How to Test an AI Trading Strategy
Backtesting evaluates an algorithm's historical performance on past data, paper trading simulates execution in live markets using real-time data but virtual money, and forward testing validates the strategy over time with real capital and actual market friction. Together, these three phases form a mandatory graduation pipeline that exposes critical mathematical and operational flaws - such as overfitting, look-ahead bias, and latency - before an artificial intelligence strategy can safely manage significant live capital.
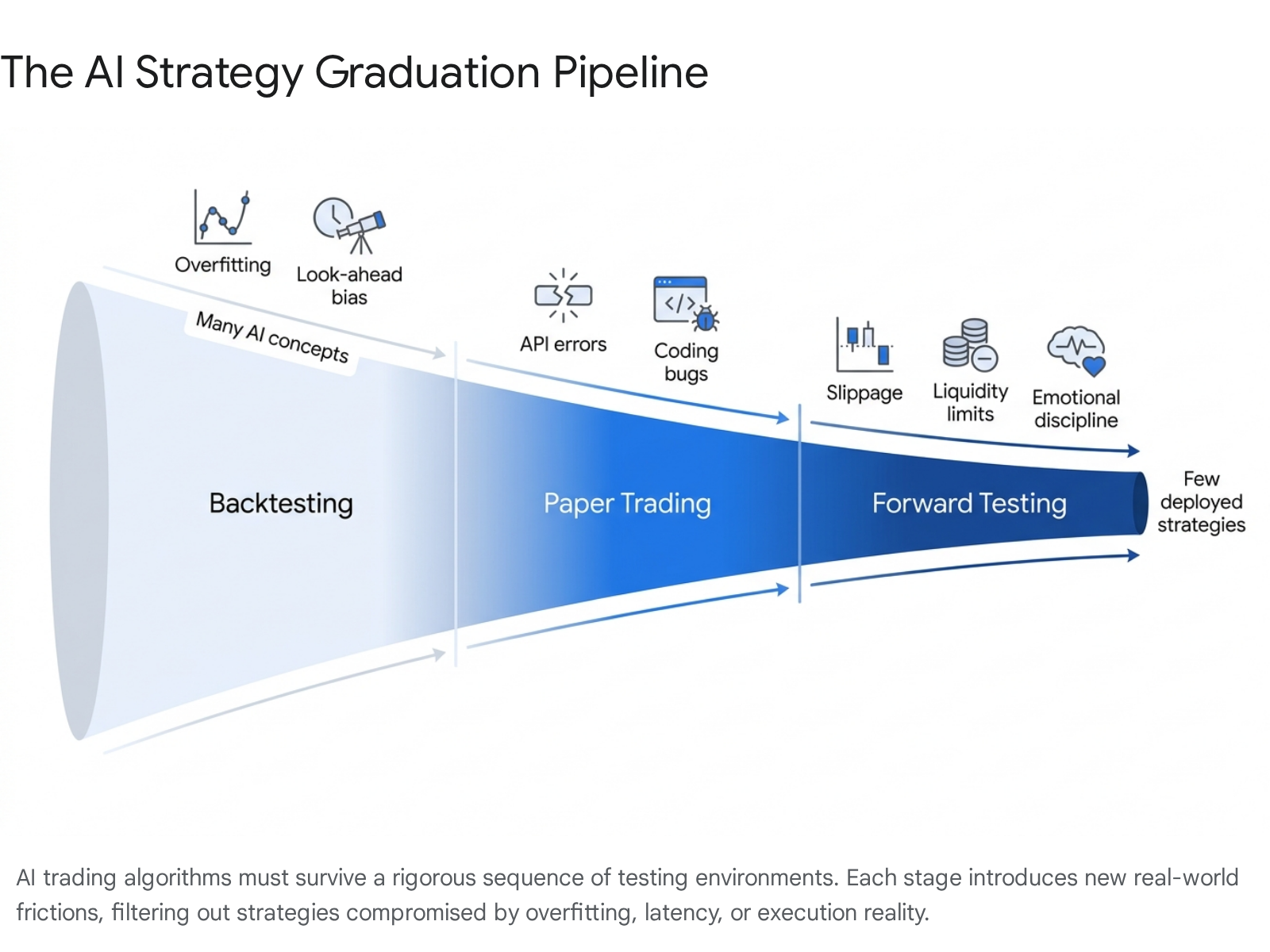
The Algorithmic Strategy Graduation Pipeline
The most common misconception among new quantitative developers and retail traders is that a highly profitable historical simulation guarantees future wealth. In reality, modern financial markets are complex, adversarial, and fundamentally non-stationary environments. Strategies that appear to be flawless money-printing machines on a computer screen frequently hemorrhage cash when exposed to real-world friction 112.
