Performance degradation of AI trading strategies in live markets
The application of machine learning and artificial intelligence in quantitative finance has fundamentally altered the landscape of systematic trading. High-capacity predictive models, ranging from deep neural networks to large language models, possess an unparalleled ability to process high-dimensional datasets, identify nonlinear dependencies, and construct complex alpha factors [34, 55, 76]. In academic literature and institutional backtests, these models routinely demonstrate statistically significant predictive power, generating theoretical returns - commonly referred to as paper alpha - that vastly outperform traditional benchmarks [8, 22, 58]. However, a persistent anomaly plagues the deployment of these computational systems: a severe degradation of performance when transitioned from the laboratory to live, out-of-sample trading environments [8, 9, 33].
This erosion of theoretical edge is not primarily a failure of the algorithms' statistical pattern-recognition capabilities, but rather a failure to accurately model the friction and the adaptive nature of the market microstructure in which they operate [8, 13, 22]. Idealized historical backtests frequently operate under the assumption that the trading agent is a price-taker operating in a frictionless vacuum, executing at the closing price or the midpoint of the bid-ask spread without consequence [9, 22]. In reality, the act of trading incurs explicit financial costs, consumes finite liquidity, alters the local market microstructure, and alerts competing algorithmic participants to the presence of an exploitable signal [22, 58, 80].
The discrepancy between theoretical and realized algorithmic performance can be decomposed into three primary structural forces. First, transaction costs and execution slippage act as immediate, mechanical filters that strip away gross returns, disproportionately impacting high-turnover machine learning strategies [8, 44, 50]. Second, capacity limits and market impact models govern the absolute extent to which an algorithm can exploit a statistical signal before its own trading volume destroys the underlying price inefficiency [29, 81]. Finally, the widespread democratization of artificial intelligence infrastructure has triggered an accelerated rate of alpha decay, where crowded signal generation and adversarial market adaptations drastically compress the half-life of predictive information [57, 58, 90].
Transaction Costs and Implementation Frictions
The most immediate mechanical cause of backtest failure in artificial intelligence trading systems is the inadequate or static modeling of transaction costs. Transaction costs are broadly categorized into explicit and implicit frictions, both of which operate continuously to erode the gross returns identified by predictive classification or regression algorithms [59, 60, 63]. While explicit costs are relatively straightforward to model deterministically, implicit costs are dynamic, highly nonlinear, and heavily dependent on prevailing market conditions, venue routing, and aggregate order size [59].
Explicit Cost Mechanics
Explicit transaction costs represent direct, observable cash outflows associated with the execution of a financial trade [59, 63, 99]. These include brokerage commissions, exchange routing fees, clearing fees, and regulatory charges [33, 59]. Because explicit costs are transparent and deterministic at the time of trade, they are generally incorporated into sophisticated backtesting environments.
However, artificial intelligence algorithms that generate high-frequency signals often suffer from an accumulation of explicit fees that mathematical optimizers fail to account for properly. Many published academic studies report impressive classification accuracy for neural network models without demonstrating corresponding economic value after accounting for these basic implementation frictions [8, 9]. Research evaluating long short-term memory networks and deep reinforcement learning agents indicates that incorporating realistic explicit transaction constraints frequently reduces realized net returns by 15% to 40% when compared to theoretical, frictionless performance [8]. For institutional participants leveraging direct market access, these costs are aggressively negotiated and optimized, but they remain a persistent structural hurdle for mid-tier quantitative funds attempting to deploy high-turnover strategies across numerous asset classes [44, 59].
Implicit Cost Mechanics and Slippage
Implicit costs are substantially more complex to forecast and often represent the largest portion of total transaction costs, particularly for institutional-scale execution algorithms [59, 60]. These costs are largely invisible on a standard accounting ledger prior to execution and must be estimated and subsequently verified through rigorous transaction cost analysis [59]. The most foundational implicit cost is the bid-ask spread, defined as the differential between the highest price a resting buyer is willing to pay and the lowest price a resting seller is willing to accept [7, 59]. In highly liquid equity indices, the spread may be minimal, but for artificial intelligence models trading across vast universes of small-cap equities or exotic cryptocurrency pairs, the spread represents a substantial physical barrier to profitability [47, 59].
