Meta-learning in artificial intelligence
Deep neural networks and foundation models conventionally require vast amounts of annotated data and extensive computational resources to achieve high performance. However, this traditional supervised learning paradigm falters in environments characterized by data scarcity, long-tailed distributions, non-stationarity, or the need for rapid, online adaptation. Meta-learning, commonly defined as "learning to learn," addresses these fundamental limitations by extracting transferable knowledge across a broad distribution of related tasks. Rather than learning a specific mapping from inputs to outputs for a single problem, a meta-learning system optimizes the learning process itself, enabling the model to adapt to novel, unseen tasks using only a few examples - a capacity known as few-shot learning 12.
By leveraging prior experience derived from a meta-training set, meta-learning algorithms derive optimal initialization parameters, generalized update rules, or highly structured embedding spaces. These generalized representations subsequently allow base learners to converge rapidly with minimal gradient updates during the meta-testing phase 23. The capacity for such rapid generalization relies on a hierarchical structure, most rigorously formalized as a bi-level optimization problem comprising an inner loop for task-specific adaptation and an outer loop for global meta-parameter refinement 56.
The Bi-Level Optimization Framework
The mathematical foundation of modern meta-learning is deeply intertwined with bi-level optimization (BLO), a concept originally derived from economic game theory (e.g., Stackelberg games) and subsequently integrated into the machine learning community to handle hierarchical problems. A bi-level optimization problem entails an upper-level (outer) optimization task whose feasible region is restricted by the solution set of a lower-level (inner) optimization task 74.
In the context of meta-learning, the framework operates over a distribution of tasks, denoted as $\mathcal{T}$. The overall process is structured into two nested optimization loops that handle distinct phases of the learning trajectory. The inner loop simulates the "fast learning" process. When the agent is presented with a specific task $\tau_i \in \mathcal{T}$, it creates a temporary copy of the global model parameters, denoted as $\theta$. The inner loop performs a small number of gradient descent steps using the loss function specific to that task's training data (often called the support set). This generates a set of adapted, task-specific parameters, $\phi_i$ 595.
