Transformer residual stream architecture
Introduction to the Residual Stream
The residual stream is the central structural component of transformer-based artificial neural networks, functioning as the primary data conduit through which all intermediate computations propagate. Originating in deep convolutional neural networks as a structural solution to the vanishing gradient problem, residual connections - or skip connections - allow gradients to propagate efficiently backward through hundreds of layers during the optimization process 12. In the context of the transformer architecture, the residual stream framework reconceptualizes the model not as a strictly sequential pipeline where each layer consumes and entirely replaces the output of the previous layer, but as a single, continuous vector space. All internal modules, specifically the Multi-Head Attention (MHA) and Feed-Forward Network (FFN) blocks, operate in parallel with respect to this central state 12.
Rather than transforming the data wholesale, these sub-layers read information from the stream, perform isolated computations, and write their results back into the stream via simple vector addition.
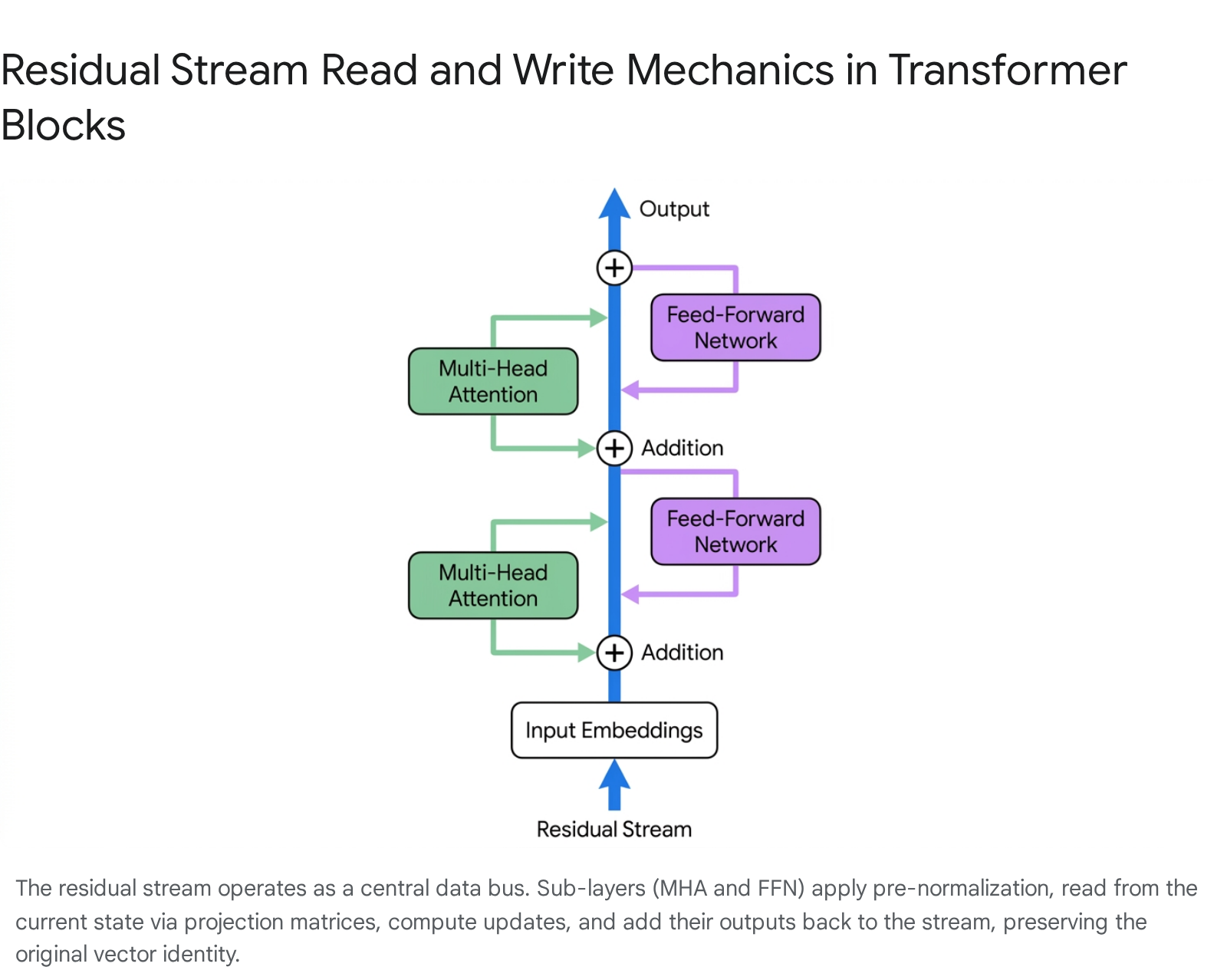
This additive accumulation enables the initial state - the raw token embeddings - to persist and undergo iterative refinement across the depth of the model, maintaining an identity path that prevents exponential decay of the learning signal and stabilizes training in deep architectures 45. Because the stream acts as a shared, bottlenecked memory, it forces the network to orchestrate sophisticated routing and subspace management strategies. Individual attention heads and multi-layer perceptron (MLP) neurons must encode their outputs into specific geometric subspaces of the stream, relying on the high-dimensional properties of the vector space to prevent destructive interference between distinct semantic features 1.
This structural paradigm forms the foundation for modern mechanistic interpretability, a subfield of artificial intelligence research that seeks to reverse-engineer neural networks into human-understandable algorithms by analyzing the information stored, modified, and erased within the residual stream at each sequential processing block 67. By treating the transformer as an ensemble of paths rather than a monolithic black box, researchers can isolate the precise computational circuits responsible for specific cognitive behaviors 8.
Mathematical Formalization and Data Flow
