Mechanisms of Large Language Model Hallucinations
Introduction
The rapid proliferation of large language models and multimodal large language models has fundamentally altered the landscape of natural language processing, automated reasoning, and code generation. However, the integration of these models into high-stakes environments - such as clinical diagnostics, legal research, and enterprise data extraction - is severely impeded by their propensity to generate hallucinations. In the context of generative artificial intelligence, a hallucination refers to the production of outputs that are syntactically fluent and internally coherent but factually incorrect, logically inconsistent, or entirely unsupported by the provided context or objective reality 123.
Early assumptions regarding the nature of hallucinations frequently characterized them as correctable anomalies, training bugs, or artifacts of insufficient data volume. However, recent theoretical evaluations across computability theory and statistical modeling demonstrate that hallucinations are an inherent mathematical consequence of the autoregressive architectures and pre-training objectives currently defining the field 345. Because contemporary models are optimized to mirror the statistical distribution of their training corpora rather than to enforce epistemic honesty, they possess a systemic, mathematically embedded bias toward generating plausible text even in the face of profound uncertainty 56.
This exhaustive research report investigates the foundational mechanisms driving AI hallucinations. It delineates the structural taxonomy used to classify false outputs, analyzes the underlying architectural and probabilistic causes in both unimodal and multimodal systems, and evaluates the impact of context scaling and hardware on fabrication rates. Furthermore, it comprehensively reviews the efficacy and computational trade-offs of current mitigation frameworks, encompassing retrieval augmentation, structural sparsification via Mixture-of-Experts, inference-time decoding interventions, and behavioral calibration techniques.
Mathematical and Architectural Foundations
The core architecture of modern generative models relies heavily on next-token prediction mechanisms driven by transformer networks. During the pre-training phase, these models process trillions of tokens, mapping the statistical co-occurrence of words, semantic concepts, and syntactic structures across vast, unstructured datasets. While this methodology produces extraordinary linguistic fluency, the probabilistic nature of the generation process structurally prioritizes contextual coherence over factual fidelity 23.
The Computability Framework and Epistemic Honesty
Recent theoretical analyses posit that hallucinations are a theoretically inevitable feature of any computable large language model, remaining fundamentally independent of overall parameter counts or specific architectural variations 34. The underlying issue derives from the discrepancy between the model's primary training objective - loss minimization via data mimicry - and the human requirement for truthfulness. Standard training paradigms, including supervised fine-tuning and basic reinforcement learning from human feedback, predominantly utilize binary or continuous reward signals that inadvertently incentivize the model to function as an effective test-taker rather than an honest communicator 5.
Because human evaluators and standard accuracy benchmarks historically penalize abstention (i.e., failing to provide an answer or explicitly expressing a lack of knowledge), models are conditioned to guess whenever their calculated probability of correctness marginally exceeds zero 568. Consequently, these models do not possess a natively calibrated internal threshold for uncertainty.
