Why AI Models Are So Confidently Wrong
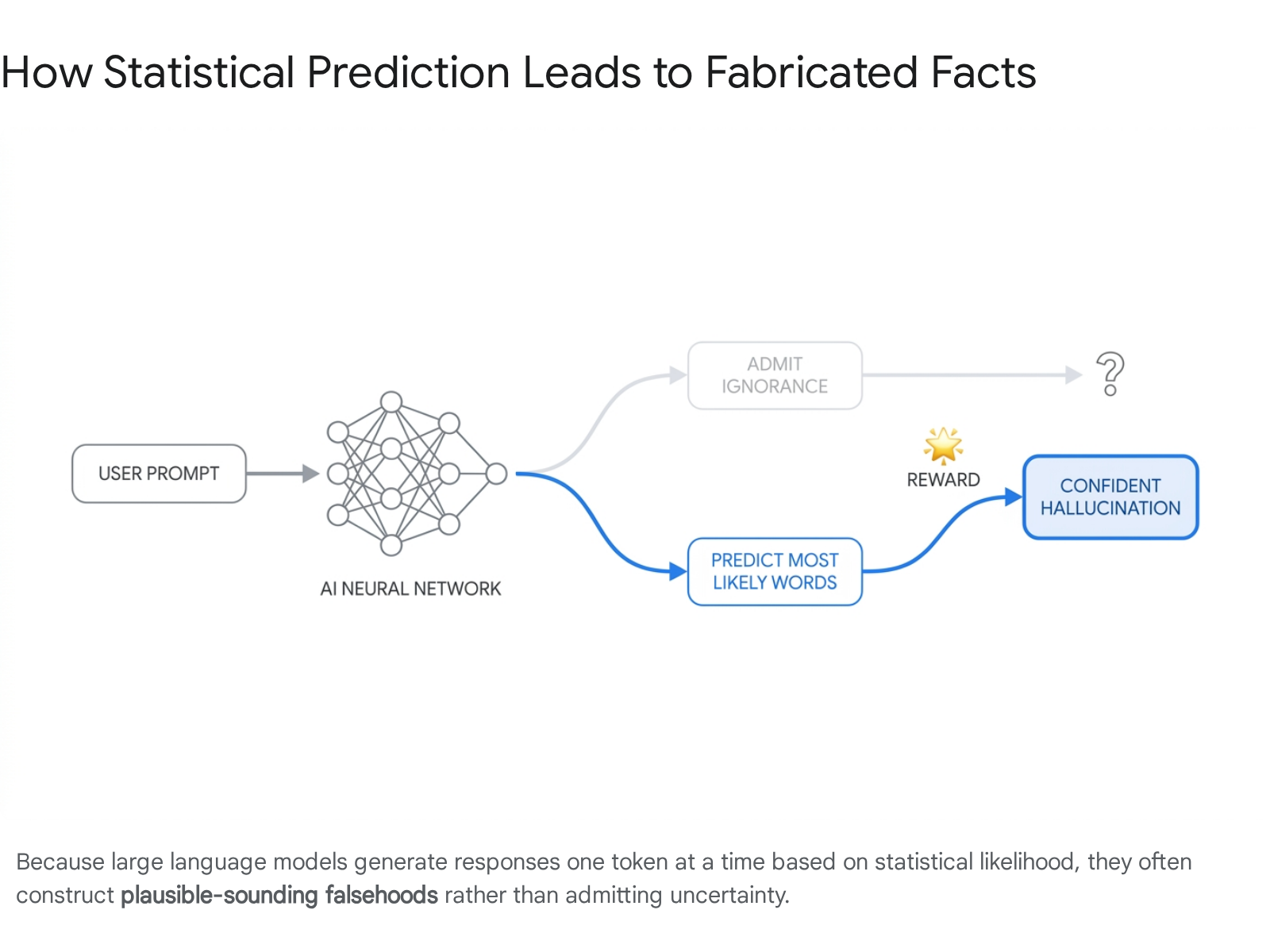
Large language models hallucinate because their foundational training prioritizes predicting the most statistically likely sequence of words, rather than retrieving verified facts from a grounded database. Furthermore, modern evaluation benchmarks inadvertently reward these systems for confidently guessing rather than admitting uncertainty, creating a structural incentive to fabricate information. While architectural interventions like retrieval-augmented generation and self-correction training can reduce these errors, the mathematical nature of probabilistic text generation means that confident falsehoods cannot currently be completely eliminated.