If a quantitative model predicts a short-term price movement of five basis points, but the prevailing bid-ask spread is eight basis points, the theoretical alpha is immediately negative upon execution if the algorithm demands liquidity by crossing the spread via a market order [9, 59]. Slippage serves as another critical implicit cost, defined formally as the difference between the expected price of an order at the time the algorithmic decision is rendered and the actual average price at which the trade is filled [7, 44, 59, 60]. Slippage is a direct manifestation of market microstructure dynamics; it depends on the latency of the execution infrastructure, the urgency of the order flow, short-term market volatility, and the depth of displayed liquidity resting in the limit order book [7, 59].
When an artificial intelligence system generates an execution signal, there is an inevitable delay before the child order reaches the exchange matching engine. During this microsecond interval, competitive high-frequency trading algorithms, reacting to the same fundamental order book imbalances, may step ahead of the order or cancel their resting liquidity, causing the realized price to slip adversely against the initiating agent [12, 13, 75]. In fast-moving or illiquid market regimes, slippage can quickly consume the entirety of the modeled alpha, rendering the strategy unprofitable in live production despite generating flawless historical backtest metrics [8, 9, 33].
Friction Discrepancies Across Asset Classes
The magnitude of explicit and implicit transaction costs varies dramatically across different financial ecosystems, directly dictating which types of artificial intelligence strategies can be effectively deployed and at what frequencies. A quantitative model trained on standardized equity data cannot be seamlessly ported to fixed income or digital asset markets without a complete recalibration of its friction assumptions.
| Asset Class | Market Structure and Liquidity | Indicative Trading Costs (Basis Points) | Primary Frictions and Execution Challenges |
|---|---|---|---|
| U.S. Equities | Centralized, highly regulated electronic communication networks. | 5 - 50 bps | Bid-ask spreads, venue fragmentation, extreme high-frequency trading competition, stringent regulatory fees, and complex maker-taker pricing schedules [7, 59]. |
| Fixed Income | Over-the-counter (OTC) dealer networks, transition to electronic trading. | 10 - 100+ bps | Dealer markups, opaque pricing pre-trade, illiquidity in off-the-run issues, and significant market impact for block trades [59, 60]. |
| Foreign Exchange | Decentralized, fragmented OTC bank and non-bank networks. | 10 - 100+ bps | Variable dealer spreads, highly fragmented liquidity pools across global centers, varying network latency, and information leakage [45, 47, 59]. |
| Cryptocurrencies | Hyper-fragmented centralized exchanges and decentralized protocols. | Highly variable (>10 bps to several percentage points) | Extreme sub-minute volatility, lack of a unified consolidated tape, automated market maker slippage formulas, continuous 24/7 noise, and wash trading manipulation [6, 7, 29, 44, 50]. |
The cryptocurrency market presents unique microstructural challenges for predictive models. Centralized cryptocurrency exchanges operate continuous limit order books with maker-taker fees analogous to traditional equities, but liquidity depth varies wildly across platforms and specific token pairs [7, 50]. Decentralized exchanges utilize automated market makers and liquidity pools, where slippage is a direct, deterministic mathematical function of trade size relative to total pool depth [7]. This represents an execution mechanic lacking a direct parallel in traditional finance. Consequently, an artificial intelligence model transferring feature weights and temporal architectures trained on historical U.S. equity data routinely fails in digital asset deployment, as it fundamentally misunderstands the prevailing liquidity mechanics and the disproportionate penalty of slippage inherent in decentralized environments [6, 9, 29].
Market Impact and the Limits of Execution
While slippage accounts for the cost of interacting with the prevailing, static state of the order book, market impact accounts for the cost of actively altering the order book itself [7, 22]. When a quantitative strategy attempts to execute a large directional order, it sequentially consumes available resting liquidity, shifting the equilibrium price adversely against its own accumulating position [22, 79, 81]. Ignoring market impact is identified as a primary reason why deep reinforcement learning agents fail catastrophically in real-world financial deployment [9, 22].