The operations on the residual stream are governed by a strictly additive sequence. Let the residual stream state at a given layer be denoted as an accumulation of vectors. The transition to the subsequent layer involves additive updates from the attention and feed-forward sub-layers. In modern large language models adopting the standard PreNorm architecture, this update highlights that the sub-layers act as additive branches mapping the normalized stream to an update vector of the exact same dimensionality 9.
The read-write framework dissects how weight matrices interact with this central stream. Within the Multi-Head Attention mechanism, the model reads from the stream by multiplying the normalized residual vector with Query and Key projection matrices to compute attention scores, establishing relevance across different token positions in the sequence 2. The Value matrix independently extracts the semantic content. Once the attention-weighted sum of values is calculated, the Output matrix projects this refined information back into the dimension of the residual stream, effectively writing the result back to the shared memory bus 12.
The Feed-Forward Network follows a similar operational logic. It reads from the stream using an initial up-projection matrix, applies a non-linear activation function, and writes back to the stream via a down-projection matrix 1011. Under this mechanistic interpretation, the entire forward pass of a transformer is an exercise in massive linear accumulation. The final output vector immediately preceding the unembedding projection is mathematically equivalent to the original input token embedding plus the weighted sum of millions of independent message vectors generated by attention heads, plus the sum of all modifications written by the network's multi-layer perceptrons 512.
Layer Normalization and Nonlinear Coupling
While the residual stream is fundamentally structured around linear addition, the inclusion of Layer Normalization or Root Mean Square Normalization (RMSNorm) introduces a nonlinear coupling of dimensions that complicates pure linear decomposition 3. The industry universally adopted PreNorm - where normalization occurs before the sub-layer transformation rather than after the residual addition - because repeated normalization in PostNorm configurations compounded into vanishing gradients at extreme depths 1415. PreNorm guarantees that the main residual highway remains completely uninterrupted by non-linearities, allowing gradients to flow straight backward through the addition operations 14.
