Evaluation of Deep Reinforcement Learning for Trading
Financial markets represent one of the most hostile environments for computational models and sequential decision-making. Characterized by severe non-stationarity, extreme signal-to-noise ratios, and the complex interplay of human psychology and multi-agent algorithmic competition, these ecosystems have historically resisted standard supervised machine learning techniques. While supervised models attempt to predict future prices based on historical features - a task prone to catastrophic overfitting - deep reinforcement learning (DRL) operates on a fundamentally different paradigm. By formalizing quantitative trading as a Markov Decision Process (MDP), DRL agents learn to optimize long-term cumulative rewards through direct interaction with historical or simulated market environments, entirely bypassing the need for explicit forecasting labels 12.
Despite the theoretical elegance of this approach, the transition from simulated environments to live capital deployment has exposed profound structural vulnerabilities in the DRL framework. Academic literature is heavily populated with DRL trading models reporting outsized, double-digit risk-adjusted returns. Yet, institutional practitioners and rigorous diagnostic studies report that an overwhelming majority of these strategies - often exceeding 90% - fail precipitously when implemented in live markets 2. This credibility gap is driven by a series of acute methodological pitfalls, including extreme sensitivity to random initialization seeds, chronic overfitting to non-stationary market regimes, and the systemic failure to accurately model market microstructure frictions and execution costs 45.
The maturation of DRL in quantitative finance now hinges on resolving these vulnerabilities. This requires a deep comparative understanding of the foundational algorithmic architectures - specifically Deep Q-Networks (DQN), Advantage Actor-Critic (A2C), and Proximal Policy Optimization (PPO) - alongside the implementation of rigorous, standardized reproducibility protocols.
Algorithmic Architectures in Quantitative Finance
The application of DRL to financial markets typically involves mapping technical indicators, order book dynamics, macroeconomic variables, and current portfolio states into a high-dimensional observation space. The action space dictates the agent's interactions, which may range from discrete buy/hold/sell decisions to continuous portfolio weight allocations. The agent receives a reward signal, frequently defined as a differential Sharpe ratio, Sortino ratio, or utility-adjusted return, which it uses to iteratively update its internal policy or value estimates 2. The mathematical mechanics of this optimization process depend entirely on the chosen algorithmic architecture, leading to vastly different behaviors under market stress.
Value-Based Approaches and Deep Q-Networks
Deep Q-Networks (DQN) represent the foundational value-based approach to deep reinforcement learning. In this architecture, the agent utilizes a deep neural network to estimate the expected cumulative future reward (the Q-value) for every possible discrete action in a given state 67. The agent's policy is implicit; it simply selects the action associated with the highest predicted Q-value.
To stabilize the highly nonlinear process of training a neural network via temporal difference learning, DQN employs two critical innovations: a target network and an experience replay buffer 78. The experience replay buffer stores past transitions (state, action, reward, next state) and samples them randomly in mini-batches during training. This mechanism is particularly critical in financial applications because it breaks the strong temporal autocorrelation inherent in asset price time series, preventing the network from aggressively overfitting to a localized chronological trend 78.
DQN is highly sample-efficient, meaning it can extract a functional trading policy from a relatively limited dataset 79. In empirical studies, such as the comprehensive evaluation conducted by the Oxford-Man Institute of Quantitative Finance across 50 highly liquid futures contracts, DQN models demonstrated the ability to capture large market trends and deliver positive returns despite heavy simulated transaction costs 1. However, DQN is strictly limited to discrete action spaces, making it unsuitable for the continuous allocations required in modern portfolio optimization 710. Furthermore, standard DQN suffers from chronic overestimation bias, where the maximization step in the Q-learning update leads the network to systematically overestimate the value of certain market states - a fatal flaw when interacting with noisy financial data 7.
On-Policy Actor-Critic and Advantage Estimation
To overcome the limitations of discrete action spaces and implicit policies, the financial industry heavily utilizes actor-critic architectures, specifically the Advantage Actor-Critic (A2C) algorithm. A2C maintains two separate neural networks. The "actor" directly parameterizes and outputs a probability distribution over continuous or discrete actions (the policy), while the "critic" estimates the value function to evaluate the quality of the actor's choices 611.