The outer loop handles the "slow learning" or meta-optimization process. The goal of the outer loop is to update the initial global parameters $\theta$ so that the adapted parameters $\phi_i$ perform optimally across all tasks. To achieve this, the performance of the adapted model is evaluated on a separate validation set (the query set) for the same task. The algorithm then calculates the gradient of this validation loss with respect to the original meta-parameters $\theta$ and performs a permanent update. This formulation explicitly captures the "learning to adapt" objective, systematically adjusting the initialization so that future inner-loop adaptations are highly sample-efficient 595.
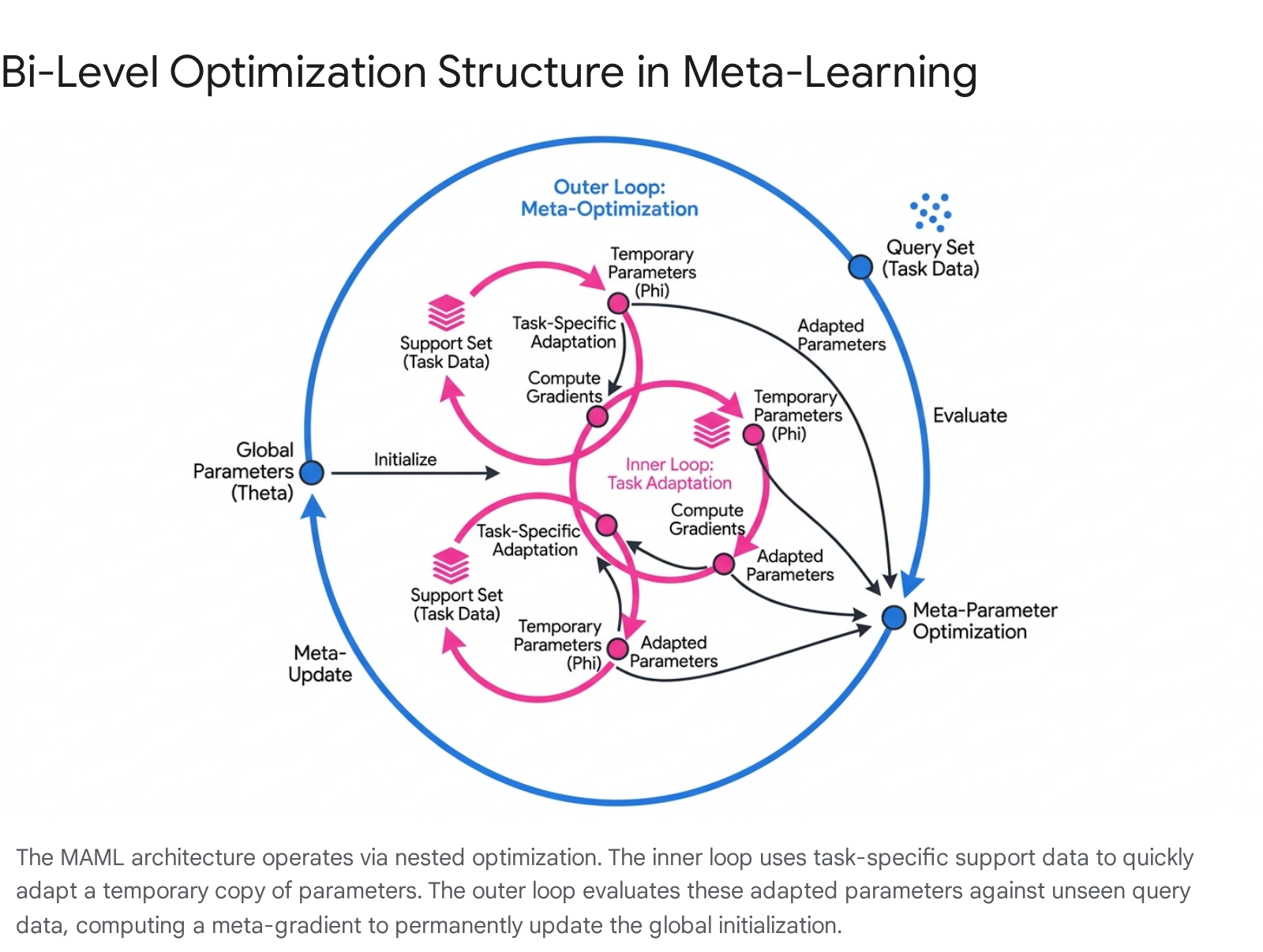
The nested nature of bi-level optimization introduces significant computational hurdles. Computing the gradient for the outer loop requires differentiating through the inner loop's optimization path. Because the inner loop itself involves gradients, calculating the outer loop's gradient necessitates the computation of second-order derivatives (Hessian matrices). This requirement makes the standard bi-level formulation computationally expensive and highly memory-intensive, particularly when scaling to deep neural networks with millions of parameters 5911.
Optimization-Based Meta-Learning Algorithms
To navigate the mathematical and computational complexities of bi-level optimization, researchers have developed various optimization-based meta-learning algorithms. These methods focus exclusively on discovering an optimal set of initial parameters that can be rapidly fine-tuned on new tasks using standard gradient-based optimizers.
Model-Agnostic Meta-Learning (MAML)
The most prominent algorithm in this category is Model-Agnostic Meta-Learning (MAML). MAML is deemed "model-agnostic" because it makes minimal assumptions about the underlying model architecture; it requires only that the model is parameterizable and differentiable, allowing it to be applied to convolutional networks, recurrent networks, and reinforcement learning policies alike 126.
