LLM Sentiment from Financial Disclosures as a Return Signal
Evolution of Financial Textual Analysis
The integration of unstructured textual data into quantitative finance has fundamentally altered the methodologies utilized in algorithmic trading and fundamental asset pricing. Historically, market participants relied on rules-based natural language processing and lexicon-driven approaches to gauge the underlying sentiment of corporate disclosures. The standard methodology involved parsing financial documents and counting the frequency of positive and negative terms using domain-specific dictionaries, most notably the Loughran-McDonald lexicon, to compute an aggregate sentiment score 12. While these early methods provided a systematic mechanism to process large volumes of 10-K filings, 10-Q statements, and earnings call transcripts, they were inherently constrained by their inability to interpret linguistic context, sentence semantics, and nuanced financial jargon. Lexicons treat documents as a "bag of words," failing to capture modifiers, negations, or the strategic ambiguity frequently employed by corporate executives 34.
The transition from dictionary-based methods to machine learning models marked a significant structural shift in financial signal extraction. The introduction of BERT (Bidirectional Encoder Representations from Transformers) and its finance-specific variants, such as FinBERT and RoBERTa, enabled algorithms to evaluate the bidirectional context of a word within a sentence 56. FinBERT, which was fine-tuned on the Financial PhraseBank dataset, achieved substantial accuracy in classifying financial sentences into rigid positive, negative, or neutral categories, effectively serving as a high-throughput qualitative gatekeeper 56. However, traditional encoder-based models still encounter difficulties when confronted with complex forward-looking safe harbor statements and the intricate legal boilerplate pervasive in modern regulatory documents 39.
The advent of large language models (LLMs) featuring autoregressive transformer architectures - including GPT-4, LLaMA, Gemini, and DeepSeek - has significantly expanded the frontier of textual analysis in asset management. Unlike discriminative models that output rigid probability scores across predefined sentiment classes, generative LLMs possess the capability to parse subtle emotional shifts, decode sarcasm or hedged language, and isolate sentiment specific to individual business segments, product lines, or overarching macroeconomic themes 345. These generative architectures can reason over extended passages, contextualizing a seemingly negative term (e.g., "cost reduction") as a positive strategic initiative depending on the broader corporate narrative.
Empirical evaluations demonstrate that LLM-based sentiment strategies generate a substantial performance premium over traditional lexicons. Data analyzing the US equity market from 2010 onward indicates that an LLM-based sentiment signal utilized in a long-short strategy yielded an annualized return of 8.4%. This performance effectively doubled the return of the lexicon-based benchmark, which stood at 4.2% over the identical period 7. This performance divergence highlights the structural limitations of rules-based algorithms, which are increasingly degraded by mass adoption on the buyside and by corporate management actively refining their disclosure language to "game" simple dictionary flags 7. Furthermore, the extracted features from LLMs maintain a significant correlation with traditional rules-based counterparts, confirming that both approaches measure the same underlying ground truth, but the LLM methodology captures the signal with far greater fidelity 7.
| Corporate Topic Category | LLM Annualized Excess Return | Lexicon Benchmark Evaluation | Signal Importance Modifier |
|---|---|---|---|
| Overall Strategy | 8.4% | 4.2% | N/A |
| Financial Results | 6.4% | Baseline Decay Observed | "High Importance" Yields 6.4% |
| Operations | 4.5% | Baseline Decay Observed | "Medium Importance" Yields 3.2% |
| Competition | 3.7% | Baseline Decay Observed | N/A |
| Macro Factors | 2.8% | Baseline Decay Observed | "Low Importance" Yields 1.7% |
The data further demonstrates that the thematic focus of the sentiment extraction dictates the efficacy of the resulting return signal. Sentiment explicitly tied to direct financial results produced the strongest excess long-short returns at 6.4%, substantially outpacing signals derived from operations (4.5%), competition (3.7%), and broader macro factors (2.8%). Moreover, when the LLM flagged these financial performance events as possessing "high importance," the sentiment signals delivered nearly four times the payoff of signals categorized as "low importance" (1.7%) 7.
