Vision transformers and attention mechanisms in computer vision
Introduction and the Architectural Shift
For nearly a decade, the field of computer vision was unequivocally dominated by Convolutional Neural Networks (CNNs). Architectures such as AlexNet, VGG, and ResNet established a paradigm where visual data was processed through localized, sliding-window filters 123. These networks operated on strong inductive biases - specifically translation equivariance and locality - which allowed them to learn feature representations highly efficiently even with moderately sized datasets. However, these same structural constraints inherently limited the ability of CNNs to model long-range, global dependencies across an entire image early in the network hierarchy 456.
In natural language processing (NLP), the introduction of the Transformer architecture by Vaswani et al. in 2017 revolutionized sequence modeling by replacing recurrent architectures with the self-attention mechanism 35. Self-attention allows a model to weigh the importance of all elements in a sequence simultaneously, granting it a global receptive field from the very first layer. Recognizing the scaling potential of this mechanism, researchers sought to determine whether the reliance on convolutional priors was strictly necessary for visual recognition tasks 18.
The seminal breakthrough occurred with the introduction of the Vision Transformer (ViT) by Dosovitskiy et al. (2020), presented at ICLR 2021 in the paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" 51. The research demonstrated that a pure transformer architecture, applied directly to sequences of image patches, could achieve state-of-the-art performance on image classification benchmarks when pre-trained on massive datasets 89. By discarding image-specific inductive biases in favor of large-scale data and flexible self-attention, ViT fundamentally shifted the trajectory of computer vision research. This transition catalyzed an intensive period of architectural innovation, leading to the development of data-efficient training recipes, hierarchical attention mechanisms, robust self-supervised learning paradigms, and entirely new state-space models designed to process visual data efficiently 362.
Mathematical and Architectural Mechanics
To understand how the attention mechanism conquered computer vision, it is necessary to examine the fundamental architecture of the Vision Transformer. The ViT model attempts to adapt the original NLP Transformer as closely as possible, treating image components identically to linguistic tokens to leverage existing scaling laws and optimized hardware implementations 211.
Patchification and Linear Embeddings
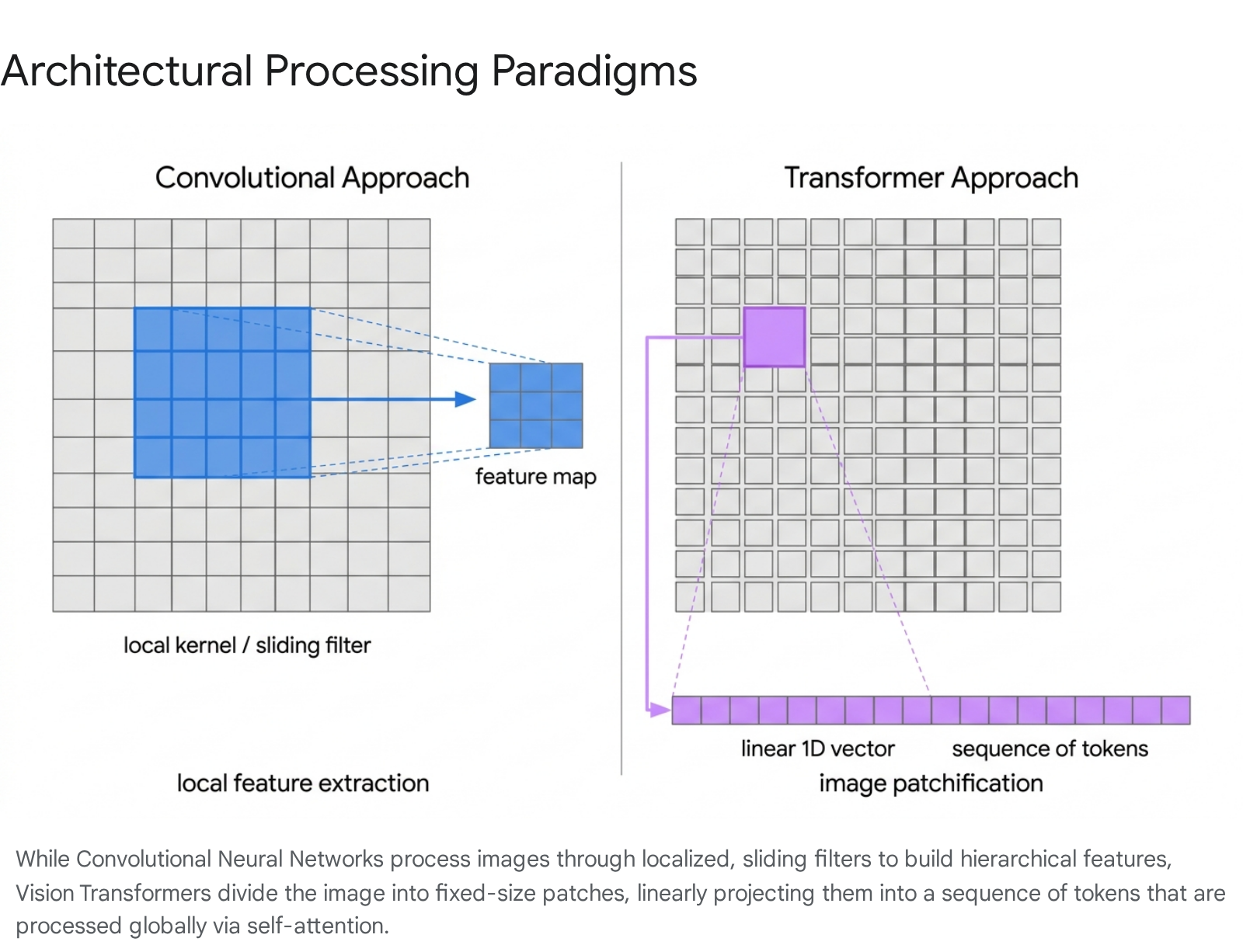
The primary challenge in applying transformers to images is the quadratic computational complexity of the self-attention mechanism with respect to sequence length 12. Computing self-attention across every individual pixel in a high-resolution image is computationally intractable, as the number of interactions would scale exponentially. To resolve this bottleneck, the Vision Transformer processes images by dividing them into a grid of non-overlapping, fixed-size patches 1314.