The Almgren-Chriss Framework and Execution Optimization
The academic and practical foundation for quantifying market impact is the Almgren-Chriss optimal execution model, which formally frames large order liquidation or accumulation as a stochastic control problem balancing transaction costs against market timing risk [79, 80, 81, 82, 83]. The model explicitly separates market impact into two distinct, mathematically tractable components.
The first component is temporary impact, defined as the instantaneous cost of demanding immediate liquidity [22, 82]. It reflects the immediate price concession required to match with resting limit orders deeper in the book. Once the algorithmic trading ceases its activity, this temporary price distortion typically reverts to the local mean [81, 82]. Temporary impact is highly sensitive to the speed or rate of trading. The second component is permanent impact, defined as the lasting change in the equilibrium price of the underlying asset [22, 82]. Permanent impact reflects the actual information content of the trade; the broader market interprets a massive, persistent sequence of algorithmic buy orders as a strong indicator of informed, predictive alpha, and rationally adjusts its baseline valuation upward accordingly [81, 82, 83].
By distilling execution into a mean-variance optimization problem, the Almgren-Chriss framework produces an efficient frontier of execution trajectories. At one extreme lies the minimum-variance strategy, which entails executing the entire order immediately, carrying zero timing risk but incurring massive temporary impact costs [82]. At the opposite extreme is the minimum-cost strategy, executing uniformly over an extended horizon, minimizing impact but maximizing exposure to exogenous price volatility [82, 83]. Modern artificial intelligence execution algorithms attempt to dynamically navigate this frontier, slicing meta-orders into smaller child orders governed by volume-weighted or time-weighted schedules [44, 81].
The Square-Root Law and Nonlinear Impact Models
Empirical market microstructure research conducted over decades heavily supports the square-root law of market impact [80, 81]. This law posits that the average permanent price impact of a large meta-order is proportional to the square root of its absolute size relative to the asset's average daily trading volume, scaled by the asset's localized daily volatility [80]. The canonical form is generally expressed mathematically as:
$\Delta p = Y \cdot \sigma \cdot \sqrt{\frac{Q}{V}}$
In this formulation, $\Delta p$ represents the price impact, $Q$ is the size of the executed trade, $V$ is the average daily trading volume, $\sigma$ is the daily price volatility, and $Y$ serves as a market-specific structural impact parameter [80]. This relationship fundamentally indicates that market impact is largely concave rather than linear [80, 81]. A trade representing ten percent of the average daily volume will incur a substantially different impact footprint than a trade representing one percent [81].
Recent empirical tests utilizing high-frequency data from European futures, Asian foreign exchange networks, and U.S. equities demonstrate a concave power-law relationship, where the specific exponent frequently ranges from $0.5$ to $0.7$ [81]. This confirms the principle of diminishing marginal impact for larger slices when executed incrementally, a metric that static machine learning backtests fail to incorporate [81]. For example, studies on S&P 500 index futures indicate that a trade sized at ten percent of average daily volume generated an average permanent impact of 4.2 basis points, while a one percent trade generated only 0.9 basis points [81].
Failures of Standard Reinforcement Learning Assumptions
The integration of complex, nonlinear impact models is computationally expensive and conceptually difficult to implement natively within standard machine learning training environments. Consequently, the vast majority of artificial intelligence agents - including advanced proximal policy optimization or soft actor-critic reinforcement learning models - are trained in simulated environments utilizing flat, fixed-cost assumptions, such as a static ten basis point fee applied indiscriminately to all trades [22].
This architectural flaw generates pathological trading behaviors during the training phase. Because the agent mathematically perceives that it can trade infinite volume at a fixed proportional cost, it learns to trade with highly unrealistic frequency, exploiting minute statistical anomalies that would instantly vanish under actual liquidity constraints [22, 50]. When these specific agents are subsequently evaluated in rigorous environments like the Market-Adjusted Cost Execution simulator, which properly incorporates the Almgren-Chriss nonlinear impact framework, their theoretical performance disintegrates.
In documented institutional experiments, switching from a fixed-cost simulation to an Almgren-Chriss impact simulation reduced a reinforcement learning agent's hypothetical daily turnover from 19% to 1%, and cut daily assumed trading costs by 96%, fundamentally altering both the absolute economic performance and the relative algorithmic ranking of the models [22]. For an artificial intelligence signal to survive in live markets, the execution layer must be strictly decoupled from the prediction layer, utilizing advanced order routing to minimize the footprint and the temporary impact of the algorithm's entry into the limit order book [44, 75, 81].