In the MAML formulation, for a task $\tau_i$, the model parameters $\theta$ are updated to task-specific parameters $\phi_i$ using one or more gradient descent steps on the task's support data. The meta-objective then minimizes the sum of losses evaluated on the query data of all sampled tasks, using the adapted parameters $\phi_i$. By explicitly differentiating through the inner-loop update, MAML guides the global parameters toward a region in the loss landscape that is highly sensitive to task-specific gradients, ensuring that subsequent fine-tuning yields maximum performance improvements 116.
First-Order Approximations and Reptile
Because MAML requires computing second-order derivatives, scaling it to massive architectures introduces extreme bottlenecks. To circumvent this "Second-Order Problem," First-Order MAML (FOMAML) was introduced. FOMAML mathematically approximates the outer-loop gradient by entirely ignoring the second-derivative terms, operating under the assumption that the gradient evaluated at the adapted location ($\phi_i$) is sufficiently similar to the gradient at the initial location ($\theta$). Despite this mathematical truncation, empirical evidence suggests that FOMAML achieves performance nearly equivalent to full MAML while drastically reducing computation time 911.
Building on this premise, the Reptile algorithm further simplifies the optimization process. Reptile repeatedly samples a task, performs multiple steps of standard stochastic gradient descent (SGD) or Adam optimization to find adapted parameters, and then simply moves the global initial parameters $\theta$ in a straight line toward the final adapted parameters 112. Reptile operates mathematically similarly to FOMAML but requires only black-box access to an optimizer, as it does not unroll a computation graph to track the history of gradients 112.
The Vanishing Gradient Problem and Implicit Differentiation
While MAML and its first-order approximations are highly expressive, extending the inner loop to multiple gradient steps frequently results in the vanishing gradient problem. When backpropagating along an extended inner-loop optimization path, the gradient signals decay, preventing the outer loop from effectively updating the meta-parameters and severely degrading learning performance 78.
To resolve this, the field has increasingly turned to Implicit Differentiation. Algorithms such as Implicit MAML (iMAML) decouple the meta-gradient computation from the inner optimization path. Rather than unrolling the computational graph step-by-step, implicit differentiation models the optimal inner-loop parameters as an implicit function of the meta-parameters. By applying the implicit function theorem, the exact meta-gradient can be computed analytically using only the final adapted parameters and estimating local curvature 9. This path-independence entirely avoids vanishing gradients. While computing the inverse Hessian matrix for implicit differentiation remains mathematically complex, iterative approximation methods like the Conjugate Gradient (CG) algorithm reduce the time complexity of this operation from $\mathcal{O}(n^3)$ to $\mathcal{O}(n)$ 10.
Alternatively, recent innovations have proposed modeling the inner-loop gradient descent process as a conditional diffusion model. Frameworks such as MetaDiff view task-specific adaptation as a reverse denoising process, mapping Gaussian initialization to the target base-learner weights. Because diffusion models are trained to predict noise at isolated timesteps without backpropagating through the entire temporal trajectory, this approach entirely bypasses the inner-loop gradient path, mitigating memory burdens and eliminating vanishing gradients 7819.
Metric-Based Meta-Learning Architectures
While optimization-based methods focus on rapid parameter adaptation through gradient updates, metric-based methods approach meta-learning fundamentally differently. These architectures project raw input data into a dense, non-linear embedding space where simple distance metrics can reliably separate and classify samples 611. At inference time, the parameters of the metric-based model remain entirely fixed; no gradient descent is performed. Instead, the model generalizes to new tasks by matching query samples to support samples based on spatial proximity 12.
Prototypical Networks
Prototypical Networks operate on the assumption that there exists an embedding space in which points cluster tightly around a single prototype representation for each class. During the inner-loop task evaluation, the network computes a "prototype" vector by calculating the arithmetic mean of the embedded support samples belonging to that class. A new query sample is subsequently classified by finding the nearest class prototype using a distance function - typically Euclidean or Manhattan distance - and applying a softmax over the distances 1314.
