LLM-based signal generation for high-frequency trading in 2025
The integration of Large Language Models (LLMs) and advanced foundation architectures into quantitative finance has fundamentally altered the landscape of algorithmic signal generation. However, deploying these complex parameter architectures within high-frequency trading (HFT) and ultra-low-latency market making presents a severe computational paradox. LLMs possess unprecedented capacities for semantic reasoning, multimodal data synthesis, and complex nonlinear pattern recognition, yet their autoregressive inference mechanisms are inherently constrained by latency bottlenecks. These latency profiles are fundamentally antithetical to the microsecond demands of high-frequency order execution. In 2025, the research and deployment frontier has shifted away from generic, monolithic model querying toward highly specialized, latency-optimized signal generation strategies. These encompass direct microstructure transformers, asynchronous multi-agent orchestration frameworks, hybrid reinforcement learning pipelines augmented by semantic sentiment, and knowledge distillation techniques designed to map the deep reasoning capabilities of LLMs onto high-speed statistical learners and Field-Programmable Gate Arrays (FPGAs).
Exchange Microstructure Dynamics
To evaluate the efficacy of any signal generation strategy, it is first necessary to define the physical and institutional parameters of the market microstructure in which the algorithm operates. High-frequency markets operate on strict queue-based order execution models where transactions are matched continuously based on absolute arrival time 12. In these environments, signal decay is not measured in minutes, but in microseconds.
Execution Mechanics and Transaction Cost Blind Spots
The practical consequence for a trading desk running passive execution strategies is that algorithmic fill-rate optimization may achieve fills at seemingly optimal prices while incurring severe queue-position-driven adverse selection costs 2. These costs are often entirely invisible in standard Transaction Cost Analysis (TCA) outputs. The dynamic component of market making captures the optionality value of locking in a queue position; once an order is stationed at a specific queue depth, there is tangible economic value in maintaining that position because re-queuing after a cancellation incurs a substantial penalty in execution priority 2.
These mechanics are heavily influenced by the specific exchange protocol. For example, calibrations against the NASDAQ ITCH market-by-order data on highly liquid US equities and ETFs (where bid/ask spreads sit close to a single tick) demonstrate that Order-To-Trade Ratio (OTR) drift is a critical precursor to adverse selection 23. Elevated OTR on a specific instrument over a defined, time-windowed pre-fill period strongly indicates that market participants are aggressively submitting and canceling orders to probe liquidity or manipulate queue dynamics 2. Under MiFID II RTS 9 regulations in Europe, OTR is a mandated surveillance metric utilized by major exchanges such as Eurex and the London Metal Exchange (LME) 24. If an LLM-based agent processes price data without explicitly accounting for these granular, protocol-specific microstructure signals, it will systematically misprice liquidity provision 2.
Structural Exchange Asymmetries
Furthermore, global exchange structures introduce idiosyncratic volatility regimes that generic LLMs fail to model correctly. A primary example is the Tokyo Commodity Exchange (TOCOM), which operates with split trading sessions that induce distinct intraday and overnight volatility regimes 3. For instruments such as TOCOM rubber futures, the dichotomy between intraday returns and overnight returns is exacerbated by trading halts and physical delivery constraints 3.
Standard daily Value-at-Risk (VaR) models, including asymmetric Generalized Autoregressive Conditional Heteroskedasticity (GARCH) variants, systematically underestimate true market risk by conflating these different volatility dynamics into a single daily series 3. An effective LLM deployment in Asian or European markets must inherently recognize these institutional boundaries, utilizing two-tiered risk management frameworks that separately apply conventional models to intraday risk and jump-aware measures for overnight risk 3. Failure to integrate the exchange's specific institutional mechanics into the model's spatial awareness leaves speculators and clearinghouses dangerously exposed during periods of market stress 3.
Latency Specifications for Large Language Models
The deployment of generative AI in trading is strictly governed by the latency-quality trade-off. This dynamic is rigorously quantified by simulation systems such as HFTBench, which evaluates real-time decision-making of LLMs using historical per-second trading data sourced from Polygon.io 1. HFTBench utilizes a linearly decaying price model to simulate queue-based execution, assigning execution prices where faster agents secure more favorable outcomes 1.