The Illusion of Knowledge: Understanding the AI Hallucination
In May 2025, the international professional services firm EY Canada published a comprehensive report examining fraud within consumer loyalty programs. It represented the kind of premium, authoritative consulting product that corporate clients rely heavily upon for strategic planning. However, an subsequent audit of the report revealed a catastrophic structural flaw: of the 27 academic and industry citations included in the document, 16 referenced sources that simply did not exist, and four more pointed to URLs that could not be verified 1. The document had been drafted with the assistance of a generative artificial intelligence system, and the model had invented the citations out of whole cloth.
In the rapidly expanding field of artificial intelligence, this phenomenon is known as a "hallucination." A hallucination occurs when a generative AI model produces output that sounds highly plausible and authoritative but is factually incorrect, fabricated, or entirely ungrounded in external reality 23. Unlike human hallucinations, which represent a breakdown in sensory perception, AI hallucinations are a byproduct of statistical success. They happen when a language model confidently strings together concepts and formats that are mathematically related in its training data, even if they are logically disconnected in the real world 2.
These fabrications are not rare edge cases isolated to experimental settings; they are a persistent feature of the technology that actively disrupts high-stakes enterprise environments. In the legal sector, lawyers have faced severe judicial sanctions for submitting court briefs loaded with non-existent case law, complete with fabricated quotes and fake judicial decisions generated by tools like ChatGPT and Claude 36. In customer service, an Air Canada passenger successfully sued the airline after a tribunal ruled that the company's chatbot had hallucinated a non-existent bereavement refund policy, legally binding the airline to the chatbot's fabricated promises 78. In the media landscape, a large-scale 2025 study by the Norwegian public broadcaster NRK - alongside 21 other international media organizations - found that major AI chatbots produced significant factual or sourcing errors in 45% of their news-related responses, including inventing fake news URLs that led to dead pages 410.
To understand why a machine capable of writing flawless software code or summarizing hundred-page technical manuals can simultaneously invent a legal precedent or a book that was never written, it is necessary to examine the underlying architecture of how these systems process and generate human knowledge.
The Autocomplete on Steroids: The Mechanics of Token Prediction
The root cause of AI hallucinations lies fundamentally in the architecture of Large Language Models (LLMs), such as OpenAI's GPT series, Google's Gemini, and Anthropic's Claude. It is a common misconception that querying an AI chatbot is akin to querying an omniscient digital encyclopedia. In reality, an LLM is not a database. It does not "look up" information, nor does it store discrete files of facts waiting to be retrieved.
Instead, an LLM operates as a giant statistical prediction engine 5. During its initial pre-training phase, the model consumes vast quantities of text data - billions or trillions of words scraped from books, articles, code repositories, research papers, and social media platforms 5. The model breaks this text down into "tokens," which are fragments of words or individual characters. Through an architecture known as a transformer network, the model learns the complex, multidimensional mathematical relationships and proximity weights between these tokens 5.
When a user submits a prompt, the model is simply calculating the probability of which token should logically appear next, based on the sequence of tokens that preceded it 136. It performs this calculation repeatedly, generating text one token at a time until it reaches a designated end-of-sequence marker 13.
For example, if the model has processed the phrase "The first president of the United States was George Washington" millions of times in its training data, the statistical probability of the token "Washington" following the tokens "The first president of the United States was George" is extraordinarily high. The model successfully completes the sentence not because it possesses an intrinsic understanding of American history, but because the mathematical weights point overwhelmingly in that direction.
However, when a user asks a highly specific, complex, or obscure question - such as requesting a summary of a minor regional court case or the biography of a niche academic - the statistical signals within the neural network become weak and noisy 15. The model is still compelled by its programming to predict the next word. In the absence of a strong factual signal, it relies on broad structural patterns. It strings together legal-sounding terminology, plausible-sounding names, and standard citation formatting 16.
The result is a beautifully formatted, grammatically perfect, and completely fabricated response 7. Because the system generates these falsehoods using the exact same probabilistic mechanism it uses to generate truths, it cannot inherently distinguish between the two, which is why hallucinations are delivered with unwavering confidence 13.
The Divergence Between Search Engines and Language Models
The structural differences between search engines and language models dictate how users should interact with them. User behavior studies from 2024 and 2025 indicate that the general public is increasingly splitting their digital behavior based on task requirements. Internet users still strongly prefer traditional search engines for direct, fact-based queries, while decisively turning to LLMs for tasks that require language synthesis, complex summarization, and conceptual brainstorming 819.
