Impact of vocal delivery on speaker credibility and authority
The scientific study of human vocal communication encompasses the biomechanical production of sound, the acoustic properties of speech, and the neurocognitive mechanisms involved in auditory perception. Beyond the literal semantic content of spoken language, paralinguistic cues - specifically pace, pitch, volume, resonance, and the duration of pauses - serve as a parallel channel of information. These acoustic variables exert a profound influence on how a speaker is perceived, shaping audience judgments regarding authority, competence, trustworthiness, and emotional state.
Historically, popular communication theory has frequently misrepresented the relative importance of paralinguistic cues versus semantic content. The most prominent example is the pervasive misapplication of Albert Mehrabian's 1967 research, often codified as the "7-38-55 rule," which erroneously claims that 93% of all communication is nonverbal (38% vocal tone and 55% body language) 12. Mehrabian's original studies were highly specific laboratory experiments involving single-word utterances (such as "maybe") spoken by 62 female subjects, designed solely to measure how listeners resolve incongruence between a spoken word and the speaker's emotional tone or facial expression 323. Academics have heavily criticized the indiscriminate application of these findings, noting that the study used static headshots and isolated words, making the role of language artificially irrelevant by design 34. Words remain the primary vehicle for conveying specific ideas; however, the paralinguistic delivery of those words modulates the listener's psychological and emotional reception, effectively determining the speaker's perceived credibility, dominance, and authenticity.
Evolutionary Psychology of Pitch Perception
Pitch, primarily determined by the fundamental frequency (F0) of vocal fold vibration, is one of the most robust acoustic predictors of perceived speaker identity and status 56. The relationship between low vocal pitch and perceived authority is deeply rooted in evolutionary biology and cross-species ethology.
The Frequency Code
The theoretical framework explaining the relationship between acoustic frequency and perceived dominance is known as the "Frequency Code," originally proposed by phonetician John Ohala in 1983 789. Across the animal kingdom, vocalizations are constrained by the physical size of the vocalizer. Larger animals possess larger vocal apparatuses - specifically longer, thicker vibrating membranes and larger resonating cavities - which naturally produce lower-frequency sounds 71011. Consequently, low-pitched vocalizations have evolved as a reliable acoustic projection of physical size, formidability, and threat.
