AI-powered personalized and adaptive learning systems
The paradigm of education is undergoing a fundamental transformation through the integration of artificial intelligence (AI) and machine learning (ML), moving away from monolithic, standardized instruction toward dynamic, individualized learning pathways. Adaptive learning systems operate by continuously ingesting real-time performance data - such as quiz scores, response times, interaction patterns, and engagement metrics - to model a student's latent knowledge state. These systems dynamically modulate the difficulty, format, and sequence of instructional content to optimize knowledge retention and mastery. This comprehensive analysis evaluates the technical architectures driving adaptive learning, the algorithmic methodologies used for knowledge tracing, the integration of generative AI, the ethical dimensions of algorithmic bias, and the global implementation challenges inherent in scaling these technologies across diverse educational infrastructure.
System Architectures and Algorithmic Paradigms
Adaptive educational technologies generally fall into two broad architectural paradigms: deterministic rule-based systems and stochastic, data-driven machine learning systems. Understanding the technical distinction between these architectures is critical for evaluating their respective deployment contexts, scalability, and efficiency. As the digital transformation of educational frameworks accelerates, stakeholders must select the architecture that aligns with their computational resources, data availability, and pedagogical objectives.
Rule-Based Branching Logic
Rule-based adaptive learning relies on predefined, static logic sets engineered by human subject-matter experts and instructional designers. In these systems, a learner's progression is determined by explicit if-then conditional decision trees 123. For example, a system might dictate that if a student scores below a 70% threshold on a diagnostic assessment regarding linear equations, they are automatically routed to foundational remedial modules before progressing to advanced calculus concepts. Simple applications of this logic include navigational branching and test-out assessments within standard Learning Management Systems (LMS) 1.
The primary advantage of rule-based systems is their immediate deployability and absolute transparency. Because the logic is hardcoded deterministically, these systems do not require vast repositories of historical data to function, operating reliably in low-data environments 13. Furthermore, their decision-making processes are fully auditable, meaning that educators can clearly trace exactly why a student received a specific intervention 3. This deterministic nature is highly beneficial in environments requiring strict regulatory compliance, basic data validation, or precision-oriented training where outcomes must be strictly controlled and guaranteed 24.
However, rule-based systems are inherently brittle. They operate strictly on fixed logic and cannot account for edge cases, ambiguity, or novel learner behaviors that fall outside the explicitly programmed rule set 23. As course complexity scales and the number of learning objectives multiplies, the combinatorial explosion of necessary rules renders system maintenance excessively costly and mathematically unwieldy. The manual updating required to keep the logic relevant ultimately limits the system's ability to provide truly nuanced personalization for diverse student populations 235.
Machine Learning and Data-Driven Adaptation
In contrast to fixed logic, machine learning-based adaptive systems learn continuously from large datasets without requiring explicit human instruction for every possible scenario 26. These systems utilize predictive analytics, anomaly detection, and pattern recognition to optimize instructional sequences dynamically 36. Rather than following static paths, ML architectures model complex, non-linear relationships between multiple variables. For instance, an algorithm might discover hidden correlations between a student's time spent reviewing external integration pages, their sequence of correct answers, and their ultimate likelihood of retaining the information 2.
Machine learning models evaluate historical learner data to generate probability distributions for future performance. As the system processes more data during its operational lifecycle, its capability to predict optimal pedagogical interventions continuously improves, allowing the system to support dynamic environments where conditions and learner behaviors fluctuate unpredictably 26.
Despite their sophistication, the efficacy of ML systems is entirely contingent upon data quality and volume. In the absence of sufficient, high-quality historical data, ML systems suffer from the "cold start" problem and may generate unreliable or entirely spurious learning pathways 37. Furthermore, ML systems require advanced technical infrastructure and specialized data science teams for continuous monitoring, bias evaluation, and model retraining, resulting in significantly higher initial capital expenditures and maintenance overhead compared to rule-based alternatives 136.