The core mathematical innovation of A2C is the computation of the "advantage" - a metric that quantifies how much better an executed action performed relative to the average baseline expectation for that specific market state 1213. By scaling the policy gradient updates by the advantage rather than the raw reward, A2C significantly reduces the variance of the updates, leading to more stable policy convergence 1114.
A2C typically operates synchronously, deploying multiple parallel actor-learners to interact with different segments of the market environment simultaneously, thereby gathering a diverse batch of experiences before updating the global network 711. Because it directly optimizes the policy, A2C naturally accommodates the continuous action spaces required for dynamic, multi-asset portfolio weighting 711. However, A2C is an on-policy algorithm; it discards financial data immediately after computing a gradient update. This renders it highly sample-inefficient compared to DQN 714. Additionally, A2C is acutely sensitive to hyperparameter configurations, particularly the learning rate and entropy coefficients, requiring extensive tuning to balance the trade-off between exploring novel trading strategies and exploiting known profitable behaviors 67.
Proximal Policy Optimization and Surrogate Constraints
Proximal Policy Optimization (PPO) has emerged as the dominant policy-gradient algorithm in both general artificial intelligence and financial research 1115. Built upon the actor-critic framework, PPO addresses the primary vulnerability of standard policy gradient methods: the tendency to enact destructively large policy updates in response to anomalous data 12.
In financial markets, extreme volatility spikes, flash crashes, or idiosyncratic news events generate highly irregular reward signals. If an unconstrained actor-critic algorithm processes this data, it may radically alter its neural network weights, effectively "unlearning" a robust, long-term trading strategy in response to transient noise. PPO solves this by introducing a clipped surrogate objective function 1216. This clipping mechanism strictly limits the ratio between the new policy and the old policy, mathematically constraining the magnitude of any single update 1216.
If an action yields an unexpectedly massive return, the clipping function prevents the agent from overwhelmingly increasing the probability of taking that action in the future. This forces PPO to learn through small, incremental adjustments, yielding exceptional convergence stability 1216. Consequently, PPO is highly robust across complex, continuous financial tasks and requires significantly less hyperparameter tuning than A2C, cementing its status as the default algorithm for institutional DRL deployment 715.
Architectural Trade-Offs in Trading Environments
The selection of a DRL architecture imposes immediate trade-offs regarding stability, data requirements, and risk profiles. Table 1 summarizes the core comparative dimensions of the three foundational algorithms when applied to quantitative trading.
| Algorithm Framework | Action Space Capability | Sample Efficiency | Convergence Stability | Primary Trading Weakness | Risk Management Profile |
|---|---|---|---|---|---|
| Deep Q-Network (DQN) | Strictly Discrete (e.g., Buy, Hold, Sell) | High (Reuses data via experience replay buffer) | Low (Oscillates wildly in non-stationary market regimes) | Overestimation bias and inability to handle continuous portfolio weights 710. | Highly aggressive; susceptible to catastrophic maximum drawdowns 715. |
| Advantage Actor-Critic (A2C) | Discrete and Continuous | Low (Discards data immediately after gradient updates) | Moderate (Reduces variance via advantage, but lacks update constraints) | Extreme sensitivity to hyperparameters, specifically learning rates and entropy 67. | Capable of steady risk-adjusted returns, but vulnerable to high-volatility batches 715. |
| Proximal Policy Optimization (PPO) | Discrete and Continuous | Moderate (Requires extensive interaction but recycles batches via clipping) | High (Clipped surrogate objective prevents catastrophic unlearning) | Can exhibit over-trading tendencies if advantage normalization is poorly calibrated 716. | Highly conservative; exceptional downside protection and low drawdown profiles 715. |
Empirical Performance and Execution Dynamics
The empirical evaluation of DRL algorithms reveals that absolute profitability is an inherently flawed metric if analyzed independently of risk management constraints. The architectural differences between value-based and policy-gradient methods manifest profoundly in their drawdown profiles and out-of-sample execution behavior.