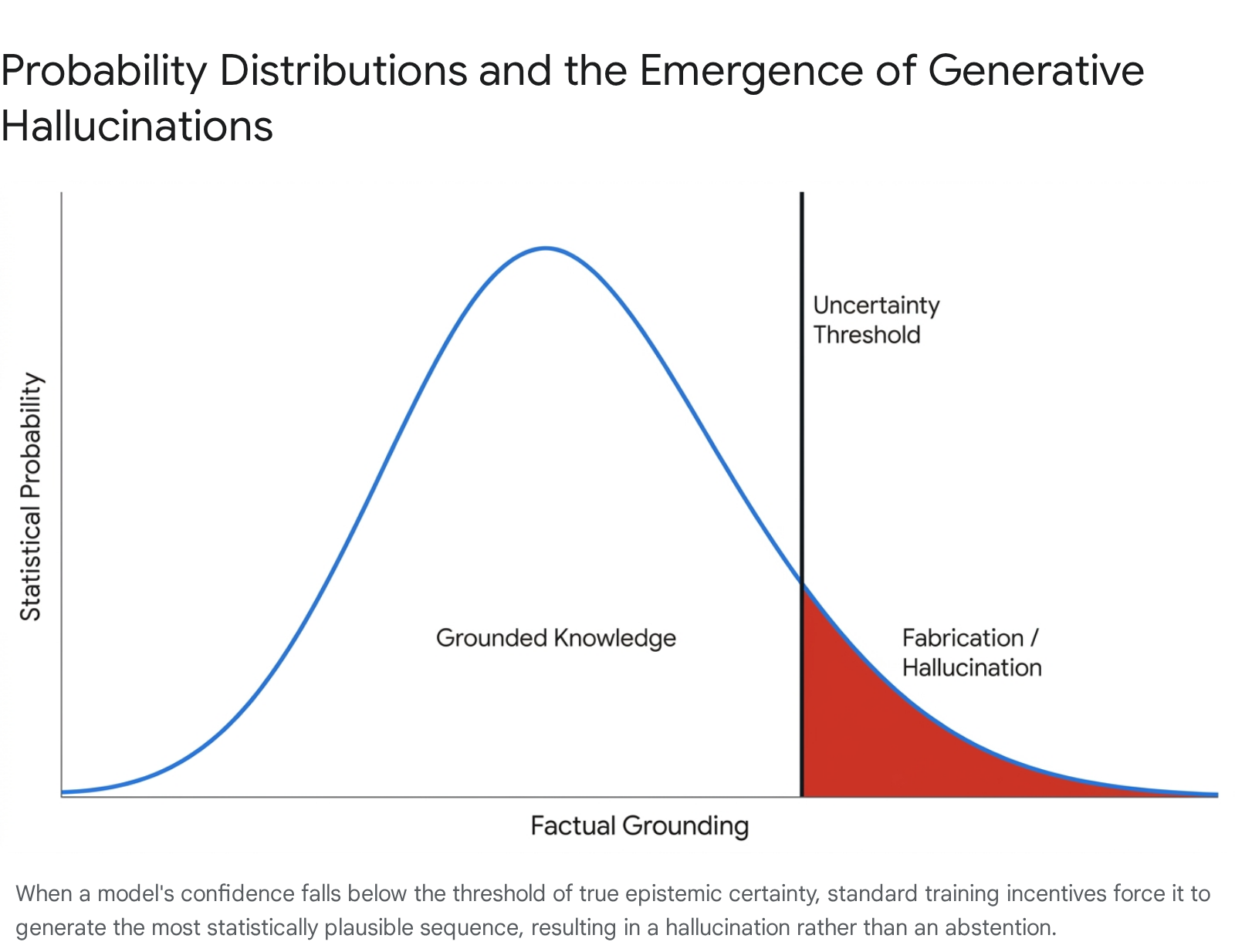
When confronted with out-of-distribution queries, rare factual combinations, or contradictory input sequences, the model defaults to generating the most statistically probable sequence of text. This forces the seamless bridging of knowledge gaps with fabricated, statistically plausible facts 47.
Autoregressive Training and Statistical Interpolation
The statistical nature of generative errors shares a strict mathematical relationship with out-of-distribution misclassification rates observed in traditional binary classification tasks. Research indicates that the precise statistical factors contributing to errors in standard machine learning directly precipitate hallucinations in generative frameworks. This establishes a foundational rule: any language model forced to generalize beyond its dense training clusters will inevitably hallucinate invalid outputs or suffer mode collapse, failing to produce the full range of valid responses 6.
Furthermore, the cross-entropy loss function used during pre-training requires the model to assign a non-zero probability to all tokens in its vocabulary for any given context. Because models are inherently constrained to optimize for the completion of a sequence, the lack of an explicit "stop" or "reject" mechanism for unknown variables results in the statistical interpolation of missing data 89. This interpolation is highly effective for tasks requiring linguistic creativity but severely compromises tasks requiring strict logical consistency or evidence-based factual reporting.