Given a standard input image with dimensions $H \times W \times C$ (Height, Width, and Channels), the image is divided into patches of size $P \times P$. The total number of resulting patches is calculated as $N = (H \times W) / P^2$ 15. For example, a standard $224 \times 224$ pixel RGB image divided into $16 \times 16$ patches yields a sequence of exactly 196 distinct patches 16.
Each $P \times P \times C$ patch is flattened into a one-dimensional vector. Because the standard transformer encoder expects inputs of a constant hidden dimension (denoted as $D$), a trainable linear projection layer is applied to these flattened vectors 15. This linear projection maps the raw pixel values into abstract mathematical spaces, resulting in a sequence of "patch embeddings" 318. This process effectively acts as the tokenization step for visual data, translating raw geometric image space into the sequential format required by the transformer.
Positional Encodings and the Class Token
Because the self-attention mechanism processes all tokens simultaneously, it is permutation-invariant; it possesses no inherent concept of sequence order or spatial geometry 318. If a Vision Transformer were fed the 196 patch embeddings without modification, it would be unable to distinguish whether a patch originated from the top-left corner or the bottom-right corner of the image, essentially viewing the image as an unstructured mathematical "bag of patches."
To inject spatial awareness back into the model, ViT adds learned one-dimensional positional embeddings to the patch embeddings prior to feeding them into the transformer encoder 318. These positional embeddings are vectors of the exact same dimensionality $D$ as the patch embeddings, and they are continuously updated during the training process via gradient descent alongside other network parameters 18. The direct summation of the patch embedding and the positional embedding ensures that the transformer has access to both the semantic content of the visual patch and its original spatial location 1416. During inference on higher resolution images, these positional embeddings can be interpolated via bicubic interpolation to maintain spatial coherence across a larger grid of patches 519.
Furthermore, to facilitate image classification, the ViT architecture explicitly borrows a technique from the BERT language model by prepending a special, learnable "class token" ([CLS]) to the sequence of patch embeddings 1415. As this token passes through the consecutive layers of the transformer, the self-attention mechanism allows it to aggregate global information from all other patches in the image. The final state of this [CLS] token at the output of the final transformer encoder layer serves as the holistic representation of the entire image, which is then fed into a standard Multi-Layer Perceptron (MLP) head to generate the final classification prediction 1618.
The Transformer Encoder
The core of the ViT architecture consists of a stack of identical transformer encoder blocks, operating linearly on the embedded sequence 15. Each block contains two primary sub-modules: a Multi-Head Self-Attention (MHSA) layer and a Multi-Layer Perceptron (MLP) block. Standard Layer Normalization is applied before every block to stabilize training, and residual (skip) connections are applied after every block to prevent the vanishing gradient problem 14.
The Multi-Head Self-Attention mechanism is the defining operational feature of the model. It projects the input embeddings into three distinct matrices: Queries ($Q$), Keys ($K$), and Values ($V$). Attention scores are computed by taking the scaled dot product of the Queries and Keys, which determines how strongly each patch should "attend" to every other patch. This means that from the very first layer, a patch in the top-left corner can aggregate contextual information directly from a patch in the bottom-right corner 1621. This global receptive field stands in stark contrast to traditional CNNs, which require many consecutive layers of pooling and convolution to gradually expand their effective receptive fields to cover the entire spatial domain of the image.
The Inductive Bias Dichotomy
The architectural differences between CNNs and Vision Transformers highlight a fundamental trade-off in machine learning architecture: the balance between inductive bias and data scale 421.