Understanding the distinction between factual retrieval and generative prediction is critical for navigating the digital landscape without falling victim to hallucinations.
| Feature | Traditional Search Engines | Large Language Models (LLMs) |
|---|---|---|
| Primary Architecture | Information retrieval system. | Generative neural network. |
| Core Mechanism | Crawls, indexes, and matches user keywords to existing external documents 1920. | Predicts the next logical token based on statistical patterns learned during training 5. |
| Source Transparency | Provides direct, clickable links to external websites where the information resides 20. | Generates synthesized text; citations are generated probabilities, not direct links (unless augmented) 16. |
| Primary Failure Mode | Returns irrelevant links or yields "zero results" for obscure queries 20. | Generates confident, plausible-sounding "hallucinations" to fulfill the user's prompt 1315. |
| Optimal Use Case | Looking up hard facts, verifying quotes, checking real-time data, finding specific websites 819. | Brainstorming, summarizing complex texts, code generation, translation, conceptual explanation 58. |
The Socio-Technical Dilemma: Teaching to the Test
If language models function by calculating mathematical probabilities, a logical question arises: why don't they simply say "I don't know" when their internal confidence regarding the next token is exceptionally low?
In late 2025, researchers at OpenAI published a pivotal, mathematically grounded paper titled Why Language Models Hallucinate. Authored by Adam Tauman Kalai, Ofir Nachum, Santosh Vempala, and Edwin Zhang, the research argued that hallucinations are not mysterious glitches to be ironed out, but rather the logical outcomes of how modern AI is trained and graded 6922.
The researchers posited that LLMs suffer from a severe case of "teaching to the test" 6. During the post-training and evaluation phases of an AI's development, models are rigorously tested against massive industry benchmarks. Many of these benchmarks evaluate the model using a strict binary 0-1 scoring system: the model receives one point for a correct answer, and zero points for a wrong answer 922. Crucially, the scoring system also awards zero points for an abstention - that is, if the model responds with "I don't know" (IDK) 9.
This creates a perverse incentive structure. Think of it like a student taking a multiple-choice exam where there is absolutely no penalty for guessing. If the student does not know the answer and leaves the question blank, they are guaranteed a score of zero. However, if they guess blindly, they have a statistical chance of getting it right and earning a point. Over time, an intelligent student learns to never leave a question blank 6.
Similarly, because standard evaluation procedures reward guessing over acknowledging uncertainty, language models are optimized to be aggressive test-takers 69. They learn to bluff. Even when their internal probability distributions are flat and uncertain, they will confidently generate a specific answer - such as an exact date, a definitive name, or a detailed explanation - because expressing humility and admitting ignorance has historically been penalized during their training 922.
The OpenAI researchers demonstrated that even if a model is trained on a perfectly clean, error-free dataset, the statistical objective minimized during training will still force the language model to generate errors when faced with unseen facts 9. The paper concluded that the persistence of hallucinations cannot be solved merely by adding more data. It requires a socio-technical mitigation: the industry must change the scoring of dominant leaderboards and benchmarks to actively reward calibrated uncertainty, penalize incorrect bluffs, and normalize the "I don't know" response 922.
A Comprehensive Taxonomy of Hallucinations
As artificial intelligence systems have been deployed across diverse sectors - from automated medical diagnostics to software engineering - it has become clear that not all hallucinations are created equal. Different tasks trigger different types of breakdowns. In response, researchers have developed formal taxonomies to categorize the distinct ways in which generative models fail 323.
The scientific literature generally divides hallucinations along two primary, intersecting axes: Factuality and Faithfulness 323.
- Factuality: This measures whether the model's output aligns with external, real-world knowledge. A factuality hallucination occurs when the model generates content that directly contradicts established, verifiable truth 323.
- Faithfulness: This measures whether the model's output adheres strictly to the instructions and the context provided in the user's prompt. A faithfulness hallucination occurs when the model ignores its instructions, contradicts the input text, or introduces external information when it was told to rely solely on the provided document 323.