Hybrid Architectural Approaches
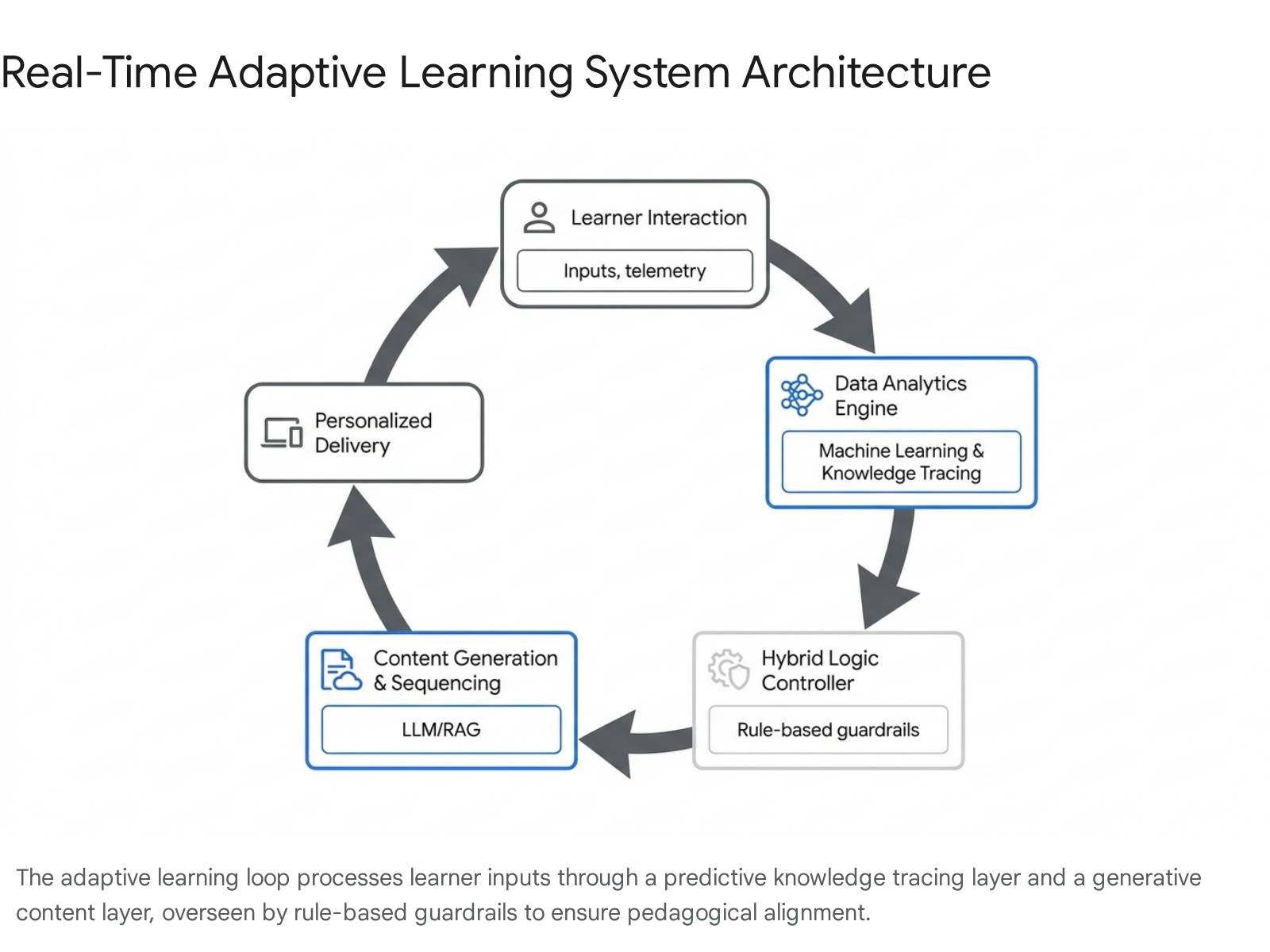
Because neither approach is universally superior across all contexts, modern enterprise-grade adaptive learning environments increasingly rely on hybrid architectures. Organizations are recognizing that ML handles prediction and pattern recognition efficiently, while rules enforce necessary guardrails, compliance, and academic business logic 24. In these configurations, machine learning algorithms handle complex pattern recognition, performance prediction, and dynamic content sequencing, while a deterministic rule-based layer guarantees that safety guidelines, curriculum standards, and accreditation requirements are met without deviation 24.