The HFTBench environment proves that trading tasks demand high response quality and low latency simultaneously 1. If an LLM agent produces a highly accurate signal but suffers from high latency, the alpha decays entirely before the order reaches the matching engine, resulting in adverse execution 1. Conversely, deploying excessively small models to reduce latency often results in degraded decision quality; if accuracy is overly compromised, the speed advantage is negated, and faster execution merely accelerates the rate of financial loss 1. Empirical testing confirms that moderately larger models (e.g., 14B parameters) generally outperform smaller alternatives in trading benchmarks because their capacity to recognize high-reward patterns outweighs the marginal latency penalty, provided the infrastructure is heavily optimized 1.
Hardware Bandwidth and Compute Architecture
The optimization of this trade-off requires specific hardware and inference software configurations. In 2025, the baseline for cloud-based LLM inference latency hovers between 800ms and 1.5 seconds, which is viable for daily portfolio rebalancing but disastrous for HFT 47. To penetrate the intraday and high-frequency execution windows, institutions are deploying customized hardware stacks.
The speed of open-source models is fundamentally memory-bound, limited by how fast the GPU can read model weights from High Bandwidth Memory (HBM) 59. Migrating from NVIDIA H100 architectures (3.35 TB/s bandwidth) to H200 architectures (HBM3e with 4.8 TB/s bandwidth) on bare-metal deployments has allowed quantitative funds to drop Time to First Token (TTFT) metrics significantly 5. For a Llama-3 8B parameter model, H200 bare-metal clusters allow the entire model to be loaded into the GPU's L2 cache and HBM, dropping TTFT to 40 milliseconds and total response delay below 300ms 5.
Further compression is achieved via the NVIDIA Blackwell architecture (B200/GB200 GPUs). Blackwell features 208 billion transistors and natively supports FP4 tensor core quantization, claiming a 4x faster LLM inference over Hopper architectures 4.
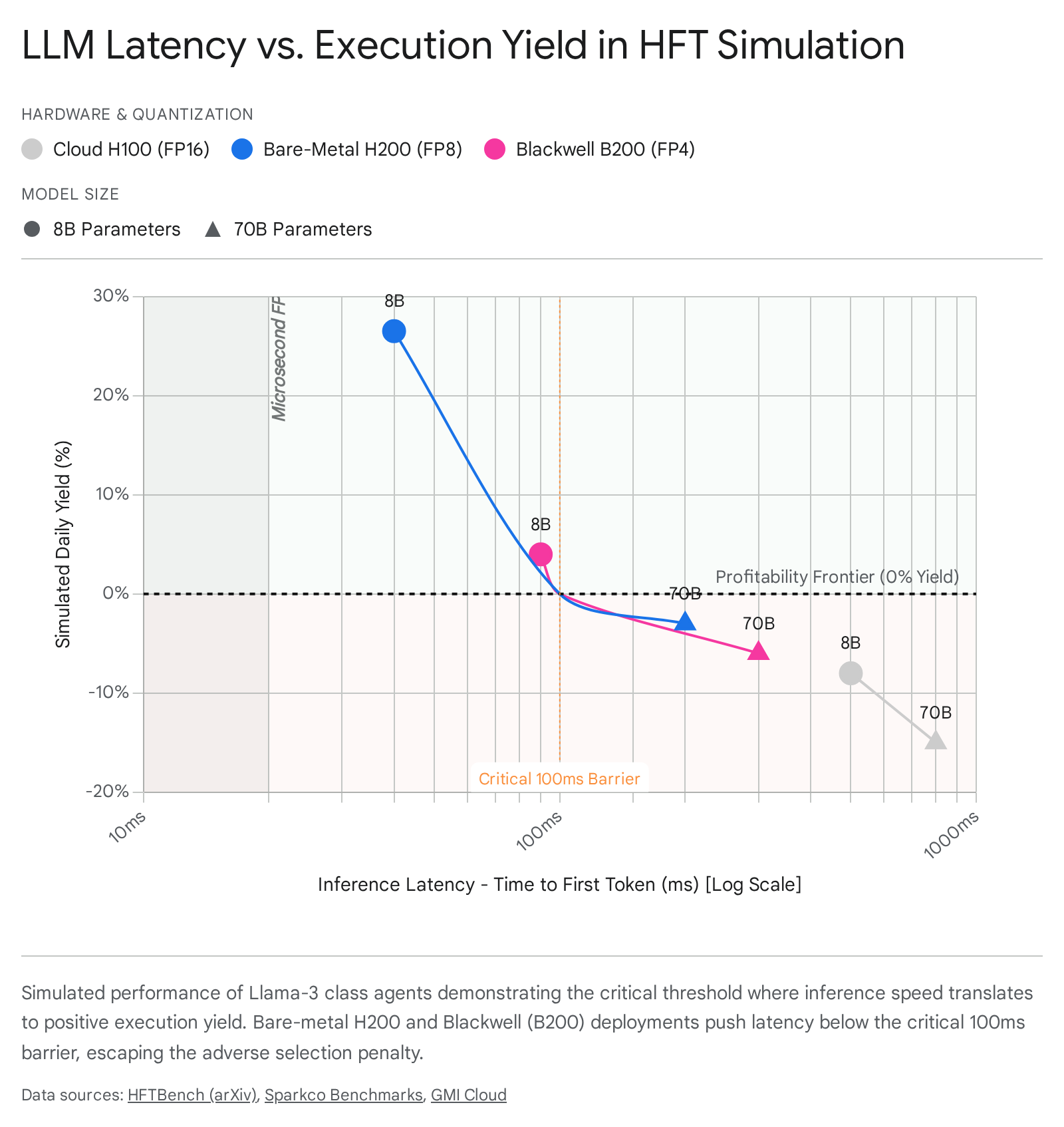
Independent MLPerf 2025 benchmarks confirm 2.5-3x p95 latency reductions for GPT-scale models, dropping latencies from 800ms to 300ms on batch sizes of 128 4. Firms employing custom silicon, such as Groq's Language Processing Unit (LPU), bypass traditional GPU training patterns entirely, achieving processing speeds exceeding 300 tokens per second on 70B-parameter architectures 10.
