Can You Use ChatGPT for Swing Trading
Large language models like ChatGPT offer swing traders a massive edge in processing news sentiment, summarizing earnings calls, and writing code for technical indicators, effectively democratizing research once reserved for institutional algorithms. However, because these systems are probabilistic text generators rather than deterministic calculators, they cannot execute reliable mathematical risk management and will fail catastrophically if trusted with autonomous trade execution.
The Democratization of Financial Intelligence
For decades, the financial markets operated on a strict, capital-intensive hierarchy of information access. Institutional investors, hedge funds, and major banks spent millions of dollars annually to access real-time data terminals, proprietary news feeds, and advanced natural language processing algorithms 12. A Bloomberg Terminal, the industry standard for real-time financial data, has seen its pricing compound from roughly $20,000 per year in 2010 to an estimated $31,980 per year by 2026 - a 60% cumulative increase that places it far beyond the reach of the average retail investor 2. Institutional algorithms could instantly read thousands of pages of corporate filings and news headlines, gauge the sentiment, and execute trades before a retail investor could even open a brokerage application.
The widespread release of ChatGPT in November 2022 triggered a structural shift in this dynamic. For the first time, individual retail traders gained free or low-cost access to institutional-grade text analysis tools 12. Rather than relying on delayed news summaries or emotional social media forums, retail swing traders began using generative artificial intelligence to ingest complex market data. This technological shift effectively began shrinking the historical information gap between Wall Street and Main Street, replacing million-dollar hedge fund infrastructure with $20-per-month consumer AI subscriptions 224.
The impact of this technology on actual market behavior is already measurable in the data. Researchers from Washington University in St. Louis analyzed retail trading patterns before and after the deployment of ChatGPT. They discovered that retail traders' market positioning began to closely resemble the sophisticated, sentiment-driven trades of institutional algorithms almost immediately after the model's release 25. This alignment was particularly evident around quarterly earnings calls, where investors must rapidly digest transcripts that can run up to 7,000 words of complex corporate commentary 2.
To prove that ChatGPT was the actual driver of this behavioral shift - rather than coincidental macroeconomic conditions - researchers examined periods when OpenAI's application programming interfaces (APIs) and servers went down. During these officially reported ChatGPT outages, the alignment between retail trading patterns and AI-driven market sentiment immediately fell away, and overall retail trading volume saw a significant, measurable decline 234. This natural experiment demonstrated empirically that retail investors were actively relying on large language models to process information and inform their swing trades.
The Shift from Meme Stocks to Systematic Analysis
The modern retail trader's search for an informational edge is not entirely new, but the methodology has matured rapidly. During the GameStop short squeeze of early 2021, retail traders demonstrated that qualitative sentiment signals from non-institutional sources - such as the Reddit forum r/WallStreetBets - carried real predictive and market-moving power 25. While institutional traders were reading fundamentals and short interest data on their terminals, retail traders were aggregating social momentum 2.
However, trading on raw forum sentiment was highly volatile and emotionally driven, leading to significant losses for many late adopters. The introduction of large language models allowed retail traders to transition from emotional, crowd-following behavior to systematic, data-driven processes 1. A swing trader can now pipe a live web search or a stream of X (formerly Twitter) posts through an AI API, instructing the model to synthesize the noise and extract nuanced real-time sentiment 29. By pairing AI-driven news analysis with traditional swing trading indicators, individual investors are constructing pipelines that mimic the systematic approaches of quantitative hedge funds.
| Market Era | Primary Retail Information Source | Institutional Edge | Retail Trading Behavior |
|---|---|---|---|
| Pre-2020 | Delayed public news, basic broker charts | High-speed algorithmic NLP, Bloomberg Terminals | Discretionary, often lagging institutional moves. |
| 2020-2021 | Reddit, social media forums (meme stock era) | Alternative data, advanced order routing | Highly emotional, crowd-driven, highly volatile. |
| Post-2022 | ChatGPT, Gemini, Claude (Generative AI) | Ultra-low latency execution, proprietary data | Systematic, sentiment-driven, aligning with AI models. |
Using LLMs for Sentiment Analysis and Research
Swing trading fundamentally relies on capturing short-to-medium-term price momentum, which is heavily influenced by market sentiment, macroeconomic data releases, and corporate news. It is in this qualitative, text-heavy arena that large language models prove immensely valuable.