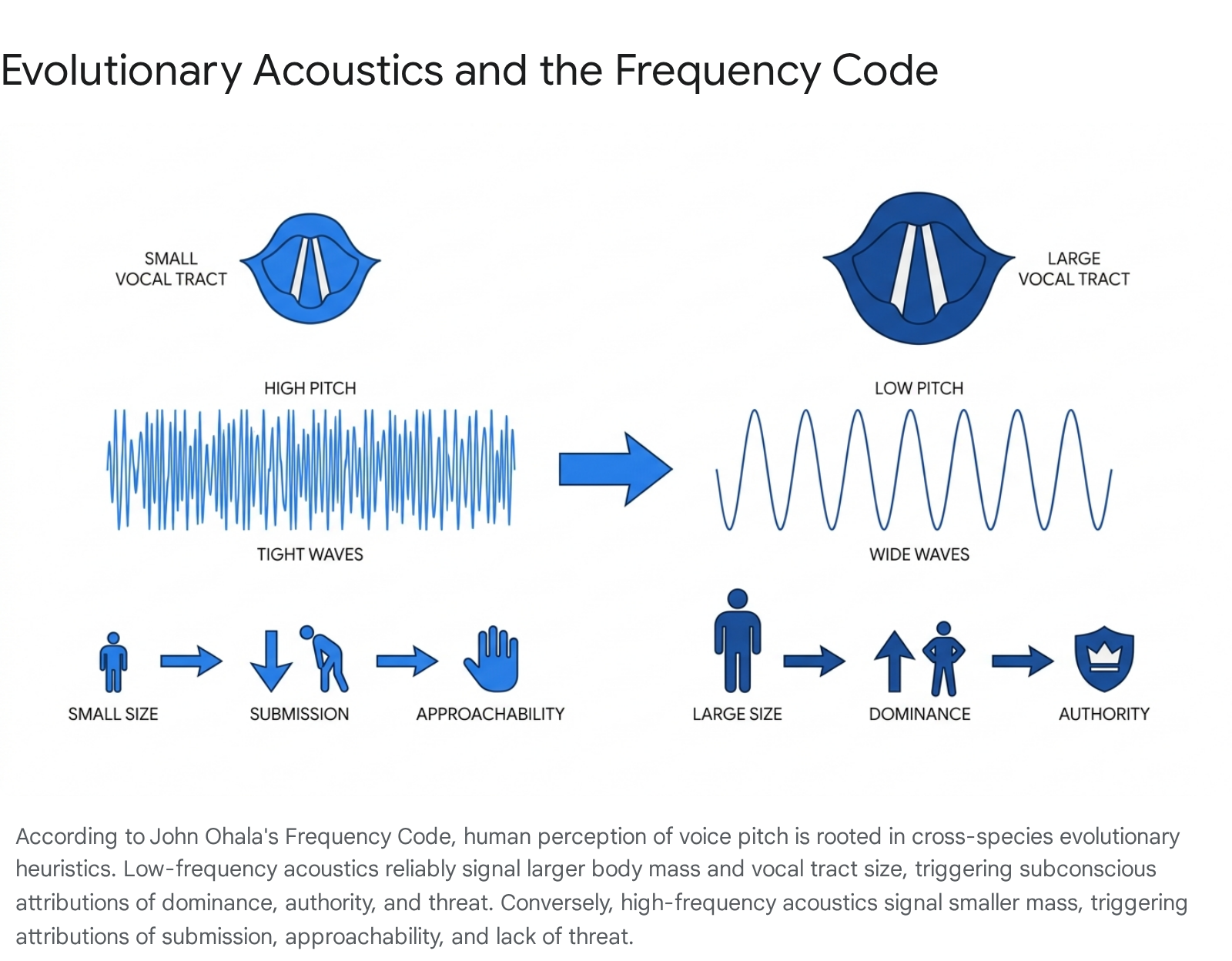
Human listeners retain this perceptual heuristic. In social and professional contexts, audiences subconsciously associate low pitch (low F0) and low resonance frequencies with larger body size, physical strength, and dominance 781412. Ohala extended this code to explain diverse linguistic phenomena, such as the cross-linguistic tendency to use high or rising pitch to mark questions (signaling submissiveness or an appeal for information) and low or falling pitch to mark assertive declarative statements 911. Furthermore, the frequency code accounts for sound symbolism, where vowels with high intrinsic acoustic frequencies (like /i/) are routinely used in words denoting smallness (e.g., tiny, petite), while low-frequency vowels (like /a/) denote largeness 79.
Hormonal Correlates and Trust Dynamics
The sexual dimorphism of the human voice, which becomes pronounced during puberty under the influence of testosterone, results in longer and thicker vocal folds in biological males, yielding an average fundamental frequency roughly half that of biological females 81013. Because lower voices correlate with higher levels of circulating testosterone, low pitch serves as a biological signal of traits historically associated with the hormone, such as assertiveness, formidability, and social aggression 171415. Experiments involving modified vocal recordings demonstrate that male and female speakers with lower-pitched voices are consistently judged as more commanding, more likely to be followed, and more competent 141516. Furthermore, individuals who naturally drop their pitch during the initial moments of an interaction are perceived as more influential and are more successful at convincing groups to adopt their ideas compared to those whose pitch rises 17.
However, the perception of pitch is not entirely linear regarding positive speaker attributes. While a low pitch enhances perceptions of dominance and authority, it can sometimes negatively impact perceived trustworthiness or warmth. A 2017 study from the University of Guelph on the economics of trust demonstrated that while lower-pitched male voices were rated as more physically attractive, they were also perceived as more likely to exploit trust or cheat 17. In economic "trust games," listeners were actually more willing to entrust resources to males who slightly raised their vocal pitch, as a higher pitch signaled a lack of aggression and a submissive, cooperative intent 1722. Thus, speakers face a physiological trade-off: deep pitch maximizes authority and formidability, while moderate or slightly elevated pitch enhances approachability and perceived ethical reliability 1819.