Absolute Returns versus Risk-Adjusted Drawdowns
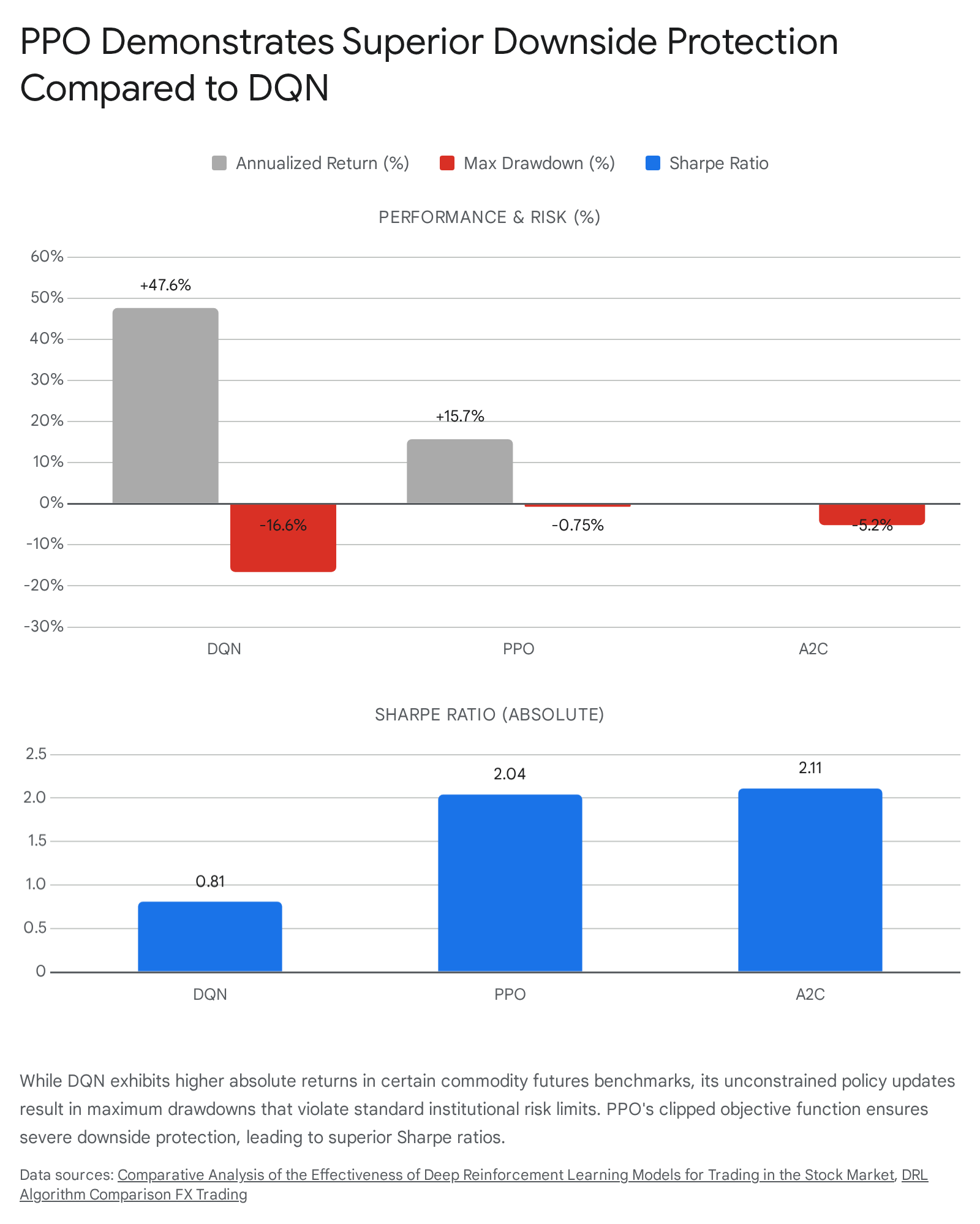
Benchmark studies evaluating DRL performance across various asset classes repeatedly highlight a critical divergence between raw geometric returns and practical institutional viability. In controlled evaluations conducted on commodity futures and foreign exchange markets, DQN algorithms frequently generate exceptional absolute returns during in-sample training and limited out-of-sample testing. In one published benchmark, a DQN agent achieved an annualized return of 47.6%, vastly outperforming a PPO agent which returned 15.7% 15.