| Architectural Paradigm | Core Mechanism | Primary Advantages | Critical Limitations | Optimal Deployment Context |
|---|---|---|---|---|
| Rule-Based Systems | Deterministic if/then logic trees encoded by human experts. | Highly transparent, easily auditable, functions with zero historical data, low initial cost 123. | Brittle, unable to handle novel scenarios, scales poorly due to complex maintenance 23. | Regulatory compliance, strict precision-oriented tasks, low-budget deployments 24. |
| Machine Learning Systems | Stochastic pattern recognition trained on historical datasets. | Adapts continuously, predicts outcomes, handles complex and ambiguous learner behavior 26. | Data dependency, "black box" interpretability issues, high technical overhead, risk of bias 36. | Predictive analytics, large-scale dynamic environments, multi-variable personalization 46. |
| Hybrid Systems | ML for prediction wrapped in rule-based compliance guardrails. | Balances predictive adaptability with strict pedagogical reliability and safety constraints 24. | Complex architectural integration, requires dual maintenance of rules and data pipelines 4. | Modern enterprise and higher education adaptive learning platforms 24. |
Algorithmic Mechanisms for Knowledge Tracing
At the computational core of any sophisticated adaptive learning system is a Knowledge Tracing (KT) model. Knowledge tracing refers to the task of modeling and inferring a student's latent cognitive state based on their sequence of observable interactions, such as correct or incorrect responses to exercises, time spent on task, and hint usage 8910. By maintaining a continuously updated probabilistic model of what a student knows, the system can tailor subsequent instructional interventions to maximize learning efficiency.
Bayesian Knowledge Tracing (BKT)
Bayesian Knowledge Tracing (BKT) has served as the foundational modeling framework in educational data mining since its development in the 1990s. BKT fundamentally characterizes human learning as a partially observable Markov process. It tracks binary knowledge states - indicating whether a student has "mastered" or "not mastered" a specific predefined skill - and updates these probabilities mathematically as the student answers questions 81112.
The classical BKT model relies on a Hidden Markov Model (HMM) defined by four core parameters estimated per skill: 1. Prior Knowledge ($p(L_0)$): The initial probability that a student has already mastered the skill before engaging with the instructional intervention. 2. Learning Rate ($p(T)$): The transition probability that a student will move from the unlearned to the learned state after a single practice opportunity. 3. Guess Rate ($p(G)$): The probability that a student answers an item correctly despite not having mastered the underlying skill. 4. Slip Rate ($p(S)$): The probability that a student answers incorrectly despite having mastered the skill, due to fatigue, distraction, or simple mechanical error 111313.
BKT's primary advantage is its mathematical transparency and high interpretability. The separation of genuine latent knowledge from performance noise (guesses and slips) allows educators to understand precisely why a system classifies a student in a certain way 1214. Furthermore, BKT converges effectively with traditional psychometric assessments. For instance, the slip and guess rates in BKT directly map to the lower and upper asymptotes in the 4-parameter logistic Item Response Theory (IRT) model, blurring the lines between continuous assessment and learning processes 11.
Despite its interpretability, classical BKT operates under rigid assumptions: it generally treats individual skills as independent entities, struggling to map complex hierarchies where multiple skills overlap within a single problem 915. To address issues with continuous observation during long tasks, researchers have introduced Time-Dependent Bayesian Knowledge Tracing (TD-BKT), which updates the user's skill estimate continuously during task completion rather than waiting for an unambiguous final answer, significantly reducing the Kullback-Leibler Divergence (KLD) of the estimated skill state 13.
Deep Knowledge Tracing (DKT)
To overcome the limitations of explicitly modeling isolated skills, researchers introduced Deep Knowledge Tracing (DKT). DKT utilizes deep learning architectures, specifically Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, to predict student performance 89. Unlike BKT, which requires human experts to manually define the mapping between questions and specific skills (often via a Q-matrix), DKT automatically learns dense vector representations from raw sequences of student interactions 1416.
LSTMs are adept at handling educational data because they mitigate the vanishing gradient problem common in standard RNNs, allowing the model to capture long-term temporal dependencies in a student's learning history 16. Consequently, the system can remember a concept a student struggled with weeks ago and seamlessly factor it into a current prediction. DKT excels at capturing inter-skill similarities without requiring explicit domain modeling. If two skills are highly similar, the hidden-to-hidden connections in the network encode this overlap naturally .