Texture Bias Versus Shape Bias
Inductive biases refer to the set of underlying assumptions a learning algorithm utilizes to predict outputs for inputs it has not previously encountered. Convolutional Neural Networks possess exceptionally strong spatial inductive biases 22. The convolution operation inherently assumes that nearby pixels are highly correlated (locality) and that a feature useful in one part of an image is likely useful anywhere else in that image (translation equivariance achieved via weight sharing) 2522. These hard-coded topological assumptions act as a powerful form of mathematical regularization, allowing CNNs to learn effective representations even when training data is relatively limited 3.
Vision Transformers, conversely, have minimal image-specific inductive bias 4522. Only the final MLP layers are local and translationally equivariant, while the self-attention layers are completely global from the outset 5. The network assumes absolutely nothing about the spatial relationship between patches; it must learn the underlying two-dimensional topological structure of the image entirely from the raw data correlations 22.
Interestingly, this lack of inductive bias leads to distinctly different feature representations. Empirical analysis by researchers such as Geirhos et al. (2019) and Hermann & Kornblith (2019) reveals that CNNs trained on datasets like ImageNet develop a pronounced "texture bias" 35. Due to the localized nature of their filters, a CNN will reliably classify an image of a cat with an elephant skin texture as an elephant 3. Vision Transformers, armed with global context, exhibit a much stronger "shape bias," aligning their recognition patterns closer to human visual cognition. This characteristic makes ViTs substantially more robust to natural image corruptions, domain shifts, and out-of-distribution adversarial data 35.
| Architectural Feature | Convolutional Neural Networks (CNNs) | Vision Transformers (ViTs) |
|---|---|---|
| Primary Operation | Localized sliding kernels with weight sharing | Global self-attention across flattened tokens |
| Inductive Bias Strength | High (Locality, translation equivariance) | Low (Must learn topological structure from data) |
| Receptive Field | Expands gradually in deeper layers | Global from the first layer |
| Representation Bias | Texture-biased (local high-frequency details) | Shape-biased (global structural coherence) |
| Corruption Robustness | Highly susceptible to local texture shifts | Highly robust to natural distribution shifts |
Data Regimes and Scaling Dynamics
Because ViTs lack the strict regularization provided by convolutional filters, they are notoriously sensitive to the volume of training data 3522. As reported by Dosovitskiy et al., when standard ViTs are trained on mid-sized datasets like ImageNet-1K (which contains approximately 1.28 million images), they tend to overfit and perform worse than comparable ResNets 35. The weak inductive bias becomes a significant liability because the model lacks the built-in constraints needed to parse complex visual structures from a limited sample size 226.
However, this paradigm reverses completely in the large-data regime. When trained on massive datasets like the public ImageNet-21k (14 million images) or Google's internal JFT-300M dataset (300 million curated images), large-scale training easily trumps inductive bias 3521. Freed from the strict, localized constraints of convolutional filters, the global self-attention mechanism discovers highly complex, long-range spatial relationships that CNNs fundamentally struggle to capture 23. Under these conditions, the largest models, such as ViT-Huge (632 million parameters) and scaling efforts approaching 22 billion parameters, achieve unprecedented accuracy, consistently surpassing state-of-the-art convolutional networks across nearly all recognition benchmarks 578.
This dynamic is equally evident in specialized domains like medical imaging. Studies utilizing digital pathology whole-slide images (WSIs) for tumor detection demonstrated that while ViTs possess more flexible feature detection capabilities, CNN baselines like ResNet18 often match or slightly outperform models like DeiT-Tiny when annotated pathological data is sparse 49. To surpass convolutional neural networks in low-data regimes like digital pathology, vision transformers require highly challenging tasks and massive downstream data to truly benefit from their weak inductive bias 49.
Democratizing Training with Data-Efficient Image Transformers (DeiT)
The reliance on hundreds of millions of images for effective pre-training posed a severe barrier to the widespread adoption of Vision Transformers outside of massive technology conglomerates 1011. To address this accessibility issue, Touvron et al. (2021) introduced the Data-Efficient Image Transformer (DeiT) 1930. The DeiT paper proved that highly competitive, convolution-free transformers could be trained entirely on the standard ImageNet-1K dataset using a single computer with 8 GPUs in under three days, without requiring any external data 1011.
Distillation Through Attention
The core architectural innovation of DeiT was a transformer-specific teacher-student knowledge distillation strategy 1930. Knowledge distillation involves training a smaller, efficient "student" model to perfectly mimic the output distributions and feature maps of a larger, pre-trained "teacher" model. The authors empirically discovered that using a strong CNN - specifically a RegNetY-16GF model with 84 million parameters - as the teacher yielded significantly better downstream performance than using a Transformer-based teacher 191130. The underlying hypothesis is that the CNN teacher mathematically imparts its strong, localized inductive biases to the ViT student during the distillation process, serving as a powerful regularizer 3012.