Runtime Engine Optimization
Hardware capability must be paired with optimized serving stacks. The choice of inference runtime determines how the system batches requests, overlaps prefill and decode phases, and manages the key-value (KV) cache 6.
The primary contention in 2025 is between vLLM and TensorRT-LLM 67. vLLM is built around PagedAttention, which partitions the KV cache into fixed-size blocks, reducing KV fragmentation to under 4% (compared to 60-80% in naive allocators) 6. This enables high GPU utilization with continuous batching, making it highly effective for concurrent workloads 6.
Conversely, NVIDIA's TensorRT-LLM utilizes Kernel Fusion, which consolidates multiple tensor operations into single CUDA kernels to minimize DRAM-to-compute data movement 7. It also leverages CUDA Graphs to capture GPU operation sequences for efficient replay, drastically reducing CPU-side overhead 7. For algorithmic trading where sub-100ms latency is an absolute requirement, TensorRT-LLM often delivers lower single-request latency on identical hardware when strictly compiled for a specific model 67. However, telemetry indicates that at high concurrency (e.g., executing multiple simultaneous portfolio queries), TensorRT-LLM's TTFT degrades significantly, whereas vLLM maintains more stable tail latencies 7.
Limit Order Book Transformer Architectures
Historically, quantitative finance relied on Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks to parse the spatial and temporal dependencies of Limit Order Book data 814. By 2025, sequence modeling for microstructure analysis advanced significantly with the introduction of the Limit Order Book Transformer (LiT).
Deep Hierarchy Modeling
LiT is engineered specifically to address the "deep hierarchy" inherent in high-frequency order books 916. Unlike generic sequence models that treat the LOB as a flat vector of numerical prices and volumes, LiT is structurally aware 89. It utilizes customized attention mechanisms to map cross-level dependencies, explicitly differentiating the microstructural significance of activity at different depths - for example, recognizing that a Level 1 bid absorbing liquidity holds fundamentally different predictive power than a Level 10 bid indicating informed institutional stacking 916.