However, the mathematical mechanics of normalization require dividing the vector by its standard deviation or root mean square, a scalar value derived from all dimensions of the vector simultaneously 3. Changing a single component of the residual stream alters the mean and variance, which in turn slightly shifts the normalized value of every other component. From the perspective of mechanistic interpretability, this breaks the strict mathematical linearity of the path decomposition. Fortunately, because large language models operate in highly dimensional spaces, altering a single dimension shifts the overall variance by a highly diluted factor 3. This high-dimensional dilution allows researchers to treat the residual stream as approximately linear for practical analytical purposes, ensuring that techniques like direct logit attribution remain highly effective despite the theoretical nonlinear coupling 3.
Bandwidth Capacity and the Dimensional Bottleneck
A defining characteristic of the residual stream is its restricted dimensionality, generally denoted as the hidden size or $d_{model}$. This dimension acts as a stringent information bottleneck between the expansive computational blocks of the transformer 1. While the residual stream maintains a constant dimension size throughout the network, the intermediate hidden layers of the Feed-Forward Networks expand significantly to provide the network with increased representational capacity 11.
Standard transformer architectures typically employ an expansion ratio of four, though modern variations utilize differing ratios depending on Mixture-of-Experts (MoE) routing or specific dense configurations 1115. Consequently, at any given layer, the residual stream is attempting to communicate with an order of magnitude more neurons than it has dimensions. For example, a single MLP layer may have tens of thousands of neurons reading from and writing to a stream with only a few thousand dimensions 1. When scaled across dozens of layers, a comparatively narrow residual stream must interact with millions of unique neural parameters, forcing the model to rely heavily on superposition to manage the limited bandwidth 116.
Architectural Dimensional Profiles
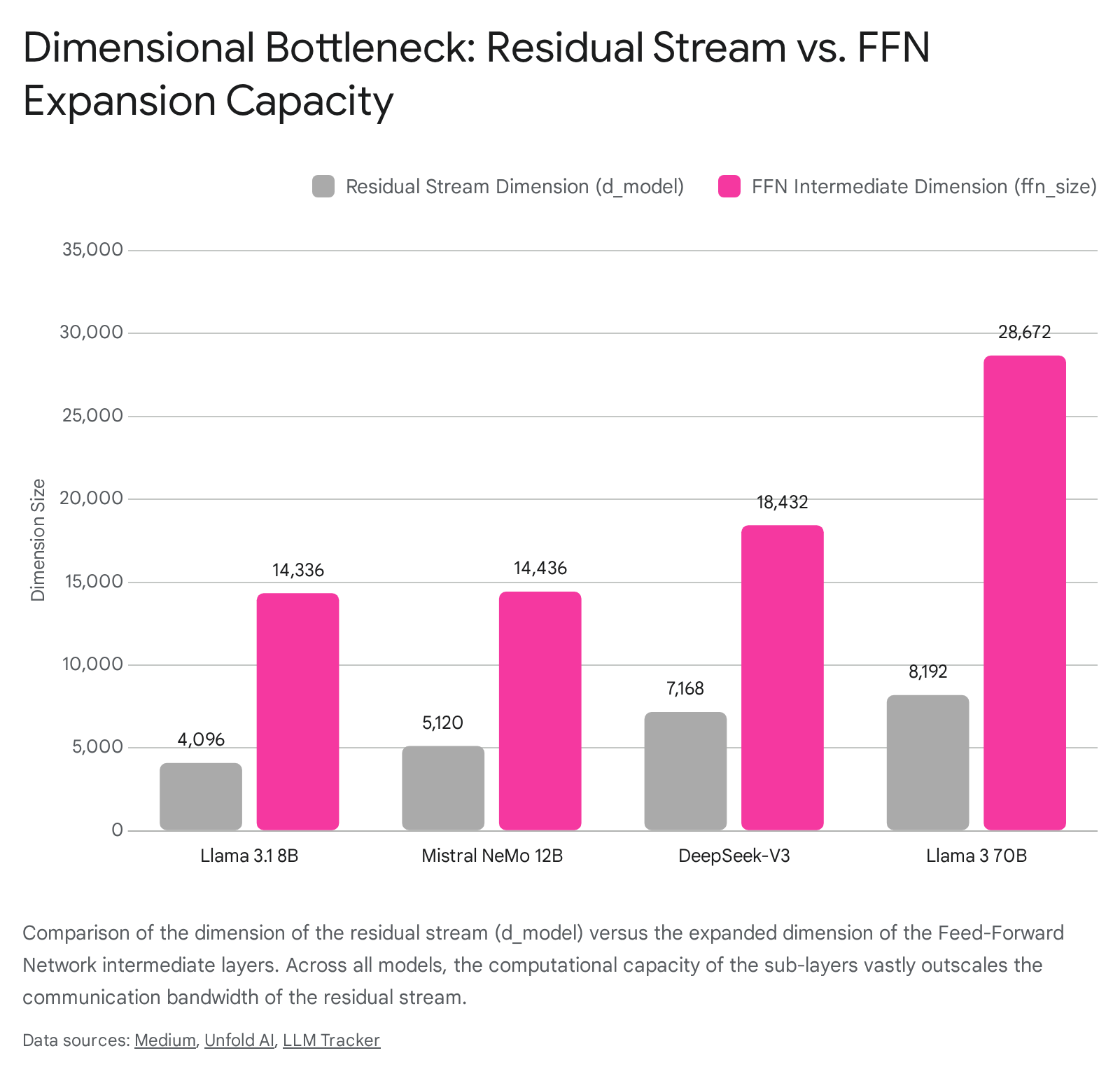
The specific dimensions of the residual stream versus the intermediate computation capacity vary significantly across contemporary foundation models, reflecting different engineering strategies for managing the bandwidth bottleneck and scaling computational density.
