, autoregressive inference is sequential and severely memory-bound 1819.
The Prefill and Decode Phases
LLM inference fundamentally consists of two distinct phases: prefill and decode 202122.
- The Prefill Phase: The model processes the entire input prompt simultaneously. It maps input tokens to dense embeddings, computes self-attention queries, keys, and values (Q, K, V) via dense matrix multiplications, and produces the first predicted output token 2122. Because all input tokens are processed in parallel, the prefill phase efficiently saturates GPU compute cores. It is a compute-bound operation characterized by high latency but maximum throughput 202123.
- The Decode Phase: The model utilizes the output token from the prefill phase to auto-regressively generate subsequent tokens, one at a time. Each new token requires a full forward pass through the network. To avoid recalculating the attention scores for all previous tokens, the model relies on the KV Cache - a mechanism that stores pre-computed Key and Value vectors in memory 222324.
The decode phase is strictly memory-bound 2125. Generating a single token requires transferring the entire multi-gigabyte weight matrix of the LLM from High Bandwidth Memory (HBM) to the processor's Static Random-Access Memory (SRAM) for every step. The arithmetic intensity (the ratio of floating-point operations to bytes transferred) during decoding is exceptionally low 2526. Using the Roofline model, engineers calculate that if a system cannot execute a sufficient number of operations per byte of memory accessed (e.g., ~208 operations per byte on specific hardware), the compute cores remain idle waiting for data 1825.
Compute-Bound versus Memory-Bound Limitations
For real-time trading, both Time-To-First-Token (TTFT) and Time-Per-Output-Token (TPOT) must be aggressively minimized 18. TTFT is dictated by the compute capacity of the hardware during the prefill phase, whereas TPOT is limited by the memory bandwidth during the decode phase 1822.
In traditional software systems, latency is reduced by processing single requests immediately (batch size of 1). However, in LLM inference, serving a batch size of 1 severely underutilizes the GPU's compute capability because the system remains throttled by memory bandwidth 1927. Conversely, grouping multiple requests into large batches increases overall system throughput (tokens per second) but degrades the latency for individual users as resources are divided 2028.
Furthermore, batching multiple requests leads to an interleaving of prefill and decode iterations, resulting in "pipeline bubbles" where the GPU sits idle during setup and teardown periods between kernel launches 2027. This inherent trade-off prohibits the use of standard LLM serving architectures for latency-sensitive trading execution.
Disaggregated Inference and Algorithmic Parallelism
To circumvent the conflicting requirements of the prefill and decode phases, modern inference architectures utilize "disaggregated inference." This distributed systems approach decouples the prefill and decode workloads, assigning them to physically separate GPU clusters 222428. A prefill worker exclusively handles prompt processing and computes the KV cache, which is then transmitted over high-speed networks (e.g., via RDMA) to a decode worker optimized for memory-bound token generation 2426.
While disaggregation improves cluster-level Service Level Agreements (SLAs) and reduces inter-request interference, it introduces a new variable: KV cache transfer latency across the network 26. Innovations in inference scheduling, such as Sarathi-Serve, introduce "chunked-prefills" that split prefill requests into equal-sized chunks, creating stall-free schedules that add new requests to a batch without pausing ongoing decodes 2021. Similarly, Shift Parallelism dynamically switches between Tensor Parallelism (optimizing latency) and Sequence Parallelism (optimizing throughput while maintaining KV cache invariance), achieving up to 1.51x faster response times in interactive workloads 2429. Despite these profound software-level optimizations, baseline latencies remain anchored in the hundreds of milliseconds 2930.
Hardware Architectures for Artificial Intelligence Inference
The pursuit of lower latency has spurred rapid evolution in specialized silicon. The hardware layer remains the ultimate constraint on the speed of LLM execution, necessitating a shift from general-purpose GPUs to memory-bandwidth-optimized architectures.
Datacenter Graphics Processing Units
Graphics Processing Units achieve high throughput through complex thread scheduling and deep memory hierarchies, which inherently introduce variable latency and jitter 3132. LLM inference performance is deeply tied to the generation of the GPU.