Strategy Capacity and Asset Under Management Constraints
Intimately related to the physics of market impact is the concept of strategy capacity - the maximum amount of assets under management an algorithmic strategy can successfully deploy before the mechanical act of deploying that capital permanently destroys the strategy's expected excess return [29, 30, 33]. Theoretical artificial intelligence models built in academic vacuums often ignore capacity entirely, assuming endless capital scalability [29].
Liquidity Exhaustion and Volume Scaling
A quantitative machine learning strategy that generates a robust Sharpe ratio of 2.0 with fifty million dollars in assets under management may fail to break even when scaled to five hundred million dollars [29]. As aggregate capital scales, the absolute order sizes required to maintain optimal target portfolio weights increase proportionally [33, 37]. If the underlying market instrument lacks the resting limit order depth to absorb this increased volume, the algorithm incurs exponentially higher slippage and permanent market impact, effectively paying a massive execution premium to enter the position and accepting a steep price discount to exit [29, 50, 75].
Capacity limits are fundamentally dictated by the underlying liquidity of the specific instruments traded and the temporal turnover frequency of the predictive strategy [30, 50, 59]. High-frequency trading and market-making strategies, which seek to systematically capture microscopic bid-ask spreads over horizons measured in milliseconds, possess extremely strict capacity constraints [70, 78]. They cannot allocate billions of dollars to a single sub-second order book imbalance without functionally becoming the entire market themselves [70, 78]. Conversely, slower, low-turnover strategies, such as cross-sectional momentum or fundamental value factors deployed across large-cap global equities, maintain much higher mathematical capacities, capable of absorbing tens of billions of dollars, albeit generating generally lower expected Sharpe ratios compared to high-frequency paradigms [70, 84].
Market-Specific Capacity Limits
In nascent, highly retail-driven markets such as cryptocurrencies, strategy capacity is a severe and persistent operational constraint [29]. While the aggregate theoretical market capitalization of the cryptocurrency ecosystem resides in the trillions of dollars, actual deployable order book liquidity is highly fragmented across dozens of competing centralized exchanges and decentralized lending protocols [7, 46].
Quantitative studies rigorously evaluating high-frequency trend-following signals on major cryptocurrency perpetual swap contracts indicate that order book depth typically limits practical trade capacity to approximately five million to ten million dollars per leg before transaction slippage exceeds ten basis points, aggressively neutralizing the artificial intelligence's predictive edge [50]. Furthermore, quantitative models tracking short-term funding rate arbitrage or structural basis trades often face similar ceilings. Funds that actively disregard these strict capacity constraints and pursue aggressive asset gathering often experience rapidly deteriorating live performance. In these scenarios, the execution algorithms are mechanically forced to cross wider spreads or implement trades over severely extended time horizons, exposing the portfolio to heightened market timing risk and accelerated alpha decay [29, 30, 33].
Signal Half-Life and Temporal Horizon Mismatch
A critical determinant of why artificial intelligence models fail in live production is the structural mismatch between the half-life of the informational signal generated by the model and the practical execution horizon required by the trading infrastructure [39, 64, 75, 90].
Mathematical Quantification of Information Decay
Every quantitative trading signal, regardless of its statistical sophistication, possesses a definitive shelf life. In quantitative finance, this is formally defined as the Information Half-Life: the specific duration required for a signal's predictive power or autocorrelated statistical edge to decay by exactly fifty percent [39, 64, 90].
In time-series modeling, this decay is frequently represented mathematically as an autoregressive process, commonly an AR(1) model. If a predictive feature $x_t$ follows the stochastic process:
$x_t = \phi x_{t-1} + \epsilon_t$
The autocorrelation of the signal decays exponentially over time [39, 64]. The half-life, denoted as $T_{1/2}$, is the discrete lag interval $k$ at which the correlation coefficient drops to $0.5$ [39, 64]. If a deep learning model identifies a highly profitable statistical pattern hidden within tick-level limit order book imbalances, the half-life of that specific signal may be measured in seconds or fractions of a second [12, 64]. Conversely, if the algorithm relies on shifting macroeconomic indicators, quarterly corporate earnings sentiment parsed by a large language model, or slow-moving supply chain disruptions, the half-life of the predictive signal may extend to several weeks or even months [11, 12, 64, 67].