DeiT implements this interaction via a novel "distillation token." Functionally similar to the standard [CLS] token, the distillation token is appended to the input sequence and interacts globally with all patch tokens through the self-attention layers 191112. However, their optimization objectives diverge: while the [CLS] token is optimized using standard cross-entropy loss against the ground-truth dataset labels, the distillation token is explicitly optimized to reproduce the hard label predictions generated by the CNN teacher 12.
The authors demonstrated that "hard distillation" (matching the exact discrete prediction of the teacher) significantly outperformed "soft distillation" (matching the continuous probability distribution) 1930. This dual-token architecture allows the transformer to learn global context from the raw data while simultaneously inheriting the localized feature-extraction strategies of a convnet. The two tokens provide complementary information; combining their outputs yields a classifier significantly more accurate than either token independently 30. The resulting DeiT-Base model achieved 85.2% top-1 accuracy on ImageNet-1K, completely outperforming its own CNN teacher and closing the long-standing performance gap between transformers and CNNs in data-constrained regimes 1011.
Optimization and Augmentation Strategies
Beyond the architectural addition of the distillation token, DeiT heavily relied on intensive modern optimization and data augmentation strategies to prevent the characteristic overfitting of data-starved transformers. The training recipe utilized the AdamW optimizer paired with aggressive regularizations like Stochastic Depth, where deeper transformer layers have a linearly increasing probability of being randomly dropped during the forward pass 19. Furthermore, DeiT incorporates strategies like bicubic interpolation of positional embeddings when fine-tuning models at higher image resolutions (e.g., scaling from $224 \times 224$ to $384 \times 384$), allowing the model to adapt smoothly to varying input sizes without losing pre-trained spatial weights 191130.
Overcoming the Quadratic Bottleneck with Hierarchical Attention
While standard ViT and DeiT architectures excelled at image classification, their foundational design posed severe computational limitations for dense prediction tasks, such as object detection, instance segmentation, and high-resolution medical scanning. These tasks inherently require high-resolution inputs to accurately detect diminutive objects and delineate precise boundary masks.
The Computational Complexity of Global Attention
Because the standard self-attention mechanism computes the relationships between all possible pairs of tokens simultaneously, its computational complexity grows quadratically, denoted as $O(N^2)$, with respect to the number of image patches 121333. Given an image partitioned into $h \times w$ patches with a channel dimension of $C$, the computational complexity of standard global multi-head self-attention is calculated mathematically as:
$$\Omega(\text{Global MSA}) = 4hwC^2 + 2(hw)^2C$$
The presence of the $(hw)^2$ term indicates that feeding a high-resolution image into a standard ViT results in an exponential explosion in both memory consumption and processing latency 34. For example, processing a $1024 \times 1024$ image with standard $16 \times 16$ patches results in approximately 4096 tokens, necessitating nearly 16.7 million attention interactions per layer, rendering the model practically unviable for real-time dense recognition frameworks 3414.
Swin Transformer and Patch Merging
To fundamentally overcome this quadratic bottleneck, Liu et al. (ICCV 2021) introduced the Swin Transformer (Hierarchical Vision Transformer using Shifted Windows), which aggressively altered how self-attention is applied to visual data 1336. The Swin architecture reintegrates several highly effective convolutional priors - specifically hierarchical scale and localized processing - back into the pure transformer framework 612.
Unlike the original ViT, which rigidly maintains a single, fixed-resolution feature map throughout all layers, the Swin Transformer builds hierarchical feature representations identical in structure to a CNN 1337. It achieves this hierarchy through a dedicated "patch merging" operation. The network begins with very small patches (typically $4 \times 4$ pixels) and progressively merges $2 \times 2$ blocks of neighboring patches in deeper network stages, incrementally reducing the spatial resolution while simultaneously increasing the channel dimension 3437. This process results in a multi-scale pyramid of visual features, enabling the model to transition seamlessly from recognizing fine-grained local textures in early layers to understanding coarse, global semantic structures in deeper layers 1237.
Shifted Window Multi-Head Self-Attention
To directly address the computational cost, the Swin Transformer completely replaces global self-attention with Window-based Multi-Head Self-Attention (W-MSA). The feature map is partitioned into non-overlapping local windows (e.g., each containing $M \times M$ patches, where $M$ is typically 7), and self-attention is computed only within the boundaries of each isolated local window 121337. By restricting attention to a fixed window size of $M$, the computational complexity drops dramatically to:
$$\Omega(\text{Window MSA}) = 4hwC^2 + 2M^2hwC$$
This formula demonstrates that complexity drops from quadratic $O(N^2)$ to linear $O(N)$ with respect to the overall image size $hw$, providing massive efficiency gains 133334. However, restricting attention strictly to non-overlapping windows prevents the model from understanding the relationships between adjacent windows, destroying the global context that makes transformers uniquely powerful 3436.
