Data leakage and look-ahead bias in machine-learning trading
Mechanisms of Information Leakage
Data leakage represents a profound methodological failure in the development of financial machine learning models. In statistical learning theory, leakage occurs when a predictive model inadvertently accesses information during its training or validation phases that would remain strictly unavailable at the exact timestamp of inference in a live production environment 1. Unlike disciplines such as natural language processing or computer vision, where data points are frequently independent and identically distributed (IID), financial time series are defined by deep serial correlation, macroeconomic regime dependence, and structural non-stationarity 23. In these low signal-to-noise environments, complex algorithms act as universal approximators that will aggressively optimize toward any leaked future information, yielding artificially inflated out-of-sample performance metrics that inevitably collapse upon real-world deployment 45.
The mechanisms of information leakage can be deconstructed into several distinct typologies, each requiring specific architectural interventions to mitigate. The most direct forms involve target leakage and feature contamination. Target leakage occurs when the target variable is derived using the exact features it is meant to predict, or when future observations of the target are embedded into the predictor matrix 6. For example, if a dataset is first clustered using all available features, and the resulting cluster identities are subsequently utilized as target labels for a classification algorithm, the supervised model will trivially reverse-engineer the clustering process, achieving near-perfect cross-validation accuracy 67.
Feature contamination, conversely, involves the utilization of explanatory variables that undergo retroactive revision. A pervasive example in macroeconomic forecasting is the reliance on finalized, revised economic indicators rather than point-in-time, preliminary releases. If a quantitative pipeline trains on the revised gross domestic product or inflation prints, it trains on an anachronism. At the actual time of execution, the algorithmic system would only possess the preliminary estimates, which often differ significantly from the finalized data published months later 18.
Temporal Contamination in Feature Engineering
Temporal leakage is uniquely insidious within financial machine learning because it frequently manifests during standard data preprocessing operations, long before model training commences. The application of full-sample normalization techniques, such as full-sample z-score standardization or Principal Component Analysis (PCA) over the entirety of a dataset, systematically injects future information into historical observations 4.