By processing the full depth of the order book across both bid and ask sides simultaneously, LiT captures the nuanced pairwise comparisons necessary to forecast short-term mid-price movements, order book imbalances, and impending price jumps 89. In isolated classification tasks, architectures with positional or dual attention have demonstrated superior performance in intraday price-movement classification compared to traditional deep learning baselines 810.
Empirical Performance Limitations
Despite representing the state-of-the-art in transformer-based LOB modeling, direct LLM-style architectures applied to raw tick data face severe empirical realities when subjected to full-friction backtesting 149.
In a rigorous walk-forward out-of-sample evaluation covering January 2020 through February 2026 (capturing the COVID-19 crash, the 2021 bull run, and the 2022 bear market), the LiT model generated an annualized return of 10.04% with an annual volatility of 7.90% 9. While the Transformer successfully learned a return signal that forced the optimizer out of a low-return minimum-variance trap, it was structurally defeated by significantly simpler models 9.
A naive 1/N equal-weight baseline achieved a superior Sharpe ratio (1.04) and Calmar ratio (0.78), experiencing roughly half the maximum drawdown (-16.5%) of the Transformer strategy 9. More critically, the Transformer was strictly beaten on return, Sharpe (0.32), drawdown, and Calmar (0.50) metrics by a rudimentary 20-day momentum factor 9. Although a Memmel-corrected Jobson-Korkie test indicated that the underperformance relative to simple momentum was not statistically significant from sampling noise, it represents a practical failure 9.
This empirical reality demonstrates that while transformers possess immense representational capability, feeding raw, high-dimensional, noise-heavy microstructure data into large attention blocks is computationally inefficient and highly susceptible to overfitting structural market breaks 911. The network learns a noisy, momentum-like signal with similar autocorrelation but at vastly higher computational cost and latency 9. Consequently, the industry consensus has pivoted away from using massive transformers as direct end-to-end price predictors at the tick level, shifting instead toward decoupled architectures.
Decoupled Multi-Agent Orchestration Frameworks
To mitigate the brittleness and latency of monolithic models, modern HFT and intraday trading systems have adopted multi-agent orchestration frameworks 121314. These systems decompose the trading workflow into specialized cognitive tasks, leveraging LLMs not for raw tick ingestion, but for complex state perception, regime classification, and strategic routing 1415.
Temporal Horizon Constraints
The degradation of LLM alpha in direct trading is closely tied to the temporal horizon of the decision. LLMs act primarily as information filters; when forced to make high-frequency buy/sell decisions based on highly noisy intraday data, their performance falters 1216.
Extensive ablation testing of models like GPT-4.1-mini acting as autonomous trading agents across five major equities (AAPL, MSFT, AMZN, TSLA, NFLX) reveals a distinct "Goldilocks zone" for LLM decision-making 16. Operating on a weekly rebalancing horizon yielded the highest performance, achieving a Sharpe ratio of 1.028 and a cumulative return of +62.4% over a two-year period (2023-2024), while utilizing 75% fewer trades than daily models 16. Daily rebalancing resulted in a lower Sharpe ratio of 0.892, while monthly rebalancing degraded performance dramatically to a Sharpe of 0.421, as the model lost critical signaling information 16. Notably, no LLM frequency surpassed a simple Buy-and-Hold strategy (Sharpe 1.620) during this sustained bull market period, reinforcing the necessity for LLMs to handle strategic asset allocation rather than rapid tick execution 1216.
Agent Specialization: QuantAgent
QuantAgent represents a shift toward specialized, price-driven multi-agent systems designed for slightly longer temporal windows (e.g., 1-hour to 4-hour bars, functioning as mid-frequency trading) 121424. It decomposes the trading process into four distinct agents: Indicator, Pattern, Trend, and Risk 1214.
Each agent is equipped with domain-specific tools and structured reasoning capabilities to capture distinct aspects of market dynamics over short temporal windows 14. By isolating signals into explicit modules, QuantAgent has demonstrated up to 80% directional accuracy at short horizons in zero-shot evaluations across ten financial instruments, including Bitcoin and Nasdaq futures 121424.