Moving Beyond Legacy Dictionary Models
Historically, quantitative sentiment analysis relied on tools like the Loughran-McDonald dictionary, a widely used academic and industry framework that scanned financial texts for specific positive or negative keywords 611. This approach was notoriously rigid; it could not understand sarcasm, double negatives, or the broader context of a sentence. A phrase like "the company's debt did not increase" might trigger a negative flag simply because the word "debt" was present. Large language models, built on transformer architectures with self-attention mechanisms, understand contextual nuance and compositional sentiment 7.
In a landmark study analyzing 965,375 U.S. financial news articles spanning from January 2010 to June 2023, researchers found that advanced language models vastly outperformed legacy systems. While the traditional Loughran-McDonald dictionary model achieved only 50.1% accuracy in sentiment prediction (essentially a coin flip), transformer-based models achieved between 72% and 74.4% accuracy 11. Specifically, the GPT-3-based OPT model hit 74.4%, slightly edging out BERT at 72.5% and FinBERT at 72.2% 211.
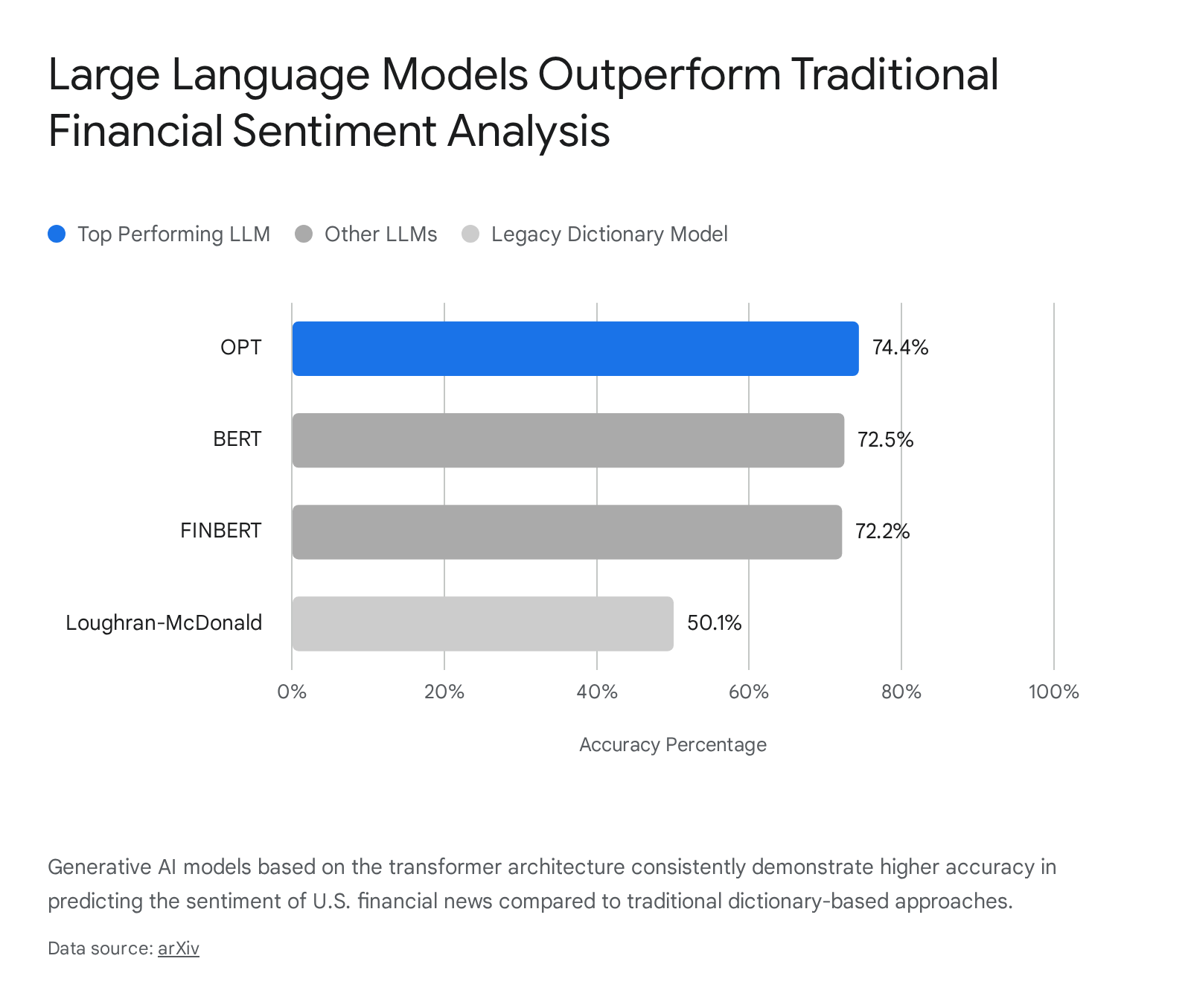
By using a large language model to read a daily barrage of news headlines, swing traders can generate a highly accurate, real-time temperature check of a stock's narrative momentum 2.
Unstructured Text and Predictive Forecasting
Beyond merely classifying sentiment as positive or negative, large language models have demonstrated a surprising capacity for predicting future price drifts based purely on textual data. An academic study conducted by researchers at the University of Florida tested ChatGPT-4's ability to predict daily stock market returns by feeding it over 67,000 post-training-cutoff news headlines 413. The methodology ensured the model had no prior knowledge of the events.