To bridge the dangerous gap between theoretical mathematics and live market environments, institutional quants and sophisticated algorithmic traders rely on a strict validation ladder. This multi-stage process is designed to ensure an artificial intelligence (AI) or machine learning model possesses a genuine statistical edge, rather than just a lucky streak discovered through aggressive data mining 456.
Backtesting: The Historical Sandbox
Backtesting is the foundational process of applying a trading strategy's logic to historical market data to observe how it would have performed in the past 273. At its core, backtesting answers a fundamental historical question: "Did this specific market logic make sense yesterday?"
Because backtesting requires no live execution and relies entirely on archived data, it is incredibly fast and computationally scalable. A deep reinforcement learning (DRL) agent or a quantitative algorithmic script can simulate thousands of trades across decades of stock, forex, or cryptocurrency data in a matter of hours or even minutes 157. This speed allows developers to filter out structurally weak ideas rapidly. If an AI model cannot generate a consistent profit on historical data spanning various market regimes - including raging bull markets, protracted bear markets, and volatile sideways consolidation - it has no business trading live capital 73.
However, backtesting operates in a frictionless, theoretical vacuum. It inherently fails to account for the harsh realities of live markets, such as delayed order execution, liquidity gaps, or the psychological pressure of managing real money during a drawdown 27. Furthermore, historical backtesting is highly susceptible to data-mining biases, where developers accidentally design a system that is perfectly optimized for past anomalies but entirely blind to future market behavior 910.
To mitigate these risks, professional developers rarely rely on a simple, single-pass backtest. Instead, they employ "walk-forward validation" and "out-of-sample" testing. In a walk-forward analysis, the historical data is divided into multiple segments. The AI model is trained (optimized) on an "in-sample" data window, and its performance is immediately tested on a subsequent, unseen "out-of-sample" data window 1011. This rolling process prevents the algorithm from simply memorizing the entire dataset, providing a much more rigorous assessment of how the strategy might adapt to future, unknown conditions 1112.
Paper Trading: The Live Execution Simulation
Once a strategy survives historical backtesting and walk-forward validation, it progresses to paper trading. Paper trading - sometimes referred to as simulated trading - involves feeding the algorithm live, real-time market data, but executing "simulated" trades without risking actual capital 71314.
While retail traders often view paper trading as a way to practice, quantitative developers view it primarily as an infrastructure and execution test. This phase reveals operational execution gaps that historical data completely hides 415. For example, paper trading verifies that your software communicates smoothly with broker Application Programming Interfaces (APIs), accurately reads live order books, processes websocket data streams without crashing, and triggers safety mechanisms like stop-losses correctly in real-time 161718.
Yet, paper trading remains an illusion of actual trading. Because your simulated orders do not actually hit the exchange's matching engine, they do not impact the market. In a paper trading simulation, a massive order to buy an illiquid micro-cap stock or a niche cryptocurrency altcoin might get "filled" instantly at the perfect quoted price 1415. In the real world, that exact same order would eat through the available liquidity in the order book, driving the price up against you and resulting in severe execution slippage 1415. Consequently, paper trading is excellent for verifying code stability, but it consistently overstates expected profitability.