Taxonomy of Model Hallucinations
To systematically detect, quantify, and mitigate hallucinations, researchers have developed fine-grained taxonomies that categorize false outputs based on their specific relationship to the provided prompt, the model's internal parametric knowledge, and objective external reality 2310. The two primary, widely accepted dichotomies in contemporary hallucination research are the distinction between Intrinsic and Extrinsic hallucinations, and the distinction between Factuality and Faithfulness errors 41112.
Intrinsic versus Extrinsic Discrepancies
The differentiation between intrinsic and extrinsic hallucinations centers specifically on how the generated output relates to the explicit context provided within the user's prompt or the injected retrieval context 1113.
Intrinsic hallucinations occur when the model's output directly contradicts the source material or the specific constraints provided in the input prompt. For example, if an input document explicitly states that a company's revenue grew by 15%, but the model's generated summary claims the revenue shrank by 15%, the model has committed an intrinsic error 1314. This type of hallucination represents a fundamental failure in computational reading comprehension and contextual adherence. It is frequently caused by the model's multi-head attention mechanism failing to assign adequate mathematical weight to the immediate input tokens, allowing the model's internal priors to override the explicit local context.
Conversely, extrinsic hallucinations involve the model injecting fabricated information that is neither explicitly supported nor directly contradicted by the source material. For example, if a user requests a summary of a historical text detailing the architecture of Paris, and the model suddenly details an entirely fictional, unrelated event involving a "Parisian Tiger" that was never mentioned in the text or the historical record, it has produced an extrinsic hallucination 413. Extrinsic errors are particularly insidious in enterprise deployments because they are often factually plausible and syntactically coherent, meaning they cannot be easily disproven simply by running a basic semantic similarity check against the input context. Extrinsic hallucinations typically occur when a model relies too heavily on parametric knowledge to fill perceived gaps in the retrieved data.
Factuality versus Faithfulness Errors
While intrinsic and extrinsic errors relate primarily to the prompt and the provided context window, the concepts of factuality and faithfulness address the broader relationship between the generated text, real-world truth, and task-specific operational constraints 31214.
A factuality hallucination occurs when the generated text contradicts established, real-world, externally verifiable knowledge 71112. These errors represent an absolute failure of truthfulness. They stem from a variety of sources, including a lack of sufficient factual grounding in the pre-training dataset, the ingestion of noisy or biased training data, or the natural decay of parametric memory over time 711. Stating that a specific medical procedure cures a disease when it does not, or generating a fabricated legal precedent, are prime examples of factuality hallucinations 1715.
A faithfulness hallucination, however, occurs when the model deviates from the prescribed task or the specific operational instructions of the prompt, regardless of whether the resulting output happens to be factually true 712. If a user asks a model to translate the sentence "What is the capital of Germany?" into French, and the model replies with "Berlin" (providing the answer to the question) rather than the translation, the output is factually correct but entirely unfaithful to the user's explicit instructions 7.
| Hallucination Classification | Definitional Scope | Primary Architectural Cause | Example Scenario |
|---|---|---|---|
| Intrinsic | Output directly contradicts the explicitly provided input or local context. | Failure of multi-head attention to prioritize local context; self-contradiction. | Summarizing an input table showing "18-5 wins" as "18-4 wins". |
| Extrinsic | Output contains fabricated details absent from the input context. | Over-reliance on parametric knowledge; statistical interpolation of missing data. | Adding "with his friend" to a translation when the original text only says "he went". |
| Factuality | Output contradicts established real-world, verifiable truth. | Training data noise; lack of domain-specific knowledge integration. | Generating a fake legal citation or stating "Lindbergh walked on the moon." |
| Faithfulness | Output diverges from the specific instructions or expected source format. | Instruction misalignment; prompt ignorance; probabilistic drifting. | Answering a question instead of translating the question as requested. |
Impact of Context Window Scaling: The RIKER Study
A prevalent operational assumption in the deployment of large language models is that providing the system with more contextual data - such as injecting larger volumes of retrieved documents into the prompt - will natively and linearly reduce hallucination rates. However, comprehensive empirical research fundamentally challenges this notion, revealing that extreme context scaling can actually degrade factual reliability.