However, this raw outperformance masks a catastrophic risk profile that renders the DQN strategy undeployable in a live environment. The maximum drawdown for the DQN agent in this environment reached -16.6%, compared to a minimal -0.75% for PPO and -5.2% for A2C 15. In institutional asset management and proprietary trading firm evaluations, maximum drawdown constraints are absolute limits. A 16.6% peak-to-trough decline would trigger severe margin calls, violate risk limits, and likely result in the immediate termination of the algorithmic trading desk 15.
DQN's vulnerability stems directly from its off-policy nature and unconstrained value-estimation mechanics. Without the mathematical governor of a clipped objective function, a DQN agent can aggressively over-leverage a perceived market pattern. When the market regime inevitably shifts, the highly concentrated strategy collapses, resulting in severe equity curve degradation 715. Conversely, PPO's clipped objective function structurally prevents the agent from abandoning a functional risk-management strategy during an anomalous market event. This forced incrementalism yields a highly stable equity curve. Despite lower absolute returns, PPO achieves a Sharpe ratio of 2.04 in identical environments, far exceeding DQN's 0.81 15.
High-Frequency Trading and Hierarchical Systems
The deployment dynamics of DRL shift significantly when applied to high-frequency trading (HFT), particularly in cryptocurrency markets characterized by extreme minute-to-minute volatility and microstructural fragmentation. Standard DRL agents deployed in HFT environments chronically suffer from severe overfitting; they memorize a highly specific sequence of limit order book states and fail to adapt when the financial context changes 17. Furthermore, because market conditions change rapidly, investment decisions made by an individual, monolithic agent tend to become highly biased, leading to significant losses during flash crashes or sudden momentum reversals 173.
To address this, researchers have developed Memory Augmented Context-aware Reinforcement Learning (MacroHFT) frameworks 17. These systems abandon the concept of a single trading agent. Instead, they deploy a hierarchical architecture that operates in two phases. First, the cryptocurrency market is algorithmically decomposed into discrete categories based on granular trend and volatility indicators 34. Multiple distinct "sub-agents" are then trained exclusively on specific market dynamics (e.g., one agent trained solely on high-volatility downtrends, another on low-volatility consolidation). Each sub-agent is equipped with a conditional adapter to adjust its policy based on micro-shifts within its domain 173.
In the second phase, a "hyper-agent" is trained to act as a meta-policy router. The hyper-agent observes the macro market context, assesses the historical reliability of each sub-agent under the current conditions, and dynamically mixes their decisions to execute the final trade 34. Augmented by an advanced memory mechanism, this hierarchical approach drastically reduces the risk of single-agent overfitting and provides consistent profitability across minute-level trading tasks, effectively insulating the strategy from abrupt regime shifts 174.
The Frontier of Alpha Generation and Model Complexity
Beyond optimal execution and portfolio weighting, the true frontier of financial machine learning involves utilizing DRL for "alpha generation" - the autonomous discovery of novel, uncorrelated mathematical signals that predict future price movements. This domain is currently the subject of intense institutional investment and fierce academic debate.
Agentic Systems and Autonomous Signal Discovery
Historically, the generation of formulaic alphas relied on the intuition of human quantitative analysts, who would hypothesize relationships, combine data streams, and rigorously backtest the resulting mathematical expressions. When firms attempted to automate this discovery process, they traditionally relied on Genetic Programming (GP) 2021. GP algorithms operate by mutating and crossing over populations of mathematical trees. However, GP is fundamentally limited by its extreme sensitivity to the initial random population, slow computational convergence, and a high propensity to stall at local optima without discovering genuinely synergistic signals 2021.
Deep reinforcement learning has revolutionized this process by reconceptualizing alpha mining as a sequential program construction task. Frameworks such as AlphaGen, AlphaQCM, and Alpha2 treat the search for synergistic formulaic alphas as an advanced Markov Decision Process 202122. The DRL agent navigates a vast, high-dimensional search space of primitive mathematical operators and financial data streams. Driven by a carefully designed reward function that evaluates potential alpha outcomes, the agent iteratively constructs logical programs 2021. To prevent the generation of mathematically absurd expressions, these frameworks incorporate pre-calculation dimensional analysis, ensuring logical soundness and drastically pruning the search space 2021. Furthermore, the objective function explicitly penalizes high correlation between generated signals, forcing the agent to explore diverse avenues of the market rather than generating hundreds of redundant momentum variations 205.