Forward Testing: The Real-World Crucible
Forward testing is the ultimate reality check for any algorithmic strategy. It involves running the trading bot in live market conditions, utilizing real - albeit usually minimal - capital to observe how the logic performs when actual money is on the line and market mechanics fully apply 2473.
Forward testing answers the most vital question in quantitative finance: "Can this strategy survive today's market behavior, complete with its unique frictions?" 2. By putting real capital at risk, traders are forced to confront the triad of live market friction: slippage, transaction costs, and platform latency 31419.
If an AI strategy passes the historical backtest but fails spectacularly in paper trading, the problem is usually related to coding bugs, real-time data ingestion errors, or API latency. However, if a strategy passes paper trading but slowly bleeds capital in forward testing, the strategy likely possesses a fundamentally flawed cost model or cannot handle the friction of actual liquidity constraints and spread costs 4. Only after an algorithm demonstrates stability and profitability in forward testing is it gradually scaled up to manage larger portions of a portfolio.
Testing Methods Comparison
| Feature | Backtesting | Paper Trading | Forward Testing |
|---|---|---|---|
| Data Type | Historical (Past archives) | Live (Real-time feeds) | Live (Real-time feeds) |
| Financial Risk | None | None | Low to High (Real capital at stake) |
| Execution Reality | Perfect (Frictionless, instant fills) | Simulated (Often ignores liquidity constraints) | Real (Slippage, latency, broker fees apply) |
| Time Required | Minutes to Hours | Days to Weeks | Weeks to Months |
| Primary Goal | Validate logic, filter weak ideas, tune parameters | Test API stability, verify live code execution | Prove live profitability, validate cost and slippage models |
Why AI Strategies Fail the Reality Check
Despite the immense processing power of artificial intelligence and the proliferation of accessible algorithmic platforms, an estimated 90% of algorithmic traders fail to achieve long-term profitability 7. This paradox stems from the fact that financial markets are not closed, predictable, deterministic systems like video games or chess boards. They are highly adversarial environments driven by collective human psychology, sudden geopolitical events, and macroeconomic shifts 120.
When AI models fail in live trading, it is rarely due to a simple syntax error in the code; it is almost always a fundamental failure of quantitative methodology. Developers routinely fall into traps that make their models look brilliant in a laboratory but hopelessly fragile in the wild.
Overfitting and the Data Starvation Problem
Overfitting - often referred to as curve-fitting - is the single most common cause of algorithmic failure 162122. It occurs when an AI model is trained so rigidly on historical data that it essentially memorizes past noise rather than learning general, repeatable predictive principles 11620.
Deep Reinforcement Learning (DRL) algorithms, such as Proximal Policy Optimization (PPO), Advantage Actor Critic (A2C), and Deep Deterministic Policy Gradient (DDPG), are incredibly powerful at finding hidden patterns and optimizing reward functions 2324. However, these algorithms were largely designed for environments with infinite replayability, like robotics simulations or board games. Financial data, by contrast, is severely limited and "sample-starved" 1.
If you train a deep neural network with millions of adjustable parameters on 20 years of daily stock data, you only have about 5,000 data points (daily candles) to work with 1. A complex model will effortlessly curve-fit itself to this tiny dataset. It might learn that buying exactly three days after a 2% drop on a Tuesday in October yields a profit, effectively memorizing the 2008 financial crisis or the 2020 COVID-19 crash 1. The resulting backtest will look like a flawless, upward-trending equity curve. But once deployed in live markets, the strategy immediately collapses because the exact historical conditions it memorized are non-stationary and will never exactly repeat 162122.
The Multiple Testing Problem and the Deflated Sharpe Ratio
The ease of modern computing compounds the overfitting problem through the "multiple testing problem." Today, an AI model or a researcher can test millions of variable combinations - different moving average lengths, various stop-loss percentages, diverse profit targets - in a matter of hours 2526.