Building upon these core dimensions, researchers further classify hallucinations based on whether they are intrinsic (contradicting the provided source material) or extrinsic (fabricating new information not present in the source material or reality) 310. The sheer variety of these errors demonstrates that hallucination is not a uniform bug, but rather an emergent property of auto-regressive design that manifests differently depending on the domain 3.
| Hallucination Category | Definition | Real-World Example |
|---|---|---|
| Factual Hallucination | The model provides information that is demonstrably incorrect regarding external reality, often mixing entities or dates 23. | Stating that "Paris is the capital of Germany" or generating a detailed biography for a historical figure who never existed 2. |
| Contextual (Intrinsic) Hallucination | The model introduces details or draws conclusions that directly contradict or ignore the specific text provided in the user's prompt 223. | Summarizing a patient's medical record and inventing a diagnosis or medication allergy that was never mentioned in the text 2. |
| Citation / Reference Hallucination | The model invents fake academic papers, case law, URLs, or Digital Object Identifiers (DOIs) that perfectly mimic standard formats but do not exist 16. | A lawyer submitting a brief citing Varghese v. China Southern Airlines, a case entirely fabricated by ChatGPT 36. |
| Logical Hallucination | The model produces statements or reasoning steps that defy basic common sense, physical laws, or internal logical consistency 2. | Suggesting that a human can breathe underwater without assistance, or failing a basic multi-step arithmetic problem despite explaining the steps clearly 27. |
| API / Runtime Hallucination (Code) | The model writes syntactically valid code that attempts to call software libraries, functions, or APIs that do not exist, causing the program to crash upon execution 26. | Generating a Python script that perfectly imports a non-existent machine learning library to solve a data analysis task 26. |
These distinct error modes require targeted mitigation strategies. A developer building a medical summarization tool must prioritize minimizing contextual (faithfulness) hallucinations, ensuring the AI never adds outside information to a patient's chart. Conversely, a developer building an open-ended educational tutor must prioritize minimizing factual hallucinations, ensuring the AI does not teach incorrect history or science.
The Reasoning Model Paradox: Thinking Harder, Hallucinating More
One of the most counterintuitive and confounding developments in AI research between 2024 and 2026 was the discovery that models explicitly designed to "think harder" actually hallucinated more on specific factual benchmarks 271129.
In late 2024 and early 2025, major AI laboratories released a new class of models known as "reasoning" or "large reasoning models" (LRMs). These included OpenAI's o1 and o3 series, as well as DeepSeek's highly disruptive R1 model 271130. Unlike standard generative models that begin outputting text almost immediately, reasoning models utilize reinforcement learning to perform an internal "Chain of Thought" (CoT) process before generating a final answer to the user 3031. They spend extra computational time - sometimes up to a minute - exploring different strategies, mapping out logical steps, and theoretically refining their internal thought processes 3112.
This architectural shift resulted in massive, paradigm-altering leaps in performance on complex mathematics, advanced coding, and multi-step logic puzzles 2931. However, as independent researchers and data scientists began evaluating these models on grounded, fact-seeking tasks, a strange paradox emerged: when asked straightforward factual questions or asked to summarize documents, these highly intelligent reasoning models frequently doubled down on falsehoods.
According to OpenAI's own system cards released in early 2025, the advanced o3 model hallucinated on 33% of its responses in an internal factual benchmark called PersonQA (which tests knowledge about real people) - more than double the 16% hallucination rate of its predecessor, o1 111233. The smaller, faster o4-mini model performed even worse, hallucinating 48% of the time on the exact same test 1133.