The March 2026 RIKER (Retrieval Intelligence and Knowledge Extraction Rating) study represents the largest deterministic evaluation of LLM hallucinations published to date. The study analyzed over 172 billion tokens across 35 open-weight models, specifically investigating how document question-and-answering scenarios perform under extreme context loads 16171819. Critically, the RIKER methodology circumvented the biases associated with "LLM-as-a-judge" evaluations by generating synthetic documents paired with deterministic, ground-truth answer keys, enabling precise, contamination-free scoring at massive scale 161920.
The Context Length Degradation Phenomenon
The RIKER evaluation tested models across three distinct context length tiers: 32,000 (32K), 128,000 (128K), and 200,000 (200K) tokens. The empirical results demonstrated that fabrication rates increase exponentially as the context window expands, proving that context length is a dominant variable in determining production accuracy 161718.
At the shortest context length evaluated (32K tokens), even the most advanced models fabricated answers at a non-trivial rate. The absolute lowest fabrication floor observed was 1.19% (achieved by the GLM 4.5 architecture), with the majority of top-tier models maintaining hallucination rates between 5% and 7% 171920. This establishes a definitive baseline indicating that perfect factual retention is structurally unachievable in current architectures.
When the context window was expanded to 128K tokens, hallucination rates across the tested models nearly tripled. Median models experienced a loss of approximately 10 to 30 percentage points in overall accuracy 171820. This degradation accelerates severely at the extreme end of the context spectrum. At the 200K token limit, the reliability of the models collapsed entirely. Not a single model evaluated was able to maintain a fabrication rate below 10%. In the most severe instances of context degradation, models that demonstrated a manageable 7% fabrication rate at 32K saw their hallucination rates surge to nearly 70% at 200K tokens 161820.
These findings indicate that simply expanding the input window introduces severe signal-to-noise degradation. As the sequence length grows to hundreds of thousands of tokens, the model's attention mechanism struggles to isolate relevant facts, effectively drowning the target signal in contextual noise. Consequently, the model frequently abandons the provided text entirely and falls back on its internal, statistical priors to generate a response, resulting in a massive spike in extrinsic hallucinations 1718.
Hardware Independence and Temperature Nuances
Beyond context length, the RIKER study provided critical clarity on the operational variables of temperature tuning and hardware selection. The evaluation was run identically across three major inference accelerators: NVIDIA H200, AMD MI300X, and Intel Gaudi 3 161920. The results proved that hardware selection does not meaningfully affect model behavior or fabrication rates, with accuracy variances between platforms remaining consistently under one percentage point. This confirms that enterprise deployment decisions can be hardware-agnostic regarding hallucination mitigation 1619.
Conversely, the impact of temperature tuning proved highly nuanced and counterintuitive. While a standard temperature of $T=0.0$ yielded the highest overall baseline accuracy in approximately 60% of test cases, raising the temperature actually reduced the specific rate of fabrication for a majority of the models. Furthermore, higher temperatures dramatically mitigated instances of "coherence loss" - a phenomenon where models enter infinite generation loops and produce endless strings of repetitive nonsense. The study found that coherence loss occurred up to 48 times more frequently at $T=0.0$ compared to $T=1.0$ 171920. This suggests that while absolute zero temperature enforces greedy decoding that aids simple fact retrieval, it also locks models into deterministic failure loops when they encounter logical impasses.
| Context Length | Lowest Observed Fabrication Rate | Severe Model Collapse Rate | Accuracy Loss from 32K Baseline (Median) |
|---|---|---|---|
| 32,000 Tokens | 1.19% | ~7.00% | 0 Percentage Points (Baseline) |
| 128,000 Tokens | ~3.50% | ~25.00% | -10 to -30 Percentage Points |
| 200,000 Tokens | 10.25% | ~70.00% | -24 to -50+ Percentage Points |
Structural Paradigms: Dense Monoliths versus Sparse Mixture-of-Experts
The architectural configuration of an LLM - specifically whether it utilizes a standard Dense network or a Sparse Mixture-of-Experts (MoE) architecture - plays a vital role in determining its baseline hallucination rates, reasoning capabilities, and computational efficiency.