Acoustic Resonance and Vocal Timbre
While fundamental frequency determines the pitch, vocal tract resonance dictates the timbre, depth, and clarity of the voice. The vocal tract functions as an acoustic filter, selectively amplifying certain harmonic frequencies produced by the glottis while dampening others 132021.
Formant Frequencies and Acoustic Power
The human vocal tract is often modeled as a closed tube resonator. With a typical adult length of roughly 17 to 18 centimeters, the unmodulated tract yields a foundational fundamental frequency near 500 Hz 21. The resonances generated within this tract are known as formants (F1, F2, F3, etc.). The lowest two formants (F1 and F2) are modified primarily by the jaw and tongue and serve to distinguish vowel sounds, while the higher formants (F3, F4, F5) are largely determined by deeper structural configurations and are instrumental in defining the individual's unique voice timbre and overall vocal power 132122.
In professional voice users, such as stage actors and opera singers, a specific acoustic phenomenon known as the "Singer's Formant" or "Speaker's Ring" is often observed. This occurs when the vocal tract is shaped to cluster the third, fourth, and fifth formants closely together, creating a prominent, consolidated peak in acoustic energy between 2.0 kHz and 4.0 kHz 13202324. Because human hearing is particularly acute in the 2 - 4 kHz range, this resonance tuning allows a speaker or singer's voice to cut through heavy background noise or dense orchestral accompaniment without requiring additional physiological exertion or breath pressure 2324. Measurements of professional tenors, baritones, and sopranos demonstrate consistent energy concentrations in the 2.2 - 3.4 kHz region, with some groups exhibiting a secondary high-frequency peak at 8 - 9 kHz, contributing to a "rich" vocal perception 24.
Perceptual Impacts of Nasality and Resonance Balancing
Resonance directly affects a speaker's perceived competence and authority. A well-resonated voice - characterized by a healthy balance of lower pharyngeal depth and higher oral brightness - is perceived as dynamic, healthy, and authoritative 182025. Conversely, poor resonance management degrades speaker credibility. For example, excessive nasal resonance (hypernasality), which occurs when acoustic energy inappropriately bleeds into the nasal cavity during oral sounds, frequently results in a voice perceived as muffled, annoying, or monotonous, thereby reducing the audience's rating of the speaker's intelligence and persuasiveness 2026.
Another common defect is "cul-de-sac" resonance, where sound is trapped due to structural blockages (such as swollen tonsils or velopharyngeal issues), preventing clear acoustic exit 26. Furthermore, research indicates that the alignment of pitch and vocal tract resonance (VTR) is crucial for perceptual fluency. When researchers artificially mismatch F0 and VTR in experimental settings, the resulting voices are rated as highly unnatural and suffer from decreased speech intelligibility, particularly in noisy environments, which forces listeners to expend greater cognitive effort to decode the message 5.
Sociolinguistic Dynamics of Pitch and Intonation
The acoustic norms of authoritative delivery are heavily influenced by cultural gender expectations. Paralinguistic phenomena such as vocal fry (creaky voice) and upspeak (terminal rising intonation) highlight the friction between vocal mechanics, gender identity, and professional credibility.
Mechanics and Perception of Vocal Fry
Vocal fry, also known as pulse phonation or glottalization, occurs when a speaker lowers their pitch to their lowest natural register, accompanied by a decrease in subglottal breath velocity 2734. This causes the vocal cords to compress and vibrate irregularly, producing a distinctive choppy or "creaky" sound, typically observed at the end of declarative utterances 2734.