If you test enough random, purely nonsensical strategies, basic probability dictates that you will eventually find one that generated massive historical returns purely by chance. A researcher might test 10,000 strategies, discard the 9,999 that failed, and present the single winner as a brilliant AI discovery. This introduces massive selection bias.
To combat this illusion, quantitative researchers David H. Bailey and Marcos López de Prado developed the Deflated Sharpe Ratio (DSR) 274. The standard Sharpe Ratio is the most widely used metric in finance for measuring risk-adjusted returns, calculated by dividing the historical excess returns by the volatility of those returns 29. However, the standard Sharpe Ratio assumes a normal distribution of data and implicitly assumes that only a single strategy was tested.
The DSR mathematically penalizes the performance metrics of a backtest to account for three major inflationary factors: 1. Selection Bias: It deflates the score based on the number of independent trials (variations) the AI tested before picking the winner. The more tests you run, the higher the hurdle for statistical significance 26430. 2. Non-Normal Returns: Financial returns are rarely bell curves; they exhibit skewness (asymmetrical returns) and fat tails (extreme, unexpected events). The DSR integrates higher moments of probability (skewness and kurtosis) to correct the uncertainty around the Sharpe estimate 26430. 3. Sample Length: It adjusts for the length of the backtest, recognizing that a high return over three months is vastly less reliable than a high return over a decade 430.
By applying the Deflated Sharpe Ratio, institutions act as statistical lie-detectors, revealing whether an AI's high returns represent a genuine market edge or just the result of data-mining thousands of random iterations until a statistical fluke emerged 2630.
Look-Ahead Bias and Causality Leaks
Look-ahead bias is an insidious and fatal flaw where an AI model accidentally uses future information to make a decision in the past during a backtest 931.
Because backtesting software loads entire historical datasets into memory simultaneously, poorly written code can easily peek ahead 32. This is incredibly common when using Large Language Models (LLMs) like ChatGPT or GitHub Copilot to write trading scripts. The AI assistant will generate code that compiles flawlessly with no syntax errors, but the code silently violates chronological causality 31.
A classic example involves calculating an intraday stop-loss using the daily Average True Range (ATR) 31. The daily ATR is mathematically derived from the asset's final High, Low, and Close prices, which are only finalized at the market close (e.g., 4:00 PM). If an algorithmic trading bot accesses that specific ATR value to execute a trade and set a dynamic stop-loss at 9:30 AM during a simulation, it is effectively looking into the future to size its risk based on volatility that has not yet occurred 31.
Other common sources of look-ahead bias include using Pandas shift(-1) commands that pull future rows into current calculations, or applying feature normalization (like Z-scores) across an entire dataset before splitting it into training and testing sets, thereby leaking future data into the past 123132.
This creates a backtest with an artificially high win rate and unrealistically low drawdowns 31. However, in live forward testing, look-ahead bias is immediately exposed because the future data simply does not exist yet to be queried. The algorithm is forced to use real-time, incomplete data, resulting in severely mismatched trade entries and immediate capital loss 931.
Survivorship Bias
Survivorship bias occurs when a backtest only evaluates assets that are currently active and successful, ignoring companies or tokens that went bankrupt, were delisted, or failed during the historical period 10. For example, testing an AI stock-picking algorithm on the current S&P 500 will yield artificially high returns because the index today only contains the "survivors." The algorithm is not tested against the hundreds of companies that plummeted to zero and were removed over the last twenty years. Reputable institutional data feeds provide point-in-time, delisted data to ensure models learn how to navigate failures, not just enduring successes 10.
Execution Frictions: Slippage, Latency, and Market Impact
Even a perfectly modeled, statistically robust AI strategy can fail due to the physical and mechanical friction of moving real money through exchange infrastructure. Backtests operate in a theoretical vacuum; live markets operate on physical servers with limited buyers and sellers.