When a time series is scaled utilizing a mean and variance derived from the complete historical dataset, the statistical parameters of the future leak backward. For instance, if an unprecedented volatility spike or price maximum occurs in the final year of a ten-year sample, full-sample z-score scaling will compress the standardized values of the preceding nine years based on that future maximum 48. Models containing non-linear activation functions (such as the Rectified Linear Unit in deep neural networks) or hierarchical split thresholds (such as decision trees) will optimize their parameters according to a global distribution shape that was fundamentally unknowable at the time of the historical prediction 4.
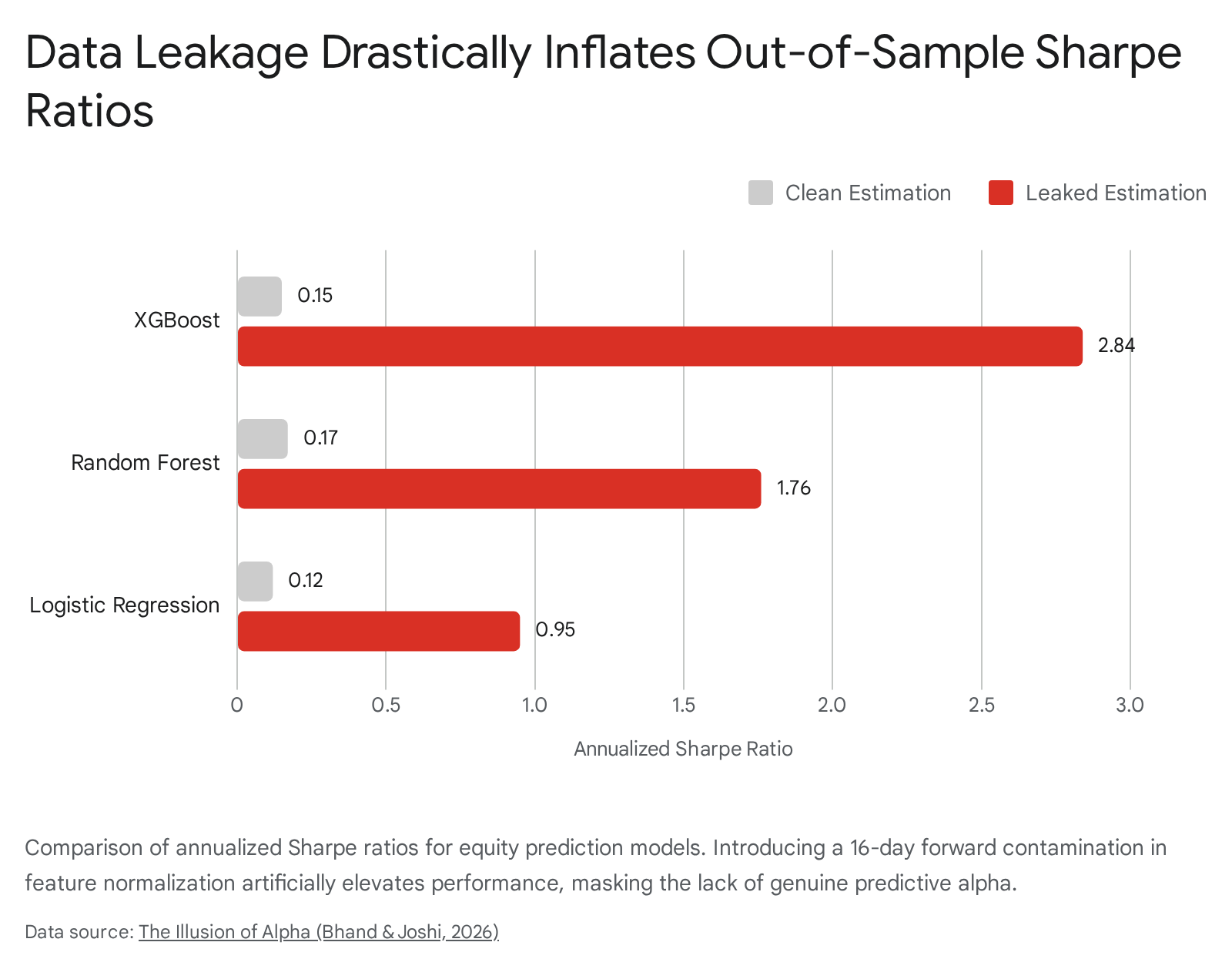
Empirical research evaluating long-short equity prediction models on a synthetic panel of 30 stocks demonstrates the severity of this preprocessing error. When a 16-day forward contamination was introduced via rolling feature normalization, the annualized Sharpe ratio of an XGBoost classifier was artificially inflated from a baseline of 0.15 under clean estimation to an extraordinary 2.84 under leaked estimation 4. The inflation is particularly severe in tree-based ensemble methods because gradient boosting algorithms aggressively exploit the precise numeric thresholds generated by the contaminated scaling parameters 4.
Cross-Sectional Leakage and Universe Selection
Cross-sectional leakage emerges when the universe of tradable assets utilized for model training is defined using ex-post criteria, generating severe survivorship bias. This occurs routinely when an algorithm is trained and evaluated exclusively on the contemporary constituents of a major index, such as the S&P 500 or the Russell 3000, retroactively applied to historical market periods 49.
By definition, the current constituents of an equity index have survived periods of economic contraction, avoided bankruptcy, and maintained sufficient market capitalization to retain their inclusion status. When a machine learning model is trained on this retroactive subset, it is artificially shielded from the asset trajectories that ended in catastrophic decline or delisting during the historical training window 49. Consequently, the algorithm learns parameters optimized for historical winners, frequently identifying mean-reverting patterns that appear highly profitable in backtests but fail in live trading because the model never learned to identify structural bankruptcy risks.
Mitigating cross-sectional leakage requires the implementation of strict Point-in-Time (PIT) databases. A PIT architecture ensures that the asset cross-section evaluated on any given historical day perfectly matches the index composition and availability as it existed on that exact date, preserving the original unrevised data and logging the precise timestamps of inclusion and exclusion 411.
Microstructure Vulnerabilities and Upstream Contamination
Beyond preprocessing and universe selection, advanced quantitative pipelines introduce sophisticated vectors for look-ahead bias at the intersection of market microstructure rules and computational execution. One of the most mechanically complex forms of data leakage is observed in rolling-window factor pipelines, specifically identified as "upstream contamination" 12.