Processing Regulatory Filings and 10-K Reports
Structural Challenges of SEC Filings
Annual 10-K and quarterly 10-Q filings present severe infrastructural challenges for artificial intelligence processing pipelines due to their extreme length, complex tabular structures, and heavy reliance on standardized legal language. The 2005 Securities and Exchange Commission (SEC) mandate requiring explicit risk factor disclosures resulted in expanded documentation that frequently blends material economic risks with boilerplate legal protections 2. This regulatory evolution created an environment where documents became increasingly bloated, making the isolation of genuine economic sentiment difficult.
Large language models processing these texts out-of-the-box can suffer from context collapse or misinterpret protective legal clauses as acute negative sentiment 9. Legal boilerplate is typically inserted to address remote contingencies or to forestall far-fetched interpretations in potential litigation. Because these clauses are repeated verbatim across thousands of documents, an uncalibrated LLM might assign undue negative weight to a standard safe harbor statement, thereby skewing the aggregate sentiment score of the filing 29. Distinguishing between a routine disclosure of systemic market risk and a specific, localized threat to the firm's immediate profitability requires deep contextual reasoning that early-generation NLP tools lacked.
Context Window Constraints and Chunking Techniques
To handle corporate documents that significantly exceed standard context windows - which traditionally ranged from 4,000 to 32,000 tokens - quantitative researchers employ sophisticated document chunking and Retrieval-Augmented Generation (RAG) frameworks 8. Filings are systematically segmented into logical sections, such as Management's Discussion and Analysis (MD&A), Risk Factors, and Financial Statements. To ensure continuity and prevent the loss of context between these segments, engineering pipelines frequently utilize sliding windows or pagination overlays. The goal of this segmentation is to preserve coherent financial concepts while keeping the text chunks small enough for dense vector embedding 8.
When a specific sentiment evaluation is required, the system relies on a retrieval step to identify only the most semantically relevant text chunks from the vector database 812. Furthermore, processing the complex tables embedded within 10-K forms introduces distinct data extraction hurdles. Standard optical character recognition (OCR) often flattens tables into continuous text, destroying the spatial relationships between column headers and numerical values. Specialized architectures, such as JPMorgan Chase's DocLLM, address this by preserving the spatial layout and bounding box coordinates of financial tables within PDFs. This visual-spatial tracking prevents data misalignment, ensuring that the language model correctly associates a specific financial metric with its corresponding footnote or time period 13.
Long-Context Model Vulnerabilities
Recent algorithmic advancements have introduced long-context large language models capable of processing up to one million tokens, theoretically allowing an entire 10-K filing to be ingested in a single continuous pass 8. Models such as GPT-4-Turbo and Claude 3 have expanded their working memory to accommodate these massive inputs. However, empirical evaluations of these long-context models operating on real-world financial news and filings indicate significant brittleness and unreliability at extended lengths 9.
As the context length and task difficulty increase, these state-of-the-art models often exhibit catastrophic instruction-following failures. For instance, testing GPT-4-Turbo at a 128,000-token context length revealed an alarming rate of degenerate outputs, where the model began repeating itself or sequentially counting article IDs rather than executing the assigned analytical task. In specific complex evaluations, degenerate responses reached 42% 9. Models also experience the "lost in the middle" phenomenon, where critical financial data points buried deep within the document's center are completely ignored during the generation phase 9. Consequently, tiered retrieval systems and multi-agent orchestration - where specialized sub-agents handle distinct extraction, summarization, and comparative tasks - remain the standard methodology for reliable institutional implementation over brute-force long-context ingestion 810.
Distillation and Cross-Market Alignment
The application of LLMs to international regulatory filings requires sophisticated cross-lingual alignment and structural standardization. In non-US markets, annual reports often adhere to distinct domestic accounting standards and formats. For example, in Japan, annual business reports known as Yuho filings contain highly specific domestic regulatory structures that do not map seamlessly to US 10-K reporting standards.