The Mismatch Between Forecast and Execution Latency
A pervasive architectural error in the application of artificial intelligence to financial markets is ignoring the underlying physics of this temporal decay [39, 64, 90]. If a neural network is explicitly trained to identify intraday mean-reverting patterns that boast an empirical half-life of fifteen minutes, but the firm's execution infrastructure requires thirty minutes to fully route and execute the order using passive limit algorithms designed to avoid slippage, the model is effectively trading stale, fully decayed information [39, 75, 90]. The theoretical edge is entirely consumed by the mechanical delay cost [75].
Empirical falsification studies conducted on intraday momentum signals often reveal that the gross mathematical edge available at the exact moment of signal generation is insufficient to overcome the explicit transaction costs necessary to capture it before the half-life completely expires [43]. Artificial intelligence practitioners frequently optimize their architectures to achieve maximum theoretical predictive accuracy over arbitrary timeframes, without ensuring that the required forecast horizon strictly aligns with the input feature's persistence and the execution system's latency constraints [64, 90]. An artificial intelligence model is only economically viable if its execution speed is strictly faster than the biological decay rate of its alpha [57, 75].
Institutional Versus Retail Flow Persistence
The half-life of an artificial intelligence signal is highly dependent on the nature of the market participants generating the underlying data. Rigorous deconvolution of market impulse response kernels reveals stark differences between institutional and retail order flow [66].
Analysis of extensive order flow data from developed markets, such as the Korean Stock Exchange, demonstrates that institutional and foreign investor flows exhibit positive, persistent impact [66]. These sophisticated agents drive fundamental value discovery, contributing to signals with extended half-lives that artificial intelligence models can exploit over multi-day horizons (cumulative price impact of +0.0056 over a 60-day lag window) [66]. In stark contrast, retail investor flow exhibits a negative cumulative impact (-0.0045) [66]. When retail traders buy aggressively en masse, prices initially spike, generating a positive contemporaneous impact, but subsequently reverse sharply as informed algorithmic investors fade the noise [66]. Artificial intelligence models that fail to distinguish between these fundamentally different impact shapes will miscalculate the required half-life of the trade, executing trend-following logic into a rapidly decaying retail noise surge that is mathematically destined to mean-revert [66, 89].