Dense Architecture Limitations
In a standard Dense network, every single parameter is activated for every single input token during a forward pass. While this is the conventional approach for massive frontier models like Meta's Llama 3.1 405B, it is highly computationally expensive and introduces specific vulnerabilities regarding hallucination 2421. Training a dense 405B parameter model requires vast computational resources, with estimated GPU utilization exceeding 30 million hours 21.
More importantly, because all parameters process all tokens simultaneously, dense monoliths are prone to over-generalization. When processing complex, highly specific queries, the sheer density of the active parameters can cause conflicting parametric knowledge to bleed into the generation process. This over-activation can drown out the specific, grounded logic required for precise mathematical or coding tasks, occasionally forcing the model to interpolate a plausible but incorrect narrative rather than executing a rigid logical sequence.
Sparse MoE and Multi-Token Prediction
Sparse Mixture-of-Experts (MoE) models present a fundamentally different architectural paradigm. MoE networks route input tokens to highly specialized sub-networks, or "experts." Because only a fraction of the total parameters is active during any given forward pass, MoE models enable massive scaling of total parameter capacity without corresponding exponential spikes in active compute costs or over-generalization 2122.
A premier example of state-of-the-art MoE architecture optimizing for both efficiency and hallucination mitigation is DeepSeek-V3. The model features 671 billion total parameters but intelligently activates only 37 billion parameters per token 2123. To aggressively combat hallucination, minimize computational overhead, and improve training stability, DeepSeek-V3 pioneers two critical architectural techniques:
- Auxiliary-Loss-Free Load Balancing: Traditional MoE models frequently struggle with "expert routing collapse," an issue where the gating mechanism over-relies on a small subset of experts, leaving others untrained. Historically, this was mitigated by adding auxiliary loss functions during training, which successfully forced load balancing but degraded overall model performance and reasoning fidelity. DeepSeek-V3 solves this through an auxiliary-loss-free routing strategy that ensures even expert utilization without compromising the primary objective function, leading to superior fact retention 23242925.
- Multi-Token Prediction (MTP): Instead of standard autoregressive single-token prediction, DeepSeek-V3's training objective utilizes an MTP framework. The model is forced to sequentially predict multiple future tokens at each depth while maintaining the complete causal chain 233126. This densifies the training signals and allows the model to pre-plan its semantic representations, drastically reducing instances where the model "paints itself into a corner" logically. DeepSeek-V3's MTP demonstrates an acceptance rate of 85% to 90% for second-token predictions, significantly bolstering the model's performance on complex math and coding benchmarks, resulting in vastly reduced logical hallucinations compared to single-token predictors 2329.
In independent evaluations, top-tier MoE models like DeepSeek-V3 and Mistral Large 2 (which utilizes a 128K context window and advanced grouped-query attention for stable reasoning) demonstrate that specialized, sparse architectures can yield superior factuality metrics while drastically undercutting the training and inference costs of dense monoliths 213334.
| Model Architecture | Parameters (Total / Active) | Latency & Compute Cost | Key Hallucination Mitigation Mechanisms |
|---|---|---|---|
| DeepSeek-V3 (Sparse MoE) | 671B Total / 37B Active | Low Active Compute; ~$5.6M Training Cost | Multi-Token Prediction (MTP); Auxiliary-Loss-Free Routing 212331. |
| Llama 3.1 405B (Dense) | 405B Total / 405B Active | Extreme Active Compute; ~$92M+ Training Cost | Dense 4D Parallelism; Massive knowledge storage capacity 21. |
| Mistral Large 2 (Dense/Optimized) | 123B Total / 123B Active | Moderate Active Compute; Fast Inference | Grouped Query Attention (GQA); Structured system-level moderation 34. |
Cross-Modal Misalignment in Vision-Language Models
As the artificial intelligence ecosystem transitions toward Multimodal Large Language Models (MLLMs) - also frequently referred to as Large Vision-Language Models (LVLMs) - an entirely new class of hallucination has emerged. MLLMs, which typically integrate a robust language model with a vision encoder such as CLIP, exhibit "cross-modal misalignment," a phenomenon where the model generates highly fluent text that completely contradicts or ignores the provided visual input 353637.