However, DKT is highly vulnerable to the "black box" problem. The massive neural network relies on tens of thousands of parameters, resulting in a latent high-dimensional state that is nearly impossible to interpret pedagogically 914. While a DKT model might accurately predict that a student has an 83% chance of failing the next algebra sequence, it cannot easily articulate which specific sub-skill the student lacks 15. Furthermore, while DKT performs well generally, specific studies in computing education reveal that DKT models significantly struggle to distinguish individual knowledge components (KCs) when students make mistakes on multi-skill problems - precisely the scenario where accurate tracing is most needed for targeted remediation 15.
Dynamic Memory Networks and Comparative Efficacy
The tension between the interpretability of BKT and the predictive power of DKT has driven the development of advanced frameworks such as Dynamic Key-Value Memory Networks (DKVMN). DKVMN models separate the underlying concept structures from individual student mastery states. By utilizing a static key matrix to store knowledge concepts and a dynamic value matrix to update the student's mastery level, DKVMN achieves high predictive accuracy while attempting to pinpoint specific skill deficits 710.
| Knowledge Tracing Model | Algorithmic Architecture | Core Operational Mechanism | Interpretability | Pedagogical Limitations |
|---|---|---|---|---|
| BKT (Bayesian Knowledge Tracing) | Hidden Markov Model (HMM) | Updates binary latent mastery states using estimated guess, slip, learning, and prior probabilities 1113. | Very High | Assumes skill independence; struggles with overlapping multi-skill tasks without extensive manual mapping 915. |
| IRT (Item Response Theory) | Logistic Regression Models | Estimates student cognitive ability and item difficulty simultaneously across a continuous scale 811. | High | Highly static; generally utilized for summative assessment rather than continuous, real-time learning modeling 811. |
| DKT (Deep Knowledge Tracing) | Recurrent Neural Networks (LSTM) | Maps raw interaction sequences to output probabilities using non-linear hidden memory states 914. | Very Low | Severe "black box" opacity; cannot effectively isolate specific knowledge component failures during errors 915. |
| DKVMN (Dynamic Key-Value Memory Networks) | Memory-Augmented Neural Networks | Utilizes a static key matrix for concepts and a dynamic value matrix for tracking student mastery 710. | Moderate | Computationally intensive; requires vast datasets to tune the memory matrices effectively prior to deployment 710. |
Recent empirical studies evaluating the "cold start" problem - the phase when a system has minimal data on a new student - indicate that deep models like DKVMN outperform classical algorithms like BKT and Performance Factors Analysis (PFA) primarily during a student's first few attempts at a novel skill 7. However, the data reveals that by the time a student reaches their third or fourth interaction with a concept, the performance gap between classic BKT and modern deep learning models narrows significantly. This suggests that while deep models offer early predictive advantages, simpler, more interpretable models may perform adequately for sustained mastery learning applications, provided they incorporate temporal or contextual extensions 717.
Generative Artificial Intelligence and Large Language Models
While knowledge tracing algorithms determine the optimal sequence of concepts a student needs to master, Generative Artificial Intelligence (GenAI) - driven by Large Language Models (LLMs) - has fundamentally altered how that content is synthesized and delivered. The integration of advanced transformer-based models (e.g., GPT-4, Claude, Gemini) marks a shift in adaptive systems from merely sequencing pre-existing static assets to generating novel, context-aware content in real time 181920.
Dynamic Content Generation and Hyper-Customization
Traditional adaptive learning environments were strictly limited by the finite volume of content available in their proprietary databases. If a student failed to grasp a concept after reading the three available explanations, the system had no further pedagogical recourse 5. GenAI bypasses this limitation by dynamically synthesizing customized explanations, alternative analogies, and targeted practice questions on demand, thereby facilitating "hyper-customized" learning pathways 18.
For example, if an AI tutor detects through profiling that a learner studying physics is highly engaged by automotive engineering, the LLM can instantly rewrite a standard kinematics problem to feature transmission gear ratios rather than generic falling objects. Studies demonstrate that aligning instructional content with student interests using LLMs significantly increases short-term engagement and long-term knowledge retention compared to standardized materials 5. Furthermore, GenAI systems can function as sophisticated "pedagogical agents" - intelligent conversational interfaces that mimic human tutoring by employing Socratic questioning, executing complex natural language processing, and providing emotional or motivational scaffolding 52122.