Frameworks like CrossAlpha address this challenge by utilizing LLMs not as direct sentiment classifiers, but as "dataset-construction infrastructure." Through an LLM-based Disclosure Distillation stage (utilizing models like GPT-4), heterogeneous foreign language filings are translated, parsed, and compressed into a standardized ten-category English business schema 11. This process forces the language model to read the document end-to-end and extract specific facts regarding the firm's business model, competitors, and strategic outlook, while actively ignoring market-specific formatting quirks.
By isolating the underlying economic reality from regulatory formatting, the algorithm identifies cross-market peers based on semantic business similarities rather than traditional, often rigid, industry classification codes.
| Evaluation Metric | US-to-Japan (Cross-Market) | Domestic Japan (Baseline) |
|---|---|---|
| Annualized Information Ratio (ICIR) | 0.39 | 0.07 |
| Annualized Long-Short Sharpe Ratio | 0.39 | 0.05 |
| Maximum Drawdown (MaxDD) | -6.8% | -9.5% |
| Annualized Long-Short Return | 1.2% | 0.3% |
| Cumulative Long-Short Return | 13.2% | 3.0% |
Evaluating US-to-Japan cross-market return predictions using these disclosure-derived semantic links demonstrated profound improvements over domestic text baselines. The cross-market signals achieved an Annualized Information Ratio (ICIR) of 0.39 and an ending cumulative long-short return of 13.2%, compared to an ICIR of 0.07 and a cumulative return of 3.0% for the domestic baseline 11. The success of these architectures confirms that LLMs can standardize global financial data, facilitating peer-momentum and sentiment strategies that operate seamlessly across fragmented international markets.
Extraction Dynamics in Earnings Call Transcripts
Prepared Remarks Versus Unscripted Analyst Interaction
Earnings call transcripts provide a dynamic and highly informational contrast to the heavily sanitized, compliance-reviewed text of SEC filings. These transcripts capture unscripted interactions between corporate executives and financial analysts, offering real-time, unfiltered reflections of corporate confidence and market perception. Large language models excel in this domain by differentiating between the carefully crafted prepared remarks delivered by a CEO and the spontaneous, often adversarial, exchanges that occur during the subsequent Q&A session.
While executives utilize earnings calls to frame corporate narratives positively, the Q&A segment forces management to respond to direct pressure. LLMs applied to these unscripted sessions can measure specific emotional classifications at the sentence, speaker, and document level, identifying nuances such as evasion, hesitation, or defensive posturing 12.
Costly Signaling in Mergers and Acquisitions
Applying LLM-based sentiment extraction to these transcripts reveals significant emotional asymmetries that carry predictive weight. Professional norms within the institutional finance industry dictate a baseline of professional optimism, politeness, and deference to management during public calls. Consequently, expressions of overt anxiety or fear by sell-side analysts are exceedingly rare events. When these negative sentiments do manifest, they represent a highly concentrated signal.
Textual analysis grounded in the Russell valence-arousal framework demonstrates that analyst anxiety during unscripted M&A conference calls serves as a robust leading indicator of value destruction. In an analysis of 2,604 deals from 2003 to 2023, while generic optimism simply validated assumed synergies, analyst anxiety and fear functioned as strong predictors of post-call underperformance. The market reacts disproportionately to these negative emotional signals, a dynamic consistent with a "costly signaling" framework where analysts break professional decorum only when the underlying corporate risks are perceived as severe 1. Elevated anxiety in these specific contexts exhibits significant predictive power for deal failure, operational integration delays, and long-run asset drift 1. Models tracking these highly specific emotional states provide a granular layer of risk assessment that generalized positive/negative polarity scores fail to capture.
Prompt Engineering and Sensitivity in Financial Contexts
Format Structures and In-Context Learning
The sensitivity of generative language models to their input instructions necessitates rigorous and systematic prompt engineering. Unlike traditional statistical models where hyperparameter tuning controls the quantitative output, the behavior and accuracy of an LLM are governed almost entirely by the semantic structure and formatting of the input prompt. Evaluations across multiple open-source and proprietary models - including Claude, DeepSeek, GPT-4, and LLaMA - indicate that enforcing structured output formats significantly improves the model's precision in data extraction 1319.