While vocal fry has existed in English speech since at least the 1930s, its increased prevalence among young American females has sparked extensive sociolinguistic research 27. The perception of vocal fry in professional and academic environments is overwhelmingly negative. In a large national study of 800 American adults published in PLOS One, young adult female voices exhibiting vocal fry were perceived as less competent, less educated, less trustworthy, less attractive, and ultimately less hirable than female voices exhibiting normal phonation 34. Because a creaky voice is acoustically associated with low-energy physiological states - such as waking up or lacking attention - listeners frequently interpret it as a sign of disinterest or intellectual disengagement 2728.
The Gendered Double Standard
Sociolinguistic analysis reveals a significant double standard in the auditory perception of both vocal fry and upspeak. Upspeak involves ending a declarative sentence with the rising pitch contour typically reserved for interrogative questions. While empirical studies demonstrate that men use upspeak and vocal fry at rates comparable to women, the professional penalty is applied almost exclusively to female speakers 29.
When male speakers utilize vocal fry, dropping their pitch into a hyper-masculine, creaky range, it is often subconsciously decoded by listeners as an assertion of dominant authority and vocal weight 27. Conversely, when women use vocal fry, it is often penalized as inappropriate "male mimicry" or viewed as an unnatural deviation from expected feminine presentation, correlating directly with a decrease in perceived attractiveness and competence 2728. Similarly, listeners are culturally conditioned to expect linguistic under-confidence from women; thus, a woman utilizing upspeak is judged as lacking self-assurance or seeking unwarranted approval 3429. A male speaker using the exact same rising intonation pattern is often granted the benefit of the doubt, his assertions evaluated purely on their semantic merit without penalty 29.
Transgender and Non-Binary Vocal Congruence
The science of vocal delivery is increasingly examining voices that do not conform to binary cisgender norms. Pitch (F0) and vocal tract resonances (formant frequencies F1 - F4) are the primary acoustic markers utilized by human listeners to categorize gender within milliseconds of vocal onset 630. For transgender and gender non-conforming (TGNC) individuals, the incongruence between their internal gender identity and the external acoustic perception of their voice can lead to significant psychological distress 631.
Gender-affirming voice training focuses heavily on manipulating both fundamental frequency and formant resonance to achieve vocal congruence. For instance, transgender women may work to raise their baseline pitch, shift resonance forward from the chest to the head/oral cavity, and utilize more rising intonations, all of which serve as perceptual markers of femininity 2632. Conversely, transgender men may focus on lowering F0, expanding pharyngeal resonance for a deeper timbre, and utilizing descending intonation patterns 32. Research indicates that the perception of gender from voice is highly variable and heavily influenced by the listener's own demographic background. Cisgender listeners rely heavily on strict binary acoustic thresholds, while gender-diverse listeners process vocal cues with greater flexibility and are more adept at identifying gender-diverse voices 630.
Speech Pacing and Pause Mechanics
The rate of speech, measured in words per minute (WPM), and the strategic deployment of silence are critical factors in managing the audience's cognitive load. If a speaker exceeds the processing capacity of the listener's working memory, comprehension and retention plummet 3341.
Optimal Speech Rates and Cognitive Load
The optimal speech rate is entirely dependent on the communication context, the complexity of the material, and the specific objective of the speaker. According to the American Speech-Language-Hearing Association (ASHA), formal, academic, or highly complex presentations should be benchmarked at roughly 110 to 130 WPM to allow audiences adequate time to decode dense semantic information 4142.
For standard business presentations, organizations such as Toastmasters International recommend a range of 120 to 160 WPM, balancing clarity with an energetic delivery 42. However, in highly engaging, narrative-driven formats where the audience is primed for entertainment and inspiration - such as TED Talks - the average speech rate climbs to 163 WPM 42. Conversational speech naturally hovers around 150 to 160 WPM because conversational shorthand and shared context drastically reduce the listener's cognitive load 4243.