This paradigm shift is rapidly moving from academic research into live institutional deployment. In 2025, Man Group, the world's largest publicly listed hedge fund, announced the deployment of "AlphaGPT," an agentic AI system designed to autonomously mine historical data, formulate rule-based trading signals, write the corresponding execution code in C++ or Python, and evaluate performance through continuous backtesting 2425. The system mimics the exact workflow of human quant researchers but operates at a scale, breadth, and speed that manual analysis cannot match, marking the arrival of fully autonomous research pipelines in top-tier asset management 2425.
The Virtue of Complexity Debate
The integration of massively parameterized machine learning models into alpha generation has ignited a profound ideological conflict within the quantitative finance community regarding model complexity. For decades, quantitative modeling operated under the strict principle of parsimony - the conviction that simpler models, constrained to a few highly intuitive variables (e.g., the Fama-French factors), are fundamentally more robust and less prone to capturing the pervasive noise of financial markets 266.
This established orthodoxy was directly challenged by researchers from AQR Capital Management and Yale University, who published highly controversial findings asserting a "Virtue of Complexity" in return prediction 6729. The authors argued that the industry's preference for simple models actively understates market predictability and leaves substantial performance uncaptured 630. By feeding 15 standard financial variables through randomized non-linear transformations (Random Fourier Features) to generate tens of thousands of derived features, their neural network - comprising roughly 12,000 parameters - drastically outperformed simple linear benchmarks in out-of-sample market timing 629. The researchers contend that the deep learning phenomenon known as "double descent" - where heavily over-parameterized models that have more parameters than training data points begin to generalize effectively rather than overfit - applies directly to financial forecasting 8.
The academic backlash to this assertion has been severe. Leading critics, including researchers from the University of Chicago and Stanford, argue that the "Virtue of Complexity" is a mathematical illusion 26308. They demonstrate mathematically that when the number of parameters vastly exceeds the number of temporal observations (e.g., using thousands of features on a rolling 12-month training window), the highly complex Random Fourier Features model mathematically degenerates into a simple recency-weighted average of the training sample returns 30. In this view, the massive neural network is not discovering profound, invisible non-linear relationships in the economy; it is merely executing a mechanically convoluted, volatility-timed momentum strategy 30.
This technical debate mirrors a broader apprehension among institutional practitioners. Prominent quantitative veterans, such as Martin Lueck of Aspect Capital, explicitly warn against delegating core portfolio construction entirely to black-box models 32. While conceding the utility of AI in data processing, Lueck argues that investors must be able to articulate a clear economic hypothesis behind their positioning, viewing the surrender to uninterpretable machine-based strategies as a profound failure of risk management 32. This tension underscores the ongoing industry struggle to distinguish genuine, machine-discovered alpha from sophisticated, multi-dimensional overfitting.
The Reproducibility Crisis in Financial Machine Learning
The skepticism directed at highly complex DRL trading systems is deeply rooted in empirical evidence. The intersection of reinforcement learning and financial time series presents unique mathematical challenges that frequently compromise the integrity of academic results.
Epistemic Uncertainty and Non-Stationary Market Ecology
The primary structural obstacle for DRL in finance is the combination of severe data scarcity and profound non-stationarity. Deep reinforcement learning was originally engineered to solve environments that are deterministic and infinite, such as chess, Go, or physics-based robotic simulators 24. In these environments, an agent can safely execute millions of random exploration episodes, iteratively learning the exact consequences of every possible action 24.
Financial markets provide exactly the opposite environment. History occurs only once, and a model trained on 20 years of daily equity data has access to roughly 5,000 samples per asset - a profoundly insufficient dataset for deep neural networks requiring millions of interactions to calibrate their weights accurately 4.