This phenomenon is highly pervasive in markets governed by strict regulatory circuit breakers, such as the Chinese A-share market. In this environment, equities are subject to daily price-move limits, generally constrained to ±10% on the main board and ±20% on the STAR and ChiNext boards 12. When an equity hits its upper price limit, it essentially ceases to be executable for prospective buyers, as liquidity vanishes on the ask side.
However, standard data engineering implementations frequently ingest these non-tradable closing prices and compute complex rolling aggregates - such as 20-day moving averages, price-volume correlations, and cross-sectional momentum ranks - before any tradability filters are applied 12. If a post-hoc row-filtering operation is deployed at the terminal assessment stage to remove non-executable trades, the systemic damage remains uncorrected. The non-tradable limit-up price has already been absorbed into the rolling mean, which in turn contaminates the correlation matrix, thereby altering the cross-sectional ranking of every other stock in the universe 12.
The machine learning model inadvertently learns to predict theoretical price movements that the portfolio manager can never actually execute in the market. On empirical A-share datasets, ignoring upstream contamination inflates the apparent Information Coefficient (IC) by 18%, while simultaneously reducing the realized Sharpe ratio by 0.44 points, as the strategy attempts to allocate capital toward inaccessible assets 12.
Mask-First Design Patterns
To eradicate upstream contamination, quantitative software engineers must adopt a "mask-first" design pattern. Under this paradigm, a Boolean tradability mask is constructed during the initial data loading phase. This mask explicitly flags non-executable intervals, including limit-up days, regulatory trading halts, or periods of extreme illiquidity 12.
Crucially, this Boolean mask is threaded sequentially through every mathematical operator in the pipeline. By zeroing out or nullifying the non-tradable values before any aggregation occurs, the rolling windows and cross-sectional ranking algorithms process exclusively the liquid, executable market reality 12. This engineering standard ensures that the terminal boundary assessment evaluates a structurally sound trading signal, rather than attempting to filter a deeply corrupted computational aggregate.
Architectural Vulnerabilities in Sequence Modeling
The integration of deep learning architectures into financial time-series forecasting has introduced a novel category of algorithmic data leakage. Recurrent architectures, including Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), inherently process data in a sequential manner, naturally maintaining directional temporal dependencies and mitigating forward-looking bias through their internal state mechanisms 101415.
Conversely, modern Transformer architectures - such as the Temporal Fusion Transformer (TFT) or the Informer - were initially theorized and optimized for natural language processing. In linguistic tasks, bidirectional context is highly advantageous, allowing the model to comprehend a word based on both its preceding and subsequent syntax 1112. When applied natively to financial sequence modeling, allowing bidirectional self-attention permits the model to map future market states backward into its historical context 11. The core self-attention mechanism computes pairwise interactions between all elements in a sequence simultaneously, meaning it lacks an intrinsic mathematical understanding of the arrow of time 813.
Causal Masking in Transformers
To enforce temporal strictness and prevent look-ahead bias, financial Transformers require the implementation of causal masking. This is typically executed mathematically via an upper-triangular mask applied directly to the attention weight matrix 1114. The causal mask strictly zeroes out the attention weights assigned to any future timestep ($>t$), forcing the neural network to generate predictive distributions for $t+1$ utilizing strictly the subset of observations $\le t$ 1420. In the absence of explicit causal constraints, attention-based models allow earlier time steps to attend to later observations within the same historical training window, severely degrading out-of-sample generalization 20.
Positional Encoding and Regime Leakage
Furthermore, Transformers rely heavily on positional encodings to inject sequence order information into the input embeddings, overcoming the permutation invariance of the self-attention mechanism 15. While deterministic sinusoidal encodings are common, financial implementations frequently utilize learned positional embeddings to capture cyclical market patterns 1617.
If these positional representations are exposed to the entire time series during initialization, or if they are applied without strict walk-forward boundaries, the model can inadvertently extract structural hints regarding the timing of regime changes or volatility spikes 24. For instance, providing a Transformer with positional encodings based on the signed business-day distance to future Federal Open Market Committee (FOMC) announcements allows the model to anticipate policy shifts in-context, artificially improving performance metrics via leaked side-information 24.