Factor Crowding and Algorithmic Homogenization
Beyond mechanical transaction costs, execution friction, and temporal decay, the most profound existential threat to theoretical artificial intelligence returns is the adaptive, adversarial nature of the financial markets themselves. The widespread institutional adoption of machine learning has structurally altered the global landscape of alpha generation, aggressively accelerating decay rates through systemic crowding and continuous technological competition [34, 57, 58].
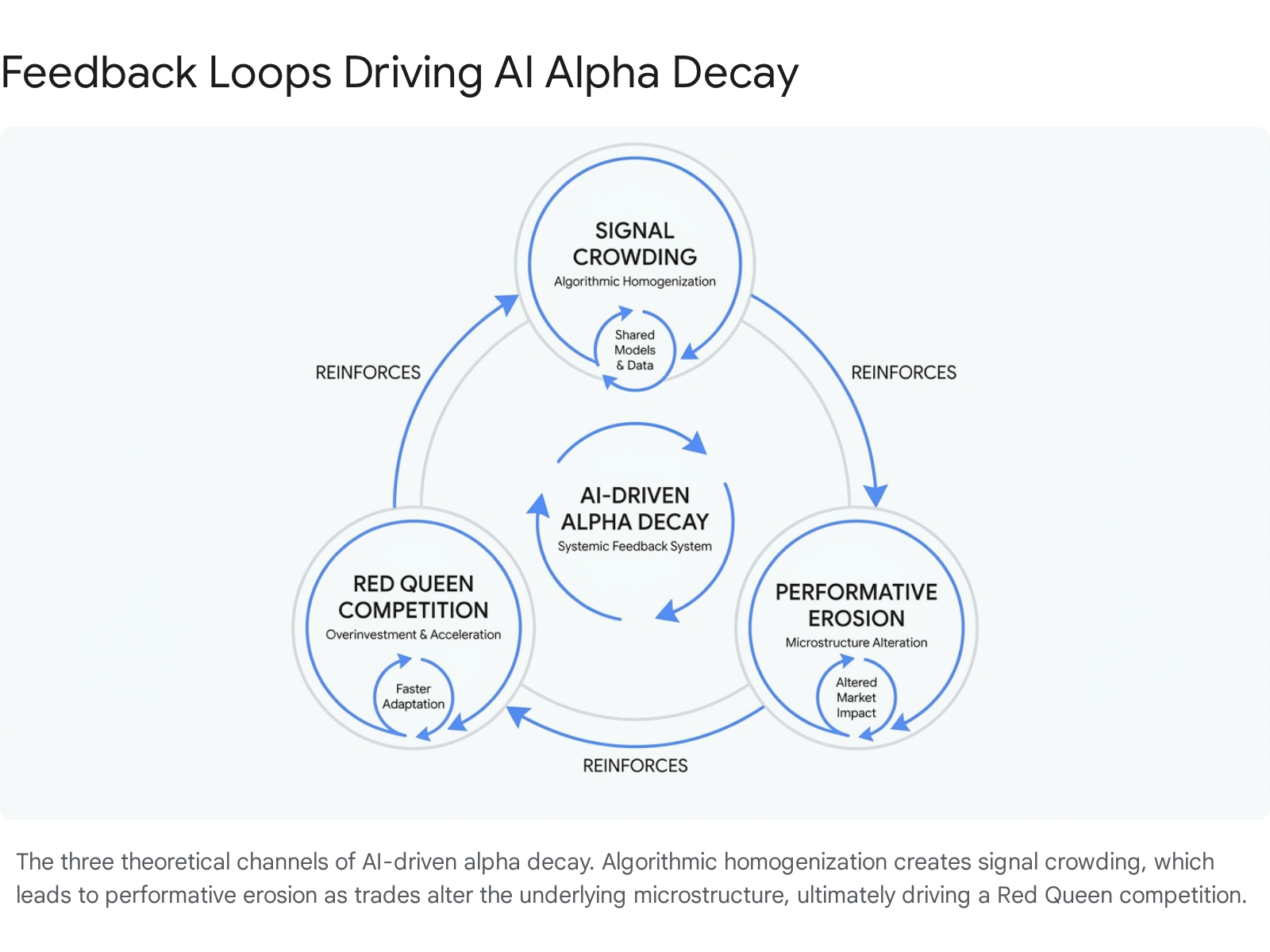
The Compression of Alpha Duration
The democratization of artificial intelligence tools, open-source machine learning frameworks, and commercialized alternative datasets has led to a widely documented phenomenon known as algorithmic homogenization [58]. When hundreds of quantitative hedge funds train similar architectural models - such as transformers, long short-term memory networks, or gradient-boosted decision trees - on identical historical financial datasets, they inevitably converge on identical alpha factors and market inefficiencies [24, 25, 26, 56, 58].
This widespread factor crowding aggressively accelerates alpha decay. In earlier eras of quantitative finance, a newly discovered pricing anomaly or statistical factor could persist in the market for five to seven years before being fully arbitraged away [58]. Today, institutional research indicates that the mass deployment of artificial intelligence has mathematically compressed the half-life of traditional factor premia to approximately eighteen months [58]. Furthermore, empirical studies quantifying the direct financial cost of alpha decay demonstrate that execution lag significantly impacts returns across geographies. The average cost of alpha decay amounts to 9.9% in European equities and 5.6% in U.S. equities, with the annual rate of this cost increasing by an average of 36 basis points in the U.S. and 16 basis points in Europe [1]. In highly volatile environments, information is priced into securities faster, making it exponentially more costly to trade on delayed or crowded artificial intelligence signals [1].
When a widely utilized algorithmic signal triggers an entry condition, dozens of competing systems attempt to execute the exact same directional trade simultaneously [34, 57, 58]. The absolute fastest participants - often those utilizing co-located, specialized high-frequency trading infrastructure - capture the entirety of the mispricing. This leaves the remaining artificial intelligence models to execute at severely disadvantageous prices or, catastrophically, to suffer massive correlated drawdowns when crowded, homogenized trades abruptly unwind during sudden market stress events [23, 24, 34, 57].