| Model | Parameter Size | Layers | Residual Stream ($d_{model}$) | FFN Intermediate Size | Attention Heads | Context Window |
|---|---|---|---|---|---|---|
| Llama 3.1 1017 | 8B | 32 | 4096 | 14336 | 32 | 128,000 |
| Mistral NeMo 1819 | 12B | 40 | 5120 | 14436 | 32 | 128,000 |
| Qwen 2.5 20 | 32B | 64 | 5120 | ~13653 (effective) | 40 | 131,072 |
| Llama 3.1 214 | 70B | 80 | 8192 | 28672 | 64 | 128,000 |
| DeepSeek-V3 423 | 671B | 61 | 7168 | 18432 (Dense) | 128 | 163,840 |
In examining these architectures, the tension between the residual stream bottleneck and the computational sub-layers becomes apparent. The Llama 3.1 8B model utilizes a 4096-dimensional residual stream to service an intermediate FFN size of 14,336 10. The 70B variant expands the stream to 8192 dimensions but increases the FFN intermediate size to 28,672, demonstrating a persistent expansion ratio constraint 4. DeepSeek-V3 introduces a hybrid architecture containing 671 billion total parameters but only activating 37 billion per token. Despite this immense parameter count, its residual stream remains bottlenecked at 7168 dimensions, with dense layers expanding to 18,432 and routed experts operating at 2048 dimensions 423.
Superposition and Subspace Allocation
To effectively manage this bandwidth constraint, transformer models rely on the mathematical properties of high-dimensional geometric spaces. In a vector space comprising thousands of dimensions, there exists an exponentially larger number of nearly orthogonal directions than there are absolute dimensions. Models exploit this phenomenon via superposition, encoding a volume of semantic features that far exceeds the hard dimensional limit of the residual stream 165.
Under this framework, different attention heads and neural layers read from and write to distinct geometric subspaces. Because these high-dimensional subspaces are approximately orthogonal, an attention head can write a specific cognitive feature into the stream without overwriting or destructively interfering with the features concurrently written by other parallel heads 1. Once information is injected into a specific subspace, it persists across subsequent layers unless another component actively deletes it. Interpretability research indicates that certain MLP neurons and attention heads act as memory managers, clearing residual stream dimensions previously set by early layers by reading the information and writing an exact negative version, thereby freeing up residual bandwidth for later computations 125.