Furthermore, the financial environment is aggressively non-stationary. The underlying statistical distributions of asset returns shift continuously and unpredictably due to changes in macroeconomic monetary policy, geopolitical conflicts, technological disruptions, and the evolving behavior of competing algorithmic participants 4934. If a DRL agent is trained on data spanning the 2008 financial crisis or the 2020 pandemic crash, the neural network effectively memorizes historical anomalies 4. Once the market ecology adapts and transitions into a low-volatility bull market, the precise economic conditions that generated the historical reward signal will not repeat 4. Consequently, DRL models that exhibit spectacular profitability during in-sample training frequently collapse upon live deployment because they have perfectly overfit to a vanished, unrepeatable regime 935.
Seed Sensitivity and Single-Run Dispersion
The fragility of DRL trading policies is most clearly exposed by their extreme sensitivity to random initialization seeds. Neural networks are initialized with random weights, and the sequence of experiences sampled from the replay buffer involves inherent stochasticity. In stable environments, different random seeds eventually converge to similarly optimal policies. In noisy financial environments, the random seed can dictate the entire trajectory of the model 536.
A comprehensive 2026 diagnostic study, RiskLens Trader, evaluated the reproducibility and seed sensitivity of a standard PPO agent tasked with long-only portfolio allocation across five large-cap U.S. equities (AAPL, MSFT, NVDA, AMZN, and GOOGL) from 2018 to 2026 536. Using an 80/20 chronological train-test split, the agent was trained for 30,000 timesteps under five distinct random seeds while keeping all hyperparameters and data identical 5.
The dispersion of the results was highly alarming. The best-performing random seed achieved an out-of-sample total return of 132.6% and an excellent Sharpe ratio of 1.78, indicating massive market outperformance 5. However, another seed utilizing the exact same algorithm lost money out-of-sample 5. When averaged across all five seeds, the PPO agent's mean Sharpe ratio (0.79) was strictly inferior to standard, non-machine-learning baselines, including equal-weight, buy-and-hold, and minimum-variance strategies 536. Furthermore, the study demonstrated that the agent's most "successful" runs were driven by aggressive risk concentration and erratic portfolio turnover rather than consistent, intelligent risk-adjusted efficiency 36.
This extreme variance definitively proves that the prevalent academic practice of publishing single-seed backtests can materially overstate the performance of financial reinforcement learning systems. Without multi-seed reporting, researchers can simply cherry-pick the random initialization that happens to overfit perfectly to the out-of-sample test set, creating a dangerous illusion of predictive edge 536.
Information Leakage and Bias Vulnerabilities
The reproducibility crisis is further exacerbated by systemic methodological errors in handling financial data, specifically look-ahead bias and survivorship bias.
Look-ahead bias occurs when a quantitative model inadvertently incorporates information that would not have been available at the precise historical moment the trading decision was made 3738. In standard machine learning, random K-Fold cross-validation is used to evaluate model robustness. In finance, executing random K-Fold splits on time-series data leaks future information into the training set due to temporal autocorrelation, fatally contaminating the model 3839. To combat this, rigorous DRL implementations now mandate Purged K-Fold Cross-Validation, which enforces strict "embargo" periods between the training and validation sets to eliminate overlapping data points and preserve the strict chronological integrity of the simulation 3739.
Survivorship bias presents an equally pervasive threat. If a researcher constructs a DRL environment using the current constituents of the S&P 500 and trains the agent on the past 20 years of their data, the simulation is inherently flawed 3839. This methodology silently removes all companies that went bankrupt, merged, or were delisted during that 20-year window, artificially presenting the agent with a universe of guaranteed long-term winners 3839. Rigorous evaluation protocols now require point-in-time constituent datasets, ensuring the DRL agent only interacts with assets that were legitimately available for trading on that specific historical date, thereby preventing artificially inflated Sharpe ratios and understated drawdowns 3739.
Methodological Solutions and Simulation Fidelity
To bridge the credibility gap between academic theory and institutional deployment, the field is undergoing a systematic methodological overhaul. This transition involves abandoning bespoke, isolated scripts in favor of standardized open-source ecosystems, implementing highly realistic market friction models, and exploring offline RL architectures to mitigate capital risk.
Standardized Benchmarking Ecosystems
The historical inability to reproduce DRL trading results stemmed largely from the lack of standardized environments. Researchers built custom simulators with proprietary data handling, making cross-study algorithmic comparisons functionally impossible 9.