The researchers found that GPT-4 could accurately capture the market's initial reaction to news with an approximate 90% hit rate for non-tradable overnight news 13. More importantly for swing traders, the model's sentiment scores exhibited statistically significant predictive power for subsequent multi-day price drifts. The predictability was notably stronger for smaller-cap stocks reacting to negative news 713. A long-short trading strategy backtested using GPT-4's evaluations delivered an annualized Sharpe ratio of 3.8 over the sample period, vastly outperforming basic market portfolios 7.
Interestingly, the study revealed that financial forecasting is an "emerging capacity" tied directly to model size and complexity. Basic models like GPT-1 and BERT failed to accurately forecast returns, while advanced models like GPT-4 excelled 713. Using novel interpretability techniques, the researchers found that GPT-4's predictions were highly accurate when its reasoning focused on concrete fundamentals mentioned in the text, such as insider stock purchases, earnings guidance, dividends, and market share 7. However, it faltered when its logic relied on vague partnerships or new developments 7.
A separate study by the University of Chicago further validated this analytical prowess. Researchers provided GPT-4 with anonymized corporate financial statements - stripped of names and industry identifiers - and asked it to predict future earnings changes. The model achieved a 60% accuracy rate using a chain-of-thought prompt, noticeably higher than the low-50% accuracy rate achieved by professional human analysts looking at the same data 8. The model's ability to recognize financial patterns and business concepts with incomplete information suggests it can extract meaningful alpha from documents that overwhelm human readers.
Processing 24/7 Crypto and Forex Markets
The utility of large language models extends well beyond traditional equities. In the cryptocurrency and foreign exchange (forex) markets, which operate 24 hours a day, the information flow is relentless 15. News breaks continuously, geopolitical events shift currency values in the middle of the night, and influencer sentiment drives massive volatility in digital assets 159.