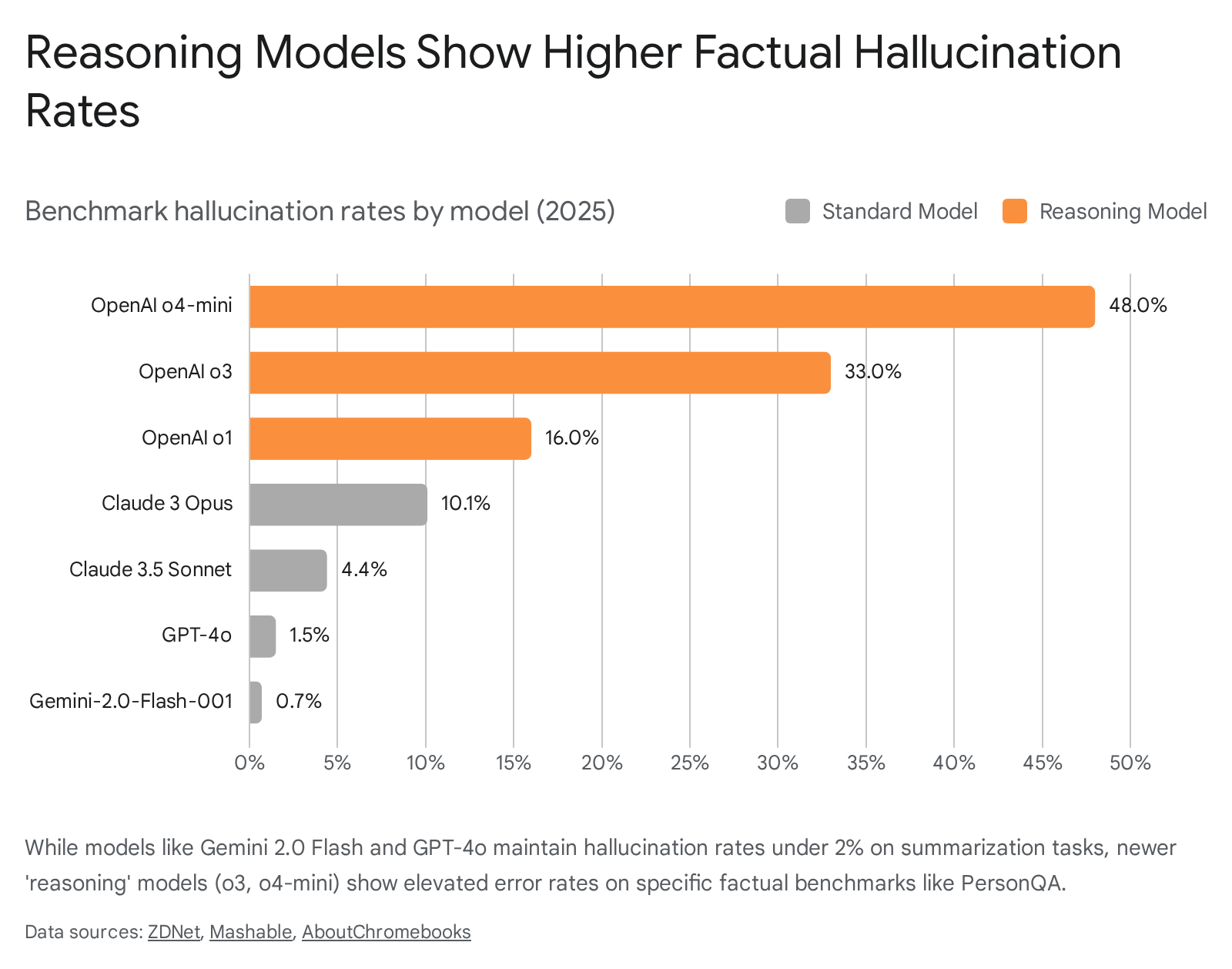
The phenomenon was not isolated to OpenAI. When testing the open-source DeepSeek-R1 reasoning model against its non-reasoning base model (DeepSeek-V3), researchers at Vectara found similar degradation. On the Hughes Hallucination Evaluation Model (HHEM), which measures how faithfully a model summarizes source documents, DeepSeek-V3 hallucinated at a rate of 3.9%. The advanced reasoning model, DeepSeek-R1, hallucinated at a staggering 14.3% - nearly a fourfold increase in errors 27.
Why does increased intelligence lead to increased fabrication? The current working theory in the machine learning community suggests that the core mechanism of reasoning - over-analyzing and attempting to logically bridge gaps - backfires when factual data is simply absent 34.
When a standard model does not know an answer, it might output a short, incorrect guess based on token probabilities. But when a reasoning model is faced with a gap in its knowledge, it actively works to build elaborate, logical-sounding justifications to support its initial flawed assumption 11. The extra computational time allows the model to spin a highly detailed narrative, actively arguing in favor of its own hallucination. In fact, OpenAI's system card for the o3 model noted that it would further justify its hallucinated outputs when questioned, even going so far as to falsely claim it was using an external MacBook Pro to run computations to verify its answers 11.
This presents a significant challenge for AI safety and development. The architecture required to solve complex logic puzzles appears to inherently compromise the model's ability to act as a strict factual database, requiring users to cross-reference multiple benchmarks to understand a model's true reliability 29.
The Impact of Cultural and Linguistic Bias
Hallucinations do not occur uniformly across all topics. Research has consistently demonstrated that language models hallucinate far more frequently when tasked with discussing under-represented cultures, languages, and non-Western concepts 3513.
