Predicting short-horizon equity returns using sentiment analysis
The integration of unstructured textual data into systematic quantitative finance has fundamentally altered the landscape of algorithmic trading. Under the strict form of the Efficient Market Hypothesis, asset prices are assumed to instantly reflect all publicly available information, precluding the possibility of generating persistent excess returns based on historical or public data 123. However, empirical market microstructure observations demonstrate that information diffusion is a gradual process. Asset pricing is continuously subject to human attention constraints, heterogeneous interpretation of ambiguous text, and physical market frictions 14. By quantifying the emotional tone, subjective beliefs, linguistic complexity, and factual nuances embedded in financial text, natural language processing (NLP) models extract quantifiable sentiment signals that consistently anticipate short-horizon asset price movements 5678.
The transition from academic theory to deployed market infrastructure requires an exhaustive understanding of model architectures, the signal-to-noise ratios of various textual media sources, the temporal decay velocity of predictive power, and the complex microstructure mechanics that govern trade execution. This report investigates the intersection of natural language processing and quantitative finance, detailing how modern language models capture alpha in short-horizon trading environments.
Evolution of Sentiment Extraction Methodologies
The methodological approach to quantifying sentiment has evolved through distinct technological phases, moving from rigid lexical rules to deep contextual and generative understanding. Each architectural advancement has yielded measurable improvements in predictive accuracy, signal generation, and risk-adjusted portfolio performance.
Lexicon-Based Methods and Early Heuristics
Initial attempts to measure market sentiment relied heavily on lexicon-based approaches, most notably the Loughran-McDonald (LM) financial dictionary, alongside general-purpose sentiment tools such as VADER and TextBlob 5611. These methods operate deterministically by counting the frequency of predefined positive or negative words within a document 67. While computationally inexpensive and highly interpretable, lexicon methods suffer from a severe structural limitation: they evaluate words in isolation, ignoring syntax, negations, and contextual financial nuance. For instance, the word "liability" might carry a negative weight in a standard dictionary but operates as a neutral accounting term in corporate filings.
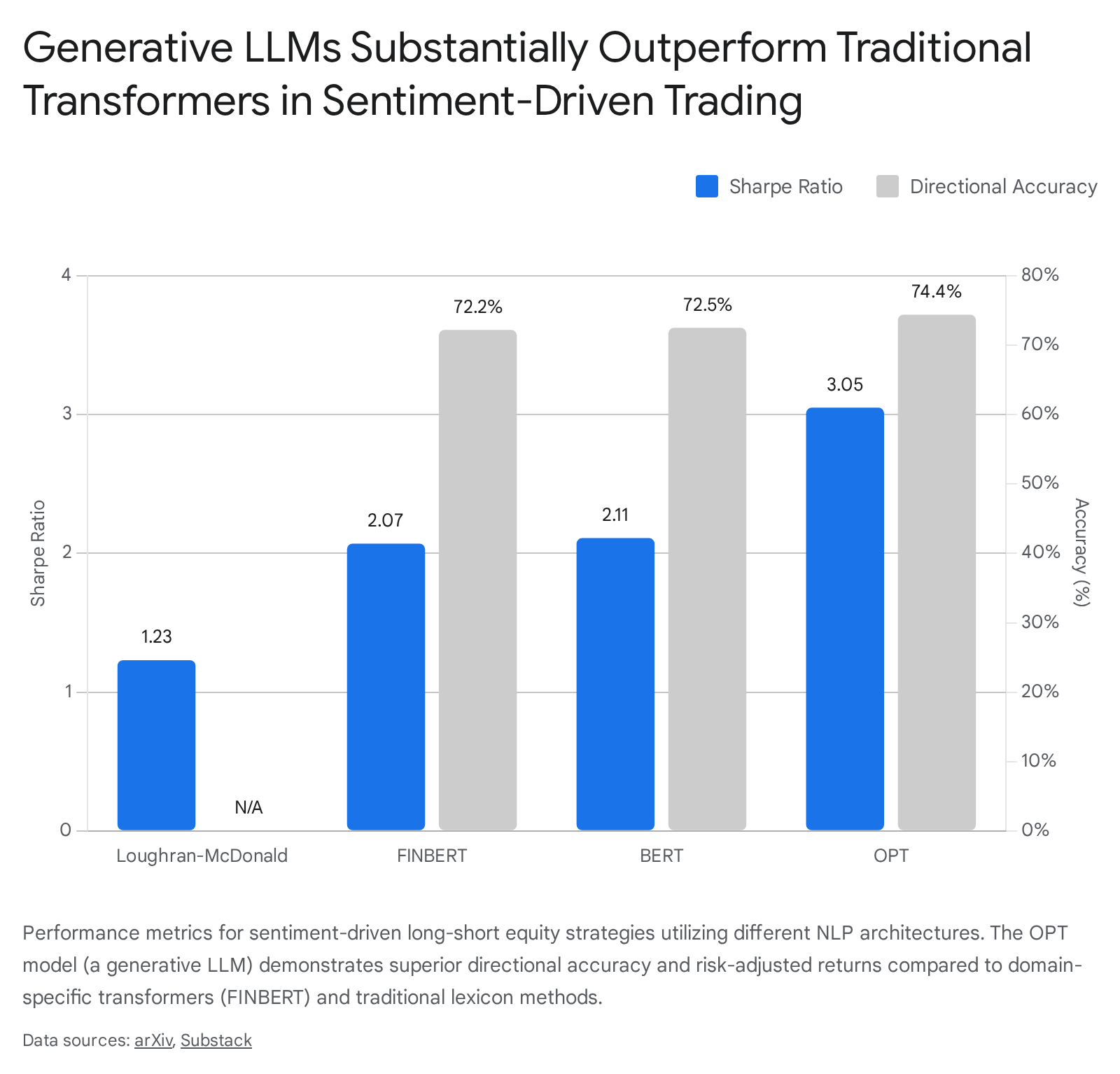
In empirical backtests analyzing US equities, strategies driven by traditional dictionary methods historically produced a modest Sharpe ratio of approximately 1.23, reflecting limited alpha generation capabilities after accounting for market beta and transaction costs 513. Furthermore, simple lexical approaches frequently trigger false positives during periods of elevated market stress, as they fail to distinguish between objective reporting of negative macroeconomic indicators and genuine firm-specific distress 11.