Recent developments in large language model-driven alpha mining explicitly highlight this systemic vulnerability. While large language models show exceptional promise in rapidly generating novel trading factors from unstructured textual and numerical data, they frequently fail to impose mathematical regularization against factor homogenization. Because these models are pre-trained on existing, publicly available human knowledge, they predominantly replicate and suggest well-documented, heavily exploited market inefficiencies, thereby exacerbating the crowding effect and guaranteeing rapid, unavoidable decay when deployed in live markets [24, 25, 26, 56]. Frameworks attempting to counter this, such as AlphaAgent, must rely on complex syntactic constraints to force models to explore uncrowded alpha spaces, demonstrating that raw generative capability without strict originality constraints yields negative expected returns [24, 25, 56].
Performative Signal Erosion
Theoretical frameworks describing the macroeconomic impact of artificial intelligence on financial markets identify a secondary, deeper feedback loop classified as performative signal erosion [58]. In this paradigm, the predictive act itself alters the surrounding environment. As artificial intelligence algorithms act upon a generated signal, their collective trading volume alters the underlying market microstructure, efficiently pricing the discovered information into the asset and permanently destroying the specific inefficiency that the model was originally trained to exploit [58, 82].
The prediction essentially becomes self-defeating at scale. A pattern identified in historical data exists precisely because past market participants were inefficient at pricing that specific information. Once artificial intelligence algorithms identify the pattern and allocate capital to it, the inefficiency ceases to exist, rendering the historical training data structurally obsolete for future inference [58].
The Red Queen Competition in Quantitative Finance
This relentless dynamic traps quantitative trading firms in a Red Queen competition - an evolutionary, self-defeating arms race where market participants must continuously invest massive amounts of capital into alternative data ingestion pipelines, highly advanced model architectures, and ultra-low-latency physical infrastructure simply to maintain their current performance levels [30, 58].
The theoretical statistical edge identified during historical backtesting assumes a completely static market regime [22, 58]. In live trading, the market operates as an aggressive, intelligent, and highly adaptive adversary that systematically hunts and arbitrages away predictable algorithmic behavior [15, 22, 58]. Firms that attempt to substitute robust, friction-aware engineering with highly complex, over-parameterized neural networks routinely discover that their models possess zero economic value outside of a vacuum [8, 9, 30].
Structural Falsification and Robust Validation
The disappearance of theoretical artificial intelligence alpha is not a transient glitch, but a fundamental reality of market mechanics interacting with statistical models. Predictive accuracy in an idealized, frictionless backtest is a mathematically necessary, but vastly insufficient, condition for true economic profitability in live deployment [8, 33]. Standard $k$-fold cross-validation techniques frequently fail in financial contexts due to temporal dependencies and severe information leakage, leading to heavily over-optimistic performance estimates [8].
When transitioning from the computational laboratory to the live limit order book, artificial intelligence models confront a hostile, non-stationary environment governed by explicit regulatory fees, dynamic bid-ask spreads, and the nonlinear realities of the Almgren-Chriss market impact dynamics. Constraints on strategy capacity ensure that theoretical returns cannot be infinitely scaled, particularly in highly volatile, structurally fragmented arenas like global cryptocurrency markets. Furthermore, the democratization of artificial intelligence tools has catalyzed a rapid era of algorithmic homogenization, where crowded trades, rapid information decay, and continuous performative erosion compress the functional lifespan of any discovered edge to a fraction of its historical duration.
For artificial intelligence to generate sustainable, real-world returns, the quantitative modeling paradigm must shift from pure predictive forecasting to integrated, friction-aware execution. Algorithms must be continuously trained under strict, realistic penalty frameworks that deeply internalize slippage, mathematically account for the asset's specific microstructure, and respect the temporal half-life of the data they consume. In the modern quantitative ecosystem, alpha generation is no longer merely about statistical signal discovery; it relies entirely on the engineering infrastructure required to execute that signal before adversarial systems extinguish the inefficiency.