Representational Geometries
A primary objective in mechanistic interpretability is mapping exactly how semantic concepts are geometrically encoded within the residual stream vector space. The manner in which the network distributes information dictates the reliability of intervention techniques used to steer model behavior.
The Linear Representation Hypothesis
For several years, the prevailing consensus has been the Linear Representation Hypothesis (LRH). The LRH posits that the neural network represents internal variables, concepts, or semantic features as discrete, linear directions within the residual stream vector space 5266. According to this hypothesis, isolating a specific semantic concept - such as truthfulness, political ideology, or relative time - is mathematically equivalent to finding its specific atomic vector direction 266.
This theoretical foundation justifies the widespread use of linear probes and concept activation vectors. If the hypothesis holds true, perturbing the residual stream along a single linear direction should predictably alter the model's output without disrupting parallel representations. However, researchers formalizing this notion note that mapping these directions often requires complex causal inner products to map unembedding representations to embedding representations, relying heavily on single-token counterfactual pairs to identify the relevant steering vectors 266.
Geometric Critiques and Advanced Topologies
Recent theoretical and empirical studies have increasingly challenged the absolute validity of the strict LRH, noting that it fails to account for the instability of practical steering. In deep architectures, linear interventions often yield unpredictable results across different input samples, occasionally causing the model to produce degenerate text or fail to execute tasks entirely 78.
To address these limitations, researchers have proposed the Cylindrical Representation Hypothesis (CRH). The CRH extends the linear framework by explicitly acknowledging that concepts exist in dense superposition and inevitably overlap. Due to this structural interference, representation differences arise from linear combinations of multiple non-orthogonal concepts rather than clean, isolated axes 7. This interference creates sample-specific cylindrical geometries around individual data points. The CRH mathematically explains why simple linear steering occasionally fails when an intervention vector inadvertently falls into unpredictable sensitive sectors caused by local feature entanglement 79.
Simultaneous investigations applying Supervised Multi-Dimensional Scaling (SMDS) have revealed that the residual stream organizes features into complex multidimensional manifolds rather than uniform straight lines. Depending on the inherent semantic property of the data, features instantiate distinct geometric structures 3110. For example, numerical entities generally exhibit monotonic, pseudo-linear organizations, whereas cyclical temporal entities - such as days of the week or months of the year - form striking circular manifolds 3110. These structures actively reshape in response to contextual changes, supporting a model of entity-based reasoning where the transformer encodes and transforms structured representations rather than operating as a simple associative memory 31.
Mechanistic Interpretability Methodologies
To empirically validate these geometric hypotheses and map the computational circuits within the transformer, researchers have developed specialized toolkits designed to decode the intermediate computations of the residual stream. These methodologies rely heavily on analyzing the causal impact of the stream's additive components.
Logit Lens and Direct Logit Attribution
Because the residual stream acts as an accumulator that eventually culminates in the final token prediction, analysts can evaluate intermediate cognitive states using the Logit Lens 11. This technique extracts the residual stream vector at an early or middle layer and projects it prematurely through the model's final unembedding matrix 35. The Logit Lens reveals what the model believes the next token should be at any given intermediate depth, allowing researchers to track how predictions evolve, mature, and undergo revision as they propagate through the network . Variations like the Tuned Lens apply learned affine transformations at each layer to account for representation drift - the phenomenon where the basis of the residual stream shifts across depth - yielding lower perplexity and a more faithful reconstruction of intermediate semantic beliefs 12.
Direct Logit Attribution leverages the linear, additive nature of the residual stream to perform more granular analyses. Instead of projecting the entire composite residual state, this method isolates the discrete output vector of a single attention head or MLP block and projects only that individual component through the unembedding matrix 35. This isolates the sub-layer's independent contribution, quantifying precisely how much a specific mechanism influenced the final probability distribution of the output tokens .
Causal Interventions and Activation Patching
While probing and Logit Lens analyses successfully identify what information exists within the stream at a given layer, they are purely observational. They cannot mathematically prove that the model causally relies on that specific information to make its final decision 913. To establish strict causality, researchers rely on activation patching, also known as causal tracing or interchange intervention 91113.