The NVIDIA H100 provides a peak memory bandwidth of ~3.3 TB/s and significant FLOP increases over its predecessor, the A100 2733. However, the H200 was designed specifically to address memory-bound bottlenecks, offering 4.8 TB/s of bandwidth, which translates to substantially higher token throughput and lower latency for large models 3435. The most recent generation, the NVIDIA B200 (Blackwell), provides 8.0 TB/s of memory bandwidth and 2,500 TFLOPS, relying heavily on FP4 precision formats to reduce the model footprint and accelerate matrix operations 3335. Benchmarks demonstrate the B200 delivering up to 4.9x the throughput of older workstation GPUs and significantly outperforming the H100 in Time-To-First-Token metrics 3536.
| Hardware Platform | Architecture Focus | Peak Memory Bandwidth | Throughput (Llama 3.1 8B) | Time-To-First-Token (TTFT) | Primary Latency Bottleneck |
|---|---|---|---|---|---|
| NVIDIA A100 | General Training & Inference | ~2.0 TB/s | ~70 tokens/s | ~420 ms | HBM Fetch / Memory Bound |
| NVIDIA H100 | Advanced Inference & FLOPs | ~3.3 TB/s | ~130 tokens/s | ~280 ms | Memory Bandwidth (Decode) |
| NVIDIA H200 | Memory-Optimized Inference | ~4.8 TB/s | ~270 tokens/s | ~200 ms | Inter-token communication |
| NVIDIA B200 (Blackwell) | Next-Gen Extreme Throughput | ~8.0 TB/s | ~500+ tokens/s | < 150 ms | Thermal constraints / Bus limits |
| Groq LPU | Inference-Specific Deterministic | ~80 TB/s (SRAM) | ~750 tokens/s | ~80 ms | On-chip SRAM Capacity |
Table 1: Comparison of state-of-the-art inference hardware, demonstrating the shift from general-purpose GPUs to memory-bandwidth-optimized architectures. 31333537.
Deterministic Language Processing Units
In contrast to the GPU paradigm, Groq's Language Processing Unit (LPU) abandons HBM entirely, relying instead on hundreds of megabytes of on-chip SRAM 3132. SRAM access is approximately 20 times faster than HBM, effectively eliminating the memory bottleneck of the decode phase 31. The LPU compiler operates deterministically, predicting exactly when data will arrive at each computation stage without hardware-level dynamic scheduling 3132.
To run large models, LPUs utilize tensor parallelism across hundreds of chips, synchronized by a plesiosynchronous protocol that cancels natural clock drift 31. Benchmark testing reveals the massive speed advantage of this architecture. Running a Llama 3.1 8B model, the Groq LPU achieves a TTFT of 80 milliseconds and a sustained throughput of 750 tokens per second 3137. An NVIDIA H100 running the same model achieves a TTFT of 280 milliseconds and 130 tokens per second 3137.
While an 80-millisecond response time is transformative for conversational AI or complex reasoning agents, it remains 80,000 microseconds - nearly 1,000 times slower than the 90-microsecond latency of an exchange matching engine 637.
Small Language Models in Financial Contexts
The strict correlation between model parameter scale and inference latency has driven the quantitative finance industry toward Small Language Models (SLMs) for targeted processing tasks 3839. SLMs are generally defined as models containing between 1 billion and 15 billion parameters, in contrast to frontier LLMs that scale into the hundreds of billions or trillions of parameters 3840.
Parameter Scale and Edge Deployment
Models such as Meta's Llama 3 8B, Microsoft's Phi-4-mini, and Mistral Small 3 offer superior token efficiency and faster throughput than their larger counterparts 384142. Because they require vastly less VRAM, SLMs can often be deployed on single GPUs or edge devices, mitigating the need for complex Tensor Parallelism across multiple nodes 3942. This lack of fragmentation eliminates inter-GPU communication overhead, further reducing latency 42.
Furthermore, the economic viability of applying generative models to millions of financial data points hinges on token pricing. Cloud-hosted frontier models can cost between $2.50 and $15.00 per million output tokens, whereas deploying open-weight SLMs on optimized infrastructure reduces costs to between $0.05 and $0.50 per million tokens 303741. In environments requiring real-time parsing of global news feeds and social media, SLMs provide the necessary cost-efficiency.
Economic and Latency Trade-Offs
Despite their speed, SLMs represent a compromise in generalized reasoning capacity. A 100B+ parameter model excels at broad reasoning, resolving ambiguous queries, and zero-shot knowledge retrieval 3038. SLMs, however, are highly susceptible to performance degradation when forced outside their narrow training distributions 30.
In a quantitative finance pipeline, SLMs are primarily utilized as fine-tuned classification engines rather than open-ended reasoning agents. By fine-tuning a 3B to 8B parameter model exclusively on corporate earnings transcripts or SEC filings, firms achieve high-precision sentiment extraction or event classification with latency footprints under 100 milliseconds 414243.