To enforce methodological rigor, the community has consolidated around unified open-source ecosystems such as FinRL and FinRL-Meta 939. These frameworks provide standardized DataOps pipelines that automate the ingestion of dynamic market data, handle the complexities of stock splits and dividends, and establish uniform, OpenAI Gym-style market environments 9. By enforcing consistent evaluation metrics (Sharpe, Sortino, Calmar, and maximum drawdown) and standardizing the underlying hardware configurations, these ecosystems isolate the actual algorithmic improvements of the DRL agent from hidden data engineering tricks 9. Furthermore, these platforms support massively parallel GPU environments, accelerating the collection of simulated trajectories and mitigating the sampling bottleneck that has historically hampered data-hungry algorithms like PPO 939.
Advanced Friction Modeling and Market Impact
A critical failure point of early DRL trading models was the assumption of infinite market liquidity and minimal transaction costs. When agents are trained under flat-fee assumptions (e.g., a static 10 basis points per trade regardless of size), they frequently learn highly pathological behaviors. These agents exploit the simulator by generating returns through rapid, high-turnover scalping strategies that would instantly collapse market prices if executed with real institutional capital 40.
To solve this, modern validation frameworks integrate nonlinear execution costs, most notably the Almgren-Chriss (AC) market impact model. The AC model dynamically penalizes trades based on volume participation rates and real-time liquidity constraints, simulating the adverse price movement caused by large orders 40. The inclusion of realistic market friction fundamentally alters both the absolute performance and the relative ranking of DRL algorithms.
In a recent evaluation of algorithmic stock trading environments, switching from a flat baseline cost to the AC impact model caused optimized TD3 agents to drop their daily trading costs by 96%, effectively forcing their portfolio turnover rates from an unfeasible 19% down to a realistic 1% 40. Conversely, algorithms that were not subjected to hyperparameter optimization (HPO) targeting these specific frictions exhibited unbounded growth in participation rates, trading aggressively until costs destroyed their portfolios 40. This dynamic provides definitive evidence that without the integration of non-linear market impact models, DRL agents do not learn genuine alpha; they merely learn to exploit the structural loopholes of simplified simulators 40.
Offline Reinforcement Learning and Cost Optimization
A major emerging trend to mitigate the risks of live-market interaction is the development of offline reinforcement learning. Offline RL leverages massive historical datasets to train agents completely isolated from live-market execution, eliminating the capital risk inherent in the exploration phase of traditional on-policy RL 3910.
A prominent advancement in this space is the ROIDICE (Return on Investment via stationary distribution correction estimation) framework, introduced at NeurIPS 2024 1042. Traditional RL agents optimize solely for maximum cumulative return, which can lead to inefficient strategies that burn excessive capital in transaction costs to achieve marginal gains 1042. ROIDICE addresses this by formalizing the objective as linear fractional programming within the MDP, allowing the agent to explicitly maximize the Return on Investment (ROI) - defined precisely as the mathematical ratio between the return and the accumulated cost 1042. By incorporating convex regularization to address the distribution shifts inherent in offline learning, ROIDICE yields highly efficient trading policies that provide a vastly superior trade-off between gross returns and execution costs compared to standard RL algorithms 1042.
Conclusion
Deep reinforcement learning possesses unparalleled theoretical potential to solve the most complex, multi-period optimization problems in quantitative finance. Its capacity to directly map granular market states to optimal execution actions without relying on fragile intermediate forecasting steps makes it uniquely suited for algorithmic order routing, dynamic hedging, and continuous portfolio management. Within this domain, constrained policy-gradient algorithms like PPO have established themselves as the industry standard, providing the necessary mathematical guardrails to prevent catastrophic unlearning in the face of financial noise.
However, the application of DRL to directional trading and autonomous alpha generation remains highly speculative and fraught with peril. Financial time-series data is fundamentally too scarce, too noisy, and too non-stationary to reliably train heavily parameterized neural networks without extreme methodological precautions. The realization of DRL's promise relies entirely on the industry's commitment to rigorous scientific hygiene. As the field matures, the transition from isolated, seed-optimized backtests to standardized, multi-baseline evaluation frameworks - incorporating point-in-time datasets and non-linear market impact models - will determine whether deep reinforcement learning becomes a foundational pillar of institutional finance or remains a heavily overfit academic curiosity.