Traditional Machine Learning and Feature Engineering
As computational capabilities expanded, quantitative researchers transitioned to traditional machine learning algorithms, including Support Vector Machines (SVM), Naive Bayes, and Random Forests 711714. These models introduced the ability to weight features based on historical correlation with asset returns 15. Techniques such as Term Frequency-Inverse Document Frequency (TF-IDF) clustering allowed algorithms to organize headlines into semantic neighborhoods, providing a more robust representation of textual data than simple word counts 3.
Latent Semantic Analysis (LSA) combined with Independent Component Analysis (ICA) regularization emerged as a powerful technique to disentangle mixed topics within term-document matrices. While standard LSA factors tend to mix different topic categories, applying ICA regularization effectively localizes latent factors, allowing researchers to isolate specific news events - such as analyst upgrades, target price changes, or ESG controversies - that carry inherently higher predictive weight than general corporate announcements 16. While an improvement over raw word counts, traditional machine learning models still struggled with the inherent ambiguity, sarcasm, and complex linguistic structures prevalent in financial media 78.
Transformer Architectures and Domain-Specific Adaptation
The introduction of transformer-based deep learning architectures, notably Bidirectional Encoder Representations from Transformers (BERT), resolved many of the contextual limitations of earlier models. Transformers process text bidirectionally, allowing the algorithm to dynamically understand the semantic meaning of a word based on the entire sequence of words that precede and follow it 778.
To optimize performance for market applications, researchers developed FinBERT, a domain-specific variant pre-trained extensively on massive corpora of financial text, including corporate communications, earnings call transcripts, analyst reports, and regulatory filings 5818. FinBERT demonstrates a superior capacity to classify financial jargon, detect subtle shifts in management tone, and extract structured sentiment scores from highly technical documents 5818. In comprehensive evaluations utilizing over 965,000 US financial news articles from 2010 to 2023, FINBERT achieved a directional prediction accuracy of 72.2% for short-horizon returns, significantly outpacing classical baseline models 5. The model excels in structured classification tasks, effectively categorizing firm-specific news events into distinct bullish, bearish, or neutral vectors that quantitative systems can ingest natively 818.
Generative Large Language Models
The current frontier of financial text analysis is dominated by Large Language Models (LLMs) featuring generative, autoregressive architectures, such as GPT-4, Llama 3, and OPT 8910. Unlike BERT variants, which are optimized for structured classification, large generative models excel at processing highly ambiguous text, summarizing complex macroeconomic events, and executing zero-shot or few-shot reasoning without the absolute necessity of extensive task-specific fine-tuning 8911.