The primary advantage of Prototypical Networks lies in their computational complexity at inference. Because they do not require backpropagation or fine-tuning, the inference time complexity is generally $\mathcal{O}(m \cdot d)$, where $m$ is the number of support samples and $d$ is the embedding dimension. This makes them significantly faster and less prone to overfitting on extremely small datasets compared to MAML 614.
Matching Networks and Relation Networks
Matching Networks expand upon the prototype concept by utilizing a differentiable nearest-neighbor mechanism augmented with an attention kernel. Instead of comparing a query to a single class centroid, Matching Networks compute the cosine similarity between the query embedding and the embedding of every individual support sample. The final prediction is generated as a probability distribution constructed from the attention-weighted combination of the support labels 1113.
Relation Networks address a core limitation of both Prototypical and Matching Networks: their reliance on fixed, pre-defined distance metrics like Euclidean or cosine distance. In complex scenarios, these linear distance metrics fail to capture intricate structural dependencies between images or text. Relation Networks replace the fixed distance metric with a learnable, non-linear relation module - essentially a secondary neural network. This relation module concatenates the embeddings of the query and support samples and explicitly learns to output a similarity score, allowing the network to dynamically reason about complex inter-class relationships 311.
| Meta-Learning Architecture | Core Mechanism | Parameter Updates at Inference? | Algorithmic Complexity Profile | Key Limitations |
|---|---|---|---|---|
| Model-Agnostic Meta-Learning (MAML) | Bi-level optimization finding an optimal global initialization | Yes (Gradient Descent) | High (Requires unrolling computation graphs) | Susceptible to vanishing gradients; computationally expensive inner loop. |
| Prototypical Networks | Metric-based mapping to class centroids | No (Distance to mean embedding) | Low ($\mathcal{O}(m \cdot d)$ inference) | Fixed metrics struggle with complex intra-class variance and non-stationary domain shifts. |
| Matching Networks | Differentiable nearest-neighbor with attention kernels | No (Attention-weighted voting) | Low to Medium | Attention mechanisms focus heavily on local features, missing global contextual dependencies. |
| Relation Networks | Learnable non-linear similarity module | No (Forward pass through relation module) | Medium (Additional neural network processing) | Risk of overfitting the relation module if meta-training task diversity is low. |
Table 1: Comparison of optimization-based and metric-based meta-learning architectures based on operational mechanisms and inference constraints.
Model-Based and Memory-Augmented Approaches
The third major paradigm in meta-learning relies on architectures specifically designed to encode fast adaptation internally, often by integrating recurrent properties or explicit memory systems. These Model-Based approaches seek to bypass both the gradient descent required by MAML and the rigid distance metric comparisons of Prototypical Networks 1315.
Memory-Augmented Neural Networks (MANNs)
Memory-Augmented Neural Networks, such as Neural Turing Machines, employ an external memory matrix to store and retrieve representations of previously encountered tasks. When faced with a new task, the controller network writes critical features of the support set into the memory module. During query evaluation, the network uses soft-attention mechanisms to read from the memory matrix, synthesizing predictions based on retrieved historical task parameters 1326. Because the adaptation mechanism relies on internal memory read/write operations rather than weight updates, MANNs can adapt to novel tasks almost instantaneously.
ALMA and Agentic Memory Design
In modern autonomous systems, the statelessness of standard foundation models presents a severe bottleneck, preventing agents from continually learning and adapting over long horizons. While hand-crafted memory designs exist, they are fixed and often fail to generalize across non-stationary, diverse domains 1628.
To address this, Google DeepMind researchers developed ALMA (Automated meta-Learning of Memory designs for Agentic systems). Rather than manually engineering memory architectures, ALMA employs an outer-loop Meta Agent that explores an open-ended search space of memory designs expressed as executable code. ALMA meta-learns entire database schemas, alongside their specialized retrieval and update mechanisms, optimizing them for continuous learning. By replacing rigid human-crafted memory modules with dynamically evolved memory code, agentic systems can autonomously improve their long-horizon reasoning and adaptability across sequential decision-making domains 1628.