Retrieval-Augmented Generation (RAG) in Academic Contexts
Despite their linguistic fluency, LLMs are prone to "hallucinations" - generating confident but factually incorrect information. In an educational setting, factual inaccuracy is highly detrimental. To mitigate this, developers integrate Retrieval-Augmented Generation (RAG) frameworks. In an educational RAG system, the LLM is anchored to a curated Knowledge Graph (KG) containing verified curriculum materials, approved textbook data, and strict academic standards 232427.
When a student poses a question, the system first retrieves the precise, verified pedagogical data from the internal database, and then instructs the LLM to use exclusively that specific data to format a natural, conversational response 24. This hybrid approach effectively merges the conversational agility of generative AI with the deterministic accuracy required in rigorous academic environments, mitigating the risks of factual inaccuracy while ensuring strict pedagogical alignment 524.
Real-Time Performance Data and Automated Feedback Loops
The efficacy of AI-powered personalized learning hinges on the latency and quality of the feedback loop. Effective systems utilize architectures wherein data collection, cognitive processing, and adaptive personalization operate as a continuous, interconnected cycle 527.
Automated Multimodal Feedback Mechanisms
Historically, automated feedback was restricted to simple validations ("correct/incorrect") or generic, static text hints that failed to address the specific misconception of the learner 25. The introduction of LLMs enables rich, multimodal, real-time feedback that adapts precisely to the student's current error state 2627.
In higher education programming courses, for instance, researchers evaluated an LLM-based copilot designed to intercept run-time execution errors in MATLAB. Instead of outputting cryptic console error codes, the AI instantly analyzed the student's specific codebase, provided a plain-language explanation of the logical flaw, and generated a localized, corrected code snippet 28. The empirical results of this real-time feedback integration were substantial. In a controlled study of 60 students, the treatment group scored higher on post-tests (16.8 vs. 13.5) and showed a much larger overall learning gain (0.58 vs. 0.29) than the control group. Furthermore, the total time students spent attempting to repair broken code dropped precipitously from 1,500 seconds to 450 seconds. The number of retries fell from two to one per error, and successful error resolution rose from 80% to 96% 28. This data demonstrates how real-time, context-aware feedback minimizes cognitive friction and accelerates the acquisition of technical skills.
Human-in-the-Loop Pedagogy and Collaborative Intervention
Despite the profound automation capabilities of AI, optimal educational outcomes are achieved when the technology augments rather than replaces the human educator. The Human-in-the-Loop (HITL) approach leverages generative AI to enhance personalized learning by directly integrating student and teacher feedback into AI-generated solutions 27. Adaptive systems process massive amounts of telemetry data to generate early-warning indicators for instructors. By clustering students based on interaction patterns - such as identifying a cohort of "fast learners" versus students exhibiting "wheel-spinning" behaviors - the system allows teachers to stage highly targeted, differentiated human interventions 3229. Instructors can utilize the AI to draft targeted lesson plans based on actual misconceptions detected in the platform, maintaining professional agency while delegating repetitive administrative monitoring to the machine 30.
Algorithmic Bias and Ethical Limitations
The rapid scaling of AI in education introduces profound ethical challenges. Because predictive algorithms and large language models are trained on historical data, they inevitably encode and often amplify pre-existing societal inequalities, manifesting as algorithmic bias 313237. The "black box" nature of complex AI systems frequently makes these internal discriminatory mechanisms difficult to decipher and audit 3133.
Embedded Bias in Predictive Analytics
Predictive adaptive models are frequently utilized by higher education institutions to identify students who are "at risk" of failing or dropping out, aiming to trigger early interventions 3137. However, when these models are trained on biased historical institutional data, they can produce highly skewed and detrimental results. Research indicates that models predicting college student success are significantly less accurate for racially minoritized students 32.
In one major study analyzing standard algorithmic prediction software, models generated false negatives for 19% of Black students and 21% of Latinx students - erroneously flagging them as likely to fail when they actually went on to achieve bachelor's degrees 31. When such algorithms inform automated advising or pathway assignment, students of color may be disproportionately routed into less rigorous remedial tracks that do not align with their actual cognitive capabilities. This structurally hinders their academic growth, limits access to advanced resources, and perpetuates historical inequities under the guise of objective, data-driven personalization 313733. To combat this, legislative frameworks such as the proposed Algorithmic Accountability Act have been introduced, aiming to mandate internal reviews of automated decision-making processes to uncover embedded unfairness 33.