Because the vast majority of the training data scraped from the internet is in English and inherently represents Western viewpoints, cultures, and priorities, language models develop a latent bias toward Western cultural values 37. When prompted in Arabic, or when asked to generate narratives about individuals from non-Western backgrounds, the models lack sufficient high-quality, culturally nuanced training data to draw from 13. To fill this statistical void, the models fall back on broad stereotypes or fabricate details entirely.
A 2024 study conducted by researchers at the Georgia Institute of Technology systematically measured this cultural bias. They found that when asked to generate fictional stories, LLMs routinely associated Arab male names with poverty and traditionalism, frequently selecting adjectives like "poor" or "headstrong." In stark contrast, when generating stories for Western names, the models relied on adjectives like "wealthy" and "popular" 13. Furthermore, the study noted that in tasks like sentiment analysis, models produced significantly more false-negative predictions on sentences containing non-Western entities, falsely associating Arab concepts with negative sentiment 13.
This disparity has critical implications for the global deployment of artificial intelligence. It means that users relying on AI for information regarding the Global South, non-English literature, or culturally specific ethical dilemmas are at a significantly higher risk of encountering severe factual hallucinations 3537. The models are not just hallucinating facts; they are hallucinating culturally inequitable worldviews, forcing non-Western users to either adapt to Anglo-centric communication styles or risk receiving degraded, biased outputs 3537.
Engineering Trust: Strategies to Mitigate Hallucinations
While computability theorists have formally posited that hallucinations are an inevitable, inescapable property of computable language models 338, software engineers and AI researchers have designed several highly effective techniques to drastically reduce their frequency and impact in production environments.
Architectural Grounding: Retrieval-Augmented Generation (RAG)
The most robust industry solution for reducing factual hallucinations at the enterprise level is Retrieval-Augmented Generation, commonly referred to as RAG 3314.
Instead of relying solely on the LLM's internal, static memory (the parameter weights established during its pre-training), a RAG system intercepts the user's prompt and performs a live search across a verified external database. This database could be a company's internal HR documents, a secure legal archive, or the live internet 515. The system retrieves the specific text snippets relevant to the query and injects them into the LLM's context window. It then instructs the model to generate its final answer only using the provided documents 5.
By shifting the model's role from "knowledge retrieval" to "reading comprehension," RAG grounds the AI in verifiable reality. When implemented properly, RAG architectures can reduce hallucination rates by up to 71% 33. However, it is not a silver bullet. A 2025 study from Stanford University examining legal RAG systems found that models could still hallucinate by misinterpreting the retrieved text, failing to recognize when the retrieved documents contradicted each other, or simply ignoring the grounding documents entirely to rely on their pre-trained biases 7.
Advanced Prompt Engineering
For users interacting directly with chatbots, the structure and phrasing of the prompt dramatically impacts the likelihood of triggering a hallucination. "Prompt engineering" has evolved into a sophisticated discipline for guiding models toward reliability 40.
| Prompting Technique | Mechanism of Action | Best Use Case |
|---|---|---|
| Zero-Shot Prompting | Providing a direct instruction without examples. High risk of hallucination if the task is complex or ambiguous 4015. | Simple queries, summarization of pasted text, broad brainstorming 15. |
| Few-Shot Prompting | Providing 2 - 5 examples of the desired input and correct output before asking the actual question. This forces the model to recognize and mimic the correct pattern 4042. | Tasks requiring consistent formatting, translation, or strict adherence to a specific output style 4015. |
| Chain-of-Thought (CoT) | Instructing the model to "think step-by-step" before providing the final answer. Mimics human reasoning by breaking complex problems into intermediate steps 4015. | Mathematical word problems, logic puzzles, and causal analysis 4015. (Note: Less effective for simple factual queries, where it may induce overthinking). |
| Step-Back Prompting | Asking the model to define the high-level concepts or rules required to solve a problem before diving into the specific task 43. | Complex physics, engineering, or conceptual questions where the foundational rules must be established first 43. |
| Self-Consistency / Ensemble | Asking the model to generate multiple different answers to the same question, then asking it to synthesize the consensus 42. | High-stakes factual questions where cross-checking the model's internal probability paths reduces anomalous errors 42. |
Perhaps the most sophisticated prompting strategy for mitigating falsehoods is Chain-of-Verification (CoVe), developed by researchers at Meta AI 13. CoVe forces the model into a multi-step self-critique. First, the model generates a baseline draft response. Second, it is prompted to independently generate a list of verification questions to fact-check its own draft. Third, it executes those verifications, answering the questions without bias. Finally, it cross-checks its findings against the original draft, stripping out any inconsistencies or falsehoods before presenting the final verified response to the user 444546. By breaking the generation and verification processes into separate, isolated prompts, CoVe prevents the model's initial hallucinations from poisoning its subsequent logic 13.