Entity Embedding Memorization in Large Language Models
Large sequence models and foundational Large Language Models (LLMs) adapted for financial sentiment analysis exhibit a unique form of target leakage driven by parameter memorization. Because these architectures are pre-trained on massive internet-scale corpora that encompass historical stock prices, corporate earnings reports, and retrospective financial news coverage, they naturally memorize specific equity trajectories 25.
During fine-tuning on historical financial classification tasks, these models demonstrate a phenomenon akin to photographic recall. They identify a specific corporate entity through contextual text clues within the prompt, retrieve their internalized knowledge of that firm's historical performance, and output a highly confident prediction 25. This creates a dangerous illusion of sophisticated reasoning, when the model is merely querying its pre-trained internal priors rather than analyzing the provided data. To mitigate this vulnerability, practitioners must enforce "entity embedding neutralization," systematically masking identifiable corporate names, executive identities, and ticker symbols with generic tokens to prevent the model from mapping the input text back to memorized historical outcomes 2526.
Asynchronous Fundamental Data and Reporting Lags
A persistent source of look-ahead bias when synthesizing fundamental accounting data with high-frequency market prices is the improper synchronization of corporate reporting lags. The fiscal quarter-end date represents merely an accounting boundary; the actual financial data is not verified, audited, and disseminated to the market until weeks or months later. Aligning a quantitative trading signal with a fiscal quarter-end date (for example, executing trades based on Q1 earnings data on March 31st) introduces massive temporal leakage, as the model accesses information that was legally and physically unavailable until the corporate filing was published 11.
Global Regulatory Divergence in Filing Deadlines
The assumption of a uniform, fixed lag (such as uniformly shifting all fundamental data forward by 30 days) is statistically insufficient because corporate filing deadlines vary significantly by jurisdiction, market capitalization, and regulatory evolution 1819. A globally deployed machine learning pipeline must dynamically adjust its data ingestion expectations based on the specific regulatory framework governing each asset.
| Jurisdiction / Exchange | Regulatory Framework | Filing Deadline / Baseline Requirement | Pipeline Implications for Look-Ahead Bias |
|---|---|---|---|
| United States (SEC) | Form 10-Q (Quarterly) | 40 days (Large Accelerated Filers), 45 days (Non-Accelerated Filers) after quarter-end 18. | U.S. fundamental pipelines require dynamic lag mapping dependent on individual firm market capitalization classification. |
| United Kingdom | Voluntary Updates | Semi-annual minimum; quarterly trading updates are optional but common 29. | UK pipelines must handle asynchronous, unaudited narrative trading updates alongside formal, audited semi-annual filings. |
| European Union | Transparency Directive | Semi-annual mandatory; mandatory interim management statements were abolished in 2013 2920. | European equities exhibit slower expectation revision cycles; quarterly temporal alignment introduces severe look-ahead bias. |
| Japan (TSE) | Exchange Rule | 45 days after quarter-end; statutory quarterly filings were officially abolished by the FSA in April 2024 292122. | Frequent policy shifts require historical databases to dynamically track regulatory reporting changes across time to prevent leakage. |
| Hong Kong (HKEX) | Main Board Rules | 60 days after half-year end (two months); no mandatory quarterly reporting rule exists for the Main Board 3323. | Prolonged blackout periods compared to U.S. equities; interpolating fundamental data across the gap risks temporal leakage. |
The regulatory landscape governing financial disclosure is highly dynamic, complicating historical backtesting. In the United States, the Securities and Exchange Commission (SEC) has historically mandated quarterly reporting via Form 10-Q 29. However, proposals to introduce Form 10-S, allowing companies to opt for semi-annual reporting, reflect an ongoing debate regarding the costs of high-frequency disclosure 2425.
In contrast, the European Union implemented the Transparency Directive Amendment in 2013, effectively removing the mandate for quarterly interim management statements and transitioning to a semi-annual baseline 2920. Consequently, "quarterly" data in Europe and the UK frequently takes the form of brief, unaudited trading updates rather than comprehensive financial statements 29. Integrating these disparate reporting cadences into a unified machine learning model without introducing look-ahead bias requires sophisticated Point-in-Time architectures that strictly index fundamental features to their exact public dissemination timestamp, rather than their underlying accounting period.