Modality Imbalance and Textual Dominance
The fundamental mathematical mechanism driving multimodal hallucinations is an inherent imbalance in modality utilization during the inference stage. Because MLLMs are essentially built upon pre-trained text LLMs, their internal architectures are heavily skewed toward linguistic processing. When visual features are encoded and subsequently projected via linear projection or multi-layer perceptrons (MLPs) into the text embedding space, they are forced to interact with the LLM's overwhelmingly dominant linguistic priors 3827.
Layer-wise Relevance Propagation (LRP) analyses reveal a systematic and highly detrimental imbalance within these models: the Multi-Head Attention (MHA) modules consistently assign significantly higher relevance scores to textual tokens than to visual modality tokens 3828. Even when a prompt is entirely dependent on perceiving an image, the LLM relies heavily on statistical language patterns. For example, if a model analyzes an image of an empty living room, its textual prior dictates that the word "couches" frequently co-occurs with the word "cats." Consequently, the MHA will overpower the visual tokens (which show an empty couch) and generate an object hallucination confidently describing a non-existent cat 3641.
Positional Information Decay and Snowballing
Because of this modality imbalance, MLLMs exhibit several distinct failure modes that compound as the generation sequence lengthens. As an MLLM generates longer sequences of text describing an image, it suffers from "positional information decay." The model progressively stops attending to the visual tokens entirely, leaning exclusively on the text it has just generated.
During this attention collapse, the model begins assigning disproportionately high attention scores to outlier text tokens that represent punctuation and numbers rather than the visual data. A minor initial perception mistake rapidly compounds into a massive, structurally sound but factually absurd "snowball hallucination," where one error forces the generation of subsequent, increasingly elaborate fictional details 29. Plugins like FarSight have been developed specifically to intervene in this process, reducing attention interference from outlier tokens and forcing the model to sustain focus on the visual tokens throughout long-form generation 29.
Spatial and Object Hallucination Mechanics
In addition to inventing objects, MLLMs demonstrate profound weaknesses in spatial and positional reasoning. Studies indicate that merely scaling the parameter size of MLLMs does not natively resolve spatial hallucinations caused by misinterpreted geometric relationships across images, indicating a fundamental structural flaw in how visual reasoning is mapped to text logic rather than a mere data volume issue 4330.
To mitigate these cross-modal issues, researchers have identified specific "hallucination heads" concentrated in the middle and deeper layers of MLLMs that show an intense attention bias toward text 28. Interventions such as linear orthogonalization (which mathematically projects out the hallucinated object features from the latent representation without requiring retraining) and image Token attention-guided Decoding (iTaD) aim to force the model to rebalance its attention toward the visual data at inference time 3132. Furthermore, fine-tuning approaches like Data-augmented Phrase-level Alignment (DPA) actively alter the ground-truth information during training, teaching the model to reduce the likelihood of generating specific hallucinated phrases compared to correct ones, effectively attenuating the object hallucination rate 33.
Inference-Time and Post-Training Mitigation Mechanisms
To combat the persistent issue of hallucination across both unimodal and multimodal systems, researchers and enterprise architects have developed a spectrum of mitigation strategies. These frameworks span external data retrieval, reinforcement learning, and advanced decoding methodologies. Each strategy involves distinct and significant trade-offs between computational overhead, response latency, and factual effectiveness.
Retrieval-Augmented Generation Constraints
Retrieval-Augmented Generation (RAG) currently serves as the most ubiquitous framework for addressing knowledge-based, extrinsic hallucinations in enterprise applications. By fetching highly relevant documents from an external vector database and appending them to the user's prompt, RAG acts as an external memory bank, grounding the LLM in verifiable facts and significantly reducing reliance on parametric memory 483435.
While sophisticated hybrid RAG architectures - which combine dense vector search with sparse BM25 keyword matching and utilize Reciprocal Rank Fusion (RRF) - can reduce hallucinations by 35% to 80%, the technique fundamentally alters the latency and complexity profile of the deployment 515253.