Conversely, relying on large, multi-agent frameworks for real-time decisions introduces unacceptable overhead. For example, the TradingAgents framework utilizes ensembles of specialized agents (Fundamental, Sentiment, Technical, and Risk) engaging in structured debate to synthesize a trading decision 44. While this achieves high Sharpe ratios in short-term tests, it incurs substantial latency overhead, requiring over 11 distinct LLM API calls and 20 tool executions per decision, completely disqualifying it from latency-sensitive deployment 44.
Moreover, LLMs struggle with direct numerical execution. Evaluating 40 LLMs using the FinMathBench dataset revealed that performance on complex, multi-formula questions degrades drastically - for instance, GPT-4o accuracy dropped from 72.9% on single-formula questions to 14.0% on multi-formula questions, demonstrating a critical flaw in direct calculation capabilities 45. Consequently, SLMs narrow the latency gap for natural language processing, but they do not bridge it for mathematical execution. They remain suitable for updating asynchronous state variables but strictly unsuitable for synchronous order routing.
| Capability Metric | Small Language Models (1B - 15B) | Large Language Models (100B+) |
|---|---|---|
| Inference Latency (Single Node) | 10ms - 100ms | 300ms - 2000ms+ |
| Hardware Requirement | Single Consumer/Datacenter GPU | Multi-GPU Cluster (H100/B200) |
| Inference Cost (per 1M Tokens) | ~$0.05 - $0.50 | ~$2.50 - $15.00 |
| Optimal Financial Use Case | Dedicated sentiment classification, log parsing | Complex thesis generation, macro-economic reasoning |
| Execution Path Viability | Near-real-time state updates | Asynchronous portfolio planning |
Table 2: Comparison of Small versus Large Language Models, demonstrating the latency and cost advantages of SLMs for structured financial tasks. 303841.
Field-Programmable Gate Arrays and Transformer Deployment
For a machine learning model to directly participate in high-frequency execution or latency arbitrage, it must be deployed on a Field-Programmable Gate Array (FPGA). FPGAs provide the deterministic, hard-wired execution required to achieve sub-microsecond response times, avoiding the variable latency spikes associated with CPU-based inference frameworks like LightGBM or Intel oneDAL 546. The contemporary frontier of financial engineering involves porting the core mathematical innovations of transformer architectures - specifically the multi-head attention mechanism - onto FPGAs 4748.
Hardware Description Language Translation
Deploying a multi-billion parameter LLM on an FPGA is physically impossible due to severe constraints on on-chip memory (Block RAM and UltraRAM) and Digital Signal Processing (DSP) slices 4849. However, researchers have successfully deployed tiny transformers (compact encoder-only architectures) onto FPGAs to achieve unprecedented speeds.
Tools such as hls4ml (High-Level Synthesis for Machine Learning) allow developers to translate models built in TensorFlow or Keras directly into Hardware Description Languages (HDL) like VHDL or Verilog 474850. This automated conversion framework bypasses CPU and GPU instruction sets entirely, laying out the neural network as a physical digital circuit.
Recent applications originating in high-energy physics - specifically for jet tagging at the CERN Large Hadron Collider - demonstrate the efficacy of this approach. Researchers successfully implemented a transformer model on an FPGA achieving $\mathcal{O}(100)$ nanosecond latency, enabling real-time analysis of vast data streams 4950.
Sub-Microsecond Attention Mechanisms and Quantization
In algorithmic trading contexts, specialized machine learning inference frameworks have brought these capabilities to the data center. Frameworks like Xelera Silva, running on high-end Intel FPGA servers (e.g., ICC VEGA with Core i9-14900KS processors), have achieved single-digit microsecond median latencies of roughly 1.128 microseconds for small models, with 99th percentile latencies under 1.4 microseconds 46. For embedded or low-power applications, AMD Spartan-7 FPGAs can run integer-only transformer inferences at 0.033 mJ of energy consumption 48.
Achieving sub-microsecond latency requires aggressive model compression. High-granularity quantization reduces the standard 32-bit floating-point (FP32) or 16-bit brain-float (BF16) weights down to 8-bit or even 4-bit integer representations 324849. While quantization-aware training ensures the model retains statistical accuracy despite the reduced precision 48, these FPGA deployments are fundamentally distinct from generative LLMs. They are narrow, task-specific neural networks structured around the attention mechanism, utilized exclusively to evaluate numerical order book microstructure or pre-processed technical indicators. They cannot process raw text, parse SEC filings, or analyze news sentiment 4849. Thus, while the transformer architecture can be heavily modified to meet HFT latency budgets, generative Large Language Models cannot.