MM-DREX: Multimodal Dynamic Routing
Financial markets exhibit severe non-stationarity, rendering fixed-structure trading models obsolete during rapid regime shifts. The MM-DREX (Multimodal-Driven Dynamic Routed Expert) framework addresses this explicitly by decoupling market state perception from strategy execution, enabling adaptive sequential decision-making 13151726.
The architecture introduces a Vision-Language Model (VLM) functioning as a dynamic router. This router jointly analyzes visual candlestick chart patterns and long-term temporal features to classify the current market regime 1315. To generate high-quality regime labels for pre-training, datasets undergo classification through technical indicators validated by institutional traders into three states: uptrend, downtrend, and consolidation 13.
Based on this real-time perception, the router dynamically allocates weights across four heterogeneous trading experts: trend, reversal, breakout, and positioning 1315.
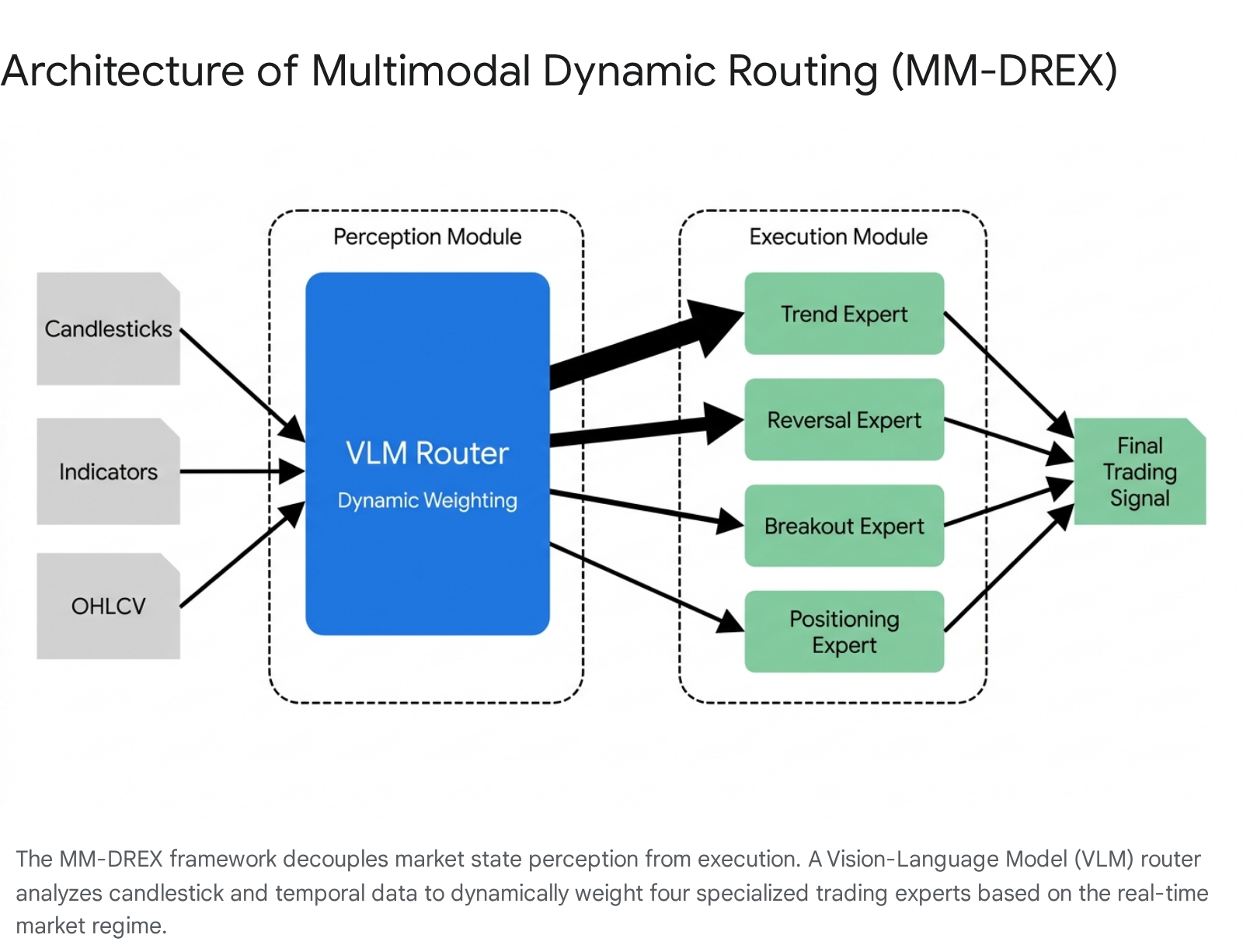
This allows for the generation of specialized, fine-grained sub-strategies 13. MM-DREX is trained via a novel SFT-RL (Supervised Fine-Tuning and Reinforcement Learning) hybrid paradigm, which handles joint training of heterogeneous modules with different objectives, mitigating gradient interference while synergistically optimizing both classification and risk-adjusted decision-making 1315.