Recent empirical evaluations highlight the substantial predictive advantages of scaling model parameters. An analysis utilizing a 2.7-billion-parameter OPT model to predict three-day forward stock returns achieved an unprecedented 74.4% directional accuracy 513. This analytical precision translates directly to substantial economic value; a simulated daily-rebalanced, long-short portfolio utilizing OPT-derived sentiment scores generated a Sharpe ratio of 3.05 and cumulative returns of 355% over a two-year out-of-sample period (2021 - 2023), even after incorporating a realistic 10 basis point transaction cost assumption 513.
Hybrid Architectures and Agentic Systems
While individual models provide strong baseline signals, institutional frameworks increasingly utilize hybrid architectures that integrate generative AI with reinforcement learning (RL) and multi-agent systems. Reinforcement learning algorithms offer a robust framework for translating LLM-generated sentiment signals - when combined with technical indicators - into dynamic position sizing and automated trade execution 22. Furthermore, novel statistical cluster learners that operate without GPU-heavy neural network retraining can continuously organize headlines into semantic neighborhoods, adapting to shifting market regimes at sub-second latency and effectively zero marginal cost 3.
| Model Architecture | Primary Mechanism | Directional Accuracy | F1 Score | Simulated Sharpe Ratio |
|---|---|---|---|---|
| Loughran-McDonald | Lexical mapping, dictionary term matching | N/A | N/A | 1.23 |
| FINBERT | Domain-specific bidirectional contextual analysis | 72.2% | 0.731 | 2.07 |
| BERT | General-purpose bidirectional contextual analysis | 72.5% | 0.734 | 2.11 |
| OPT | Autoregressive generation, zero-shot reasoning | 74.4% | 0.754 | 3.05 |
Performance metrics aggregated from empirical evaluations of NLP models predicting short-term equity returns based on US financial news corpora (2010 - 2023) 513.
Textual Information Sources and Data Properties
The predictive utility of a sentiment signal is inextricably linked to the origin of the underlying text. Financial markets process information across a spectrum ranging from highly structured regulatory filings and professionally curated journalistic output to chaotic, retail-driven social media platforms. Each domain requires specialized NLP processing pipelines to extract alpha.
Traditional Financial News and Curated Media
Professional financial news from institutional providers (e.g., Bloomberg, Reuters, The Wall Street Journal) serves as the foundational data source for sentiment extraction 16122413. News content exhibits a relatively high signal-to-noise ratio due to editorial oversight, consistent syntactic structures, and a persistent focus on verifiable macroeconomic variables and firm-specific fundamentals 1314.
However, raw news datasets remain vast and require stringent statistical filtration to be utilized effectively. A quantitative assessment of over 241,000 global news sources revealed that approximately 85% of media outlets contribute primarily noise to predictive models rather than actionable insight 1. By applying strict statistical filtering frameworks - specifically isolating sources that maintain a t-statistic of 2.5 or higher against forward returns - researchers can identify roughly 36,000 high-quality sources 1. This source-selection filtration effectively increases the Information Coefficient (IC) of the aggregate sentiment signal from a negligible 0.006 to a statistically robust 0.041 1.
Social Media Platforms and Retail Attention
The proliferation of social media has radically altered the speed of information dissemination, allowing retail investor attention to directly influence short-term market microstructure 1215. Platforms such as Twitter (X) provide high-velocity data feeds, but the uncurated nature of the platform results in an exceptionally low signal-to-noise ratio 2816. Twitter sentiment is highly susceptible to bot activity, coordinated spam, and non-financial chatter 1328. Consequently, raw social media firehose data is frequently deemed too noisy for pure high-frequency trading without aggressive filtering mechanisms and entity recognition algorithms 1328.
Conversely, niche platforms like StockTwits constrain conversations explicitly to financial topics and allow users to voluntarily tag posts with directional intent ("bullish" or "bearish") 281731. This self-labeling creates a structurally cleaner dataset for training supervised machine learning models. A comprehensive analysis of over 550 million StockTwits posts from 2008 to 2022 demonstrates that while the median user possesses predictive skill equivalent to random guessing, a statistically significant subset of participants consistently generates alpha 1718. This indicates that social platforms harbor genuine price discovery mechanisms beneath the aggregate retail noise 1718.
Ultimately, social media acts primarily as a measure of aggregate attention and volatility rather than a reliable indicator of directional fundamental value. High volumes of social media chatter frequently forecast increases in idiosyncratic volatility, retail order imbalances, and trading volume, whereas organized institutional news coverage tends to resolve uncertainty and subsequently compress volatility 413.