Temporal Validation Frameworks
The fundamental incompatibility between financial market data and the core assumptions of classical machine learning necessitates the deployment of specialized, time-aware validation protocols.
Limitations of Standard Cross-Validation
Standard k-fold cross-validation is the default evaluation mechanism in traditional data science. It randomly partitions a dataset into $k$ equal-sized folds, iterating through the data such that each fold serves as the validation set once while the remaining folds are used for training. This methodology relies entirely on the assumption that the data is Independent and Identically Distributed (IID) 2.
Financial time series exhibit strong serial correlation, volatility clustering, and macroeconomic regime dependence, dictating that observations are neither independent nor identically distributed 23. When standard k-fold cross-validation is applied to financial data, adjacent time steps are frequently allocated to different folds 37. Because market states are highly autoregressive, placing an observation in the validation set while its chronologically adjacent predecessor remains in the training set creates a conduit for information leakage, contaminating the validation phase and resulting in optimistic performance estimates 237.
Walk-Forward and Nested Cross-Validation
To preserve chronological integrity, the quantitative finance industry has historically relied on Walk-Forward (WF) validation 11263927. Walk-forward validation strictly adheres to the arrow of time: an initial historical window is utilized for training, and the immediately subsequent, non-overlapping window is utilized for out-of-sample testing. The window is subsequently rolled forward through the dataset.
While walk-forward evaluation ensures causality, it is subject to severe methodological critiques. Primarily, walk-forward validation evaluates only a single historical path 22627. Because it tests exclusively the specific sequence of events that actually materialized in history, a walk-forward backtest can be easily overfit to the idiosyncratic noise of that unique chronological timeline, failing to prove that the algorithmic strategy is robust to alternative but statistically plausible market scenarios 2627. Furthermore, executing hyperparameter optimization within a standard walk-forward setup can lead to validation leakage if the out-of-sample test performance is iteratively utilized to guide model selection.
To address hyperparameter leakage, practitioners employ Nested Cross-Validation. This architecture systematically separates model evaluation from hyperparameter optimization by constructing an outer loop and an inner loop 1128. The outer loop partitions a chronological fold to serve exclusively as a true, untouched out-of-sample test set. The remaining preceding data is passed to the inner loop, which performs secondary chronological splits to tune hyperparameters and select the optimal model configuration 112628. The test set in the outer loop remains completely isolated from the iterative tuning process, ensuring that the final performance metrics represent a genuine out-of-sample evaluation.