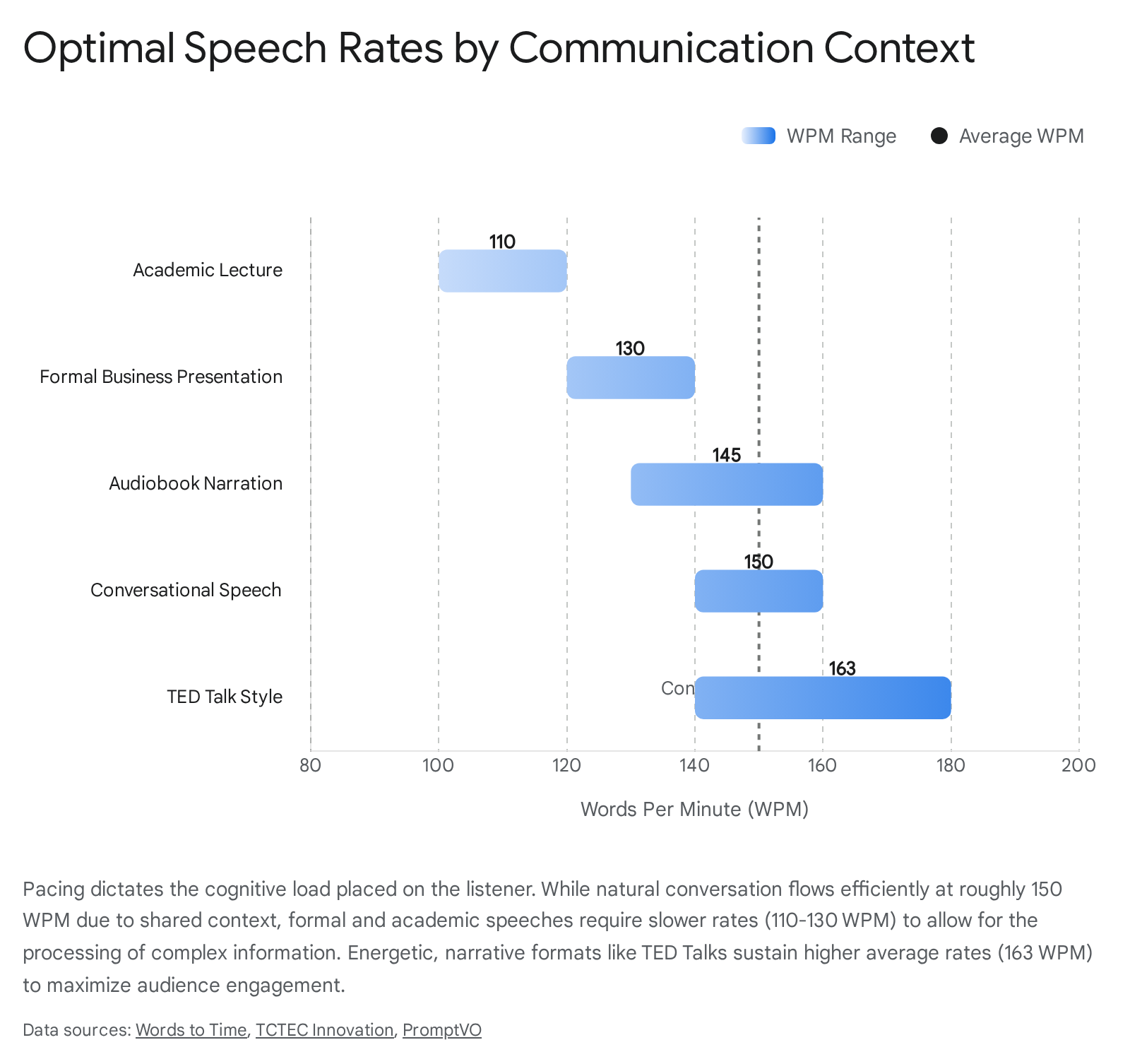
Deviations from these optimal zones carry severe perceptual risks. Speaking too rapidly (above 170-180 WPM) can project urgency and passion, but it frequently results in listeners feeling overwhelmed and missing key messages 334243. Conversely, speaking too slowly (below 100 WPM) risks monotony, signaling a lack of enthusiasm or confidence, and causing the audience to disengage or lose focus entirely 3344.