To solve this isolation, the authors introduced the "Shifted Window" (SW-MSA) mechanism 11336. In alternating transformer layers, the window partitioning grid is shifted by a specific spatial offset (e.g., displacing the grid by $\lfloor M/2 \rfloor$ patches). This displacement effectively bridges the boundaries of the preceding layer's localized windows, enabling vital cross-window interactions and allowing information to propagate globally across the image over multiple sequential layers 1337.
| Feature | Standard Vision Transformer (ViT) | Swin Transformer |
|---|---|---|
| Attention Mechanism | Global Multi-Head Self-Attention | Windowed & Shifted Window Self-Attention |
| Complexity Formula | $4hwC^2 + 2(hw)^2C$ | $4hwC^2 + 2M^2hwC$ |
| Scaling Complexity | Quadratic $O(N^2)$ | Linear $O(N)$ |
| Feature Map Structure | Single-scale (Flat representation) | Hierarchical (Pyramid representation) |
| Primary Use Case | Image Classification (Large pre-training) | Dense Prediction (Detection, Segmentation) |
The introduction of the Swin Transformer was a watershed moment, rapidly accruing over 28,000 citations. It established the transformer as a truly general-purpose backbone capable of handling the extreme variations in scale required for computer vision. The Swin-Large model achieved 87.3% top-1 accuracy on ImageNet-1K, and its hierarchical design allowed it to dominate dense prediction benchmarks, reaching 58.7 Average Precision (AP) on the COCO object detection dataset and 53.5 mIoU on the ADE20K semantic segmentation benchmark, surpassing all prior state-of-the-art methods 7133615.
The Resurgence of Pure Convolutions
The meteoric rise of Vision Transformers and hierarchical models like Swin led some researchers to prematurely predict the obsolescence of convolutional architectures. However, the success of Swin indicated that convolutional priors - such as local windows, hierarchical resolution reduction, and translation invariance - remained deeply valuable for visual recognition tasks 6. This realization prompted a critical reevaluation within the research community: was the empirical superiority of ViTs solely due to the intrinsic power of the self-attention mechanism, or was it a byproduct of modernized architectural engineering and drastically superior training recipes developed over the previous five years?
ConvNeXt: Modernizing the Residual Network
In 2022, Liu et al. published "A ConvNet for the 2020s," challenging the dominance of transformers by systematically re-engineering a standard ResNet-50 entirely with standard convolutional modules 639. The resulting family of models, known as ConvNeXt, systematically imported the specific design decisions that made ViTs successful while strictly avoiding any attention mechanisms, testing the absolute limits of what pure convolutions could achieve 6440.
The ConvNeXt modernization process proceeded through several highly specific, empirically tested stages. At the macro design level, the stage compute ratio was adjusted to match Swin-Tiny (a 1:1:3:1 ratio), heavily concentrating computation in the third stage of the network 441. Furthermore, the standard ResNet stem - which traditionally utilized a heavy $7 \times 7$ convolution and max pooling - was replaced with a "patchify" stem utilizing a non-overlapping $4 \times 4$ convolution with a stride of 4, exactly mimicking the ViT and Swin patch embedding processes 44142.
The network then adopted depthwise separable convolutions to isolate spatial mixing from channel mixing, a core philosophy of self-attention 40. Crucially, ConvNeXt utilized unusually large convolution kernels (scaling up to $7 \times 7$) to simulate the larger global receptive fields of self-attention without incurring the quadratic computational cost 43940. The architecture also utilized an inverted bottleneck design (expanding the hidden dimension by a factor of 4 inside the block before projecting it back down), intentionally aligning with the MLP design found natively in all transformer encoders 442.
ConvNeXt V2 and Global Response Normalization
At the micro-level, the ConvNeXt engineering team replaced standard ReLU activations with the smoother GELU activation commonly used in NLP transformers. They substituted traditional Batch Normalization with Layer Normalization, and aggressively reduced the total number of normalization and activation layers per block, relying on a single activation per residual unit 43940.
The outcome of this purely convolutional redesign was staggering. The ConvNeXt models consistently outperformed their direct Swin Transformer counterparts across various complexities. ConvNeXt-Tiny achieved 82.1% accuracy compared to Swin-Tiny's 81.3%, while demonstrating a higher inference throughput of 774.7 images per second on V100 GPUs compared to Swin's 757.9 images per second 43941.
This trajectory continued with the ConvNeXt V2 iteration, which integrated Masked Autoencoder pre-training (FCMAE) to adapt self-supervised learning for convolutions. Because pure convolutions struggled with feature collapse during masked image modeling, ConvNeXt V2 introduced a novel Global Response Normalization (GRN) layer to enhance inter-channel feature competition 4016. This co-design pushed the pure ConvNet boundary even further, with the 650-million-parameter ConvNeXt-V2 Huge achieving an extraordinary 88.9% top-1 accuracy on ImageNet-1K using ImageNet-22K labels 716. This definitively established that carefully engineered convolutions can compete favorably with Transformers, retaining superior efficiency and deployment flexibility on modern hardware heavily optimized for standard CNN matrix operations 3940.