For the average swing trader, monitoring this chaotic environment is physically impossible. This is where AI acts as a relentless research co-pilot. Traders are using models to continuously scan whitepapers, tokenomics documents, and smart contract summaries, translating complex blockchain jargon into simple risk assessments 1517. In forex, an LLM can parse central bank transcripts - such as the massive documents released by the Federal Open Market Committee (FOMC) - to detect subtle shifts in hawkish or dovish language that precede interest rate adjustments 18. By cross-referencing AI summaries of institutional news with sentiment analysis of social media platforms like X, traders can identify discrepancies that often signal impending volatility 15.
Prompt Engineering and Workflow Automation
While predictive forecasting represents the frontier of AI trading research, the most immediate and practical use case for swing traders lies in workflow automation. Modern traders use large language models to bridge the gap between trading ideas and execution infrastructure.
Writing Code for Technical Indicators
Most swing traders rely on technical analysis - the study of price charts and trading volume - to identify entry and exit points. Traditionally, turning a conceptual trading strategy into a visual chart indicator or an automated alert required proficiency in programming languages like Python or TradingView's Pine Script. Today, large language models have democratized financial coding 1910.
A trader can provide an AI with a plain-English prompt describing a specific technical setup. For example, a user might prompt the model to "Write a Pine Script indicator that plots a buy signal when the 50-day moving average crosses above the 200-day moving average, but only if the 14-period Relative Strength Index (RSI) is below 30." The language model will generate the necessary code in seconds 421.
Traders also use AI to write data extraction scripts. If a trader wants to pull historical pricing data from the Yahoo Finance API, merge it with an alternative dataset, and calculate the moving average convergence divergence (MACD) crossover, an LLM can provide the exact pandas dataframe operations required in Python 2223. This rapid prototyping allows traders to test hundreds of mechanical rule variations in the time it previously took to manually code one 10.
Structuring Trade Ideation
Beyond writing code, traders use language models as sounding boards to refine their discretionary strategies. A trader might upload an image of a chart and ask the AI to identify potential support and resistance zones, or to point out historical chart patterns like head-and-shoulders formations or double bottoms 417. While the base versions of these tools cannot access live data feeds without specific plugins, they are highly capable of explaining complex concepts like options Greeks, portfolio convexity, and macroeconomic relationships 423.
However, experts strongly advise treating the AI as a tool for validation rather than an oracle. A trader should ask the AI to poke holes in a strategy or highlight potential macroeconomic risks they may have overlooked, but the final decision to risk capital must remain firmly with the human operator 1024.
| Application Area | How LLMs Provide an Edge | Key Limitation |
|---|---|---|
| Indicator Coding | Translates plain English into Pine Script/Python instantly. | Code often requires manual debugging; logic may be flawed. |
| Earnings Analysis | Summarizes 7,000-word transcripts into bullet points in seconds. | Can occasionally hallucinate a metric if the transcript is ambiguous. |
| Market Ideation | Explains complex options strategies and macro concepts. | Lacks real-time market awareness without expensive API integrations. |
| Chart Pattern Recognition | Can process image uploads to identify historical technical setups. | Vision models can misinterpret scale, axes, or candlestick wicks. |
The "Stochastic Parrot" Problem in Financial Mathematics
Despite their profound capabilities in language processing, coding, and sentiment extraction, large language models possess a critical architectural flaw that makes them highly dangerous for quantitative swing trading: they cannot perform mathematics reliably.
Why Large Language Models Fail at Math
To understand why an AI that can write complex Python code struggles to execute basic arithmetic, one must understand how a transformer model functions. Models like ChatGPT are not deterministic calculators; they are probabilistic text generators. Coined by researcher Emily Bender, the term "stochastic parrot" illustrates that while these models generate language that sounds convincingly human and authoritative, they do not fundamentally understand the logical meaning of the symbols they are outputting 25.