The Structural Role of Pauses
Pausing is not merely the absence of sound; it is a structural mechanism that delineates syntactic boundaries, allowing listeners to parse information efficiently. Acoustic analyses of fluent English speech reveal highly consistent mathematical ratios for natural pausing. Research demonstrates that pauses denoting minor syntactic boundaries (such as commas) typically last around 0.38 to 0.67 seconds, whereas pauses denoting major boundaries (such as periods) average between 0.81 and 1.24 seconds, creating a reliable 1:2 ratio 3435. In subjective listener evaluations conducted by Fuyuno et al., fixing pause durations consistently at roughly 0.6 seconds within sentences yielded the highest ratings for speech "naturalness" and overall speaker credibility 34.
Pauses also carry heavily weighted interpersonal judgments. In experimental settings, when non-native speakers pause slightly longer before answering a question or granting a request, native listeners systematically judge them as less willing, less truthful, and less competent 36. The listener misinterprets the cognitive processing delay required for second-language retrieval as an indicator of social reluctance or deception 36.
Pauses as Clinical Biomarkers
The duration and frequency of speech pauses are so inextricably linked to neurocognitive function that they serve as highly reliable clinical biomarkers for neurological decline. Quantitative meta-analyses comparing healthy older adults to individuals with Mild Cognitive Impairment (MCI) or Alzheimer's Dementia (AD) show that pause duration is a significantly more sensitive indicator of cognitive pathology than overall speech rate 3738.
Individuals with MCI and AD exhibit longer pauses (by 0.62 and 1.20 standard deviations, respectively, compared to healthy controls) and more frequent hesitation mumbles 3738. As the semantic retrieval systems in the brain falter due to neurodegeneration, the speaker requires exponentially more time to source the correct vocabulary, leading to prolonged inter-utterance silences 38. Because pause analysis is face-valid, interpretable as a ratio of reaction time, and relatively easy to compute automatically, acoustic assessment of silence is becoming a frontline tool for the early identification of dementia 37.
Cross-Cultural Variances in Vocal Delivery
The science of vocal delivery cannot be universally applied without strictly accounting for profound cultural variations in communicative norms. The interpretation of volume, pace, and pause is heavily dependent on whether a culture operates on a high-context or low-context communicative framework.
High-Context and Low-Context Paradigms
Developed by anthropologist Edward T. Hall, the high/low context framework explains how different societies encode and decode information 394041. * Low-Context Cultures: Prevalent in the United States, Germany, Scandinavia, and Australia, low-context cultures prioritize individualism and require explicit, direct verbal communication 39414243. Meaning is derived directly from the spoken word, with less reliance on environmental or paralinguistic cues. * High-Context Cultures: Prevalent in Japan, China, Korea, Indigenous cultures in the Americas, and Latin America, high-context cultures prioritize collectivism and relational harmony 394142. Communication is subtle, and meaning is largely implicit, requiring the listener to carefully decode nonverbal cues, vocal tone, and the broader social context 434456.
The Cultural Interpretation of Silence
The most striking paralinguistic divergence between these cultural frameworks is the interpretation of silence. In mainstream low-context cultures (e.g., the U.S. and Northern Europe), conversational silence is frequently perceived as a negative void 564546. Extended pauses are interpreted as awkwardness, a lack of preparation, disengagement, or even hostility 3945. Speakers in these cultures tend to rush to fill gaps with small talk to maintain conversational energy and prevent social discomfort 5646.
Conversely, in many high-context cultures (e.g., Japan, China, and Indigenous communities), silence is an active, highly meaningful component of communication 564546. Silence conveys deference to hierarchy, deep contemplation, and profound respect for the speaker 394456. In Japan and Finland (which, despite being a low-context European culture, shares a unique cultural appreciation for quietude and privacy), interrupting a speaker or rushing a response is considered highly impolite; "still waters run deep," and silence signifies maturity and emotional self-discipline rather than confusion or ignorance 39564748.