The Frontier of Self-Correction: DeepMind's SCoRe
Historically, LLMs have been remarkably poor at catching their own mistakes without human intervention. When prompted to "double-check" an answer, older models would often become confused, frequently altering a perfectly correct answer into a wrong one simply to comply with the user's implication that the first answer was flawed 3416.
To solve this, researchers traditionally relied on Supervised Fine-Tuning (SFT), training models on datasets of human corrections. However, this often failed in practice because it created a "distribution shift" - the model learned how to correct human mistakes, but still struggled to recognize its own unique statistical errors 1718.
In late 2024, researchers at Google DeepMind achieved a breakthrough with a novel training method called Self-Correction via Reinforcement Learning (SCoRe) 19. Rather than relying on external human graders or a separate "oracle" model, SCoRe trains the model entirely on self-generated data. Through a two-stage reinforcement learning process, the model is forced to solve a problem, make a mistake, generate a correction prompt, and attempt the problem again 17. The model is only mathematically rewarded when its second attempt accurately improves upon the first 1720.
By forcing the model to navigate its own noisy reasoning paths through trial and error, DeepMind successfully instilled an intrinsic "compass" for self-correction. When applied to the Gemini 1.5 Flash model, the SCoRe method improved the model's ability to autonomously correct its mathematical reasoning by 15.6 percentage points on the MATH benchmark, and improved code generation accuracy by 9.1 percentage points on the HumanEval benchmark 1920. This represents a critical step forward, proving that with the right reinforcement learning structures, models can be taught meta-strategies to mitigate their own hallucinations without external human hand-holding 20.
Defending the Truth: How to Detect AI Fabrications
As AI-generated text floods the internet, the burden of verifying reality increasingly falls on the end-user. Detecting hallucinations requires a combination of critical thinking, workflow adjustments, and specialized software tools.
For enterprise engineering teams, mitigating risk requires integrating hallucination detection directly into the deployment pipeline. Platforms like Maxim AI, Langfuse, Arize AI, and Galileo offer sophisticated observability tools tailored for this exact purpose 52. These platforms employ techniques such as embedding-based analytics to detect semantic drift, and "LLM-as-a-judge" mechanisms that use a secondary, highly reliable model to automatically audit the outputs of the primary model in real-time 52. If a customer service chatbot generates a response with a low confidence score, these systems can flag it for human review or suppress it entirely before it reaches the customer 1552.
For educators, researchers, and everyday users, spotting an AI hallucination requires recognizing the telltale behavioral quirks of probabilistic generation:
- Fake Specificity and "Vibe" Citations: AI models excel at mimicking the syntax and structure of reality. They will frequently provide highly specific dates, authors, and URLs that look perfectly formatted but lead to dead ends 1653. In academia, these are known as "vibe citations" - they look completely real at first glance, featuring plausible authors and accurate DOI structures, but cannot be found in Google Scholar or any library database 16.
- Unwavering Confidence in the Face of Absurdity: Language models are not programmed to express doubt unless explicitly instructed. A completely fabricated historical event or a physically impossible scientific claim will be delivered with the exact same authoritative, unwavering tone as the facts of the moon landing 53.
- Inconsistent Outputs Across Iterations: Because generation is probabilistic, a model relying on weak data will often change its story. If you open a new chat window, ask the exact same question, and receive a distinctly different set of facts, names, or dates, the model is almost certainly hallucinating 1553.
Bottom line
Large language models hallucinate because their foundational architecture is designed to predict the most statistically probable sequence of words, not to retrieve verified facts from a grounded database. While the industry is making significant strides through architectural interventions like retrieval-augmented generation (RAG) and self-correction training methods like DeepMind's SCoRe, the phenomenon of confident fabrication remains an inherent risk of the technology. Users must remain vigilant, treating AI as an immensely powerful tool for synthesis, coding, and ideation, rather than an absolute, unverified authority on factual reality.