Extensive experiments on multi-modal datasets covering U.S. and Chinese equity markets, futures, ETFs, and cryptocurrencies demonstrate that MM-DREX significantly outperforms 15 diverse baselines (including state-of-the-art financial LLMs and standard deep reinforcement learning models) across total return, Sharpe ratio, and maximum drawdown 131517. The system also incorporates an interpretability module that traces routing logic and expert behavior in real-time, providing a critical audit trail for strategy transparency 1317.
Semantic Sentiment and Reinforcement Learning
While LLMs encounter friction with the numeric density of raw LOB data, they remain the undisputed state-of-the-art for natural language processing, semantic extraction, and financial sentiment analysis 271829. Financial news and macroeconomic reports exhibit long-memory effects and delayed incorporation into asset prices due to limits to arbitrage 2718. The optimal strategy relies on asynchronous fusion: utilizing LLMs to extract real-time sentiment from unstructured text and feeding these high-level signals into traditional high-speed statistical or Reinforcement Learning (RL) execution engines 19.
Sentiment-Augmented Proximal Policy Optimization
The Sentiment-Augmented Proximal Policy Optimization (SAPPO) framework exemplifies this synthesis 202122. Standard PPO algorithms in quantitative finance rely exclusively on historical price and volume data, optimizing policies via reward functions tied to cumulative returns. However, they are entirely blind to the exogenous textual shocks that drive sudden regime shifts 2021.
SAPPO utilizes a finance-optimized LLM (such as LLaMA 3.3) to parse continuous streams of Refinitiv financial news and generate daily sentiment scores 2021. The critical innovation lies in how this sentiment is integrated: rather than treating sentiment as a mere input feature alongside technical indicators, SAPPO directly alters the PPO advantage function via a sentiment-weighted term 2021.
The advantage function dictates how much a specific action exceeded the expected baseline return. By injecting a sentiment influence parameter (empirically optimized through ablation studies at $\lambda = 0.1$), SAPPO forces the policy network to aggressively scale up exposure when favorable price momentum coincides with positive semantic sentiment, while dampening allocations when price action diverges from the underlying news narrative 202122.
In empirical testing on multi-asset portfolios (e.g., evaluating a three-stock portfolio of Google, Microsoft, and Meta), the integration of LLM sentiment via SAPPO increased the Sharpe ratio from 1.55 (standard PPO) to 1.90 202122. The strategy also resulted in a statistically significant reduction in maximum drawdowns relative to purely price-based strategies, confirmed via $t$-tests ($p < 0.001$) 2021.
Knowledge Distillation and Gradient Boosting
The most profound operational realization in quantitative finance in 2025 is that LLMs do not need to exist in the critical execution path to generate HFT alpha. The computational overhead of even heavily quantized parameter sets precludes them from generating responses in the microsecond windows required to execute against elite market makers 5734. To resolve this, researchers have perfected distillation and rule extraction frameworks 352337.