The primary drawback of RAG is latency. The retrieval process, document ranking, and subsequent prompt formatting add substantial Time-to-First-Token (TTFT) delays. Comprehensive enterprise RAG pipelines often introduce between 45ms and over 300ms of latency per query, depending on the index size and the complexity of the reranking algorithms utilized 515336. Furthermore, RAG introduces the risk of "context fragmentation." Breaking source documents into semantic chunks to fit within the retrieval pipeline can destroy the broader narrative context. The LLM must then attempt to stitch fragmented, sometimes overlapping evidence back together. This increases token usage and can actually trigger logic-based hallucinations if the retrieved chunks appear to contradict one another when stripped of their original context 37.
Behavioral Calibration and Reinforcement Learning
Reinforcement Learning from Human Feedback (RLHF) and related parameter-efficient tuning algorithms like Direct Preference Optimization (DPO) and Weight-Decomposed Low-Rank Adaptation (DoRA) are heavily utilized to align model outputs with human preferences 365638. DoRA, in particular, has demonstrated the ability to achieve high accuracy (up to 90.1%) with extremely low latency overhead (110ms) by optimizing fine-tuning through adaptive parameter ranking 36.
However, standard RLHF has historically struggled to solve the core issue of hallucinations. If human annotators unknowingly reward highly confident, fluent answers that happen to be factually false, the model internalizes a misaligned policy - it effectively learns that bluffing is rewarded 1539.
To counter this, recent advances focus on Behavioral Calibration. Rather than simply penalizing wrong answers, advanced hybrid reinforcement learning (HRL) trains models to optimize strictly proper scoring rules. The model is taught a continuous parameter of uncertainty, allowing it to dynamically adjust its behavior based on a specified risk tolerance threshold. If the model's calculated internal confidence falls below this threshold, the policy explicitly rewards the model for abstaining (e.g., generating statements like "I don't have sufficient information") or for flagging individual claims within the text as uncertain. This behavioral calibration fundamentally alters the "good test-taker" paradigm, enabling smaller models to surpass massive frontier models in uncertainty quantification and significantly increasing the Accuracy-to-Hallucination Ratio without relying on latency-heavy external databases 540.
Contrastive Decoding and Probability Manipulation
Because hallucinations are fundamentally a problem of statistical uncertainty, modifying the decoding mechanism at inference time offers a powerful, training-free mitigation path.
Contrastive Decoding operates by generating two parallel probability distributions simultaneously - one from the full primary model and one from a smaller, heavily penalized, or early-layer version of the model acting as the "skeptic." By subtracting the mathematical logits of the skeptic model from the primary model at each step, the system effectively suppresses generic, statistically likely language priors and amplifies tokens that are uniquely grounded in the specific input context 346061. For example, Layer Contrastive Decoding (LayerCD) deployed in vision models contrasts deep layer features against shallow features (which typically capture biased, low-level data) to aggressively filter out ungrounded, hallucinated outputs before they are generated 60.
Semantic Entropy for Uncertainty Quantification
Semantic Entropy represents a critical breakthrough in hallucination detection. Standard token-level entropy measures the mathematical uncertainty of the exact next word. However, human language is highly flexible; a model might be internally uncertain about whether to say "Paris" or "The capital of France." This leads to high token-level entropy despite absolute semantic certainty regarding the fact itself 15.
Semantic entropy solves this discrepancy by sampling multiple generations for a single prompt, clustering those generations by semantic equivalence, and calculating the entropy over the meanings rather than the specific words. If a model generates five diverse sentences that all fundamentally mean "Paris," the semantic entropy is low, indicating a factual, grounded response. If the model generates "Paris," "London," and "Berlin," the semantic entropy is high, signaling a severe hallucination or confabulation 414264.