Self-Supervised Vision Foundation Models
As Vision Transformers grew exponentially in parameter count, the dependence on massive, meticulously labeled datasets like JFT-300M became a critical bottleneck for the industry. In natural language processing, models like BERT and GPT achieved revolutionary success not through supervised human labels, but through self-supervised pre-training on vast, unstructured corpuses of raw text. The computer vision community aggressively pursued similar foundational paradigms that could learn robust, transferable visual features without requiring exhaustive human annotation 444546.
Masked Autoencoders and Pixel Reconstruction
A major paradigm shift in visual self-supervised learning arrived with the Masked Autoencoder (MAE), introduced by He et al. (2021) 4748. Directly inspired by masked language modeling in NLP, MAE demonstrated that transformers could learn highly scalable, generalizable representations purely through aggressive pixel reconstruction 4649.
The MAE architecture relies on a uniquely asymmetric encoder-decoder design. First, an input image is patchified into standard tokens, but a staggeringly high proportion of the patches - specifically 75% - are randomly masked and discarded from the sequence 474850. The foundational logic of MAE rests on the realization that images contain massive spatial redundancy; if only 15% of an image is masked, a convolutional network can simply interpolate local pixel colors without understanding any underlying semantic content 50. By obliterating 75% of the image, the network is forced to learn deep, holistic representations of objects, boundaries, and geometry to accurately hallucinate the missing structures 50.
The heavyweight ViT encoder operates only on the 25% visible patches 4849. Because it ignores the masked tokens entirely, the computational load is drastically reduced, allowing massive architectures like ViT-Large and ViT-Huge to be trained efficiently on standard GPU setups 4850. The encoded visible patches and the blank mask tokens are then passed to a lightweight, highly efficient ViT decoder, whose sole objective is to reconstruct the original pixel values using a Mean Squared Error (MSE) loss function 4649. After the pre-training phase concludes, the decoder is discarded entirely, leaving a highly optimized encoder. A vanilla ViT-Huge pre-trained with MAE achieved 87.8% on ImageNet-1K, proving that visual systems can develop profound semantic understanding purely by learning to fill in the missing pieces of raw geometric data 474850.
DINOv2 and Discriminative Feature Learning
While MAE optimized generative, pixel-level reconstruction, researchers at Meta AI pursued a discriminative, feature-level approach to self-supervised learning. The original DINO (Self-Distillation with NO labels) model, released in 2021, demonstrated that ViTs trained via knowledge distillation naturally developed explicit, interpretable attention maps that precisely focused on semantic object boundaries 455152. This created an emergent object segmentation capability without any labeled supervision or bounding boxes 5152.
In 2023, Meta introduced DINOv2, aggressively scaling this paradigm to create a true, all-purpose foundation model for computer vision 531755. Recognizing that feature quality is inextricably linked to data quality, DINOv2 was trained on a meticulously curated, deduplicated dataset of 142 million diverse images (LVD-142M) rather than relying on uncurated, highly biased web scrapes 535556.
The DINOv2 training objective engineered a sophisticated combination of the global image-level distillation loss of the original DINO with the patch-level Masked Image Modeling (MIM) loss found in iBOT 555657. By forcing the student network to match the teacher network's representations at both the holistic image level (using cross-entropy via Sinkhorn-Knopp centering) and the highly granular masked patch level, DINOv2 learned features that are incredibly robust 4555.
Furthermore, DINOv2 incorporated the KoLeo regularizer to encourage a uniform span of patch embeddings across the feature hypersphere, thereby preventing feature collapse and ensuring rich semantic separation 455556. Unlike DINOv1, which shared a single projection head, DINOv2 utilized untied head weights for different objectives to specialize handling for different aspects of visual understanding 4555.
The ultimate result is a model capable of generating "all-purpose" visual features that perform at state-of-the-art levels across a vast array of complex downstream tasks - including fine-grained classification, monocular depth estimation, semantic dense matching, and zero-shot retrieval - without requiring any task-specific fine-tuning 44531757.
| Feature / Objective | DINOv1 (2021) | DINOv2 (2023) |
|---|---|---|
| Core Architecture | ViT-Base | Scaled up to ViT-Giant (ViT-g/14) |
| Training Data | Uncurated datasets | LVD-142M (Highly curated, deduplicated) |
| Loss Function | Image-level cross-entropy distillation | Image-level + Patch-level (iBOT) MIM loss |
| Regularization | Momentum encoder centering | Sinkhorn-Knopp centering + KoLeo regularizer |
| Emergent Capabilities | Semantic segmentation, object discovery | Monocular depth estimation, dense matching |
State Space Models and the Bidirectional Mamba Architecture
As the timeline advances into 2024 and 2025, the computer vision research community is actively exploring novel architectures that completely bypass both the localized, rigid constraints of CNNs and the quadratic computational bottleneck inherent to Transformers. The most prominent and aggressive development in this space is the adaptation of State Space Models (SSMs), specifically the Mamba architecture, to multidimensional visual data 21458.