Activation patching involves executing the model on two contrasting inputs - a clean prompt and a corrupted prompt. By systematically swapping the residual stream state, or the specific output of a single component, from the clean run into the corrupted run, researchers can observe whether the model's output distribution reverts to the correct answer 91113. If injecting an intermediate residual vector restores the correct behavior, it proves that the specific layer or subspace is causally responsible for the target computation 13. This method has been instrumental in discovering specific subgraphs within the network, such as the Indirect Object Identification circuit, which maps exactly how induction heads route factual knowledge across the residual stream to complete syntactic tasks 251338.
Sparse Autoencoders
To address the severe polysemanticity caused by the bandwidth bottleneck - where a single dimension in the residual stream responds to multiple unrelated features - researchers apply Sparse Autoencoders (SAEs) 113940. SAEs project the comparatively low-dimensional residual stream into a massively expanded latent space, often containing hundreds of thousands or millions of dimensions. The autoencoder applies an $L_1$ regularization penalty during training to enforce extreme sparsity 1139.
The theoretical objective is to disentangle the overlapping, superpositional features into highly interpretable, monosemantic directions where each feature activates solely in the presence of a single, human-understandable concept 540. While empirically successful at revealing hidden structures, SAEs remain computationally prohibitive to train on frontier models. Training robust dictionaries requires processing hundreds of petabytes of activation data and fitting trillions of total SAE parameters, meaning the interpretability tool often contains more parameters than the layers it interprets 41. Furthermore, replacing activations with their sparse reconstructions often degrades the model's performance, indicating that the assumption of perfectly linear, sparse representations may fail to capture the nonlinear nuances of the original neural computations 41.
The Representation-Behavior Gap
A critical open problem emerging from residual stream analysis - particularly concerning safety alignment and agentic tool use - is the representation-behavior gap. Extensive linear probing demonstrates that the residual stream reliably encodes necessary high-level knowledge or detects malicious intent with extreme precision, yet the model frequently fails to execute the corresponding behavioral output 914.
For instance, in clinical triage scenarios or tool-calling tasks, linear probes can extract correct intent or hazard representations from mid-layer residual streams with up to 99% accuracy 914. Despite this clean internal representation, the agent often acts conservatively, failing to cross the discrete decision threshold required to trigger the correct generation path, effectively creating a "Lazy Agent" failure mode 14. Similarly, in safety alignment research, probes demonstrate that early layers successfully detect harmful jailbreak queries embedded within ethical framing, but this accurate refusal signal is actively overridden by later instruction-following dynamics in the residual stream 43.
This gap suggests that the mere presence of decodable information in the residual stream is insufficient to guarantee execution 914. The causal pathways connecting these representations to the final output generation are fragile and heavily entangled. Mechanistic steering attempts, such as adding a static steering vector to the stream, often fail to close this gap due to geometric entanglement. Because features overlap in superposition, artificially amplifying one vector direction inevitably perturbs others, causing the model to veer out-of-distribution, trigger endogenous resistance circuits, or produce unpredictable hallucinations 89.
Dynamical Systems and Chaotic Flow
While algebraic and geometric perspectives dominate contemporary mechanistic interpretability, analyzing the residual stream through the rigorous lens of dynamical systems theory presents a formidable theoretical challenge to the linear steering paradigm. Treating the deep transformer as a discrete-time dynamical system allows researchers to measure Finite-Time Lyapunov Exponents, which quantify the rate at which initially close trajectories diverge over sequential iterations 844.
Recent mathematical analyses indicate that deep residual networks frequently operate in chaotic regimes characterized by positive Lyapunov exponents 845. In practical terms, this implies exponential sensitivity to initial conditions within the residual stream. Two latent vectors in the residual stream that are initially $\epsilon$-close can diverge exponentially within just $O(\log(1/\epsilon))$ layers under positive Lyapunov exponents 8.