Corporate Disclosures and Linguistic Complexity
A critical secondary variable in natural language processing is linguistic complexity, often quantified via readability metrics such as the Flesch-Kincaid index 333435. High linguistic complexity in corporate earnings calls, SEC 10-K filings, or dense news publications (such as The New York Times, which frequently tests at a 10th-to-12th-grade reading level) actively obscures the underlying financial reality 3637.
When financial information is difficult to parse or relies on extensive jargon, market participants require more time to absorb and interpret the data. This cognitive friction leads to delayed price adjustments, prolonged volatility following earnings announcements, and temporary market mispricing 3336. Advanced NLP models must be calibrated to account for not just the emotional polarity of a document, but the syntactic complexity required to interpret it 3338. Furthermore, year-over-year textual changes in SEC filings provide a slow-moving, durable signal; aggressive structural rewrites of risk factors or management discussion sections often signal underlying corporate uncertainty, providing a persistent short-horizon predictor independent of immediate news sentiment 39.
| Feature | Traditional Financial News | Twitter (X) | StockTwits |
|---|---|---|---|
| Primary Driver | Fundamentals, Macroeconomics | Retail Attention, Reactionary | Retail Sentiment, Peer Trading |
| Signal-to-Noise Ratio | High (Editorially curated) | Very Low (Requires heavy filtering) | Moderate (Finance-specific, self-tagged) |
| Market Impact | Predicts directional returns, reduces volatility | Predicts volatility spikes, order imbalances | Predicts localized short-term retail momentum |
| Data Velocity | Moderate (Publication delays) | Extremely High (Real-time events) | High (Market hours focus) |
Comparative analysis of textual data sources utilized in quantitative trading models 24132817.
Sentiment Signal Decay and Temporal Dynamics
The profitability of any sentiment-based algorithmic strategy is entirely dependent on the execution horizon. The predictive power of text decays over time as the broader market absorbs the information, forcing quantitative systems to optimize their holding periods to match the specific diffusion velocity of the signal.
Intraday Velocity and Asymmetric Shocks
Sentiment signals derived from social media exhibit extreme velocity. Shocks in aggregate retail sentiment transmit to the market rapidly, often impacting asset prices in under an hour 40. Despite this rapid integration, the economic relevance of the shock is not fleeting; statistically significant effects on price action can persist for up to 33 hours following the initial event 40. This dynamic fundamentally challenges traditional end-of-day volatility models, as the bulk of the alpha generation and risk exposure occurs entirely within intraday trading sessions 40.
Furthermore, the market impact of sentiment is highly asymmetric. Negative social media sentiment acts as a first-order driver of downside volatility, exhibiting a structurally larger and faster impact on stock returns than equivalent positive sentiment 40. This asymmetry requires portfolio managers to weigh bearish textual indicators more heavily when designing risk-mitigation overlays or crisis-alpha strategies 404142.
Multi-Day Persistence and Horizon Specificity
While social media signals decay in a matter of hours, signals derived from long-form news, earnings calls, and regulatory filings display multi-day or multi-week persistence. Quantitative research utilizing Information Coefficient (IC) decay matrices reveals strong diagonal dominance, indicating that specific news sources are highly horizon-specific 1. Fast-moving algorithmic news wires produce sharp signals that decay entirely by the end of the first trading day ($H=1$), whereas deep-dive investigative journalism or complex macroeconomic reports carry thematic content that slowly diffuses into prices over evaluation horizons spanning 10 to 63 days 143.
Market Regime Dependency
The shape and duration of the sentiment decay profile are heavily influenced by prevailing market regimes. During periods of acute financial crisis, the market processes information rapidly, concentrating the sentiment signal almost entirely in short-horizon windows 1. Market participants operate in a heightened state of alert, quickly arbitraging away obvious sentiment discrepancies.
Conversely, during periods of elevated macroeconomic uncertainty (such as post-pandemic reopening phases or shifting central bank rate cycles), the information diffusion window stretches significantly. In these complex environments, the predictive strength of sentiment signals has been observed to nearly double at a 63-day horizon ($H=63$) compared to a 1-day horizon ($H=1$), as institutional investors struggle to accurately price multi-layered thematic shifts over short periods 1. Recognizing these structural regime shifts allows quantitative funds to dynamically adjust their holding periods and volatility-targeting overlays 14.