The True Cost of Slippage
Slippage is the quantifiable difference between the expected price of a trade generated by a signal and the actual execution price achieved in the market 131633.
In a backtest, if an AI signals a buy order at $100.00, the simulation software typically logs the purchase at exactly $100.00. In reality, order books have finite depth. If an algorithm attempts to buy 1,000 shares, there might only be 200 shares available at $100.00. The remaining 800 shares must be bought at higher prices as the order eats through the available limit orders - perhaps filling at an average price of $100.15 155.
While 15 cents seems trivial, automated algorithms often trade hundreds of times a day aiming for small margins. Across thousands of trades, these fractional slippage costs compound relentlessly, turning a strategy that is wildly profitable on paper into a net-negative system in real life 131622. Paper trading platforms often fail to replicate this accurately, assuming perfect fills, which is why forward testing with real capital is required to calibrate an algorithm's true cost model 415.
Network Latency and AI Inference Delays
Latency is the time delay involved in transmitting data from the exchange to your system, processing it, and sending an order back 3335. In algorithmic environments, speed dictates access to liquidity.
High-frequency trading (HFT) firms operate on the scale of microseconds (millionths of a second) and nanoseconds, spending millions of dollars to co-locate their servers physically inside the exchange data centers to reduce fiber-optic cable distance 353637. They require latencies well under 100 milliseconds to function, capturing tiny price discrepancies before anyone else can react 3537.
Retail AI bots face a severe structural disadvantage here. This latency friction is particularly devastating when attempting to use complex generative AI, like Large Language Models (LLMs), as direct execution agents. Processing a complex market snapshot through a deep LLM can take two to four seconds of inference time 25. In highly volatile environments like cryptocurrency, prices can swing 3% to 5% during a sudden liquidation cascade in the time it takes the AI to "think" 25. The LLM ultimately makes decisions based on stale data, executing orders exactly when the market has already moved.
This was highlighted in extensive experiments testing LLMs against deterministic, rule-based systems in live crypto execution. Across 24,000 experimental trades, rule-based systems reacting in milliseconds unambiguously outperformed AI models attempting direct execution, because the AI's inference delay negated any analytical advantage 25. Consequently, sophisticated developers separate their architecture: AI belongs in the research lab for strategy development and pattern discovery, while lightweight, deterministic code handles the millisecond-level live trade execution 25.
Market Impact and Learning Externalities
Market impact refers to the effect a trader's own order has on moving the asset's price 1622.
Advanced academic research into Deep Reinforcement Learning reveals a severe complication called a "learning externality" when multiple AI agents operate in the same market environment. In partial-equilibrium backtests, an AI acts as a price-taker, assuming its actions do not alter the historical timeline 6. However, in a live equilibrium environment, prices respond endogenously to demand.
When multiple AI bots execute trades, their combined orders inject noise into the order flow. The exploratory trades of one AI alter the environment and contaminate the pricing signals for others 6. Because the AI agents cannot differentiate between fundamental market moves and the noise created by competing algorithms, their ability to learn becomes impaired. A strategy that worked perfectly in an isolated backtest degrades substantially because the collective interaction of algorithms dampens market efficiency and creates chaotic feedback loops 6.
How Asset Classes Dictate AI Strategy
The viability of an AI strategy is deeply intertwined with the specific asset class it targets. An algorithm built for US Equities cannot simply be ported over to the Cryptocurrency or Forex markets, as the underlying market microstructure, liquidity profiles, and operational hours differ vastly 3940.