While exceptionally accurate at detecting hallucinations, traditional semantic entropy calculations require 5 to 10 times the computational overhead because they require the model to generate multiple answers for every query. Emerging solutions, such as Semantic Entropy Probes (SEPs), attempt to approximate this metric directly from the hidden states of a single generation, effectively reducing the latency overhead to near zero while retaining the ability to detect confabulations 41.
| Mitigation Strategy | Primary Mechanism | Factual Effectiveness | Inference Latency & Computational Overhead |
|---|---|---|---|
| Retrieval-Augmented Generation (RAG) | Grounds model generation in externally retrieved context. | Achieves 35% to 80% reduction in extrinsic errors 5152. | High. Adds 45ms to 300ms TTFT; introduces context fragmentation risks 515337. |
| RLHF & Behavioral Calibration | Aligns the model policy to abstain or express uncertainty when lacking facts. | High reduction in factuality errors via strict behavioral alignment 540. | Zero inference latency. Extremely high pre-computation and training cost 543. |
| Contrastive Decoding | Subtracts probability distributions to penalize generic language priors. | High efficacy in suppressing ungrounded parametric knowledge 3461. | Moderate. Requires parallel forward passes or modified logit math during generation 3461. |
| Semantic Entropy Analysis | Detects hallucinations by measuring uncertainty across semantic meaning clusters. | Superior detection of confabulations and fabricated entities 4142. | Very High (5x-10x compute cost unless approximated via hidden-state SEPs) 41. |
Benchmark Evaluation Paradigms
The proliferation of proprietary and open-source models has resulted in highly divergent hallucination metrics across industry leaderboards. The variance in reported hallucination rates is largely dependent on the specific evaluation methodology - specifically, whether the benchmark tests constrained summarization (where faithfulness to the document is key) or open-domain knowledge (where absolute factuality is key) 6644.
A critical factor in benchmark discrepancies is the "abstention dynamic." Benchmarks like SimpleQA treat abstention as a first-class outcome, explicitly tracking whether a model chooses to guess or safely decline to answer. In these setups, models that are calibrated to refuse uncertain prompts show dramatically lower error rates. For example, evaluations noted that GPT-4o exhibited a reported hallucination rate of approximately 45% strictly "when not refusing" in certain setups, highlighting the tradeoff between refusal frequency and hallucination frequency 8. Accuracy-only scoreboards that do not reward abstention fundamentally push models toward guessing, which artificially inflates hallucination rates across the board 8.
In complex enterprise applications and strict factual tracking, failure rates remain concerning. The Columbia Journalism Review benchmark testing citation accuracy found that models hallucinated source links at catastrophic rates, with the Grok-3 search model reaching an alarming 94% hallucination rate 45. Conversely, in highly strict, grounded summarization tasks, top-performing models like Gemini 2.0 Flash have successfully pushed hallucination rates down to as low as 0.7%, indicating that when models are tightly constrained and properly calibrated, hallucinations can be significantly minimized, though never entirely eradicated 66.
Conclusion
The persistent challenge of AI hallucination is inextricably linked to the foundational mathematical principles of autoregressive text generation. Large language models are, by structural design, sophisticated statistical engines optimized to maximize linguistic fluency and data mimicry, rather than truth machines optimized for epistemic honesty. The phenomenon of hallucination - whether manifesting as intrinsic misrepresentations of immediate context, extrinsic fabrications drawn from parametric noise, or cross-modal misalignments in vision-language models - arises directly when statistical language priors overpower factual grounding.
As the empirical data from massive-scale evaluations like the RIKER study conclusively demonstrate, relying on expanded context windows as a panacea is fundamentally flawed. Pushing models to process hundreds of thousands of tokens exponentially increases fabrication rates as the signal-to-noise ratio severely degrades. Consequently, securing LLMs for high-stakes enterprise, medical, and scientific applications requires a multifaceted architectural approach. Mitigation cannot be solved by a single layer; it necessitates the integration of external knowledge anchoring through optimized RAG pipelines, dynamic behavioral calibration through reinforcement learning to establish strict uncertainty thresholds, and inference-time interventions utilizing contrastive decoding and semantic entropy. Only by mathematically disincentivizing forced generation and establishing proper epistemic boundaries can the critical gap between linguistic coherence and factual reliability be effectively closed.