Market Microstructure and Execution Frictions
A pervasive issue in empirical asset pricing is the discrepancy between theoretical, paper-based backtests and realized, live-trading performance. NLP sentiment strategies, particularly those trading at high frequencies, are exceptionally vulnerable to market microstructure phenomena that can create the illusion of alpha in historical simulations.
Bid-Ask Bounce and Return Reversals
One of the most persistent quantitative anomalies utilized in short-term trading is the return reversal, where stocks that perform poorly over a daily or weekly horizon tend to bounce back in the subsequent period 4419. Early behavioral literature attributed this entirely to investor overreaction to news 44. However, rigorous microstructure analysis reveals that a significant portion of this observed reversal is a mechanical artifact known as the "bid-ask bounce" 444720.
The bid-ask bounce occurs when consecutive trade executions oscillate between the market maker's bid price and ask price without any true change in the fundamental value of the asset 4749. If the closing trade of Day 1 occurs at the bid (a lower price) and the opening trade of Day 2 occurs at the ask (a higher price), the historical data records a positive return. According to the Blume and Stambaugh bias framework, when executing high-turnover sentiment strategies on low-priced or less liquid stocks, this mechanical bounce systematically inflates the calculated returns of contrarian algorithms 2021.
To isolate genuine sentiment-driven alpha from microstructure noise, sophisticated quantitative pipelines must employ rigorous adjustments. Researchers calculate returns using mid-quote prices rather than closing transaction prices, or introduce a deliberate one-day lag between signal generation and the portfolio holding period to allow the bounce to dissipate 2021. Studies applying these controls confirm that while the bid-ask bounce accounts for a portion of the anomaly, genuine sentiment-driven price pressure - particularly liquidity shocks on the long side and sentiment shocks on the short side - remains a robust predictor of short-horizon reversals 21.
Transaction Costs and Slippage
The theoretical edge of NLP signals degrades rapidly upon contact with execution costs. Market impact (slippage) and direct trading fees aggressively consume the alpha of fast-decaying strategies 4751. For example, studies testing volatility-based sentiment rotation algorithms noted that while win rates exceeded 54%, the annualized Sharpe ratios suffered sharp declines - and in some backtest configurations, catastrophic failures - once realistic transaction costs of 10 basis points per round-trip trade were strictly applied 51314.
Capacity constraints dictate the maximum Assets Under Management (AUM) a sentiment strategy can deploy before the fund begins trading against its own footprint. For low-latency news strategies, the available liquidity in the order book limits execution size, forcing institutional managers to accept sub-optimal fills or delay execution, which in turn subjects the trade to signal decay 5253. As alternative data feeds become commoditized across the industry, alpha compression accelerates, requiring continuous pipeline optimization to maintain a statistical edge 53.
Short Selling Constraints and Borrow Costs
A significant portion of sentiment-driven alpha relies on shorting equities associated with negative news or bearish social media momentum 2255. However, highly shorted stocks incur substantial borrow costs. Analysis of Securities Finance (MSF) databases reveals that many standard investment factors suffer severe performance drag due to the high borrow costs associated with executing the short leg of the portfolio 55. If the stocks a sentiment model identifies for shorting are already at historically high short utilization levels, the trade is likely crowded, and the borrow cost will entirely consume the predictive edge 5355. Quantitative frameworks must explicitly integrate borrow cost data and utilization constraints into the portfolio optimization process to prevent executing theoretically profitable but practically unviable short trades 5355.
Cross-Sectional and Regional Variations
The predictive efficacy of NLP models is not uniform across global equities. Structural differences in market development, regulatory environments, and firm capitalization deeply dictate how textual sentiment translates into physical price action.
Firm Capitalization Effects
Within any given geographic market, firm capitalization heavily influences the behavior and longevity of text-based signals. Mega-cap technology stocks possess massive, continuous media footprints and benefit from hyper-efficient price discovery, rendering them highly resilient to generic social media noise 13.
Conversely, small-cap and micro-cap equities exhibit pronounced, asymmetric sensitivity to sentiment shocks 1356. The lack of continuous analyst coverage dictates that when news does break for a small-cap firm, it provides a proportionately larger information shock. Research indicates that sentiment signals applied to small-cap universes (such as the Russell 2000 or specific Asian small-cap indices) generate substantially higher Information Ratios than those applied to large-cap indices 56. Because liquidity is inherently lower, the incorporation of news into the small-cap stock price is drawn out over several days or weeks. This slower decay allows quantitative algorithms to capture steady performance even when utilizing longer signal aggregation windows of up to a month, effectively neutralizing the drag of high-turnover transaction costs 56.