| Market Characteristic | US Equities (Stocks) | Cryptocurrency | Foreign Exchange (Forex) |
|---|---|---|---|
| Market Hours | Defined sessions (e.g., 9:30 AM - 4:00 PM EST), limited after-hours 40. | 24/7/365 continuous trading globally 53940. | 24 hours a day, 5 days a week (24/5) 407. |
| Liquidity & Slippage | High for large-caps (Apple, Microsoft); low for small-caps, resulting in variable slippage 3940. | Highly fragmented. Deep for Bitcoin/Ethereum, very shallow for altcoins causing extreme slippage 3942. | Deepest liquidity globally (trillions daily). Minimal slippage on major pairs (EUR/USD) 3942. |
| Volatility Profile | Low to medium. Blue-chips typically move 1-3% daily. Circuit breakers exist 394042. | Extreme volatility. 5-10% daily moves for majors, 20%+ for altcoins. No market halts 394042. | Low volatility. Major pairs move 0.5-1% daily. Driven by macroeconomic data 4042. |
| Algorithmic Focus | Statistical arbitrage, momentum, earnings sentiment, HFT 37. | Trend following, cross-exchange arbitrage, managing smart-contract risk 3940. | Mean reversion, scalping tight spreads, macro-economic event trading 4243. |
Cryptocurrency: The 24/7 Volatility Engine
Crypto markets never close, which is highly appealing for algorithmic automation, as bots do not need sleep 3944. However, the market is highly fragmented across dozens of decentralized and centralized exchanges, meaning liquidity is not pooled in one central venue 539. While this creates opportunities for cross-exchange arbitrage, it also means altcoins suffer from shallow order books 39. An AI bot trading a mid-cap altcoin may face massive slippage and structural risks, such as exchange API outages during high-volatility events like a Bitcoin flash crash 41739.
Forex: Deep Liquidity and High Leverage
The Foreign Exchange market trades over $7.5 trillion daily, offering unparalleled liquidity for major pairs like the EUR/USD 42. This massive scale means slippage is generally minimal, making it an ideal environment for low-latency, high-frequency scalping algorithms 404243. Because currency pairs are less volatile than stocks (moving less than 1% a day), Forex brokers offer massive leverage (up to 1:2000 in some jurisdictions) 4042. While this allows algorithms to amplify tiny price discrepancies into significant profits, a minor flaw in the AI's risk management or stop-loss coding can result in rapid, total account liquidation 3342.
US Equities: Regulated Structure and Sentiment
Equities are highly structured, operating within defined market hours and protected by regulatory circuit breakers 3940. Liquidity is deep for mega-cap tech stocks but thins out considerably in small-cap markets. AI algorithms in equities frequently rely on analyzing corporate fundamentals, SEC filings, and quarterly earnings reports 3745. Because equities are heavily influenced by news and executive communications, they are currently the prime target for advanced LLM sentiment analysis.
LLMs and the Shift in Financial Sentiment Analysis
While Large Language Models struggle with the latency required for direct high-frequency execution, they are revolutionizing Target-Based Financial Sentiment Analysis (TBFSA) 8479.
Historically, quantitative funds used dictionary-based Natural Language Processing (NLP) to read news articles. These systems simply counted the number of "positive" words (e.g., growth, profit) versus "negative" words (e.g., loss, decline) to generate a trading signal 1011. However, financial language is highly contextual; the phrase "inflation expectations dropped" contains the word "dropped" (usually negative), but in context, it is a bullish macroeconomic signal.
Traditional NLP suffers heavily from "concept drift," requiring constant manual updates to dictionaries to understand evolving market narratives 10. Recent research from 2024 and 2025 demonstrates that generative LLMs - such as OpenAI's ChatGPT-4o, DeepSeek-R1, Meta's Llama-3, and specialized models like FinBERT - vastly outperform older methods 454751.
In comprehensive tests analyzing Bloomberg news articles and central bank communications, advanced LLMs demonstrated superior ability to capture nuanced sentiments, detect corporate biases, and extract economically relevant information without requiring extensive, expensive task-specific fine-tuning 471151. By integrating these LLM sentiment signals into traditional quantitative frameworks (like SVM or LSTM models), institutional traders are achieving significantly higher accuracy in forecasting market volatility and stock return drift in the days following an earnings call 1051. In this workflow, the AI acts as an elite, high-speed research analyst, while deterministic algorithms execute the resulting trades 5112.