This chaotic dynamic fundamentally undermines the assumption that applying a fixed linear steering vector at an early layer will predictably control the final output distribution. The exponential sensitivity characteristic of chaotic systems means that linear approximations become entirely unreliable across deep network architectures 8. This provides a robust theoretical explanation for why activation patching and representation engineering often exhibit brittle, sample-specific efficacy when applied to complex capabilities, and suggests that future interpretability interventions must account for the nonlinear, chaotic dynamics of the latent space 7846.
Architectural Innovations and Residual Flow Control
Recognizing the fundamental constraints of the standard residual stream bottleneck and the chaotic degradation of linear pathways, computer scientists have proposed several architectural modifications designed to expand cross-layer communication bandwidth, optimize flow dynamics, or compress states for distributed inference.
- KV Cache Compression and Route Rigidity: During autoregressive decoding, transformers store historical key and value matrices to avoid redundant computation. Because the residual stream satisfies a Markov property, future outputs depend on the input history only through the current residual vectors, meaning the KV cache carries no additional information beyond what is processed through the stream 15. Extreme KV compression techniques attempt to discard historical tokens, but research indicates this induces a structural phase transition in semantic reachability. Compression failures occur via representational erasure, where essential tokens are deleted across all heads, or representational rigidity, where tokens survive but the excessive consensus prevents flexible routing within the residual stream 1649.
- Multiway Dynamic Dense Connections: Standard dense connections use static weights to allow subsequent layers to directly access the outputs of preceding layers. Multiway Dynamic Dense (MUDD) connections generate dynamic connection weights depending on the hidden states of queries, keys, values, and residuals at each sequence position. This architecture functions as a depth-wise multi-head attention mechanism, expanding the cross-layer communication bandwidth far beyond the rigid constraint of a single residual stream, mitigating capacity overload in very deep models and enhancing downstream accuracy 1550.
- Residual Bottleneck Models: Designed specifically to support low-bandwidth pipeline parallelism across decentralized GPU clusters, Residual Bottleneck Models (ResBM) insert learnable autoencoder bottlenecks directly into the pipeline boundary. The model compresses the residual stream dimensionality substantially for transmission between discrete nodes, and decompresses it upon arrival 5152. Crucially, the bottleneck operates alongside the residual function, maintaining a low-rank identity path that preserves the optimizer stability of the original residual stream while achieving up to 128x activation compression without significant convergence loss 5152.
- Variational Information Bottlenecks: Used primarily for interpretability research rather than raw performance scaling, this methodology installs information bottlenecks immediately after attention heads, restricting the amount of data permitted to be written to the residual stream. By penalizing information flow, this forces the model to learn a spectrum of communication capacities, allowing researchers to observe exactly how global coordination degrades into independent patch-processing when residual stream bandwidth is artificially choked 5354.
Conclusion
The residual stream serves as the foundational anatomical structure enabling the profound, emergent capabilities of large language models. Operating as a high-dimensional, additive memory bus, it supports an intricate choreography of token routing, feature extraction, and knowledge retrieval, allowing attention heads and multi-layer perceptrons to progressively refine a shared state without succumbing to exponential gradient decay.
However, the stream is fundamentally constrained by its fixed dimensionality relative to the immense parametric volume of modern computational modules. This severe bandwidth bottleneck enforces complex geometries of dense superposition, prompting researchers to develop advanced mechanistic interpretability tools - from causal activation patching to sparse autoencoders - to untangle overlapping representations. Despite significant breakthroughs in mapping localized computational circuits and linear features, profound open problems remain. The representation-behavior gap and the inherent chaotic dynamics of deep residual state propagation highlight the limitations of current linear interpretability hypotheses. Advancing our understanding of the residual stream's geometric, information-theoretic, and dynamic properties will be essential for developing more efficient architectures, overcoming the limitations of current steering methodologies, and guaranteeing the safety, alignment, and reliability of future frontier artificial intelligence systems.