When an LLM is asked a question, it does not execute a rigid set of mathematical rules to arrive at an answer. Instead, it predicts the most statistically likely sequence of "tokens" (word fragments) to follow the prompt, based on the vast corpus of text it ingested during training 251112. Language is inherently statistical - if a sentence begins with "The batter hit the ball out of the," the statistically probable next word is "park." Arithmetic, however, is strictly rule-based. There is no statistical leeway in the calculation "62.3 * 73.98." Mathematics rewards exactness, not plausibility 2511.
The technical root of this problem lies in tokenization. Because an LLM represents text as discrete tokens optimized for language frequency rather than numeric structure, continuous real values are discretized 12. This token-level representation introduces unavoidable quantization errors. When an LLM generates a multi-digit number, it does so one token at a time autoregressively. If the model mis-predicts a single decimal place or digit early in the generation process, every subsequent token it predicts conditions itself on that flawed premise, leading to massive error compounding 1112.
Even simple facts, like $1 + 1 = 2$, are often retrieved as memorized text patterns rather than executed as general algorithms. As soon as a trader introduces larger numbers, unfamiliar formats, or intricate position sizing formulas, the AI's apparent mathematical certainty evaporates 2511.
The Danger to Position Sizing and Risk Management
For a swing trader, mathematical precision is quite literally a matter of survival. The difference between risking 1% of a portfolio and 10% of a portfolio on a single trade dictates whether an account can survive a normal string of drawdowns 1329.
If a trader relies on ChatGPT to calculate their position size based on a specific stop-loss distance and account equity, the AI may confidently produce an answer that contains a rounding error, confuses percentages with decimals, or simply hallucinates a completely incorrect figure 4. A Stanford University study showed that while GPT-4 can hit 90% accuracy on basic math tasks, a 10% failure rate in financial calculations means one in ten transactions could be fundamentally compromised 30. In financial systems, 90% accuracy is unacceptable; markets do not accept "close enough" 30.
These errors are not theoretical. In a test evaluating LLMs for financial advice, researchers posed a simple math problem to four prominent models (GPT-4o, DeepSeek, Grok, and Gemini): calculate the implied annual percentage rate (APR) of a rent-to-own TV purchase. All four models completely failed the financial analysis, generating mathematically incorrect steps, ignoring the time value of money, and providing vastly different, incorrect APRs while maintaining an authoritative tone 31. Grok even generated basic arithmetic failures like adding rent and utilities incorrectly, while DeepSeek botched a simple division formula 31.
When the financial education site DayTrading.com tested AI models in live market conditions, the results were equally alarming. When asked to calculate moving averages for gold prices, Meta AI miscalculated the math entirely and claimed a "strong uptrend" despite the price being measurably lower over the period 32. When asked for specific forex trade ideas, an AI model named Groq suggested an aggressive long position with zero stop-loss, ignoring major resistance levels and advising dangerously reckless risk parameters 32.
In trading, risking capital based on AI-generated arithmetic without human verification is a catastrophic vulnerability. While an AI can suggest the concept of a trailing stop-loss, it should never be trusted to calculate the exact dollar values or share quantities required for execution 430.
The Backtesting Illusion and Market Regimes
When retail traders discover the coding capabilities of LLMs, the immediate impulse is to ask the AI for a trading strategy and backtest it to prove its profitability. The internet is replete with viral stories claiming that ChatGPT-generated strategies returned 350% to 500% in a historical backtest 24. However, rigorous institutional research reveals severe methodological flaws in how these AI strategies are evaluated by amateurs.
Look-Ahead Bias and Data Leakage
The most pervasive and dangerous issue in testing AI trading strategies is "look-ahead bias," also known as data leakage 1415. Because models like GPT-4 are trained on the entirety of the open internet up to a specific cutoff date (e.g., December 2023), they inherently possess "future knowledge" about the time periods they are often tested against.