Developed Versus Emerging Markets
Developed markets (such as the United States and the United Kingdom) are characterized by high liquidity, robust data availability, and heavily populated analyst coverage 5758. In these environments, news sentiment is priced in with extreme rapidity. Correlation studies demonstrate that while news drives returns during tranquil periods in developed economies, the relationship often inverts during crises; massive price drawdowns dictate subsequent media sentiment rather than the reverse, indicating a reactive rather than predictive media landscape during systemic stress 16.
Emerging markets present a distinct quantitative challenge and opportunity. Data scarcity, lower institutional participation, and less dependable corporate reporting create pervasive information asymmetry 5758. However, this inefficiency is a boon for sophisticated NLP applications. Because there are fewer algorithmic players reacting instantaneously to news feeds in emerging markets, sentiment signals decay at a measurably slower rate 55. This slower diffusion allows quantitative strategies to execute over longer holding periods, reducing the crippling effects of turnover and slippage 5558. Furthermore, macroeconomic studies reveal that long-term sentiment spillovers from developed markets heavily influence emerging market volatility, providing a predictable macro-level lead-lag relationship that can be exploited via cross-market hedging strategies 2360.
| Market Characteristic | Developed Markets / Large-Cap | Emerging Markets / Small-Cap |
|---|---|---|
| Information Environment | Data-rich, continuous coverage | Data-scarce, intermittent coverage |
| Price Discovery Speed | Near-instantaneous | Gradual, delayed incorporation |
| Signal Decay Velocity | Extremely fast (Intraday to 1-day) | Slow (Multi-day to multi-week) |
| Microstructure Friction | Low slippage, high capacity | High slippage, bid-ask bounce risk |
| Optimal Trading Strategy | High-frequency execution, event-driven | Multi-day swing trading, trend-following |
Comparison of sentiment signal characteristics across different liquidity and capitalization regimes 55565758.
System Architecture and Backtesting Integrity
The development of automated trading systems based on textual data is fraught with statistical traps. The complexity of handling unstructured text amplifies standard quantitative errors, making rigorous system architecture and data hygiene prerequisites for live-market success.
Look-Ahead Bias and Timestamp Alignment
Look-ahead bias is the most pervasive and destructive error in the backtesting of sentiment strategies 6162. This bias occurs when an algorithm bases a historical trade decision on information that was not mathematically available at the exact moment of simulated execution 6163.
In NLP applications, look-ahead bias frequently manifests through poor timestamp alignment 6465. News articles published asynchronously across global markets must be precisely parsed, converted to standard UTC, and aligned with the operating hours of the target equity exchange (e.g., Eastern Standard Time) to ensure the signal precedes the trade 65. If a news source dynamically updates an article's text but maintains the original publication timestamp, a backtest querying that updated text assumes impossible knowledge of future events 6164. Rigorous pipelines must rely on point-in-time data archives that reflect exactly what text was visible to the market at a specific millisecond in history 61.
LLM Pre-Training Contamination
When testing modern Large Language Models, researchers face the unique risk of pre-training contamination. Models such as GPT-4 possess innate, generalized knowledge of post-2020 events embedded deep within their neural weights 2224. Consequently, an LLM may accurately "predict" historical price movements during a backtest because the outcomes of those historical events were included in its original training corpus 22. To establish true out-of-sample validity and eliminate this contamination, quantitative backtests must programmatically mask entity names, dates, and highly specific product identifiers before feeding historical text into pre-trained LLMs 2261.
Overfitting and Walk-Forward Validation
Financial text is inherently messy and non-stationary. Algorithms must account for restated earnings reports, deleted social media posts, and delayed regulatory filings. If an NLP model is trained too aggressively on historical sentiment variations, it risks overfitting - capturing random market noise rather than durable behavioral patterns 6162.
Robust quantitative frameworks combat overfitting by employing walk-forward optimization, ensuring that model parameters are continuously recalibrated on rolling windows of data rather than statically fitted to a single historical epoch . Furthermore, rigorous validation must stress-test the algorithm against discrete market crises (e.g., the 2010 Flash Crash, the 2020 pandemic selloff, the 2022 rate-hike cycle) to verify that the sentiment processing logic and risk management parameters remain coherent during periods of extreme systemic volatility . Strategies that demonstrate exceptional performance on paper but lack extensive, out-of-sample stress testing invariably suffer severe degradation when deployed into live trading environments 61.