Marked Pedagogies and Feedback Disparities
Bias in adaptive learning is not limited to predictive routing mechanisms; it extends deeply into the generative content produced by LLM pedagogical agents. A recent comprehensive study out of Stanford University evaluated how AI tutors generated feedback across simulated student profiles varying by race, gender, and English language proficiency 34. The research uncovered a persistent phenomenon termed "marked pedagogies," wherein the AI models fundamentally altered their instructional intent and depth based purely on the inferred demographic characteristics of the student 34.
When interacting with profiles identified as White or high-achieving, the LLMs consistently delivered deep, development-focused feedback. They critiqued logical argumentation, challenged the student to extend their reasoning, and focused heavily on higher-order cognitive skills 34. Conversely, when interacting with profiles identified as Hispanic, English Language Learners (ELL), or low-achieving, the models engaged in "feedback withholding bias." The AI shifted its focus almost exclusively to surface-level mechanics - such as grammar, spelling, and formality - providing excessive positive reinforcement but actively withholding actionable, critical guidance regarding the underlying academic content 34. This bifurcated instructional behavior threatens to create a digital landscape where marginalized students receive a structurally inferior, less intellectually demanding educational experience from automated systems.
Global Implementation Contexts and Infrastructure Challenges
The theoretical potential of adaptive learning systems is frequently constrained by the material realities of their deployment environments. Global education systems must confront the "implementation gap" - the persistent disconnect between a policy's technological intentions and what actually materializes in schools 35. Implementation strategies must acknowledge that hardware access, internet bandwidth, and digital literacy vary drastically across global populations 3536.
Resource-Constrained Environments in the Global South
In regions characterized by severe resource constraints, the deployment of high-bandwidth, cloud-dependent AI platforms is completely untenable. Across Africa, millions of students contend with overcrowded, multi-grade classrooms, under-resourced teachers, and a chronic lack of continuous internet access 3738. According to data reflecting educational challenges, over 80% of Grade 4 learners in South Africa are unable to read for meaning, underscoring the urgency for scalable interventions 38.
To bridge this gap, developers are pioneering "equity-first" EdTech solutions that prioritize low-data, low-device requirements over high-fidelity multimedia 38. A notable example is the Luma Learn platform, which delivers adaptive, curriculum-aligned literacy instruction via WhatsApp - the continent's most ubiquitous messaging application. By leveraging existing communication infrastructure rather than demanding high-end proprietary hardware, such initiatives reduce onboarding barriers for rural and underserved students 38.
Furthermore, offline AI adaptations have demonstrated profound efficacy in overcoming connectivity challenges. A 2024 pilot program implemented in Nigeria utilized AI tools preloaded onto tablets to entirely bypass unreliable internet connectivity 37. Over a six-week intervention, students interacting with the offline adaptive platform achieved a 0.31 standard deviation jump in test scores encompassing English proficiency and digital skills. In the context of global education metrics, a gain of 0.31 standard deviations is equivalent to roughly two years of standard learning progress 37.
Institutional Adoption in Latin America
In Latin America (LATAM), the transition toward Education 4.0 is accelerating, though progress remains uneven due to the persistent urban-rural digital divide and institutional fragmentation 3940. Higher education institutions in Chile, Colombia, and Brazil have emerged as regional pioneers in integrating AI-driven adaptive software 3940. For example, the Uplanner platform, originally developed in Chile and deployed across multiple nations, utilizes predictive analytics to forecast student demand, manage retention, and optimize curriculum planning, showcasing how adaptive technologies can streamline institutional administration alongside individual student instruction 30.
Interviews with innovative educators across Mexico, Colombia, Brazil, and Argentina indicate that while AI adoption improves student retention and reduces the time teachers spend on repetitive administrative tasks (noted by 66% of surveyed educators), major structural barriers remain 40. Successful, sustainable implementation relies heavily on developing localized human capital; without intensive, ongoing teacher training, advanced AI platforms ultimately fail to integrate into daily pedagogical practice. As research indicates, AI must be viewed as a tool to enhance human capacity, requiring robust professional development initiatives to ensure educators can appropriately supervise and adapt to algorithmic recommendations 3040.