Prompting an LLM to return its analysis in structured formats such as JSON, YAML, or Markdown restricts the model from generating extraneous conversational text and forces it to map its findings to strict data keys. Furthermore, employing techniques like Chain-of-Thought (CoT) and In-Context Learning (ICL) forces the model to articulate its deductive steps prior to issuing a final sentiment classification 19. By decomposing a broad instruction into discrete analytical stages - for example, instructing the model to first isolate revenue metrics, then evaluate management tone regarding supply chains, and finally synthesize an aggregate sentiment score - the output becomes highly accurate and auditable 1920. This structured decomposition minimizes instances where the LLM conflates separate business segments or allows a positive macroeconomic outlook to mask deteriorating core corporate fundamentals 314.
Latent Affective Prompt Sensitivity
A critical, yet frequently under-researched, variable in LLM deployment is the latent affective characteristic of the prompt itself. The emotional framing and underlying tone of the human query directly influence the factual accuracy, coherence, and bias of the generated output. Systematic studies examining prompt variations reveal that supplying an LLM with negatively framed instructions results in an 8.4% decline in factual accuracy 13.
When processing queries heavily laden with negative sentiment, the model's probability distribution shifts toward speculative, exaggerated, or alarmist responses. The language model mimics the anxiety embedded in the prompt, leading to hallucinations or the amplification of minor risk factors. Conversely, highly positive prompts often induce excessive verbosity and sentiment propagation, where the model outputs overly optimistic assessments that ignore or downplay underlying systemic risks 13. In the context of quantitative finance, where inputs are algorithmically generated and fed into the LLM at high frequencies, failing to neutralize the prompt language can systematically bias the resulting sentiment scores, leading to severely skewed portfolio allocations and risk estimations.
Empirical Return Signals and Strategy Performance
Hybrid Sentiment-Trading Frameworks
The translation of LLM-extracted sentiment into actionable, systematic trading strategies has yielded robust empirical outcomes, challenging traditional efficient market assumptions. A prominent study implementing a hybrid sentiment-trading strategy utilized FinBERT to process over nine million data points - including 10-K/10-Q SEC filings and financial news headlines. FinBERT operated as a high-throughput filter to eliminate routine noise. The remaining high-conviction data points were then passed to Google Gemini 2.5 Flash, which performed qualitative reasoning to validate the semantic context of the signal 6.
Tested over a 16-year period across the top S&P 500 constituents using a dollar-neutral long/short framework, this "Data Funnel" architecture demonstrated remarkable performance. The strategy generated a mean excess return of 51.02% per annum, net of transaction costs 6.
| Performance Metric | Hybrid AI Strategy (FinBERT + Gemini) | Random Draw Baseline (Ablation Study) |
|---|---|---|
| Annualized Return | 51.02% | -10.05% |
| Sharpe Ratio | 1.06 | -2.30 |
| Sortino Ratio | 2.61 | -2.95 |
| Annualized Volatility | 48.95% | N/A |
| t-Statistic (Statistical Significance) | 4.01 | -8.35 |
The pronounced divergence between the Sharpe ratio (1.06) and the Sortino ratio (2.61) indicates substantial positive skewness (6.11) and high convexity in the return distribution. This suggests that the system effectively captured upside volatility momentum while strictly limiting downside risk 6. To validate the informational value of the AI sentiment signals, researchers conducted an ablation study replacing the LLM-generated signals with uniform random draws. The random baseline resulted in an annualized return of -10.05% and a Sharpe ratio of -2.30, confirming that the execution framework itself provided no structural advantage and that the generated alpha was entirely driven by the textual classification quality of the AI 6. Furthermore, sensitivity testing demonstrated that even under pessimistic transaction cost assumptions of 30 basis points, the strategy maintained an annualized return of 33.68% 6.
Multi-Agent Fundamental Analysis Platforms
Comprehensive agentic systems that merge text analysis with quantitative metrics have similarly demonstrated massive outperformance. The MarketSenseAI framework, which processes historical prices, SEC filings, earnings calls, and macroeconomic reports through a network of specialized LLM agents, provides a clear example of scalable alpha generation 2223.