Theoretical Guarantees and Convergence Analysis
Despite the empirical dominance of meta-learning algorithms across benchmarks, establishing rigorous theoretical guarantees regarding their convergence rates and generalization boundaries remains highly challenging. The bi-level nature of the problem dictates that theoretical models must account for both task-level empirical risk minimization (inner loop) and environment-level expected risk minimization (outer loop) simultaneously 2930.
Convergence Rates in Non-Convex Landscapes
Deep neural networks inherently possess highly non-convex loss landscapes, making traditional convergence guarantees difficult to formulate. However, recent analyses utilizing the Neural Tangent Kernel (NTK) framework have yielded significant breakthroughs. Researchers have proven that when MAML is applied to extremely over-parameterized neural networks, the model is guaranteed to converge to a global optimum at a linear rate 3117.
Under these over-parameterized conditions, the inner-loop adaptation trajectory is mathematically equivalent to kernel regression utilizing a novel class of kernels designated as Meta Neural Tangent Kernels (MetaNTK). By evaluating the condition number of the MetaNTK matrix at initialization, researchers can accurately predict a network's trainability and convergence speed without executing the full training loop. This theoretical insight has been leveraged to accelerate Neural Architecture Search (NAS) for few-shot learning, providing over 100x speedups by using MetaNTK to rank architectures prior to training 3117.
In more constrained, non-convex settings without infinite width assumptions, full MAML has been theoretically proven to find an $\epsilon$-first-order stationary point ($\epsilon$-FOSP) in at most $\mathcal{O}(1/\epsilon^2)$ iterations, provided the algorithm has access to second-order information 218. Conversely, strict first-order approximations like FO-MAML, while empirically successful, theoretically fail to guarantee convergence to an $\epsilon$-FOSP for any $\epsilon > 0$. This highlights a fundamental theoretical trade-off: omitting second-order information significantly boosts computational speed but sacrifices mathematical guarantees of convergence 2.
Generalization Bounds and Robustness
Generalization bounds in meta-learning quantify the expected performance gap between the tasks seen during meta-training and novel, unseen tasks drawn from the same task distribution $\mathcal{T}$ 2930. Modern theoretical frameworks rely on PAC-Bayesian learning theories and Sample Compression frameworks to derive tight, non-vacuous bounds for these algorithms 19.
By treating the meta-learner as a hypernetwork that compresses dataset inputs into a latent space, researchers can measure the complexity of the information bottleneck to establish formal generalization limits 19. Furthermore, when shared task representations are mapped to infinite-dimensional reproducing kernel Hilbert spaces, theoretical models show that careful regularization - leveraging the inherent smoothness of task-specific regression functions - can mitigate non-trivial biases. This results in generalization bounds that scale favorably, and often logarithmically, with the total number of meta-training tasks 3020.
| MAML Variant | Convergence Guarantee (Non-Convex) | Computational Complexity | Memory Complexity | Implicit Approximation Error |
|---|---|---|---|---|
| MAML (Full Back-prop) | Converges to $\epsilon$-FOSP in $\mathcal{O}(1/\epsilon^2)$ | $\mathcal{O}(\kappa \log \frac{D}{\delta})$ | $\text{Mem}(\nabla \hat{L}_i) \cdot \kappa \log \frac{D}{\delta}$ | 0 (Exact calculation) |
| FO-MAML | No formal $\epsilon$-FOSP guarantee | $\mathcal{O}(1)$ relative to inner loop | $\text{Mem}(\nabla \hat{L}_i)$ | High (Truncates second-order terms) |
| Implicit MAML | Converges to $\epsilon$-FOSP | $\mathcal{O}(\sqrt{\kappa} \log \frac{D}{\delta})$ | $\text{Mem}(\nabla \hat{L}_i)$ | $\delta$ (Dependent on curvature estimation) |
Table 2: Comparison of theoretical convergence bounds, computational complexity, and memory requirements for finding an $\epsilon$-approximate meta-gradient across different MAML formulations. $\kappa$ denotes the condition number of the inner problem, $D$ is the search space diameter, and $\delta$ is the target error level 2.