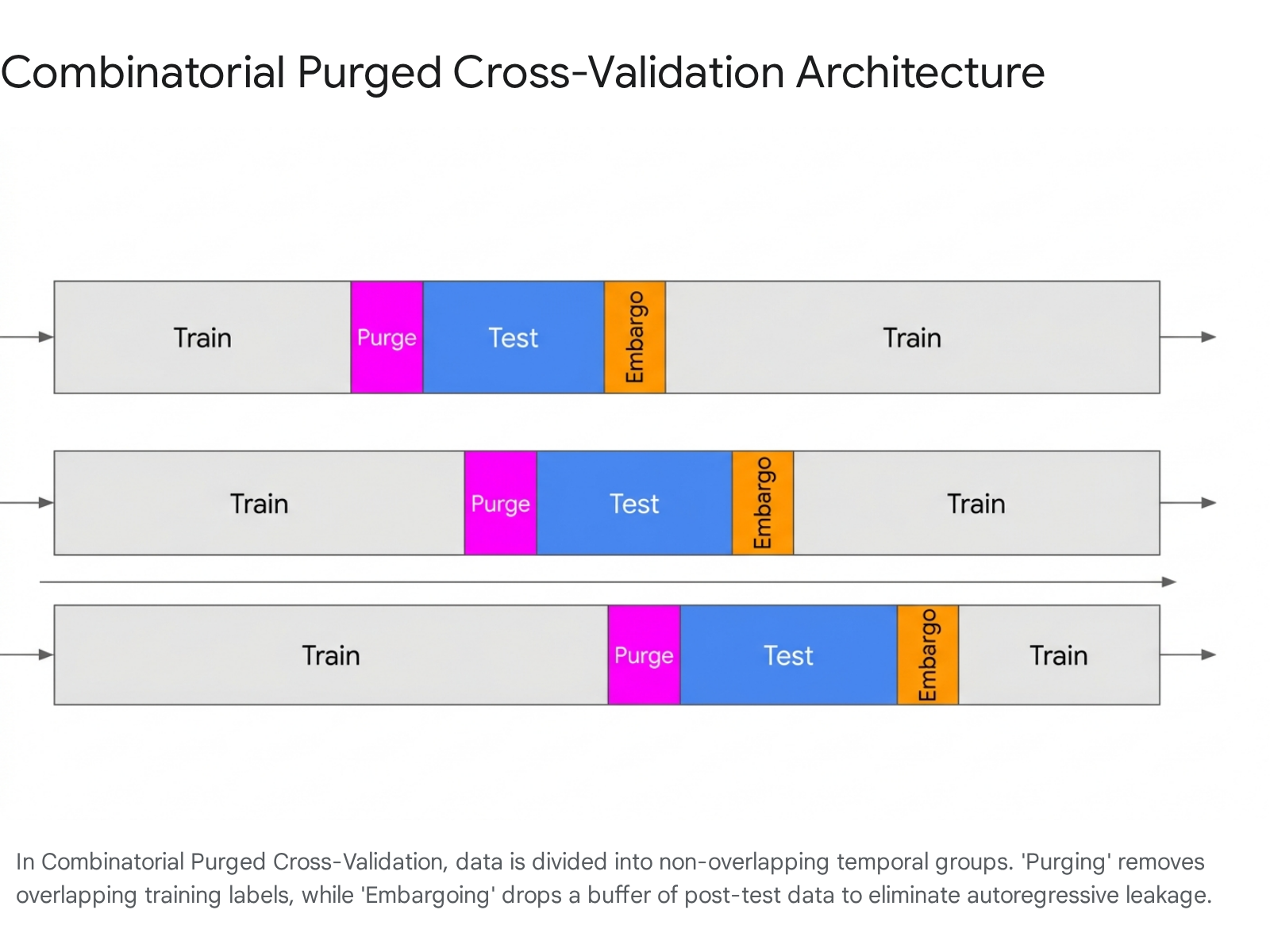
Combinatorial Purged Cross-Validation
To overcome the single-path limitation inherent in walk-forward testing while maintaining the rigorous chronological integrity required for time-series data, quantitative researchers have increasingly adopted Combinatorial Purged Cross-Validation (CPCV) 22943. CPCV is engineered to simulate a multitude of historical scenarios, allowing researchers to derive an empirical distribution of a strategy's performance metrics rather than relying on a fragile single-point estimate 4344.
The CPCV methodology divides the historical dataset into $N$ sequential, non-overlapping groups. For a testing set composed of $k$ groups, the algorithm computes all possible combinatorial partitions of training and testing data 227. Because these permutations frequently place testing folds before or between training folds, two critical mechanisms must be rigorously applied to prevent leakage:
- Purging: Any observation in the training set whose label evaluation period overlaps temporally with any observation in the testing set is entirely excised from the training matrix 272845. This mathematically prevents the model from peeking at future outcomes during the training phase.
- Embargoing: Because financial features (such as fractional differentiation, moving averages, or ARMA processes) exhibit memory, removing overlapping labels is insufficient. An embargo applies a strict time buffer immediately following the testing set, discarding a predetermined window of training data to allow serial correlations to decay completely before training resumes 372745. For example, if utilizing hourly sentiment data to forecast a 4-hour prediction horizon, a purge and embargo window of 24 to 48 hours is necessary to enforce genuine temporal separation 37.
By applying CPCV, quantitative researchers can evaluate strategies across thousands of independent backtest paths. Instead of searching for the parameter combination that yields the highest absolute return - which is highly susceptible to selection bias - CPCV allows practitioners to identify parameter "plateaus" that remain stable and performant across a diverse set of plausible historical trajectories 4346.
However, the CPCV framework involves substantial trade-offs. The aggressive deletion of data points through purging and embargoing reduces the effective sample size, which can degrade the training efficacy of data-hungry deep learning architectures that require vast quantities of data to converge 2843. Furthermore, the complexity of implementing the multi-dimensional indexing required for combinatorial splits creates a high risk of subtle programming errors, potentially reintroducing look-ahead bias in a highly obscured manner 43.