Evaluated against the S&P 100 over a two-year window (2023-2024), a capitalization-weighted portfolio driven by MarketSenseAI achieved cumulative returns of 125.9%, dramatically outperforming the benchmark index return of 73.5%. The strategy maintained a Sortino ratio of 4.43, which was 16% higher than the benchmark. When the evaluation universe was expanded to the broader S&P 500 throughout 2024, the framework's capitalization-weighted portfolio delivered returns of 48.7% compared to the benchmark's 25.6%. This demonstrates that multi-modal LLM evaluations can systematically construct portfolios with superior risk-adjusted profiles that scale across broader market capitalizations 22.
Volatility Regime Conditioning and Delayed Arbitrage
Market sentiment does not operate as a uniform predictor across all market environments. The efficacy of a sentiment signal is heavily dependent on the broader macroeconomic volatility state. The mechanism driving this phenomenon is the "delayed arbitrage trap": rational arbitrageurs generally avoid attacking minor mispricings immediately, preferring to wait for synchronized market action to avoid taking on excessive idiosyncratic risk 24.
During periods of low volatility (commonly measured by the VIX), arbitrageurs tend to "ride the sentiment," creating momentum in sentiment-prone equities, such as small-cap or highly volatile non-dividend payers. Conversely, when volatility spikes, synchronized corrections occur, rapidly reversing prior sentiment-driven gains. Incorporating VIX-based regime conditioning into LLM sentiment strategies transforms borderline signals into substantial alpha.
A cross-sectional strategy that holds sentiment-prone stocks during low VIX environments and dynamically rotates to sentiment-immune stocks when the VIX exceeds its 25-day moving average by 10% generates 20% to 40% annualized returns. Unconditional strategies utilizing the exact same underlying LLM sentiment scores frequently generate losses or negligible single-digit returns. This proves that the signal's true value lies not merely in predicting the sentiment direction, but in knowing precisely when sentiment matters to market participants based on overarching liquidity and volatility constraints 24.
Market Microstructure and Emerging Market Friction
Applying these models to emerging or heavily regulated markets highlights the current limitations of generalized LLM sentiment models. In China's A-share market, predictions derived from advanced LLMs exhibited highly volatile and inconsistent accuracy. A study evaluating GPT-4's performance in predicting earnings and stock returns in the A-share market from 2000 to 2023 found that the model's predictive accuracy fluctuated violently between 10.62% and 48.67%, yielding an average F1 score of only 0.30 25.
Despite this poor accuracy, the LLM maintained improperly high prediction confidence levels between 75% and 90%. The stock returns associated with these signals swung from -4.86% to 13.59%, displaying no consistent correlation with the model's predictions 25. This severe deterioration in signal quality is attributed to the distinct market microstructures of the A-share environment, which features a remarkably high proportion of retail investors, frequent state policy interventions, and distinct localized sentiment drivers. Global LLMs, trained predominantly on Western financial literature and operating under efficient-market assumptions, struggle to map extracted sentiment to price action in environments driven by retail behavioral cascades or unannounced regulatory shifts 25.
Systemic Risks in LLM-Driven Quantitative Finance
Look-Ahead Bias and Temporal Hallucinations
The most severe structural flaw in applying commercial LLMs to historical financial analysis is look-ahead bias, which often manifests as "temporal hallucination." Quantitative trading relies entirely on the concept of point-in-time data to validate strategy backtests. If a quantitative model tests an algorithm in 2021 utilizing macroeconomic data or earnings surprises that were only published in 2022, the backtest is contaminated and invalidated 2627.
Commercial LLMs are trained on massive, unstructured datasets extending up to their respective knowledge cutoffs. If a researcher feeds a news headline or 10-K snippet from January 2021 into an LLM trained on data through 2024 and asks it to predict the subsequent market reaction, the model already possesses latent, implicit knowledge of the actual historical outcome 2627. It does not reason about the future; it simply recalls it.
A benchmark study evaluating this phenomenon (Look-Ahead-Bench) applied commercial LLMs to stock selection across two identical six-month periods: one inside the model's training window (in-sample) and one outside (out-of-sample). A strategy utilizing a 671-billion-parameter model (DeepSeek 3.2) generated a highly impressive +20.73% annualized alpha in-sample. However, when applied to the out-of-sample period, the alpha immediately swung to -1.04% 27.