Evaluating AI Agents: The Threat of Non-Stationarity
Despite successes in sentiment analysis, unleashing fully autonomous, agentic AI bots to trade live markets remains highly experimental. Markets suffer from non-stationarity - the statistical rules of the game change unpredictably as macroeconomic regimes shift 1144.
An AI algorithm trained extensively during a prolonged, low-interest-rate bull market will learn that buying every minor dip is highly rewarded 1617. When the macroeconomic regime suddenly shifts to a high-inflation, high-interest-rate bear market, those learned behaviors become toxic 1617. The rules the AI optimized for no longer exist.
Sophisticated institutional algorithms address this through regime detection filtering. They utilize advanced statistical tools, such as Hidden Markov Models (HMM), the Hurst exponent, or volatility clustering metrics (ATR, ADX), to continuously assess the current market state 1743. If the regime detector concludes that the market has shifted from a persistent trend into chaotic, sideways chop, it overrides the primary trading algorithm, forcing the bot to stay flat and preserve capital until favorable conditions return 1743.
Without these overarching rule-based constraints, autonomous AI agents struggle. In a recent rigorous experiment known as the "Alpha Arena," researchers gave six leading LLMs $10,000 each to trade cryptocurrency autonomously, relying solely on raw quantitative data 12. The results were sobering. The models exhibited inconsistent reasoning, traded excessively, and demonstrated weak risk discipline. Ultimately, four of the six LLMs lost more than 30% of their capital, proving that unconstrained language-model reasoning is not yet a substitute for robust, mathematically grounded risk management 112.
The Psychological Shift: Why Paper Profits Evaporate
Even when an AI strategy is technologically sound, the transition from paper trading to live forward testing often fails due to the reintroduction of human psychology.
Paper trading is fundamentally a frictionless sandbox; it removes consequence 1519. When virtual losses occur, they do not trigger financial anxiety. Traders execute setups and let the algorithms run without emotional interference 1519. However, the moment real capital is involved, the human operator's brain switches into loss-aversion mode 19.
Data shows that the psychological divide between paper trading and real trading is massive 19. When observing a live algorithm experience a normal, statistically expected drawdown, retail traders often panic. They manually intervene, halting the bot, widening stop-losses, or closing positions early 1819. This human interference breaks the statistical probability of the system. The strategy itself did not fail; the emotional load of the operator did 19.
This is why forward testing must be scaled slowly. Traders must start with minimum position sizes to build psychological tolerance to the algorithm's natural volatility swings before scaling up to full production 1519.
Regulatory Scrutiny: The Crackdown on "AI Washing"
As retail interest in artificial intelligence has skyrocketed, a lucrative cottage industry of platforms promising guaranteed, market-beating returns via "proprietary AI bots" has flooded the internet 2013. Regulators have noticed, leading to a sharp escalation in enforcement actions against fraudulent and misleading technological claims.
"AI Washing" and Enforcement Actions
The Securities and Exchange Commission (SEC), the Financial Industry Regulatory Authority (FINRA), and the Commodity Futures Trading Commission (CFTC) have zeroed in on "AI washing" - the practice of making false, exaggerated, or misleading claims about a firm's artificial intelligence capabilities to attract investors 5455.