Regime-Aware Validation Methodologies
Even when utilizing rigorous temporal cross-validation, models evaluated over extensive historical horizons may fail due to macroeconomic non-stationarity. Financial markets transition through distinct phases, including volatility regimes, inflationary environments, and liquidity cycles. Evaluating a predictive model's average performance over a continuous ten-year period obscures whether the algorithmic strategy systematically fails during specific market states 3031.
Regime-aware validation frameworks address this deficiency by integrating market state detection directly into the model evaluation pipeline. Utilizing mathematical tools such as rolling Hidden Markov Models (HMM) or threshold segmentations based on the CBOE Volatility Index (VIX), researchers divide the historical timeline into distinct, structurally homogeneous regimes (e.g., bull market expansions, bear market contractions, high-volatility sideways chop) 33031.
Under this framework, predictive performance and portfolio allocation are conditionally evaluated. A regime-aware approach ensures that models optimized for low-volatility expansion periods are not erroneously applied to crisis events, and vice versa 3149. By restricting algorithmic training and validation to structurally similar market states, quantitative pipelines avoid extrapolating parameters derived from uncorrelated noise, providing a higher degree of robustness against future structural breaks in the market 49.
Performance Evaluation and Statistical Inference
The final defensive layer against look-ahead bias and overfitting occurs at the statistical evaluation stage. In quantitative finance, analyzing multiple model configurations, feature sets, and hyperparameters on the same historical dataset inherently introduces multiple testing bias. Given the mathematical realities of probability, if enough random algorithmic strategies are evaluated on a finite dataset, a subset of them will yield statistically significant out-of-sample returns purely by random chance 24332.
Relying on a standard, unadjusted annualized Sharpe ratio is fundamentally inadequate when evaluating machine learning pipelines 2732. To accurately compensate for selection bias, the industry relies on advanced, adjusted metrics, primarily the Probabilistic Sharpe Ratio (PSR) and the Deflated Sharpe Ratio (DSR) 392733.
The Deflated Sharpe Ratio mathematically adjusts the required threshold for statistical significance by explicitly accounting for the non-normality of the underlying return distribution - correcting for empirical skewness and kurtosis - while simultaneously penalizing the final score based on the number of independent trials (backtests) conducted during the model development phase 392732. The larger the hyperparameter grid search or feature selection process, the higher the empirical hurdle rate required to prove that the strategy possesses genuine, durable predictive alpha rather than a spurious correlation 2743.
By coupling the penalty structure of the DSR with the comprehensive output distributions of a Combinatorial Purged Cross-Validation routine, researchers can calculate the Probability of Backtest Overfitting (PBO). The PBO provides a mathematically rigorous estimate of the likelihood that a strategy's observed historical performance is the result of fitting to historical noise rather than capturing a persistent market inefficiency 392733.
Conclusion
The pursuit of algorithmic alpha is uniquely constrained by the low signal-to-noise ratio and fundamental non-stationarity of financial markets. Standard machine learning workflows, predominantly designed for static, independent datasets, routinely fail in quantitative trading because they systematically ignore the arrow of time. Look-ahead bias and data leakage are rarely simple coding errors; they are complex, systemic vulnerabilities embedded within feature scaling, market microstructure limits, asynchronous corporate reporting, and architectural choices like bidirectional attention in Transformers.
Constructing robust quantitative pipelines requires a foundational shift from point-estimate optimization to structural, causal validation. Techniques such as mask-first data engineering, strictly causal Transformer masking, and integration with Point-in-Time data architecture are required to eliminate upstream and temporal leakage at the source. At the evaluation layer, moving beyond Walk-Forward testing to implement Combinatorial Purged Cross-Validation and Regime-Aware frameworks enables the rigorous stress-testing of algorithms against multiple plausible histories while neutralizing serial correlation. Ultimately, mitigating data leakage demands that machine learning systems are governed by stringent statistical corrections like the Deflated Sharpe Ratio, ensuring that apparent predictive power represents an enduring market reality rather than a fragile artifact of contaminated historical data.