| Vocal Parameter | Low-Context & Western Norms (e.g., USA, Germany) | High-Context & Eastern Norms (e.g., Japan, China) |
|---|---|---|
| Silence / Pauses | Viewed negatively; indicates awkwardness, lack of preparation, or disengagement. Rushed to be filled. | Viewed positively; indicates respect, active listening, contemplation, and emotional self-control. |
| Pace and Volume | Fast, loud delivery often signals passion, confidence, and assertiveness. | Fast, loud delivery may be viewed as domineering, impolite, or lacking self-discipline. |
| Directness | Values explicit, blunt verbal clarity. Tone is secondary to the literal meaning of words. | Values indirect, nuanced delivery to preserve group harmony and save face. Tone carries vital contextual data. |
| Emotional Expression | Prioritizes forthright expression of personal opinions, even if divergent. | Favors reserved, controlled tones to signal professionalism, with notable exceptions (e.g., Latin America). |
Table 1: Divergent perceptions of paralinguistic delivery across cultural frameworks 394142444546. Note: Certain regions, such as Latin America and the Middle East, present a hybrid paradigm: they are high-context but favor highly expressive, loud, and energetic vocal delivery to signal engagement 424445.
Cross-Cultural Emotion Recognition
The ability to detect emotion from vocal cues possesses both universal and culturally specific components. Meta-analyses of cross-cultural vocal emotion recognition consistently reveal an "in-group advantage" 124950. While basic emotions (anger, sadness, fear) can be recognized across linguistic barriers at rates well above chance, listeners are significantly more accurate at identifying the emotional valence and arousal of speakers from their own cultural or linguistic group 50. The manifestation of specific emotions in the voice constitutes a "cultural dialect"; parameters such as spectral tilt, F0 manipulation, and open quotient (breathiness) are weighted differently by listeners depending on their cultural conditioning 5063.
Organizational Leadership and Crisis Communication
Within organizational environments, a leader's vocal delivery directly impacts workforce engagement, motivation, and the psychological safety required for corporate innovation.
Vocal Charisma and Emotional Contagion
Charismatic leadership is defined by the ability to inspire followers, articulate a compelling vision, and foster deep emotional bonds, rather than relying strictly on transactional rewards or positional authority 5165. The primary transmission mechanism for this leadership style is the human voice. A charismatic vocal delivery - characterized by dynamic pitch variations, optimal resonance, and strategic pacing - triggers a psychological phenomenon known as "emotional contagion" 5165. Because the human limbic system processes acoustic cues automatically, an emotionally expressive and confident vocal tone from a leader causes listeners to subconsciously mirror those emotions (neural resonance), spreading enthusiasm, optimism, and motivation throughout a team 196552.
Conversely, an absence of vocal modulation or the presence of a tense, creaky voice degrades perceptions of a leader's warmth and competence, reducing their ability to persuade 1653. Furthermore, research into "employee voice behavior" - the proactive sharing of constructive ideas, innovations, or safety warnings by subordinates - shows that leaders who demonstrate vocal warmth, inclusivity, and empathy foster a climate of psychological safety 68545556. This safe acoustic and psychological environment directly increases the likelihood of upward communication, particularly under servant or inclusive leadership models 5556.
Rhetorical Appeals in Crisis Scenarios
During acute crises, such as the COVID-19 pandemic, political leaders and public health officials utilize highly calculated rhetorical and vocal strategies to manage public perception. Analysis of political crisis communication reveals an interplay of the classic Aristotelian appeals: logos (logic/facts), ethos (credibility/authority), and pathos (emotion/empathy) 57.
When leaders rely heavily on low, resonant, and slow-paced vocal delivery, they lean into ethos and logos to project stability, competence, and control over chaotic events 5758. The strategic lowering of fundamental frequency communicates formidability and command, assuring the public that the crisis is being managed by a capable authority 1759. However, to motivate public compliance with sweeping safety directives or lockdowns, leaders must inject pathos through subtle variations in pitch and volume that convey empathy and shared sacrifice 57. Miscalibration of these vocal traits during a crisis - such as sounding overly monotonous or aggressively loud - can result in catastrophic losses of public trust and policy non-compliance 5859.