Firms cannot legally market basic, static rule-sets as advanced machine learning algorithms, nor can they promise guaranteed returns using AI 1354. Recent high-profile enforcement actions highlight the severity of this regulatory pivot: * Delphia and Global Predictions (March 2024): The SEC fined these two investment advisers a combined $400,000 for falsely claiming their investment portfolio construction was powered by advanced AI, when internal documents revealed highly limited automation 5414. * Rimar Capital (October 2024): The firm paid $310,000 to settle SEC charges regarding exaggerated claims about its AI trading capabilities 54. * The Privvy Investments Scheme (Mid-2024): The SEC charged Texas resident Nathan Fuller with orchestrating a $12.3 million crypto fraud scheme. Fuller lured approximately 150 investors by guaranteeing 40% to 100% returns using a purported "proprietary AI-based high-frequency arbitrage bot" 57585960. Investigators revealed that the bot essentially did not exist; only 3% of the funds were ever traded. The remaining capital was allegedly misappropriated for personal luxuries, including real estate and gambling, or used to make Ponzi-like payments to early investors 585960.
Supervision and Compliance Requirements
Beyond prosecuting outright fraud, regulators are enforcing stringent governance frameworks on legitimate financial institutions utilizing AI. FINRA's regulatory posture has hardened, shifting from issuing broad guidance to demanding accountability 14.
Under FINRA Rule 3110 (Supervision) and the SEC's Regulation Best Interest (Reg BI), regulatory bodies apply a "technology-neutral" standard 551415. This means that if an AI tool or algorithm is used to generate investment recommendations, monitor trades, or draft client communications, it is considered a part of the firm's supervisory chain and must be overseen with the exact same rigor as a human broker 141562.
Broker-dealers and registered investment advisors are required to rigorously test, validate, and document their AI models 556364. This includes maintaining comprehensive audit logs of all automated decisions, establishing vendor risk processes for third-party AI tools, and documenting human review checkpoints within regulated workflows 146264.
The regulatory mandate is clear: financial firms cannot outsource their fiduciary accountability to a "black box" algorithm 6316. If a trading algorithm exhibits uncorrected bias, hallucinates false data, or executes flawed trades that harm clients or disrupt market stability, the human supervisors and the firm are held strictly liable for the resulting financial damage and regulatory breaches 5516.
An Investor's Checklist for Evaluating AI Trading Bots
Given the prevalence of AI washing and outright scams, retail investors must exercise extreme caution when evaluating commercial algorithmic trading platforms.
The SEC, FINRA, and consumer protection agencies note several major red flags 1366: 1. Guaranteed High Returns: There is no such thing as a guaranteed return in legitimate investing. Claims that an AI can generate "consistent 10% monthly profits with zero risk" are the primary hallmark of a Ponzi scheme 1366. 2. Unregistered Platforms: Legitimate investment firms and brokerages must be registered with government agencies. If a platform cannot provide verifiable SEC or FINRA registration numbers (which can be checked via the SEC EDGAR database or FINRA BrokerCheck), investors should walk away immediately 1366. 3. The "Black Box" Defense: If a promoter refuses to explain the basic mechanics of how their algorithm generates signals, claiming it is a "highly guarded proprietary secret," it is usually because the technology does not exist 66. Legitimate quantitative firms can explain their methodologies (e.g., mean reversion, statistical arbitrage) without revealing proprietary source code. 4. Manufactured Urgency and Fake Endorsements: Scammers frequently utilize deepfake videos of celebrities or billionaires endorsing their platforms on social media, combined with high-pressure tactics demanding immediate deposits to "secure a spot" 66.
Bottom line
Testing an AI trading strategy requires a disciplined progression from historical backtesting to paper trading, and finally, forward testing in live markets. While AI excels at discovering complex patterns in historical data and parsing sentiment from unstructured text, it frequently fails in the real world due to statistical overfitting, look-ahead bias, and an inability to adapt autonomously to shifting macroeconomic regimes. Furthermore, the physical friction of live execution - including latency, severe slippage, and market impact - routinely destroys profit margins that looked flawless in a simulator. Ultimately, successful algorithmic trading relies less on the sheer complexity of the artificial intelligence and more on rigorous validation methods like the Deflated Sharpe Ratio, robust deterministic risk management, and strict regulatory oversight.