The Adaptation of State Space Models to Visual Data
Mamba originally gained massive traction in NLP sequence modeling by offering an input-dependent selection mechanism and a hardware-aware parallel scan that theoretically achieves strictly linear time complexity ($O(N)$) while maintaining infinite context length 214. However, applying Mamba's continuous state-space equations ($h'(t) = Ah(t) + Bx(t)$) to vision tasks poses a profound mathematical challenge: SSMs process one-dimensional data strictly causally (from left to right), whereas two-dimensional images contain non-causal, deep spatial relationships in all cardinal directions 145918.
To resolve this dimensional conflict, two highly concurrent models emerged. The Vision Mamba (Vim) model utilizes Bidirectional Mamba blocks, processing the flattened sequence of image patches both forward and backward using dedicated 1D convolutions for each direction. This allows the model to capture bidirectional context effectively without relying on self-attention 258611963. Simultaneously, the VMamba (Visual State Space Model) introduced the Cross-Scan Module (CSM), which actively traverses the spatial domain in four distinct sweeping directions to convert non-causal 2D visual data into ordered sequences 21459.
These SSM-based vision models effectively maintain the global receptive field characteristics of ViTs but mathematically execute with the linear scalability of CNNs. As a result, Vim is significantly faster and more memory-efficient than comparable transformers; empirical testing proves that when performing batch inference on high-resolution $1248 \times 1248$ images, Vim is 2.8 times faster than DeiT while drastically reducing GPU memory consumption by 86.8% 58591964.
Hybrid Innovations: MambaVision
Pushing the architectural boundaries further, NVIDIA researchers introduced MambaVision at CVPR 2025. This architecture hybridizes the strengths of multiple paradigms, integrating CNN feature extraction with selective SSMs and Transformer-style components 18206621.
MambaVision recognizes that pure SSMs can suffer from unstable contextual learning 66. To mitigate this, the architecture utilizes multi-resolution CNN-based residual blocks in the early stages (Stages 1 and 2) to rapidly extract localized fine-grained textures and structural features 186621. In the deeper network stages (Stages 3 and 4), MambaVision deploys specialized MambaVision Mixer blocks that combine Structured SSMs with Transformer attention blocks to capture both short- and long-range dependencies efficiently 1821.
This hybrid integration allows MambaVision to achieve a new Pareto front for accuracy and throughput 2168. The model consistently demonstrates superior data efficiency, performing exceptionally well in complex tasks like 3D lane detection for autonomous driving and highly fine-grained agricultural disease classification 1866. The massive MambaVision-L3 variant (739.6 million parameters) achieved 88.1% top-1 accuracy on ImageNet-1K, indicating that the future of computer vision backbones may not belong to a single, monolithic paradigm, but rather to highly optimized integrations of convolutions, state space models, and attention mechanisms 2168.