This phenomenon, termed the "Scaling Paradox," reveals that larger models with greater memorization capacity exhibit significantly worse out-of-sample decay. Their initial backtest performance is driven almost entirely by data recall rather than genuine deductive reasoning 27. Temporal integrity requires strict bitemporal data management, ensuring the model predicting a past event has mathematically zero access to data generated after that specific timestamp.
Alpha Decay and Factor Crowding
Alpha decay - the phenomenon where predictive financial signals lose their efficacy over time - is a known feature of financial markets, but it accelerates rapidly with the proliferation of AI-driven trading. Traditional quantitative factors decay due to overfitting and factor crowding, which occurs when multiple market participants deploy identical signals, thereby arbitraging the inefficiency away 1516.
When investment firms utilize off-the-shelf LLMs to generate trading features without proprietary guardrails, the models tend to default to universally documented patterns. Because LLMs are trained on vast corpora of historical financial research, they naturally gravitate toward established market anomalies (such as momentum, RSI, or standard size/value factors). This reliance on existing knowledge pools exacerbates factor homogeneity and crowding 1516. If every LLM sentiment parser is interpreting a specific phrasing in a 10-K report as a "sell" signal simultaneously, the resulting liquidity rush instantly destroys the alpha.
Mitigation Through Structural Regularization
To combat the inherent decay and crowding of LLM-generated signals, sophisticated autonomous frameworks, such as AlphaAgent, introduce rigorous mathematical regularization into the generative pipeline. Rather than allowing the LLM to output direct buy/sell decisions or simplistic sentiment scores, the agent is constrained to generate mathematical expressions (formulaic alphas) derived from price, volume, and structured sentiment data 1731.
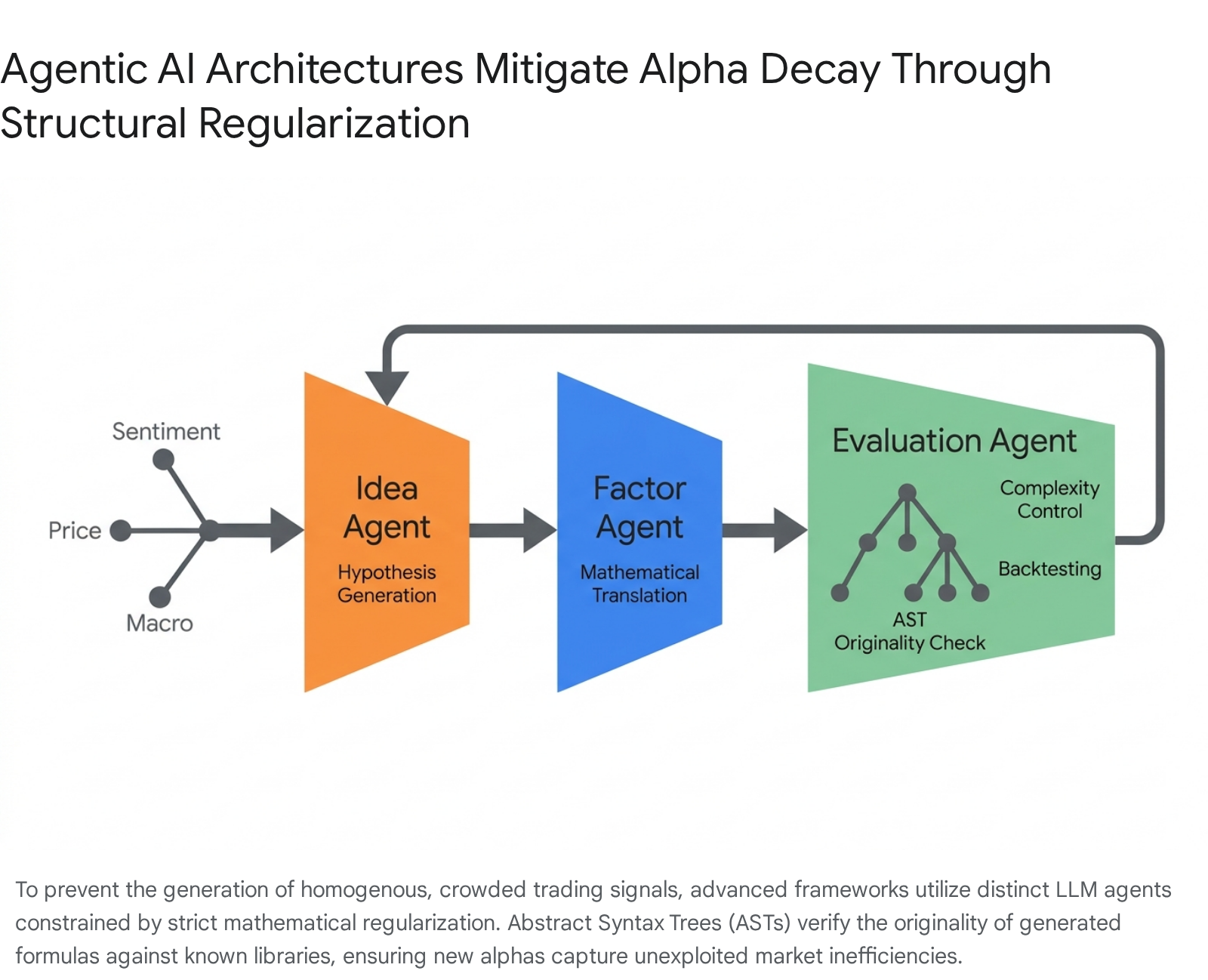
AlphaAgent mitigates decay through three specific mechanisms. First, it enforces originality via Abstract Syntax Tree (AST) isomorphism detection. This mechanism implements a pairwise subtree detection protocol that compares newly generated factors against existing libraries (such as Alpha101) to ensure the formulas are mathematically unique. Second, it enforces hypothesis-factor alignment by utilizing an LLM evaluator to check if the generated mathematical expression semantically matches the