Convergence with Foundation Models
The rapid scaling of generative AI and Large Language Models (LLMs) has fundamentally altered the meta-learning landscape. As foundation models grow to hundreds of billions of parameters, executing standard bi-level gradient updates becomes computationally unfeasible. Consequently, the mechanisms of meta-learning have abstracted from parameter updates to context window manipulations and structured prompting.
In-Context Learning vs. Meta-Learning
The ability of LLMs to execute few-shot learning by simply observing demonstrations in their input prompt is known as In-Context Learning (ICL). ICL emerges implicitly during the unsupervised pre-training phase of attention-based transformer models. Unlike traditional meta-learning, ICL requires zero weight updates; the model infers the task mapping purely by attending to the concatenated support examples and applying that logic to the query 363721.
However, because ICL does not explicitly optimize for generalization, it can be brittle and highly sensitive to prompt formatting and example bias. To bridge this gap, researchers have developed frameworks like MetaICL and MICRE (Meta In-Context learning for Relation Extraction). These models apply the bi-level meta-learning objective directly to the ICL paradigm. During the meta-training phase, the LLM is explicitly trained across a massive corpus of tasks to minimize prediction loss on a target example, conditioned strictly on a support set residing in its context window. This "meta-training for in-context learning" explicitly teaches the LLM how to perform ICL, dramatically improving zero-shot and few-shot task generalization at inference time without requiring any localized fine-tuning 37212240.
Meta-Prompting and Agentic Workflow Induction
Extending beyond simple few-shot ICL, the concept of "Meta-Prompting" abstracts the problem-solving process entirely. Rather than feeding an LLM specific, content-based examples, a meta-prompt provides a high-level syntactical structure or instruction framework. This forces the model to recursively decompose intricate problems into manageable sub-tasks. By eliminating reliance on specific examples, meta-prompting removes example bias, improves token efficiency, and establishes a functorial relationship between tasks and prompts, allowing the LLM to generate its own sub-prompts in a metaprogramming-like fashion 364123.
In the realm of autonomous agents, meta-learning principles are applied to workflow induction. Complex LLM systems coordinate structured sequences of model calls, tools, and reasoning steps to achieve specific goals. Frameworks like FlowBot cast the creation of these agentic workflows as a bi-level optimization problem. The outer loop optimizes a high-level structural "sketch" of the workflow (determining how and when LLMs are called), while the inner loop optimizes the specific textual prompts for each individual call. To execute this without parameter gradients, both loops utilize "textual gradients" - natural language feedback generated by an LLM that evaluates the input, output, and loss, effectively mimicking layer-wise backpropagation entirely in text 43.
| Adaptation Paradigm | Primary Mechanism | Parameter Updates During Inference? | Operational Complexity | Vulnerability to Example Bias |
|---|---|---|---|---|
| Transfer Learning | Supervised fine-tuning on downstream datasets | Yes (Extensive, full network) | High | Low (Overrides prompt bias via tuning) |
| In-Context Learning (ICL) | Few-shot demonstrations in the input context window | No | Low | High |
| Meta-Training for ICL | Bi-level pre-training specifically to optimize in-context reasoning | No | Medium (Heavy pre-training required) | Medium |
| Meta-Prompting | Abstracting logical syntax and problem-solving structures | No | Low | Low (Focuses on structure, not content) |
Table 3: Comparison of adaptation paradigms in foundation models, illustrating the shift from parameter-based learning to context-based reasoning 36372241.
Applied Meta-Learning Domains
The theoretical advancements in meta-learning have rapidly translated into robust applications in highly constrained, real-world domains where data is sparse, expensive, or highly variable.