If a trader asks an LLM to generate a trading strategy and simulate it on data from 2021 to 2023, the model already implicitly "knows" that tech stocks rallied, that inflation spiked, or that a specific geopolitical event occurred during that window. Even if the user attempts to hide the exact dates in the prompt, the macroeconomic context is baked into the model's weights. Consequently, the AI will build a strategy perfectly optimized for events that have already occurred, resulting in spectacular - and entirely fictional - historical returns that will immediately fail when applied to live, out-of-sample markets 141535. True backtesting of an LLM requires complex "time-capsule data" where researchers ensure the AI has absolutely no training exposure to the events it is predicting, a feat difficult for the average retail trader to orchestrate 14.
The FINSABER Framework and Long-Term Deterioration
When academic researchers apply strict, bias-free methodologies to eliminate data leakage, the results are far less glamorous. A comprehensive backtesting framework called FINSABER was recently developed to evaluate LLM timing-based investing strategies across two decades and over 100 stock symbols, explicitly accounting for survivorship bias by including delisted stocks 3536.
The researchers found that the purported massive advantages of LLM strategies deteriorate significantly when tested over long horizons and broad market cross-sections 3537. The study revealed a critical flaw in how LLMs handle changing market regimes. During sustained bull markets, the AI strategies tended to be overly conservative, ultimately underperforming simple passive benchmark indices. Conversely, during bear markets, the models proved overly aggressive, exhibiting inadequate risk control and incurring heavy, disproportionate portfolio losses 3536.
This regime failure underscores a fundamental truth about generative AI: large language models lack a persistent reasoning state. Unlike a human trader who learns that market conditions have shifted from low-volatility to high-volatility, an LLM starts from zero with every single query 38. It has no memory of what was established in the last analysis, no graph of how current assumptions connect to past trades, and no inherent mechanism to know when a new macroeconomic data point invalidates a prior conclusion 38. For a quantitative swing trading workflow, this lack of persistent state is a structural failure, not a prompt engineering issue.
Multi-Agent Systems: A Safer Path Forward