Technological Mediation of the Voice
The migration of professional communication to digital platforms (e.g., Zoom, Microsoft Teams) and asynchronous audio (podcasts) has introduced profound technological variables that actively alter both the biological production and the auditory perception of the human voice.
Telepractice and Compensatory Vocal Effort
Media Richness Theory posits that remote audio-visual communication suffers from a reduction in physical, spatial, and tactile cues compared to face-to-face interactions 6061. In response to this communicative barrier, speakers subconsciously alter their vocal production. Studies monitoring speech behavior during teleconferencing demonstrate that individuals automatically increase their vocal intensity (volume) and fundamental frequency (pitch) to compensate for the perceived distance and the loss of subtle nonverbal feedback from the audience 60. While these adjustments aid in maintaining speech intelligibility over digital connections, chronic over-projection requires immense physiological effort, leading to vocal fatigue and altering the natural, authoritative baseline of the speaker 6061.
Digital Audio Compression and Algorithmic Bias
Perhaps the most insidious impact of remote communication on speaker perception stems from the digital audio compression algorithms (codecs like OPUS, AAC, and MP3) utilized by modern teleconferencing and telehealth software. To preserve internet bandwidth, these lossy codecs aggressively discard acoustic data that falls outside the narrow frequencies strictly required for basic word recognition 626364.
This compression has a devastating effect on paralinguistic nuance. Codecs selectively strip away high-frequency harmonics and formant data - precisely the acoustic elements that provide vocal timbre, emotion, and the authoritative "Speaker's Ring" 236566. Consequently, highly compressed audio induces a phenomenon termed "digital flat affect," wherein listeners are unable to distinguish between high-arousal emotions (like joy or passion) and low-arousal states (like boredom or sadness) 65. The speaker is perceived as less charismatic, less engaged, and less persuasive entirely due to algorithmic filtering 65.
Furthermore, this technological degradation is not gender-neutral. Because legacy lossy codecs prioritize the lower frequency ranges typical of adult male voices, the removal of high-frequency data disproportionately distorts and degrades voices with higher fundamental frequencies, primarily those of women and children 6465. At lower bitrates (6 - 16 kbps), female voices suffer significantly greater signal degradation than male voices, leading to systemic, algorithmic biases that diminish female speaker clarity, emotional resonance, and perceived professional competence in virtual environments 6465.
Podcasting and Acoustic Intimacy
In stark contrast to the degraded audio of teleconferencing, the high-fidelity, long-form environment of podcasting has revolutionized political and corporate communication. Traditional broadcast media (television and radio news) relies on adversarial interviews and highly constrained soundbites, forcing speakers into rapid, defensive vocal postures 8267. Podcasting, however, mimics the acoustic environment of intimate, casual conversation 8284.
By recording in acoustically treated studios with high-quality microphones that capture the full spectrum of vocal resonance, podcasters deliver a rich, warm, and expansive sound directly into the listener's ears, frequently via headphones 5284. This high-fidelity capture of deep vocal resonance directly stimulates the listener's limbic system, fostering parasocial bonding and a deep sense of trust and authenticity 5284. Political actors and corporate executives increasingly leverage this acoustic intimacy to bypass traditional media gatekeepers, utilizing relaxed pacing and warm resonance to humanize their image and persuade highly engaged audiences 826785.
Conclusion
The science of vocal delivery unequivocally demonstrates that the manner in which a message is spoken is as psychologically impactful as the semantic content it carries. The human auditory system, shaped by evolutionary biology, is highly attuned to decode dominance, competence, and emotional state from minute variations in pitch, pace, and resonance. However, these biological heuristics are continuously modulated by sociolinguistic expectations, gender biases, and the profound differences between high-context and low-context cultures. As global communication increasingly relies on digital platforms, professionals must recognize that their vocal delivery is not a static physiological trait, but a highly flexible, strategically vital instrument that must be calibrated to the specific acoustic, cultural, and technological environment of the audience.