The Distill-to-Select Paradigm
Model distillation in finance involves utilizing a massive, computationally expensive LLM (the "Teacher") in an offline environment to process deep historical datasets, unstructured filings, and complex factor interactions. The LLM identifies non-linear logic rules, penalizes hallucinated or adversarial signals, and curates a sparse set of highly predictive semantic features 352337. These insights are then distilled into a lightweight "Student" model - typically a Gradient Boosted Decision Tree (GBDT) architecture such as XGBoost or LightGBM 3724394025.
Frameworks such as the Distill-to-Select approach build feature selection into the training process itself 37. By combining label accuracy, teacher mimicry, and feature sparsity (via L1 regularization) into a single loss function, the resulting logistic regression or shallow tree is both compact and aligned with the deep reasoning of the high-performing teacher 37.
More advanced frameworks like Statsformer integrate LLM-derived feature priors into supervised learning via "validated prior integration." Semantic priors supplied by the foundation model act as an inductive bias for the base learners (e.g., XGBoost, Lasso), while empirical risk validation determines how strongly the system should rely on that bias 35. Similarly, logic rule learning systems utilize Monte Carlo Tree Search (MCTS) to extract interpretable first-order logic rules from offline data, which are then used to boost reasoning capabilities without the latency overhead of Retrieval-Augmented Generation (RAG) 23.
Efficacy of XGBoost in HFT
XGBoost and similar tree-based learners remain the state-of-the-art lower-bound single-model references for tabular tasks due to their robustness, computational efficiency through histogram-based algorithms, and leaf-wise growth strategies 354026. When benchmarked in credit risk and financial fraud prediction tasks against LLMs directly, XGBoost frequently achieves superior accuracy (e.g., 99.4% in specific baseline datasets) 3925. Furthermore, adversarial training reveals that XGBoost matches the robustness of LLMs against input disturbances while offering highly interpretable SHapley Additive exPlanations (SHAP) values that quantify the marginal impacts of features on predictions 394025. Because XGBoost executes via simple decision nodes, inference times are measured in nanoseconds 3726. This allows HFT firms to leverage the offline semantic reasoning of foundation models while executing trades using hyper-fast boosted trees directly on the trading desk 243927.
Hardware Acceleration and Field-Programmable Gate Arrays
For absolute latency minimization, the industry has bypassed general-purpose GPUs for the execution phase, shifting toward dedicated hardware acceleration via Field-Programmable Gate Arrays (FPGAs) 44452829. FPGAs allow quantitative researchers to program digital logic directly into the silicon, optimizing data movement and bypassing the operating system kernel entirely (kernel bypass) 444530. In the cloud-native architectures of 2025, FPGAs are deployed directly in the data path to manage streaming, act as smart Network Interface Cards (NICs), and pre-process infrastructure data before it reaches central processors 4445.
Embedded Transformer Quantization
Recent advancements have enabled the deployment of compact Transformer architectures directly onto FPGA boards (e.g., AMD Alveo U50, Spartan-7, or Xilinx Ultra96V2) 3049. Training transformers on resource-constrained embedded devices requires overcoming significant memory demands. Researchers leverage low-rank tensor compression and quantization-aware training down to 4-bit fixed-point precision to create unified Tiny Transformer deployments 3049.
By storing all highly compressed model parameters and gradient information on-chip (utilizing BRAM and URAM), these architectures eliminate off-chip PCIe communication bottlenecks 49. Custom computing kernels employ intra-layer parallelism and pipe-lining to enhance run-time efficiency 49. These tensorized FPGA accelerators can execute time-series Transformer inference with latencies as low as 1.03 milliseconds, consuming merely 0.033 mJ of energy per inference on embedded systems 30.
On institutional-grade hardware, the STAC-ML (Markets) Inference benchmark - a critical standard for financial institutions measuring time series models under realistic market conditions - demonstrates the sheer speed of customized hardware 28. Benchmarks for LSTM models (Tacana parameters) on NVIDIA GH200 Grace Hopper superchips achieved p99 latencies of 4.70 microseconds 28. FPGAs achieve comparable single-digit microsecond latencies by focusing on custom-tailored solutions that leverage precomputations outside critical sections for the final time step of sliding windows 28. In the context of HFT, an FPGA-accelerated model parsing stationary LOB features or distilled LLM rules provides a deterministic, ultra-low latency signal that standard neural network clusters cannot physically match 4429.