To bypass the limitations of single-prompt AI interactions and mathematical hallucinations, quantitative researchers and advanced retail traders are moving away from treating ChatGPT as a singular oracle. Instead, they are developing "multi-agent" frameworks. Rather than asking a single LLM to analyze the market, pick a stock, calculate risk, and execute a trade all at once, these systems break the trading process down into distinct, isolated roles managed by specialized agents interacting with one another 391641.
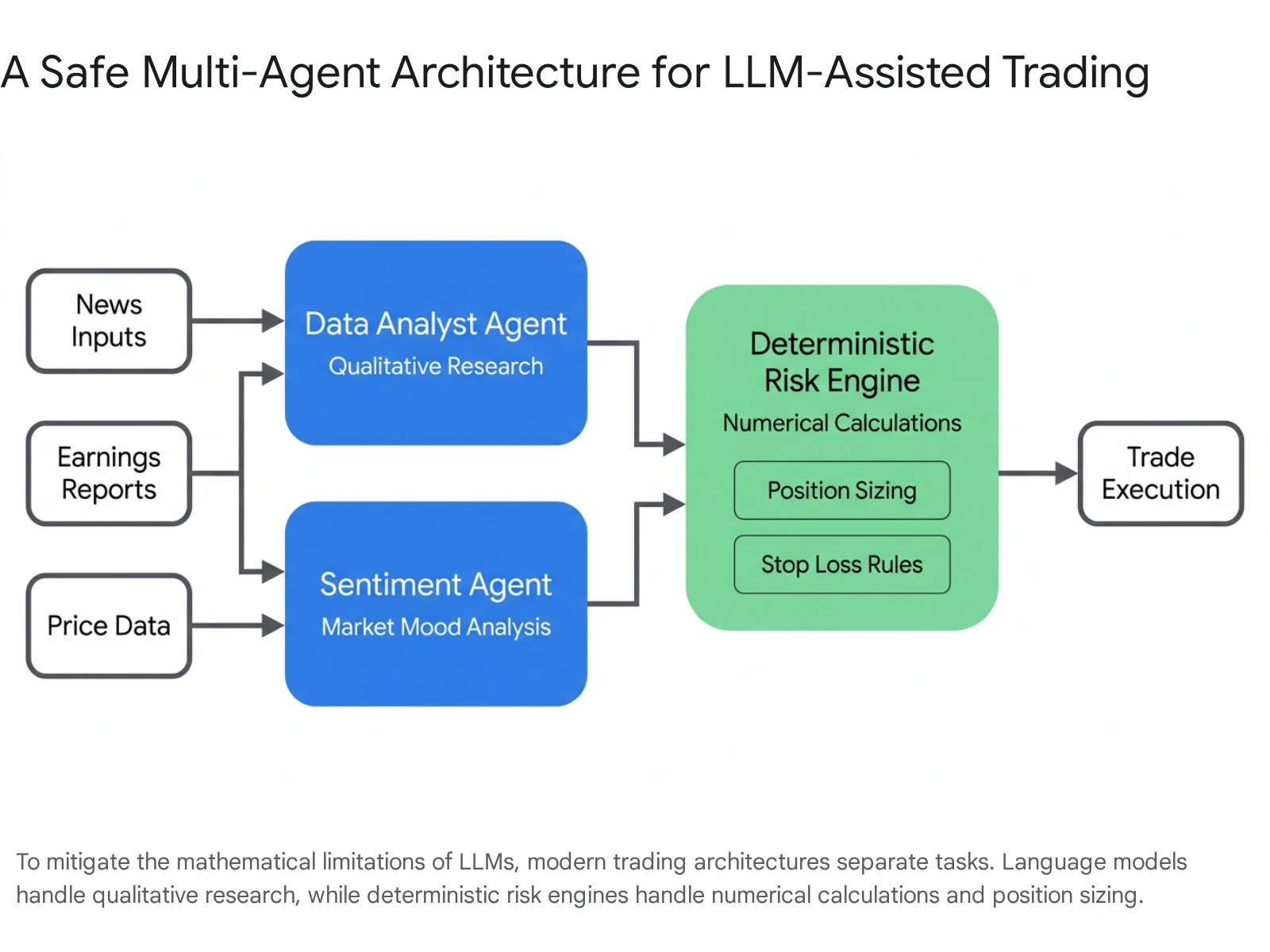
Separating Language from Logic
In a properly designed multi-agent architecture, the workload is distributed to exploit the strengths of AI while insulating the system from its weaknesses: * The Data Scientist Agent: This agent does not trade; it solely writes code to pull historical pricing APIs, clean data, and format it into readable tables 1641. * The Analyst Agent: This agent ingests news sentiment, parses social media trends, and evaluates macroeconomic variables to establish a directional market bias 1641. * The Risk Manager Engine: Crucially, this layer is not a language model. Instead of relying on an AI to do arithmetic, the system passes the Analyst's bias to a traditional, deterministic Python script. The hard-coded calculator engine computes the exact position sizing, value at risk (VaR), and stop-loss placement, preventing tokenization math errors from ever reaching the broker 112916.
Factual vs. Subjective Reasoning
Advanced frameworks, such as the FS-ReasoningAgent designed for cryptocurrency markets, further refine this process by isolating different types of AI logic. Researchers noticed a counterintuitive phenomenon: sometimes, highly advanced models like GPT-4 underperformed weaker models in live trading scenarios 39. They discovered that stronger LLMs have an inherent bias toward strictly factual information and tend to ignore subjective emotional data. However, markets - especially crypto and meme stocks - are often driven entirely by irrational human psychology rather than intrinsic value 39.
To solve this, the FS-ReasoningAgent separates "factual reasoning" (analyzing hard economic data like transaction volume and gas fees) from "subjective reasoning" (interpreting emotional news sentiment and social hype) 39. The system then dynamically weights these inputs. Extensive experiments showed that relying heavily on subjective news generated much higher returns during exuberant bull markets, while focusing strictly on factual, quantitative data provided superior protection and returns during bear markets 39. Implementing this fine-grained, multi-agent reasoning improved overall profits by 7% in Bitcoin trading and 10% in Solana trading compared to baseline AI models 39.