Hybrid Trading Architectures and Asynchronous Signal Generation
Given the unyielding physical limitations of computing hardware, quantitative trading firms have adopted hybrid artificial intelligence architectures. These frameworks structurally separate the tasks that require deep semantic understanding (assigned to LLMs) from the tasks that require sub-millisecond reactions (assigned to deterministic execution engines) 5152.
Decoupling Sentiment Analysis from Order Routing
In a hybrid architecture, the LLM operates asynchronously, entirely outside the critical execution path 515354. As financial news, regulatory filings, and social media data streams enter the system, they are routed to a natural language processing pipeline. High-throughput encoder models (e.g., FinBERT) serve as a frontline filter, screening millions of data points to identify relevant events 4455.
For example, a "Data Funnel" architecture leveraging FinBERT's high throughput combined with Google Gemini's contextual reasoning processed over 9,000,000 data points to extract high-conviction signals 55. When applied to a dollar-neutral long/short framework, this methodology demonstrated a mean excess return of 51.02% per annum, with a Sharpe ratio of 1.06 and a Sortino ratio of 2.61, indicating a highly positive skewness that captures upside volatility while limiting downside risk 55.
The output of the LLM pipeline is not a discrete trade order; it is a continuously updating state variable - a "sentiment signal" or a "regime classification" (e.g., bullish, bearish, high-volatility) 175152. This signal represents the LLM's assessment of the overarching market context and is stored in a shared memory database accessible by the execution engine 4451.

Historical State Reconstruction and Retrieval Latency
To ensure that hybrid models do not suffer from look-ahead bias during backtesting and to minimize latency during live execution, advanced data structures are employed. Traditional Retrieval-Augmented Generation (RAG) introduces massive latency overheads when querying large vector databases. To mitigate this, frameworks utilizing Just-in-Time Historical State Reconstruction (HSTR) transform unstructured financial retrieval into a deterministic state query 44. By employing a bitemporal data structure, HSTR ensures temporal integrity, reducing context retrieval latency by over 97% compared to traditional RAG baselines while maintaining a 300:1 compression ratio for financial health data 44.
Reinforcement Learning and Adaptive Execution
The synchronous execution engine - often written in C++ or executing via an FPGA - operates independently at the tick level 5154. It continuously monitors real-time market data, technical indicators (e.g., Moving Average Convergence Divergence, Relative Strength Index), and order book depth 5152. Crucially, the execution engine continuously reads the asynchronous state variable generated by the LLM without blocking to wait for the LLM's next inference.
To dynamically bridge LLM sentiment with technical execution, many firms deploy Deep Reinforcement Learning (DRL) agents 565758. A DRL agent can be trained to observe complex states comprising both microstructural features (order book depth) and the semantic embeddings or sentiment scores output by an LLM 5657.
The integration of reinforcement learning solves the translation problem between natural language understanding and algorithmic trading execution 5658. The LLM comprehends that an earnings report is structurally positive but contextually disappointing relative to whisper numbers; the RL agent learns how to size the position and navigate the resulting order book volatility to minimize execution costs 5158. By relying on the RL agent for the immediate mechanical response, the system maintains robustness against latency. The RL policy evaluates market conditions in microseconds, adjusting limit orders to prevent adverse selection, while the LLM re-evaluates the broader narrative asynchronously in the background 535659.
Conclusion
The pursuit of artificial intelligence in quantitative trading has undeniably shifted toward Large Language Models for their unparalleled ability to extract structured intent from unstructured textual data. However, the physical realities of trading infrastructure dictate that generative LLMs cannot currently, and may never, operate directly within the critical execution path of latency-sensitive strategies.
The autoregressive decoding mechanism of transformer models enforces memory-bound bottlenecks that restrict inference speeds to the millisecond domain, even on cutting-edge hardware like the NVIDIA Blackwell architecture or specialized Groq Language Processing Units. In a market where exchange matching engines and High-Frequency Trading networks operate in nanoseconds and microseconds, a millisecond delay guarantees catastrophic adverse selection and stale quote execution.
To circumvent these latency constraints, modern financial engineering relies on asynchronous hybrid architectures. By deploying LLMs as continuous, background state-generators - often utilizing heavily quantized, domain-specific Small Language Models to reduce compute overhead and API costs - firms can extract semantic alpha without sacrificing execution speed. The actual routing of orders is subsequently left to deterministic, low-latency systems such as FPGA-accelerated rule engines or tick-level Deep Reinforcement Learning agents. This architectural decoupling ensures that the strategic foresight of the language model is executed with the mechanical precision required to survive in live trading environments.