Comparative Performance of Signal Generation Architectures
The effectiveness of these architectures varies significantly based on the intended trading horizon, the underlying data modality, and the rigid hardware constraints of the trading venue. The following table summarizes the comparative performance and characteristics of the leading LLM-based signal generation strategies in 2025.
| Architecture / Framework | Primary Data Modality | Core Mechanism | Execution Latency Tier | Net Alpha / Sharpe Impact |
|---|---|---|---|---|
| LiT (LOB Transformer) | Raw Tick / Limit Order Book | Cross-level attention on deep LOB hierarchy | High (GPU-bound) | Underperforms naive momentum (Sharpe 0.32) due to overfitting and data noise 9. |
| MM-DREX | Multimodal (Candlesticks + Indicators) | VLM dynamic router delegating to specialized trading experts | Medium (Multi-agent inference) | High robustness; significant outperformance in Sharpe and drawdowns 131517. |
| SAPPO | Text (Financial News) + Price | LLM sentiment parameter integrated into PPO advantage function | Low (Asynchronous signal) | Increases Sharpe from 1.55 to 1.90 with reduced volatility 202122. |
| Distill-to-XGBoost | Structured Features + Semantic Rules | Deep LLM logic rules distilled into lightweight GBDT | Ultra-Low (Nanoseconds) | Maintains LLM accuracy profile; ideal for sub-millisecond execution 352425. |
| FPGA Tiny-Transformer | Time-Series / LOB Features | Tensor-compressed Transformer on bare-metal logic gates | Ultra-Low (Microseconds) | High deterministic execution; single-digit microsecond latency 283049. |
Evaluation Realities and the Alpha Illusion
As the deployment of LLMs in quantitative finance accelerates, the academic literature has been saturated with frameworks claiming extraordinary risk-adjusted returns 5051. However, rigorous systemic reviews have identified a pervasive "Alpha Illusion" resulting from severe evaluation flaws in agentic trading research 5051.
Many academic LLM trading agents (such as FinMem, TradingAgents, and FinCon) report headline Sharpe ratios exceeding 2.0 or 3.0 based on short, heavily prompted evaluation windows that suffer from temporal leakage 5051. When these strategies are subjected to rigorous reproduction harnesses that account for full-friction deployment realities - specifically bid-ask spreads, trading commissions, slippage, execution latency, and LLM API token costs - the gross alpha is rapidly devoured 5051.
For example, in a 2025-2026 reproduction harness testing an equal-weight portfolio (TSLA, NVDA, KO, XOM, MSTR), the TradingAgents framework generated a gross return of $106.4K but dropped to $102.3K net of frictions 50. More severely, the QuantAgent framework resulted in a net return of $77.9K, massively underperforming a naive buy-and-hold strategy that ended at $104.8K 50. In contamination-free, point-in-time real-market evaluations, most LLM agents struggle to consistently outperform a passive benchmark, exposing the gap between theoretical architecture research and deployable trading capability 1650.
Conclusion
In 2025, the most effective LLM-based signal generation strategies for high-frequency trading are explicitly those that remove the autoregressive generation of the LLM from the critical execution path. While direct sequence models like the Limit Order Book Transformer push the boundaries of spatial-temporal analysis, they are computationally heavy and highly vulnerable to underperforming simple, robust heuristics like momentum. True edge is achieved through architectural decoupling. The most robust frameworks operate asynchronously: utilizing multimodal LLM routers (MM-DREX) to determine market regimes, employing real-time semantic analysis to reshape the advantage functions of reinforcement learning agents (SAPPO), or conducting offline Knowledge Distillation to imprint deep semantic reasoning onto microsecond-capable XGBoost decision trees. Ultimately, securing an advantage in modern market microstructure demands that the vast intelligence of foundation models be constrained, translated, and hardware-accelerated via FPGAs to survive the brutal latency realities of the electronic limit order book.