Medical Image Analysis Under Data Scarcity
The training of deep learning models in medical imaging is severely restricted by the high cost of expert annotation and strict patient privacy regulations. Meta-learning has emerged as the premier solution for these few-shot scenarios, excelling in tumor segmentation, disease classification, and cross-modality image registration 2425.
A systematic review of few-shot medical imaging models indicates that the choice of meta-learning algorithm is highly domain-dependent. In tasks such as Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) brain tumor classification, empirical evidence demonstrates that metric-based architectures (e.g., Siamese and Prototypical Networks) consistently outperform optimization-based models like MAML. Medical scans frequently exhibit high intra-class variance and complex anatomical noise. MAML often struggles to converge to a stable generalized representation within the restrictive 1 to 5 gradient steps typically allowed in few-shot settings. Conversely, metric-based methods coupled with Vision Transformers (ViTs) generate highly robust, stable embeddings that adapt effectively to structural variability, significantly mitigating the risk of overfitting on minimal data volumes 2627.
Robotics and Continuous Control Systems
Standard reinforcement learning (RL) policies frequently experience catastrophic failure when exposed to physical distribution shifts in the real world, such as unexpected changes in friction, mass, or actuator degradation. Meta Reinforcement Learning (Meta-RL) mitigates this by allowing robotic policies to execute rapid online adaptation to environmental perturbations 293018.
Research conducted by teams at Google DeepMind and affiliated robotics labs has successfully embedded meta-learning directly into continuous control pipelines. These frameworks employ bi-level optimization where the upper level searches for generalized meta-priors over reward functions and safety constraints, while the lower level refines the specific policy actions based on limited expert demonstrations 1828. To ensure these models operate safely in unpredictable physical environments, researchers utilize techniques like "predictive red teaming," which actively breaks policies in simulation to feed failure data back into the meta-optimizer, resulting in highly resilient, zero-shot generalizable robotic behavior 1828.
Neuroscience Integration and Evolving Models
To further stabilize meta-learning architectures, researchers are increasingly drawing inspiration from biological systems. For instance, studies from KAIST have introduced "meta-prediction," a learning methodology modeled on the human brain's predictive coding mechanisms. In deep neural networks, errors often accumulate unevenly during backpropagation. Meta-prediction addresses this by forcing the AI to predict how its own prediction errors will evolve over time, allowing the system to engage in localized, distributed self-correction. This biomimetic approach achieves higher stability than whole-network backpropagation and offers promising pathways for energy-efficient, edge-deployed AI models 49.
Simultaneously, educational AI research at Tsinghua University demonstrates how meta-learning concepts apply to user modeling. By analyzing interaction data across Large Language Model (LLM) agent frameworks, researchers dynamically classify students into specific behavioral clusters (e.g., active questioners, responsive navigators) using epistemic network analysis. This allows the AI to rapidly adapt its pedagogical strategies to individual users, establishing highly personalized, continuous learning environments 5029.
Conclusion
Meta-learning represents a paradigm shift in artificial intelligence, moving from models that passively memorize specific mappings to systems that actively engineer their own cognitive architectures and optimization strategies. Optimization-based frameworks, despite the mathematical friction of bi-level constraints and vanishing gradients, establish rigorous methodologies for discovering highly adaptable neural initializations. Concurrently, metric-based networks offer stable, non-parametric inference pathways highly suited for noisy, low-data domains like medical imaging.
As the field intersects with the extreme scale of foundation models, the principles of meta-learning are undergoing continuous abstraction. Through mechanisms like textual gradients, meta-prompting, and dynamically evolving memory schemas, modern AI systems are learning to orchestrate complex reasoning workflows autonomously. By embedding the capacity to "learn to learn" directly into both neural weights and high-level logic, meta-learning ensures that future AI systems remain robust, sample-efficient, and capable of seamless adaptation in continuously evolving, non-stationary environments.