underlying market theory. Finally, it implements complexity control by capping the structural depth of the syntax trees, preventing the LLM from generating overly complex parameters that overfit historical data 1516. Evaluated over a four-year period, these bounded, machine-generated alphas exhibited remarkable resistance to decay across both bull and bear market regimes, maintaining predictive effectiveness far longer than unconstrained approaches 1532.
Conclusion
The application of Large Language Models to extract sentiment from financial disclosures represents a paradigm shift in quantitative analysis. Moving beyond the rigid limitations of dictionary-based lexicons, advanced autoregressive models successfully navigate the linguistic complexity, legal boilerplate, and strategic ambiguity inherent in lengthy 10-K filings and dynamic earnings call transcripts.
The empirical evidence confirms that LLM-derived sentiment provides a potent source of alpha. Strategies that integrate context-aware textual extraction with traditional numerical indicators - and dynamically adjust for macroeconomic volatility regimes - consistently generate superior risk-adjusted returns compared to passive benchmarks and legacy NLP techniques. The ability of generative models to parse specific emotional states, such as analyst anxiety during M&A calls, uncovers leading indicators of fundamental value destruction that traditional price data fails to reflect in real time.
However, the deployment of LLMs at scale is fraught with systemic challenges. Look-ahead bias resulting from training data overlap fundamentally threatens the integrity of historical backtesting, requiring meticulous bitemporal data infrastructure to resolve. The sensitivity of these models to prompt formatting and latent emotional framing necessitates strict engineering to prevent the injection of artificial bias into the resulting portfolio weights. Furthermore, the inherent pattern-recognition capabilities of generative models accelerate alpha decay and factor crowding unless explicitly constrained by mathematical regularization.
Ultimately, the future of AI-driven quantitative finance relies on highly constrained hybrid architectures. The most successful institutional implementations do not deploy LLMs as standalone trading oracles; rather, they embed them within deterministic, multi-agent frameworks where human intuition defines the risk parameters, the language model interprets the unstructured complexity of global disclosures, and rigorous statistical models govern final execution.