Regulatory Crackdowns, "AI Washing," and Compliance
As the hype surrounding AI trading tools reached a fever pitch, federal regulators moved swiftly to address the severe risks posed to retail investors and the integrity of the financial markets. The U.S. Securities and Exchange Commission (SEC) and the Financial Industry Regulatory Authority (FINRA) have both issued stringent warnings, alerts, and regulatory actions regarding the misuse of generative AI 171819.
The SEC's War on "AI Washing"
The primary regulatory concern is "AI washing" - a deceptive marketing practice where firms exaggerate, misrepresent, or entirely fabricate their use of artificial intelligence to lure in investor capital 1820. Much like "greenwashing" in the environmental sector, firms have realized that slapping the term "AI" on a standard algorithmic trading product instantly attracts retail money 21.
In March 2024, the SEC issued its first-ever enforcement actions regarding this practice, levying a combined $400,000 in civil penalties against two investment advisers 2223. The Toronto-based firm Delphia was fined $225,000 for falsely claiming to use AI and machine learning to analyze client data and predict market trends, when in reality, they possessed no such capabilities 2123. Similarly, San Francisco-based Global Predictions was fined $175,000 for falsely advertising itself as the "first regulated AI financial advisor" and offering "expert AI-driven forecasts" that were entirely fabricated 2123.
The crackdown continued into late 2024. In October, the SEC charged Rimar Capital and its officers, imposing a $250,000 penalty for defrauding investors with buzzwords and false claims about using artificial intelligence to perform automated trading 24. SEC Chair Gary Gensler has repeatedly warned that the opacity of algorithmic "black boxes" poses a systemic risk. He notes that investors who blindly trust AI-branded systems often suffer financial harm due to unverified logic, and that relying on standardized models across multiple firms could lead to a dangerous concentration of risk, sparking a future financial crisis 202551.
FINRA Guidelines and Supervisory Standards
For broker-dealers and institutional trading desks utilizing these tools, FINRA has made its stance unequivocally clear. In Regulatory Notice 24-09, issued in June 2024, FINRA emphasized that its rules are technologically neutral. This means that existing securities laws apply to large language models exactly as they apply to any other piece of technology 172627.
If a firm uses an LLM to generate an email to a client, that communication is fully subject to FINRA Rule 2210 (Communications with the Public), meaning it must be fair, balanced, and free of misleading claims 1726. If an AI hallucinates a false stock price or invents a non-existent corporate fundamental, the human operators and the deploying firm are held entirely responsible for the regulatory breach 2654. Furthermore, under FINRA Rule 3110 (Supervision), firms are required to implement strict technology governance, model risk management, and data privacy controls before letting any AI tool touch live market data or client information 2655.
For the retail swing trader, this regulatory consensus serves as a stark warning. The watchdogs governing the global financial system recognize that while AI holds immense promise for efficiency, it is fundamentally prone to errors, hallucinations, and bias 1556. Relying on it as a fully autonomous financial advisor or execution engine is both legally and financially hazardous 3255.
Bottom line
Large language models provide swing traders with an unprecedented ability to rapidly analyze market sentiment, summarize dense earnings transcripts, and generate technical trading scripts. They have effectively democratized a layer of research that was previously locked behind expensive institutional terminals. However, due to their probabilistic, token-based design, LLMs suffer from severe limitations in mathematical reasoning, making them wholly unreliable for calculating position sizes, executing hard risk management, or conducting valid historical backtests. Ultimately, artificial intelligence should be integrated into a multi-agent workflow where it serves as a high-speed research co-pilot, leaving the exact mathematics and final trade execution to deterministic engines and human judgment.