Empirical Benchmarks and Architectural Trade-Offs
To synthesize the vast landscape of foundational vision models and their empirical impact, the following table summarizes the peak performance metrics on the industry-standard ImageNet-1K image classification benchmark.
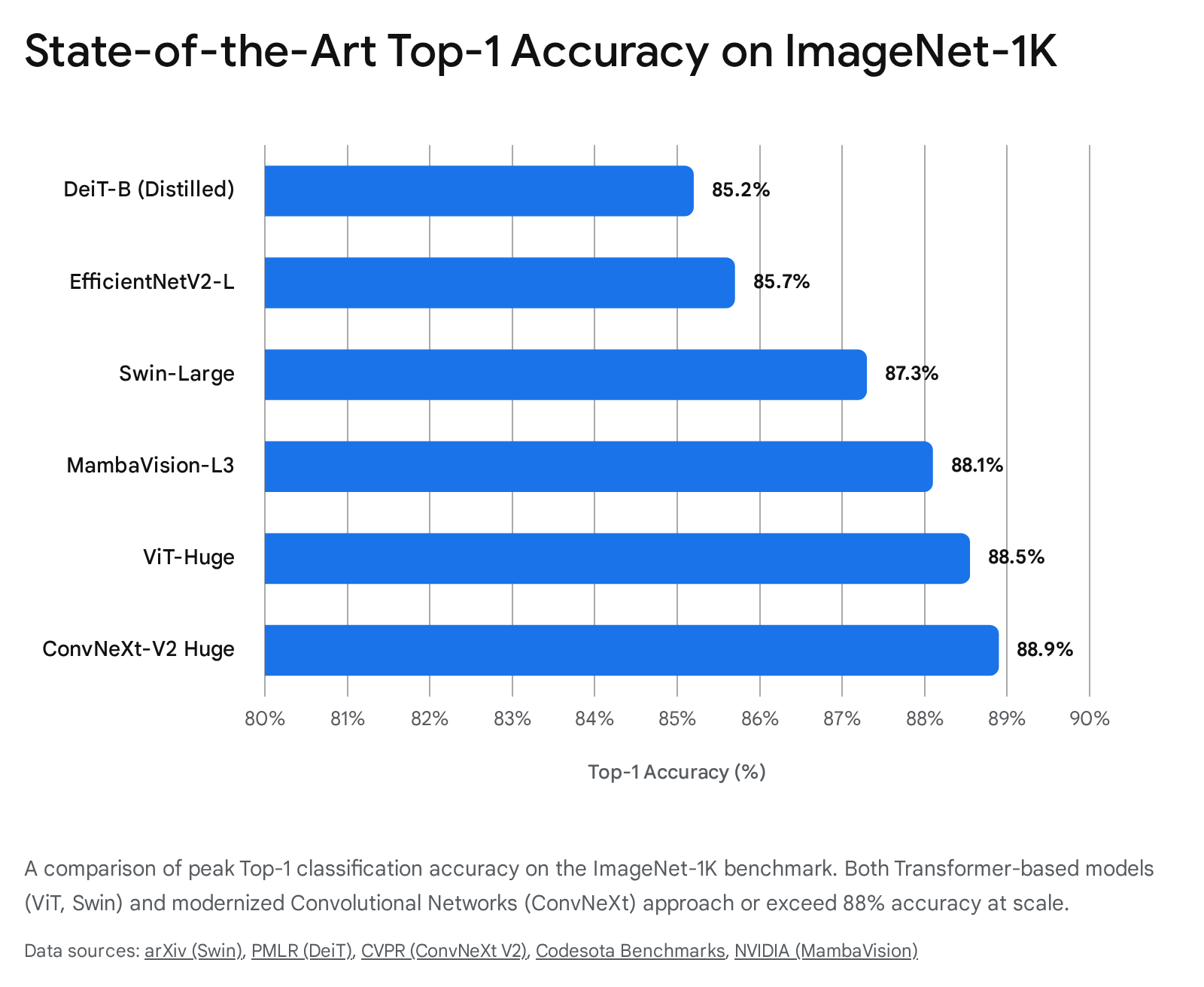
This highlights the tight competitive grouping among state-of-the-art models developed over the last few years 57101668.
| Model Name | Architectural Paradigm | Top-1 Accuracy (ImageNet-1K) | Pre-training Strategy | Key Characteristic |
|---|---|---|---|---|
| ResNet-50 | Traditional CNN | 76.1% (Baseline) | Supervised | Localized hierarchical filters |
| DeiT-Base⚗ | Distilled Transformer | 85.2% | ImageNet-1K Only | Distillation token via CNN teacher |
| EfficientNetV2-L | Compound Scaled CNN | 85.7% | ImageNet-21K | Balance of accuracy and deployability |
| Swin-Large | Hierarchical Transformer | 87.3% | ImageNet-22K | Shifted-window linear complexity |
| MambaVision-L3 | Hybrid SSM-Transformer | 88.1% | ImageNet-21K | New CVPR 2025 Pareto front |
| ViT-Huge / 14 | Pure Transformer | 88.55% | JFT-300M / LAION | Requires massive scale and compute |
| ConvNeXt-V2 Huge | Modernized CNN | 88.9% | FCMAE (Masked Autoencoder) | Proves CNNs remain SOTA |
Conclusion
The ascendance of the attention mechanism in computer vision, heralded irrevocably by the Vision Transformer, fundamentally reshaped the field's underlying mathematical understanding of inductive bias, data scale, and architectural design space. By proving that algorithms completely free from rigid convolutional priors could learn profound, global spatial relationships when supplied with sufficient data, ViTs established a new upper bound for visual recognition performance and robustness.
However, the rapid evolution of the field over the subsequent years illustrates that true architectural innovation does not occur through the sheer replacement of older techniques, but through dialectical synthesis. The quadratic computational constraints of pure attention forced the reintegration of convolutional concepts like localized windows and hierarchical scale mapping, successfully manifesting in the Swin Transformer. The empirical success of ViTs simultaneously inspired the systematic modernization of pure convolutions in the ConvNeXt architecture, proving that architectural design spaces are vast and highly sensitive to micro-level engineering choices. Furthermore, the relentless industrial demand for unannotated scaling gave rise to transformative self-supervised learning paradigms like Masked Autoencoders and DINOv2, allowing models to develop deep semantic understanding through pure pixel reconstruction and self-distillation techniques.
As the field pushes into 2025 and beyond, the emergence of State Space Models like Vision Mamba and hybrid frameworks like MambaVision heavily suggest that the ultimate quest for architectures seamlessly balancing global receptive fields with linear computational efficiency is far from over. The future of computer vision relies not on a single monolithic algorithm, but on the precise, task-specific integration of convolutions, attention mechanisms, and state spaces.