| Global Region | Primary Infrastructure Challenges | Adaptive Implementation Strategies | Representative Initiatives |
|---|---|---|---|
| Africa (e.g., Nigeria, South Africa) | High data costs, lack of reliable internet, shared devices, massive multi-grade classrooms 3738. | Utilizing low-bandwidth delivery (SMS/WhatsApp), offline preloaded AI models, asynchronous tracking 3738. | Luma Learn (WhatsApp), USAID localized offline tablet pilots 3738. |
| Latin America (e.g., Brazil, Chile, Colombia) | Fragmentation of public policy, severe urban-rural digital divide, limited specialized teacher training 3940. | Public-private partnerships, integration of predictive AI for curriculum management, localized teacher upskilling 3040. | Uplanner predictive tracking, HEI distance education network expansions 3039. |
| Developed Contexts (e.g., US, EU) | Data privacy concerns, algorithmic accountability, integrating legacy LMS architectures 2133. | Cloud-based hyper-personalization, HITL deployment, legislative frameworks (e.g., Algorithmic Accountability Act) 2733. | Deep integrations of GPT-4 into primary learning management platforms 1946. |
Efficacy, Engagement, and Learning Outcomes
Empirical evaluations across diverse academic environments consistently validate the efficacy of AI-driven personalized learning pathways when implemented correctly. Quantitative analyses reveal significant, measurable gains over traditional "sheep-dip" (uniform, one-size-fits-all) instructional methodologies 132.
In a comprehensive empirical test involving 500 students, 100 content units, and over 5,000 discrete learning interactions, an AI-driven adaptive system correctly segmented learners into four precise behavioral clusters - allowing for targeted interventions on underachievers, average students, high-achievers, and fast learners. The system attained a 78.5% completion prediction accuracy 32. More importantly, students routed through these personalized learning pathways exhibited a mean performance improvement of 11.7% and a 6.3% increase in total course completion rates compared to a control group utilizing conventional static learning materials 32. Broader industry reports corroborate these localized findings, indicating that enterprise adaptive software interventions can generally improve learning outcomes by 15% to 25%, enhance student engagement by roughly 30%, and reduce the total time required to achieve mastery by 20% by actively skipping redundant content that the student has already mastered 4748.
However, the efficacy of generative feedback on higher-order cognitive traits, such as Self-Assessment Accuracy (SAA) - a student's ability to accurately monitor and judge their own performance - remains highly nuanced. While real-time LLM feedback vastly accelerates tactical problem-solving, randomized control trials examining language arts instruction suggest that simply providing LLM feedback does not uniformly improve metacognitive self-calibration across all cohorts 49. Research demonstrates a significant interaction effect: students with initially poor self-assessment skills showed marked improvement when provided with AI feedback. Conversely, highly calibrated students (those who already accurately judged their own abilities) did not improve and sometimes experienced decreased self-assessment accuracy when relying on the AI 49. This divergence suggests that an over-reliance on AI evaluation may occasionally disrupt a high-performing student's internal cognitive monitoring, reinforcing the premise that adaptive interventions must be contextually calibrated not just to a student's domain knowledge, but to their metacognitive baseline proficiency.
Conclusion
AI-powered personalized learning represents a fundamental evolution in educational technology. By synthesizing continuous telemetry data through advanced knowledge tracing algorithms - ranging from highly interpretable Bayesian Knowledge Tracing models to computationally complex Deep Knowledge Tracing neural networks - these systems maintain a probabilistic map of student mastery. The recent integration of Large Language Models has further elevated these platforms, enabling the real-time generation of context-aware, multimodal feedback that dynamically adjusts to a student's specific cognitive state and learning pace. Empirical evidence consistently confirms that when properly aligned, these systems increase engagement, accelerate error repair, and improve overall academic performance.
However, the proliferation of this technology requires rigorous ethical governance and technical scrutiny. The inherent opacity of deep learning models, combined with well-documented algorithmic biases that encode disparate feedback patterns and disproportionately route marginalized demographics into less rigorous pathways, necessitates a cautious, Human-in-the-Loop approach to deployment. As global case studies from Latin America to Sub-Saharan Africa demonstrate, the ultimate success of adaptive learning depends not merely on algorithmic sophistication, but on inclusive, adaptive implementation strategies. These strategies must account for local technological infrastructure constraints, prioritize digital equity, and support the indispensable role of the human educator. Only through the deliberate combination of intelligent algorithms, transparent data governance, and reflective pedagogical oversight can the promise of universally accessible, equitable, and personalized education be fully realized.